


Data are the building blocks of research, and access to data is necessary to fully understand and extend the work of others (Fienberg, Martin, and Straf Reference Fienberg, Martin and Straf1985). Yet archaeological data are often not available for a variety of reasons, including a perceived lack of credit for making data available. The goal of this article is to present a standard for the scholarly citation of archaeological data, akin to the way we cite publications. The need for this has been motivated by Huggett's (Reference Huggett2017) findings of low levels of data citation and reuse in archaeology and Clarke's (Reference Clarke2015) analysis that digital data preservation and management systems are underdeveloped in archaeology, despite our obligations as stewards of cultural heritage. A standard for data citation is important because it gives credit to the authors or compilers of the data and so accords them visibility and recognition for their scholarly contribution in a way that is valued broadly in the discipline. A citation standard is also important for tracking the use of data and generating metrics about the impact of a dataset on the discipline. Understanding the use of resources such as datasets is important for allocating resources within archaeology and identifying novel research directions.
Archaeologists work with data in research, commercial, government, and other contexts. A full investigation of data in each of these contexts is beyond the scope of this article, so we limit this study to what we are most familiar with, the research context. However, many of the practical details we discuss here will also be relevant to archaeologists working in other contexts. We begin by defining what we mean by “data” and reviewing previous work on researchers’ attitudes to sharing data. We motivate data sharing and citing behaviors by explaining why data sharing is beneficial to archaeology as a discipline and to individual researchers. Then we survey some of the data sharing and citing norms that have emerged in other research areas. From these norms we derive a standard suitable for the citation of archaeological data. Finally, we present some basic instructions on how to share archaeological data.
WHAT ARE DATA?
Defining what data are is an ongoing research problem for information scientists (Borgman Reference Borgman2012; Leonelli Reference Leonelli2016). Table 1 summarizes some of the definitions debated in the philosophy of science literature. A more concrete starting point is this definition from the National Academies of Sciences:
The term “data” as used in this document is meant to be broadly inclusive. In addition to digital manifestations of literature (including text, sound, still images, moving images, models, games, or simulations), it refers as well to forms of data and databases that generally require the assistance of computational machinery and software in order to be useful, such as various types of laboratory data including spectrographic, genomic sequencing, and electron microscopy data; observational data, such as remote sensing, geospatial, and socioeconomic data; and other forms of data either generated or compiled, by humans or machines [Uhlir and Cohen Reference Uhlir and Cohen2011, cited in Borgman Reference Borgman2015 p. 1061].
TABLE 1. Selection of Definitions of Research Data.

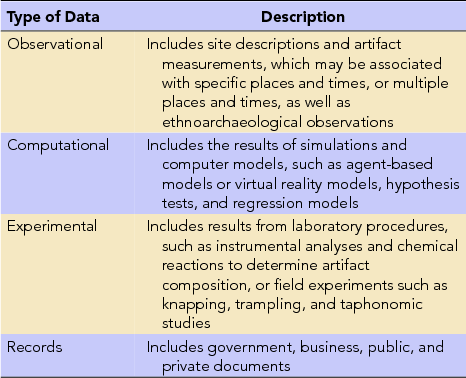
This is a useful definition because it emphasizes data as digital manifestations and so suitable for transmission, storage, and retrieval using the internet. Physical objects (such as samples, collections, hard copies of notes, etc.) are data also, but they are out of the scope of this discussion because of the different challenges and requirements for access, archiving, and so on. The categories shown in Table 2 are useful as a rough guide to what data can be, although this table is not comprehensive and does not represent the full diversity of data used by archaeologists. Ultimately, data are whatever the community decides, as the National Science Foundation notes in its commentary on data management plans: “‘Data’ are defined as the recorded factual material commonly accepted in the scientific community as necessary to validate research findings. This includes original data, but also ‘metadata’ (e.g. experimental protocols, code written for statistical analyses, etc.)” (2010).
TABLE 2. Selection of Types of Data Encountered by Archaeologists.
These definitions in policy are consistent with the relational account of data in philosophy of science scholarship, which holds that what data are is dependent on who uses it, how, and for what purpose (Daston and Galison Reference Daston and Galison1992; Leonelli Reference Leonelli2015). How can these definitions and philosophical discussions inform our practice? They tell us that what count as data are emergent from our professional interactions. Data are the materials we request when we do peer review of manuscripts and grant proposals or when we make an informal request for more information by e-mail. They are not exclusively objective archaeometric records but, rather, include interpretive and derivative results. In short, data are anything another person needs to understand our work better.
To translate this into a more applied context, our practice of data sharing is to make available the computer files (e.g., containing text, raw structured data, images, etc.) that we analyze or otherwise use to create the figures, tables, and quantitative results that we include in our reports and publications. These include our derived results and secondary data, such as taxonomic and typological classifications. This selection omits materials that could also be considered data according to the definitions noted above (e.g., field notes), but we feel that our selection represents the most information-dense and meaningful items that are useful for our community of interest. These are also the items that have been most frequently requested from us by others in our professional interactions. Our citation standard is inclusive and imposes no constraints on what data can be, but we propose a few minimal qualities for how data should be organized that will help ground our discussion.
WHAT ARE THE ETHICS OF DATA SHARING?
A full treatment of the ethical issues of data sharing is beyond the scope of this article, but we can highlight some points specifically relevant to the question of when not to share archaeological data. Much of the discussion on ethics and data sharing generally relates to appropriate attribution (assigning credit for the data) in data reuse (Duke and Porter Reference Duke and Porter2013). The default position for archaeological data, like data from many other sciences, is that they are part of the global human patrimony and should be accessible to other scholars and the public (Vitelli and Colwell-Chanthaphonh Reference Vitelli and Colwell-Chanthaphonh2006; Zimmerman et al. Reference Zimmerman, Vitelli and Hollowell-Zimmer2003). However, archaeologists, like other researchers working with local and indigenous communities, governments, and international collaborators, generate research data that are intellectual property with many stakeholders. With diverse stakeholders, archaeological data can become entangled in economics, nationalism, cultural politics, and identity (Nicholas and Wylie Reference Nicholas, Wylie, Young and Brunk2009). Often, one of these stakeholders is an indigenous community, and archaeologists may find differences between Western and indigenous conceptions of what data are and how they may be generated, used, shared, and “owned” (Harding et al. Reference Harding, Harper, Stone, O'Neill, Berger, Harris and Donatuto2012).
One of these differences is that Western researchers often have individual autonomy in sharing data, and once data are shared, they are free for all to use. In contrast, within many indigenous communities, data are part of the group's identity and property, akin to tangible heritage (Nicholas Reference Nicholas, Coombe, Wershler and Zeilinger2014), with certain members entrusted to keep that data on behalf of the group, and sometimes it may be inappropriate for these people to share data with other members of the group or beyond the group (Tsosie Reference Tsosie2007). Differences between Western and indigenous concepts of data are not only cultural—substantial inequalities exist in access to resources for converting archaeological data into economic and political benefit (e.g., graduate degrees, employment, publications, grants, promotions). On one hand, making archaeological data openly available benefits indigenous communities because it removes some of the financial and technical barriers to accessing that data (e.g., subscription fees to journals). On the other hand, this may be little more than a useless courtesy (Hymes Reference Hymes1972), because simply making data openly available does not give indigenous people access to the contexts where data can be used to generate economic and political benefits. Thus, open data have different values for Western and indigenous communities, and if archaeologists want to make a compelling case to their indigenous partners for data sharing, they should also make a commitment to reducing some of the inequalities in making use of the data, for example, by providing some training in data analysis or adapting the data to a context that is valued by the indigenous community.
In short, there is more to the ethics of data sharing than avoiding risk of damage. Redacting the locations of archaeological sites to prevent looting is an obvious case of preparing data for sharing to reduce the risk of damage to the sites (and in some jurisdictions, mandated by law). However, because of cultural, economic, and political differences between Western archaeologists and the communities they work with, archaeologists cannot consider their own risk assessment to be comprehensive and exhaustive (Nicholas and Wylie Reference Nicholas, Wylie, Coningham and Scarre2012). It is crucial for archaeologists to discuss data sharing plans during negotiations with representatives authorized by the indigenous peoples whose cultural heritage is the subject of investigation. This negotiation process is important because only indigenous peoples themselves can identify potential adverse outcomes to data sharing, and they can do this only if they understand the proposed research and anticipated results. The concrete outcome of this process is often a memorandum of understanding between the indigenous community and the archaeologist's employer that documents the outcome of negotiations about data sharing. If an archaeologist's indigenous partners have reasons not to share data in public, then the archaeologist should respect that position and note in publication that the data are restricted at the request of the indigenous collaborators.
WHAT ARE THE BENEFITS OF DATA SHARING TO THE INDIVIDUAL RESEARCHER?
While public and community benefits and costs are well rehearsed and widely agreed on (Tables 3 and 4), they offer no, or only weak, tangible incentives to the individual researcher (Rowhani-Farid, Allen, and Barnett Reference Rowhani-Farid, Allen and Barnett2017). Previous work has identified citation advantages as a tangible benefit to individual researchers who share data with publications, although the magnitude of the advantage varies greatly (see Table 5 for a summary). Increased publication productivity also appeared to be associated with data sharing behaviors. Across more than 7,000 National Science Foundation and National Institute of the Humanities awards, Pienta, Alter, and Lyle (Reference Pienta, Alter and Lyle2010) report that research projects with archived data produced a median of 10 publications, vs. only five for projects without archived data.
TABLE 3. Summary of Public and Community Costs of Data Sharing.
Source: From Borgman Reference Borgman2012; Stodden Reference Stodden2010.
TABLE 4. Summary of Public and Community Benefits of Data Sharing.

Source: From Borgman Reference Borgman2012; Stodden Reference Stodden2010.
TABLE 5. Summary of Individual Benefits to Data Sharing.

WHAT DO RESEARCHERS THINK ABOUT SHARING DATA?
Sharing of data is a quality that is fundamental to the definition of science (cf. Merton's [Reference Merton and Merton1942] communalism norm, where intellectual property rights are normally given up in exchange for recognition and esteem) and to data both as an abstract quality (cf. the definitions in Table 1 that mention data as “portable,” “stable across different domains”) and as a concrete detail to be managed with policy. For example, for over a decade the National Science Foundation has had a data sharing policy that states:
Investigators are expected to share with other researchers, at no more than incremental cost and within a reasonable time, the primary data, samples, physical collections and other supporting materials created or gathered in the course of work under NSF grants. Grantees are expected to encourage and facilitate such sharing [2016].
Surveys of researchers across different domains repeatedly show that people value the ideal of data sharing (Kratz and Strasser Reference Kratz and Strasser2014, Reference Kratz and Strasser2015). However, data sharing is not widespread in many disciplines, raising questions about why researchers do or do not share their data. Three recent studies have attempted to answer these questions, in the search for strategies to encourage sharing.
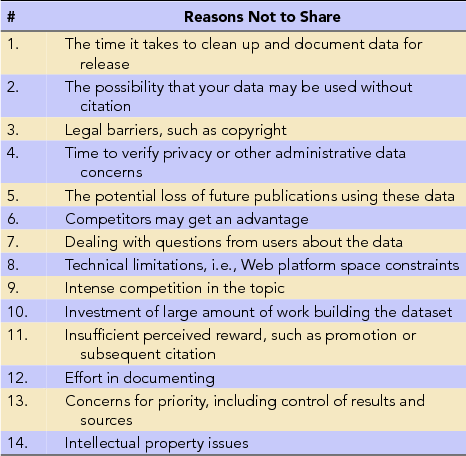
Stodden (Reference Stodden2010) surveyed registrants at a top machine learning conference (the Neural Information Processing Systems conference) to identify the factors that affect researchers’ decisions to reveal data (Table 4). Stodden found that communitarian factors influence scientists to share their data but private incentives determine when scientists choose not to share their code and data. In the top three reasons not to share, we see a lack of incentives to invest time in data sharing (however, there are many other time-consuming tasks in research, and they get done because clear reward structures are in place), a lack of faith in data citation (which we hope this article will help with), and a lack of an efficient copyright process. Stodden's (Reference Stodden2009a, Reference Stodden2009b) “Reproducible Research Standard,” summarized in Table 6, is a convenient and robust copyright schema that is in wide use for many typical research projects.
TABLE 6. Summary of Stodden's “Reproducible Research Standard.”

Note: This standard realigns legal rights with scientific norms by freeing scientific work from copying and reuse restrictions, with attribution. It encourages researchers to release their products with standardized instructions for reuse and attribution.
Source: Stodden Reference Stodden2009a.
Other surveys have found similar results. Tenopir and colleagues (Reference Tenopir, Allard, Douglass, Aydinoglu, Wu and Frame2011) received 1,329 responses to a survey conducted by the research team of the National Science Foundation–funded DataONE project. They found that when researchers did not share data it was due to reasons that included insufficient time (54%), a lack of funding (40%), having no place to put the data (24%), a lack of standards (20%), and the fact that their sponsor did not require it (17%). A remarkable observation by Tenopir and colleagues is that while 75% of respondents said that they shared data, only 36% of those respondents said that their data are easy to access, while only 6% said that they make all their data available. This suggests that most data sharing occurs in private directly between individual researchers, rather than in public via open repositories. A similar focus on private, peer-to-peer sharing is evident in interviews conducted by Wallis and colleagues (Reference Wallis, Rolando and Borgman2013) with 43 researchers at the Center for Embedded Networked Sensing. They found that the most commonly cited conditions for sharing data were (1) first rights to publish results, (2) proper attribution to the data source, (3) familiarity between sharer and recipient, (4) funding agency expectations, and (5) the amount of effort required to share.
WHAT ARE THE CURRENT NORMS OF DATA SHARING?
The surveys above show that data sharing practices tend to be a private activity, but where public sharing does occur, what forms does it take, and how do these vary across different fields of research? Wouters and Haak (Reference Wouters and Haak2017) surveyed 1,200 researchers about data sharing behaviors and found a spectrum from “intensive data-sharing fields” to “restricted data-sharing fields.” Intensive data-sharing fields often depend on access to global databases, for example, human genetics, while restricted data-sharing fields depend mostly on data collected by the individual researcher or his or her immediate collaborators, such as digital humanities. These differences in disciplinary norms have implications for data ownership (intensive: collectively owned, willing to share; restrictive: owned by the individual, reluctant to share) and the effort required to share (intensive: low effort because data are prepared for sharing as an integral part of the research process; restrictive: high effort because data are prepared for sharing after the research, or apart from it, in response to a request from another researcher).
This intensive-restricted spectrum also maps onto Sawyer's (Reference Sawyer2008) analysis of data sharing in data-rich fields compared with data-poor fields. Data-rich fields, such as astronomy, oceanography, and ecology, have three common characteristics: Pooling and sharing data resources is expected; the cumulative nature of work that builds on common data and common methods reduces the likelihood of alternative data sources and other methods being widespread; and the number of theoretical choices is limited because there is enough data to adequately test competing theories. Data-poor fields have three common characteristics: Data are rare, or hard to get, or both; the types of data available often dictate the methods used; and theories are relatively easy to generate and more difficult to validate. In data-poor fields, researchers often invest substantial time and resources on gathering their own data. The accumulation of data, and the quality of the data collected, is often a key determinant of the status of a researcher, leading to hoarding of data as an asset to be traded for professional benefit.
Archaeologists can be found all over this spectrum because of the diversity of archaeological research. However, our observations of data sharing in archaeology, and the nature of archaeological research generally, indicate that it is, for the most part, currently a restricted data-sharing and data-poor field. There are few standardized and widely used methods for sharing and citing data, a challenge for archaeological data sharing that we hope this article will help to address.
Even though there is a wide spectrum of data sharing behaviors, overall rates of data sharing by individual researchers are very low in many fields. Wicherts and colleagues (Reference Wicherts, Borsboom, Kats and Molenaar2006) e-mailed authors of 141 empirical articles recently published by American Psychological Association (APA) journals to request a copy of the original data reported in the article. They received 64 of the 249 datasets they requested, resulting in a data sharing rate of about 26%, despite all the authors of the articles in their study being bound by the APA's Ethical Principles, which stated that authors must “not withhold the data on which their conclusions are based from other competent professionals who seek to verify the substantive claims” (APA 2001:396). Vanpaemel and colleagues (Reference Vanpaemel, Vermorgen, Deriemaecker and Storms2015) similarly requested data for 394 articles, published in all issues of four APA journals in 2012, and found that 38% of authors responded with their data. They conclude that although the data sharing rate increased as compared with the study by Wicherts and colleagues, their findings are “worrisome” and indicate a “poor availability of data” (Vanpaemel et al. Reference Vanpaemel, Vermorgen, Deriemaecker and Storms2015: 3).
Savage and Vickers (Reference Savage and Vickers2009) requested data from the authors of 10 papers published in PLOS journals and received only one reply. Although this is a very small sample, it is notable because PLOS journals require authors to share data as a condition of publication: “PLOS journals require authors to make all data underlying the findings described in their manuscript fully available without restriction, with rare exception” (PLOS Editorial and Publishing Policies 2017); and yet only one out of the 10 authors actually complied with this requirement. Alsheikh-Ali and colleagues (Reference Alsheikh-Ali, Qureshi, Al-Mallah and Ioannidis2011) inspected 500 articles published in high-impact science journals in 2009 and found that only 47 essays (9%) deposited full primary raw data online. Similarly, Womack (Reference Womack2015) inspected 4,370 articles published in high-impact science journals in 2014 and found that 13% of articles with original data published had made the data available to others.
The absence of a standardized and sustainable approach to data sharing is starkly demonstrated by Vines and colleagues (Reference Vines, Albert, Andrew, Débarre, Bock, Franklin and Rennison2014) study of data availability over time in biology publications. They examined the availability of data from 516 studies of plants or animal morphology between two and 22 years old. Vines et al. found that the odds of a dataset referred to in a publication being available fell by 17% per year. They found that the key factors responsible for the unavailability of data were that the data were lost or on inaccessible storage media.
DO ARCHAEOLOGISTS SHARE DATA?
Here we present the results of three small pilot studies aimed at understanding how archaeologists share their data. First, we e-mailed a sample of authors of research publications to request access to the data behind their publication. Second, we surveyed a sample of journal articles to see what data were available. Third, we analyzed information about archaeological data files in online repositories tracked by DataCite (an organization that provides persistent identifiers, or digital object identifiers [DOIs], for research data). The small sample sizes of the first two of these pilot studies limit how generalizable the results are, but as the first of their kind for archaeology, they are valuable for proposing hypotheses for larger-scale investigations.
Reproducibility and Open-Source Materials for This Study
To enable reuse of our materials and improve reproducibility and transparency according to the principles outlined in Marwick Reference Marwick2017, we include the entire R code used for all the analysis and visualizations contained in this article in our compendium at http://doi.org/10.17605/OSF.IO/KSRUZ. Also in this version-controlled compendium are the raw data for all the tests reported here. All of the figures and quantitative results presented here can be independently reproduced with the code and data in this repository. In our compendium our code is released under the MIT license, our data as CC-0, and our figures as CC-BY, to enable maximum reuse (for more details, see Marwick Reference Marwick2017).
E-mail Requests for Data in a Published Article
Our sample focused on Journal of Archaeological Science articles on experiments with stone artifacts that were published during 2009 and 2015. We focused on stone artifact experiments because all research materials in these projects are generated by the researcher, so there are no other stakeholders to consider when determining how to share the data: the researcher has complete control over the data. There are also no risks of damage to people or property in sharing these data because they do not include archaeological sites or human subjects. Because we contacted authors of essays at the intersection of (1) containing eminently sharable data and (2) our bona fide research interests (i.e., stone artifacts for BM), this is a targeted, nonrandom sample that may not be representative of the entire archaeological community. In contacting the authors, we requested the datasets for use in a graduate seminar with the aim of reproducing the published results and further exploring the data (this stage is still in progress). We promised to contact the authors if we discovered anything new and not to share the data further without their permission. The data included with this article are anonymized so the specific authors we contacted are not identifiable.
We sent out e-mails to the first authors of 23 stone artifact experiment articles and received 15 replies, resulting in a 70% response rate. We received five responses that included data files, giving an overall sharing rate of 20%. Our small sample size limits the robustness of our analysis but points to some observations that may be worth following up in a larger study. We found no clear relationship of data sharing and date of publication. We do not have any insights into why authors of older essays declined to share, but three of the six responses for articles published in 2014–2015 said that they declined to share data because they intended to use these data in a future publication. Other noteworthy reasons provided by respondents for declining to share include the fact that the authors were about to defend their thesis or about to go on vacation. We found no effect of the author's student status at time of publication on data sharing behaviors, with roughly equal proportions of students and nonstudents sharing and not sharing (Figure 1).
Similarly there are no clear patterns of data sharing among different journals. It is remarkable that the authors of the PLOS ONE article we contacted declined to share because that refusal violates the policy of that journal at the time of publication of the essay (early 2014). Our finding is not unique—Chambers (Reference Chambers2017) examined 50 PLOS ONE articles on brain images published in November 2014–May 2015 and found that only 38% of the essays’ authors had archived their data in an open repository. Similarly, Nuijten and colleagues (Reference Nuijten, Borghuis, Veldkamp, Alvarez, van Assen and Wicherts2017) found that of 462 PLOS ONE articles that promised data availability, 29% of these did not have any available data. Unfulfilled promises to share data are not unique to PLOS ONE (Kidwell et al. Reference Kidwell, Lazarević, Baranski, Hardwicke, Piechowski, Falkenberg and Nosek2016), but these studies highlight the need to resolve ambiguity among authors about what count as data and for editors and peer reviewers to more critically assess whether authors have made their data openly available.
We see similar rates of sharing in response to e-mail requests among archaeologists to what have been described in other disciplines (Table 7; Tenopir et al. Reference Tenopir, Dalton, Allard, Frame, Pjesivac, Birch and Dorsett2015; Vanpaemel et al. Reference Vanpaemel, Vermorgen, Deriemaecker and Storms2015). However, our results may overestimate the true rate because our sample did not include datasets that authors might not be able or willing to share because they contain sensitive location or cultural information. Analysis of the qualitative responses we received suggests two key reasons why authors are reluctant to share: they are fearful that they will lose the opportunity to produce further publications from those data (a typical concern of researchers in data-poor fields) and that their data are not in a form suitable for sharing and the task of organizing those data is not a high priority. These reasons not to share have also been documented in other research areas, noted above. The absence of patterns in the date of publication, student status of the author, and other variables (Figure 1) may relate more to our small sample size than to a real absence of relationships in data sharing behavior.
TABLE 7. Summary of a Selection of Previous Studies of Data Sharing in Various Fields.
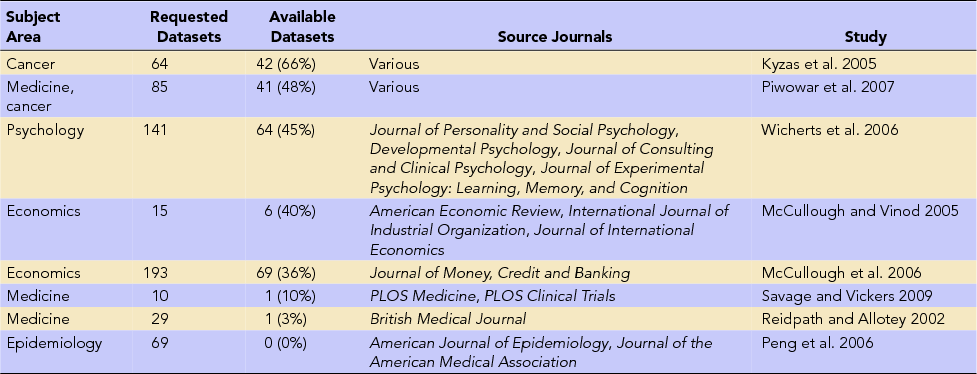
Note: In the study by Peng, Dominici, and Zege (Reference Peng, Dominici and Zege2006), the authors did not attempt to contact other researchers but note the availability of data as described in the published article.
Source: From Spencer Reference Spencer2010.
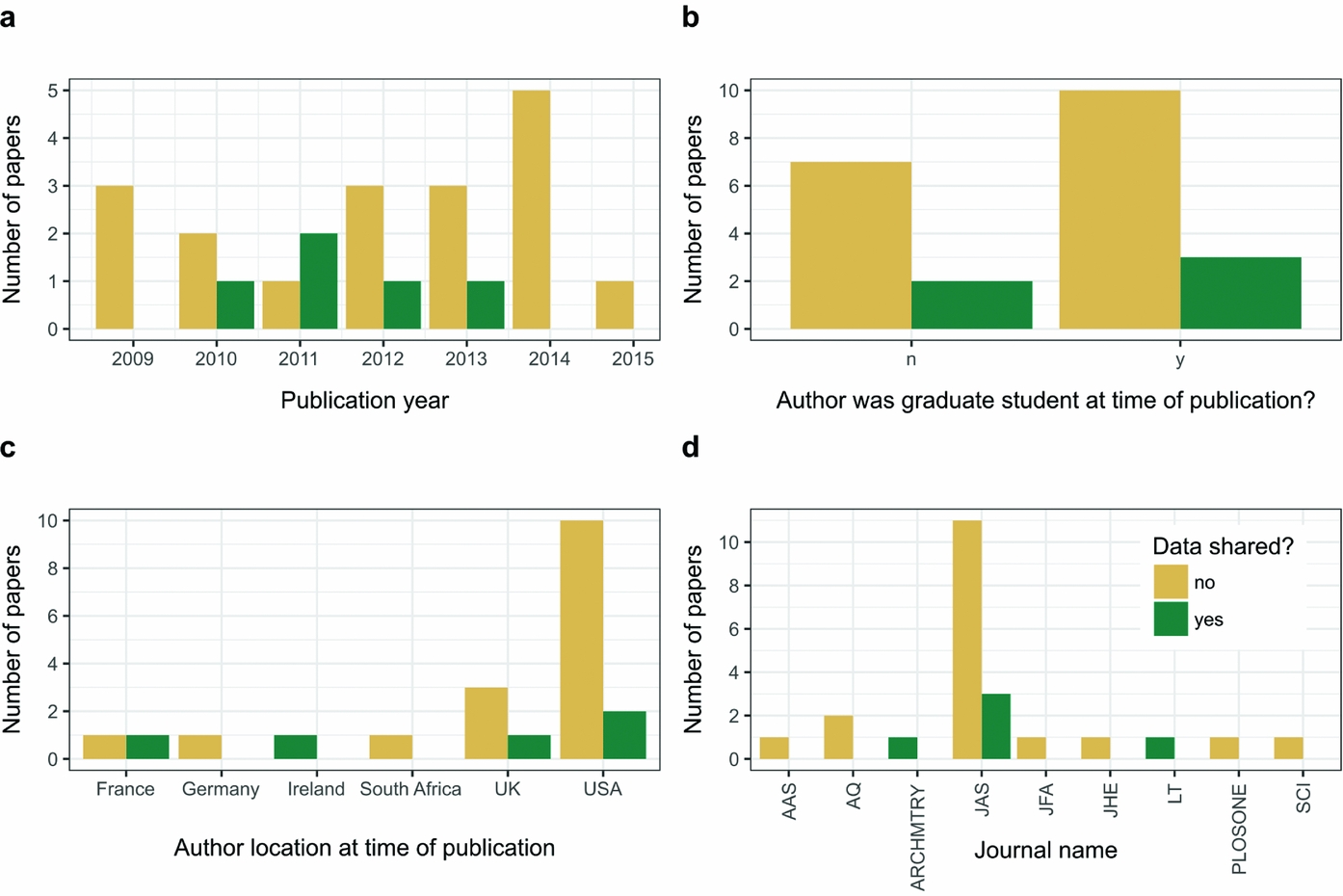
FIGURE 1. Summary of results of e-mail requests for data: (a) responses by year of journal article publication; (b) student status of first author; (c) country location of first author; (d) journal. AAS = Archaeological and Anthropological Sciences; AQ = American Antiquity; ARCHMTRY = Archaeometry; JAS = Journal of Archaeological Science; JFA = Journal of Field Archaeology; JHE = Journal of Human Evolution; LT = Lithic Technology; PLOSONE = PLOS ONE; SCI = Science.
Survey of Articles Published in the Journal of Archaeological Science
In addition to our e-mail survey, we also conducted a pilot study of a random sample of 48 articles published during February–May 2017 in the Journal of Archaeological Science to investigate data sharing behaviors. In this sample we found openly available raw data for 18 essays (53%), even though only seven articles (21%) include a data availability statement. For essays where data are available, nine (50%) have data contained in supplementary files published with the article, six (33%) have all the raw data in tables in the text of the essays, and three (17%) have data in an online repository. The most frequently shared type of data is compositional (e.g., element concentrations; n = 9, 28%), followed by radiocarbon and luminescence age data (where the dates are the primary object of analysis; n = 5, 16%) and DNA sequences (n = 4, 12%). Generally, compositional data are presented in tables in the text, dating data are presented in supplementary files, and DNA data are in repositories (as is typical for DNA data; Figure 2). Data shared in supplementary files and online repositories were most often in Microsoft Excel format (n = 38, 38% of the files in supplementary files and repositories), followed by CSV (aka comma-separated values, an open-source plain text spreadsheet format; n = 4, 31%), and tables embedded in Microsoft Word or PDF documents (n = 4, 31%). When a scripting language such as R, Python, MATLAB, or OxCal was used as the analysis software for an article (n = 7, 54% of the essays would identify the software), only two also provided the script with the article.
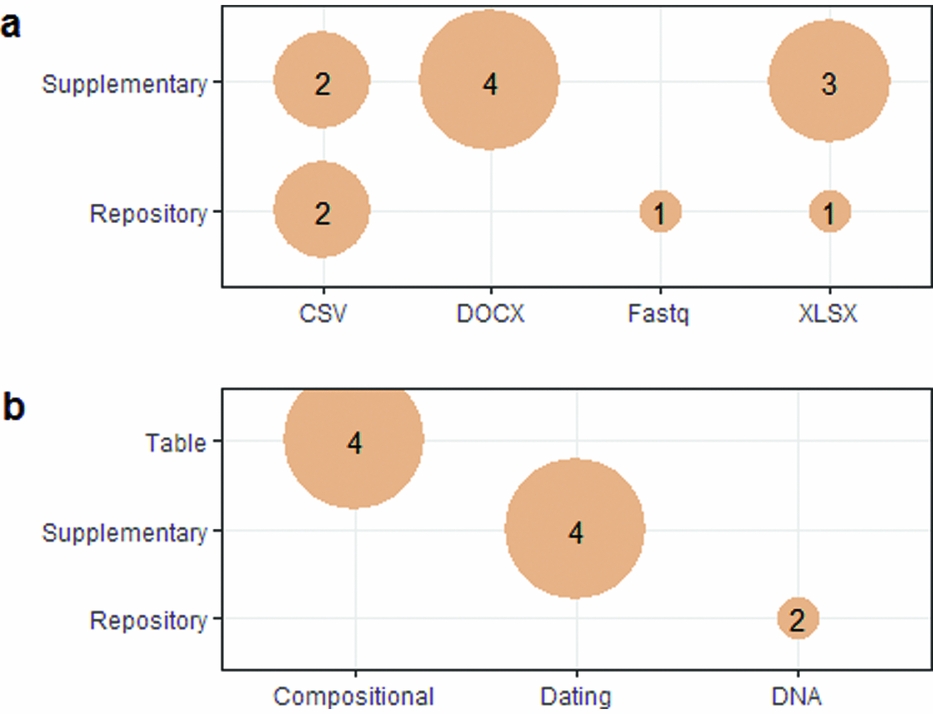
FIGURE 2. Summary of relationships among file types, data types, and data locations: (a) file types and data locations; (b) data types and data locations.
The Journal of Archaeological Science has had a “data disclosure” policy since at least 2013 that states that “all data relating to the article must be made available in Supplementary files or deposited in external repositories and linked to within the article” (2013). The data availability rate of 53% reported in our pilot study reflects either weak enforcement of this policy or an incomplete understanding among editors, reviewers, and authors of how to interpret and implement this policy. The prominence of compositional and dating data among the shared data types suggests a least effort strategy, with authors sharing data that do not require extensive cleaning and tidying (because the data are generated by instruments rather than entered by hand, such as artifact attribute data). The size of compositional and dating datasets means that they mostly fit easily into tables in the text or supplementary files and do not require much effort to organize (e.g., very few metadata are required for others to use these data). The small proportion of articles in our sample using or sharing a scripting language suggests that, unlike authors in other fields (Eglen et al. Reference Ellison2017), archaeologists do not appear to recognize code for data analysis as a primary research object to share with the research community. Code written by the researcher for even the simplest operations should be shared along with data because code communicates decisions made about the data analysis that can help others understand, analyze, and reuse the data.
Datasets in Repositories Tracked by DataCite
Our third investigation of archaeologists’ data sharing behaviors is an analysis of all records (n = 118,311, as of August 2017) of archaeological data files in online repositories tracked by DataCite. DataCite is the primary (but not the only) organization that provides persistent identifiers, or DOIs, for research data. Although DataCite is an international organization, our results are highly concentrated in just a few locations in Europe. The majority of records come from the Archaeology Data Service (ADS) in the United Kingdom, followed by the Dutch Data Archiving and Networked Services (DANS-EASY; Figure 3). Although the earliest data date to 1640, file deposition started and steadily increased during 1990–2008, as personal computers became more affordable and data became easier to digitize. There was a substantial increase in 2009, when the DANS-EASY repository saw an influx of records from Dutch cultural resource management firms (Figure 4a). This can be explained as a result of Dutch archaeology legislation, the Wet op de archeologische monumentenzorg, in 2007 that formally obligated archaeologists in the Netherlands to archive their data via DANS within two years of completion of their projects (Keers et al. Reference Keers, van derReijden and van Rossum2011). Another spike occurred in 2012, when tDAR: The Digital Archaeological Record had a large increase in deposits, likely due to it waiving its deposit fees for that year (Ellison Reference Ellison2012). After 2009 the volume of deposits declined in many repositories, with the exception of generic repositories such as Figshare, Zenodo, and ResearchGate, which continued to grow (Figure 4b).

FIGURE 3. Distributions of data centers, languages, and licenses (see text for details) among archaeology datasets known to DataCite. Horizontal axis is the number of digital object identifiers. DANS = Data Archiving and Networked Services; en = English; nl = Dutch; swe = Swedish; de = German; it = Italian.
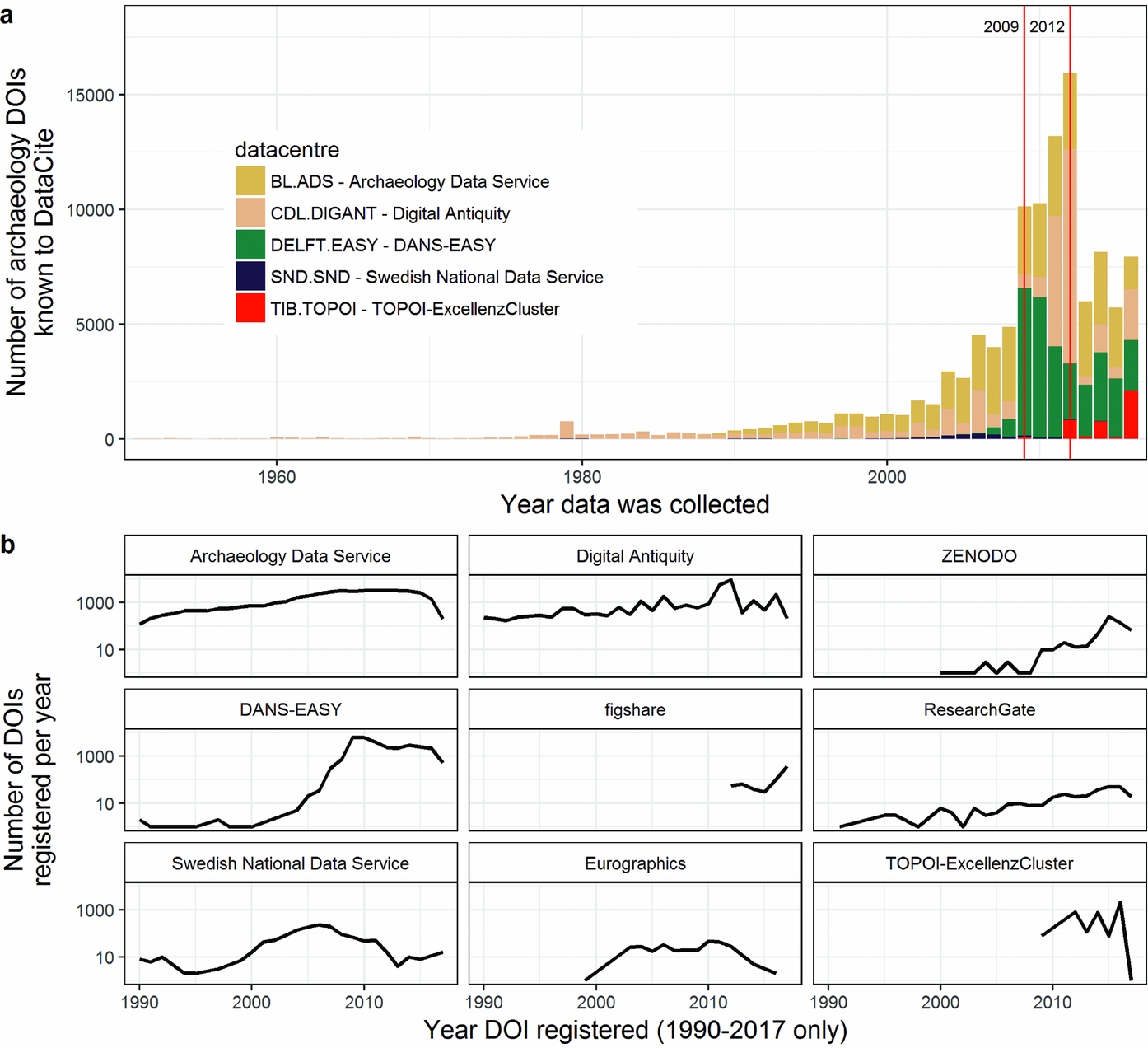
FIGURE 4. Change over time in archaeology datasets known to DataCite. (a) Counts of datasets per year by the major data centers; red lines indicate major increases in the number of datasets in repositories. Note that the date on the horizontal axis indicates when the data were collected, not when they were deposited in the data center. (b) Temporal trends in the number of digital object identifiers (DOIs) at individual data centers. DANS = Data Archiving and Networked Services.
Of the 75,632 records with copyright information, the majority are released under the ADS conditions of use (n = 43,661, 58%), which is broadly similar to the CC-BY-NC (Moore and Richards Reference Moore, Richards, Wilson and Edwards2015; Figure 5). The next most frequently used condition is the EU Open Access license (n = 22,198, 29%), similar to the CC-BY license. Creative Commons licenses such as CC-BY, CC-0, and others are used by less than 3% of records.
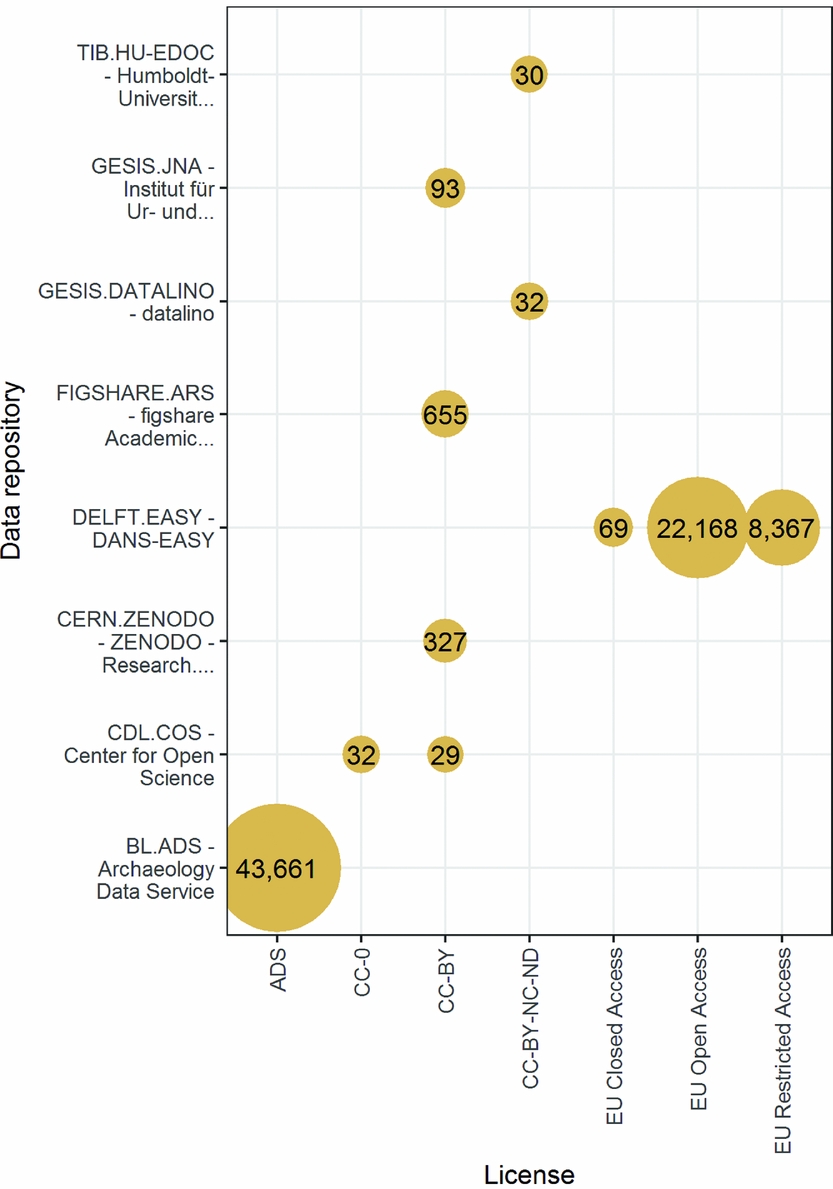
FIGURE 5. Summary of licenses used by data centers with archaeological data. ADS = Archaeology Data Service; DANS = Data Archiving and Networked Services.
Many of the records are gray literature such as unpublished reports (Figure 6), produced by commercial consultants or research projects. Of the 66,121 (56%) records that include information about the file types in the deposit, 86% (n = 56,935) contain only PDFs. Structured data files such as spreadsheets, databases, and shapefiles are found either alone or together with other file types (typically PDFs) in 7% (n = 4,481) of records. The highest proportion of records with structured data files is found in the DANS-EASY repository (n = 4,304, 14%), followed by the ADS with 0.4% (n = 174). Note that file format information is not present for all records in this sample, and some of the smaller repositories do not supply this information to DataCite at all, so it is possible that the true proportion of structured files in these records is higher than observed here.
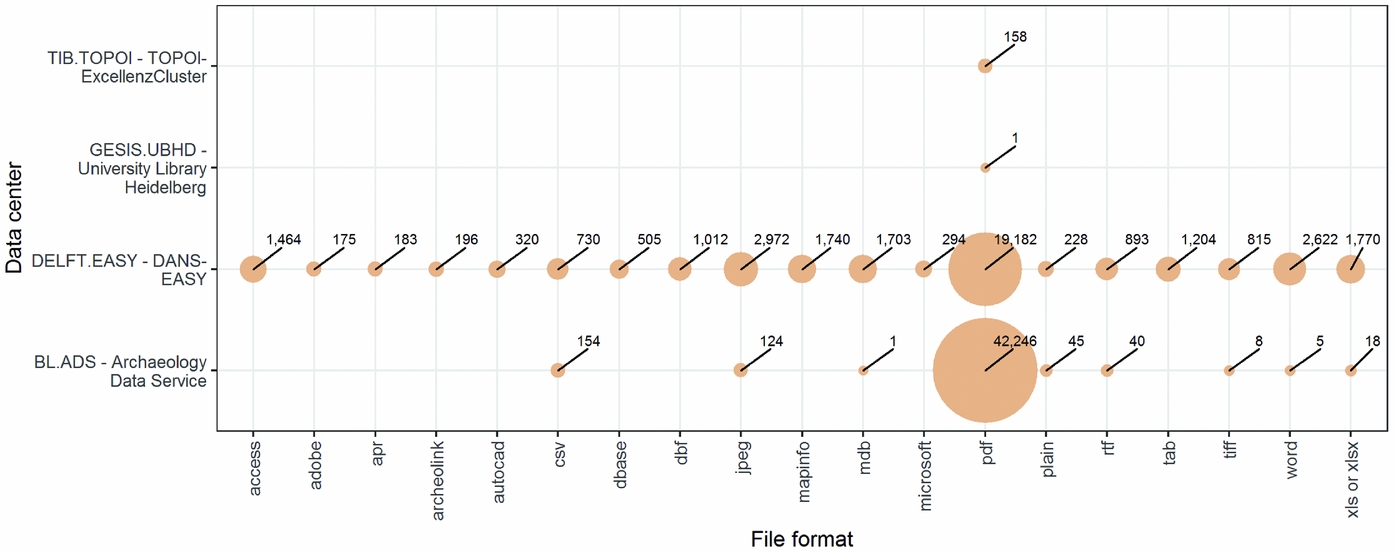
FIGURE 6. Relationships between data centers and file formats. The 10 most frequently found file formats are shown, in the data centers with these files from the top 10 data centers by number of digital object identifiers. Open file formats for structured data, such as CSV, are not common. DANS = Data Archiving and Networked Services.
From this pilot study of repository data we see that policy mandates in the United Kingdom and the Netherlands have been effective in populating repositories with archaeological data. With the 2012 spike in records deposited in tDAR we also see that archaeologists are sensitive to the price of sharing data. Nearly all records are made available under conditions that permit others to use the data while requiring that the original author of the data receive credit in reuse. In most cases this is because the repository hosting the data requires the author to choose one of these permissive licenses as a condition of making the deposit. However, although many items are able to be reused because of the licenses, the ease of reuse of these items is low. Only a small fraction of the items deposited are machine-readable structured data files. The majority of items are PDFs, which require extensive manual handling to extract tabular data for convenient reuse and combination with other datasets.
We can get some insights into the impact of repository data by querying the Crossref (2017) Event Data service, a freely accessible DOI citation dataset produced by periodic scanning of a variety of online sources. Crossref is an official DOI registration agency, focused on issuing DOIs for scholarly materials such as journal articles, books, e-books, and so on. Another source for data citation data is the Thomson Reuters Data Citation Index (Pavlech Reference Pavlech2016), but this resource is not free, and we did not have access to a subscription. Of the 118,311 DOIs in our sample, we found a total of 366 citations of 80 unique DOIs in the Crossref events data. The majority of these citations were found on Wikipedia (Figure 7), followed by other data repositories (i.e., cross-citations from one dataset to another in the same repository). The largest source of citations is the Zenodo repository, followed by articles in the journal Medieval Archaeology, which appear here because Volumes 1–50 are hosted by the ADS. According to the Crossref data, citation of archaeological data in repositories is a recent phenomenon, with the majority in our sample occurring over the last 12 months. We found only one example of a dataset DOI cited in a journal article (McCoy and Codlin Reference McCoy and Codlin2016). This may be an underestimate, given Huggett's (Reference Huggett2017) finding that 56 of 476 archaeology data sources in the Thomson Reuters Data Citation Index have citations in Web of Science databases. However, Huggett notes that the Thomson Reuters citation data are unreliable, for example, with incomplete citations and citations that predate the cited dataset. Huggett also shows an example of archaeologists citing datasets but omitting the DOI (e.g., Nugent and Williams Reference Nugent, Williams, Danielsson, Fahlander and Sjöstrand2012), so the citation is not captured by services such as Crossref or Thomson Reuters. These malformed citations add to the difficulty of accurately measuring data citation in archaeology (cf. Belter Reference Belter2014).
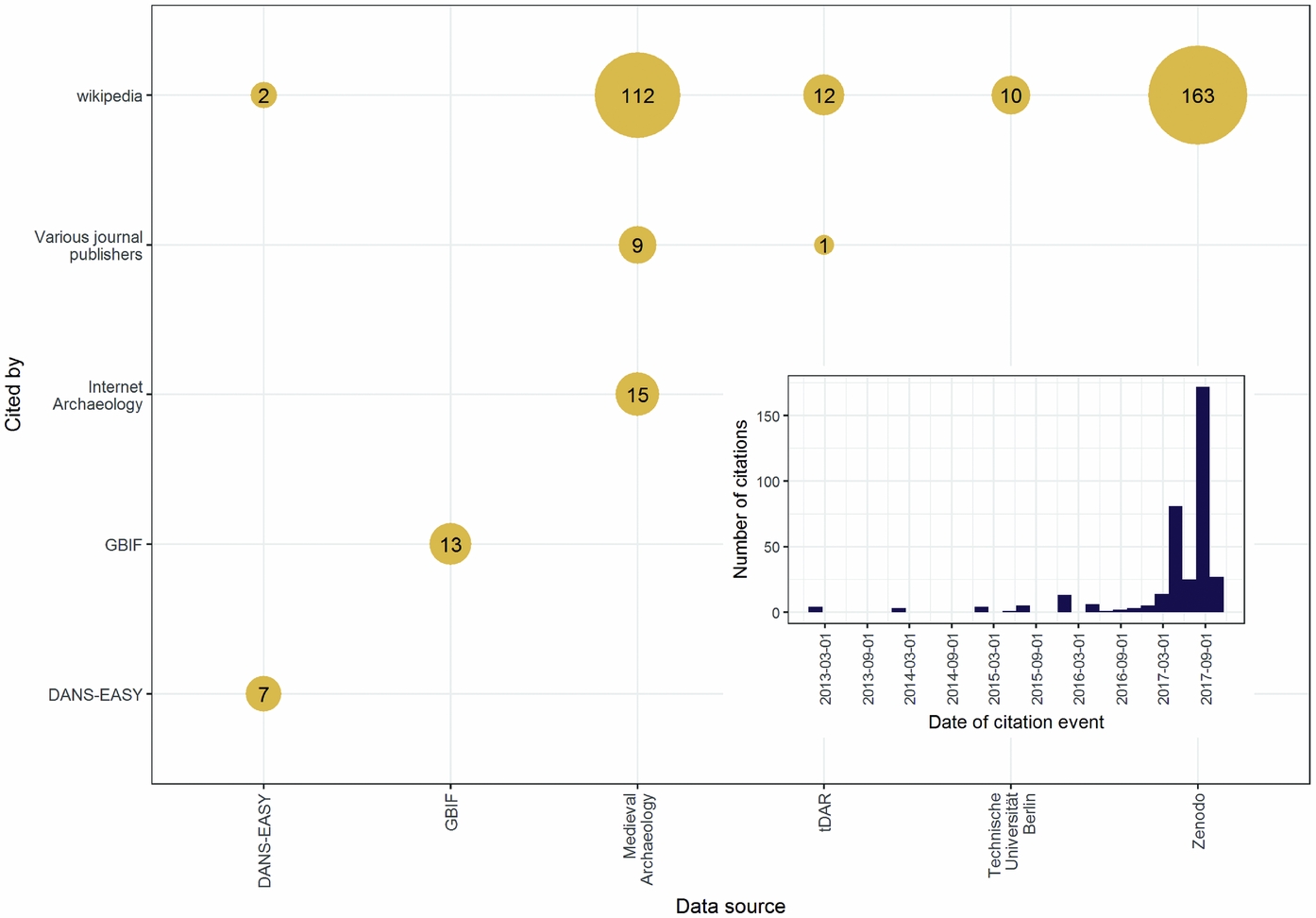
FIGURE 7. Citation of archaeological data digital object identifiers tracked by the Crossref Event Data service. Inset shows the distribution of these citations over time. DANS = Data Archiving and Networked Services, GBIF = Global Biodiversity Information Facility.
HOW TO SHARE ARCHAEOLOGICAL DATA?
In the pilot studies reported above we see three common approaches to sharing data: sending files privately by e-mail, following a personal request; including data as supplementary files submitted for publication with a journal article; and sharing data by depositing files in a trustworthy, public, DOI-issuing repository. The third method, via a public repository, is by far the most widely recommended method both specifically by archaeologists (Kansa and Kansa Reference Kansa and Kansa2013; Kansa et al. Reference Kansa, Kansa and Watrall2011; Kintigh Reference Kintigh2006) and in other sciences (see Cranston et al. Reference Cranston, Harmon, O'Leary and Lisle2014; Mounce Reference Mounce and Moore2014; Penev et al. Reference Penev, Mietchen, Chavan, Hagedorn, Smith, Shotton, Tuama, Senderov, Georgiev, Stoev, Groom, Remsen and Edmunds2017; Thessen and Patterson Reference Thessen and Patterson2011; Whitlock Reference Whitlock2011). Lists of trustworthy repositories are maintained by the editors of the journal Scientific Data (Nature: Scientific Data Editors 2017) and http://www.re3data.org, a global registry of research data repositories (Pampel et al. Reference Pampel, Vierkant, Scholze, Bertelmann, Kindling, Klump and Dierolf2013). University librarians are another resource for advice on choosing repositories and preparing data for sharing. There are many guidelines and conventions from other disciplines that are relevant to sharing archaeological data (Inter-university Consortium for Political and Social Research 2012; Strasser et al. Reference Strasser, Cook, Michener and Budden2012; Wilkinson et al. Reference Wilkinson, Dumontier, Aalbersberg, Appleton, Axton, Baak and Mons2016). Table 8 summarizes some of these, and recommendations specifically written for archaeologists can be found in Archaeology Data Service/Digital Antiquity (2011) and Archaeological Resources in Cultural Heritage: A European Standard (2014). Many of these guidelines may create new technical and practical challenges for archaeologists who are not accustomed to sharing data, and many archaeologists do not want to dedicate resources to sharing data. However, we should not let the perfect be the enemy of the good. In our own work we try to follow these guidelines with no dedicated resources for data sharing and with an incomplete knowledge of some of the technical details of repository operations. While we recognize that our data sharing practices fall short of all the guidelines, we still see value in sharing data imperfectly, rather than not at all.
TABLE 8. Nine Key Things to Do before Sharing Your Data.
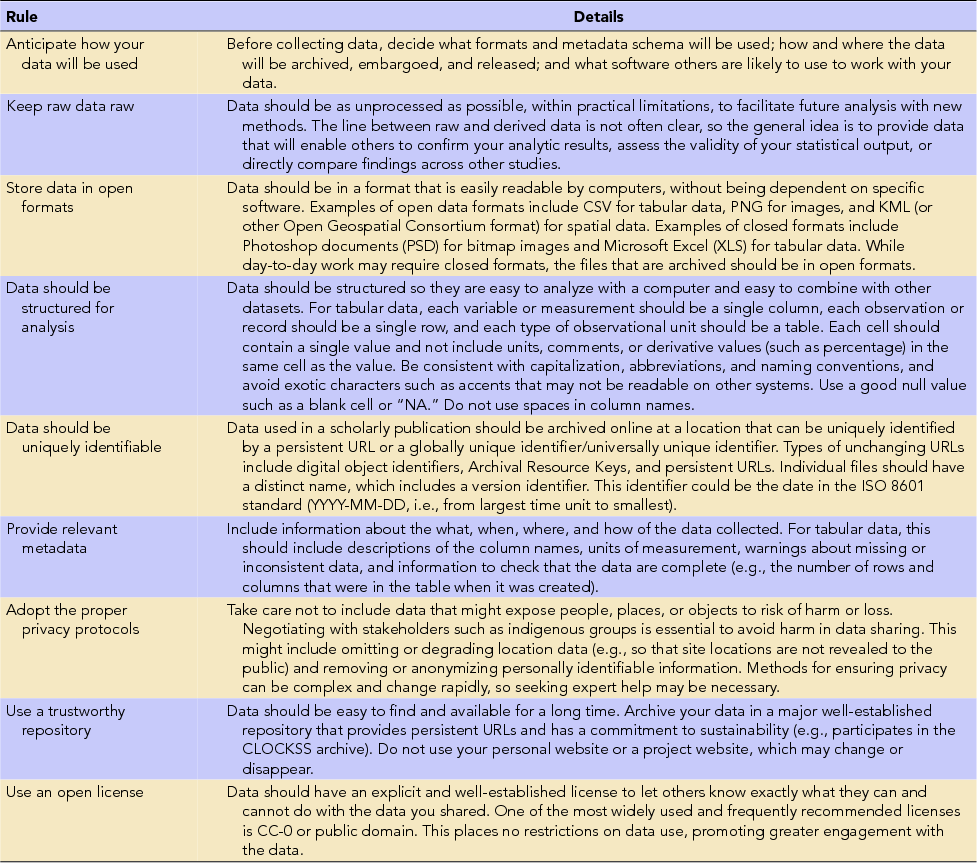
Source: Hart et al. Reference Hart, Barmby, LeBauer, Michonneau, Mount, Mulrooney and Hollister2016; White et al. Reference White, Baldridge, Brym, Locey, McGlinn and Supp2013.
Data sharing is a relatively new behavior for most archaeologists, so it is important to clarify what does not count as data sharing. Making data available on a website that is not a trustworthy, persistent-identifier-issuing repository is not data sharing. For example, data files hosted on a personal faculty web page or the Web server of a research project is problematic because these files could disappear at any time, the data can change in untracked ways, and published links to the files are broken when these websites are reorganized, making the files inaccessible. Sharing data via supplementary files attached to a journal article is problematic because they are inaccessible to nonsubscribers for paywalled journals, because publishers often alter the data file formats and file names during the production process, and because publishers own those data and the original authors may need to request permission to reuse their own data. For example, machine-readable formats such as CSV are sometimes presented as PDF or Microsoft Word files in supplementary files. The modification of supplementary file names during the article production process can break scripts that attempt to read files by referring to file names as they were prior to the publisher handling the files.
Finally, authors who write in their publications that “the data are available by request” are not sharing data. Not only are the data not actually available, but there is no way to enforce that the authors will actually honor any requests for their data. A simple strategy for avoiding these pseudo-sharing behaviors is to deposit data files in a trustworthy data repository and use persistent links to the files in reports and manuscripts. In our own work we have used figshare.com, zenodo.org, osf.io, neotomadb.org, opencontext.org, and our university repositories. However, there are many other options, and we recommend seeking advice from librarians and funding agencies to help with finding the most suitable service.
HOW TO CITE ARCHAEOLOGICAL DATA?
The Joint Declaration of Data Citation Principles is the current standard in many disciplines for data citation within any research object (Data Citation Synthesis Group Reference Martone2014). The result of these principles is a citation formation as follows (the exact order of the items may vary slightly across different referencing styles):
Creator (PublicationYear). Title. Version. Publisher. Identifier
The “PublicationYear,” “Title,” and “Publisher” are familiar from traditional citation formats, except that the publisher may not be a traditional book or journal publisher but, rather, a dedicated data repository organization. “Creator” is equivalent to the author or primary collector and arranger of the data (e.g., Open Context or tDAR). The “Version” and “Identifier” fields are unique to data citation and can take a variety of forms. The identifier is a special type of persistent internet address. The identifier must have two important qualities: the address contains some metadata (such as the identity of the publisher, but not necessarily in a human-readable format), and it remains fixed to a specific file or bundle of files over the lifetime of those objects, even if their location on the internet changes. There are several varieties of these in use, with DOIs currently the most common form. When a data publisher changes the internet address of a dataset, it is responsible for informing the DOI-issuing authority so that the DOI resolves to the new location of the files.
A DOI consists of three parts:
• the proxy, usually https://doi.org but sometimes also https://hdl.handle.net/ or just DOI
• the prefix, usually a string of numbers that is unique to the organization publishing the DOI. For example, the tDAR prefix is 10.6067
• the suffix, a random-looking string of any combination of characters and numbers that uniquely identify the file or bundle of files; this is also known as a local identifier (local ID) or an “accession,” an identifier that, by itself, is only guaranteed to be locally unique within the database or source (McMurry et al. Reference McMurry, Juty, Blomberg, Burdett, Conlin, Conte and Parkinson2017)
A DOI alone is not sufficient for citing a dataset, because, as with many things on the internet, the files can change over time. For example, we might upload data files to the repository when we submit a paper for peer review and then get a DOI and cite that in our manuscript so the peer reviewers can see them (some services provide a private URL that can be shared with reviewers but is not publicly accessible or discoverable by a search engine). Then when we resubmit our manuscript after peer review, we might update the repository to include additional data files relating to additional analyses requested by the reviewers. We still have the same DOI in our manuscript for this dataset, but the files have changed because of the revisions we did in response to the peer reviewers’ comments. Most data repositories will keep each version of the files that you upload, so in this scenario there will be at least two versions of the files in our data repository. Even if we do not follow this exact sequence of updating the files, we may still change them in the future, after our article has been published. Because of this potential to change the files stored at the DOI, it is necessary to identify specific file versions in our citation of the data. A simple method to record the version is to include the date that the data files were accessed, as when citing any other resource found on the internet. Some repositories also provide DOIs that have a version number suffix such as “.v2,” “.2,” “/2.” However, this is not formally a functionality of the DOI system, so including the date accessed is a more robust and general method of indicating the version. Technological solutions to issues of transience, permanence, and granularity in data citation are still in development.
When citing data in the text of a manuscript or report, the ideal practice is to cite the dataset and the traditional publication that first described it, like so (Penev et al. Reference Penev, Mietchen, Chavan, Hagedorn, Smith, Shotton, Tuama, Senderov, Georgiev, Stoev, Groom, Remsen and Edmunds2017): “This paper uses data from the [name] data repository at http://doi.org/xxx/xxx (Author YYYY), first described in Author YYYY.” For example: “This paper uses data from the Open Science Framework data repository at http://doi.org/10.17605/OSF.IO/32A87 (Marwick Reference Marwick2017), first described in Marwick et al. Reference Marwick, Hayes, Clarkson and Fullagar2017.” Citing both the dataset and the publication helps to resolve ambiguity about the source of the data and gives context to the data. Furthermore, the authorship of the data files may differ from that of the paper describing the data, and it is important that both authors (or sets of authors) receive credit for their work through the normal mechanisms of citation recognition. In cases where authors have published their data and then make an intellectual contribution to a separate study led by others that uses the published data, then the data author should also be a coauthor of the separate study. If other researchers use published data in their publication without any input from the data author, then citation of the data is all that is required, and adding the data author as a coauthor is not necessary.
In the paper in which these data are first described, the citation statement should be included in the body of the paper, in the “Material and Methods” section. In addition, the formal data reference should be included in the paper's reference list, using the recommended journal's reference format. For example, here is a statement that would appear in the paper in which the data are first presented: “The data underpinning the analysis reported in this paper were deposited in the Open Science Framework Repository at http://doi.org/10.17605/OSF.IO/32A87 (Marwick Reference Marwick2017).” The reference list of that paper would include Marwick Reference Marwick2017 as
Marwick, B. (Reference Marwick, Hayes, Clarkson and Fullagar2017). Dataset and R code for “Movement of lithics by trampling: An experiment in the Madjedbebe sediments,” http://doi.org/10.17605/OSF.IO/32A87, Open Science Framework, Accessed 7 Sept 2017.
SUMMARY AND CONCLUSION
The status of research data is slowly changing in many fields from a gift culture where data are privately held commodities traded for coauthorship, invitations, and other status tokens (Hagstrom Reference Hagstrom, Barnes and Edge1982; Wallis et al. Reference Wallis, Rolando and Borgman2013) to part of the public commons, accessible to anyone with an internet connection. This change has been fastest in data-rich “big science” fields, such as astronomy, physics, and oceanography, that use expensive instruments that generate data shared with large teams of collaborators to produce new discoveries (Reichman and Uhlir Reference Reichman and Uhlir2003). However, in “smaller” data-poor sciences such as archaeology, where collaborative groups are modest, data sharing is still mostly ad hoc and disaggregated. Our pilot studies, while small and limited in many ways, support this statement, with an overall sharing rate of 20% in responses to private requests for data and 53% of sampled journal articles with openly available data, in a wide variety of formats and locations. We found that legislation requiring data sharing resulted in a substantial increase in the rate of data deposition and that archaeologists are sensitive to repository fees. In examining archaeological data deposited in repositories, we found that most of the contents are PDF files of reports and only a very small fraction of the data files are structured data such as spreadsheets. Archaeologists still have a long way to go in making their data easier to reuse by sharing data in plain text structured data formats such as CSV. We found that citation of datasets, although problematic to measure, appears to be almost nonexistent in archaeological literature. Table 8 summarizes nine key tasks archaeologists should do with their data to optimize their discovery and reuse.
Among the many challenges of increasing the rate of data sharing in archaeology and other “small” sciences is that data sharing is unfunded, unrewarded, and only rarely required. Who is responsible for changing this? There is no simple answer, but we believe that the task must be shared between individuals and institutions, with individuals pushing for institutional change. The challenge of funding can be tackled by practical action from members of professional societies. For example, the Society for American Archaeology should communicate to funding bodies, such as the National Science Foundation, about the importance of allocating funds specifically for data sharing and providing reliable information on how to choose and use data repositories. The challenge of requiring data sharing can also be addressed by funding bodies and federal agencies, through more rigorous evaluation and enforcement of data management plans during the review process. However, changes in the policies of professional societies and other agencies are primarily responses to changes in norms in the community of researchers. In practice, individual researchers are responsible for communicating the value of data sharing to professional societies and funding agencies (e.g., by holding peers to high standards of data sharing during grant reviews). Changes in individual practice will demonstrate a change in norms and motivate our institutions to formalize these new data sharing values through policies and regulations.
One area where changes in individual practice may be especially effective is among journal editors and editorial boards. For example, editors of archaeology journals should adopt the Transparency and Openness Protocols of the Center for Open Science (Nosek et al. Reference Nosek, Alter, Banks, Borsboom, Bowman, Breckler and Yarkoni2015). Editors should then educate their editorial board members, peer reviewers, and contributors about their obligations regarding these protocols. Editors should only accept papers that, minimally, provide the raw data used to produce each table and visualization in the manuscript. Changes in journal-specific submission guidelines can result in substantial changes in authors’ research practices (Giofrè et al. Reference Giofrè, Cumming, Fresc, Boedker and Tressoldi2017; Macleod et al. Reference Macleod2017). For example, if archaeology journals adopt incentives such as badging (Kidwell et al. Reference Kidwell, Lazarević, Baranski, Hardwicke, Piechowski, Falkenberg and Nosek2016), and require as a condition of publication that submitted articles include in the text a properly formatted citation to the data analyzed in the article (or if the data cannot be shared, an explanation why the data are not available), authors would quickly adapt to this new requirement to ensure that their articles will be published.
Individual researchers can also contribute to changing the norms on data sharing via several practical actions suitable for typical day-to-day work:
• When preparing research for publication, we can upload data to a trustworthy repository and cite the data in the manuscript.
• When writing peer reviews of journal articles, we can tell editors that we require data to be available for papers that we read and that the manuscripts we review must include citations of datasets analyzed in them. We can write in our peer reviews that data need to be available for us to make a proper assessment of the manuscript.
• When reviewing grant applications, we can critically evaluate data management plans and report on the applicants’ past record on data sharing. We can offer helpful suggestions about how to improve data availability (e.g., Table 8).
• When teaching students, we can instruct them how to prepare data for sharing, and how to find and use publicly available datasets to give students experience analyzing and writing about shared data, and cultivate the expectation among students that data sharing is a normal part of archaeological research.
• When evaluating candidates for hiring and promotion, we can ensure that commitments to data sharing are valued.
The challenge of data sharing as an unrewarded behavior was the primary motivation for this article. By specifying a standard for the scholarly citation of archaeological data we provide a method for giving credit to the authors or compilers of data. This rewards those authors with visibility and recognition for their effort with citations, a currency that is valued broadly in the discipline. The data citation standard outlined above is easy for humans and search engines to understand and is highly functional, with a full internet address for the data contained in the citation. The standard can accommodate the addition of further information required by different citation styles and publishers’ requirements. The data citation standard is not dependent on any specific choices of software, archive, data producer, publisher, or author and is easy to adapt into existing writing and research workflows. There are still many unresolved challenges in data sharing, such as how to manage high volumes of data generated by photogrammetry. However, we are confident that solutions to many of these challenges will emerge as data sharing is increasingly valued by the research community.
Acknowledgments
This article emerged out of discussions at the 2017 Society for American Archaeology meeting, specifically the forum “Beyond Data Management: A Conversation about ‘Digital Data Realities,’” organized by Sarah Kansa and Eric Kansa, and the Society for American Archaeology Publications Committee. Thanks go to Canan Çakirlar for insights into the history of archaeological data sharing in the Netherlands and Stefano Costa for many helpful suggestions. BM was supported by an Australian Research Council Future Fellowship (FT140100101). Thanks go to Stefanie Crabtree and the other four peer reviewers for their constructive suggestions.
Data Availability Statement
This article uses data from the Open Science Framework repository at http://doi.org/10.17605/OSF.IO/KSRUZ. (Marwick and Pilaar Birch Reference Marwick and Birch2018), first described in this article. See the methods section of the text for more details. A capsule of text, data and code to reproduce this article is also available in Code Ocean, a computational reproducibility platform at https://doi.org/10.24433/CO.ca12b3f0-55a2-4eba-9687-168c8281e535.















