


1. Introduction
The Cambridge Dictionary defines hate speech as follows: “Hate speech is a public speech that expresses hate or encourages violence towards a person or group based on race, religion, sex, or sexual orientation.”Footnote a It has been estimated that half of the world’s population uses social mediaFootnote b and that users spend over
 $12\frac{1}{2}$
trillion hours per year online.Footnote c This current trend is rapidly expanding. Social violence, including riots, has been caused by aggressive online behavior such as false news, abusive comments, and hostile online communities (Laub Reference Laub2019). Governments worldwide are enacting anti-hate speech laws.Footnote d As a result, online platforms like ™Twitter, ™Facebook, etc., are becoming increasingly aware of the issue and working to prevent the spread of hate speech, sexual harassment, cyberbullying, and other forms of abuse.
$12\frac{1}{2}$
trillion hours per year online.Footnote c This current trend is rapidly expanding. Social violence, including riots, has been caused by aggressive online behavior such as false news, abusive comments, and hostile online communities (Laub Reference Laub2019). Governments worldwide are enacting anti-hate speech laws.Footnote d As a result, online platforms like ™Twitter, ™Facebook, etc., are becoming increasingly aware of the issue and working to prevent the spread of hate speech, sexual harassment, cyberbullying, and other forms of abuse.
Most hate speech detection research is conducted using European language.Footnote e Except for the publication of datasets and the improvement in accuracy, very little is done to study Indian languages further. According to Rajrani and Ashok (Reference Rajrani and Ashok2019), the Eighth Schedule of the Indian Constitution lists 22 languages and over 1,000 living languages from different linguistic families. Users on social media platforms in India often post in their native languages, which might make it difficult to detect hate speech computationally because of improper syntax or grammar. Because of this incident, we investigated hate speech in online comments. Hate speech detection in text is difficult for machine learning techniques. Researchers increasingly adopt advanced transformer models to improve performance in fields like NLP, information retrieval, and others that deal with language. Named entity recognition (Luoma and Pyysalo Reference Luoma and Pyysalo2020), question answering (McCarley et al. Reference McCarley, Chakravarti and Sil2019), token classification (Ulčar and Robnik-Šikonja Reference Ulčar and Robnik-Šikonja2020), text classification (Sun et al. Reference Sun, Qiu, Xu and Huang2019), etc., are the significant famous field of NLP researchers. Hate speech detection is closely related to text classification.
India is diverse in language, so many language-specific studies and research have been done. Hate speech is subjective and context-dependent most of the time, so in the Indian context, it is a very challenging problem. Most Indian languages are under-resourced. This study aims to detect hate content in comments written in Hindi, Marathi, Bangla, Assamese, and Bodo gathered from social media platforms. We used HASOC (Hate Speech and Offensive Content Identification)Footnote f and HS-Bangla (Hate Speech Bangla)Footnote g datasets, employing binary classification methods. Hindi, Marathi, and Bangla are almost moderately spoken languages in India, and they have the advantage in the computational fields where annotated data is required. Regardless, this is not sufficient; at least they are available. However, some low-resource languages suffer simultaneously due to a shortage of annotated data. Considering the scarcity, we have prepared an Assamese and a Bodo dataset for the hate speech detection task, which will be publicly available shortly. Both languages are one of the 22 scheduled languages in India, primarily spoken in the Northeastern region of India–Assamese shares the Bangla-Assamese script, which has evolved from the Kamrupi script. On the other hand, Bodo pronounced as Boro, is mainly spoken in India’s Northeastern part of the Brahmaputra valley. The language is part of the Sino-Tibetan language family under the Assam-Burmese group and shares the Devanagari script. The 2011 Indian CensusFootnote h (Census 2011a, 2011b) estimates a total of 1,482,929 Bodo speakers, including 1,454,547 native speakers. Assamese is spoken by 15,311,351 people, which is a huge number. In NLP research, very few resources are available on Assamese and Bodo, which leads to less advancement.
We take advantage of the multilingual and monolingual language models based on transformers, which have brought attention to low-resource languages. Multilingual and monolingual language models are pre-trained on BERT (Bidirectional Encoder Representations from Transformers) (Devlin et al. Reference Devlin, Chang, Lee and Toutanova2018), RoBERTa (Robustly optimized BERT) (Liu et al. Reference Liu, Ott, Goyal, Du, Joshi, Chen, Levy, Lewis, Zettlemoyer and Stoyanov2019), ALBERT (A Lite BERT) (Lan et al. Reference Lan, Chen, Goodman, Gimpel, Sharma and Soricut2019), DistilBERT (Distilled version of BERT) (Sanh et al. Reference Sanh, Debut, Chaumond and Wolf2019a). We utilize few pre-trained multilingual models like m-BERT (Devlin et al. Reference Devlin, Chang, Lee and Toutanova2018), MuRIL-BERT (Khanuja et al. Reference Khanuja, Bansal, Mehtani, Khosla, Dey, Gopalan, Margam, Aggarwal, Nagipogu, Dave, Gupta, Gali, Subramanian and Talukdar2021), and monolingual models as well such as NeuralSpaceHi-BERT (Jain et al. Reference Jain, Deshpande, Shridhar, Laumann and Dash2020), RoBERTa-Hindi, Indic-BERTt (Kakwani et al. Reference Kakwani, Kunchukuttan, Golla, Gokul, Bhattacharyya, Khapra and Kumar2020), Maha-BERT (Joshi Reference Joshi2022a), Maha-RoBERTa (Joshi Reference Joshi2022b), XLM-RoBERTa (Conneau et al. Reference Conneau, Khandelwal, Goyal, Chaudhary, Wenzek, Guzmán, Grave, Ott, Zettlemoyer and Stoyanov2019), Bangla-BERT (Sarker Reference Sarker2020), Assamese-BERT (Joshi Reference Joshi2023) etc. We fine-tuned different multilingual and monolingual pre-trained BERT models for all the languages. Later, an analysis-based study compares the performance of different pre-trained language models on Hindi, Marathi, Bangla, Assamese, and Bodo datasets. In our case, the monolingual models are only pre-trained in Hindi, Marathi, Bangla, and Assamese data. Next, we follow a cross-lingual experiment (Litake et al. Reference Litake, Sabane, Patil, Ranade and Joshi2022) which includes only monolingual models, since Hindi-Marathi-Bodo shares the Devanagari script, where Assamese-Bangla shares similar scripts except for few characters (Ghosh et al. Reference Subhankar Ghosh, Das and Chaudhuri2012). The experiments are a hurricane test on the dataset to see whether the experiments give a promising result or not. We found a promising result, which is another contribution of this paper. So, our experiment can help researchers to work with under-resource languages.
Our focus in this work is :
-
• We prepare two hate speech text datasets in Assamese and Bodo languages, consisting of two classes: “NOT” and “HOF.”
-
• Subsequently, we fine-tuned pre-trained language models on three existing (Hindi, Marathi, and Bangla) and two new datasets (Assamese and Bodo) to evaluate their performance in handling a new language.
-
• To assess the performance of language models, we employed mono and multilingual variants of transformer-based language models (TLMs).
-
• A comprehensive comparison among all models has been conducted for the mentioned languages. Around forty-one experiments were carried out: twelve for Hindi and Marathi each, seven for Bangla, and five for Bodo and Assamese individually.
-
• In the end, a cross-lingual experiment between Hindi-Marathi-Bodo and Assamese-Bangla is done where monolingual Marathi models, i.e., Maha-BERT, Maha-RoBERTa, RoBERTa-Base-Mr, and Maha-AlBERT, perform well on the Hindi dataset. NeuralSpaceHi-BERT, RoBERT-Hindi, and DistilBERTHi, which are monolingual Hindi models, also perform well in the case of the Marathi dataset.
The flow of the paper is structured as follows. Section 2 covers the relevant literature on detecting hate speech in Indian languages. Section 3 describes the existing as well as new datasets. Section 4 explains detailed methodology like preprocessing steps, transformer-based models, experimental settings, etc. Section 5 presents the results and findings obtained from the comprehensive experiments conducted. Finally, conclusions are drawn in Section 6.
2. Related work
Extensive research exists in hate speech detection for European languages, but there is a significant gap regarding Indian languages. This scarcity arises from the limited availability of publicly accessible datasets for NLP tasks, including hate speech detection. Creating datasets for hate speech detection is particularly demanding as it requires extensive groundwork and data preprocessing, such as cleaning the data, ensuring annotator agreement on hate speech identification, and transforming raw social media content into valuable training data. In this section, we shall discuss the existing research specific to Indian languages to address this challenge.
2.1 Hindi
In 2019, a shared task called HASOC (Mandl et al. Reference Mandl, Modha, Majumder, Patel, Dave, Mandlia and Patel2019) released its first collection of datasets focusing on hate speech detection in Indian languages like Hindi and Marathi. HASOC is a collaborative effort organized by FIRE,Footnote i the Forum for Information Retrieval Evaluation. HASOC (Indo-Aryan Languages) included subtask A, a binary classification task for identifying hateful text in Hindi, which is relevant to our objective. The winning team QutNocturnal (Bashar and Nayak Reference Bashar and Nayak2020) for subtask A achieved good results in identifying hateful text. They used a convolutional neural network (CNN) with Word2Vec embeddings and achieved Marco-F1 of 0.8149 and weighted F1 of 0.8202. LGI2P (Mensonides et al. Reference Mensonides, Jean, Tchechmedjiev and Harispe2019) team also achieved strong results on subtask A. Their system utilized a fastText model to learn word representations in Hindi, followed by BERT for classification. This approach produced a Marco-F1 score of 0.8111 and a weighted F1 score of 0.8116. The HASOC also included another task (subtask B) focusing on classifying the type of hate speech, such as whether it’s profane or abusive (multiclass). The team 3Idiots (Mishra and Mishra Reference Mishra and Mishra2019) achieved promising results on subtask B using BERT, obtaining Marco-F1 and weighted F1 scores of 0.5812 and 0.7147, respectively. Subtask C focused on identifying whether hate speech targets a specific group or individual, i.e., targeted or untargeted (multiclass). Team A3-108 (Mujadia, Mishra, and Sharma Reference Mujadia, Mishra and Sharma2019) achieved the best results on this task, with a Marco-F1 score of 0.5754. Their approach relied on Adaboost (Freund and Schapire Reference Freund and Schapire1997), a machine learning algorithm that outperformed other options like Random Forest (RF) and Support Vector Machines (SVMs) for this specific task. Interestingly, combining these three classifiers using a technique called “ensemble with hard voting” yielded even better results. They utilized TF-IDF to extract features from word unigrams (individual words) and character sequences of varying lengths (2 g to 5 g), including tweet length as a feature. Subtask A (binary class) and subtask B (multiclass) are offered with a new Hindi dataset in HASOC 2020 (Mandl et al. Reference Mandl, Modha, Anand Kumar and Chakravarthi2020). Team NSIT_ML_Geeks (Raj, Srivastava, and Saumya Reference Raj, Srivastava and Saumya2020) utilize CNN and Bidirectional long short-term memory (BiLSTM) to beat other teams with the Marco-F1 score of 0.5337 in subtask A and 0.2667 in subtask B. Nohate (Kumari) fine-tuned BERT model and gained Marco-F1 0.3345 in subtask B. In HASOC-2021, on a newly published Hindi dataset (Modha et al. Reference Modha, Mandl, Shahi, Madhu, Satapara, Ranasinghe and Zampieri2021), the best submission was performed macro F1 0.7825 in subtask A where authors fine-tuned multilingual BERT (m-BERT) upto 20 epochs with a classifier layer added at the final phase. The second team also fine-tuned (m-BERT) and scored macro F1 0.7797. NeuralSpace (Bhatia et al. Reference Bhatia, Bhotia, Agarwal, Ramesh, Gupta, Shridhar, Laumann and Dash2021) got macro F1 0.5603 in subtask B. They use an XLM-R transformer, vector representations for emojis using the system Emoji2Vec, and sentence embeddings for hashtags. After that, three resulting representations were concatenated before classification. In other independent work, authors (Bhardwaj et al. Reference Bhardwaj, Akhtar, Ekbal, Das and Chakraborty2020) prepared the hostility detection dataset in Hindi and applied the pre-trained m-BERT model for computing the input embedding. Later, classifiers such as SVM, RF, Multilayer perceptron (MLP), and Logistic Regression (LR) models were employed. In coarse-grained evaluation, SVM achieved the highest weighted F1 score of 84% whereas LR, MLP, and RF scores of 84%, 83%, and 80%, respectively. In fine-grained evaluation, SVM displays the highest F1 scores across three hostile dimensions: Hate (47%), Offensive (42%), and Defamation (43%). Logistic Regression outperforms other models in the Fake dimension, achieving an F1 score of 68%. Authors (Ghosh et al. Reference Ghosh, Sonowal, Basumatary, Gogoi and Senapati2023c) presented a multitasked framework for hate and aggression detection on social media data. They used a transformer-based approach like XLM-RoBERTa. Ghosh and Senapati (Reference Ghosh and Senapati2022) present an analysis of multi and monolingual language models on three Indian languages like Hindi, Marathi, and Bangla.
2.2 Marathi
Team WLV-RIT (Nene et al. Reference Nene, North, Ranasinghe and Zampieri2021) uses XLM-R Large model with a simple softmax layer for fine-tuning on Marathi dataset of HASOC-2021 (Modha et al. Reference Modha, Mandl, Shahi, Madhu, Satapara, Ranasinghe and Zampieri2021) and secure the first rank. dataset named OffensEval 2019 (Zampieri et al. Reference Zampieri, Malmasi, Nakov, Rosenthal, Farra and Kumar2019) and Hindi data released for HASOC 2019 (Mandl et al. Reference Mandl, Modha, Majumder, Patel, Dave, Mandlia and Patel2019) are used for the performance. The authors established that transfer learning from Hindi is better than learning from English, with a score of 0.9144 (macro F1). The second team scores 0.8808, fine-tuning LaBSE transformer (Feng et al. Reference Feng, Yang, Cer, Arivazhagan and Wang2020) on the Marathi and Hindi datasets. LaBSE transformer (Glazkova et al. Reference Glazkova, Kadantsev and Glazkov2021) outperforms XLM-R in the monolingual settings, but XLM-R performs better when Hindi and Marathi data are merged. The first huge Marathi hate dataset on text is presented by L3Cube-MahaHate (Velankar et al. Reference Velankar, Patil, Gore, Salunke and Joshi2022) with 25,000 distinct tweets from ™Twitter, later annotated manually, and labeled them into four major classes, i.e., hate, offensive, profane, and not. Finally, they use CNN, Long short-term memory (LSTM), and Transformers. Next, they study monolingual and multilingual variants of BERT like Maha-BERT, Indic-BERT, m-BERT, and XLM-RoBERTa, showing that monolingual models perform better than their multilingual counterparts. Their Maha-BERT (Joshi Reference Joshi2022a) model provides the best results on L3Cube-MahaHate Corpus.
2.3 Bangla
Karim et al. (Reference Karim, Chakravarthi, McCrae and Cochez2020) prepared a dataset with 35,000 hate statements (political, personal, geopolitical, and religious) in Bangla and analyzed the data by combining multichannel CNN and LSTM-based networks. Later, more than 5,000 labeled examples were added to the previous dataset, and an extended version, i.e., DeepHateExplainer (Karim et al. Reference Karim, Dey, Islam, Sarker, Menon, Hossain, Hossain and Decker2021), was published. Authors used an ensemble method of transformer-based neural architectures to classify them into political, personal, geopolitical, and religious hates. They achieved F1 scores of 78%, 91%, 89%, and 84% for political, personal, geopolitical, and religious hates. In the paper (Romim et al. Reference Romim, Ahmed, Talukder and Saiful2021), they prepared a Bangla Hate Speech corpus with 30,000 comments labeled with “1” for hate comments; otherwise, “0." Authors (Mandal, Senapati, and Nag Reference Mandal, Senapati and Nag2022) produced a political news corpus and then developed a keyword or phrase-based hate speech identifier using a semi-automated approach. Authors (Romim et al. Reference Romim, Ahmed, Islam, Sharma, Talukder and Amin2022) created a Bangla dataset that includes 50,200 offensive comments. Here, they did binary classification and multilabel classification using BiLSTM and SVM.
2.4 Assamese
In the NLP field, Assamese is a very low-resourced language. Some recent works have been done on the Assamese language. In Nath et al. (Reference Nath, Mannan and Krishnaswamy2023), authors present AxomiyaBERTa, which is a novel BERT model for Assamese, a morphologically rich low-resource language of Eastern India. Authors (Das and Senapati Reference Das and Senapati2023) present a co-reference Resolution Tagged Data set in the Assamese dataset applying a semi-automated approach as co-reference resolution is an essential task in several NLP applications. Authors (Laskar et al. Reference Laskar, Paul, Dadure, Manna, Pakray and Bandyopadhyay2023) work on English to Assamese translation using the transformer-based neural machine translation. From the source-target sentences, they extract alignment information and they have used the pre-trained multilingual contextual embeddings-based alignment technique. In the paper Laskar et al. (Reference Laskar, Gogoi, Dutta, Adhikary, Nath, Pakray and Bandyopadhyay2022), the authors investigate the negation effect for English to Assamese machine translation.
2.5 Bodo
The NLP language technologies remain challenging due to resource constraints, research interest, and the unavailability of primary research tools. Historically, Bodo has a rich literature with a large corpus of oral history in the form of stories, folk tales, etc. Scholars suggested the presence of a lost Bodo script called “Deodhai.” Following the script movement, Bodo adopted the use of the Devanagari script. Bodo is one of the low-resource languages out of the scheduled languages of India. Various studies in the field of NLP have recently been undertaken. Bodo Wordnet (Bhattacharyya Reference Bhattacharyya2010) is another one of such first initiatives. With the initial efforts on the development of language tools and corpus undertaken by the Government of India. Datasets currently available are mainly due to efforts by Technology Development for Indian Languages (TDIL-DC). One such initiative is English to Indian Language Machine Translation (EILMT) consortia, under which the tourism domain English-Bodo parallel corpus consisting of 11,977 sentences was made and released for research purposes. EILMT Consortium developed an English-Bodo Agriculture text corpus consisting of 4,000 sentences and a Health Corpus of 12,383 parallel pairs. Indian Languages Corpora Initiative phase-II (ILCI Phase-II) project initiated by MeitY, Government of India resulted in the creation of 37,768 sentences of Agriculture & Entertainment domain for the Hindi-Bodo language pair. Low-resource languages are limited in terms of resources and language technologies to build the corpus. Recently, Narzary et al. (Reference Narzary, Brahma, Narzary, Muchahary, Singh, Senapati, Nandi and Som2022) proposed a methodology to utilize available freely accessible tools like Google Keep to extract monolingual corpus from old books written in Bodo. The majority of the NLP research for Bodo is towards the problem of machine translation (MT) with the objective of building English to Bodo or vice versa MT system. One such work (Narzary et al. Reference Narzary, Brahma, Singha, Brahma, Dibragede, Barman, Nandi and Som2019) English to Bodo MT system for Tourism domain achieved BLEU score of 17.9. The landscape of other NLP tasks remains challenging due to the absence of an annotated corpus.
3. Dataset
We used some existing datasets for our experiments, and later, we created an Assamese and a Bodo hate speech dataset for the experiments.
3.1 Existing datasets
Here, we use three publically available datasets i.e., HASOC-Hindi (Mandl et al. Reference Mandl, Modha, Majumder, Patel, Dave, Mandlia and Patel2019), HASOC-Marathi (Modha et al. Reference Modha, Mandl, Shahi, Madhu, Satapara, Ranasinghe and Zampieri2021), and HS-Bangla (2021) (Romim et al. Reference Romim, Ahmed, Talukder and Saiful2021).
3.1.1 HASOC-Hindi (2019) (Mandl et al. Reference Mandl, Modha, Majumder, Patel, Dave, Mandlia and Patel2019)
We use the HASOC-Hindi dataset, which was published in 2019. The entire dataset was collected from ™Twitter and ™Facebook with the help of different hashtags and keywords. Annotators tagged the data with two classes: hate & offensive (HOF) and not hate (NOT). HOF implies that a post contains hate speech, offensive language, or both. NOT means the absence of hate speech or other offensive material in the post. This is a shared task data, so training and test data are available separately.
3.1.2 HASOC-Marathi (2021) (Modha et al. Reference Modha, Mandl, Shahi, Madhu, Satapara, Ranasinghe and Zampieri2021)
This dataset is based on the released MOLD dataset (Gaikwad et al. Reference Gaikwad, Ranasinghe, Zampieri and Homan2021). MOLD contains data collected from ™Twitter. Authors used the hashtag #Marathi with 22 typical Marathi curse words and search terms for politics, entertainment, and sports. More than a total of 2,547 tweets were collected and were annotated by six native annotators. The final MOLD dataset contains 2,499 annotated tweets after removing non-Marathi tweets.
3.1.3 HS-Bangla (2021) (Romim et al. Reference Romim, Ahmed, Talukder and Saiful2021)
Researchers gather vast amounts of data from social media (™Twitter, ™Facebook pages and groups, ™LinkedIn), Bangla articles from various sources, including a Bangla Wikipedia dump, Bangla news articles like Daily Prothom Alo, Anandbazar Patrika, BBC, news dumps of TV channels (ETV Bangla, ZEE news), blogs, and books. The scraped text corpus consists of 250 million articles. This dataset consists of 30,000 instances, where 10,000 instances belong to the hate category, and 20,000 instances belong to non-hate. Hate comments are additionally categorized as political, gender abusive, personal, religious, or geopolitical hate.
Table 1 shows the training and test dataset statistics along with HOF (hate) and NOT (Not hate) class distribution for Hindi, Marathi, and Bangla datasets.
Table 1. Class-wise distribution for HASOC-Hindi (2019), HASOC-Marathi (2021), and HS-Bangla(2021) dataset

Figure 1 shows some snaps of the datasets, and the task is the binary classification for this paper, i.e., detecting whether a sentence or text conveys hate or not. For HASOC-Hindi (2019) and HASOC-Marathi (2021), classes are HOF and NOT whereas in HS-Bangla (2021), classes are 1 (hate) and 0 (non-hate).

Figure 1. Dataset samples of (a) HASOC-Hindi (2019), (b) HASOC-Marathi (2021), and (c) HS-Bangla (2021) datasets, respectively.
3.2 New corpus creation
We have created our hate speech dataset in the Assamese and Bodo languages, i.e., (HS-Assamese and HS-Bodo). This dataset is the extended version 2 and well-updated NEIHS (version 1) (Ghosh et al. Reference Ghosh, Senapati, Narzary and Brahma2023a, Reference Ghosh, Sonowal, Basumatary, Gogoi and Senapati2023b) datasets. We briefly discuss the data generation process in this section.
3.2.1 Dataset collection
Assamese and Bodo data have been collected mainly from ™Facebook and ™YouTube. We observed that the comment sections of political, news, celebrity, entertainment-based, etc. ™Facebook pages or ™YouTube channels are the most toxic. So, we target specific uploads and fetch the hate and not hate comments using open-source scrapper tools.Footnote j On the internet, data are primarily English transliteration and contain unwanted symbols -, ’, (, ), etc. We cleaned the data using an automatic or manual approach (if required) and translated the sentences. Finally, some native speakers annotate the comments either HOF or NOT. Sentences with HOF that include hate words are considered hate-offensive statements, while sentences that convey formal information, suggestions, or questions are considered non-hate sentences.
3.2.2 Dataset annotation
Two native speakers annotate the data for each language. Both annotators are young adults (aged 19 to 24). The annotators are all Central Institute of Technology undergraduate students, Kokrajhar. The annotation team manually assigns binary labels (hate and non-hate) to all Bodo comments to indicate the presence or absence of hateful content. When two students disagreed on a label, a third student with experience in social media research made the final call. Hate speech is a highly subjective issue. As a result, defining what constitutes hate speech is difficult. As a result, we’ve established specific strict guidelines. These regulations are based on the community standards of ™FacebookFootnote k and ™YouTube.Footnote l Comments with the following aims should be marked as hate. (a) Profanity: Comments that contain profanity, cussing, or swear words are marked as hate. (b) Sexual orientation: Sexual attraction (or a combination of these) to people of the opposite sex or gender, to people of the same sex or gender, to both sexes, or to people of more than one gender. (c) Personal: remarks on clothing sense, content selection, language selection, etc. (d) Gender chauvinism: Comments in which people are targeted because of their gender. (e) Religious: Comments in which the person is criticized for their religious beliefs and practices. For example, comments challenging the use of a turban or a burkha (the veil), (f) Political: Comments criticizing a person’s political beliefs. For instance, bullying people for supporting a political party. (g) Violent intention: Comments containing a threat or call to violence.
3.2.3 Dataset analysis
We summarize class distribution statistics of the HS-Assamese and HS-Bodo datasets in Table 2. Out of 2,497 comments in our HS-Bodo dataset, 1,396 contain hate speech, and for HS-Assamese, out of 5,045 comments, 2,955 are hate, and 2,090 are non-hate. As a result, our data set is slightly skewed in favor of containing hate speech. We split the dataset into a training set and test set by 80:20. In the HS-Bodo training set, 1,130 comments are hate out of 2,015 comments, and 266 are hate out of 482 in the test set. Figure 2 shows the HS-Assamese and HS-Bodo datasets sample.
Table 2. Class distribution analysis for Training and test set HS-Assamese and HS-Bodo datasets, respectively


Figure 2. Samples of (a) HS-Assamese and (b) HS-Bodo datasets where hate comments are tagged as HOF and otherwise NOT.
4. Methodology
Our experiment is mainly done on several transformer-based BERT models. We utilize three publicly available datasets: HASOC-Hindi (2019), HASOC-Marathi (2021), and HS-Bangla (2021). Later, two new hate speech datasets on the Assamese language (HS-Assamese) and Bodo language (HS-Bodo) were created for all the experiments.
4.1 Problem definition
The task aims to classify a given text as either HOF or NOT. Our dataset is
 $D$
, consists of
$D$
, consists of
 $ p$
texts, represented as
$ p$
texts, represented as
 $\{t_1, t_2, t_3,\ldots, t_i,\ldots t_p\}$
, where
$\{t_1, t_2, t_3,\ldots, t_i,\ldots t_p\}$
, where
 $t_i$
denotes the
$t_i$
denotes the
 $i^{th}$
text and
$i^{th}$
text and
 $ p$
is the total number of texts present in the dataset. Each text
$ p$
is the total number of texts present in the dataset. Each text
 $ t_i$
consists of
$ t_i$
consists of
 $ m$
words, denoted by
$ m$
words, denoted by
 $t_i =\{w_{i,1}, w_{i,2}, w_{i,3},\ldots,w_{i,k},\ldots,w_{i,m}\}$
, where
$t_i =\{w_{i,1}, w_{i,2}, w_{i,3},\ldots,w_{i,k},\ldots,w_{i,m}\}$
, where
 $ w_{i,k}$
indicates the
$ w_{i,k}$
indicates the
 $ k^{th}$
word in the
$ k^{th}$
word in the
 $i^{th}$
text. The dataset
$i^{th}$
text. The dataset
 $D$
is defined as
$D$
is defined as
 $D = \{(t_i,y_i)\}_{i=1}^p$
, where the
$D = \{(t_i,y_i)\}_{i=1}^p$
, where the
 $i^{th}$
text
$i^{th}$
text
 $t_i$
is labeled as either HOF or NOT, denoted as
$t_i$
is labeled as either HOF or NOT, denoted as
 $y_i$
. Thus,
$y_i$
. Thus,
 $D = \{(t_1, y_1), (t_2, y_2),(t_3, y_3),\ldots,(t_i,y_i),\ldots,(t_p,y_p)\}$
, where each tuple consists of the text (
$D = \{(t_1, y_1), (t_2, y_2),(t_3, y_3),\ldots,(t_i,y_i),\ldots,(t_p,y_p)\}$
, where each tuple consists of the text (
 $t_i$
) and label (
$t_i$
) and label (
 $y_i$
) corresponding to the text. This hate speech detection is a binary classification task, and the goal of the task is to maximize the value of the function
$y_i$
) corresponding to the text. This hate speech detection is a binary classification task, and the goal of the task is to maximize the value of the function
 \begin{equation} \textrm{argmax}_{\theta } \left(\Pi _{i=1}^p\left(P(y_i|t_i;\,\theta)\right)\right), \end{equation}
\begin{equation} \textrm{argmax}_{\theta } \left(\Pi _{i=1}^p\left(P(y_i|t_i;\,\theta)\right)\right), \end{equation}
where
 $t_i$
represents a text with an associated label
$t_i$
represents a text with an associated label
 $y_i$
, which is to be predicted.
$y_i$
, which is to be predicted.
 $\theta$
is the model parameter that needs to be optimized. The approach is to develop a classifier for a task where texts must be organized into two classes. First, two parts of datasets are there: one is training, and another one is test datasets. These two datasets aim to train the classifier on the training dataset and assess its performance on the test dataset. The model differentiates between the two classes by examining the processed text data. During the learning phase, the algorithm adjusts its internal settings based on the training data, improving its ability to make accurate predictions. These adjustments are driven by the differences between the two classes in the training data. The classifier becomes trained during the learning process, which can now identify the given text data class. This system is tested on new, unseen text to assure reliability.
$\theta$
is the model parameter that needs to be optimized. The approach is to develop a classifier for a task where texts must be organized into two classes. First, two parts of datasets are there: one is training, and another one is test datasets. These two datasets aim to train the classifier on the training dataset and assess its performance on the test dataset. The model differentiates between the two classes by examining the processed text data. During the learning phase, the algorithm adjusts its internal settings based on the training data, improving its ability to make accurate predictions. These adjustments are driven by the differences between the two classes in the training data. The classifier becomes trained during the learning process, which can now identify the given text data class. This system is tested on new, unseen text to assure reliability.
4.2 Preprocessing
Any deep learning or transformer model needs cleaned and noise-free data. So, preprocessing is necessary to enhance performance. Researchers use almost similar preprocessing approaches for the same category languages. Datasets include raw comments with punctuation, URLs, emojis, and unwanted characters. In most circumstances, the following actions are employed.
Normalization
Existing emojis removal, undesirable characters, and stop-words from sentences.
Punctuation removal
Punctuations are removed except “.”, “?” and “!” as these are considered delimiters to tokenize each sentence.
Label encoding
Labels (task_1) for HASOC-Hindi (2019), HASOC-Marathi (2021), HS-Assamese, and HS-Bodo are labeled as NOT and HOF. We encode these labels into a distinctive number. NOT is converted to 0 and HOF to 1, where we leave the HS-Bangla (2021) dataset as it is labeled with the numeral already.
We followed the steps mentioned above for HASOC-Marathi (2021), HS-Bangla (2021), HS-Assamese, and HS-Bodo datasets. We perform preprocessing strategies as mentioned in paper (Bashar and Nayak Reference Bashar and Nayak2020) for HASOC-Hindi (2019), like URL occurrence with xxurl, replacing person occurrence (e.g., @someone) with xxatp, source of modified retweet with xxrtm, source of not modified retweet with xxrtu, fixing the repeating characters (e.g., goooood), removed familiar invalid characters (e.g.,
 $\lt br= \gt$
,
$\lt br= \gt$
,
 $\lt unk \gt$
,
$\lt unk \gt$
,
 $@-@$
, etc.) and a lightweight stemmer for Hindi language (Ramanathan and Rao Reference Ramanathan and Rao2003) for stemming the words.
$@-@$
, etc.) and a lightweight stemmer for Hindi language (Ramanathan and Rao Reference Ramanathan and Rao2003) for stemming the words.
4.3 Transformer-based Language Models (TLMs)
4.3.1 Input representation
After basic preprocessing step our texts are
 $\{t_1, t_2, t_3,\ldots, t_i,\ldots t_p\}$
. Each word is then tokenized and three embeddings token, segment, and position embeddings are combined to obtain a fixed-length vector. For every model separate tokenizer is used, like BERT, RoBERTa, ALBERT, DistilBERT uses WordPiece (Wu et al. Reference Wu, Schuster, Chen, Le, Norouzi, Macherey, Krikun, Cao, Gao, Macherey, Klingner, Shah, Johnson, Liu, Kaiser, Gouws, Kato, Kudo, Kazawa, Stevens, Kurian, Patil, Wang, Young, Smith, Riesa, Rudnick, Vinyals, Corrado, Hughes and Dean2016), Byte Pair Encoding (Shibata et al. Reference Shibata, Kida, Fukamachi, Takeda, Shinohara, Shinohara and Arikawa1999), SentencePiece (Kudo and Richardson Reference Kudo and Richardson2018), and WordPiece correspondingly. Later,
$\{t_1, t_2, t_3,\ldots, t_i,\ldots t_p\}$
. Each word is then tokenized and three embeddings token, segment, and position embeddings are combined to obtain a fixed-length vector. For every model separate tokenizer is used, like BERT, RoBERTa, ALBERT, DistilBERT uses WordPiece (Wu et al. Reference Wu, Schuster, Chen, Le, Norouzi, Macherey, Krikun, Cao, Gao, Macherey, Klingner, Shah, Johnson, Liu, Kaiser, Gouws, Kato, Kudo, Kazawa, Stevens, Kurian, Patil, Wang, Young, Smith, Riesa, Rudnick, Vinyals, Corrado, Hughes and Dean2016), Byte Pair Encoding (Shibata et al. Reference Shibata, Kida, Fukamachi, Takeda, Shinohara, Shinohara and Arikawa1999), SentencePiece (Kudo and Richardson Reference Kudo and Richardson2018), and WordPiece correspondingly. Later,
 $[CLS]$
is added for classification, and
$[CLS]$
is added for classification, and
 $[SEP]$
separates input segments. Figure 3(a) shows the input representations for TLMs. So, the preprocessed text
$[SEP]$
separates input segments. Figure 3(a) shows the input representations for TLMs. So, the preprocessed text
 $t_i$
having
$t_i$
having
 $m$
words:
$m$
words:
 $t_i =\{w_{i,1}, w_{i,2}, w_{i,3},\ldots,w_{i,k},\ldots,w_{i,m}\}$
. Now, a word embedding layer, position embedding, and segment embedding convert each token into its vector representation.
$t_i =\{w_{i,1}, w_{i,2}, w_{i,3},\ldots,w_{i,k},\ldots,w_{i,m}\}$
. Now, a word embedding layer, position embedding, and segment embedding convert each token into its vector representation.
 \begin{equation} w_{i,k} = \{Word Embedding + Position Embedding + Segment Embedding\}, \end{equation}
\begin{equation} w_{i,k} = \{Word Embedding + Position Embedding + Segment Embedding\}, \end{equation}
4.3.2 Transformer
For our task, transformers play a vital role. So, a brief introduction to the transformer is needed. Vaswani et al. (Reference Vaswani, Shazeer, Parmar, Uszkoreit, Jones, Gomez, Kaiser and Polosukhin2017) represent transformers, a sequence-to-sequence architecture (Seq2Seq) is a type of neural network designed to transform a given sentence’s sequence of words into a different sequence. Seq2Seq models excel at translation tasks, converting a sequence of words from one language into another. These models comprise an encoder and a decoder. The Encoder transforms the input sequence into a higher-dimensional space (an n-dimensional vector).
In our task, hate speech detection, which is more similar to text classification, only uses a transformer encoder block. Figure 3(b) shows the transformer encoder block. The transformer models below (BERT, RoBERTa, ALBERT, DistilBERT, etc.) are trained as language models. These language models, like BERT, RoBERTa, etc., include two stages: (1) pre-training and (2) fine-tuning. The pre-training involves two self-supervised tasks; one is Masked Language Modeling (MLM), and the other is Next Sentence Prediction (NSP). MLM is to predict randomly masked input tokens, and NSP predicts whether two sentences are adjacent or not. In the pre-trained phase, these models have been trained extensively on vast quantities of unprocessed text using a self-supervised approach. Self-supervised learning involves the model calculating its objective based on input data, indicating that human labeling of data is not required. At this phase, while this model gains a statistical comprehension of the trained language, its practical utility for specific tasks is limited. To address this, the broad pre-trained model undergoes transfer learning. The model is refined in this phase using supervised techniques involving human-provided labels for a particular task. In our experiments, we use several existing pre-trained TLMs and fine-tune them for the specific task i.e., hate speech detection. During fine-tuning, one or more fully connected layers are added on top of the last transformer layer with the
 $softmax$
activation function. Figure 3(c) shows the fine-tuning part of the model, and at the final transformer layer, we include a linear layer with
$softmax$
activation function. Figure 3(c) shows the fine-tuning part of the model, and at the final transformer layer, we include a linear layer with
 $softmax$
.
$softmax$
.

Figure 3. Architecture of hate speech detection model which includes (a) input representation, (b) transformer encoder block, and (c) BERT model.
4.3.3 BERT
Google developed BERT, a transformer-based technique for NLP. BERT can generate embeddings with specific contexts. It generates vectors almost identical for synonyms but distinct when used in different contexts. During training, it learns the details from both sides of the word’s context. So, it is called a bidirectional model. We tested Hindi, Marathi, and Bangla-BERT datasets to compare monolingual and multilingual BERT.
-
1. m-BERT (Devlin et al. Reference Devlin, Chang, Lee and Toutanova2018) is prepared with Wikipedia content in 104 top languages, including Hindi, Bangla, and Marathi, utilizing a masked language modeling (MLM) objective using the largest Wikipedia as the training set.
-
2. MuRIL-BERT (Khanuja et al. Reference Khanuja, Bansal, Mehtani, Khosla, Dey, Gopalan, Margam, Aggarwal, Nagipogu, Dave, Gupta, Gali, Subramanian and Talukdar2021), MuRIL is a BERT model that has already been trained on 17 Indian languages and their transliterated counterparts, including monolingual segments and parallel segments.
-
3. NeuralSpaceHi-BERT (Jain et al. Reference Jain, Deshpande, Shridhar, Laumann and Dash2020), thanks to its extensive pre-training on the 3 GB monolingual OSCAR corpus made available by neuralspace-reverie, this is ready to use. Text classification, POS tagging, question answering, etc., were all fine-tuned.
-
4. Maha-BERT (Joshi Reference Joshi2022a) uses L3Cube-MahaCorpus and other publicly accessible Marathi monolingual datasets to fine-tune a multilingual BERT (bert-base-multilingual-cased) model.
-
5. Bangla-BERT (Sarker Reference Sarker2020) bangla-Bert-Base was pre-trained using OSCAR and the Bangla Wikipedia Dump Dataset with the help of MLM.
-
6. Assamese-BERT (Joshi Reference Joshi2023) is a monolingual BERT model trained on publicly available Assamese monolingual datasets.
4.3.4 RoBERTa
BERT can benefit from more time spent training on a large dataset. Using a character-level BPE (Byte Pair Encoding) tokenizer, RoBERTa, a self-supervised transformer model trained on raw texts, beats BERT by 4%-5% in natural language inference tasks. However, RoBERTa employs a byte-level BPE tokenizer, which takes advantage of a standard encoding format.
-
1. XLM-RoBERTa (base-sized model) (Conneau et al. Reference Conneau, Khandelwal, Goyal, Chaudhary, Wenzek, Guzmán, Grave, Ott, Zettlemoyer and Stoyanov2019) is a multilingual RoBERTa model that has been pre-trained on 2.5 TB of cleaned CommonCrawl data in 100 different languages. In contrast to XLM multilingual models, it does not rely on
 $lang$
tensors to identify the language being used and select it appropriately from the input ids.
$lang$
tensors to identify the language being used and select it appropriately from the input ids. -
2. Roberta-HindiFootnote m is RoBERTa transformer base model, which was pre-trained on a large Hindi corpus (a combination of MC4, OSCAR, and indic-nlp datasets) and released by flax-community.
-
3. Maha-RoBERTa (Joshi Reference Joshi2022b) is a multilingual RoBERTa (xlm-roberta-base) model fine-tuned on publicly available Marathi monolingual datasets and L3Cube-MahaCorpus.
-
4. RoBERTa-Base-Mr is a RoBERTa Marathi model, which was pre-trained on mr dataset of C4 (Colossal Clean Crawled Corpus) (Raffel et al. Reference Raffel, Shazeer, Roberts, Lee, Narang, Matena, Zhou, Li and Liu2019) multilingual dataset.

4.3.5 ALBERT
As a lightweight alternative to BERT for self-supervised learning, Google AI released ALBERT.
-
1. Indic-BERT (Kakwani et al. Reference Kakwani, Kunchukuttan, Golla, Gokul, Bhattacharyya, Khapra and Kumar2020) is a multilingual ALBERT model containing 12 major Indian languages (including Hindi, Marathi, Bangla, Assamese, English, Gujarati, Oriya, Punjabi, Tamil, Telugu, Kannada, and Malayalam) was recently released by Ai4Bharat. This model was trained on large-scale datasets.
-
2. Maha-ALBERT (Joshi Reference Joshi2022a) is a Marathi ALBERT model trained on L3Cube-MahaCorpus and Marathi monolingual datasets made available to the public.
4.3.6 DistilBERT
DistilBERT is a lightweight transformer model that is tiny, fast, and cheap, thanks to its training on the BERT base. This version of BERT has 40% fewer parameters and runs 60% faster than the previous version while retaining over 95% of its performance on the GLUE language understanding benchmark.
-
1. m-DistilBERT (Sanh et al. Reference Sanh, Debut, Chaumond and Wolf2019b) is trained using all 104 of Wikipedia’s language versions.
-
2. DistilBERTHiFootnote n , using OSCAR’s monolingual training dataset, this DistilBERT language model has already been pre-trained.
4.4 Experiments
Our main motive for all the experiments is to fine-tune the existing pre-trained TLMs models with Hindi, Marathi, Bangla, Assamese, and Bodo task-specific datasets. We performed three experiments multilingual, monolingual, and cross-lingual experiments. All three experiments and Forty-one sub-experiments have been performed with different pre-trained models.

Figure 4. Experiments of hate speech detection model which includes (a) Multilingual experiment, (b) Monolingual experiment, and (c) Cross-lingual experiment.
4.4.1 Multilingual experiment
This is an experiment where existing multilingual pre-trained TLMs are fine-tuned on task-specific datasets. In our case, we fine-tune existing multilingual pre-trained TLMs like m-BERT, MuRIL-BERT, XLM-RoBERTa, Indic-BERT, m-DistilBERT on Hindi, Marathi, Bangla, Assamese, and Bodo datasets. Note that, existing multilingual pre-trained TLMs are not trained on the Bodo dataset previously. Figure 4(a) shows a very basic overview of multilingual experiments with an example.
4.4.2 Monolingual experiment
Here, existing monolingual pre-trained TLMs are fine-tuned on task-specific datasets where pre-trained models and task-specific datasets belong to the same language. In our case, we fine-tune existing monolingual Hindi pre-trained TLMs like NeuralSpaceHi-BERT, Roberta-Hindi, and DistilBERTHi on the Hindi dataset. Existing monolingual Marathi pre-trained TLMs like Maha-BERT, Maha-RoBERTa, RoBERTa-Base-Mr, and Maha-AlBERT are fine-tuned on the Marathi dataset. Existing monolingual Bangla pre-trained TLM like Bangla-BERT is fine-tuned on the Bangla dataset. Lastly, existing monolingual Assamese pre-trained TLM like Assamese-BERT is fine-tuned on the Assamese dataset. Note that no monolingual Bodo pre-trained BERT model is available. So, we skip this experiment for the Bodo dataset only. Figure 4(b) shows a monolingual experiment with an example.
4.4.3 Cross-lingual experiment
In this experiment, existing monolingual pre-trained TLMs are fine-tuned to task-specific datasets where pre-trained models and task-specific datasets belong to different languages. We are considering the same language family and the same script for this experiment (Hindi—Marathi and Assamese—Bangla). In the case of Hindi and Marathi, both belong to the same Indo-Aryan language family and share the same script, i.e., Devnagri. Assamese and Bangla belong to the same language family, i.e., Indo-Aryan language family, and share almost the same script, i.e., Bangla-Assamese script, except for two letters. In the case of Bodo, which belongs to the Sino-Tibetan language family but shares the same script as Hindi and Marathi, we did the cross-lingual experiment on Hindi, Marathi, and Bodo too. For example, We fine-tune NeuralSpaceHi-BERT for Marathi and Bodo data, whereas we fine-tune Bangla-BERT for the Assamese language and Assamese-BERT for the Bangla data. Figure 4(c) shows a Cross-lingual experiment with an example.
4.5 Experimental setup
We execute all experiments with the same hyperparameter combination (Table 3) due to memory and GPU issues and pick the best result. We use Python-based libraries like Huggingface, PyTorch, and TensorFlowFootnote o at different stages of our implementations. We utilize the GPU of Google Colab for all our experiments.
Table 3. Hyperparameters for all the experiments

5. Result and analysis
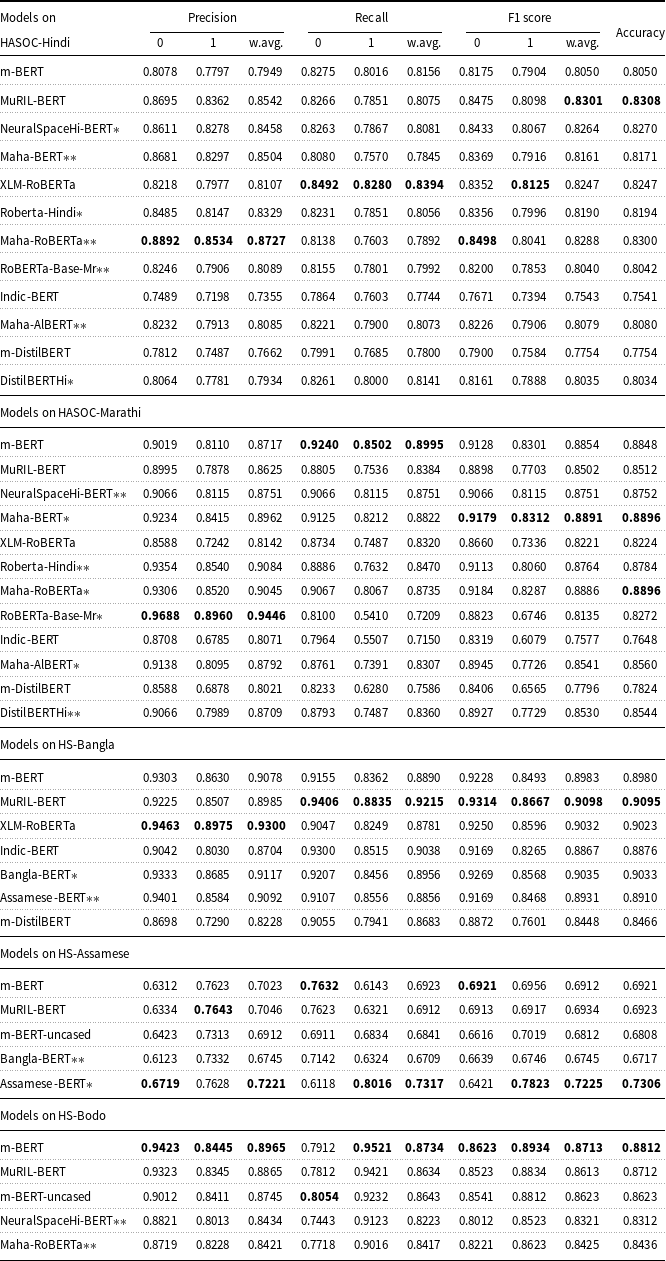
A total of forty-one models are ready, and now, an evaluation of their performance is required. We calculate precision, recall, and weighted F1 scores on the test set of Hindi, Marathi, Bangla, Assamese, and Bodo datasets. Table 4 represents the results of TLMs trained on the HASOC-Hindi (2019), HASOC-Marathi (2021), HS-Bangla (2021), HS-Assamese and HS-Bodo datasets, where simple, star (*), and double stars (**) indicate multilingual, monolingual, and cross-lingual models correspondingly. We offer both a weighted F1 score and an accuracy score for model evaluation due to the dominant issue of imbalanced class distribution in classification problems. So, a weighted F1 score is a more suitable metric to believe for the imbalanced class distribution scenario.
Table 4. Calculations of precision, recall, F1 score, and accuracy of various TLMs on HASOC-Hindi (2019), HASOC-Marathi (2021), HS-Bangla (2021), HS-Assamese, and HS-Bodo datasets, respectively
5.1 Evaluation metrics
We use two class precisions (
 $P_{NOT}$
,
$P_{NOT}$
,
 $P_{HOF}$
), recalls (
$P_{HOF}$
), recalls (
 $R_{NOT}$
,
$R_{NOT}$
,
 $R_{HOF}$
), F1 scores (
$R_{HOF}$
), F1 scores (
 $F1_{NOT}$
,
$F1_{NOT}$
,
 $F1_{HOF}$
) to evaluate the models then calculate weighted precision (
$F1_{HOF}$
) to evaluate the models then calculate weighted precision (
 $W_P$
), recall (
$W_P$
), recall (
 $W_R$
), and F1 score (
$W_R$
), and F1 score (
 $W_{F1}$
) here. At last, we calculate
$W_{F1}$
) here. At last, we calculate
 $Accuracy$
.
$Accuracy$
.
 \begin{equation} P_{NOT} = \frac{True_{NOT}}{True_{NOT} + False_{HOF}} \end{equation}
\begin{equation} P_{NOT} = \frac{True_{NOT}}{True_{NOT} + False_{HOF}} \end{equation}
 \begin{equation} P_{HOF} = \frac{True_{HOF}}{True_{HOF} + False_{HOF}} \end{equation}
\begin{equation} P_{HOF} = \frac{True_{HOF}}{True_{HOF} + False_{HOF}} \end{equation}
 \begin{equation} R_{NOT} = \frac{True_{NOT}}{True_{NOT} + False_{NOT}} \end{equation}
\begin{equation} R_{NOT} = \frac{True_{NOT}}{True_{NOT} + False_{NOT}} \end{equation}
 \begin{equation} R_{HOF} = \frac{True_{HOF}}{True_{HOF} + False_{NOT}} \end{equation}
\begin{equation} R_{HOF} = \frac{True_{HOF}}{True_{HOF} + False_{NOT}} \end{equation}
 \begin{equation} F1_{NOT} = 2*\frac{P_{NOT}*R_{NOT}}{P_{NOT}+R_{NOT}} \end{equation}
\begin{equation} F1_{NOT} = 2*\frac{P_{NOT}*R_{NOT}}{P_{NOT}+R_{NOT}} \end{equation}
 \begin{equation} F1_{HOF} = 2*\frac{P_{HOF}*R_{HOF}}{P_{HOF}+R_{HOF}} \end{equation}
\begin{equation} F1_{HOF} = 2*\frac{P_{HOF}*R_{HOF}}{P_{HOF}+R_{HOF}} \end{equation}
 \begin{equation} W_P = \frac{P_{NOT}*T_{NOT} + P_{HOF}*T_{HOF}}{T_{NOT} + T_{HOF}} \end{equation}
\begin{equation} W_P = \frac{P_{NOT}*T_{NOT} + P_{HOF}*T_{HOF}}{T_{NOT} + T_{HOF}} \end{equation}
 \begin{equation} W_R = \frac{R_{NOT}*T_{NOT} + R_{HOF}*T_{HOF}}{T_{NOT} + T_{HOF}} \end{equation}
\begin{equation} W_R = \frac{R_{NOT}*T_{NOT} + R_{HOF}*T_{HOF}}{T_{NOT} + T_{HOF}} \end{equation}
 \begin{equation} W_{F1} = \frac{F1_{NOT}*T_{NOT} + F1_{HOF}*T_{HOF}}{T_{NOT} + T_{HOF}} \end{equation}
\begin{equation} W_{F1} = \frac{F1_{NOT}*T_{NOT} + F1_{HOF}*T_{HOF}}{T_{NOT} + T_{HOF}} \end{equation}
 \begin{equation} Accuracy = \frac{True_{NOT}+True_{HOF}}{T_{NOT} + T_{HOF}} \end{equation}
\begin{equation} Accuracy = \frac{True_{NOT}+True_{HOF}}{T_{NOT} + T_{HOF}} \end{equation}
where
 $True_{NOT}$
= True-negative (model predicted the texts as NOT, and the actual value of the same is also NOT),
$True_{NOT}$
= True-negative (model predicted the texts as NOT, and the actual value of the same is also NOT),
 $True_{HOF}$
= True-positive (model predicted the texts as HOF, and the actual value of the same is also HOF),
$True_{HOF}$
= True-positive (model predicted the texts as HOF, and the actual value of the same is also HOF),
 $False_{NOT}$
= False-negative (model predicted the texts as NOT, but the true value of the same is HOF),
$False_{NOT}$
= False-negative (model predicted the texts as NOT, but the true value of the same is HOF),
 $False_{HOF}$
= False-positive (model predicted the texts as HOF, but the true value of the same is NOT),
$False_{HOF}$
= False-positive (model predicted the texts as HOF, but the true value of the same is NOT),
 $P_{NOT}$
= Precision of NOT class,
$P_{NOT}$
= Precision of NOT class,
 $P_{HOF}$
= Precision of HOF class,
$P_{HOF}$
= Precision of HOF class,
 $R_{NOT}$
= Recall of NOT class,
$R_{NOT}$
= Recall of NOT class,
 $R_{HOF}$
= Recall of HOF class,
$R_{HOF}$
= Recall of HOF class,
 $F1_{NOT}$
= F1 score of NOT class,
$F1_{NOT}$
= F1 score of NOT class,
 $F1_{HOF}$
= F1 score of HOF class,
$F1_{HOF}$
= F1 score of HOF class,
 $T_{NOT}$
= The total number of NOT class text present in test set,
$T_{NOT}$
= The total number of NOT class text present in test set,
 $T_{HOF}$
= The total number of HOF class text present in test set.
$T_{HOF}$
= The total number of HOF class text present in test set.
5.2 Best TLMs per dataset
For the Hindi dataset, the weighted F1 score of four models MuRIL-BERT, Maha-RoBERTa, NeuralSpaceHi-BERT, and XLM-RoBERTa are very close. Maha-BERT, Maha-RoBERTa, m-BERT, and Roberta-Hindi scored at the top of the Marathi dataset. MuRIL-BERT, Bangla-BERT, XLM-RoBERTa, and m-BERT models are the scoring models for the Bangla dataset. For the Assamese dataset, the Assamese-BERT monolingual model scores are at the top. The m-BERT model performs best on the Bodo dataset, and MuRIL-BERT scores well, too. Figure 5 shows the confusion matrix of the best models on five datasets separately.
5.3 Multilingual models vs monolingual models
On the Hindi dataset, multilingual models like MuRIL-BERT and XLM-RoBERTa perform better, but the monolingual model NeuralSpaceHi-BERT also gives tough competition. We can conclude that multilingual models perform well, but the difference in performance between monolingual and multilingual models is negligible. Maha-BERT and Maha-RoBERTa models provide the highest weighted F1 score for the Marathi dataset, and m-BERT also performs well, whereas MuRIL-BERT scores a little less. We use two monolingual pre-trained models for Bangla, i.e., Bangla-BERT and Assamese-BERT; it performs very well, but the MuRIL-BERT wins marginally. Indic-BERT and m-DistilBERT models’ performance is significantly less on all datasets than in other models. Therefore, developing better resources for the Hindi and Bangla languages is necessary, as language-specific fine-tuning does not guarantee the best performance. For the Assamese dataset, we observe that Assamese-BERT gives the top result. We fine-tune NeuralSpaceHi-BERT and Maha-RoBERTa with the Bodo dataset, and both of the models provide a little less result than the multilingual models. For the Bodo dataset, there are no existing monolingual models available, so we tried only two experiments, i.e., fine-tuning with multilingual models and cross-lingual experiments.
5.4 Cross-lingual experiments
The purpose of this experiment is to open a door for researchers who are dealing with low-resourced languages. During the cross-lingual experiments, we consider the Marathi models on the Hindi dataset and vice versa, as both languages share the Devanagari script. Maha-RoBERTa performs well on the Hindi dataset, and Maha-BERT, RoBERTa-Base-Mr, and Maha-AlBERT also score sufficiently. NeuralSpaceHi-BERT and Roberta-Hindi perform well on the Marathi dataset. Still, surprisingly, DistilBERTHi performs poorly on the Hindi dataset rather well on the Marathi dataset, though performance also depends on the amount and diversity of data. We also perform cross-lingual experiments on the Bangla and Assamese datasets, as they both share the same script. Surprisingly, Bangla-BERT on Assamese data and Assamese-BERT on the Bangla dataset perform well. In the Bodo dataset, we tried to fine-tune NeuralSpaceHi-BERT and Maha-RoBERTa, which is one kind of cross-lingual experiment. This kind of transfer learning also works well in cross-lingual experiments.

Figure 5. Confusion matrix of best models such as MuRIL-BERT for HASOC-Hindi (2019) (a), Maha-BERT for HASOC-Marathi (2021) (b), MuRIL-BERT for HS-Bangla (2021) (c), Assamese-BERT for HS-Assamese (d) and m-BERT for HS-Bodo (e).
5.5 How models gather knowledge!
All our experiments, like monolingual, multilingual, and cross-lingual, are based on transfer learning. We are using pre-trained TLMs and fine-tuning those models with our tagged hate dataset. In Section 4.3, we explain that pre-trained TLMs are already trained on huge amounts of multilingual raw data or only monolingual data in a self-supervised manner, and then we fine-tuned those existing pre-trained models with our small tagged datasets for a particular task. Here, TLMs need vast amounts of data for scratch training where low-resource languages suffer; then, we have to use existing pre-trained models. So, from a pre-trained model to a fine-tuning model, we are actually transferring the language-related knowledge. According to Rogers et al. (Reference Rogers, Kovaleva and Rumshisky2020), TLMs gather syntactic knowledge, semantic knowledge, and world knowledge during the training procedure. Syntactic knowledge (Berwick Reference Berwick1985) is about understanding the rules and structures that help to arrange the words and phrases to build grammatically correct sentences in a particular language. Semantic knowledge (Patterson, Nestor, and Rogers Reference Patterson, Nestor and Rogers2007) is all about understanding the meaning of words, phrases, and sentences as well as the relationships among them. It also gathers information on similar or opposite words, contextual understanding, different senses of words, etc. World knowledge (Hagoort et al. Reference Hagoort, Hald, Bastiaansen and Petersson2004) includes information about the history, country, society, common sense, culture, scientific principles, geographical, geopolitical, etc. TLMs gather all that information in some vector components via embedding for each word/ token. TLMs perform word embedding using vectors of length 768, which are contextual representations of words. It not only retrieves the important features but also captures the context information in a bidirectional manner of a word in a sentence. Hence, some components of the embedding vector store the features, and some combined components preserve the context information.
If pre-trained multilingual or monolingual models are used for fine-tuning with the same language data, then it is obvious that the model is learning the same language patterns, features, and structure because of the same vocabulary and syntax. Now, the existing pre-trained model is in one language and fine-tuned in another language, i.e., our cross-lingual experiment. In such cases, we are considering either the same language family (Hindi—Marathi and Assamese—Bangla) or the same script (Hindi—Marathi—Bodo and Assamese—Bangla). Each pair for the same language family shares linguistic features, patterns, and structures. The hateful language might share a similar kind of linguistic feature, and it is captured during the fine-tuning model. If it is so, then it will behave almost similarly to the other language of the same language family and hence perform well.
6. Conclusion
In major languages like English, significant work is done. A little work has been done on the Indian languages, like Hindi, Bangla, Marathi, Tamil, Malayalam, etc. In short, we conclude this work: (i) We explore variants of language models based on transformers in Indic languages. (ii) Two hate speech datasets have been created in the Assamese and Bodo languages named HS-Assamese and HS-Bodo. (iii) A comparison has been drawn on monolingual and multilingual language model which uses transformers for hate speech detection data like HASOC-Hindi, HASOC-Marathi, HS-Bangla, HS-Assamese, and HS-Bodo datasets. (iv) Cross-lingual experiments have been done successfully on the mentioned language pairs like Hindi-Marathi, Hindi-Bodo, Marathi-Bodo, and Bangla-Assamese. We can witness that monolingual training only sometimes ensures superior performance only if raw data are sufficient while scratch training is done. Multilingual models performed best on the Hindi, Bangla, and Bodo datasets, whereas monolingual models were superior on the Marathi and Assamese datasets. We also observe that the “0” class precision, recall, and F1 score is slightly higher than the “1” class, indicating the data imbalance. So, we can apply SMOTE (Bowyer et al. Reference Bowyer, Chawla, Hall and Kegelmeyer2011), ADASYN (He et al. Reference He, Bai, Garcia and Li2008), or data augmentation (techniques to increase the amount of data) (Nozza Reference Nozza2022) to handle data imbalance in the future. Research on hate speech affects both technical and socio-linguistic concerns, such as freedom of speech and legislation on both the national and international levels. We are preparing more new datasets and conducting experiments on the dataset, representing the first attempt at detecting hate speech in Northeast languages. We present a dataset of annotated anti-Bodo discourse. In the future, we intend to add more data to the dataset and train the entire pre-trained model on our dataset. Hopefully, researchers will find this work and dataset helpful and may imply a cross-lingual effect on every area of NLP.










 Open access
Open access