


No CrossRef data available.
Article contents
Maximizing the probability of visiting a set infinitely often for a Markov decision process with Borel state and action spaces
Part of:
Markov processes
Published online by Cambridge University Press: 22 August 2024
Abstract
We consider a Markov control model with Borel state space, metric compact action space, and transitions assumed to have a density function with respect to some probability measure satisfying some continuity conditions. We study the optimization problem of maximizing the probability of visiting some subset of the state space infinitely often, and we show that there exists an optimal stationary Markov policy for this problem. We endow the set of stationary Markov policies and the family of strategic probability measures with adequate topologies (namely, the narrow topology for Young measures and the 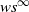 $ws^\infty$-topology, respectively) to obtain compactness and continuity properties, which allow us to obtain our main results.
$ws^\infty$-topology, respectively) to obtain compactness and continuity properties, which allow us to obtain our main results.
Keywords
MSC classification
- Type
- Original Article
- Information
- Copyright
- © The Author(s), 2024. Published by Cambridge University Press on behalf of Applied Probability Trust
References
Aliprantis, C. D. and Border, K. C. (2006). Infinite Dimensional Analysis, 3rd edn. Springer, Berlin.Google Scholar
Balder, E. J. (1988). Generalized equilibrium results for games with incomplete information. Math. Operat. Res. 13, 265–276.CrossRefGoogle Scholar
Balder, E. J. (1989). On compactness of the space of policies in stochastic dynamic programming. Stoch. Process. Appl. 32, 141–150.CrossRefGoogle Scholar
Balder, E. J. (1991). On Cournot–Nash equilibrium distributions for games with differential information and discontinuous payoffs. Econom. Theory 1, 339–354.CrossRefGoogle Scholar
Balder, E. J. (1992). Existence without explicit compactness in stochastic dynamic programming. Math. Operat. Res. 17, 572–580.CrossRefGoogle Scholar
Bäuerle, N. and Rieder, U. (2011). Markov Decision Processes with Applications to Finance. Springer, Heidelberg.CrossRefGoogle Scholar
Bäuerle, N. and Rieder, U. (2014). More risk-sensitive Markov decision processes. Math. Operat. Res. 39, 105–120.CrossRefGoogle Scholar
Bertsekas, D. P. and Tsitsiklis, J. N. (1996). Neuro-dynamic Programming. Athena Scientific, Belmont, MA.Google Scholar
Borkar, V. S. (2002). Convex analytic methods in Markov decision processes. In Handbook of Markov Decision Processes, Kluwer Academic Publishers, Boston, pp. 347–375.CrossRefGoogle Scholar
Brezis, H. (2011). Functional Analysis, Sobolev Spaces and Partial Differential Equations. Springer, New York.CrossRefGoogle Scholar
Cavazos-Cadena, R. (2018). Characterization of the optimal risk-sensitive average cost in denumerable Markov decision chains. Math. Operat. Res. 43, 1025–1050.CrossRefGoogle Scholar
Dufour, F., Horiguchi, M. and Piunovskiy, A. B. (2012). The expected total cost criterion for Markov decision processes under constraints: a convex analytic approach. Adv. Appl. Prob. 44, 774–793.CrossRefGoogle Scholar
Dufour, F. and Piunovskiy, A. B. (2013). The expected total cost criterion for Markov decision processes under constraints. Adv. Appl. Prob. 45, 837–859.CrossRefGoogle Scholar
Dufour, F. and Prieto-Rumeau, T. (2022). Maximizing the probability of visiting a set infinitely often for a countable state space Markov decision process. J. Math. Anal. Appl. 505, paper no. 125639.CrossRefGoogle Scholar
Dynkin, E. B. and Yushkevich, A. A. (1979). Controlled Markov Processes. Springer, Berlin.CrossRefGoogle Scholar
Feinberg, E. A. and Rothblum, U. G. (2012). Splitting randomized stationary policies in total-reward Markov decision processes. Math. Operat. Res. 37, 129–153.CrossRefGoogle Scholar
Hernández-Lerma, O. and Lasserre, J. B. (1996). Discrete-Time Markov Control Processes: Basic Optimality Criteria. Springer, New York.CrossRefGoogle Scholar
Hernández-Lerma, O. and Lasserre, J. B. (1999). Further Topics on Discrete-Time Markov Control Processes. Springer, New York.CrossRefGoogle Scholar
Hinderer, K. (1970). Foundations of Non-stationary Dynamic Programming with Discrete Time Parameter. Springer, Berlin.CrossRefGoogle Scholar
Howard, R. A. (1960). Dynamic Programming and Markov Processes. Technology Press of MIT.Google Scholar
Meyn, S. P. and Tweedie, R. L. (1993). Markov Chains and Stochastic Stability. Springer, London.CrossRefGoogle Scholar
Nowak, A. S. (1988). On the weak topology on a space of probability measures induced by policies. Bull. Polish Acad. Sci. Math. 36, 181–186.Google Scholar
Piunovskiy, A. B. (1998). Controlled random sequences: methods of convex analysis and problems with functional constraints. Uspekhi Mat. Nauk 53, 129–192.Google Scholar
Piunovskiy, A. B. (2004). Multicriteria impulsive control of jump Markov processes. Math. Meth. Operat. Res. 60, 125–144.CrossRefGoogle Scholar
Puterman, M. L. (1994). Markov Decision Processes: Discrete Stochastic Dynamic Programming. John Wiley, New York.CrossRefGoogle Scholar
Schäl, M. (1975). Conditions for optimality in dynamic programming and for the limit of n-stage optimal policies to be optimal. Z. Wahrscheinlichkeitsth. 32, 179–196.CrossRefGoogle Scholar
Schäl, M. (1975). On dynamic programming: compactness of the space of policies. Stoch. Process. Appl. 3, 345–364.CrossRefGoogle Scholar
Schäl, M. (1979). On dynamic programming and statistical decision theory. Ann. Statist. 7, 432–445.CrossRefGoogle Scholar
Schäl, M. (1983). Stationary policies in dynamic programming models under compactness assumptions. Math. Operat. Res. 8, 366–372.CrossRefGoogle Scholar
Schäl, M. (1990). On the chance to visit a goal set infinitely often. Optimization 21, 585–592.CrossRefGoogle Scholar
Sennott, L. I. (1999). Stochastic Dynamic Programming and the Control of Queueing Systems. John Wiley, New York.Google Scholar
Venel, X. and Ziliotto, B. (2016). Strong uniform value in gambling houses and partially observable Markov decision processes. SIAM J. Control Optimization 54, 1983–2008.CrossRefGoogle Scholar
Zhang, Y. (2017). Continuous-time Markov decision processes with exponential utility. SIAM J. Control Optimization 55, 2636–2660.CrossRefGoogle Scholar