



1. Introduction
With the increase of research on the linguistic properties of heritage languages over the past three decades, one consensus emerging from these studies is that ‘morphology’, broadly construed, represents one of the most vulnerable domains of grammar for change and attrition (Putnam et al. Reference Putnam, Schwarz, Hoffman, Montrul and Polinsky2021). This larger point notwithstanding, there are subdomains of morphology that have proved to be highly resistant to change, similar to what is claimed in language contact with respect to scales of borrowability. This stability has been observed in the domain of verbal inflectional morphology (Thomason Reference Thomason2001:70–71; Matras Reference Matras2009:Ch.8.2.2; Gardani et al. Reference Gardani, Arkadiev and Amiridze2015). The primary focus of this article seeks to better understand this apparent paradox in the stability of heritage language morphology in a modular architecture of grammar. We pursue a detailed and explicit account of the underlying nature of exponency to model shared and competing representations, with North American Norwegian–English bilinguals as a case study, that explains the relative stability of Norwegian tense morphology in a moribund heritage language context.
There have of course been competing, rational hypotheses put forward to account for this observed asymmetry. In discussing the distinctions existing within her 4-M model of language contact with respect to verbal inflectional morphology, Myers-Scotton (Reference Myers-Scotton2002:Ch.3.4) distinguishes between early system morphemes and late system morphemes, with the former being non-thematic and determined mostly by semantic means. In contrast, late system morphemes require grammatical (i.e. syntactic) information based on information in an extended projection.Footnote 1 More recently, Polinsky (Reference Polinsky2018:Ch.5) alludes to the observation that within the domain of verbal morphosyntax, tense has been argued to show less vulnerability when compared with other attributes such as aspect in languages in which both categories realize distinct exponency. She appeals to the notion of structurally salient elements of grammar being most resistant to (radical) morphological change when they are associated with the topmost projection (bearing meaningful content) of the verbal projection.
One of the fundamental problems we encounter in this literature is arriving at a clear definition of what various linguists define morphology to be (and, in contrast, not to be). These issues are part and parcel the same faced by those who adopt late-insertion, realizational approaches to the lexicon–morphology–phonology interface (Embick & Noyer Reference Embick, Noyer, Ramchand and Reiss2007, Borer Reference Borer2013, Baunaz & Lander Reference Baunaz, Lander, Lena Baunaz, Haegeman and Lander2018). As we explain throughout this article, approaches such as these aid us in making progress towards understanding the ‘depths of morphology’, i.e. the various levels of structural interactions that broadly fall within the traditional bandwidth of ‘morphology’ and how one goes about establishing exactly how ‘allomorphy’ should be conceptualized. At the conclusion of this paper, we provide additional arguments as to how this proposal can potentially advance our understanding of the syntax–morphology–phonology interface in heritage bilingualism (Putnam et al. Reference Putnam, Schwarz, Hoffman, Montrul and Polinsky2021, Fisher et al. Reference Fisher, David Natvig, Putnam and Schuhmann2022, Natvig et al. Reference Natvig, Pretorius, Putnam and Carlsonforthcoming).
In the remainder of this article, we home in on tense morphology in North American Norwegian (NAmNo), here based on varieties from Biri and Southern Gudbrandsdal (see Section 2.1), with a particular focus on simple past and perfective tense exponency. Here we seek to provide a detailed systematic treatment of the overwhelming consistency within this paradigm, guided by the following central research question:
How do we best conceptualize and explain allomorphy within a (heritage) bilingual grammar with competing syntactic and phonological representations?
We openly acknowledge that answering this question requires a more grounded and precise definition of ‘allomorphy’ proper. In the pages that follow, we make the case for a bifurcated distinction of syntactically conditioned and phonologically conditioned allomorphy. With respect to the phonologically conditioned allomorphy we follow the development of events, features, and precedence (EFP) phonology (Raimy Reference Raimy2000, Papillon Reference Papillon2020, Idsardi Reference Idsardi2022). Morphological alternations that cannot be made in terms of phonological statements, however, are based on abstract grammatical distinctions modeled in the syntax. Returning to our empirical investigation of the realization of tense in North American Norwegian, we provide an account of how units of syntactic and phonological structure compete and are combined in hybrid representations.
The remainder of this article adopts the following structure. In Section 2 we lay out the core empirical and theoretical assumptions associated with our analysis. We adopt a spanning-based approach to syntactic structure (Starke Reference Starke and Picalo2014, Blix Reference Blix2021, Fisher et al. Reference Fisher, David Natvig, Putnam and Schuhmann2022) that interfaces with EFP phonology principles. We turn to the morphosyntax of tense in Section 3, where we establish our representational assumptions that anchor our analysis of Norwegian and English patterns throughout the remainder of this article. We present evidence for overwhelming stability in the expression of tense in NAmNo in Section 4. We discuss the rationale behind these patterns and return to our guiding research question introduced above in Section 5, demonstrating how our spanning/EFP-based treatment of exponency provides a straightforward account for this systemic stability. In Section 6 we conclude and discuss avenues for further investigation.
2. Empirical and theoretical preliminaries
In this section we outline our empirical focus and present our position on the nature of syntactic and phonological representations, with a particular eye to their organization in an integrated bi/multilingual grammar. We first present relevant past tense patterns of the Biri and Southern Gudbrandsdal Norwegian, which are the source varieties of the NAmNo speakers we investigate. We then discuss our understanding of the role of syntactic structure for modeling competition between phonological forms, specifically related to the size of syntactic structure, or spans. Following this, we present our perspective on phonological representations. We take a somewhat unconventional approach in the phonological literature – precedence phonology (Raimy Reference Raimy2000) – although it is a perspective that is gaining traction in recent work (Papillon Reference Papillon2020, Idsardi Reference Idsardi2022). Finally, we outline our view on the nature of linguistic representations among bi/multilinguals, specifically in favor of integrated grammatical architecture.
2.1 Past inflection in Biri and Southern Gudbrandsdal Norwegian
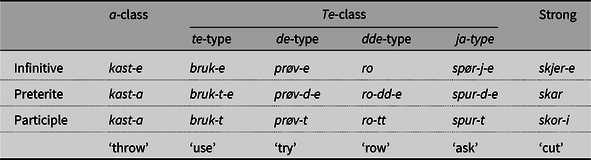
In order to restrict our focus to a relatively cohesive community of post-language shift NAmNo speakers – i.e. in a moribund heritage language context, where English is undoubtedly the primary mode of communication – we focus on individuals from the area surrounding Coon Valley and Westby, Wisconsin, and recorded between 2010 and 2012. Although there are many varieties of Norwegian spoken in North America, we use North American Norwegian (NAmNo) here to refer to this particular group. In Coon Valley and Westby, the Southern Gudbrandsdal and Biri dialects have been the principle varieties spoken since it was settled. They are both Eastern Norwegian dialects from adjoining areas in Norway. In accordance with Venås (Reference Venås1967, Reference Venås1974) and Skjekkeland (Reference Skjekkeland1997), we assume the general pattern for verbs in the Norwegian varieties spoken in Westby and Coon Valley presented in Table 1.
Table 1. Idealized inflectional system for NAmNo verb classes

Based on inflectional patterns, i.e. suffix type and the presence or absence of stem alternations, verbs are divided into two classes of ‘weak’ verbs and one class of ‘strong’ verbs. Weak verbs are inflected for past tense via suffixation: either -a or a coronal suffix. We follow Lykke (Reference Lykke2020) and refer to these respectively as a-class and Te-class, according to their preterite forms. The Te-class verbs are further divided into four subtypes, three determined by the realization of the coronal (as t, d, or dd, the latter indicating vowel shortening) and one with an additional stem-vowel change, which we call ja-type.Footnote 2 Finally, the strong verbs also undergo stem-vowel change in the past tenses, but they lack an independent suffix in the preterite. These alternations are reflexes of Indo-European ablaut, with subsequent changes throughout the history of Germanic. We elaborate on the syntactic and phonological representations of these classes and types, as well as preterite and perfect distinctions, in Section 3.1.
Two notable differences between these dialects concern the a-class verbs and the suffix of past participles for strong verbs. First, compared to Southern Gudbrandsdal, the Biri dialect has a higher degree of syncretism in the a-class paradigm, with -e as a form of the past tenses (preterite and participle) in addition to the infinitive (Venås Reference Venås1974, Skjekkeland Reference Skjekkeland1997). Analyses of the 1942 Norwegian of Coon Valley and Westby demonstrate a tendency for forms with -a to spread to speakers with a background from Biri (Eide & Hjelde Reference Eide, Hjelde, Richard Page and Putnam2015, Lykke Reference Lykke, Sippola and Peterson2022). For our purposes, Coon Valley and Westby constitute a single bidialectal and bilingual speech community. Both dialect and language contact therefore result in a local pattern of variation in the surface implementation of the -a suffix as [ɑ], [ϵ], or [ə]. No speaker has a system with a categorical -e in the past, and its use does not closely align with the ancestral dialect of the speakers. Overall, the distribution of forms we find conforms to the similar trends described by Lykke (Reference Lykke2020:191).
The second dialectal difference relates to the realization of the suffix in the past participle of strong verbs, what we consider to be -i (see Table 1). Although this is the form for all relevant participles in the Biri dialect, alternation between -i and -e has been reported for South Gudbrandsdal (Venås Reference Venås1967:428), with -e raising to -i following a high vowel in the stem (Skjekkeland Reference Skjekkeland1997:66). Again, we view this as a dialectal difference in the production of the presence vs. absence of a predictable height assimilation (itself worthy of further investigation in the view we develop below) and not in syntactic representations that define an alternation between two exponents (see Section 3.1). Keeping in mind the system presented in Table 1, we now turn to a discussion of the core theoretical tools we use to analyze the syntactic and phonological contributions to these alternations.
2.2 Syntactic structure and spanning
In order to properly establish the connection between sound and structure, we start our proposal by laying out some of the necessary background of our view of syntax. We adopt a late-insertion, realizational approach to morphosyntax according to which exponency is conditioned by syntactic structure. In principle, the key elements of our approach to phonological forms as precedence structures (Raimy Reference Raimy2000, Papillon Reference Papillon2020, Idsardi Reference Idsardi2022) are amendable to different versions of late-insertion models (Embick & Noyer Reference Embick, Noyer, Ramchand and Reiss2007, Starke Reference Starke2009, Borer Reference Borer2013, Baunaz & Lander Reference Baunaz, Lander, Lena Baunaz, Haegeman and Lander2018). The pre-syntactic lexicon contains nothing more than (unorganized) synsem-features and non-decomposable
 $\sqrt {{\rm{roots}}} $
. Each synsem-feature is associated with a syntactic head, resulting in a one feature – one head (OFOH) hierarchy (Kayne Reference Kayne2005, Cinque & Rizzi Reference Cinque, Rizzi and Moscati2008, Putnam Reference Putnam, Guijarro Fuentes and Suárez-Gómez2020b). The post-syntactic structures created through the course of the derivation consist of lexical items, which pair sound, form, and meaning. The ‘phonological form’ is minimally composed on the units of syntactic structure associated with phonological exponents. These lexical items are well-formed syntactic expressions of varying sizes (Starke Reference Starke and Picalo2014), with all features being hierarchically organized in tree structures. To illustrate these core architectural principles, consider the tree in (1).
$\sqrt {{\rm{roots}}} $
. Each synsem-feature is associated with a syntactic head, resulting in a one feature – one head (OFOH) hierarchy (Kayne Reference Kayne2005, Cinque & Rizzi Reference Cinque, Rizzi and Moscati2008, Putnam Reference Putnam, Guijarro Fuentes and Suárez-Gómez2020b). The post-syntactic structures created through the course of the derivation consist of lexical items, which pair sound, form, and meaning. The ‘phonological form’ is minimally composed on the units of syntactic structure associated with phonological exponents. These lexical items are well-formed syntactic expressions of varying sizes (Starke Reference Starke and Picalo2014), with all features being hierarchically organized in tree structures. To illustrate these core architectural principles, consider the tree in (1).

Each of the features – F1, F2, Fn, and so on – represents a unique feature that is realized in the sequence of function heads as a unique head (in line with the OFOH hierarchy).Footnote 3 The heads present in the syntax can combine in unique and informative ways in smaller tree structures to pair with semantic and phonological information. The differing size and shape of these licit syntactic structures are stored in the post-syntactic lexicon in tandem with components of sound and meaning to constitute ‘lexical items’.
There are two core principles that guide the lexicalization process in our late-insertion model. The first is known as the Exhaustive Lexicalization Principle (Fábregas Reference Fábregas2007, Fábregas & Putnam Reference Fábregas and Putnam2020), which avoids stranding features in syntactic structure that are not lexicalized in a licit syntactic configuration.

Adopting the Exhaustive Lexicalization Principle in (2) is grounded in the assumption that syntactic structures identified as ‘lexical items’ post-syntactically typically contain more than one singleton feature, hence they target larger domains of structure. For our purposes here, we adopt spans as a unified collection of contiguous formal features that mediate said features between exponency. The concept of the span has been defined in various ways (e.g. Svenonius Reference Svenonius, Asatryan, Song and Whitmal2020, Blix Reference Blix2021, Julien Reference Julien2021), and we adopt in our approach the definition in (3) (from Blix Reference Blix2021:7):

The second principle worth mentioning here is the lexicalization algorithm that guides lexical insertion, namely the Superset Principle:Footnote 4

The Superset Principle restricts any pending competition that may exist between multiple candidate forms vying for lexical insertion. The Superset Principle – acting in tandem with the Exhaustive Lexicalization Principle – ensures that the syntactic structure containing the least amount of superfluous features is recognized as the best fit for mapping to exponency. To demonstrate the logic behind these principles, take for example regular (stor ‘large’) and irregular (lit- ‘little’) Norwegian adjective inflection for agreement with plural, definite, and definite plural nouns. These are demonstrated with trees in (5) and spell-out combinations in (6); note that the line connecting [def] and [pl] in (5) indicates a span of these two features.


Example (6) demonstrates that, for regular adjectives, the suffix {e} spells out agreement for both [pl] and [def] features independently and in combination. Following the Superset Principle, this means that the stored lexical information for {e} contains both of these features, and will be inserted in contexts where either or both are generated. For
 $\sqrt{\rm{lit}}$
, however, agreement for number and definiteness is suppletive: lille spells out only the feature [def], whereas små spells out both features, just like {e} for the regular class. This is because when both [def] and [pl] are generated, the two available options do not occur simultaneously (as in *små-lille). Rather, små is the best match for this syntactic structure. The same is true for plural indefinite contexts, i.e. a lack of [def] in the structure, since små spells out [pl] as well. Because the suppletive forms for lit and the {e} for stor are root- or class-specific, they do not directly compete for insertion. This will be relevant to our discussion of verbs in Section 3.1, and we assume that it will apply to other word classes as well.
$\sqrt{\rm{lit}}$
, however, agreement for number and definiteness is suppletive: lille spells out only the feature [def], whereas små spells out both features, just like {e} for the regular class. This is because when both [def] and [pl] are generated, the two available options do not occur simultaneously (as in *små-lille). Rather, små is the best match for this syntactic structure. The same is true for plural indefinite contexts, i.e. a lack of [def] in the structure, since små spells out [pl] as well. Because the suppletive forms for lit and the {e} for stor are root- or class-specific, they do not directly compete for insertion. This will be relevant to our discussion of verbs in Section 3.1, and we assume that it will apply to other word classes as well.
2.3 Phonological representations: events, features, and precedence
As a default, we assume that syntactic and phonological allomorphy is determined by means of syntactic configurations (see e.g. Kalin Reference Kalin2022 for a summary of this perspective). This point notwithstanding, here we clarify and delineate the specific roles of syntax and phonology proper, showing that when allomorphy is phonologically predictable, ‘phonological’ operations are at play, and when this is not the case, syntax holds sway. In this subsection we outline our perspective on phonological representations, particularly the content of distinctive features and how features and phonemes are organized in time. This framework falls under a broader set of approaches that operationalize precedence relationships between phonological constituents (Raimy Reference Raimy2000, Papillon Reference Papillon2020, Idsardi Reference Idsardi2022).
Before going into detail on the role of precedence in our analysis, we first discuss features. We adopt a ‘laryngeal realist’ approach (Honeybone Reference Honeybone, Carr, Durand and Ewen2005) that views a direct connection between phonologically active properties and representations. Features that are active in phonological processes mark the relevant phoneme(s). Therefore we look to the directionality of laryngeal assimilations to determine whether we should consider aspiration or voicing as the relevant contrast between t and d. For Norwegian, as well as for most of Germanic (Iverson & Salmons Reference Iverson and Salmons1995, Allen Reference Allen2016, Salmons Reference Salmons, Putnam and Richard Page2020), the so-called ‘voiceless’ or fortis consonants are active, spreading their ‘voicelessness’ to the inactive ‘voiced’ consonants in relevant environments, as in trygg [thɾ̥ʏɡ] ‘safe (m.sg/f.sg)’ vs. trygt [thɾ̥ʏkt] ‘safe-n.sg’ (cf. *[thɾ̥ʏɡd]).Footnote
5
Fortis consonants are aspirated initially and may induce both progressive and regressive sonorant devoicing (Kristoffersen Reference Kristoffersen2000, Allen Reference Allen2016). Furthermore, there is no evidence that the feature [voice] has any active role in assimilatory processes in Norwegian. These facts lead us to posit [spread] (glottis) as the phonologically relevant feature that distinguishes, for example,
 $p,t,k$
from the laryngeally unspecified, or phonologically
$p,t,k$
from the laryngeally unspecified, or phonologically
 $\emptyset $
, phonemes
$\emptyset $
, phonemes
 $b,d,g$
(see Raimy Reference Raimy, Bendjaballah, Tifrit and Voeltzel2021 for a discussion of various types of ‘zero’ specification within phonological representations). We therefore distinguish the fortis phonemes written
$b,d,g$
(see Raimy Reference Raimy, Bendjaballah, Tifrit and Voeltzel2021 for a discussion of various types of ‘zero’ specification within phonological representations). We therefore distinguish the fortis phonemes written
 $p,t,k$
as aspirated /ph, th, kh/ from plain, voiceless /p, t, k/, which are written
$p,t,k$
as aspirated /ph, th, kh/ from plain, voiceless /p, t, k/, which are written
 $b,d,g$
. Although the latter may be fully voiced in surface forms ([b, d, ɡ]), we are concerned with their distinctive features rather than their phonetic implementations, which deserve their own treatment.
$b,d,g$
. Although the latter may be fully voiced in surface forms ([b, d, ɡ]), we are concerned with their distinctive features rather than their phonetic implementations, which deserve their own treatment.
Our second concern relates to a fundamental issue for understanding the phonological component of the grammar: the relationship between segments in a multiphonemic representation. It is common to assume, and operationalize, phonological representations as strings, such that the linear order of sounds in speech is fully specified. A different view is that phonology deals in precedence relationships (Raimy Reference Raimy2000, Papillon Reference Papillon2020). This position holds that the relative order of phonological representations is made explicit through directed graphs, here as arrows, that specify an ordered relationship between pairs of constituents (phonemes, features, etc.). Take the verb stem kast ‘throw’ in (7). The symbols (#) and (%) mark the beginning and end of the underlying form, respectively, and we read the precedence statements as ordered pairs: # precedes /kh/, /kh/ precedes /ɑ/, /ɑ/ precedes /s/, and so on. The phonetic implementation of this particular set of ordered pairs according to precedence specifications results in a surface form along the lines of [khɑst] or [khɑsth], depending on the timing involved in actuating a spread glottis gesture for final /th/ in a coda cluster with /s/.
Directed graphs require a segment or feature to precede another unit, but they do not require immediate precedence (Papillon Reference Papillon2020, Idsardi Reference Idsardi2022). Instead they signify a ‘preceding–following’ relationship. It is furthermore not a requirement that each unit be preceded or followed by only one phoneme, feature, etc. Although this may be true for morphologically simplex structures, we find multiple precedence relationships especially in morphological processes where additional forms may be concatenated. We refer to this as union, following (Idsardi & Raimy Reference Idsardi, Raimy, Grohmann and Leivadaforthcoming), which describes the joining of two exponents’ directed graph structures. The concatenation of more than one exponent to a
 $\sqrt {\rm root} $
involves multiple union events that coincide with the cyclic spell-out of syntactic features.
$\sqrt {\rm root} $
involves multiple union events that coincide with the cyclic spell-out of syntactic features.
Precedence-theoretic models further posit that the linear order of morphemes relative to stems is encoded in the exponent itself, e.g. as ‘before first segment’ (prefix), ‘after last segment’ (suffix), and in relative precedence with any other stateable phonological constituent (C, V, [sonorant], [nasal], etc.). These representations unify non-concatenative and concatenative morphology, as only differing in terms of where exponents attach (see Raimy Reference Raimy2000 or Papillon Reference Papillon2020 for more detailed discussion). We only examine suffixes here, and use the notation from Papillon (Reference Papillon2020), where their underlying representations begin with the symbol [
 $\_\_ \to $
%] (‘segment that precedes the final segment’). For example, the phoneme /ɑ/ in the past tense exponent of a-class verbs follows the last segment of the structure it joins with via union, in this case a verb stem. The /ɑ/ is then specified to precede the end of the form, (%). The underlying representations of {a} are given in (8a). The structures in (8b) show the feature [pst] merging with
$\_\_ \to $
%] (‘segment that precedes the final segment’). For example, the phoneme /ɑ/ in the past tense exponent of a-class verbs follows the last segment of the structure it joins with via union, in this case a verb stem. The /ɑ/ is then specified to precede the end of the form, (%). The underlying representations of {a} are given in (8a). The structures in (8b) show the feature [pst] merging with
 $\sqrt {\rm kast} $
, both of which are spelled out with their corresponding phonological forms. Next, (8c) demonstrates the union of these forms with directed graphs, where /ɑ/ both follows the last segment of the stem, here /th/, and precedes the end of the representation (%). Finally, the adjoined structures are implemented in speech, illustrated as phonetic notation in (8d). Note that in this example, all representations must be produced sequentially to adhere to precedence specifications. However, representations of this type, i.e. those that are underspecified in time (Idsardi Reference Idsardi2022), also model the implementation of parallel streams of units, such that – under the right conditions – phonological structures may be implemented and pronounced simultaneously. We explore this further in Section 3.1.
$\sqrt {\rm kast} $
, both of which are spelled out with their corresponding phonological forms. Next, (8c) demonstrates the union of these forms with directed graphs, where /ɑ/ both follows the last segment of the stem, here /th/, and precedes the end of the representation (%). Finally, the adjoined structures are implemented in speech, illustrated as phonetic notation in (8d). Note that in this example, all representations must be produced sequentially to adhere to precedence specifications. However, representations of this type, i.e. those that are underspecified in time (Idsardi Reference Idsardi2022), also model the implementation of parallel streams of units, such that – under the right conditions – phonological structures may be implemented and pronounced simultaneously. We explore this further in Section 3.1.

We argue below that these types of structures explain distinct yet interrelated phenomena. As shown in Papillon (Reference Papillon2020), they demonstrate how phonology contributes to allomorphy by appealing to phonological generalizations that are more abstract than feature spreading. We therefore assume that, regardless of source grammar, phonologically predictable allomorphy resides in one representational module (Natvig Reference Natvig2021). Accordingly, ‘single underlying form’ (SUF) structures help make explicit the morphophonological characteristics that reflect the fact that bilingual grammars are integrated (Kroll & Gollan Reference Kroll, Gollan, Goldrick, Ferreira and Miozzo2014, Putnam et al. Reference Putnam, Carlson and Reitter2018), resulting in hybrid grammars (Aboh Reference Aboh2015) consisting of output representations from both languages (Goldrick et al. Reference Goldrick, Putnam and Schwarz2016, Marian & Spivey Reference Marian and Spivey2003). A key structural assumption associated with an integrated view of bilingual grammars is that the underlying syntactic representations are ‘shared’; however, the size of spans and exponency will differ potentially from one source grammar to another. This opens the door to variation and what may be perceived to be ‘instability’ in bilingual grammars. It is worth emphasizing that in this view it is not the representations themselves but their mapping to exponency that is the locus of vulnerability or instability (Perez-Cortes et al. Reference Perez-Cortes, Putnam and Sánchez2019, Putnam Reference Putnam2019, López Reference López2020, Putnam Reference Putnam2020a). We return to this latter point in more detail in Section 5, but first we lay out our analysis of the shared roles of syntactic and phonological representations in Norwegian tense allomorphy (Section 3) before exploring their distributions in the data (Section 4).
3. The morphosyntax of tense
The approach to syntax we adopt here can naturally be extended to the treatment of tense exponency in NAmNo that we pursue in this paper. Building upon previous proposals that define the determination of tense (and other temporal relations, such as those associated with grammatical aspect) as a hierarchical relationship among functional heads in the syntax (Stowell Reference Stowell, Rooryck and Zaring1996, Demirdache & Uribe-Extebarria Reference Demirdache, Uribe-Extebarria, Curtis, Lyle and Webster1997, Reference Demirdache, Uribe-Extebarria, Martin, Michaels and Uriagereka2000, Arche Reference Arche2006, Stowell Reference Stowell2007, Ritter & Wiltschko Reference Ritter, Wiltschko and van Craenenbroeck2009, Reference Ritter and Wiltschko2014), we discuss here how the insights gained from this body of research can be translated into a spanning approach. We understand the notion of tense not as a unified categorical primitive, but rather as set of local, decompositional functional features. We adopt the following working definition of tense:
[T]ense is a deictic-relational category of the verb: it indicates a temporal relation between the situation described by the sentence and some deictically given time span; this time span is usually the moment at which the sentence is uttered … or the ‘now’ (Klein Reference Klein, Klein and Li2009:44)
Here we develop a decompositional approach to periphrastic tense that is consistent with the OFOH architecture we introduced in Section 2. Building upon an initial proposal by Julien (Reference Julien2001), which we expand on below, Natvig et al. (Reference Natvig, Pretorius, Putnam and Carlsonforthcoming) have reconceptualized the core structure attributes of this system. According to Julien (Reference Julien2001), periphrastic tenses are considered to be bi-clausal, that is, both the lexical verb and the auxiliary lexicalize some form of tense. This situation contrasts with ‘simple’ tenses which, in turn, are monoclausal. Accordingly, tense is relevant in both monoclausal and bi-clausal configurations. In this system, the morphology of lexical verbs in periphrastic tenses is a realization of tense (which may or may not include aspect). Most relevant to our current interests, Julien (Reference Julien2001:132) classifies non-finite present, past, and future as periphrastic, i.e. bi-clausal, tenses. The tree structures in (9) and (10) respectively offer the underlying representations for the simple past expression He played (monoclausal) and the periphrastic past He has played (bi-clausal).


Clarifying things a bit, Julien (Reference Julien2001) analyzes perfective aspect as non-finite past. This is captured in the lower clause in (10), where [
 $ - $
fin] embeds [+pst]. Second, present tense is the realization of the combination of [
$ - $
fin] embeds [+pst]. Second, present tense is the realization of the combination of [
 $ - $
fut] and [
$ - $
fut] and [
 $ - $
pst]. Third, the auxiliaries be and have lack content (except for formal features) (see Roberts Reference Roberts1998 for similar arguments). This explains why has in (10) is in fact the V of the higher clause, which inflects for present tense (i.e. [
$ - $
pst]. Third, the auxiliaries be and have lack content (except for formal features) (see Roberts Reference Roberts1998 for similar arguments). This explains why has in (10) is in fact the V of the higher clause, which inflects for present tense (i.e. [
 $ - $
pst], [
$ - $
pst], [
 $ - $
fut]).
$ - $
fut]).
Julien’s (Reference Julien2001) bi-clausal analysis can be translated into our spanning approach outlined in Section 2. Here are a few adjustments worth noting. First, our approach to the nature of features does not require bundled features anchored to functional heads such as ‘T’. Rather, in an OFOH approach, privative features themselves are all held to be ‘contentful’. Second, adopting privative features eliminates the need for any types/subtypes of feature clusters on syntactic heads (such as ‘T’), e.g. [pst] on T(past) and [fut] on T(future). The OFOH architecture is more fine-grained, hence any appeal to a functional head such as ‘T’ should be understood as a proximal zone of related features/heads in syntactic structure. Third, privative features do not require an attribute:value structure, because the negative feature value is either indicated simply by the absence of that feature in syntactic structure or by means of a different feature entirely. The tree structures below in (11a) and (11b) stand in for the basic template of ‘simple’ (monoclausal) and ‘complex/periphrastic’ (bi-clausal) tenses in an OFOH structural adaptation of Julien’s (Reference Julien2001) system.

The syntactic structure of monoclausal ‘simple’ tenses (such as English simple past) contains the features [fin] (the clause is finite) and [pst] (the tense associated with the clause is past tense). In the bi-clausal representation of ‘complex/periphrastic’ tenses (such as present perfect), the top half of the structure in (11b) houses the [fin[‘V’
 ${^2}$
]] features. Note that [‘V’
${^2}$
]] features. Note that [‘V’
 ${^2}$
] is the ‘contentless’ verb (Roberts Reference Roberts1998). Due to the lack of negative features, [+fin] would merge directly with ‘V’
${^2}$
] is the ‘contentless’ verb (Roberts Reference Roberts1998). Due to the lack of negative features, [+fin] would merge directly with ‘V’
 ${^2}$
to yield the ‘default’ present tense. The feature [‘V’
${^2}$
to yield the ‘default’ present tense. The feature [‘V’
 ${^1}$
]] in (11b) is associated with the lower half of the bi-clausal structure. Furthermore, it is worth noting that [pst] is not embedded by any [fin] feature. This would result in a non-finite past interpretation, i.e. perfect aspect, which embeds the lexical (i.e. ‘contentful’) verb.
${^1}$
]] in (11b) is associated with the lower half of the bi-clausal structure. Furthermore, it is worth noting that [pst] is not embedded by any [fin] feature. This would result in a non-finite past interpretation, i.e. perfect aspect, which embeds the lexical (i.e. ‘contentful’) verb.
3.1 North American Norwegian past tense morphosyntax and morphophonology
Recall from Table 1 in Section 2.1 that there are three main verb classes in Norwegian, two weak and one strong, and that past inflection for weak verbs occurs primarily via suffixation, but as stem-vowel alternations for strong verbs. In this section we present the syntactic and phonological representations that contribute to allomorphy in the past tenses, starting with the weak classes as shown in (12). Here the stem of the a-class verb kast-e ‘throw’ is inflected for the preterite with the suffix -a in (12a), whereas the suffix contains a coronal, here -te, for the Te-class verb bruk-e ‘use’ in (12b). According to our OFOH interpretation of Julien (Reference Julien2001), both suffixes spell out a span that includes [pst] and [fin]. The tree structures for the spans that these suffixes spell out are presented in (13).


Comparing these verbs’ participles with their preterite forms reveals distinct correspondences between exponents and the features they spell out, as the sentences in (14) show. The verbs with -a are syncretous in the past participle and the preterite (cf. (12a) and (14a)). Based on the Superset Principle, the {a} exponent spells out the whole span that includes [fin[pst]], even when [fin] is excluded from the syntactic representation, as in (15a). This presents a pattern parallel to that discussed previously with the plural, definite, and definite plural alternations for the adjective
 $\sqrt{\rm{lit}} $
‘little’ in (6). For the Te-class verbs, which take the exponent that we refer to as a {T} because it alternates between t and d, the preterite and participle have different expressions. Namely, the final vowel in the preterite is absent in the participle (cf. (12b) and (14b)). This lack of syncretism suggests that the independent phonological forms, i.e. the t and the e, spell out separate syntactic features, respectively [pst] and [fin]. The tree structure for the past participle is shown in (15b) and the preterite in (15c), modified from (13b).
$\sqrt{\rm{lit}} $
‘little’ in (6). For the Te-class verbs, which take the exponent that we refer to as a {T} because it alternates between t and d, the preterite and participle have different expressions. Namely, the final vowel in the preterite is absent in the participle (cf. (12b) and (14b)). This lack of syncretism suggests that the independent phonological forms, i.e. the t and the e, spell out separate syntactic features, respectively [pst] and [fin]. The tree structure for the past participle is shown in (15b) and the preterite in (15c), modified from (13b).


We have thus far demonstrated that these classes of weak verbs differ in terms of how [fin] and [pst] associate to three different exponents. For the a-class, both features are spelled out by one exponent, {a}, which occurs in both preterite and participial contexts. For the other class, there is a one-to-one relationship between feature and exponent : {T} spells out [pst] and {e} (pronounced [ϵ] or [ǝ]) spells out [fin].Footnote 6 Unlike the past participle suffix -i (see below), {e} is not a target for vowel harmonic patterns in the relevant dialects.
Deriving the distinction between the verb classes still requires explanation. Neither {a} nor {T} should be able to compete for the same insertion environments in our model. For instance, based on the features we have proposed so far, {T} should be a better candidate than {a} for the past participle (see (15a)) because it is a one-to-one match with [pst], which would result in the ungrammatical form *kast-t. Finally, the distributions of these exponents are not predictably conditioned by phonological environment. For example, for both ro-e ‘calm’ and ro ‘row’, the stem is homophonous (ro).Footnote 7 The former falls into the the a-class – ro-a ‘calmed’ – whereas the latter is inflected with a {T} in the preterite (ro-dde) and participle (ro-tt), both meaning ‘rowed’. We take these and similar patterns to indicate that the distinction between weak verb classes is made in the syntax.
One way to achieve these class distinctions is by indexing roots to different subclasses, as is common in Distributed Morphology (Harley Reference Harley2014). Another approach, which we adopt here, is to model class distinctions in terms of the size of syntactic trees, i.e. as spans (Starke Reference Starke and Picalo2014, Fisher et al. Reference Fisher, David Natvig, Putnam and Schuhmann2022). For our purposes, this means that, similarly to the phonological forms that are often associated to ‘morphemes’ in a non-technical sense, grammatical features may also be decomposable. Following this hypothesis, features that are typically based on the semantic or grammatical meanings are mediated here through an interpretation of a span composed of at least one formal feature.
The major verb classes are presented in Table 2, with forms for infinitives, preterites, and participles. In terms of exponents that associate with a [pst] interpretation, there are three: {a}, {T}, and {i}. Accordingly, these formal features define syntactic environments for insertion, and the lexicalization of the full span produces the interpretable feature content (Fisher et al. Reference Fisher, David Natvig, Putnam and Schuhmann2022). We therefore propose that [pst] consists of a span of three units, e.g. [p
 ${_3}$
[p
${_3}$
[p
 ${_2}$
[p
${_2}$
[p
 ${_1}$
]]], where the numbers are given for expository purposes. This [pst] span is represented in the tree structure in (16).
${_1}$
]]], where the numbers are given for expository purposes. This [pst] span is represented in the tree structure in (16).

Table 2. NAmNo past inflection classes (based on exponency of [pst] and [fin])
The primary purpose of the formal units p
 ${_1}$
, p
${_1}$
, p
 ${_2}$
, and p
${_2}$
, and p
 ${_3}$
is to distinguish exponents that spell out the same or similar grammatical features. These features provide the structural environments in which exponents compete for insertion (e.g. Hall Reference Hall, Bjorkman and Currie Hall2020:262), and form the smallest span size that captures the phonologically unpredictable patterns in past tense allomorphy. We illustrate this and discuss the underlying structures that the relevant exponents spell out below.
${_3}$
is to distinguish exponents that spell out the same or similar grammatical features. These features provide the structural environments in which exponents compete for insertion (e.g. Hall Reference Hall, Bjorkman and Currie Hall2020:262), and form the smallest span size that captures the phonologically unpredictable patterns in past tense allomorphy. We illustrate this and discuss the underlying structures that the relevant exponents spell out below.
Like our previous examples, the a-class exponent, {a}, spells out all the relevant features, i.e. [fin] and the entire three-head span corresponding to [pst], as in (17). The syncretism between preterite and participle is still captured within this distributed [pst] tree structure based on the Superset Principle.

The spell-out and union of the stem kast and the exponent {a} are presented in (18), updated from (8) to include the full span that it maps to.

In contrast to the a-class, we propose that all verbs in the Te-class have phonological forms that spell out a structure that contains both the
 $\sqrt {{\rm{root}}} $
and [p
$\sqrt {{\rm{root}}} $
and [p
 ${_1}$
] (see Fisher et al. Reference Fisher, David Natvig, Putnam and Schuhmann2022). What this stipulation is intended to capture is that partially lexicalizing the [pst] span via the spell-out of the verb stem changes the syntactic environment that needs to be spelled out. For this class of verbs, {T} maps to the [p
${_1}$
] (see Fisher et al. Reference Fisher, David Natvig, Putnam and Schuhmann2022). What this stipulation is intended to capture is that partially lexicalizing the [pst] span via the spell-out of the verb stem changes the syntactic environment that needs to be spelled out. For this class of verbs, {T} maps to the [p
 ${_3}$
[p
${_3}$
[p
 ${_2}$
]]. That is, this exponent spells out the remainder of [pst] span because it contains fewer superfluous features than {a} due to the lexicalization of [p
${_2}$
]]. That is, this exponent spells out the remainder of [pst] span because it contains fewer superfluous features than {a} due to the lexicalization of [p
 ${_1}$
] from the phonological form signaled by the
${_1}$
] from the phonological form signaled by the
 $\sqrt {{\rm{root}}} $
. The syntax for the regular Te-verbs, i.e. those that do not have stem alternations, is shown in (19a). These include all of the subtypes shown in Table 2, with the exception of the ja-type. For the ja-type, however, there are distinct forms for whether [p
$\sqrt {{\rm{root}}} $
. The syntax for the regular Te-verbs, i.e. those that do not have stem alternations, is shown in (19a). These include all of the subtypes shown in Table 2, with the exception of the ja-type. For the ja-type, however, there are distinct forms for whether [p
 ${_1}$
] is generated. The verb spør-j-e ‘ask’ in (19b) has the front vowel ø in non-past contexts (without [p
${_1}$
] is generated. The verb spør-j-e ‘ask’ in (19b) has the front vowel ø in non-past contexts (without [p
 ${_1}$
]), but u in the preterite and past participle (with [p
${_1}$
]), but u in the preterite and past participle (with [p
 ${_1}$
]). We assume that the same relationships hold for verbs such as kjøp-e ‘buy’ that, in these and similar source varieties, undergo consonant alternations in the preterite and perfect, as in kjøf-t-e ‘bought’.
${_1}$
]). We assume that the same relationships hold for verbs such as kjøp-e ‘buy’ that, in these and similar source varieties, undergo consonant alternations in the preterite and perfect, as in kjøf-t-e ‘bought’.

Unlike the syncretism found in the a-class verbs as in (8), the {T} occurs in all past contexts for this class, but {e} only in preterite ones. We show here that the surface form of {T}, i.e. [th] or [t]/[d], is phonologically regular, although in various ways: one due to feature sharing and gestural overlap, the other due to definable points of concatenation that either do or do not hold based on the phonological shape of the stem.
The clearest pattern for the surface realization of {T} in preterites is based on the laryngeal setting of obstruent-final stems, which is always congruent. Because of this predictability, and following our position that fortis obstruents are specified for the gesture [spread], we propose that the lenis /t/ is the ‘base’ form of the {T} exponent, which spells out the span of [p
 ${_3}$
[p
${_3}$
[p
 ${_2}$
]] as in (20a); again the {e} in (20b) expresses the feature [fin] in preterite contexts.
${_2}$
]] as in (20a); again the {e} in (20b) expresses the feature [fin] in preterite contexts.

Compare the examples in (21). In the first, prøv ‘try’ ends in the lenis /v/. Following union with /t/ (21b), there is no [spread] feature that spreads to the the coronal and it surfaces as lenis, likely with passive voicing as [d] in (21c). Note that for all Te-class verbs, there are two union operations. The first joins the
 $\sqrt {{\rm{root}}} $
with {T} (21b-i) and the second joins the product of that union to {e} (21b-ii). For the next example, (21d), the stem bruk ‘use’ ends in fortis /kh/, specified for the feature [spread]. When bruk and {T} are joined (21e), and then implemented (21f), [spread] is produced simultaneously with /t/, as in (21f). This purely phonetic/phonological alternation falls out exclusively from the laryngeal specification of the stem-final obstruent and therefore only requires one underlying segment to spell out [pst] for this class of verbs.
$\sqrt {{\rm{root}}} $
with {T} (21b-i) and the second joins the product of that union to {e} (21b-ii). For the next example, (21d), the stem bruk ‘use’ ends in fortis /kh/, specified for the feature [spread]. When bruk and {T} are joined (21e), and then implemented (21f), [spread] is produced simultaneously with /t/, as in (21f). This purely phonetic/phonological alternation falls out exclusively from the laryngeal specification of the stem-final obstruent and therefore only requires one underlying segment to spell out [pst] for this class of verbs.

The alternation of surface forms for {T} following consonant sonorants, on the other hand, is slightly more complicated. There is considerable dialectal variation regarding which sonorants specify an environment for a surface {T} with the opposite laryngeal setting, namely [th]. In varieties that behave more closely to the written Bokmål standard, the fortis occurs with all stems ending in consonant sonorants. On the other hand, lenis surface forms following laterals, rhotics, and nasals are also attested. For the sake of our present discussion, we present [(cons) sonorant] as an environment for /th/ in the preterite and revise following an examination of the North American Norwegian data in Section 4.2. This form is represented through parallel directed graphs in (22a), where the /t/ adjoins following the last segment as in other environments. However, following a final sonorant, i.e. [[sonorant]
 $ \to $
%], the feature [spread] occurs along a directed graph parallel to /t/. Provided the appropriate environment obtains, in our toy example here following a sonorant-final stem, the phoneme /t/ and the feature [spread] both follow the sonorant and precede the end of the form (and precede /e/ following the union with the spell-out of the [fin] feature). This is presented in the precedence graphs in (22b), where the stem kjen ‘know’ combines with {T} and then {e} in the preterite. Because /t/ and [spread] can be implemented simultaneously, they satisfy their precedence relations and surface as fortis [th], as in (22d). Where there is no final sonorant, as in (21), the directed graph that leads to [spread] fails to attach, and this feature is unpronounced in the implementation phase of the derivation (see Papillon Reference Papillon2020) for more detail). We refer to these complex, parallel representations as ‘single underlying forms’ (SUFs) (see Papillon Reference Papillon2020), and they are interchangeable with our use of exponent.
$ \to $
%], the feature [spread] occurs along a directed graph parallel to /t/. Provided the appropriate environment obtains, in our toy example here following a sonorant-final stem, the phoneme /t/ and the feature [spread] both follow the sonorant and precede the end of the form (and precede /e/ following the union with the spell-out of the [fin] feature). This is presented in the precedence graphs in (22b), where the stem kjen ‘know’ combines with {T} and then {e} in the preterite. Because /t/ and [spread] can be implemented simultaneously, they satisfy their precedence relations and surface as fortis [th], as in (22d). Where there is no final sonorant, as in (21), the directed graph that leads to [spread] fails to attach, and this feature is unpronounced in the implementation phase of the derivation (see Papillon Reference Papillon2020) for more detail). We refer to these complex, parallel representations as ‘single underlying forms’ (SUFs) (see Papillon Reference Papillon2020), and they are interchangeable with our use of exponent.

The final regular morphophonological alternation for {T} that appeals to statements over phonological environment concerns vowel length alternations in the dde-type weak verbs. These consist of monosyllabic stems ending in a stressed vowel, for example tru ‘believe’ and bu ‘live/dwell’. In the non-past, the vowel is always long, whereas concatenation of the {T} shortens the vowel. Norwegian vowel length patterns are complicated and a full account is beyond our current scope, but we are primarily concerned with the following generalizations.

This means that all Norwegian stressed syllables are heavy. Some consonants contribute to syllable weight (i.e. underlyingly moraic) and some do not. In the latter case, stressed vowels lengthen to satisfy the weight conditions, otherwise the vowel is short. To account for the contrast between moraic and non-moraic consonants in Kristoffersen’s (Reference Kristoffersen2000) system in an SUF representation, we adopt a juncture mark ‘)’ to specify whether or not a coda consonant is included in the stressed syllable for purposes of weight calculations. Note that this is distinct from stress calculations, an analysis of which is beyond our present focus. For our purposes, V)C excludes the consonant and the syllable is treated as open and the vowel lengthens: [VːC]. On the other hand, VC) stipulates that the consonant is included within the syllable and that the vowel does not lengthen.
When a stressed vowel is followed by a single consonant, it will be long (see 23b) unless otherwise stated via representations (with juncture marks). This is the case for the short verbs, where, for example, the vowel in bu [bʉː] ‘live’ shortens following the single consonant in {T} for both the preterite ([bʉd.dɛ]) and base participle form ([bʉth]; see Section 3.2).Footnote
8
We accordingly add the directed graph structure to the {T} exponent that specifies that when a stem ends in a vowel ([V
 $ \to $
%]), a juncture mark is preceded by a consonant (C), as in (24a). Like the parallel [spread] feature in (22b), the constituent C is implemented contemporaneously with the base segment /t/ when affixed to the stem-final vowel in (24b). The juncture mark then follows the consonant, yet precedes the end (%) prior to union with /e/ in the preterite. This ensures that /e/ follows ) and accordingly that the juncture is both preceded by /t/ and precedes /e/ at the end of the derivation. Again, because the specific (consonant) [sonorant] environment condition is not met, there are no viable paths through [spread], so it is left unpronounceable. The pronounceable representations are implemented as in (24d), with a short, stressed vowel.
$ \to $
%]), a juncture mark is preceded by a consonant (C), as in (24a). Like the parallel [spread] feature in (22b), the constituent C is implemented contemporaneously with the base segment /t/ when affixed to the stem-final vowel in (24b). The juncture mark then follows the consonant, yet precedes the end (%) prior to union with /e/ in the preterite. This ensures that /e/ follows ) and accordingly that the juncture is both preceded by /t/ and precedes /e/ at the end of the derivation. Again, because the specific (consonant) [sonorant] environment condition is not met, there are no viable paths through [spread], so it is left unpronounceable. The pronounceable representations are implemented as in (24d), with a short, stressed vowel.

We now turn our discussion to the strong verbs, which may occur with different types of vowel alternations for preterites, participles, and even in the present tense. For our purposes, while a verb like skjer-e ‘cut’ undergoes a vowel (and consonant) alternation in the preterite with no inflectional morphology (skjer /∫er/ – skar /skɑr/), the past participle displays both a vowel change and has a suffix, i.e. the exponent {i}, as in skor-i.
The preterite forms, regardless of how their phonological representations compare to the non-past, spell out all required features in (25a). There are no suffixes because skar lexicalizes entire [pst] span and [fin]. In the perfect structures, where [fin] is not generated for the lower verb, skar and other strong preterite forms are not optimal matches for spell-out because of this superfluous feature. In these contexts, a participial form that corresponds to a smaller syntactic tree (skor) partially spells out the [pst] span, i.e. [p
 ${_2}$
[p
${_2}$
[p
 ${_1}$
]] in (25b). Yet to encode a [pst] reading, the whole span needs to be lexicalized. This is accomplished through the suffixation of {i}, which spells out [p
${_1}$
]] in (25b). Yet to encode a [pst] reading, the whole span needs to be lexicalized. This is accomplished through the suffixation of {i}, which spells out [p
 ${_3}$
]. Some Norwegian strong verbs, e.g. ta ‘take’, have past participles that are more similar to Te-class verbs than other strong verbs: tok ‘took’, but ta-tt ‘taken’. For this subset, we assume that although the phonological forms for preterites spell out the [fin[p
${_3}$
]. Some Norwegian strong verbs, e.g. ta ‘take’, have past participles that are more similar to Te-class verbs than other strong verbs: tok ‘took’, but ta-tt ‘taken’. For this subset, we assume that although the phonological forms for preterites spell out the [fin[p
 ${_3}$
[p
${_3}$
[p
 ${_2}$
[p
${_2}$
[p
 ${_1}$
[
${_1}$
[
 $\sqrt {\rm root} $
]]]]] span, only [p
$\sqrt {\rm root} $
]]]]] span, only [p
 ${_1}$
[
${_1}$
[
 $\sqrt {\rm root} $
]] is spelled out by the participle. The distributions that we find in the actual forms fall out from the Exhaustive Lexicalization Principle in (2) and the Superset Principle in (4).
$\sqrt {\rm root} $
]] is spelled out by the participle. The distributions that we find in the actual forms fall out from the Exhaustive Lexicalization Principle in (2) and the Superset Principle in (4).

Thus far we have presented our position on the phonological form of the suffixes that denote past inflection in Norwegian. One exponent spells out a span of the feature [pst] and [fin] (26a) and displays syncretism in the preterite and perfect past on superset mapping conditions. A second exponent, the SUF in (26b), expresses only [pst], but undergoes a considerable amount of regular, predictable phonetic and phonological variation. For these verbs, [fin] is spelled out by its own exponent, {e} (26d). Finally, most of the strong verbs have a distinct suffix in participles, {i} (26c), that spells out the last feature of the [pst] span ([p
 ${_3}$
]). Again we consider potential alternations between -i ([i]) and -e ([ϵ]/[ǝ]) here to be implementations of one exponent (see Section 2.1), although individuals may clearly vary according to whether or not they have harmony-like patterns. Future work could look at capturing these alternations in SUF representations, but what is critical for us is that this form is distinct, in either surface realization or in phonological behavior, from the other exponents involved in past tense morphology.
${_3}$
]). Again we consider potential alternations between -i ([i]) and -e ([ϵ]/[ǝ]) here to be implementations of one exponent (see Section 2.1), although individuals may clearly vary according to whether or not they have harmony-like patterns. Future work could look at capturing these alternations in SUF representations, but what is critical for us is that this form is distinct, in either surface realization or in phonological behavior, from the other exponents involved in past tense morphology.
We rely on distinct phonological environments, stateable as parallel structures as an SUF through precedence relationships, to facilitate a clear division of labor between syntax and phonology in contributing to allomorphic patterns. Syntax distinguishes between classes based either on feature syntactic constellations (Fisher et al. Reference Fisher, David Natvig, Putnam and Schuhmann2022) or root indexes (Harley Reference Harley2014), whereas multiple phonological statements can occur in parallel in a single form. We leave aside for now the specific mechanisms that underlie the ‘non-concatenative’ aspects of Germanic verb inflection, i.e. umlaut and ablaut, except to say that these involve additional types of parallel structures, either as exponents that attach to different places on the stem, more phonologically robust stems that map out vowel alternations for each root (Idsardi & Raimy Reference Idsardi, Raimy, Grohmann and Leivadaforthcoming), or both.

3.2 Perfect agreement
One last comment on the surface forms of Norwegian verbs is in order. This concerns particularly the participles, i.e. the forms that involve the merging and union of a verbal root and the span for [pst], but not [fin]. As is common in the Germanic languages, past participles occur as both adjectives and as members of the compound verb forms in the perfect in Norwegian. Past participial adjectives adhere to the same morphological patterns as typical adjectives, namely they agree in gender, number, and definiteness with the constituents they modify. For our purposes, there are three genders, m, f, n, which are only distinguished in the singular. The plural and definite forms, i.e. ‘weak’ adjectival inflection, are identical for the vast majority of adjectives in Norwegian. The gender agreement patterns for regular adjectives and major verb classes are presented in Table 3.
Table 3. Gender agreement for adjectives and past participles

For the regular adjective, trygg ‘safe’, neither masculine nor feminine requires additional morphological marking for singular, indefinite forms. For singular neuter, however, agreement is marked via the suffix /th/. Both plural and definite, regardless of gender or number, show agreement with the suffix /e/. For all regular adjectival agreement inflection, the plural and weak forms (in the singular and plural) are syncretous. Participial adjectives likewise agree with the elements they modify, but they vary in how agreement is expressed. For example, a-class verbs have no additional inflectional morphology beyond the /ɑ/ suffix that expresses agreement. We understand this pattern to indicate that, in addition to [pst] and [fin], the exponent {a} spells out all relevant adjectival features as well, dependent on syntactic context and the Superset Principle. In contrast to {a}, participial adjectives from the Te-class conform to the regular adjective pattern, where /th/ marks n.sg and /e/ expresses both plural and definite. This suggests that the relevant agreement features are lacking for {T}. Agreement then proceeds as the identical process that affects typical Norwegian adjectives. Finally, strong verbs express their own agreement pattern. Although there is considerable variation, in terms of both strong verb class and regional variety, like the Te-class verbs and regular adjectives, the neuter form for strong verbs is typically distinct from the other available categories.
A full analysis of the allomorphy of participial adjective agreement takes us too far afield from our present discussion. For our current purposes, it is important that past participles in complex tenses occur in their neuter inflection, however that may be formed. We understand this pattern to mean that when Te-class verbs occur as past participles and are produced with a final fortis /th/, this /th/ is the exponent agreeing with n, rather than a difference in the spell-out of [pst]. That is, the /t/ in bo-dde ‘lived (pret.)’ from (24a) also spells out [pst] for the participle in bo-tt ‘lived (part.)’, but with an additional /th/ suffix marking neuter gender agreement. This is represented in (27), where the features for the past participial form are [n[p
 ${_3}$
[p
${_3}$
[p
 ${_2}$
[p
${_2}$
[p
 ${_1}$
[
${_1}$
[
 $\sqrt {{\rm{root}}} $
]]]]]. For Te-verbs, like bu, the feature [n] is realized as /th/. For a-class verbs, on the other hand, the past suffix is capable of spelling out n with no additional exponent; the same is true for strong verbs, although the particular feature–form relationship differs. Norwegian varieties differ in the extent to which especially Te-verbs show neuter agreement as participles. Because we find consistent neuter marking in our data set (see Section 4.2), we assume that this is a feature of the relevant North American dialect(s).
$\sqrt {{\rm{root}}} $
]]]]]. For Te-verbs, like bu, the feature [n] is realized as /th/. For a-class verbs, on the other hand, the past suffix is capable of spelling out n with no additional exponent; the same is true for strong verbs, although the particular feature–form relationship differs. Norwegian varieties differ in the extent to which especially Te-verbs show neuter agreement as participles. Because we find consistent neuter marking in our data set (see Section 4.2), we assume that this is a feature of the relevant North American dialect(s).

Our review of the morphosyntax of tense in Norwegian and its engagement with EFP phonology undertaken in this section serves as analytical model as we shift our investigation to patterns in the NAmNo data in the subsequent section.
4. Stability in North American Norwegian
Having introduced the relevant Norwegian dialectal patterns and our position on the formal structure of Norwegian verbal morphosyntax, we now comment on the data collection of NAmNo tense exponents, while also providing an account of the distribution of tense morphology related to verb classes.
4.1 Data collection
The empirical basis for the study is spontaneous speech data drawn from the Corpus of American Nordic Speech, version 3.1 (CANS, Johannessen Reference Johannessen and Megyesi2015). These recordings consist of both interviews and conversations, i.e. with and without a researcher present. Our subcorpus comprises 21 speakers from Coon Valley and Westby, Wisconsin, 6 women and 15 men, who were born between 1920 and 1957. The mean age at the time of the recordings was 79 years. We extracted tokens tagged as preterite or perfect participle, excluding items incorrectly tagged for part of speech, obtaining a dataset of 9161 tokens, with 772 unique transcriptions. From this initial set, we removed modals and auxiliaries, the latter including all instances of vere ‘be’, bli ‘become’, and ha ‘have’, because they involve interactions across multiple syntactic projections. We also excluded the set verbs that inflect with -s, often indicating passive or middle voice (Wiklund Reference Wiklund2007, Fábregas & Putnam Reference Fábregas and Putnam2020), e.g. syn-s ‘seem, think’ (lit. ‘view-pass’). These forms can diverge from their non-middle counterparts and it is not clear how NAmNo speakers treat these verbs. We also removed examples of English-origin verbs because it is also not always clear how to classify them based on inflectional class. This leaves us with a total of 3672 tokens in our dataset.
We manually evaluated forms for whether they are inflected for expected verbal class and type distinctions presented in Table 1 and discussed in Section 2.1. Each form was categorized either as ‘expected’, ‘not expected’, or ‘unclear’ with respect to verb class, based on the appropriate dialect area. We based these on descriptions in Venås (Reference Venås1967, Reference Venås1974) and from comparisons to two spoken language corpora: the Nordic Dialect Corpus (NDC), which has speakers born between 1916 and 1997 (Johannessen et al. Reference Johannessen, Joel Priestley, Åfarli, Vangsnes, Jokinen and Bick2009), and the LIA corpus, whose speakers were born between 1837 and 1988 (LIA-korpuset (The LIA Corpus) 2023). The category ‘expected’ contains forms which are inflected by expected verb class as in the relevant baseline dialects. For example, a-class verbs inflected with [ə], rather than [ɑ], in the past were annotated as such. These forms are recognizable from the Biri dialect, and are additionally consistent with English-like unstressed vowel reduction patterns.
The category ‘not expected’ consists of forms that are different from the comparison groups, normally verbs that are inflected for a different class. Finally, the ‘unclear’ category contains tokens that are ambiguous or uninterpretable. For example, one speaker produces likter as preterite of like ‘like’ and it is unclear whether the form is intended to be in the past or present. This item only occurs once in the dataset, and the speaker otherwise typically produces expected preterite forms. We now present and discuss preterite and participial forms in the data.
4.2 Distribution of exponency related to verb class
North American Norwegian speakers in Westby and Coon Valley demonstrate overwhelming consistency and stability (3568 of 3672 tokens, 97.2%) in terms of the system of verb classes and types, the individual verbs that belong to each, and the expression of the corresponding past exponents, including both preterite and perfect forms. Furthermore, there appears to be very little difference in how speakers treat different classes of verbs; over 95% of within-class tokens reflect stable patterns, i.e. consistent with source dialects. Regarding tokens that represent forms that consist of either a different class, type, or exponency, we find a range of between approximately 1% and 2.5%; the rest are unclear. These data are presented in Table 4, where we extract the ja-type verbs from the larger Te-class because vowel alternation in addition to suffix is also part of the ‘expected’ patterning; the remaining subtypes of the Te-class are based on phonologically predictable patterns, which are also borne out in the data.
Table 4. Distributions of expected, not expected, and unclear past forms by verb class

In terms of the breakdown of forms tagged as preterite and perfect (Table 5), we see no discernible divergences from the combined distributions in Table 4. Except for the a-class verbs, at least 95% of forms each for preterite and perfect are classified as expected. For the a-class, 98.1% of participle forms are expected, whereas this number drops to 92.6% for preterites. What we take from the overall picture is that there has been almost no systematic or meaningful influence from English, or the particular sociolinguistic setting of heritage language multilingualism, on the morphosyntactic structure underlying Norwegian tense in this community.
Table 5. Distributions of expected, not expected, and unclear preterite and perfect forms by verb class

A few comments on these data are in order before we discuss these results in terms of an integrated grammatical architecture. First, of the 404 expected a-class verbs, 38 (9.1%) of them occur with a schwa-like unstressed vowel. Although forms like this are indistinguishable from the infinitive, this syncretism is a characteristic of the Biri dialect, and accordingly reflects a degree of stability in the options available in the pool of variation (see Section 2.1). We see a similar pattern in the perfect of a subset of strong verbs. Of the 80 tokens with {i} (recall that many strong verbs have {T} forms in the perfect), 61 (76.3%) are produced with -i. Of the 19 (23.8%) with -e, there are no consistent phonological or lexical patterns. We therefore also consider this result evidence of community-level variation in the phonetic implementation of a single exponent, as argued in Section 2.1.
Second, participial forms of the Te-class, including ja-type, verbs almost always show what we analyze as neuter agreement, ending in [th]. Of the 194 unambiguous tokens, i.e. those with stems not ending in a fortis consonant, only 8 (4.1%) occur with a lenis d; the remaining 186 (94.8%) have neuter agreement. For example, one of the most commonly used verbs in this class, høyre, ‘hear’, occurs as the participle /hør-th/ in all 48 examples, but with a d in all 44 instances in the preterite (/hør-t-e/). For all lemmas with more than one token without neuter agreement, i.e. a participle ending in [d], there were also tokens with agreement, e.g. /prøv-t/ (2 tokens) and /prøv-th/ (3 tokens).
Third, the data shed light on the phonologically conditioned allomorphy of Te-class verbs by demonstrating which sonorants condition a fortis [th] in the preterite. Among the expected forms, nasals precede [th] in 168 of 171 tokens. Laterals, on the other hand are more variable, with 54 of 95 (56.8%) occurring with a fortis suffix. Stems ending in /r/ are almost exclusively inflected with lenis d (258 of 262 tokens), with the exception of the four examples ending in the verbalizer -er(e) having [th] in the preterite. Whether or not this represents a consistent subpattern warrants further investigation. However, we update the phonological form of the {T} exponent in (26b) to the following in (28), where [nasal] precedes the [spread] gesture – leaving the question of [lateral] variation open to further research.

Finally, there is a subset of Te-verbs, including the ja-class, that inflects as expected according to verb class, i.e. with a {T} exponent, yet with what on the surface is a participle in the preterite, e.g. [çϵnth] instead of [çϵn.thϵ] ‘knew’. Although we consider these to be ‘expected’ based on inflectional class, this type of syncretism, albeit fairly infrequent as we will show, appears to be an innovation among these North American speakers. Of the 1024 tokens of relevant Te-class and ja-type verbs in the preterite, 128 (12.5%) are produced without the final {e} exponent that spells out [fin], as in (19).Footnote 9 We do not find a related increase in syncretic forms among strong verbs, and preterite–perfect syncretism is a pre-existing feature of the a-class verbs. We show in the next section that this type of constrained variation is expected from our explicit model of integrated grammatical representations, where in this case Norwegian- and English-origin exponents compete to spell out the same underlying syntactic structure.
5. (Heritage language) bilingualism and integrated representations
In this section we propose an explanation for the stability of the exponency of NAmNo tense that draws explicitly on the role of shared structures in a bilingual grammar. We first discuss the relationship between Norwegian and English [pst] spans in defining the appropriate inflectional classes in each language before we explore the the integration of phonological material from both languages that spells out the relevant class-delimiting spans.
NAmNo speakers acquired Norwegian as children, most of them before acquiring English. In the following, we consider the extent to which English patterns can be represented using the Norwegian syntax we proposed above. Our conclusion is that, at least regarding the size of spans necessary for distinguishing verb classes, English and Norwegian use the same syntactic structure. Cross-linguistic differences present themselves in (i) the portions of the [fin[p
 ${_3}$
[p
${_3}$
[p
 ${_2}$
[p
${_2}$
[p
 ${_1}$
]]]] span that exponents spell out, and (ii) the phonological forms of exponents that are associated with each language.
${_1}$
]]]] span that exponents spell out, and (ii) the phonological forms of exponents that are associated with each language.
In terms of distinguishing what, if any, contribution acquiring English makes to enriching Norwegian representations in a heritage language setting, we adopt a position commensurate with Westergaard (Reference Westergaard2021). In her view, acquisition is a conservative process, and new structures are only acquired when existing ones are unable to parse the new language input. As we discussed in Section 3, Norwegian and English share the same general relationships with respect to past tense and finiteness and their relationships in monoclausal and biclausal structures. The relevant issue here is the extent to which the three-feature [pst] span in Norwegian suffices to model English allomorphy. Stated more precisely, are the underlying syntactic representations in NAmNo sufficient for expounding English past tense allomorphy? We view this in terms of number of classes, so if English has more classes than Norwegian, this would, following the spirit of Westergaard (Reference Westergaard2021), prompt the acquisition of additional [p] features and enlarge this [pst] span. Furthermore, the relationship between [fin] and [pst] in syntactically conditioned allomorphy, since – as we show below – English demonstrates preterite–perfect syncretism with two exponents, rather than one. We take the forms in (29), following Embick (Reference Embick2010:6) as representative of the English system, incorporated into our model.

Just as the Norwegian {a} exponent spells out finite (preterite) and non-finite (perfect) forms, so do both {t} and {th} in English. Unlike Norwegian, however, the distributions of {t} and {th} are not phonologically predictable, so we are unable to integrate them into one SUF; their distributions are encoded syntactically. They are furthermore distinct from Norwegian {T}, which does not spell out [fin]. Again drawing on the Superset Principle, we propose that both {t} and {th} spell out [fin] and some contiguous portion of the [pst] span, as in (29a) and (29b). Because there are stem alternations with both exponents, neither of them spells out the entire sequence of [p
 ${_3}$
[p
${_3}$
[p
 ${_2}$
[p
${_2}$
[p
 ${_1}$
]]], so both are also distinct from Norwegian {a}. The choice between which exponent maps to which portion of [pst] features follows from our working assumption that the forms that correspond to the most regular classes, here Norwegian {a} and English {t}, spell out the largest portion of the relevant span. In other words, the regular stems have roots that spell out the smallest spans. Whether or not this assumption can be upheld remains to be investigated. Finally, strong verbs in English work exactly the same as in Norwegian, but with {en} spelling out [p
${_1}$
]]], so both are also distinct from Norwegian {a}. The choice between which exponent maps to which portion of [pst] features follows from our working assumption that the forms that correspond to the most regular classes, here Norwegian {a} and English {t}, spell out the largest portion of the relevant span. In other words, the regular stems have roots that spell out the smallest spans. Whether or not this assumption can be upheld remains to be investigated. Finally, strong verbs in English work exactly the same as in Norwegian, but with {en} spelling out [p
 ${_3}$
]. Here we find the only instance of distinct phonological material across languages corresponding to the same underlying syntactic structure. We leave open to further research whether these are separate exponents that compete for insertion or are incorporated into one SUF with language-specific implementation procedures.
${_3}$
]. Here we find the only instance of distinct phonological material across languages corresponding to the same underlying syntactic structure. We leave open to further research whether these are separate exponents that compete for insertion or are incorporated into one SUF with language-specific implementation procedures.
For purposes of comparison, Norwegian and English exponents, and the spans they spell out, are presented in (30). Norwegian-origin exponents are found in (30a–30d), whereas English-origin ones are in (30e–30g). Representations for strong verbs in (30h) are shared for both languages. Preterite forms spell out the entire span from
 $\sqrt {{\rm{root}}} $
to [fin], whereas the maximum span for past participles extends to [p
$\sqrt {{\rm{root}}} $
to [fin], whereas the maximum span for past participles extends to [p
 ${_2}$
].
${_2}$
].

From the comparative analysis of Norwegian and English past tense morphosyntactic structures and the relevant exponency, we demonstrate that the underlying system in both languages is the same. This concerns specifically the relationship between [fin] and [pst] in determining the distributions of preterite and perfect forms, as well as the span size of [pst], here composed of three features, to represent the appropriate class distributions. What this then illustrates is that the acquisition task for NAmNo speakers learning English only requires the learning of additional exponents and how they map to the already existing (Norwegian) syntactic structures. There is no need to acquire additional syntactico-semantic categories, e.g. syntactic features specifically dedicated to the spell-out of mood or aspect,Footnote 10 or to modify the size of the [pst] span to accommodate the English system. Although, we argue, the particular constellations of these features and how they map to language-specific exponents are different, NAmNo speakers draw on the exact same core representations for accessing and processing morphosyntactic information in English as they do in Norwegian, indicating that these structures are always in use regardless of which language is spoken. This continued use of the (originally) Norwegian past tense formal features for English purposes accounts for the observed stability of NAmNo tense allomorphy (see Putnam & Sánchez Reference Putnam and Sánchez2013 or Putnam et al. Reference Putnam, Perez-Cortes, Sánchez, Schmid and Köpke2019 for related arguments). This analysis contributes to future discussions of the stability of tense in contrast to other morphosyntactic categories. Future research should investigate the effects of different span sizes across languages in the relative stability of allomorphy in tense and elsewhere (Lohndal & Putnam Reference Lohndal, Putnam, Polinsky and Putnam2023).
Finally, the one potential exception to this general stability – syncretism in the preterite and perfect for Te-class verbs – falls into place when comparing NAmNo and English exponent-to-span correspondence. Recall that these verbs require the lexicalization of the [fin[p
 ${_3}$
[p
${_3}$
[p
 ${_2}$
]]] span. In a presumed monolingual Norwegian context, this requires two exponents: {T} spells out [p
${_2}$
]]] span. In a presumed monolingual Norwegian context, this requires two exponents: {T} spells out [p
 ${_3}$
[p
${_3}$
[p
 ${_2}$
]] and {e} spells out [fin]. Following the acquisition of English, however, an additional exponent {t} is available to spell out the subspan. See (31) for a model of this competition, with Norwegian-origin exponents to the right and English-origin to the left. While the complex exponent pair {T}{e} may be more appropriate in terms of the sociolinguistic conditions prescribed by language mode, the competing {t} option offers a more direct exponent-to-span mapping relationship that, at least in our data, is implemented for 12.5% of tokens. We expect individuals to vary on this point, based on a host of contextual and personal factors. What is important is that the available grammatical structures constrain the potential options for real-time variation in speech.
${_2}$
]] and {e} spells out [fin]. Following the acquisition of English, however, an additional exponent {t} is available to spell out the subspan. See (31) for a model of this competition, with Norwegian-origin exponents to the right and English-origin to the left. While the complex exponent pair {T}{e} may be more appropriate in terms of the sociolinguistic conditions prescribed by language mode, the competing {t} option offers a more direct exponent-to-span mapping relationship that, at least in our data, is implemented for 12.5% of tokens. We expect individuals to vary on this point, based on a host of contextual and personal factors. What is important is that the available grammatical structures constrain the potential options for real-time variation in speech.

In summary, we find nothing immediately unique concerning the morphosyntactic structure underlying the category tense in connection with its stability in NAmNo. Rather, what appears to be at play here is that English–NAmNo bilinguals are able to effectively recycle the same spans used in both source grammars. Although English and NAmNo differ with regard to the classes of exponents they exploit for lexicalization, the underlying syntactic structures (i.e. span sizes) are identical (Fisher et al. Reference Fisher, David Natvig, Putnam and Schuhmann2022). A late-insertion model to the syntax–lexicon interface such as this one provides a grounded and constrained approach to how the various modules of grammar communicate with one another in both monolingual and bilingual settings (López Reference López2020, Putnam Reference Putnam, Guijarro Fuentes and Suárez-Gómez2020b).
6. Conclusion and outlook
Our treatment of the realization of tense in North American Norwegian provides a more detailed division of labor concerning the syntactic and phonological requirements responsible for conditioning exponency. Our appeal to spanning has the advantage over assigning indices to
 $\sqrt {{\rm{roots}}} $
of allowing bilinguals to construct similar, if not identical, syntactic units (spans) across different sets of languages. In the absence of this analysis, there is no way to predict whether or not these morphophonological expressions captured in (classes of) exponents are stable.Footnote
11
From the perspective of the phonological module of grammar, appealing to EFP phonology allows us to keep syntax ‘phonology-free’, and to ensure that distributions based on phonological statements are housed in the phonology proper. This furthermore defines the set of exponents that are distinct and require some sort of pre-phonological information or structure to guide the distributions of unpredictable patterns. These statements fall into place if phonology is not restricted to strings, and feature spreading is not the only type of phonological operation that can account for allomorphy (in a broad sense).
$\sqrt {{\rm{roots}}} $
of allowing bilinguals to construct similar, if not identical, syntactic units (spans) across different sets of languages. In the absence of this analysis, there is no way to predict whether or not these morphophonological expressions captured in (classes of) exponents are stable.Footnote
11
From the perspective of the phonological module of grammar, appealing to EFP phonology allows us to keep syntax ‘phonology-free’, and to ensure that distributions based on phonological statements are housed in the phonology proper. This furthermore defines the set of exponents that are distinct and require some sort of pre-phonological information or structure to guide the distributions of unpredictable patterns. These statements fall into place if phonology is not restricted to strings, and feature spreading is not the only type of phonological operation that can account for allomorphy (in a broad sense).
Our spanning/EFP approach to exponency also presents issues that should be pursued in future research. One clear question concerns the extent to which
 $\sqrt {{\rm{roots}}} $
and related exponents may exist in a map of precedence connections that correspond to different syntactic features, e.g. tell/tol-d as a stem t{ϵ,o}l (see Idsardi & Raimy Reference Idsardi, Raimy, Grohmann and Leivadaforthcoming for an analysis of Hebrew on these grounds).Footnote
12
Specifically, should we treat /ϵ/ and /o/ as parallel elements that spell out different span configurations? Following from this question, to what extent can ablaut patterns like this be generalizable over multiple
$\sqrt {{\rm{roots}}} $
and related exponents may exist in a map of precedence connections that correspond to different syntactic features, e.g. tell/tol-d as a stem t{ϵ,o}l (see Idsardi & Raimy Reference Idsardi, Raimy, Grohmann and Leivadaforthcoming for an analysis of Hebrew on these grounds).Footnote
12
Specifically, should we treat /ϵ/ and /o/ as parallel elements that spell out different span configurations? Following from this question, to what extent can ablaut patterns like this be generalizable over multiple
 $\sqrt {{\rm{root}}} $
(sub)classes? Finally, the non-linear nature of representations afforded by EFP phonology opens the possibility that phonological forms originating from different languages may occur in the same SUF. To what extent would such a representation be distinct from competing exponents that spell out the same syntactic structure? That is, does housing this competition in phonological representations or spell-out procedures make different predictions for patterns of cross-linguistic influence? Irrespective of the answers that these and other questions may receive, the late-insertion model adopted here provides a reliable way to conceptualize the complex syntax–phonology interface that mediates exponency, while explicitly operationalizing bilingual representations as a core component of speakers’ generative capabilities.
$\sqrt {{\rm{root}}} $
(sub)classes? Finally, the non-linear nature of representations afforded by EFP phonology opens the possibility that phonological forms originating from different languages may occur in the same SUF. To what extent would such a representation be distinct from competing exponents that spell out the same syntactic structure? That is, does housing this competition in phonological representations or spell-out procedures make different predictions for patterns of cross-linguistic influence? Irrespective of the answers that these and other questions may receive, the late-insertion model adopted here provides a reliable way to conceptualize the complex syntax–phonology interface that mediates exponency, while explicitly operationalizing bilingual representations as a core component of speakers’ generative capabilities.
Acknowledgements
We would like to thank the audiences at the 27th Germanic Linguistics Annual Conference (GLAC) and the 13th Workshop on Immigrant Languages in the Americas (WILA), the editors, and three anonymous reviewers for their critical suggestions and queries, both of which have helped us improve this article. The usual disclaimers apply.
Competing interests
The authors have no competing interests to declare.







 Open access
Open access