


A substantial amount of work has focused on social sensitivity to accent differences by infants and young children (Kinzler, Corriveau, & Harris, Reference Kinzler, Corriveau and Harris2011; Kinzler & DeJesus, Reference Kinzler and DeJesus2013; Kinzler, Dupoux, & Spelke, Reference Kinzler, Dupoux and Spelke2007; Wagner, Clopper, & Pate, Reference Wagner, Clopper and Pate2014). This research suggests that accent sensitivity begins to emerge in infancy (Butler, Floccia, Goslin, & Panneton, Reference Butler, Floccia, Goslin and Panneton2011; Kinzler et al., Reference Kinzler, Dupoux and Spelke2007) with continued development of explicit social awareness for dialect and accent categories throughout the school-aged years (Floccia, Butler, Girard, & Goslin, Reference Floccia, Butler, Girard and Goslin2009; Jones, Yan, Wagner, & Clopper, Reference Jones, Yan, Wagner and Clopper2017; Wagner et al., Reference Wagner, Clopper and Pate2014). When cognitive demands are taken into account, accent sensitivity may take many years to fully mature and social preferences are shown to increase in the early school-age years (Creel, Reference Creel2017). A child's recognition of a speaker's accent or social preference for one's own accent does not, however, indicate whether a listener is able to understand the linguistic content of the speech.
The ability to successfully extract meaning from speakers whose productions differ from familiar phonological patterns, such as in unfamiliar non-native accents or regional dialects, requires substantial perceptual flexibility. Naturally produced non-native speech can present a challenge for successful communication because non-native talkers’ productions can deviate from native language norms along numerous phonological dimensions. Considering only the segmental domain, within a sentence or two it would not be uncommon to encounter phonemes that are ambiguous between two native categories, phonemes that fall unambiguously into the wrong category, variability among different substitutions, and added or deleted phonemes that can change the syllabic structure of a word (Carlisle, Reference Carlisle1991; Flege, Bohn, & Jang, Reference Flege, Bohn and Jang1997; Sumner, Reference Sumner2011). Overlaying these phonemic differences are deviations from native norms in the suprasegmental domain, with deviations in stress, intonation, and speaking rate (Sereno, Lammers, & Jongman, Reference Sereno, Lammers and Jongman2016). Yet, amidst this substantial variability, adult listeners generally understand non-native speakers accurately, at least in quiet listening conditions (Rogers, Dalby, & Nishi, Reference Rogers, Dalby and Nishi2004). Considering that phonological constancy (i.e., mapping variable pronunciations of a word to the same mental lexicon entry) is essential for word recognition and that non-native speech may present a substantial challenge to this ability, it is important to determine when children's understanding of speakers that deviate from native norms emerges and reaches maturity.
Many of the fundamental skills that likely underlie the understanding of and adaptation to speakers with unfamiliar accents appear to be in place relatively early in development. For example, children as young as six years of age demonstrate lexically guided retuning of phoneme boundaries (McQueen, Tyler, & Cutler, Reference McQueen, Tyler and Cutler2012) and toddlers can learn phoneme remappings within artificially created accents (White & Aslin, Reference White and Aslin2011). In fact, there have been claims that young children (two to three years of age) can understand accented speech quite well (Mulak, Best, Tyler, Kitamura, & Irwin, Reference Mulak, Best, Tyler, Kitamura and Irwin2013; van Heugten & Johnson, Reference van Heugten and Johnson2016), while other work has found that children continue to have difficulty understanding speakers with unfamiliar dialects and accents into the early school-age years (Bent, Reference Bent2014; Bent & Atagi, Reference Bent and Atagi2015, Reference Bent and Atagi2017; Nathan, Wells, & Donlan, Reference Nathan, Wells and Donlan1998; O'Connor & Gibbon, Reference O'Connor and Gibbon2011), suggesting that mapping unfamiliar pronunciations to known words may show a protracted developmental trajectory.
Support for the hypothesis that there is protracted perceptual learning for unfamiliar accents comes from work demonstrating that children's general auditory and speech perception abilities are still developing into adolescence. General auditory abilities, including auditory perceptual learning, continue to develop during adolescence (Huyck & Wright, Reference Huyck and Wright2011). In other areas of linguistic and sociolinguistic development, there is evidence that children's perception and production abilities demonstrate quite protracted trajectories. In understanding speech in challenging environmental listening conditions (noise or reverberation), children do not reach maturity until late adolescence (Johnson, Reference Johnson2000). There is also evidence that some aspects of speech perception are developing into adolescence, including the consistency of phoneme categorization (Hazan & Barrett, Reference Hazan and Barrett2000). Similarly, some aspects of children's sociolinguistic competence (i.e., regional dialect classification) are not adult-like until sixteen to seventeen years of age (Jones et al., Reference Jones, Yan, Wagner and Clopper2017). Thus, although core linguistic abilities may develop early in life (e.g., the first five years), there are substantial changes in auditory and phonetic development that occur during the second decade of life. Although previous research has emphasized the early availability of some mechanisms that may support the understanding of unfamiliar accents, there is reason to believe that the very complex skill of perceiving naturally produced non-native speech may take many years to fully develop. The conflicting findings regarding claims of early emergence of understanding for accented speakers and findings of continued difficulty may be rooted in the differing cognitive demands for the tasks used with younger children (e.g., headturn preference procedure, preferential looking paradigms, or visual fixation procedures) compared to those used with older children and adults (e.g., open-set word or sentence identification). When testing more closely approximates the perceptual and cognitive requirements of conversation, children appear to still be developing their perceptual abilities, suggesting a protracted perceptual learning account, similar to that proposed for accent sensitivity (Creel, Reference Creel2017). Here, the developmental trajectory for accented speech comprehension is mapped. Greater understanding of how word identification skills develop will provide essential data for expanding models of speech perception that characterize adult abilities to understand speech under conditions with high variability (Kleinschmidt & Jaeger, Reference Kleinschmidt and Jaeger2015; Pierrehumbert, Reference Pierrehumbert2016).
Method
Participants
Seventy-four monolingual American English-speaking children between the ages of 8;0 and 15;10 participated (40 female) including 24 eight- to nine-year-old children, 24 eleven- to twelve-year-old children, and 26 fourteen- to fifteen-year-old children. These age ranges were selected to allow comparison to data from five- to six-year-old children and eighteen- to twenty-four-year-old adults from Bent and Atagi (Reference Bent and Atagi2015). Children were tested between September 2014 and July 2017 in Bloomington, IN, in a laboratory on the Indiana University campus within the Department of Speech and Hearing Sciences. Bloomington is in the southern region of Indiana and has a population of approximately 83,000, with residents who are primarily White (82%) with Asian as the next largest racial group (9%). The children were selected from a database of families interested in participating in research studies that is shared by several laboratories in the department. Families are recruited for the database from community events throughout the year (e.g., the farmer's market, a Children's Expo). From this database, the selection criteria were that the children fit the age range, were monolingual, and did not have any reported speech, language, or hearing impairments. Two parents did not report their children's ethnicity or race. Of the remaining children, one was Hispanic or Latino. There were two multi-racial children, two Asian children, and one Black child. The remaining children were White. All children had age-appropriate hearing, language, and articulation as measured by a pure-tone hearing screening of 25 dB at 250 Hz and 20 dB at octave intervals between 500 and 8000 Hz, a standard score of 85 or higher on the Peabody Picture Vocabulary Test–fourth edition (average standard score = 115; range = 90–141) (Dunn & Dunn, Reference Dunn and Dunn2007), and a standard score of 85 or higher on the Goldman–Fristoe Test of Articulation–second edition (average standard score = 103; range = 97–107) (Goldman & Fristoe, Reference Goldman and Fristoe2000), respectively. Three additional children were tested, but one child's data could not be included due to a software error, and two children failed the hearing screening.
Prior to participation, a parent of the child completed a language background and experiences questionnaire as well as an informed consent form. All children also completed an assent form. Children's exposure to various accents was rated by the parents on a scale from 1 to 5, where 1 = no exposure and 5 = frequent daily exposure. Children's average exposure score for Japanese-accented English, the non-native accent employed in the study, was 1.2 (range = 1–4). All children were highly familiar with the native talker's dialect (i.e., central midland), as they were currently living in Indiana. Furthermore, most children had lived primarily or exclusively in Indiana (n = 67).
Stimuli
The stimuli included 80 sentences from the Hearing in Noise Test for Children (HINT-C) (Nilsson, Soli, & Gelnett, Reference Nilsson, Soli and Gelnett1996). These syntactically simple, meaningful sentences are appropriate for use with young children and contain three to four keywords each (e.g., “The lady packed her bag.” or “The little boy left home.”). The sentences were produced by two adult male talkers: a monolingual speaker of American English from the midland dialect region and a non-native speaker of English with a first language of Japanese. The Japanese-accented sentences deviated from native norms along multiple dimensions. For example, the native English speaker produced the sentence “the two children were laughing” as [ðətʰuʧɪldɹεnwɚlæfɪŋ]. In contrast, the native Japanese speaker produced the sentence as [zətʰuʧɪldεnwɚ̞ɹʌfɪŋkʰ], demonstrating both consonant and vowel substitutions (/z/ for /ð/, /ɹ/ for /l/, and /ʌ/ for /æ/), a distortion (lowering of /ɚ/), a deletion (lack of /ɹ/ in children), and an addition (/k/ at the end of laughing). The sentences were equalized in amplitude using Praat. See Bent and Atagi (Reference Bent and Atagi2015) for additional information regarding the talkers.
Procedure
Participants were tested in a single one-hour session. After completing the consent and assent process, the children were administered the standardized hearing, articulation, and vocabulary assessments. After these tests, they completed the experimental sentence recognition test, which was custom designed in Python and controlled by a Mac Mini. The children were tested individually in a sound-attenuated booth. The stimuli were presented over a loudspeaker (Yamaha MSP7 Studio Powered Monitor) in four blocks of 20 sentences each. These blocks included four listening conditions: (1) native speaker in quiet; (2) native speaker in noise; (3) non-native speaker in quiet; and (4) non-native speaker in noise. For the noise conditions, the sentences were embedded in a speech-shaped noise with a signal-to-noise ratio of 0 dB that was one second longer than the sentence. The order of the conditions and sentences assigned to the conditions were counterbalanced across participants. Within a block, sentences were randomized for each participant. After the presentation of each sentence, children repeated back what they heard and an experimenter typed in their response. As the stimuli were played over a loudspeaker, the experimenter could also hear the stimulus as well as the child's response. The children's responses were audio-recorded so that accuracy re-checking could be conducted, if needed. However, previous work with children between the ages of five and eight years using very similar stimuli and methods showed that discrepancies between initial and second transcriptions occurred on only 1% of keywords (Bent & Atagi, Reference Bent and Atagi2017). Because the children in this study were of similar age or older (with most of them older), accuracy re-checking was not deemed necessary for this study. Before the beginning of the experimental trials, listeners were presented with four practice trials, with one from each listening condition. Children were not provided feedback regarding the accuracy of their responses but were encouraged to provide their best guess.
Results
Children's responses were scored for keyword identification accuracy resulting in a word identification accuracy score for each condition (Figures 1 and 2). These scores were converted to rationalized arcsine units (RAU) (Studebaker, Reference Studebaker1985) to facilitate meaningful comparisons across the entire range of the scale and then entered into an ANOVA with listener age as the between-subject factor (five- to six-year-olds, eight- to nine-year-olds, eleven- to twelve-year-olds, fourteen- to fifteen-year-olds, adults) as well as talker accent (native, non-native) and listening environment (noise, quiet) as the within-subject factors. All three main effects were significant in the expected directions. Word identification was more accurate with increasing listener age (F(4,144) = 81.15, p < .001, η p2 = .693), for the native talker compared to the non-native talker (F(1,144) = 3333.45, p < .001, η p2 = .959), and in quiet compared to noise (F(1,144) = 1928.83, p < .001, η p2 = .931). Further, all two-way interactions were significant. General trends for the two-way interactions are described first, with more specific information about differences between age groups described below, following the finding of a significant three-way interaction. The younger listeners showed greater intelligibility decrements for non-native talker relative to the native talker compared to older listeners (F(4,144) = 24.22, p < .001, η p2 = .402). Younger listeners were also more affected by noise than older listeners (F(4,144) = 5.23, p = .001, η p2 = .127). Last, there was a greater negative impact of noise on the non-native talker compared to the native talker (F(1,144) = 142.02, p <.001, η p2 = .497). The three-way interaction was also significant (F(4,142) = 3.56, p =.008, η p2 = .090).

Figure 1. Average word identification accuracy for the five listener groups for the native in quiet (dashed and dotted line with open squares), native in noise (dashed line with open circles), non-native in quiet (dotted line with filled squares), and non-native in noise (solid line with filled circles). Error bars indicate standard deviations.
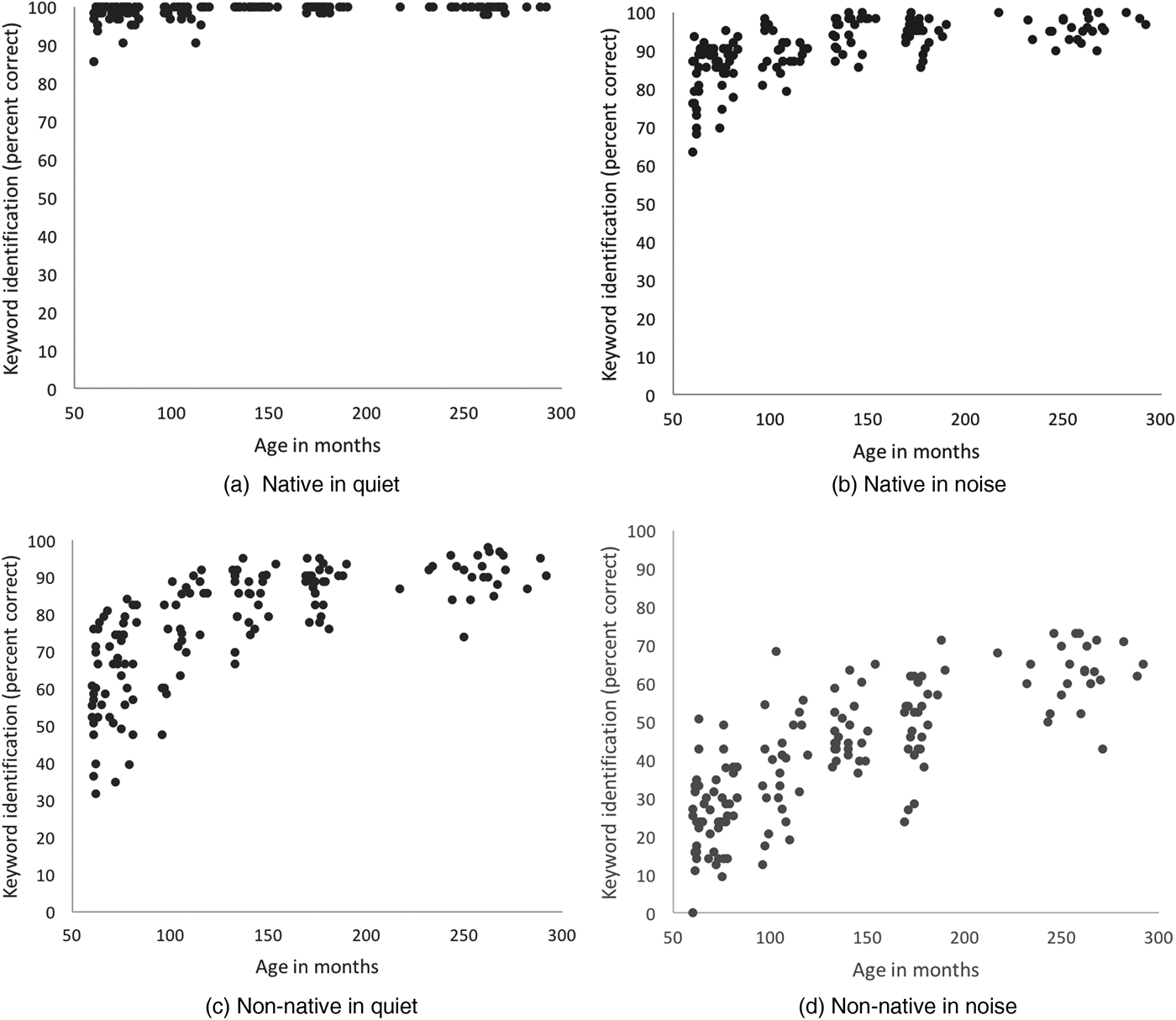
Figure 2. Word identification accuracy in percent correct for individual listeners from five to twenty-four years of age for the four listening conditions: (a) native talker in quiet, (b) native talker in noise, (c) non-native talker in quiet, and (d) non-native talker in noise.
To follow up on the three-way interaction and determine when the children reached adult-like performance in each of the conditions, independent samples t-tests were conducted. Performance for each age group in each condition was compared to adult performance (see Table 1 for a summary). Based on the number of t-tests, p-values less than or equal to .003 were considered significant. For the native in quiet, the five- and -six-year-old children's accuracy was significantly lower than the adults (t(60.97) = 3.87, p < .001), but the other three age groups did not significantly differ from adults. For the native in noise, the five- to six-year-old and the eight- to nine-year-old children were less accurate than the adults (both ps < .001), but the eleven- to twelve- and fourteen- to fifteen-year-old age groups’ performances did not significantly differ from the adults. For the non-native in quiet, all age groups except the fourteen- and fifteen-year-old children were significantly less accurate than the adults (all ps < .001). Finally, for the non-native in noise, all of the child groups showed significantly less accurate word recognition performance compared to the adults (all ps < .001). Thus, the results showed that the age at which children reach mature performance differed across conditions, with children's performance reaching asymptotic behavior in the easiest condition (native in quiet) by eight to nine years of age, whereas performance was still significantly less accurate for the most difficult condition (non-native in noise) even for the fourteen- to fifteen-year-old children.
Table 1. Comparison of Word Identification Accuracy between Adults and Children from Four Age Groups.

Notes. *indicate conditions in which children's performance was less accurate than adults'.
The data in each of the four conditions was also analyzed with correlations to determine the strength of the relationship between age as a continuous variable and word recognition scores (Figure 2). All four correlations between age and words recognition (in RAU) were significant (native in quiet: r = .376, n = 149, p < .001; native in noise: r = .626, n = 149, p < .001; non-native in quiet: r = .717, n = 149, p < .001; and non-native in noise: r = .759, n = 149, p < .001). These correlations demonstrate only a moderate correlation in the native in quiet condition, likely due to highly accurate performance by nearly all listeners, but large effect sizes in the other three listening conditions.
In addition to analyzing the relationship between word recognition accuracy and age, partial correlations were conducted to determine if there were relationships between the listeners’ vocabulary scores (PPVT raw scores) and their speech perception abilities (with RAU scores) in the four conditions, controlling for age. This analysis was only conducted with data from adults and the children who were eight years of age and older because the PPVT was not administered to the five- and six-year-old children in the previous study. All correlations were significant (native in quiet: r(95) = .406, p < .001; native in noise: r(95) = .213, p = .036; non-native in quiet: r(95) = .394, p < .001; and non-native in noise: r(95) = .320, p = .001). This analysis suggests that above the influence of age, vocabulary size may provide listeners with a word recognition advantage.
Discussion
The results presented here suggest that, similar to the proposed protracted development for metalinguistic knowledge about accents (Creel, Reference Creel2017; Jones et al., Reference Jones, Yan, Wagner and Clopper2017; Kinzler & DeJesus, Reference Kinzler and DeJesus2013), children's abilities to extract the linguistic content from non-native-accented speech demonstrates a long learning trajectory. Word recognition performance in the three adverse listening conditions (native in noise and non-native in quiet or noise) showed very strong positive correlations with listener age. Further, although performance for the native talker reached adult-like levels by eight to nine years in quiet and by eleven to twelve years in noise, performance for the non-native in quiet did not reach adult-like performance until adolescence (fourteen to fifteen years), and the adolescents did not display equivalent performance to the adult group for the most challenging listening condition (non-native in noise), suggesting continued development after fifteen years of age. These results contrast with claims in the literature that children in the preschool age years are able to understand talkers with unfamiliar accents and dialects (Best, Tyler, Gooding, Orlando, & Quann, Reference Best, Tyler, Gooding, Orlando and Quann2009; Mulak et al., Reference Mulak, Best, Tyler, Kitamura and Irwin2013; van Heugten & Johnson, Reference van Heugten and Johnson2016). Although the ability to maintain perceptual constancy under a range of variability conditions – including differences across specific talkers, talker gender, and speaker affect – clearly begins to emerge within the first two years of life (Cristia, Seidl, Vaughn, Schmale, Bradlow, & Floccia, Reference Cristia, Seidl, Vaughn, Schmale, Bradlow and Floccia2012), the ability to comprehend words by talkers whose production patterns deviate from the child's home dialect appears to take well over a decade to reach maturity. Listening conditions that more closely mimic real-world listening (i.e., not perfectly quiet lab conditions) show that these abilities are not adult-like until late adolescence. The mechanisms supporting word recognition for unfamiliar accents may be different than those related to the ability to categorize a talker as non-native versus native or from a different dialect region than the home region. That is, entrenched learning of the home accent (Creel, Reference Creel2017) has been proposed as being required for determining that accents deviate from one's own, suggesting that greater amounts of exposure to the home dialect will strengthen metalinguistic abilities with non-native and regional dialects. In contrast, the understanding of speech that deviates from the home dialect may require not only substantial experience with the home dialect, but also exposure to variations outside of the home dialect.
One possible explanation for the performance gap between the fourteen- and fifteen-year-olds and adults may be that the adults were primarily university students. The exposure to a much larger range of speakers, both native and non-native, at university may increase a listener's ability to understand non-native-accented speech even with an accent that is not specifically familiar. None of the adults in this study were highly familiar with Japanese-accented English, but likely had exposure to other non-native speakers (i.e., ~14% of the students on the Bloomington campus of Indiana University where the testing was conducted are international), as well as speakers from many regions of the United States. Results from both laboratory training studies and experiments incorporating metrics of naturalistic exposure to accent variation find that increased experience with non-native-accented speech results in more accurate accented word recognition in adults (Baese-Berk, Bradlow, & Wright, Reference Baese-Berk, Bradlow and Wright2013; Porretta, Tucker, & Jarvikivi, Reference Porretta, Tucker and Jarvikivi2016). In recent work, Buckler, Oczak-Arsic, Siddiqui, and Johnson (Reference Buckler, Oczak-Arsic, Siddiqui and Johnson2017) and van Heugten and Johnson (Reference van Heugten and Johnson2017) demonstrate that infants who receive regular input from more than one accent show later development for word forms in a familiar accent than infants who only receive input in one accent, as measured by recognition or speed. These results support the idea that children exposed to input that is more variable develop qualitatively different word-form representations. They further suggest that although there are initial costs to word recognition, infants with greater exposure to accent variability may have an advantage in later development. Indeed, in Potter and Saffran (Reference Potter and Saffran2017) when eighteen-month-olds were given exposure to multiple accents in the lab, they were able to recognize words produced in an unfamiliar accent, but fifteen-month-olds did not show the same benefit.
Future studies should continue to examine how varying amounts of exposure to linguistic variability impact accented word comprehension. To determine what types of experience are leading to the increase in performance for the adults compared to the adolescents, different groups of adults could be tested. For example, adults who have just entered college could be compared to those with several years of experience in college. Alternatively, adults with college experience or other experiences leading to contact with a variety of accents and dialect (e.g., military) could be compared to those who did not pursue education or a profession that would provide a linguistically diverse environment. Another approach could be to test adolescents with greater or lesser amounts of naturalistic exposure to regional- and non-native-accent variation through the testing of children attending schools with linguistically homogenous student bodies compared with those attending linguistically and culturally diverse schools (e.g., International Baccalaureate schools). Likewise, the variation seen within the age groups (Figure 2) may be, at least partially, due to differing amounts of exposure to various non-native accents and regional dialects across children.
Exposure to linguistic variation is likely not the only factor propelling development. Many of the linguistic and cognitive skills that have been found to be related to perception of or adaptation to unfamiliar speech varieties, such as inhibition, working memory, and vocabulary knowledge (e.g., Banks, Gowen, Munro, & Adank, Reference Banks, Gowen, Munro and Adank2015) show large changes between five years of age and adulthood (Coch, Sanders, & Neville, Reference Coch, Sanders and Neville2005; Gathercole, Reference Gathercole1999; Segbers & Schroeder, Reference Segbers and Schroeder2017). Here, the impact of vocabulary size was assessed for a subset of the participants (ages eight and above). This analysis demonstrated that, even when controlling for age, listeners with larger vocabulary sizes (as measured by the PPVT) had better performance in all four listening conditions. The results from this study cannot determine how increases in lexicon size enhance speech perception abilities, but one possibility is that listeners with larger vocabularies have more exposure to language overall. Those with greater language exposure may have lower activation thresholds for words, even when they are degraded through the presence of noise or an unfamiliar accent. Other linguistic abilities that develop during the school-age years, including increases in sociolinguistic competence (e.g., dialect identification), may support accurate word recognition. In adults, metalinguistic awareness for linguistic variations has been shown to be linked to the ability to understand non-native-accented speech (Atagi & Bent, Reference Atagi and Bent2015). Thus, future work should consider including multiple linguistic, cognitive, perceptual, and experiential measures for children across a wide age range to begin to determine the factors that are central for propelling comprehension of talkers with unfamiliar accents.
The current study was limited by including only one non-native talker. Children's understanding of talkers with non-native accents that deviate less from native norms would likely reach adult-like levels at an earlier age. Future work should include a greater number of talkers, who represent a variety of non-native accents or regional dialects. To shed light on how accent strength impacts the developmental trajectory for word recognition, measures of acoustic-phonetic distance from the home dialect should be calculated for the stimuli. The continued development of robust, objective metrics that can quantify distances between linguistic varieties is an important part of this work (Cristia et al., Reference Cristia, Seidl, Vaughn, Schmale, Bradlow and Floccia2012). Testing children from a wide age range on stimuli that vary in accent strength within the same experimental paradigm may also help to reconcile differing claims about the developmental trajectory of word identification with unfamiliar accents. Furthermore, designs that manipulate the specific differences in phonological characteristics of the varieties compared to the home dialect (i.e., deviations in vowel vs. consonants; distortions vs. substitutions) may also elucidate how skills, such as lexically guided retuning or the resolution of phoneme substitutions, are brought to bear on word recognition tasks across development.
Conclusion
This study demonstrates that children's understanding of speakers whose accents differ from the home dialect may continue to develop throughout adolescence. Although both children's linguistic abilities with unfamiliar accents (e.g., word recognition, lexically guided retuning) and metalinguistic abilities (e.g., dialect identification) begin to emerge early in development, adult-like performance levels for word recognition with unfamiliar accents may not emerge until well into adolescence. This result suggests that exposure to many talkers or a range of dialect and accent variations may be required to support accurate word recognition under very challenging listening conditions stemming from both the talker (i.e., a non-native speaker) and the environment (i.e., noise). If continued accretion of experience with linguistic variability improves word recognition, it also remains possible that continued improvement would be observed beyond young adulthood.
Acknowledgements
This research would not have been possible without the technical support of Charles Brandt and data collection assistance from Eriko Atagi, Emma Bonifield, Taylor Burris, Emily Byers, KuanYi Chao, Haley Craig, Nancy Eastman, Steven Elmlinger, Kimberly Fishman, Emma Folk, Valentyna Filimonova, Julianne Frye, Katie Gray, Amanda Helms, Megan Loughnane, Megan McKee, David Phillips, Kristin Quinones, Rachel Shepherd, Layne Shidlofsky, Alexandra Simeur, Katherine Taelman, and Zachary Smith.



