



1. Introduction
With the popularity of the Internet and information technology, the network information data show an explosive growth and information overload becomes prominent. As users are inundated with a large and growing pool of content, products, and services (collectively referred to as items), recommender systems have become essential tools for selecting the information they need (Ricci, Rokach, and Shapira Reference Ricci, Rokach and Shapira2021). These recommender systems are a static process that tend to learn users’ interests from their past behaviors, thereby recommending suitable items (Chen et al. Reference Chen, Lin, Zhang, Ding, Cen, Yang and Tang2019). However, the user’s current interest may have changed, and it is difficult to provide feedback on dissatisfaction with current recommended content or new requirements in the current interaction. The dialog system is more concerned about the user’s current interests (Christakopoulou, Radlinski, and Hofmann Reference Christakopoulou, Radlinski and Hofmann2016). In the process of user decision-making, both historical information and current information are significant, so the dialog recommender system emerges as the times require.
Conversational recommender system aims to recommend high-quality items to users through interactive dialog, which realizes the linkage between traditional information retrieval and recommendation (Jannach et al. Reference Jannach, Manzoor, Cai and Chen2021). Specifically, the system has multiple rounds of real-time interaction based on natural language with the user, combining the user’s historical interests with their preferences captured in the current conversation to recommend products. Knowledge graph contains item attributes and various types of relationships, providing powerful background knowledge that can provide rich semantic information to recommendation algorithms. Therefore, dialog recommendation systems based on knowledge graphs have tremendous potential (Li et al. Reference Li, Ebrahimi Kahou, Schulz, Michalski, Charlin and Pal2018).
While existing research has made significant strides in improving the performance of conversational recommender systems, certain challenges remain. In particular, existing systems often overlook the importance of time-series feature information in capturing user interests and recommending relevant items, where time-series features refer to the change rule or trend of user preferences over time. Additionally, systems often fail to consider the content of the dialog when making recommendations, leading to the loss of overall semantic meaning. For example, different mentions of the same item may have positive or negative connotations, leading to varying recommendations. The items are mentioned in different order, the suggestions may also be different, so we should take information about the content of the conversation into account in the recommendation. As shown in Table 1, both examples mentioned that the user likes Bruce Willis, but due to the time sequence mentioned is inconsistent, the final system recommendation results are also different. At the same time, we also pay attention to the connection between words (such as movies and actors) and introduce knowledge graph (Wang et al. Reference Wang, Zhang, Zhao, Li, Xie and Guo2019) and copy mechanism (He et al. Reference He, Liu, Liu and Zhao2017a) to enrich dialog information.
Table 1. Two examples of dialog recommender systems for movies

The use of deep learning methods to study natural language processing has sprung up in recent years. We use deep learning methods to propose a deep timing network(DTN) to model the serialized dialog data, capture global information and current interests, and use the copy mechanism to map some proper nouns into the generated sequence, so as to give appropriate recommendations. We demonstrate through a series of experiments that the proposed model achieves certain improvements in both recommender and conversation tasks.
The main contributions of this paper are as follows:
-
• We focus on the phenomenon of user interest transition in dialog recommender systems and propose a new network structure to optimize user interest recommendation and improve accuracy.
-
• We propose to add a retrieval model and use the copy mechanism to retain retrieved information in the output, enhancing the generation model’s effectiveness and alleviating the problem of new words.
-
• We propose DTN, which uses BiGRU attention to serialize dialog content, accurately learns the feature relationship between users and items, and adds position encoding to absorb position information, reinforcing the importance of time-series features in the dialog context and reducing the occurrence of repeated words and increasing diversity in the generated responses.
2. Related work
The conversation recommender system aims to facilitate task-oriented multi-turn dialogs with users, consisting of two modules: recommendation and dialog (Lei et al. Reference Lei, He, Miao, Wu, Hong, Kan and Chua2020). In this section, we provide a detailed introduction to these two components, as well as discuss related work in the field of dialog recommender systems.
2.1 Recommender system
The recommendation system mainly utilizes user’s behavioral information on items to mine personalized needs and actively provides them with information that satisfies their needs through the their interest model (Christakopoulou et al. Reference Christakopoulou, Beutel, Li, Jain and Chi2018). Traditional personalized recommendation algorithms are mainly divided into content-based recommendation algorithms and collaborative filtering recommendation algorithms. Content-based filtering (Javed et al. Reference Javed, Shaukat, Hameed, Iqbal, Alam and Luo2021) requires analyzing the description of file resources and each user’s interests, thus establishing a user preference model and providing recommendation services to users through their interest preference model. The core idea of recommender system based on collaborative filtering (Polatidis and Georgiadis Reference Polatidis and Georgiadis2016) is to integrate the explicit feedback information of users and items, and filter out the items that may be of interest to target users for recommendation.
With the development of deep learning technology, He et al. (Reference He, Liao, Zhang, Nie, Hu and Chua2017b) proposed a neural collaborative filtering model, integrating matrix decomposition processing with deep learning. Liu et al. (Reference Liu, Lu, Yang, Zhao, Xu, Peng, Zhang, Niu, Zhu, Bao and Yan2020) used CNN to extract image information, learn the impact of product images on user behavior, and improve the accuracy of click probability prediction. Feng et al. (Reference Feng, Lv, Shen, Wang, Sun, Zhu and Yang2019) applied RNN to capture dynamic and constantly changing user interests from user behavior sequences. Zhang et al. (Reference Zhang, Qian, Cui, Liu, Li, Zhou, Ma and Chen2021) adopted the attention mechanism to alleviate the uninterpretability of the recommendation model and improve the sense of user experience. However, it is important to note that the number of users and items in commercial recommendation systems is often very large, and users can only access a very limited number of items, resulting in very sparse behavioral information about items. To address this problem, we introduce knowledge graph (Bizer et al. Reference Bizer, Lehmann, Kobilarov, Auer, Becker, Cyganiak and Hellmann2009) as auxiliary information to improve the performance of the recommendation system, which contains item attributes and relationships of various types, allowing us to obtain multi-dimensional, richer information about items and their relationships.
2.2 Conversational system
The field of dialog systems has received increasing attention in various domains and can be broadly classified into two types: task-oriented and non-task-oriented dialog systems (Chen et al. Reference Chen, Liu, Yin and Tang2017). Task-oriented systems are designed to help users complete practical and specific tasks and can be divided into retrieval-based and generation-based methods. Retrieval-based methods involve searching a pre-defined index and learning to select a response from the current dialog (Cai et al. Reference Cai, Wang, Bi, Tu, Liu and Shi2019). Lowe et al. (Reference Lowe, Pow, Serban and Pineau2015) concatenated the dialog history with the question and encoded them separately with RNNs before calculating the match between the two encoded vectors to rank candidate responses. Kadlec, Schmid, and Kleindienst (Reference Kadlec, Schmid and Kleindienst2015) applied CNN and bidirectional LSTMs to the candidate response selection task and investigated the impact of semantic representation on reply selection. Yang et al. (Reference Yang, Qiu, Qu, Guo, Zhang, Croft, Huang and Chen2018) guided the selection of responses by retrieving the responses corresponding to the most similar questions of the user as auxiliary information. One potential advantage of retrieval-based methods is that they return utterances previously uttered by humans, which means that they are typically grammatically correct and inherently meaningful in terms of semantics. In addition, retrieval-based methods do not require the potentially expensive training of complex language models. On the other hand, retrieval-based methods may lack creativity and may suffer from the problem of not being able to respond appropriately to previously unseen situations.
Unlike retrieval-based dialog systems, generative methods can produce a completely new response (Singla et al. Reference Singla, Chen, Atkins and Narayanan2020) which is relatively more flexible. Vinyals and Le (Reference Vinyals and Le2015) first used the Seq2Seq model in the dialog generation task, constructing the model by using two RNNs, one for encoding the user’s message and the other for decoding the generated response. Shang, Lu, and Li (Reference Shang, Lu and Li2015) adopted a general encoder-decoder framework that generates a response based on a potential representation of the input text as the decoding process, while using RNN for both encoding and decoding. Various extensions based on the Seq2Seq architecture have been developed to improve the quality of response generation. To overcome the limitations of data scale, Naous, Hokayem, and Hajj (Reference Naous, Hokayem and Hajj2020) proposed an empathy-driven Arabic chatbot with a special encoder-decoder composed of a LSTM Sequence2Sequence. Boussakssou, Ezzikouri, and Erritali (Reference Boussakssou, Ezzikouri and Erritali2022) presented an Arabic chatbot focused on the Seq2Seq framework, using Aravec to transform a sentence into a vector of actual numbers representing the sentence’s input. Woungang et al. (Reference Woungang, Dhurandher, Pattanaik, Verma and Verma2023) established a generative model neural conversation system using a deep LSTM Seq2Seq model with attention mechanism. However, generative methods also have disadvantages, such as the tendency to produce grammatical errors or meaningless responses, so we propose combining both retrieval and generative methods.
2.3 Conversational recommender system
Dialog technology provides new solutions and methods for solving the problems existing in traditional recommendation systems, namely the conversational recommender system. Through rich interactive behavior, dialog recommendation breaks down the barriers of information asymmetry between the system and the user in static recommendation systems, allowing the recommender system to dynamically capture user preferences in interactive dialogs. The dialog recommendation system can also be called a task-oriented dialog system, in which the system can elicit detailed current preferences from the user, provide explanations for topic recommendations, or handle user feedback on proposed suggestions to achieve dynamic updates and learning.
Recently, some research has begun to reintegrate dialog and recommendation systems to recommend the appropriate items through dialog. Quadrana et al. (Reference Quadrana, Karatzoglou, Hidasi and Cremonesi2017) proposed a hierarchical RNN model structure to explore relationships within and between dialogs, achieving more reliable next-item recommendations. Wang et al. (Reference Wang, Wang, Wang, Sheng and Orgun2020) introduced GNNs to model complex transitions within and between dialogs, building better-performing dialog recommender systems. Yuan et al. (Reference Yuan, Karatzoglou, Arapakis, Jose and He2019) proposed the NextInet model based on generative models to design a probability distribution for candidate items. In particular, Li et al. (Reference Li, Ebrahimi Kahou, Schulz, Michalski, Charlin and Pal2018) collected a dialog dataset focused on providing movie recommendations, and Chen et al. (Reference Chen, Lin, Zhang, Ding, Cen, Yang and Tang2019) proposed the KBRD model for end-to-end training of both recommendation and dialog systems, making it possible to suggest recommendations based on entities mentioned in the dialog. Zhou et al. (Reference Zhou, Zhao, Bian, Zhou, Wen and Yu2020) proposed KGSF, which used knowledge graphs and semantic fusion to integrate dialog and recommendation modules. Ma, Takanobu, and Huang (Reference Ma, Takanobu and Huang2021) proposed a model called CR-walk that performs tree-based reasoning on knowledge graphs and generates dialog actions to guide language generation.
Although these studies have improved the performance of dialog recommender systems, some limitations still exist, such as the failure to fully consider the order of entities mentioned in dialogs, and the current dialog recommender systems relying solely on generation methods, which require further improvement in terms of accuracy. Therefore, inspired by existing research on dialog recommender systems, we propose utilizing knowledge graphs to introduce external knowledge, using time-series feature methods to fully leverage contextual information, and incorporating retrieval methods (Manzoor and Jannach Reference Manzoor and Jannach2022) to assist in generating methods to jointly construct a dialog module. This will enable us to achieve a more reliable recommendation dialog text generation model and provide the most reasonable recommendations.
3. Task definition and approach
In this section, we start from the task definition and describe our approach in detail. The overall model framework is shown in Fig. 1, which is divided into three modules a, b, and c, corresponding to semantic fusion module, dialog module, and recommender module, respectively. In part a, the semantic representation is enhanced by encoding an external knowledge graph. Part b includes retrieval and generation components. In part c, the enhanced semantic representation is passed through DTN to obtain more accurate user preferences.
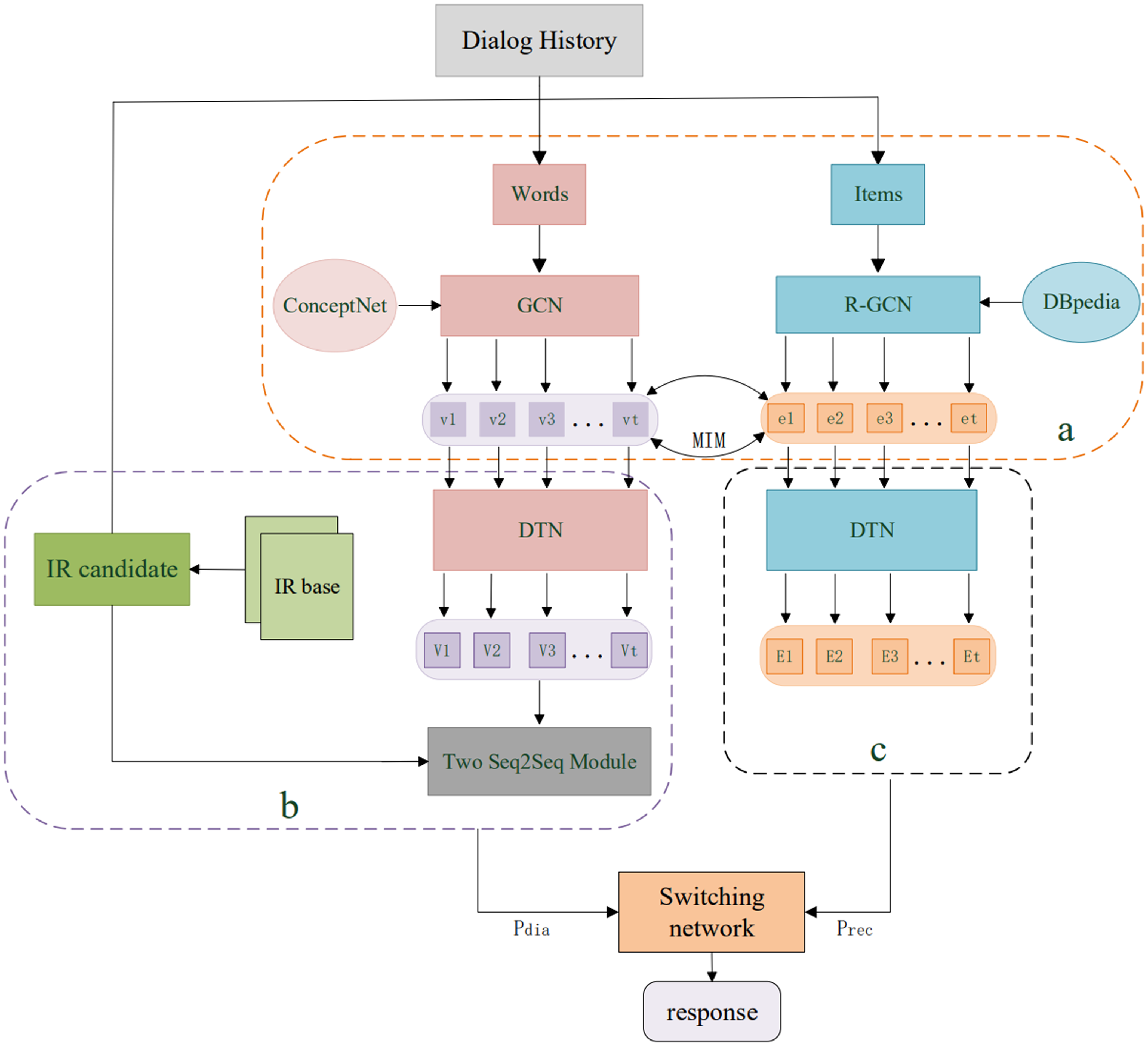
Figure 1. Overall framework of the model.
3.1 Task definition
The conversational recommender system, as the name implies, has to solve both dialog and recommendation problems. The overall architecture of a dialog recommender system can be thought of as consisting of a recommendation module and a dialog module. The goal of the entire system is to provide the most accurate recommendation results in the shortest possible number of dialogs.
Let
 $u \in U$
denote a user
$u \in U$
denote a user
 $u$
in user set
$u$
in user set
 $U$
,
$U$
,
 $i \in I$
denote an item
$i \in I$
denote an item
 $i$
in item set
$i$
in item set
 $I$
, and
$I$
, and
 $v \in V$
denote a word
$v \in V$
denote a word
 $v$
in vocabulary
$v$
in vocabulary
 $V$
. A dialog
$V$
. A dialog
 $C$
is an ordered list
$C$
is an ordered list
 $C=\left \{S_{t}\right \}_{t=1}^{n}$
composed of a series of sentences, and
$C=\left \{S_{t}\right \}_{t=1}^{n}$
composed of a series of sentences, and
 $S_{t}$
is the sentence at the
$S_{t}$
is the sentence at the
 $t$
-th round of dialog interaction. In the
$t$
-th round of dialog interaction. In the
 $t$
-th round of the dialog, the recommendation module will select a candidate item subset
$t$
-th round of the dialog, the recommendation module will select a candidate item subset
 $I_{t}$
from the item set I according to a certain strategy, and the dialog module needs to generate the reply text
$I_{t}$
from the item set I according to a certain strategy, and the dialog module needs to generate the reply text
 $S_{t}$
of the current round. It is worth noting that the candidate item subset
$S_{t}$
of the current round. It is worth noting that the candidate item subset
 $I_{t}$
may be empty, in which case the dialog module generates relevant texts for queries, or just chat texts. Given the
$I_{t}$
may be empty, in which case the dialog module generates relevant texts for queries, or just chat texts. Given the
 $n$
sentences that the above system interacts with the user, the goal of the generative dialog recommender system is to generate corresponding responses. That is, the recommendation result
$n$
sentences that the above system interacts with the user, the goal of the generative dialog recommender system is to generate corresponding responses. That is, the recommendation result
 $I_{n+1}$
and the reply text
$I_{n+1}$
and the reply text
 $S_{n+1}$
together constitute the reply at this moment.
$S_{n+1}$
together constitute the reply at this moment.
3.2 Semantic fusion module
The semantic fusion module is constructed based on knowledge graph(KG) and graph convolutional neural network(GCN). To comprehensively understand user interests, two independent knowledge graphs are used in dialog and recommender systems to enhance the representation of basic semantic units. ConceptNet (Speer, Chin, and Havasi Reference Speer, Chin and Havasi2017) is a common sense knowledge base that represents the most basic knowledge that humans understand. It is composed of relational knowledge in the form of triples and focuses on the relationship between words, which is used as a word-oriented KG. Conversation-related words are filtered from the entire KG to form a small KG, which provides relationships between words, such as synonyms, antonyms, and co-occurring words for each word. GCN (Chiang et al. Reference Chiang, Liu, Si, Li, Bengio and Hsieh2019) is then employed to learn embedding representations for word nodes. In the data of the graph structure, both the characteristics of each node and structural information should be fully considered. GCN can automatically learn the feature information and structural information of the graph, and each node contains its own characteristics and structural information. On each update of node representation, GCN receives information from one-hop neighbors in the graph and performs the following aggregation operations:
 \begin{equation} V^{(l)}=\operatorname{ReLU}\left (\mathrm{D}^{-\frac{1}{2}} \mathrm{AD}^{-\frac{1}{2}} \mathrm{ V}^{(1-1)} W^{l}\right ) \end{equation}
\begin{equation} V^{(l)}=\operatorname{ReLU}\left (\mathrm{D}^{-\frac{1}{2}} \mathrm{AD}^{-\frac{1}{2}} \mathrm{ V}^{(1-1)} W^{l}\right ) \end{equation}
where
 $V^{(l)} \in \mathrm{R}^{\mathrm{V} \times \mathrm{d}^{\mathrm{w}}}$
is the representation of nodes,
$V^{(l)} \in \mathrm{R}^{\mathrm{V} \times \mathrm{d}^{\mathrm{w}}}$
is the representation of nodes,
 $W^{l}$
is the learnable matrix of each layer,
$W^{l}$
is the learnable matrix of each layer,
 $A$
is the adjacency matrix corresponding to the graph, and
$A$
is the adjacency matrix corresponding to the graph, and
 $D$
is a diagonal matrix. By stacking multiple convolutions, information can be propagated together along the graph structure. When the algorithm terminates, each word corresponds to a
$D$
is a diagonal matrix. By stacking multiple convolutions, information can be propagated together along the graph structure. When the algorithm terminates, each word corresponds to a
 $\mathrm{d}_{\mathrm{W}}$
-dimensional representation
$\mathrm{d}_{\mathrm{W}}$
-dimensional representation
 $\mathrm{n}_{\mathrm{W}}$
. Thus, this paper learns the embedding representation of word nodes through GCN.
$\mathrm{n}_{\mathrm{W}}$
. Thus, this paper learns the embedding representation of word nodes through GCN.
On the other hand, we adopt DBpedia (Bizer et al. Reference Bizer, Lehmann, Kobilarov, Auer, Becker, Cyganiak and Hellmann2009) as an item-oriented knowledge graph that provides structured facts about item attributes and the relationships between them. Items related to the dialog content are filtered out from the entire KG to form a small KG, and R-GCN (Gao et al. Reference Gao, Wang, Pi, Zhang, Yang, Huang and Sun2020) is used to extract item representations on subgraphs that more fully consider edge types and orientations. R-GCN is a simple attempt of GCN in multi-relational graph scenarios. From homogeneous graphs to heterogeneous graphs, R-GCN solves the core problem of interacting with multiple relations. Under each relationship, the inward-pointing and outward-pointing points are regarded as neighbor points, and self-circulating features are added at the same time to perform feature fusion and participate in updating the central node. They are beneficial for handling multi-relational data features in knowledge bases, so R-GCN is used to extract item representations on subgraphs. After obtaining the node representations of word and item, in order to effectively align the semantic space of the two KGs, we use mutual information maximization (Yeh and Chen Reference Yeh and Chen2019) to mutually enhance the data representation of paired signals and make the representations of words and items appearing in a dialog more similar, thereby retaining the most important features.
3.3 Dialog retrieval module
Retrieval-based methods are commonly used to select the desired response from a candidate response pool using a dialog corpus and user questions. In this paper, we construct a retrieval module and create a new retrieval database that includes the dialog history in the training set, the ID and content of each sentence, and the movie ID mentioned in each sentence and the dialog history. To avoid problems with repeated lists, maybe this sentence refers to a movie, and the next sentence also refers to it, we use Elasticsearch (Divya and Goyal Reference Divya and Goyal2013), an open-source search engine based on the Lucene library, which processes data in JSON format. User data as shown in Fig. 2 below:

Figure 2. Data form diagram.
Our retrieval module retrieves a set of candidate responses from the dialog history repository using an entity-context matching method. We use Elasticsearch to index all conversation histories that contain the entity mentioned in the current conversation in the training data, which improves search efficiency by finding the target document’s approximate position directly in memory. We then calculate the similarity between the searched question and the input question to obtain the most similar questions’ replies as candidate responses. In summary, our retrieval module feeds the dialog content in the training set into a third-party retrieval interface, extracting informative words from the retrieved responses to generate the most useful response.
3.4 Dialog generation module
To leverage the temporal nature of dialog content, we propose the deep timing network (DTN). As depicted in Fig. 3, the word and item vectors are fed into the position encoding module, followed by feature extraction through BiGRU to obtain the feature vectors of the word and item. Then, the attention mechanism assigns corresponding probability weights to different feature vectors, and the keyword and key item information are obtained through softmax calculation. The representation after fusion of the knowledge graph is then passed through the DTN, which endows the dialog data with location information and time-series features. The attention mechanism is used to capture global information and current interests to infer user preferences. Moreover, we suggest introducing relevant information retrieved by our retrieval module to provide appropriate recommendations for the generation module.

Figure 3. Deep Timing Network(DTN).
3.4.1 Positional encoding
The content of a dialog is a time-series data, and the order and position of words in a sentence hold significant importance. These factors are not only integral to the grammatical structure of a sentence but also crucial for expressing its semantics. In fact, the same set of words in different positions within the same sentence can convey vastly different meanings. For example, in the following two sentences, the constituent words of the sentences are exactly the same, but the meanings are quite different:
I don’t like the story of this movie, but I like the actors.
I like the story of this movie, but I don’t like the actors.
To prevent unnecessary misunderstandings, we introduce position encoding (Yang et al. Reference Yang, Tong, Ma and Deng2016) when modeling text data to encode the positions of words in the sequence. This allows the model to fully comprehend the relative relationship between positions. In this paper, we express the sine and cosine functions of different frequencies as follows:
 \begin{equation} P E( p o s, 2 i)=\sin \left (p o s/ 10,000^{2 i/ d_{m o d e l}}\right ) \end{equation}
\begin{equation} P E( p o s, 2 i)=\sin \left (p o s/ 10,000^{2 i/ d_{m o d e l}}\right ) \end{equation}
 \begin{equation} P E(p o s, 2 i+1)=\cos \left (p o s/ 10,000^{2 i/ d_{\text{model }}}\right ) \end{equation}
\begin{equation} P E(p o s, 2 i+1)=\cos \left (p o s/ 10,000^{2 i/ d_{\text{model }}}\right ) \end{equation}
where
 $PE$
is a two-dimensional matrix, with the same size as the input embedding dimension. The rows represent the words, and the columns represent the word vectors.
$PE$
is a two-dimensional matrix, with the same size as the input embedding dimension. The rows represent the words, and the columns represent the word vectors.
 $p o s$
represents the position of the word in the sentence;
$p o s$
represents the position of the word in the sentence;
 $d_{\text{model }}$
represents the dimension of the word vector;
$d_{\text{model }}$
represents the dimension of the word vector;
 $i$
represents the position of the word vector. The above formula means adding the
$i$
represents the position of the word vector. The above formula means adding the
 $\sin$
variable to the even-numbered position of the word vector of each word, and adding the
$\sin$
variable to the even-numbered position of the word vector of each word, and adding the
 $\cos$
variable to the odd-numbered position, filling the entire
$\cos$
variable to the odd-numbered position, filling the entire
 $PE$
matrix, and then adding it to the input embedding. This introduces position information of words, reducing the occurrence of repeated words in the generated replies.
$PE$
matrix, and then adding it to the input embedding. This introduces position information of words, reducing the occurrence of repeated words in the generated replies.
3.4.2 BiGRU-attention
GRU, a type of RNN, determines the output value of the current node jointly based on the current input and the output of the previous node. This enables it to fully capture the information between the dialog content before and after (Bansal, Belanger, and McCallum Reference Bansal, Belanger and McCallum2016). However, GRU can only use historical information to make judgments on the current information and cannot use future information. Therefore, after assigning relative position information to the word and item-level data representations, we use bidirectional GRU to deeply extract the input vector (as shown in Fig. 4), such that the output of the current moment is related to the state of the previous and next moments.

Figure 4. BiGRU structure diagram (Bansal et al. Reference Bansal, Belanger and McCallum2016).
In addition, the attention mechanism (Vaswani et al. Reference Vaswani, Shazeer, Parmar, Uszkoreit, Jones, Gomez, Kaiser and Polosukhin2017) is introduced to assign corresponding probability weights to different word vectors and further extract features that highlight the key information of the dialog content. The attention mechanism helps to allocate resources to relatively more important tasks and alleviate information overload when computation is limited. It can effectively deal with the problem of complicated information selection and improve the ability of task processing. In each step of GRU, the attention mechanism can enhance the influence of relative interest, and the calculation of items in the recommender system is similar. Since the BiGRU model is regarded as two GRUs in opposite directions, the formula is simplified to Equation (3a). The word vector of the
 $t$
-th word of the
$t$
-th word of the
 $j$
-th sentence input at the
$j$
-th sentence input at the
 $i$
-th moment in the dialog system is
$i$
-th moment in the dialog system is
 $v_{i j t}$
, and the specific calculation formula is:
$v_{i j t}$
, and the specific calculation formula is:
 \begin{equation} h_{i j t}=\operatorname{BiGRU}\left (v_{i j t}\right ) \end{equation}
\begin{equation} h_{i j t}=\operatorname{BiGRU}\left (v_{i j t}\right ) \end{equation}
 \begin{equation} u_{i j t}=\tanh \left (w_{w} h_{i j t}+b_{w}\right ) \end{equation}
\begin{equation} u_{i j t}=\tanh \left (w_{w} h_{i j t}+b_{w}\right ) \end{equation}
 \begin{equation} \alpha _{i j t}=\frac{\exp \left (u_{i j t}^{T} u_{w}\right )}{\sum _{t} \exp \left (u_{i j t}^{T} u_{w}\right )} \end{equation}
\begin{equation} \alpha _{i j t}=\frac{\exp \left (u_{i j t}^{T} u_{w}\right )}{\sum _{t} \exp \left (u_{i j t}^{T} u_{w}\right )} \end{equation}
 \begin{equation} c_{i j t}=\sum _{i=1}^{n} \alpha _{i j t} h_{i j t} \end{equation}
\begin{equation} c_{i j t}=\sum _{i=1}^{n} \alpha _{i j t} h_{i j t} \end{equation}
where
 $h_{i j t}$
is the output vector of the BiGRU layer;
$h_{i j t}$
is the output vector of the BiGRU layer;
 $w_{w}$
is the weight coefficient;
$w_{w}$
is the weight coefficient;
 $b_{w}$
is the bias coefficient;
$b_{w}$
is the bias coefficient;
 $u_{w}$
is the randomly initialized attention mechanism matrix, and the activation function tanh adjusts the neural network’s output, compressing the value between -1 and 1. The attention mechanism matrix is obtained by the cumulative sum of the products of different probability weights assigned by the attention mechanism and the states of each hidden layer, using the softmax function for normalization. Thus, we use the attention mechanism to capture global information and current interests to infer user preferences.
$u_{w}$
is the randomly initialized attention mechanism matrix, and the activation function tanh adjusts the neural network’s output, compressing the value between -1 and 1. The attention mechanism matrix is obtained by the cumulative sum of the products of different probability weights assigned by the attention mechanism and the states of each hidden layer, using the softmax function for normalization. Thus, we use the attention mechanism to capture global information and current interests to infer user preferences.
3.4.3 Copy mechanism
Traditional sequence-to-sequence (seq2seq) models often generate responses that are irrelevant or invalid due to the fact that they rely solely on the conditional probability of the given query. To address this issue, we propose a two-seq2seq model (shown in Fig. 5) that utilizes both the query q and the retrieved reply r to synthesize a customized reply r *. Our proposed approach complements retrieval-based methods and enables generation-based dialog systems to generate new and relevant sentences. The two-seq2seq model consists of two encoders, one for the query and one for the retrieved reply, and a decoder that takes the outputs of both encoders as input. This design enables retrieval-based replies to provide additional information for generating responses, reducing the likelihood of generating generic replies. To fully capitalize on the retrieved replies, we integrate a copy mechanism (He et al. Reference He, Liu, Liu and Zhao2017a) into the decoding process.

Figure 5. The two-seq2seq model.
The copy mechanism enhances the quality of the generated response r * by extracting informative words from the retrieved reply r and suitable words from the encoder, which are then used as output words in the decoding process. The probability in the decoding process consists of two parts: the original probability
 $P_{g}$
, and
$P_{g}$
, and
 $P_{r^{*}}$
, which represents the matching degree between the current state vector
$P_{r^{*}}$
, which represents the matching degree between the current state vector
 $y_{t}$
and the corresponding state of the encoder. The formula is as follows:
$y_{t}$
and the corresponding state of the encoder. The formula is as follows:
 \begin{equation} P\left (y_{t} \mid s_{t}\right )=P_{g}\left (y_{t} \mid s_{t}\right )+P_{r^{*}}\left (y_{t} \mid h_{y_{t}}\right ) \end{equation}
\begin{equation} P\left (y_{t} \mid s_{t}\right )=P_{g}\left (y_{t} \mid s_{t}\right )+P_{r^{*}}\left (y_{t} \mid h_{y_{t}}\right ) \end{equation}
 \begin{equation} P_{r^{*}}\left (y_{t} \mid h_{y_{t}}\right )=\delta \left (s_{t} W_{c} h_{y_{t}}\right ) \end{equation}
\begin{equation} P_{r^{*}}\left (y_{t} \mid h_{y_{t}}\right )=\delta \left (s_{t} W_{c} h_{y_{t}}\right ) \end{equation}
where
 $h_{y_{t}}$
is the hidden state of the retrieved reply r, corresponding to
$h_{y_{t}}$
is the hidden state of the retrieved reply r, corresponding to
 $y_{t}$
in the decoder,
$y_{t}$
in the decoder,
 $\delta$
(.) is the sigmoid function, and
$\delta$
(.) is the sigmoid function, and
 $w_{c}$
is the parameter matching
$w_{c}$
is the parameter matching
 $s_{t}$
and
$s_{t}$
and
 $y_{t}$
. It should be noted that only words are copied from the replies, if
$y_{t}$
. It should be noted that only words are copied from the replies, if
 $y_{t}$
does not appear in the retrieved replies, then the corresponding
$y_{t}$
does not appear in the retrieved replies, then the corresponding
 $P_{r^{*}}$
is 0. It can be seen that the generated responses are closely related to the query, and keywords are extracted from the retrieved responses, enhancing the quality of the generated responses.
$P_{r^{*}}$
is 0. It can be seen that the generated responses are closely related to the query, and keywords are extracted from the retrieved responses, enhancing the quality of the generated responses.
In summary, our proposed approach combines DTN with a two-seq2seq model to enhance the relevance and coherence of the generated responses in a dialog system. By incorporating temporal features and leveraging the information contained in retrieved replies, we aim to improve the overall quality of the system’s outputs.
3.5 Enhanced recommender system
After obtaining the representation of the time-series feature of the conversation, our model generates recommendations based on the user’s preferences, keyword information, and relevant item information. Specifically, we fuse the word representation
 $v^{(C)}$
of all contexts in the dialog with the representation
$v^{(C)}$
of all contexts in the dialog with the representation
 $n^{(C)}$
of all items that appear and use this information to obtain the user preference
$n^{(C)}$
of all items that appear and use this information to obtain the user preference
 $p_{u}$
as follows:
$p_{u}$
as follows:
 \begin{equation} p_{u}=\beta \cdot v^{(C)}+(1-\beta ) \cdot n^{(C)} \end{equation}
\begin{equation} p_{u}=\beta \cdot v^{(C)}+(1-\beta ) \cdot n^{(C)} \end{equation}
 \begin{equation} \beta =\sigma \left (W_{\text{gate }}\left [v^{(C)} ;\; n^{(C)}\right ]\right ) \end{equation}
\begin{equation} \beta =\sigma \left (W_{\text{gate }}\left [v^{(C)} ;\; n^{(C)}\right ]\right ) \end{equation}
where
 $\beta$
is the update gate, which is used to decide whether to ignore the current word,
$\beta$
is the update gate, which is used to decide whether to ignore the current word,
 $\sigma$
means that the update gate adds the two parts of information and puts it into the sigmoid activation function, and
$\sigma$
means that the update gate adds the two parts of information and puts it into the sigmoid activation function, and
 $W_{\text{gate }}$
is a learnable parameter matrix. Once the user preference
$W_{\text{gate }}$
is a learnable parameter matrix. Once the user preference
 $p_{u}$
has been obtained, we can calculate the probability of recommending each item to the user, resulting in a ranking of recommended items:
$p_{u}$
has been obtained, we can calculate the probability of recommending each item to the user, resulting in a ranking of recommended items:
 \begin{equation} P_{r e c}(i)=\operatorname{softmax}\left (p_{u}^{T} \cdot n_{i}\right ) \end{equation}
\begin{equation} P_{r e c}(i)=\operatorname{softmax}\left (p_{u}^{T} \cdot n_{i}\right ) \end{equation}
With this framework, we have successfully integrated the recommender system and dialog system, promoting seamless collaboration between the two modules and improving the overall performance of the dialog recommender system.
4. Experiment
In this section, we provide a comprehensive description of our experimental setup, including datasets, results, and analysis.
4.1 Datasets
In order to verify the effectiveness of the model, we select REcommendations through DIALog (REDIAL) (Li et al. Reference Li, Ebrahimi Kahou, Schulz, Michalski, Charlin and Pal2018) and INSPIRED (Hayati et al. Reference Hayati, Kang, Zhu, Shi and Yu2020) as datasets. The REDIAL has 10,006 dialogs and 182,150 sentences on the topic of providing movie recommendations. The total number of users and movies is 956 and 51,699, respectively. In each dialog, one person is the movie seeker and the other is the recommender. The movie seeker must explain what genres they like and ask for advice on movies, while the recommender tries to understand the seeker’s movie tastes and recommend movies. All information exchanges and suggestions are done using formal natural language, only talking about the movie and especially not the task itself. The training set, validation set, and test set are divided in a ratio of 8:1:1. INSPIRED is a similar dataset for movie recommendations as REDIAL, but smaller, containing only 1001 human conversations. In addition to the movie datasets, we also introduce related entities and relations from Conceptnet and DBpedia to improve the performance of our model. We systematically proposed and evaluated neural models for the entire dialog recommender system using this corpus.
4.2 Setting
This experiment adopts the PyTorch deep learning framework and uses the Python language programming to realize; the experimental running environment is JetBrains PyCharm software, ubuntu20.04 system, memory 11 GB, etc. The embedding dimensions (including hidden vectors) of the dialog system and the recommender system are set to 300 and 128, respectively; the number of layers L of both GCN and R-GCN is 1. During training, we use the Adam optimizer with default parameter settings: the batch size is set to 32, the learning rate is 0.001, and the gradient is limited to [0, 0.1]. The experimental parameter Settings are shown in Table 2.
Table 2. Experimental hyperparameter settings

4.3 Evaluation metrics
In the experiments, we adopt two different metrics to evaluate the dialog and recommendation modules respectively, which are also common in previous work. Dialog evaluation includes automatic evaluation and human evaluation. For automatic evaluation, since the diversity score of vocabulary can measure the breadth and richness of words used in the text, this paper uses the diversity (Distinct) indicator to judge whether there are a large number of general and repetitive replies. Distinct is defined as follows:
 \begin{equation} \operatorname{Distinct}(n)=\frac{\operatorname{Count}(\text{unique n-gram})}{\operatorname{Count}(\text{word})} \end{equation}
\begin{equation} \operatorname{Distinct}(n)=\frac{\operatorname{Count}(\text{unique n-gram})}{\operatorname{Count}(\text{word})} \end{equation}
 $Count(unique\,n-gram)$
represents the number of unique n-grams present in the reply sentence, while
$Count(unique\,n-gram)$
represents the number of unique n-grams present in the reply sentence, while
 $Count(word)$
represents the total number of n-gram words in the reply sentence. In this paper, Distinct 2-gram, Distinct 3-gram, and Distinct 4-gram are used to evaluate the performance of the dialog module. The larger the Distinct-n, the higher the diversity of responses.
$Count(word)$
represents the total number of n-gram words in the reply sentence. In this paper, Distinct 2-gram, Distinct 3-gram, and Distinct 4-gram are used to evaluate the performance of the dialog module. The larger the Distinct-n, the higher the diversity of responses.
The evaluation of the recommendation module is based on the recall rate, which measures the ratio of relevant results retrieved from the top k items in the recommendation list to the total number of relevant items in the dataset. Recall rate ranges from 0 to 1, with higher values indicating better performance. We report the recall rates at different values of k, namely Recall@1, Recall@10, and Recall@50.
Meanwhile, for human evaluation, since we want the generated replies to be item-related suggestions, we invite five annotators with knowledge in linguistics and require them to score the generated sentences in two aspects, namely Fluency and Informativeness. The final performance is calculated using the average score of these annotators.
4.4 Compared methods
We compare our approach with models used by some mainstream dialog recommender systems:
TextCNN (Kim Reference Kim2014): It proposed a CNN-based model for sentence-level classification tasks by extracting features in context. First, the natural language of the input sentence is encoded into a distributed representation through the embedding layer, and then, the different n-gram features of the sentence are extracted through a convolution layer, and finally, the output results are obtained through the fully connected layer.
Transformer (Wang et al. Reference Wang, Zhang, Zhao, Li, Xie and Guo2019): It adopted a transformer-based encoder-decoder framework consisting of self-attention and feed-forward neural networks to generate appropriate responses for dialog modules. It can be trained in parallel, the speed is relatively fast, and the problem of long-distance dependence is well solved.
REDIAL (Li et al. Reference Li, Ebrahimi Kahou, Schulz, Michalski, Charlin and Pal2018): This work is the earliest exploration of generative dialog recommendation to develop an agent that can chat with partners and ask their movie tastes in order to provide movie recommendations. It is mainly composed of HRED-based dialog generation system, auto-encoder-based recommender system, and sentiment analysis module.
KBRD (Chen et al. Reference Chen, Lin, Zhang, Ding, Cen, Yang and Tang2019): An end-to-end framework, KBRD, is proposed to bridge the gap between recommender systems and dialog systems through knowledge dissemination. External knowledge is also introduced to align entities that appear in the dialog content with nodes on the graph, making it possible for the system to recommend based on entities mentioned in the dialog.
KGSF (Zhou et al. Reference Zhou, Zhao, Bian, Zhou, Wen and Yu2020): It proposed a knowledge graph-based semantic fusion method that enhances the semantic representation of words and items and uses mutual information maximization to align the semantic spaces of two different components by using two external KGs.
RevCore (Lu et al. Reference Lu, Bao, Song, Ma, Cui, Wu and He2021): It performed comment enrichment and entity-based recommendations on item suggestions by extracting comments that match emotions and generating responses using a comment-focused encoder-decoder.
 $C^{2}$
-CRS (Zhou et al. Reference Zhou, Zhou, Zhao, Wang, Jiang and Hu2022): It proposed a new contrastive learning-based coarse-to-fine pre-training method, which effectively integrated multi-type data representations by adopting a coarse-to-fine pre-training strategy to enhance the representation of the conversation context.
$C^{2}$
-CRS (Zhou et al. Reference Zhou, Zhou, Zhao, Wang, Jiang and Hu2022): It proposed a new contrastive learning-based coarse-to-fine pre-training method, which effectively integrated multi-type data representations by adopting a coarse-to-fine pre-training strategy to enhance the representation of the conversation context.
KGTO (Pan, Yin, and Huang Reference Pan, Yin and Huang2022): It presented a topic-oriented model based on keyword guidance, which used a hierarchical attention mechanism to extract keywords and capture more accurate topics. It also integrated co-occurrence and knowledge graphs to enrich contextual information of the item.
Among these baseline models, TextCNN is a recommendation method, transformer is the state-of-the-art text generation method. Redial is the earliest exploration of generative dialog recommendation. The rest Redial, KBRD, KGSF,
 $C^{2}$
-CRS, and KGTO are dialog recommender systems.
$C^{2}$
-CRS, and KGTO are dialog recommender systems.
4.5 Results
In this subsection, we present our experimental results, including recommendation and dialog generation aspects. Table 3 shows the performance of different methods under three settings.
Table 3. Results of recommendation system

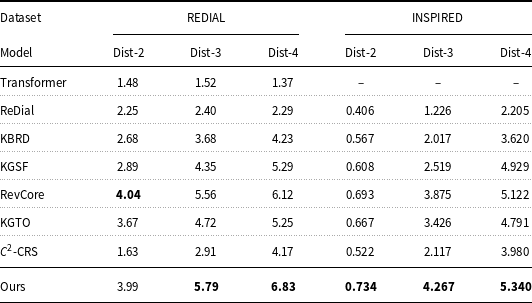
Table 4. Automatic evaluation of dialog system
4.5.1 Recommended module performance
To evaluate the effect of recommender systems, we evaluate Recall@K, which refers to whether the top k items selected by the recommender system contain ground truth recommendations provided by human recommenders. The results are shown in Table 3.
The results show that the CRS model is more effective than the simple recommendation method TextCNN. In contrast to the basic TextCNN, Redial uses entities or items in context to make recommendations, while KBRD and KGSF make more use of external knowledge. RevCore further enhances the generation of dialog responses by using emotionally coordinated comments on top of this. Our method is superior to all the above-generation methods. Unfortunately, our approach is worse than the
 $C^{2}$
-CRS model based on the pre-training approach.
$C^{2}$
-CRS model based on the pre-training approach.
 $C^{2}$
-CRS uses contrastive learning method to combine multi-type data such as text, item, and external comments related to entities to enhance data representation, which helps to better capture user preferences. In contrast, we only use words and items to align semantic representations, ignoring unstructured data such as reviews, and incomprehensively utilizing heterogeneous external data. However, this does not mean that our method is meaningless, as we can see below that our method performs better than
$C^{2}$
-CRS uses contrastive learning method to combine multi-type data such as text, item, and external comments related to entities to enhance data representation, which helps to better capture user preferences. In contrast, we only use words and items to align semantic representations, ignoring unstructured data such as reviews, and incomprehensively utilizing heterogeneous external data. However, this does not mean that our method is meaningless, as we can see below that our method performs better than
 $C^{2}$
-CRS in the dialog module, one possible reason is that the external comments introduced contain a lot of noise. In addition, we should note that our method outperforms all the generative methods. This shows that on the basis of the retrieval method, the introduction of knowledge graph and context based on time-series features can indeed accurately learn the feature relationship between users and items. Inspired by
$C^{2}$
-CRS in the dialog module, one possible reason is that the external comments introduced contain a lot of noise. In addition, we should note that our method outperforms all the generative methods. This shows that on the basis of the retrieval method, the introduction of knowledge graph and context based on time-series features can indeed accurately learn the feature relationship between users and items. Inspired by
 $C^{2}$
-CRS, we can study how to integrate more external data while improving the accuracy of recommendations and diversity of conversations.
$C^{2}$
-CRS, we can study how to integrate more external data while improving the accuracy of recommendations and diversity of conversations.
4.5.2 Dialog module performance
In this subsection, we verify the effectiveness of the proposed model for the conversation task and describe the results on automatic and human evaluation metrics.
4.5.2.1 Automatic evaluation
Table 4 shows the evaluation results of the baseline models and the proposed methods in dialog generation. Dist-2, Dist-3, and Dist-4 represent distinct 2-gram, distinct 3-gram, and distinct 4-gram, respectively. We can see that ReDial performs better than transformer because ReDial applies RNN models to generate better historical dialog representations. Secondly, KBRD and KGSF enhance the context entities and items by external knowledge graphs, resulting in sentence diversity. Thirdly, RevCore enriches the dialog representation by introducing emotional factors, producing diverse responses. Additionally, KGTO and
 $C^{2}$
-CRS perform poorly, possibly due to focusing more on the accuracy of generating sentences, while neglecting to reduce the generation of safe responses. On the REDIAL dataset, our proposed method is close to the results of RevCore in the Dist-2 metric and significantly better than baselines in Dist-3 and Dist-4. On the INSPIRED dataset, our method also obviously outperforms the other models, indicating that introducing the temporal features of dialog content and retrieval model is extremely necessary. Our model can generate relatively more diverse content while ensuring fluency and informativeness.
$C^{2}$
-CRS perform poorly, possibly due to focusing more on the accuracy of generating sentences, while neglecting to reduce the generation of safe responses. On the REDIAL dataset, our proposed method is close to the results of RevCore in the Dist-2 metric and significantly better than baselines in Dist-3 and Dist-4. On the INSPIRED dataset, our method also obviously outperforms the other models, indicating that introducing the temporal features of dialog content and retrieval model is extremely necessary. Our model can generate relatively more diverse content while ensuring fluency and informativeness.
4.5.2.2 Human evaluation
For human evaluation, we sample 100 multi-turn dialogs from REDIAL’s test set together with the corresponding responses and require the annotators to score the whether the candidates have more meaningful information and fluency. The score range is 0–2 points, and we adopt the average score of these annotators. As shown in Table 5, compared with the best-performing
 $C^{2}$
-CRS model, our method achieved better performance with increases of 0.02 in fluency and 0.08 in informativeness, indicating that our model can effectively utilize context information and generate fluent and informative responses.
$C^{2}$
-CRS model, our method achieved better performance with increases of 0.02 in fluency and 0.08 in informativeness, indicating that our model can effectively utilize context information and generate fluent and informative responses.
Table 5. Human evaluation of dialog system

Table 6. Results of ablation analysis

4.5.3 Ablation analysis
Additionally, this study also conducted ablation studies (as shown in Table 6) to observe the contribution of each component. Specifically, one module was removed for training, and then, the experimental results were compared. If the overall performance is lower after removing the module than before, it indicates that the module is effective in improving performance. Four ablation experiments were conducted in this paper: the method without the retrieval module (w/o Retrieval), the method without positional encoding (w/o PE), the method without the proposed deep temporal network, and the method without knowledge graph (w/o DB).
From Table 6, we can observe that each indicator decreases to varying degrees when a particular part of the model is removed during training. Furthermore, from Fig. 6, it can be seen that the model performs best when the retrieval and generation modules are both present. The retrieval module provides accurate candidate replies for CRS and provides effective information for the generation model. When this part is removed, the system’s performance will decrease. Specifically, the knowledge graph provides various types of knowledge and background data for the dialog recommendation system. When the item-oriented KG is removed, the performance decrease is particularly significant. In addition, the DTN provides potential sequential dependencies for the dialog context. When the model does not add DTN, each indicator shows a significant decrease. The position encoding strengthens the importance of temporal features and reduces the occurrence of repeated words in the generated responses. When this part is removed, the performance also decreases accordingly. Therefore, we have reason to believe that the content of the dialog based on deep temporal features is particularly important in the dialog recommendation system, and the retrieval function is also indispensable, providing suitable recommendations together.

Figure 6. Line chart of ablation experiment results.
In conclusion, this study believes that the proposed method of fusing retrieval and generation based on time-series features can effectively enrich the performance of dialog recommendation systems. By combining the precision of retrieval methods with the fluency of generation methods, and utilizing the deep temporal features of dialog content, our method is highly effective.
5. Conclusion
This paper proposes an improved dialog recommender method based on time-series features of dialog context. By augmenting the semantic representation of word and item with two external knowledge graphs, the semantic space is aligned using mutual information maximization techniques. Additionally, we use a deep timing network model to provide different recommendations based on the order of dialog content and introduce the retrieved responses to provide the corresponding information for the generative model to improve the accuracy and diversity of the dialog recommendation system. Through a series of experiments, we demonstrate that our method achieves good performance in both dialog and recommendation. In future work, we will focus on introducing more context-relevant external data and designing generic presentation models to incorporate the underlying semantics. We will also consider introducing new techniques to make conversations more persuasive and provide explanations for recommendations, while applying the model to more scenarios, such as multi-modal CRS.
Financial support
This work is supported by National Key Research and Development Program of China (2020AAA0109700), National Natural Science Foundation of China (62076167), the general project of the 14th Five-Year Scientific Research Plan of the National Language Commission (YB145-16) and China Post Doctoral Science Foundation (2022M722231).













 Open access
Open access