




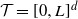
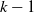
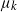
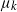
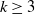
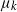
1. Introduction
Cancer is often caused by genetic mutations which disrupt regular cell division and apoptosis, in which case cancerous cells divide much more rapidly compared to healthy cells. This can happen, for example, as soon as several distinct mutations occur and dramatically disrupt cell function. Thus, it is sometimes reasonable to model cancer as occurring after k distinct mutations appear in sequence within a large body.
Mathematical models in which cancer occurs once some cell acquires k mutations date back to the famous 1954 paper [Reference Armitage and Doll1], which proposed a multi-stage model of carcinogenesis in which, once a cell has acquired
 $k-1$
mutations, it acquires a kth mutation at rate
$k-1$
mutations, it acquires a kth mutation at rate
 $\mu_k$
. In this model, the probability of acquiring the kth mutation during a small time interval
$\mu_k$
. In this model, the probability of acquiring the kth mutation during a small time interval
 $(t,t+\textrm{d}t)$
is
$(t,t+\textrm{d}t)$
is
 \begin{align*}\frac{\mu_1\mu_2\cdots\mu_kt^{k-1}}{(k-1)!}\,\textrm{d}t.\end{align*}
\begin{align*}\frac{\mu_1\mu_2\cdots\mu_kt^{k-1}}{(k-1)!}\,\textrm{d}t.\end{align*}
That is, the incidence rate of the kth mutation (at which point the individual becomes cancerous) is proportional to
 $\mu_1\mu_2\cdots\mu_k t^{k-1}$
. This means that cancer risk is proportional to both the mutation rates and the
$\mu_1\mu_2\cdots\mu_k t^{k-1}$
. This means that cancer risk is proportional to both the mutation rates and the
 $(k-1)$
th power of age. More sophisticated models, taking into account the possibilities of cell division and cell death, were later analyzed in [Reference Durrett and Mayberry6, Reference Durrett and Moseley7, Reference Durrett, Schmidt and Schweinsberg9, Reference Iwasa, Michor, Komarova and Nowak12, Reference Iwasa, Michor and Nowak13, Reference Komarova, Sengupta and Nowak15, Reference Moolgavkar and Luebeck17, Reference Moolgavkar and Luebeck18, Reference Schweinsberg24].
$(k-1)$
th power of age. More sophisticated models, taking into account the possibilities of cell division and cell death, were later analyzed in [Reference Durrett and Mayberry6, Reference Durrett and Moseley7, Reference Durrett, Schmidt and Schweinsberg9, Reference Iwasa, Michor, Komarova and Nowak12, Reference Iwasa, Michor and Nowak13, Reference Komarova, Sengupta and Nowak15, Reference Moolgavkar and Luebeck17, Reference Moolgavkar and Luebeck18, Reference Schweinsberg24].
To model some types of cancer, it is important to also include spatial structure in the model. In 1972, [Reference Williams and Bjerknes25] introduced a spatial model of skin cancer now known as the biased voter model. At each site on a lattice, there is an associated binary state indicating whether the site is cancerous or healthy. Each cell divides at a certain rate, and when cell division occurs, the daughter cell replaces one of the neighboring cells chosen at random. The model is biased in that a cancerous cell spreads
 $\kappa>1$
times as fast as a healthy cell. Computer simulations for this model were presented in [Reference Williams and Bjerknes25], and the model was later analyzed mathematically [Reference Bramson and Griffeath3, Reference Bramson and Griffeath4].
$\kappa>1$
times as fast as a healthy cell. Computer simulations for this model were presented in [Reference Williams and Bjerknes25], and the model was later analyzed mathematically [Reference Bramson and Griffeath3, Reference Bramson and Griffeath4].
More recently, [Reference Durrett, Foo and Leder5], building on earlier work in [Reference Durrett and Moseley8, Reference Komarova14], studied a spatial Moran model which is a generalization of the biased voter model. Cells are modeled as points of the discrete torus
 $(\mathbb{Z}\text{ mod }L)^d$
, and each cell is of type
$(\mathbb{Z}\text{ mod }L)^d$
, and each cell is of type
 $i\in\mathbb{N}\cup\{0\}$
. A cell of type
$i\in\mathbb{N}\cup\{0\}$
. A cell of type
 $i-1$
mutates to type i at rate
$i-1$
mutates to type i at rate
 $\mu_i$
. Type i cells have fitness level
$\mu_i$
. Type i cells have fitness level
 $(1+s)^i$
, where
$(1+s)^i$
, where
 $s>0$
measures the selective advantage of one cell over its predecessors. Each cell divides at a rate proportional to its fitness, and then, as in the biased voter model, the daughter cell replaces a randomly chosen neighboring cell. The authors considered the question of how long it takes for some type 2 cell to appear. To simplify the analysis, they introduced a continuous model where cells live inside the torus
$s>0$
measures the selective advantage of one cell over its predecessors. Each cell divides at a rate proportional to its fitness, and then, as in the biased voter model, the daughter cell replaces a randomly chosen neighboring cell. The authors considered the question of how long it takes for some type 2 cell to appear. To simplify the analysis, they introduced a continuous model where cells live inside the torus
 $[0,L]^d$
. This continuous stochastic model approximates the biased voter model because of the Bramson–Griffeath shape theorem [Reference Bramson and Griffeath3, Reference Bramson and Griffeath4], which implies that, conditioned on the survival of the mutations, the cluster of cells in
$[0,L]^d$
. This continuous stochastic model approximates the biased voter model because of the Bramson–Griffeath shape theorem [Reference Bramson and Griffeath3, Reference Bramson and Griffeath4], which implies that, conditioned on the survival of the mutations, the cluster of cells in
 $\mathbb{Z}^d$
with a particular mutation has an asymptotic shape that is a convex subset of
$\mathbb{Z}^d$
with a particular mutation has an asymptotic shape that is a convex subset of
 $\mathbb{R}^d$
. In [Reference Durrett, Foo and Leder5, Section 4], the authors used the continuous model to compute the distribution of the time that the first type 2 cell appears, under certain assumptions on the mutation rates.
$\mathbb{R}^d$
. In [Reference Durrett, Foo and Leder5, Section 4], the authors used the continuous model to compute the distribution of the time that the first type 2 cell appears, under certain assumptions on the mutation rates.
We describe here in more detail this continuous approximation to the biased voter model. The spread of cancer is modeled on the d-dimensional torus
 $\mathcal{T}\;:\!=\;[0,L]^d$
, where the points 0 and L are identified. Note that this is the continuous analog of the space
$\mathcal{T}\;:\!=\;[0,L]^d$
, where the points 0 and L are identified. Note that this is the continuous analog of the space
 $(\mathbb{Z}\text{ mod }L)^d$
considered in [Reference Durrett, Foo and Leder5]. We write
$(\mathbb{Z}\text{ mod }L)^d$
considered in [Reference Durrett, Foo and Leder5]. We write
 $N\;:\!=\;L^d$
to denote the volume of
$N\;:\!=\;L^d$
to denote the volume of
 $\mathcal{T}$
. Each point in
$\mathcal{T}$
. Each point in
 $\mathcal{T}$
is assigned a type, indicating the number of mutations the cell has acquired. At the initial time
$\mathcal{T}$
is assigned a type, indicating the number of mutations the cell has acquired. At the initial time
 $t=0$
, all points in
$t=0$
, all points in
 $\mathcal{T}$
are type 0, meaning they have no mutations. A so-called type 1 mutation then occurs at rate
$\mathcal{T}$
are type 0, meaning they have no mutations. A so-called type 1 mutation then occurs at rate
 $\mu_1$
per unit volume. Once each type 1 mutation appears, it spreads out in a ball at rate
$\mu_1$
per unit volume. Once each type 1 mutation appears, it spreads out in a ball at rate
 $\alpha$
per unit time. This means that t time units after a mutation appears, all points within a distance
$\alpha$
per unit time. This means that t time units after a mutation appears, all points within a distance
 $\alpha t$
of the site where the mutation occurred will have acquired the mutation. Type 1 points then acquire a type 2 mutation at rate
$\alpha t$
of the site where the mutation occurred will have acquired the mutation. Type 1 points then acquire a type 2 mutation at rate
 $\mu_2$
per unit volume, and this process continues indefinitely. In general, type k mutations overtake type
$\mu_2$
per unit volume, and this process continues indefinitely. In general, type k mutations overtake type
 $k-1$
mutations at rate
$k-1$
mutations at rate
 $\mu_k$
per unit volume, and each type k mutation then spreads outward in a ball at rate
$\mu_k$
per unit volume, and each type k mutation then spreads outward in a ball at rate
 $\alpha$
per unit time. A full mathematical construction of this process, starting from Poisson point processes which govern the mutations, is given at the beginning of Section 3.
$\alpha$
per unit time. A full mathematical construction of this process, starting from Poisson point processes which govern the mutations, is given at the beginning of Section 3.
Let
 $\sigma_k$
denote the first time that some cell becomes type k; [Reference Foo, Leder and Schweinsberg11] obtained the asymptotic distribution of
$\sigma_k$
denote the first time that some cell becomes type k; [Reference Foo, Leder and Schweinsberg11] obtained the asymptotic distribution of
 $\sigma_2$
under a wide range of values for the parameters
$\sigma_2$
under a wide range of values for the parameters
 $\alpha$
,
$\alpha$
,
 $\mu_1$
, and
$\mu_1$
, and
 $\mu_2$
, extending the results in [Reference Durrett, Foo and Leder5], and also found the asymptotic distribution of
$\mu_2$
, extending the results in [Reference Durrett, Foo and Leder5], and also found the asymptotic distribution of
 $\sigma_k$
for
$\sigma_k$
for
 $k \geq 3$
assuming equal mutation rates
$k \geq 3$
assuming equal mutation rates
 $\mu_i=\mu$
for all i. In this paper, we will further generalize the results in [Reference Foo, Leder and Schweinsberg11] for
$\mu_i=\mu$
for all i. In this paper, we will further generalize the results in [Reference Foo, Leder and Schweinsberg11] for
 $k \geq 3$
by considering the case where the mutation rates are increasing. We will see that several qualitatively different types of behavior are possible, depending on how fast the mutation rates increase.
$k \geq 3$
by considering the case where the mutation rates are increasing. We will see that several qualitatively different types of behavior are possible, depending on how fast the mutation rates increase.
We mention two biological justifications for assuming increasing mutation rates. A general phenomenon in carcinogenesis was suggested in [Reference Loeb and Loeb16] where there is favorable selection for certain mutations in genes responsible for repairing DNA damage. The increasing genetic instability disrupting DNA repair, in the context of the present paper, would correspond to increasing mutation rates. Also, our model would be of interest in the situation described in [Reference Prindle, Fox and Loeb22], which hypothesized that cancer cells express a mutator phenotype, which causes cells to mutate at a much higher rate, and proposed targeting the mutator phenotype as part of cancer therapy, possibly with the goal of further increasing the mutation rate to the point where the mutations incapacitate or kill malignant cells.
As in [Reference Foo, Leder and Schweinsberg11], we assume that the rate of mutation spread
 $\alpha$
is constant across mutation types, so that successive mutations have equal selective advantage. One possible generalization of our model would be to allow each type i mutation to have a different rate of spread
$\alpha$
is constant across mutation types, so that successive mutations have equal selective advantage. One possible generalization of our model would be to allow each type i mutation to have a different rate of spread
 $\alpha_i$
. However, this more general model is non-trivial even to formulate unless
$\alpha_i$
. However, this more general model is non-trivial even to formulate unless
 $(\alpha_i)_{i=1}^{\infty}$
is decreasing, because if
$(\alpha_i)_{i=1}^{\infty}$
is decreasing, because if
 $\alpha_{i+1}>\alpha_{i}$
, then regions of type
$\alpha_{i+1}>\alpha_{i}$
, then regions of type
 $i+1$
could completely swallow the surrounding type i region. Consequently, it would be necessary to model what happens not only when mutations of types
$i+1$
could completely swallow the surrounding type i region. Consequently, it would be necessary to model what happens not only when mutations of types
 $i+1$
and i compete, but also how mutations of types
$i+1$
and i compete, but also how mutations of types
 $i+1$
and
$i+1$
and
 $j\in \{1,\ldots,i-1\}$
compete. We do not pursue this generalization here.
$j\in \{1,\ldots,i-1\}$
compete. We do not pursue this generalization here.
After computing the limiting distribution of
 $\sigma_k$
, we also find the limiting distribution of the distances between the first mutation of type i and the first mutation of type j, where
$\sigma_k$
, we also find the limiting distribution of the distances between the first mutation of type i and the first mutation of type j, where
 $i < j$
. The distribution of distances between mutations is relevant in studying a phenomenon known as the “cancer field effect”, which refers to the increased risk for certain regions to acquire primary tumors. These regions are called premalignant fields, and they have a high risk of becoming malignant despite appearing to be normal [Reference Foo, Leder and Ryser10]. The size of the premalignant field is clinically relevant when a patient is diagnosed with cancer, because it will determine the area of tissue to be surgically removed in order to avoid cancer recurrence. Surgical removal of premalignant fields, put in the context of this paper, is akin to removing the region with at least i mutations once the first type
$i < j$
. The distribution of distances between mutations is relevant in studying a phenomenon known as the “cancer field effect”, which refers to the increased risk for certain regions to acquire primary tumors. These regions are called premalignant fields, and they have a high risk of becoming malignant despite appearing to be normal [Reference Foo, Leder and Ryser10]. The size of the premalignant field is clinically relevant when a patient is diagnosed with cancer, because it will determine the area of tissue to be surgically removed in order to avoid cancer recurrence. Surgical removal of premalignant fields, put in the context of this paper, is akin to removing the region with at least i mutations once the first type
 $j>i$
mutation appears. The case in which
$j>i$
mutation appears. The case in which
 $i = 1$
and
$i = 1$
and
 $j = 2$
was considered in [Reference Foo, Leder and Ryser10], which characterized the sizes of premalignant fields conditioned on
$j = 2$
was considered in [Reference Foo, Leder and Ryser10], which characterized the sizes of premalignant fields conditioned on
 $\{\sigma_2=t\}$
in
$\{\sigma_2=t\}$
in
 $d\in \{1,2,3\}$
spatial dimensions. These ideas were applied to head and neck cancer in [Reference Ryser, Lee, Ready, Leder and Foo23].
$d\in \{1,2,3\}$
spatial dimensions. These ideas were applied to head and neck cancer in [Reference Ryser, Lee, Ready, Leder and Foo23].
We note that the model that we are studying in this paper independently appeared in the statistical physics literature, where it is known as the polynuclear growth model. It has been studied most extensively in
 $d = 1$
when all of the
$d = 1$
when all of the
 $\mu_k$
are the same [Reference Borodin, Ferrari and Sasamoto2, Reference Prähofer and Spohn19, Reference Prähofer and Spohn20], but the model was also formulated in higher dimensions in [Reference Prähofer and Spohn21]. Most of this work in the statistical physics literature focuses on the long-run growth properties of the surface, and detailed information about the fluctuations has been established when
$\mu_k$
are the same [Reference Borodin, Ferrari and Sasamoto2, Reference Prähofer and Spohn19, Reference Prähofer and Spohn20], but the model was also formulated in higher dimensions in [Reference Prähofer and Spohn21]. Most of this work in the statistical physics literature focuses on the long-run growth properties of the surface, and detailed information about the fluctuations has been established when
 $d = 1$
. This is quite different from our goal of understanding the time to acquire a fixed number of mutations.
$d = 1$
. This is quite different from our goal of understanding the time to acquire a fixed number of mutations.
In Section 2 we introduce some basic notation and state our main results, as well as some heuristics explaining why these results are true. In Section 3 we prove the limit theorems regarding the time to wait for k mutations, and in Section 4 we prove the limit theorems for the distances between mutations.
2. Main results and heuristics
We first introduce some notation that we will need before stating the results. Given two sequences of non-negative real numbers
 $(a_N)_{N=1}^{\infty}$
and
$(a_N)_{N=1}^{\infty}$
and
 $(b_N)_{N=1}^{\infty}$
, we write:
$(b_N)_{N=1}^{\infty}$
, we write:
 \begin{align*} &a_N \sim b_N \text{ if } \lim_{N\to\infty}a_N/b_N=1; \\[5pt] &a_N \ll b_N \text{ if } \lim_{N\to \infty}a_N/b_N=0 \text{ and } a_N\gg b_N \text{ if } \lim_{N\to\infty}a_N/b_N=\infty; \\[5pt] &a_N \asymp b_N \text{ if } 0<\liminf_{N\to \infty}a_N/b_N\leq \limsup_{N\to \infty}a_N/b_N<\infty; \\[5pt] &a_N \lesssim b_N \text{ if } \limsup_{N\to\infty} a_N/b_N<\infty.\end{align*}
\begin{align*} &a_N \sim b_N \text{ if } \lim_{N\to\infty}a_N/b_N=1; \\[5pt] &a_N \ll b_N \text{ if } \lim_{N\to \infty}a_N/b_N=0 \text{ and } a_N\gg b_N \text{ if } \lim_{N\to\infty}a_N/b_N=\infty; \\[5pt] &a_N \asymp b_N \text{ if } 0<\liminf_{N\to \infty}a_N/b_N\leq \limsup_{N\to \infty}a_N/b_N<\infty; \\[5pt] &a_N \lesssim b_N \text{ if } \limsup_{N\to\infty} a_N/b_N<\infty.\end{align*}
We also define the following notation:
-
If
 $X_N$
converges to X in distribution, we write
$X_N\Rightarrow X$
.
$X_N$
converges to X in distribution, we write
$X_N\Rightarrow X$
. -
If
$X_N$
converges to X in probability, we write
$X_N\to_\textrm{p} X$
. -
$\gamma_d$
denotes the volume of the unit ball in
$\mathbb{R}^d$
.
-
For each
$k\geq 1$
and
$j \geq 1$
, we define (1)We explain how
\begin{align} \beta_k\;:\!=\;\Bigg(N\alpha^{(k-1)d}\prod_{i=1}^{k}\mu_i\Bigg)^{-1/((k-1)d+k)}, \qquad \kappa_j\;:\!=\;(\mu_j\alpha^d)^{-1/(d+1)}. \end{align}
$\beta_k$
and
$\kappa_j$
arise in Sections 2.3 and 2.5, respectively.
-
$\sigma_k$
denotes the first time a mutation of type k appears, and
$\sigma_k^{(2)}$
denotes the second time a mutation of type k appears. More rigorous definitions of
$\sigma_k$
and
$\sigma_k^{(2)}$
are given in Sections 3 and 4, respectively.















All limits in this paper will be taken as
 $N \rightarrow \infty$
. The mutation rates
$N \rightarrow \infty$
. The mutation rates
 $(\mu_i)_{i=1}^{\infty}$
and the rate of mutation spread
$(\mu_i)_{i=1}^{\infty}$
and the rate of mutation spread
 $\alpha$
will depend on N, even though this dependence is not recorded in the notation. Throughout the paper we will assume that the mutation rates
$\alpha$
will depend on N, even though this dependence is not recorded in the notation. Throughout the paper we will assume that the mutation rates
 $(\mu_i)_{i=1}^{\infty}$
are asymptotically increasing, i.e.
$(\mu_i)_{i=1}^{\infty}$
are asymptotically increasing, i.e.
 \begin{align} \mu_1\lesssim \mu_2\lesssim \mu_3\lesssim \cdots .\end{align}
\begin{align} \mu_1\lesssim \mu_2\lesssim \mu_3\lesssim \cdots .\end{align}
2.1. Theorem 1: Low mutation rates
Assume
 \begin{align*} \mu_1\ll \frac{\alpha}{N^{(d+1)/d}} \text{ and } \frac{\mu_i}{\mu_1}\to c_i\in (0,\infty]\text{ for all }i\in \{1,\ldots,k\}.\end{align*}
\begin{align*} \mu_1\ll \frac{\alpha}{N^{(d+1)/d}} \text{ and } \frac{\mu_i}{\mu_1}\to c_i\in (0,\infty]\text{ for all }i\in \{1,\ldots,k\}.\end{align*}
The first time a mutation of type 1 appears is exponentially distributed with rate
 $N\mu_1$
. The maximal distance between any two points on the torus
$N\mu_1$
. The maximal distance between any two points on the torus
 $\mathcal{T}=[0,L]^d$
is
$\mathcal{T}=[0,L]^d$
is
 $\sqrt{d}L/2$
. Also note that
$\sqrt{d}L/2$
. Also note that
 $L=N^{1/d}$
, where N is the volume of
$L=N^{1/d}$
, where N is the volume of
 $\mathcal{T}$
. Consequently, once the first type 1 mutation appears, it will spread to the entire torus in time
$\mathcal{T}$
. Consequently, once the first type 1 mutation appears, it will spread to the entire torus in time
 $\sqrt{d}L/(2\alpha)=\sqrt{d}N^{1/d}/(2\alpha)$
. Hence, as noted in [Reference Foo, Leder and Schweinsberg11], the time required for a type 1 mutation to fixate once it has first appeared is much shorter than
$\sqrt{d}L/(2\alpha)=\sqrt{d}N^{1/d}/(2\alpha)$
. Hence, as noted in [Reference Foo, Leder and Schweinsberg11], the time required for a type 1 mutation to fixate once it has first appeared is much shorter than
 $\sigma_1$
precisely when
$\sigma_1$
precisely when
 $N^{1/d}/\alpha\ll 1/(N\mu_1)$
, which is equivalent to
$N^{1/d}/\alpha\ll 1/(N\mu_1)$
, which is equivalent to
 $\mu_1\ll \alpha/N^{(d+1)/d}$
.
$\mu_1\ll \alpha/N^{(d+1)/d}$
.
Now, because of the second assumption
 $\mu_i/\mu_1\to c_i \in (0,\infty]$
, mutations of types
$\mu_i/\mu_1\to c_i \in (0,\infty]$
, mutations of types
 $i\in \{2,\ldots,k\}$
appear at least as fast as the first mutation. If
$i\in \{2,\ldots,k\}$
appear at least as fast as the first mutation. If
 $c_i<\infty$
, then the waiting times
$c_i<\infty$
, then the waiting times
 $\sigma_1$
and
$\sigma_1$
and
 $\sigma_i-\sigma_{i-1}$
are on the same order of magnitude. Because we have
$\sigma_i-\sigma_{i-1}$
are on the same order of magnitude. Because we have
 $\sigma_1\sim \text{Exponential}(N\mu_1c_1)$
, it follows that
$\sigma_1\sim \text{Exponential}(N\mu_1c_1)$
, it follows that
 $\sigma_i-\sigma_{i-1}$
is also exponentially distributed and that
$\sigma_i-\sigma_{i-1}$
is also exponentially distributed and that
 $\sigma_i-\sigma_{i-1}\sim\text{Exponential}(N\mu_1c_i)$
. Otherwise, if
$\sigma_i-\sigma_{i-1}\sim\text{Exponential}(N\mu_1c_i)$
. Otherwise, if
 $c_i=\infty$
, then the first type i mutation appears so quickly that its waiting time
$c_i=\infty$
, then the first type i mutation appears so quickly that its waiting time
 $\sigma_i-\sigma_{i-1}$
is negligible as
$\sigma_i-\sigma_{i-1}$
is negligible as
 $N\to\infty$
. Putting everything together gives us the following theorem. This result is a very slight generalization of [Reference Foo, Leder and Schweinsberg11, Theorem 1], and is proved by the same method.
$N\to\infty$
. Putting everything together gives us the following theorem. This result is a very slight generalization of [Reference Foo, Leder and Schweinsberg11, Theorem 1], and is proved by the same method.
Theorem 1.
Suppose (2) holds, and
 $\mu_1 \ll \alpha/N^{(d+1)/d}$
. Suppose that, for all
$\mu_1 \ll \alpha/N^{(d+1)/d}$
. Suppose that, for all
 $i\in \{1,\ldots,k\}$
, we have
$i\in \{1,\ldots,k\}$
, we have
 ${\mu_i}/{\mu_1}\to c_i\in (0,\infty]$
. Let
${\mu_i}/{\mu_1}\to c_i\in (0,\infty]$
. Let
 $W_1,\ldots,W_k$
be independent random variables with
$W_1,\ldots,W_k$
be independent random variables with
 $W_i\sim \textrm{Exponential}(c_i)$
if
$W_i\sim \textrm{Exponential}(c_i)$
if
 $c_i<\infty$
and
$c_i<\infty$
and
 $W_i=0$
if
$W_i=0$
if
 $c_i=\infty$
. Then
$c_i=\infty$
. Then
 $N\mu_1\sigma_k\Rightarrow W_1+\cdots+W_k$
.
$N\mu_1\sigma_k\Rightarrow W_1+\cdots+W_k$
.
Figure 1 illustrates that once a type i mutation appears, it quickly fills up the whole torus, and then a type
 $i+1$
mutation occurs.
$i+1$
mutation occurs.

Figure 1. Mutations transition from type i to type
 $i+1$
. Higher mutation types are colored darker than lower mutation types.
$i+1$
. Higher mutation types are colored darker than lower mutation types.
2.2. Theorem 2: Type
$\boldsymbol{j}\geq 2$
mutations occur rapidly after
$\sigma_1$


Assume
 \begin{equation} \mu_1\gg \frac{\alpha}{N^{(d+1)/d}}, \qquad \mu_2\gg \frac{(N\mu_1)^{d+1}}{\alpha^d}.\end{equation}
\begin{equation} \mu_1\gg \frac{\alpha}{N^{(d+1)/d}}, \qquad \mu_2\gg \frac{(N\mu_1)^{d+1}}{\alpha^d}.\end{equation}
In contrast to Theorem 1, the assumption
 $\mu_1\gg \alpha/N^{(d+1)/d}$
means that the time it takes for type 1 mutations to spread to the entire torus is much longer than
$\mu_1\gg \alpha/N^{(d+1)/d}$
means that the time it takes for type 1 mutations to spread to the entire torus is much longer than
 $\sigma_1$
. As a result, there will be many growing balls of type 1 mutations before any of these balls can fill the entire torus. However, if mutations of types
$\sigma_1$
. As a result, there will be many growing balls of type 1 mutations before any of these balls can fill the entire torus. However, if mutations of types
 $2, 3, \dots, k$
appear quickly after the first type 1 mutation appears, then the time to wait for the first type k mutation will be close to the time to wait for the first type 1 mutation. We consider here the conditions under which this will be the case.
$2, 3, \dots, k$
appear quickly after the first type 1 mutation appears, then the time to wait for the first type k mutation will be close to the time to wait for the first type 1 mutation. We consider here the conditions under which this will be the case.
First, consider the ball of type 1 cells resulting from the initial type 1 mutation at time
 $\sigma_1$
. Assuming t is small enough that, by time
$\sigma_1$
. Assuming t is small enough that, by time
 $\sigma_1 + t$
, the ball has not started overlapping itself by wrapping around the torus, the ball will have volume
$\sigma_1 + t$
, the ball has not started overlapping itself by wrapping around the torus, the ball will have volume
 $\gamma_d (\alpha t)^d$
at time t. Then the probability that the first type 2 mutation appears in that ball before time t is
$\gamma_d (\alpha t)^d$
at time t. Then the probability that the first type 2 mutation appears in that ball before time t is
 \begin{align} 1-\exp\!\bigg({-}\int_0^{t}\mu_2\gamma_d(\alpha r)^d \,\textrm{d}r \bigg) = 1-\exp\!\bigg({-}\frac{\gamma_d}{d+1}\mu_2\alpha^d t^{d+1}\bigg).\end{align}
\begin{align} 1-\exp\!\bigg({-}\int_0^{t}\mu_2\gamma_d(\alpha r)^d \,\textrm{d}r \bigg) = 1-\exp\!\bigg({-}\frac{\gamma_d}{d+1}\mu_2\alpha^d t^{d+1}\bigg).\end{align}
It follows that the first time a type 2 mutation occurs in this ball is on the order of
 $(\mu_2\alpha^d)^{-1/(d+1)}$
. Hence, whenever
$(\mu_2\alpha^d)^{-1/(d+1)}$
. Hence, whenever
 $(\mu_2\alpha^d)^{-1/(d+1)}\ll 1/(N\mu_1)$
, which is equivalent to the second assumption in (3), it follows that
$(\mu_2\alpha^d)^{-1/(d+1)}\ll 1/(N\mu_1)$
, which is equivalent to the second assumption in (3), it follows that
 $\sigma_2-\sigma_1$
is much quicker than
$\sigma_2-\sigma_1$
is much quicker than
 $\sigma_1$
. From this heuristic, we see that
$\sigma_1$
. From this heuristic, we see that
 $N\mu_1(\sigma_2-\sigma_1)\to_\textrm{p} 0$
. Repeating this reasoning with types
$N\mu_1(\sigma_2-\sigma_1)\to_\textrm{p} 0$
. Repeating this reasoning with types
 $j-1$
and j in place of types 1 and 2, we see that
$j-1$
and j in place of types 1 and 2, we see that
 $\sigma_j-\sigma_{j-1}$
is much quicker than
$\sigma_j-\sigma_{j-1}$
is much quicker than
 $\sigma_1$
when
$\sigma_1$
when
 $(\mu_j\alpha^d)^{-1/(d+1)}\ll 1/(N\mu_1)$
, or, equivalently,
$(\mu_j\alpha^d)^{-1/(d+1)}\ll 1/(N\mu_1)$
, or, equivalently,
 $\mu_j\gg (N\mu_1)^{d+1}/\alpha^d$
. However, this follows from the second assumption in (3) because of (2). Hence, we also have
$\mu_j\gg (N\mu_1)^{d+1}/\alpha^d$
. However, this follows from the second assumption in (3) because of (2). Hence, we also have
 $N\mu_1(\sigma_j-\sigma_{j-1})\to_\textrm{p} 0$
. Putting everything together, when N is large,
$N\mu_1(\sigma_j-\sigma_{j-1})\to_\textrm{p} 0$
. Putting everything together, when N is large,
 \begin{align*}N\mu_1\sigma_k= N\mu_1\sigma_1+N\mu_1(\sigma_2-\sigma_1)+\cdots+N\mu_1(\sigma_k-\sigma_{k-1})\approx N\mu_1\sigma_1.\end{align*}
\begin{align*}N\mu_1\sigma_k= N\mu_1\sigma_1+N\mu_1(\sigma_2-\sigma_1)+\cdots+N\mu_1(\sigma_k-\sigma_{k-1})\approx N\mu_1\sigma_1.\end{align*}
This gives us the following theorem. We note that the
 $k=2$
case was proved in [Reference Durrett, Foo and Leder5, Theorem 3] using essentially the same reasoning as above.
$k=2$
case was proved in [Reference Durrett, Foo and Leder5, Theorem 3] using essentially the same reasoning as above.

Figure 2. Once the first type 1 mutation appears, the type 2, 3, and 4 mutations all happen quickly. Higher mutation types are colored darker than lower mutation types.
Theorem 2.
Suppose (2) holds. Suppose
 $\mu_1\gg \alpha/N^{(d+1)/d}$
and
$\mu_1\gg \alpha/N^{(d+1)/d}$
and
 $\mu_2\gg (N\mu_1)^{d+1}/\alpha^d$
. For all
$\mu_2\gg (N\mu_1)^{d+1}/\alpha^d$
. For all
 $k \geq 2$
,
$k \geq 2$
,
 $N\mu_1\sigma_k\Rightarrow W$
, where
$N\mu_1\sigma_k\Rightarrow W$
, where
 $W\sim \textrm{Exponential}(1)$
.
$W\sim \textrm{Exponential}(1)$
.
A pictorial representation is given in Fig. 2, where the nested circles correspond to mutations of types
 $1,\ldots,k$
for
$1,\ldots,k$
for
 $k=4$
.
$k=4$
.
2.3. Theorem 3: Type
$\boldsymbol{j}\in \{1,\ldots,\boldsymbol{k}-1\}$
mutations appear many times

Assume
 \begin{equation} \mu_1\gg \frac{\alpha}{N^{(d+1)/d}}, \qquad \mu_k\ll \frac{1}{\alpha^d\beta^{d+1}_{k-1}}.\end{equation}
\begin{equation} \mu_1\gg \frac{\alpha}{N^{(d+1)/d}}, \qquad \mu_k\ll \frac{1}{\alpha^d\beta^{d+1}_{k-1}}.\end{equation}
As in Theorem 2, the first assumption ensures that
 $\sigma_1$
is shorter than the time it takes for type 1 mutations to fixate once they appear. The second assumption ensures that all mutations of types up to k do not appear too quickly, so that we are not in the setting of Theorem 2. In particular, note that when
$\sigma_1$
is shorter than the time it takes for type 1 mutations to fixate once they appear. The second assumption ensures that all mutations of types up to k do not appear too quickly, so that we are not in the setting of Theorem 2. In particular, note that when
 $k=2$
, we have
$k=2$
, we have
 $\beta_{k-1}=(N\mu_1)^{-1}$
, and the second assumption reduces to
$\beta_{k-1}=(N\mu_1)^{-1}$
, and the second assumption reduces to
 $\mu_2\ll (N\mu_1)^{d+1}/\alpha^d$
. When (5) holds, for
$\mu_2\ll (N\mu_1)^{d+1}/\alpha^d$
. When (5) holds, for
 $j \in \{2, \dots, k\}$
there will be many small balls of type
$j \in \{2, \dots, k\}$
there will be many small balls of type
 $j-1$
before any type j mutation appears. In this case, we will be able to use a ‘law of large numbers’ established in [Reference Foo, Leder and Schweinsberg11] to approximate the total volume of type
$j-1$
before any type j mutation appears. In this case, we will be able to use a ‘law of large numbers’ established in [Reference Foo, Leder and Schweinsberg11] to approximate the total volume of type
 $j-1$
regions with its expectation.
$j-1$
regions with its expectation.
To explain what happens in this case, we review a derivation from [Reference Foo, Leder and Schweinsberg11]. We want to define an approximation
 $v_j(t)$
to the total volume of regions with at least j mutations at time t. We set
$v_j(t)$
to the total volume of regions with at least j mutations at time t. We set
 $v_0(t)\equiv N$
. Next, let
$v_0(t)\equiv N$
. Next, let
 $t>0$
. For times
$t>0$
. For times
 $r\in [0,t]$
, type j mutations occur at rate
$r\in [0,t]$
, type j mutations occur at rate
 $\mu_jv_{j-1}(r)$
, and these type j mutations each grow into a ball of size
$\mu_jv_{j-1}(r)$
, and these type j mutations each grow into a ball of size
 $\gamma_d(\alpha(t-r))^d$
by time t. Therefore, we define
$\gamma_d(\alpha(t-r))^d$
by time t. Therefore, we define
 \begin{equation*} v_j(t) = \int_{0}^{t}\mu_jv_{j-1}(r)\gamma_d(\alpha(t-r))^d \,\textrm{d}r.\end{equation*}
\begin{equation*} v_j(t) = \int_{0}^{t}\mu_jv_{j-1}(r)\gamma_d(\alpha(t-r))^d \,\textrm{d}r.\end{equation*}
Note that this gives a good approximation to the volume of the type j region because we have many mostly non-overlapping balls of type j. In [Reference Foo, Leder and Schweinsberg11] it is shown using induction that
 \begin{align*}v_j(t)=\frac{\gamma_d^j(d!)^j}{(j(d+1))!}\Bigg(\prod_{i=1}^{j}\mu_i\Bigg)N\alpha^{jd}t^{j(d+1)},\end{align*}
\begin{align*}v_j(t)=\frac{\gamma_d^j(d!)^j}{(j(d+1))!}\Bigg(\prod_{i=1}^{j}\mu_i\Bigg)N\alpha^{jd}t^{j(d+1)},\end{align*}
which gives us the approximation
 \begin{align*} \mathbb{P}(\sigma_k>t) &\approx \exp\!\bigg({-}\int_{0}^{t}\mu_kv_{k-1}(r)\,\textrm{d} r\bigg) \\[5pt] &= \exp\!\Bigg({-}\frac{\gamma_d^{k-1}(d!)^{k-1}}{((k-1)d+k)!} \Bigg(\prod_{i=1}^{k}\mu_i\Bigg)N\alpha^{(k-1)d}t^{(k-1)d+k}\Bigg).\end{align*}
\begin{align*} \mathbb{P}(\sigma_k>t) &\approx \exp\!\bigg({-}\int_{0}^{t}\mu_kv_{k-1}(r)\,\textrm{d} r\bigg) \\[5pt] &= \exp\!\Bigg({-}\frac{\gamma_d^{k-1}(d!)^{k-1}}{((k-1)d+k)!} \Bigg(\prod_{i=1}^{k}\mu_i\Bigg)N\alpha^{(k-1)d}t^{(k-1)d+k}\Bigg).\end{align*}
It will follow that if we define
 $\beta_k$
as in (1), then we have the following result.
$\beta_k$
as in (1), then we have the following result.
Theorem 3.
Suppose (2) holds. Let
 $k\geq 2$
, and suppose
$k\geq 2$
, and suppose
 $\mu_1\gg \alpha/N^{(d+1)/d}$
and
$\mu_1\gg \alpha/N^{(d+1)/d}$
and
 $\mu_k\ll 1/(\alpha^d\beta_{k-1}^{d+1})$
. Then, for
$\mu_k\ll 1/(\alpha^d\beta_{k-1}^{d+1})$
. Then, for
 $t>0$
,
$t>0$
,
 \begin{align*}\mathbb{P}(\sigma_k>\beta_kt) \to \exp\!\bigg({-}\frac{\gamma_d^{k-1}(d!)^{k-1}}{((k-1)d+k)!}t^{(k-1)d+k}\bigg).\end{align*}
\begin{align*}\mathbb{P}(\sigma_k>\beta_kt) \to \exp\!\bigg({-}\frac{\gamma_d^{k-1}(d!)^{k-1}}{((k-1)d+k)!}t^{(k-1)d+k}\bigg).\end{align*}
When we have equal mutation rates (i.e.
 $\mu_i=\mu$
for all i), the result above is covered by [Reference Foo, Leder and Schweinsberg11, Theorem 10, part 3]. The form of the result and the strategy of the proof are exactly the same in the more general case when the mutation rates can differ. Theorem 3 is illustrated in Fig. 3 for
$\mu_i=\mu$
for all i), the result above is covered by [Reference Foo, Leder and Schweinsberg11, Theorem 10, part 3]. The form of the result and the strategy of the proof are exactly the same in the more general case when the mutation rates can differ. Theorem 3 is illustrated in Fig. 3 for
 $k=3$
.
$k=3$
.

Figure 3. Mutations of types 1, 2, and 3 appear in succession. Higher mutation types are colored darker than lower mutation types.
2.4. Theorem 4: An intermediate case between Theorems 2 and 3
Assume
 $\mu_1\gg{\alpha}/{N^{(d+1)/d}}$
. We first define
$\mu_1\gg{\alpha}/{N^{(d+1)/d}}$
. We first define
 \begin{equation} l\;:\!=\;\max\Bigg\{j\geq 2\colon\mu_j\ll \frac{1}{\alpha^d\beta_{j-1}^{d+1}}\Bigg\}.\end{equation}
\begin{equation} l\;:\!=\;\max\Bigg\{j\geq 2\colon\mu_j\ll \frac{1}{\alpha^d\beta_{j-1}^{d+1}}\Bigg\}.\end{equation}
It follows from (2) that if
 $\mu_j\ll 1/\big(\alpha^d\beta_{j-1}^{d+1}\big)$
, then
$\mu_j\ll 1/\big(\alpha^d\beta_{j-1}^{d+1}\big)$
, then
 $\mu_{j-1} \ll 1/\big(\alpha^d\beta_{j-1}^{d+1}\big)$
, which by Lemma 2 below implies that
$\mu_{j-1} \ll 1/\big(\alpha^d\beta_{j-1}^{d+1}\big)$
, which by Lemma 2 below implies that
 $\mu_{j-1} \ll 1/\big(\alpha^d\beta_{j-2}^{d+1}\big)$
. It follows that
$\mu_{j-1} \ll 1/\big(\alpha^d\beta_{j-2}^{d+1}\big)$
. It follows that
 \begin{equation} l=\max\Bigg\{j\geq 2\colon\mu_2\ll \frac{1}{\alpha^d \beta^{d+1}_{1}},\, \mu_3\ll \frac{1}{\alpha^d \beta^{d+1}_{2}},\ldots,\, \mu_j\ll \frac{1}{\alpha^d \beta^{d+1}_{j-1}}\Bigg\}.\end{equation}
\begin{equation} l=\max\Bigg\{j\geq 2\colon\mu_2\ll \frac{1}{\alpha^d \beta^{d+1}_{1}},\, \mu_3\ll \frac{1}{\alpha^d \beta^{d+1}_{2}},\ldots,\, \mu_j\ll \frac{1}{\alpha^d \beta^{d+1}_{j-1}}\Bigg\}.\end{equation}
Intuitively, l is the largest index for which mutations of types
 $1,2,\ldots,l$
behave exactly as in Theorem 3. The definition of l in (6) omits the possibility
$1,2,\ldots,l$
behave exactly as in Theorem 3. The definition of l in (6) omits the possibility
 $l=1$
, since
$l=1$
, since
 $\beta_0$
is undefined. However, if we define
$\beta_0$
is undefined. However, if we define
 $l = 1$
when the set over which we take the maximum in (6) is empty, then Theorem 4 below when
$l = 1$
when the set over which we take the maximum in (6) is empty, then Theorem 4 below when
 $l = 1$
is the same as Theorem 2. On the other hand, if
$l = 1$
is the same as Theorem 2. On the other hand, if
 $l \in \{k,k+1,\ldots\}\cup \{\infty\}$
, then by (7) we have
$l \in \{k,k+1,\ldots\}\cup \{\infty\}$
, then by (7) we have
 $\mu_k\ll 1/\big(\alpha^d\beta_{k-1}^{d+1}\big)$
, in which case Theorem 3 applies. Hence, we assume
$\mu_k\ll 1/\big(\alpha^d\beta_{k-1}^{d+1}\big)$
, in which case Theorem 3 applies. Hence, we assume
 $l\in \{2,\ldots,k-1\}$
and
$l\in \{2,\ldots,k-1\}$
and
 \begin{align} \mu_{l+1}\gg \frac{1}{\alpha^d\beta_l^{d+1}}.\end{align}
\begin{align} \mu_{l+1}\gg \frac{1}{\alpha^d\beta_l^{d+1}}.\end{align}
The situation in Theorem 4 is a hybrid of Theorems 2 and 3. A mutation of type
 $j\in \{1,\ldots,l-1\}$
takes a longer time to fixate in the torus than the interarrival time
$j\in \{1,\ldots,l-1\}$
takes a longer time to fixate in the torus than the interarrival time
 $\sigma_{j}-\sigma_{j-1}$
. As a result, if
$\sigma_{j}-\sigma_{j-1}$
. As a result, if
 $j\in \{2,\ldots,l\}$
, there will be many mostly non-overlapping balls of type
$j\in \{2,\ldots,l\}$
, there will be many mostly non-overlapping balls of type
 $j-1$
before time
$j-1$
before time
 $\sigma_j$
. Using this fact, we proceed as in Theorem 3 and find
$\sigma_j$
. Using this fact, we proceed as in Theorem 3 and find
 $\lim_{N\to\infty}\mathbb{P}(\sigma_l>\beta_lt)$
. Next, our assumption in (8) places us in the regime of Theorem 2; all mutations of types
$\lim_{N\to\infty}\mathbb{P}(\sigma_l>\beta_lt)$
. Next, our assumption in (8) places us in the regime of Theorem 2; all mutations of types
 $l+1,\ldots,k$
happen so quickly that for all
$l+1,\ldots,k$
happen so quickly that for all
 $\varepsilon>0$
we have
$\varepsilon>0$
we have
 $\mathbb{P}(\sigma_k-\sigma_l>\beta_l\varepsilon)\to 0$
. Then, combining these two results yields the following theorem.
$\mathbb{P}(\sigma_k-\sigma_l>\beta_l\varepsilon)\to 0$
. Then, combining these two results yields the following theorem.
Theorem 4.
Suppose (2) holds, and suppose
 $\mu_1\gg \alpha/N^{(d+1)/d}$
. Suppose also that
$\mu_1\gg \alpha/N^{(d+1)/d}$
. Suppose also that
 $l\in \{2,\ldots,k-1\}$
and that
$l\in \{2,\ldots,k-1\}$
and that
 $\mu_{l+1}\gg 1/\big(\alpha^d\beta_l^{d+1}\big)$
. Then, for
$\mu_{l+1}\gg 1/\big(\alpha^d\beta_l^{d+1}\big)$
. Then, for
 $t>0$
,
$t>0$
,
 \begin{align*}\mathbb{P}(\sigma_k>\beta_l t)\to \exp\!\bigg({-}\frac{\gamma_d^{l-1}(d!)^{l-1}}{((l-1)d+l)!}t^{(l-1)d+l}\bigg).\end{align*}
\begin{align*}\mathbb{P}(\sigma_k>\beta_l t)\to \exp\!\bigg({-}\frac{\gamma_d^{l-1}(d!)^{l-1}}{((l-1)d+l)!}t^{(l-1)d+l}\bigg).\end{align*}
In pictures, Theorem 4 looks like Fig. 3 for mutations up to type l. Then, once the first type l mutation appears and spreads in a circle, all the subsequent mutations become nested within that circle, similar to Fig. 2.
Remark 1. Theorems 1–4 cover most of the possible cases in which (2) holds. However, we assume that either
 $\mu_1 \ll \alpha/N^{(d+1)/d}$
or
$\mu_1 \ll \alpha/N^{(d+1)/d}$
or
 $\mu_1 \gg \alpha/N^{(d+1)/d}$
. In the case
$\mu_1 \gg \alpha/N^{(d+1)/d}$
. In the case
 $\mu_1 \asymp \alpha/N^{(d+1)/d}$
, we expect that at the time a type 2 mutation appears, there could be several overlapping type 1 balls whose size is comparable to the size of the torus, and we do not expect the limiting distribution of
$\mu_1 \asymp \alpha/N^{(d+1)/d}$
, we expect that at the time a type 2 mutation appears, there could be several overlapping type 1 balls whose size is comparable to the size of the torus, and we do not expect the limiting distribution of
 $\sigma_k$
to have a simple expression. Consequently, we do not pursue this case here. We note that if
$\sigma_k$
to have a simple expression. Consequently, we do not pursue this case here. We note that if
 $\mu_1 \asymp \alpha/N^{(d+1)/d}$
and all mutation rates are equal (i.e.
$\mu_1 \asymp \alpha/N^{(d+1)/d}$
and all mutation rates are equal (i.e.
 $\mu_i=\mu$
for all i), then it is proven, as a special case of [Reference Foo, Leder and Schweinsberg11, Theorem 12], that
$\mu_i=\mu$
for all i), then it is proven, as a special case of [Reference Foo, Leder and Schweinsberg11, Theorem 12], that
 $N\mu\sigma_k$
converges in distribution to a non-degenerate random variable for every
$N\mu\sigma_k$
converges in distribution to a non-degenerate random variable for every
 $k\geq 1$
. Likewise, we do not consider the case in which, instead of (8), we have
$k\geq 1$
. Likewise, we do not consider the case in which, instead of (8), we have
 $\mu_{l+1} \asymp 1/\big(\alpha^d \beta_l^{d+1}\big)$
. In this case we believe there could be several overlapping type l balls at the time the first type
$\mu_{l+1} \asymp 1/\big(\alpha^d \beta_l^{d+1}\big)$
. In this case we believe there could be several overlapping type l balls at the time the first type
 $l+1$
mutation occurs, again preventing there from being a simple expression for the limit distribution.
$l+1$
mutation occurs, again preventing there from being a simple expression for the limit distribution.
2.5. Distances between mutations
For
 $1\leq i<j$
, define
$1\leq i<j$
, define
 $D_{i,j}$
to be the distance in the torus between the location of the first mutation of type j and the location of the first mutation of type i. Also define
$D_{i,j}$
to be the distance in the torus between the location of the first mutation of type j and the location of the first mutation of type i. Also define
 $D_{i+1}\;:\!=\;D_{i,i+1}$
.
$D_{i+1}\;:\!=\;D_{i,i+1}$
.
Consider the setting of Theorem 2. We will assume a stronger version of (2):
 \begin{equation} \mu_2\ll \mu_3\ll \mu_4\ll \cdots.\end{equation}
\begin{equation} \mu_2\ll \mu_3\ll \mu_4\ll \cdots.\end{equation}
Recall that the mutations appear in nested balls as in Fig. 2. Because the first type
 $j+1$
mutation will therefore appear before the second type j mutation with high probability, we can calculate, as in (4), that
$j+1$
mutation will therefore appear before the second type j mutation with high probability, we can calculate, as in (4), that
 \begin{align*}\mathbb{P}(\sigma_{j+1}-\sigma_j>t) \approx \exp\!\bigg({-}\frac{\mu_{j+1}\gamma_d\alpha^d}{d+1}t^{d+1}\bigg).\end{align*}
\begin{align*}\mathbb{P}(\sigma_{j+1}-\sigma_j>t) \approx \exp\!\bigg({-}\frac{\mu_{j+1}\gamma_d\alpha^d}{d+1}t^{d+1}\bigg).\end{align*}
It follows that if we define
 $\kappa_{j+1}$
as in (1), then
$\kappa_{j+1}$
as in (1), then
 \begin{align*}\mathbb{P}(\sigma_{j+1}-\sigma_j>\kappa_{j+1}t) \approx \exp\!\bigg({-}\frac{\gamma_d}{d+1}t^{d+1}\bigg).\end{align*}
\begin{align*}\mathbb{P}(\sigma_{j+1}-\sigma_j>\kappa_{j+1}t) \approx \exp\!\bigg({-}\frac{\gamma_d}{d+1}t^{d+1}\bigg).\end{align*}
With this, we can calculate the approximate density f(t) of
 $(\sigma_{j+1}-\sigma_j)/\kappa_{j+1}$
. This allows us to calculate
$(\sigma_{j+1}-\sigma_j)/\kappa_{j+1}$
. This allows us to calculate
 \begin{align*}\mathbb{P}\bigg(\frac{D_{j+1}}{\alpha\kappa_{j+1}}\leq s \bigg) \approx \int_{0}^{\infty}\mathbb{P}\bigg(\frac{D_{j+1}}{\alpha\kappa_{j+1}}\leq s\mid\frac{\sigma_{j+1}-\sigma_j}{\kappa_{j+1}}=t \bigg)f(t)\,\textrm{d} t.\end{align*}
\begin{align*}\mathbb{P}\bigg(\frac{D_{j+1}}{\alpha\kappa_{j+1}}\leq s \bigg) \approx \int_{0}^{\infty}\mathbb{P}\bigg(\frac{D_{j+1}}{\alpha\kappa_{j+1}}\leq s\mid\frac{\sigma_{j+1}-\sigma_j}{\kappa_{j+1}}=t \bigg)f(t)\,\textrm{d} t.\end{align*}
The location of the first type
 $j+1$
mutation conditioned on
$j+1$
mutation conditioned on
 $\sigma_{j+1}-\sigma_j=\kappa_{j+1}t$
is a uniformly random point on a d-dimensional ball of radius
$\sigma_{j+1}-\sigma_j=\kappa_{j+1}t$
is a uniformly random point on a d-dimensional ball of radius
 $\alpha\kappa_{j+1}t$
. This allows us to calculate
$\alpha\kappa_{j+1}t$
. This allows us to calculate
 $\lim_{N\to\infty}\mathbb{P}(D_{j+1}\leq \alpha\kappa_{j+1}s)$
. Next, because of (9), mutations of types
$\lim_{N\to\infty}\mathbb{P}(D_{j+1}\leq \alpha\kappa_{j+1}s)$
. Next, because of (9), mutations of types
 $j+2,j+3,j+4,\ldots$
appear rapidly once the first type
$j+2,j+3,j+4,\ldots$
appear rapidly once the first type
 $j+1$
appears. This means that
$j+1$
appears. This means that
 $D_{j+2}+\cdots+D_{j+k}$
is small relative to
$D_{j+2}+\cdots+D_{j+k}$
is small relative to
 $D_{j+1}$
, and therefore that
$D_{j+1}$
, and therefore that
 $D_{j,k}$
has the same limiting distribution as
$D_{j,k}$
has the same limiting distribution as
 $D_{j+1}$
. These heuristics lead to the following theorem.
$D_{j+1}$
. These heuristics lead to the following theorem.
Theorem 5.
Suppose (9) holds. Suppose
 $\mu_1\gg\alpha/N^{(d+1)/d}$
and
$\mu_1\gg\alpha/N^{(d+1)/d}$
and
 $\mu_2\gg \big(N\mu_1\big)^{d+1}/\alpha^d$
. Suppose
$\mu_2\gg \big(N\mu_1\big)^{d+1}/\alpha^d$
. Suppose
 $1 \leq j < k$
. Then, for all
$1 \leq j < k$
. Then, for all
 $s>0$
,
$s>0$
,
 \begin{align*}\mathbb{P}\bigg(\frac{D_{j,k}}{\alpha\kappa_{j+1}}\leq s\bigg) \to \int_0^\infty \gamma_d (t \wedge s)^d \exp\!\bigg({-}\frac{\gamma_d t^{d+1}}{d+1}\bigg)\,\textrm{d} t.\end{align*}
\begin{align*}\mathbb{P}\bigg(\frac{D_{j,k}}{\alpha\kappa_{j+1}}\leq s\bigg) \to \int_0^\infty \gamma_d (t \wedge s)^d \exp\!\bigg({-}\frac{\gamma_d t^{d+1}}{d+1}\bigg)\,\textrm{d} t.\end{align*}
Recall the definition of l in (6). Theorem 4 is similar to Theorem 2 in that once the first type l mutation appears, all the subsequent type
 $l+1,l+2,\ldots$
mutations happen quickly. Therefore, it is reasonable to expect that the type
$l+1,l+2,\ldots$
mutations happen quickly. Therefore, it is reasonable to expect that the type
 $l,l+1,l+2,\ldots$
mutations behave similarly to the type
$l,l+1,l+2,\ldots$
mutations behave similarly to the type
 $1,2,3,\ldots$
mutations in Theorem 2. Hence, analogous to (9), assume that
$1,2,3,\ldots$
mutations in Theorem 2. Hence, analogous to (9), assume that
 \begin{equation} \mu_{l+1}\ll\mu_{l+2}\ll \mu_{l+3}\ll \cdots.\end{equation}
\begin{equation} \mu_{l+1}\ll\mu_{l+2}\ll \mu_{l+3}\ll \cdots.\end{equation}
We then obtain the following result.
Theorem 6.
Suppose (10) holds, and suppose
 $\mu_1 \gg \alpha/N^{(d+1)/d}$
. Define l as in (6), and suppose also that
$\mu_1 \gg \alpha/N^{(d+1)/d}$
. Define l as in (6), and suppose also that
 $l \geq 2$
and that
$l \geq 2$
and that
 $\mu_{l+1}\gg 1/\big(\alpha^d\beta_l^{d+1}\big)$
. Suppose
$\mu_{l+1}\gg 1/\big(\alpha^d\beta_l^{d+1}\big)$
. Suppose
 $l \leq j<k$
. Then, for all
$l \leq j<k$
. Then, for all
 $s>0$
,
$s>0$
,
 \begin{align*}\mathbb{P}\bigg(\frac{D_{j,k}}{\alpha\kappa_{j+1}}\leq s\bigg) \to \int_0^{\infty} \gamma_d (t \wedge s)^d\exp\!\bigg({-}\frac{\gamma_d t^{d+1}}{d+1}\bigg)\,\textrm{d} t.\end{align*}
\begin{align*}\mathbb{P}\bigg(\frac{D_{j,k}}{\alpha\kappa_{j+1}}\leq s\bigg) \to \int_0^{\infty} \gamma_d (t \wedge s)^d\exp\!\bigg({-}\frac{\gamma_d t^{d+1}}{d+1}\bigg)\,\textrm{d} t.\end{align*}
Remark 2. Theorems 5 and 6 hold in the settings of Theorems 2 and 4 respectively. In the setting of Theorem 1, each type
 $i\geq 1$
mutation fills up the entire torus before a type
$i\geq 1$
mutation fills up the entire torus before a type
 $i+1$
mutation occurs, and so the first type
$i+1$
mutation occurs, and so the first type
 $i+1$
mutation appears at a uniformly distributed point on the torus, independently of where all previous mutations originated. Therefore, the problem of finding the distribution of the distances between mutations becomes trivial in this case. On the other hand, in the setting of Theorem 3, type i mutations appear in small and mostly non-overlapping circles before the first type
$i+1$
mutation appears at a uniformly distributed point on the torus, independently of where all previous mutations originated. Therefore, the problem of finding the distribution of the distances between mutations becomes trivial in this case. On the other hand, in the setting of Theorem 3, type i mutations appear in small and mostly non-overlapping circles before the first type
 $i+1$
mutation appears. Thus, calculating the distribution of
$i+1$
mutation appears. Thus, calculating the distribution of
 $D_{i+1}$
requires understanding not only the total volume of the type i region, but also the sizes and locations of many small type i regions. We do not pursue this case here, but we conjecture that because the first type
$D_{i+1}$
requires understanding not only the total volume of the type i region, but also the sizes and locations of many small type i regions. We do not pursue this case here, but we conjecture that because the first type
 $i+1$
mutation is likely not to appear within the type i region generated by the first type i mutation, the locations of the first type i and the first type
$i+1$
mutation is likely not to appear within the type i region generated by the first type i mutation, the locations of the first type i and the first type
 $i+1$
mutations should be nearly independent of each other, as in the setting of Theorem 1.
$i+1$
mutations should be nearly independent of each other, as in the setting of Theorem 1.
3. Proofs of limit theorems for
$\sigma_k$

In this section we prove Theorems 1–4. We begin by introducing the structure of the torus
 $\mathcal{T}=[0,L]^d$
, following the notation of [Reference Foo, Leder and Schweinsberg11]. We define a pseudometric on the closed interval [0, L] by
$\mathcal{T}=[0,L]^d$
, following the notation of [Reference Foo, Leder and Schweinsberg11]. We define a pseudometric on the closed interval [0, L] by
 $d_L(x,y)\;:\!=\;\min\{|x-y|,L-|x-y|\}$
. The d-dimensional torus of side length L will be denoted by
$d_L(x,y)\;:\!=\;\min\{|x-y|,L-|x-y|\}$
. The d-dimensional torus of side length L will be denoted by
 $\mathcal{T}=[0,L]^d$
. For
$\mathcal{T}=[0,L]^d$
. For
 $x=(x^1,\ldots,x^d)\in \mathcal{T}$
and
$x=(x^1,\ldots,x^d)\in \mathcal{T}$
and
 $y=(y^1,\ldots,y^d)\in \mathcal{T}$
, we define a pseudometric by
$y=(y^1,\ldots,y^d)\in \mathcal{T}$
, we define a pseudometric by
 \begin{align*}|x-y|\;:\!=\;\sqrt{\sum_{i=1}^{d}d_L(x^i,y^i)^2}.\end{align*}
\begin{align*}|x-y|\;:\!=\;\sqrt{\sum_{i=1}^{d}d_L(x^i,y^i)^2}.\end{align*}
The torus should be viewed as
 $\mathcal{T}$
modulo the equivalence relation
$\mathcal{T}$
modulo the equivalence relation
 $x\sim y$
if and only if
$x\sim y$
if and only if
 $|x-y|=0$
, or more simply
$|x-y|=0$
, or more simply
 $\mathcal{T}=(\mathbb{R}\ (\text{ mod }L))^d$
. However, we will continue to write
$\mathcal{T}=(\mathbb{R}\ (\text{ mod }L))^d$
. However, we will continue to write
 $\mathcal{T}=[0,L]^d$
, keeping in mind that certain points are considered to be the same via the equivalence relation defined above. It will be useful to observe the following:
$\mathcal{T}=[0,L]^d$
, keeping in mind that certain points are considered to be the same via the equivalence relation defined above. It will be useful to observe the following:
-
We have
$d_L(x,y)\leq L/2$
for all
$x,y\in [0,L]$
. As a result, the distance between any two points
$x,y\in \mathcal{T}$
is at most
\begin{equation*} \sup\{|x-y|\colon x,y\in \mathcal{T}\} = \sqrt{\sum_{i=1}^{d}\bigg(\frac{L}{2}\bigg)^2}=\frac{\sqrt{d}L}{2}. \end{equation*}
-
Therefore, once a mutation of type j appears, the entire torus will become type j in time
(11)
\begin{equation} \frac{\text{maximal distance between any }x,y\in\mathcal{T}}{\text{rate of mutation spread per unit time}}=\frac{\sqrt{d}L}{2\alpha}. \end{equation}





We use
 $|A|$
to denote the Lebesgue measure of some subset A of
$|A|$
to denote the Lebesgue measure of some subset A of
 $\mathcal{T}$
or
$\mathcal{T}$
or
 $\mathcal{T}\times [0,\infty)$
, so that
$\mathcal{T}\times [0,\infty)$
, so that
 $N=L^d=|\mathcal{T}|$
is the torus volume. Each
$N=L^d=|\mathcal{T}|$
is the torus volume. Each
 $x\in \mathcal{T}$
at time t has a type
$x\in \mathcal{T}$
at time t has a type
 $k\in \{0,1,2,\ldots\}$
, which we denote by T(x, t), corresponding to the number of mutations the site has acquired. The set of type i sites is defined by
$k\in \{0,1,2,\ldots\}$
, which we denote by T(x, t), corresponding to the number of mutations the site has acquired. The set of type i sites is defined by
 $\chi_i(t)\;:\!=\;\{x\in \mathcal{T}\colon T(x,t)=i\}$
. The set of points whose type is at least i is defined by
$\chi_i(t)\;:\!=\;\{x\in \mathcal{T}\colon T(x,t)=i\}$
. The set of points whose type is at least i is defined by
 \begin{align*}\psi_i(t)\;:\!=\;\{x\in \mathcal{T}\colon T(x,t)\geq i\}=\bigcup_{j=i}^{\infty}\chi_j(t).\end{align*}
\begin{align*}\psi_i(t)\;:\!=\;\{x\in \mathcal{T}\colon T(x,t)\geq i\}=\bigcup_{j=i}^{\infty}\chi_j(t).\end{align*}
At time t, we denote the total volume of type i sites by
 $X_i(t)\;:\!=\;|\chi_i(t)|$
, and the total volume of sites with type at least i by
$X_i(t)\;:\!=\;|\chi_i(t)|$
, and the total volume of sites with type at least i by
 $Y_i(t)\;:\!=\;|\psi_i(t)|$
. The first time a type k mutation appears in the torus can be expressed as
$Y_i(t)\;:\!=\;|\psi_i(t)|$
. The first time a type k mutation appears in the torus can be expressed as
 $\sigma_k=\inf\{t>0\colon Y_k(t)>0\}$
.
$\sigma_k=\inf\{t>0\colon Y_k(t)>0\}$
.
Still following [Reference Foo, Leder and Schweinsberg11], we now explicitly describe the construction of the process which gives rise to mutations in the torus. We model mutations as random space-time points
 $(x,t)\in \mathcal{T}\times [0,\infty)$
. Let
$(x,t)\in \mathcal{T}\times [0,\infty)$
. Let
 $(\Pi_k)_{k=1}^{\infty}$
be a sequence of independent Poisson point processes on
$(\Pi_k)_{k=1}^{\infty}$
be a sequence of independent Poisson point processes on
 $\mathcal{T}\times [0,\infty)$
, where
$\mathcal{T}\times [0,\infty)$
, where
 $\Pi_k$
has intensity
$\Pi_k$
has intensity
 $\mu_k$
. That is, for any space-time region
$\mu_k$
. That is, for any space-time region
 $A\subseteq \mathcal{T}\times [0,\infty)$
, the probability that A contains j points of type k is
$A\subseteq \mathcal{T}\times [0,\infty)$
, the probability that A contains j points of type k is
 $\textrm{e}^{-\mu_k|A|}{(\mu_k|A|)^j}/{j!}$
. Each
$\textrm{e}^{-\mu_k|A|}{(\mu_k|A|)^j}/{j!}$
. Each
 $(x,t)\in \Pi_k$
is a space-time point at which
$(x,t)\in \Pi_k$
is a space-time point at which
 $x\in \mathcal{T}$
can acquire a kth mutation at time t. We say that x mutates to type k at time t precisely when
$x\in \mathcal{T}$
can acquire a kth mutation at time t. We say that x mutates to type k at time t precisely when
 $x\in \chi_{k-1}(t)$
and
$x\in \chi_{k-1}(t)$
and
 $(x,t)\in \Pi_k$
. Once an individual obtains a type k mutation, it spreads the type k mutations outward in a ball at rate
$(x,t)\in \Pi_k$
. Once an individual obtains a type k mutation, it spreads the type k mutations outward in a ball at rate
 $\alpha$
per unit time.
$\alpha$
per unit time.
3.1. Proof of Theorem 1
In the setting of Theorem 1, once the first mutation appears, with high probability it spreads to the entire torus before another mutation appears. The proof of Theorem 1 uses [Reference Foo, Leder and Schweinsberg11, Theorem 1], which we restate below as Theorem 7. Theorem 1 is very similar to Theorem 7 when
 $j=1$
. However, Theorem 7 requires
$j=1$
. However, Theorem 7 requires
 $\mu_j \ll \alpha/N^{(d+1)/d}$
for all
$\mu_j \ll \alpha/N^{(d+1)/d}$
for all
 $j \in \{1, \dots, k\}$
, whereas Theorem 1 requires this condition only for
$j \in \{1, \dots, k\}$
, whereas Theorem 1 requires this condition only for
 $j = 1$
. This is why Theorem 1 cannot be deduced directly from Theorem 7, even though the proofs of the results are essentially the same.
$j = 1$
. This is why Theorem 1 cannot be deduced directly from Theorem 7, even though the proofs of the results are essentially the same.
Theorem 7. ([Reference Foo, Leder and Schweinsberg11, Theorem 1].) Suppose
 $\mu_i\ll \alpha/N^{(d+1)/d}$
for
$\mu_i\ll \alpha/N^{(d+1)/d}$
for
 $i\in \{1,\ldots,k-1\}$
. Suppose there exists
$i\in \{1,\ldots,k-1\}$
. Suppose there exists
 $j\in \{1,\ldots,k\}$
such that
$j\in \{1,\ldots,k\}$
such that
 $\mu_j\ll \alpha/N^{(d+1)/d}$
and
$\mu_j\ll \alpha/N^{(d+1)/d}$
and
 ${\mu_i}/{\mu_j}\to c_i\in (0,\infty]$
for all
${\mu_i}/{\mu_j}\to c_i\in (0,\infty]$
for all
 $i\in \{1,\ldots,k\}$
. Let
$i\in \{1,\ldots,k\}$
. Let
 $W_1,\ldots,W_k$
be independent random variables such that
$W_1,\ldots,W_k$
be independent random variables such that
 $W_i$
has an exponential distribution with rate parameter
$W_i$
has an exponential distribution with rate parameter
 $c_i$
if
$c_i$
if
 $c_i<\infty$
and
$c_i<\infty$
and
 $W_i=0$
if
$W_i=0$
if
 $c_i=\infty$
. Then
$c_i=\infty$
. Then
 $N\mu_j\sigma_k\Rightarrow W_1+\cdots+W_k$
.
$N\mu_j\sigma_k\Rightarrow W_1+\cdots+W_k$
.
Proof of Theorem
1. Let
 $r\;:\!=\;\max\{j\in \{1,\ldots,k\}:\mu_j\lesssim \mu _1\}$
. For all
$r\;:\!=\;\max\{j\in \{1,\ldots,k\}:\mu_j\lesssim \mu _1\}$
. For all
 $j \in \{1, \dots, r\}$
, we have
$j \in \{1, \dots, r\}$
, we have
 $\mu_j\ll \alpha/N^{(d+1)/d}$
. By Theorem 7,
$\mu_j\ll \alpha/N^{(d+1)/d}$
. By Theorem 7,
 $N\mu_1\sigma_r\Rightarrow W_1+\cdots+ W_r$
. If
$N\mu_1\sigma_r\Rightarrow W_1+\cdots+ W_r$
. If
 $r=k$
, then the conclusion follows. Otherwise,
$r=k$
, then the conclusion follows. Otherwise,
 $r\leq k-1$
, and by the maximality of r and (2), we have
$r\leq k-1$
, and by the maximality of r and (2), we have
 $\mu_l/\mu_1 \rightarrow \infty$
for all
$\mu_l/\mu_1 \rightarrow \infty$
for all
 $l\in \{r+1,\ldots,k\}$
. Then the result follows if we show that
$l\in \{r+1,\ldots,k\}$
. Then the result follows if we show that
 $N\mu_1(\sigma_k-\sigma_r)\to_\textrm{p} 0$
. We have
$N\mu_1(\sigma_k-\sigma_r)\to_\textrm{p} 0$
. We have
 \begin{equation} 0\leq N\mu_1(\sigma_k-\sigma_r) = N\mu_1\sum_{j=r}^{k-1}(\sigma_{j+1}-\sigma_j). \end{equation}
\begin{equation} 0\leq N\mu_1(\sigma_k-\sigma_r) = N\mu_1\sum_{j=r}^{k-1}(\sigma_{j+1}-\sigma_j). \end{equation}
We will find an upper bound for the right-hand side of (12). For
 $i\geq 1$
, let
$i\geq 1$
, let
 $t_i=\inf\{t>0\colon Y_i(t)=N\}$
be the first time which every point in
$t_i=\inf\{t>0\colon Y_i(t)=N\}$
be the first time which every point in
 $\mathcal{T}$
is of at least type i. Define
$\mathcal{T}$
is of at least type i. Define
 $\hat{t}_i\;:\!=\;t_i-\sigma_i$
, which is the time elapsed between
$\hat{t}_i\;:\!=\;t_i-\sigma_i$
, which is the time elapsed between
 $\sigma_i$
and when mutations of type i fixate in the torus. Also define
$\sigma_i$
and when mutations of type i fixate in the torus. Also define
 $\hat{\sigma}_i=\inf\{t>0\colon \Pi_i\cap (\mathcal{T}\times [t_{i-1},t])\neq \varnothing\}$
, which is the first time there is a potential type i mutation after
$\hat{\sigma}_i=\inf\{t>0\colon \Pi_i\cap (\mathcal{T}\times [t_{i-1},t])\neq \varnothing\}$
, which is the first time there is a potential type i mutation after
 $t_{i-1}$
. Observe that, because we always have
$t_{i-1}$
. Observe that, because we always have
 $\sigma_i \leq \hat{\sigma}_i$
,
$\sigma_i \leq \hat{\sigma}_i$
,
 \begin{align*}\sigma_{j+1}-\sigma_j \leq \hat{\sigma}_{j+1}-\sigma_j = \hat{\sigma}_{j+1}-\sigma_j +t_j-t_j = \hat{t}_j + (\hat{\sigma}_{j+1}-t_j).\end{align*}
\begin{align*}\sigma_{j+1}-\sigma_j \leq \hat{\sigma}_{j+1}-\sigma_j = \hat{\sigma}_{j+1}-\sigma_j +t_j-t_j = \hat{t}_j + (\hat{\sigma}_{j+1}-t_j).\end{align*}
Also observe that, by (11), we have
 $\hat{t}_j\leq \sqrt{d}N^{1/d}/(2\alpha)$
. Consequently, the right-hand side of (12) has the upper bound
$\hat{t}_j\leq \sqrt{d}N^{1/d}/(2\alpha)$
. Consequently, the right-hand side of (12) has the upper bound
 \begin{equation*} N\mu_1\Bigg(\sum_{j=r}^{k-1}\hat{t}_j+\sum_{j=r}^{k-1}(\hat{\sigma}_{j+1}-t_j)\Bigg) \leq N\mu_1(k-r)\frac{\sqrt{d}N^{1/d}}{2\alpha} + N\mu_1\sum_{j=r}^{k-1}(\hat{\sigma}_{j+1}-t_j). \end{equation*}
\begin{equation*} N\mu_1\Bigg(\sum_{j=r}^{k-1}\hat{t}_j+\sum_{j=r}^{k-1}(\hat{\sigma}_{j+1}-t_j)\Bigg) \leq N\mu_1(k-r)\frac{\sqrt{d}N^{1/d}}{2\alpha} + N\mu_1\sum_{j=r}^{k-1}(\hat{\sigma}_{j+1}-t_j). \end{equation*}
The result follows if the right-hand side of the above expression converges to 0 in probability. The first term tends to zero because
 $\mu_1\ll \alpha/N^{(d+1)/d}$
. The second term tends to zero because
$\mu_1\ll \alpha/N^{(d+1)/d}$
. The second term tends to zero because
 $\hat{\sigma}_{j+1}-t_j\sim \text{Exponential}(N\mu_{j+1})$
, so
$\hat{\sigma}_{j+1}-t_j\sim \text{Exponential}(N\mu_{j+1})$
, so
 $N\mu_1(\hat{\sigma}_{j+1}-t_j)\sim \text{Exponential}(\mu_{j+1}/\mu_1)\to_\textrm{p} 0$
.
$N\mu_1(\hat{\sigma}_{j+1}-t_j)\sim \text{Exponential}(\mu_{j+1}/\mu_1)\to_\textrm{p} 0$
.
3.2. Proof of Theorem 2
Lemma 1.
Let
 $t_N$
be a random time that is
$t_N$
be a random time that is
 $\sigma(\Pi_1,\ldots,\Pi_{j-1})$
-measurable and satisfies
$\sigma(\Pi_1,\ldots,\Pi_{j-1})$
-measurable and satisfies
 $t_N\geq \sigma_{j-1}$
. Then
$t_N\geq \sigma_{j-1}$
. Then
 \begin{align*}\mathbb{P}(\sigma_j>t_N) = \mathbb{E}\bigg[ \exp\!\bigg({-}\int_{\sigma_{j-1}}^{t_N}\mu_jY_{j-1}(s)\,\textrm{d} s\bigg)\bigg].\end{align*}
\begin{align*}\mathbb{P}(\sigma_j>t_N) = \mathbb{E}\bigg[ \exp\!\bigg({-}\int_{\sigma_{j-1}}^{t_N}\mu_jY_{j-1}(s)\,\textrm{d} s\bigg)\bigg].\end{align*}
Proof. Write
 $\mathcal{G}\;:\!=\;\sigma(\Pi_1,\ldots,\Pi_{j-1})$
. Define the set
$\mathcal{G}\;:\!=\;\sigma(\Pi_1,\ldots,\Pi_{j-1})$
. Define the set
 $A\;:\!=\;\{(x,r)\in \psi_{j-1}(r)\times [\sigma_{j-1},t_N]\}$
, and note that the Lebesgue measure of this set, which we denote by
$A\;:\!=\;\{(x,r)\in \psi_{j-1}(r)\times [\sigma_{j-1},t_N]\}$
, and note that the Lebesgue measure of this set, which we denote by
 $|A|$
, is a
$|A|$
, is a
 $\mathcal{G}$
-measurable random variable. The event
$\mathcal{G}$
-measurable random variable. The event
 $\{\sigma_{j}>t_N\}$
occurs precisely when
$\{\sigma_{j}>t_N\}$
occurs precisely when
 $\Pi_j\cap A =\varnothing$
. Let X be the number of points of
$\Pi_j\cap A =\varnothing$
. Let X be the number of points of
 $\Pi_j$
in the set A. Because
$\Pi_j$
in the set A. Because
 $\Pi_j$
is independent of
$\Pi_j$
is independent of
 $\Pi_1, \dots, \Pi_{j-1}$
, the conditional distribution of X given
$\Pi_1, \dots, \Pi_{j-1}$
, the conditional distribution of X given
 $\mathcal{G}$
is Poisson
$\mathcal{G}$
is Poisson
 $(\mu_j|A|)$
. Therefore,
$(\mu_j|A|)$
. Therefore,
 \begin{align*}\mathbb{P}(\sigma_j>t_N\mid\mathcal{G}) = \mathbb{P}(X=0\mid\mathcal{G}) = \exp\!(-\mu_j |A|) = \exp\!\bigg({-}\int_{\sigma_{j-1}}^{t_N}\mu_jY_{j-1}(s)\,\textrm{d} s\bigg).\end{align*}
\begin{align*}\mathbb{P}(\sigma_j>t_N\mid\mathcal{G}) = \mathbb{P}(X=0\mid\mathcal{G}) = \exp\!(-\mu_j |A|) = \exp\!\bigg({-}\int_{\sigma_{j-1}}^{t_N}\mu_jY_{j-1}(s)\,\textrm{d} s\bigg).\end{align*}
Taking expectations of both sides completes the proof.
Proof of Theorem
2. Write
 $N\mu_1\sigma_k$
as a telescoping sum,
$N\mu_1\sigma_k$
as a telescoping sum,
 \begin{align*}N\mu_1\sigma_k=N\mu_1\sigma_1+\sum_{j=2}^{k}N\mu_1(\sigma_j-\sigma_{j-1}).\end{align*}
\begin{align*}N\mu_1\sigma_k=N\mu_1\sigma_1+\sum_{j=2}^{k}N\mu_1(\sigma_j-\sigma_{j-1}).\end{align*}
We have
 $N\mu_1\sigma_1\sim \text{Exponential}(1)$
. Hence, it suffices to show that, for each
$N\mu_1\sigma_1\sim \text{Exponential}(1)$
. Hence, it suffices to show that, for each
 $j\geq 2$
, the random variable
$j\geq 2$
, the random variable
 $N\mu_1(\sigma_j-\sigma_{j-1})$
converges in probability to zero. Let
$N\mu_1(\sigma_j-\sigma_{j-1})$
converges in probability to zero. Let
 $t>0$
. Then, by Lemma 1,
$t>0$
. Then, by Lemma 1,
 \begin{equation*} \mathbb{P}(N\mu_1(\sigma_j-\sigma_{j-1})> t) = \mathbb{P}\bigg(\sigma_j> \frac{t}{N\mu_1}+\sigma_{j-1}\bigg) = \mathbb{E}\bigg[ \exp\!\bigg({-}\int_{\sigma_{j-1}}^{t/(N\mu_1)+\sigma_{j-1}}\mu_jY_{j-1}(s)\,\textrm{d} s\bigg)\bigg]. \end{equation*}
\begin{equation*} \mathbb{P}(N\mu_1(\sigma_j-\sigma_{j-1})> t) = \mathbb{P}\bigg(\sigma_j> \frac{t}{N\mu_1}+\sigma_{j-1}\bigg) = \mathbb{E}\bigg[ \exp\!\bigg({-}\int_{\sigma_{j-1}}^{t/(N\mu_1)+\sigma_{j-1}}\mu_jY_{j-1}(s)\,\textrm{d} s\bigg)\bigg]. \end{equation*}
We want to show that the term on the right-hand side tends to zero. By the dominated convergence theorem, it suffices to show that as
 $N\to \infty$
,
$N\to \infty$
,
 \begin{align*}\int_{\sigma_{j-1}}^{t/(N\mu_1)+\sigma_{j-1}}\mu_jY_{j-1}(s)\,\textrm{d} s\to \infty.\end{align*}
\begin{align*}\int_{\sigma_{j-1}}^{t/(N\mu_1)+\sigma_{j-1}}\mu_jY_{j-1}(s)\,\textrm{d} s\to \infty.\end{align*}
Notice that because
 $\mu_1\gg \alpha/N^{(d+1)/d}$
, for all sufficiently large N we have
$\mu_1\gg \alpha/N^{(d+1)/d}$
, for all sufficiently large N we have
 $t/(N\mu_1)\leq N^{1/d}/(2\alpha)$
. Therefore, at time
$t/(N\mu_1)\leq N^{1/d}/(2\alpha)$
. Therefore, at time
 $\sigma_{j-1} + t/(N \mu_1)$
, there is a ball of type
$\sigma_{j-1} + t/(N \mu_1)$
, there is a ball of type
 $j-1$
mutations of radius
$j-1$
mutations of radius
 $\alpha(t - \sigma_{j-1})$
which has not yet begun to wrap around the torus and overlap itself. Hence, we have
$\alpha(t - \sigma_{j-1})$
which has not yet begun to wrap around the torus and overlap itself. Hence, we have
 $Y_{j-1}(s)\geq \gamma_d\alpha^d(s-\sigma_{j-1})^d$
for
$Y_{j-1}(s)\geq \gamma_d\alpha^d(s-\sigma_{j-1})^d$
for
 $s\in [\sigma_{j-1},\sigma_{j-1}+t/(N\mu_1)]$
, and therefore
$s\in [\sigma_{j-1},\sigma_{j-1}+t/(N\mu_1)]$
, and therefore
 \begin{align*} \int_{\sigma_{j-1}}^{t/(N\mu_1)+\sigma_{j-1}}\mu_jY_{j-1}(s)\,\textrm{d} s &\geq \int_{\sigma_{j-1}}^{t/(N\mu_1)+\sigma_{j-1}}\mu_j\gamma_d\alpha^d (s-\sigma_{j-1})^d \,\textrm{d} s \\[3pt] &= \int_{0}^{t/(N\mu_1)}\mu_j\gamma_d \alpha^d u^d \,\textrm{d} u = \frac{\mu_j\gamma_d \alpha^d}{d+1}\bigg(\frac{t}{N\mu_1}\bigg)^{d+1}. \end{align*}
\begin{align*} \int_{\sigma_{j-1}}^{t/(N\mu_1)+\sigma_{j-1}}\mu_jY_{j-1}(s)\,\textrm{d} s &\geq \int_{\sigma_{j-1}}^{t/(N\mu_1)+\sigma_{j-1}}\mu_j\gamma_d\alpha^d (s-\sigma_{j-1})^d \,\textrm{d} s \\[3pt] &= \int_{0}^{t/(N\mu_1)}\mu_j\gamma_d \alpha^d u^d \,\textrm{d} u = \frac{\mu_j\gamma_d \alpha^d}{d+1}\bigg(\frac{t}{N\mu_1}\bigg)^{d+1}. \end{align*}
It remains to show that
 \begin{align*}\frac{\mu_j\gamma_d\alpha^d}{d+1}\bigg(\frac{t}{N\mu_1}\bigg)^{d+1}\to \infty\text{ as }N\to \infty.\end{align*}
\begin{align*}\frac{\mu_j\gamma_d\alpha^d}{d+1}\bigg(\frac{t}{N\mu_1}\bigg)^{d+1}\to \infty\text{ as }N\to \infty.\end{align*}
For the above to hold, it suffices to have
 $ \mu_j\gg (N\mu_1)^{d+1}/\alpha^d$
, which holds due to the second assumption in the theorem and (2). This completes the proof.
$ \mu_j\gg (N\mu_1)^{d+1}/\alpha^d$
, which holds due to the second assumption in the theorem and (2). This completes the proof.
3.3. Proof of Theorem 3
We recall the definition of
 $\beta_k$
as in (1) of Section 2. In the setting of Theorem 3,
$\beta_k$
as in (1) of Section 2. In the setting of Theorem 3,
 $\beta_k$
is the order of magnitude of the time it takes for the kth mutation to appear.
$\beta_k$
is the order of magnitude of the time it takes for the kth mutation to appear.
Much of the proof of Theorem 3 will rely on [Reference Foo, Leder and Schweinsberg11, Lemma 9], which approximates a monotone stochastic process by a deterministic function under a certain time scaling. In order to apply this lemma, it is important to ensure that
 $Y_k(t)$
is well approximated by its expectation, which is [Reference Foo, Leder and Schweinsberg11, Lemma 8].
$Y_k(t)$
is well approximated by its expectation, which is [Reference Foo, Leder and Schweinsberg11, Lemma 8].
Before proving Theorem 3, we state several lemmas, some of which are from [Reference Foo, Leder and Schweinsberg11]. First, we need to ensure that the last assumption,
 $\mu_k\alpha^d\beta_{k-1}^{d+1}\to 0$
, in Theorem 3 implies
$\mu_k\alpha^d\beta_{k-1}^{d+1}\to 0$
, in Theorem 3 implies
 $\mu_k\alpha^d\beta_{k}^{d+1}\to 0$
, so that we are able to use part (ii) of Lemma 5 to approximate
$\mu_k\alpha^d\beta_{k}^{d+1}\to 0$
, so that we are able to use part (ii) of Lemma 5 to approximate
 $Y_{k-1}(\beta_k t)$
by its expectation.
$Y_{k-1}(\beta_k t)$
by its expectation.
Lemma 2.
For
 $k\geq 2$
, we have
$k\geq 2$
, we have
 $\mu_k\ll 1/\big(\alpha^d\beta_k^{d+1}\big)$
if and only if
$\mu_k\ll 1/\big(\alpha^d\beta_k^{d+1}\big)$
if and only if
 $\mu_k\ll 1/\big(\alpha^d\beta_{k-1}^{d+1}\big)$
.
$\mu_k\ll 1/\big(\alpha^d\beta_{k-1}^{d+1}\big)$
.
Proof. By using the definition of
 $\beta_k$
from (1), we get
$\beta_k$
from (1), we get
 \begin{align*} \mu_k \ll \frac{1}{\alpha^d\beta_k^{d+1}} &\iff \mu_k^{(k-1)d + k} \ll \frac{1}{\alpha^{d[(k-1)d + k]}} \Bigg(N \alpha^{(k-1)d} \prod_{i=1}^k \mu_k\Bigg)^{d+1} \\[3pt] &\iff \mu_k^{(k-2)d+(k-1)}\ll \frac{1}{\alpha^d}N^{d+1}\Bigg(\prod_{i=1}^{k-1}\mu_i\Bigg)^{d+1} \\[3pt] & \iff \mu_k^{(k-2)d+(k-1)}\ll \frac{\alpha^{d(d+1)(k-2)}}{\alpha^{d[(k-2)d+(k-1)]}}N^{d+1} \Bigg(\prod_{i=1}^{k-1}\mu_i\Bigg)^{d+1} \\[3pt] & \iff \mu_k^{(k-2)d+(k-1)}\ll \frac{1}{\alpha^{d[(k-2)d+(k-1)]}} \Bigg(N\alpha^{(k-2)d}\prod_{i=1}^{k-1}\mu_i\Bigg)^{d+1} \\[3pt] &\iff \mu_k \ll \frac{1}{\alpha^d\beta_{k-1}^{d+1}} , \end{align*}
\begin{align*} \mu_k \ll \frac{1}{\alpha^d\beta_k^{d+1}} &\iff \mu_k^{(k-1)d + k} \ll \frac{1}{\alpha^{d[(k-1)d + k]}} \Bigg(N \alpha^{(k-1)d} \prod_{i=1}^k \mu_k\Bigg)^{d+1} \\[3pt] &\iff \mu_k^{(k-2)d+(k-1)}\ll \frac{1}{\alpha^d}N^{d+1}\Bigg(\prod_{i=1}^{k-1}\mu_i\Bigg)^{d+1} \\[3pt] & \iff \mu_k^{(k-2)d+(k-1)}\ll \frac{\alpha^{d(d+1)(k-2)}}{\alpha^{d[(k-2)d+(k-1)]}}N^{d+1} \Bigg(\prod_{i=1}^{k-1}\mu_i\Bigg)^{d+1} \\[3pt] & \iff \mu_k^{(k-2)d+(k-1)}\ll \frac{1}{\alpha^{d[(k-2)d+(k-1)]}} \Bigg(N\alpha^{(k-2)d}\prod_{i=1}^{k-1}\mu_i\Bigg)^{d+1} \\[3pt] &\iff \mu_k \ll \frac{1}{\alpha^d\beta_{k-1}^{d+1}} , \end{align*}
as claimed.
We also need [Reference Foo, Leder and Schweinsberg11, Lemma 9], which is restated as Lemma 3. This lemma gives necessary conditions under which a monotone stochastic process is well approximated by a deterministic function.
Lemma 3.
Suppose, for all positive integers N,
 $(Y_N(t),t\geq 0)$
is a non-decreasing stochastic process such that
$(Y_N(t),t\geq 0)$
is a non-decreasing stochastic process such that
 $\mathbb{E}[Y_N(t)] < \infty$
for each
$\mathbb{E}[Y_N(t)] < \infty$
for each
 $t > 0$
. Assume there exist sequences of positive numbers
$t > 0$
. Assume there exist sequences of positive numbers
 $(\nu_N)_{N=1}^{\infty}$
and
$(\nu_N)_{N=1}^{\infty}$
and
 $(s_N)_{N=1}^{\infty}$
and a continuous non-decreasing function
$(s_N)_{N=1}^{\infty}$
and a continuous non-decreasing function
 $g>0$
such that, for each fixed
$g>0$
such that, for each fixed
 $t>0$
and
$t>0$
and
 $\varepsilon>0$
, we have
$\varepsilon>0$
, we have
 \begin{equation} \lim_{N\to\infty}\mathbb{P}(|Y_N(s_Nt)-\mathbb{E}[Y_N(s_Nt)]|>\varepsilon\mathbb{E}[Y_N(s_Nt)])=0, \end{equation}
\begin{equation} \lim_{N\to\infty}\mathbb{P}(|Y_N(s_Nt)-\mathbb{E}[Y_N(s_Nt)]|>\varepsilon\mathbb{E}[Y_N(s_Nt)])=0, \end{equation}
and
 \begin{equation} \lim_{N\to\infty}\frac{1}{\nu_N}\mathbb{E}[Y_N(s_Nt)]=g(t). \end{equation}
\begin{equation} \lim_{N\to\infty}\frac{1}{\nu_N}\mathbb{E}[Y_N(s_Nt)]=g(t). \end{equation}
Then, for all
 $\varepsilon>0$
and
$\varepsilon>0$
and
 $\delta>0$
, we have
$\delta>0$
, we have
 \begin{align*}\lim_{N\to\infty}\mathbb{P}(\nu_Ng(t)(1-\varepsilon) \leq Y_N(s_Nt) \leq \nu_N g(t)(1+\varepsilon) \textit{ for all} \enspace t\in [\delta,\delta^{-1}])=1.\end{align*}
\begin{align*}\lim_{N\to\infty}\mathbb{P}(\nu_Ng(t)(1-\varepsilon) \leq Y_N(s_Nt) \leq \nu_N g(t)(1+\varepsilon) \textit{ for all} \enspace t\in [\delta,\delta^{-1}])=1.\end{align*}
Next, we state a criterion which guarantees that, for fixed
 $t>0$
, the probability
$t>0$
, the probability
 $\mathbb{P}(\sigma_k>\beta_kt)$
converges to a deterministic function as
$\mathbb{P}(\sigma_k>\beta_kt)$
converges to a deterministic function as
 $N\to\infty$
.
$N\to\infty$
.
Lemma 4.
For a continuous non-negative function g, a sequence
 $(\nu_N)_{N=1}^{\infty}$
of positive real numbers, and
$(\nu_N)_{N=1}^{\infty}$
of positive real numbers, and
 $\delta,\varepsilon>0$
, define the event
$\delta,\varepsilon>0$
, define the event
 \begin{align*}B_N^{k-1}(\delta,\varepsilon,g,\nu_N)=\{g(u)(1-\varepsilon)\nu_N \leq Y_{k-1}(\beta_ku)\leq g(u)(1+\varepsilon)\nu_N, \textit{ for all} \enspace u\in [\delta,\delta^{-1}] \}.\end{align*}
\begin{align*}B_N^{k-1}(\delta,\varepsilon,g,\nu_N)=\{g(u)(1-\varepsilon)\nu_N \leq Y_{k-1}(\beta_ku)\leq g(u)(1+\varepsilon)\nu_N, \textit{ for all} \enspace u\in [\delta,\delta^{-1}] \}.\end{align*}
If
 $(\nu_N)_{N=1}^{\infty}$
and g are chosen such that
$(\nu_N)_{N=1}^{\infty}$
and g are chosen such that
 $\lim_{N\to\infty}\mathbb{P}\big(B_N^{k-1}(\delta,\varepsilon,g,\nu_N)\big)=1$
and
$\lim_{N\to\infty}\mathbb{P}\big(B_N^{k-1}(\delta,\varepsilon,g,\nu_N)\big)=1$
and
 $\lim_{N\to\infty}\nu_N\beta_k\mu_k$
exists, then
$\lim_{N\to\infty}\nu_N\beta_k\mu_k$
exists, then
 \begin{align*}\lim_{N\to\infty}\mathbb{P}(\sigma_k>\beta_kt) = \lim_{N\to\infty}\exp\!\bigg({-}\nu_N\beta_k\mu_k\int_{0}^{t}g(u)\,\textrm{d} u\bigg).\end{align*}
\begin{align*}\lim_{N\to\infty}\mathbb{P}(\sigma_k>\beta_kt) = \lim_{N\to\infty}\exp\!\bigg({-}\nu_N\beta_k\mu_k\int_{0}^{t}g(u)\,\textrm{d} u\bigg).\end{align*}
Proof. Suppose
 $\delta \leq t \leq \delta^{-1}$
. We reason as in the proof of [Reference Foo, Leder and Schweinsberg11, Theorem 10]. The upper and lower bounds from [Reference Foo, Leder and Schweinsberg11, (26) and (27)] are
$\delta \leq t \leq \delta^{-1}$
. We reason as in the proof of [Reference Foo, Leder and Schweinsberg11, Theorem 10]. The upper and lower bounds from [Reference Foo, Leder and Schweinsberg11, (26) and (27)] are
 \begin{align*} \mathbb{P}(\sigma_k>\beta_k t) & \leq \exp\!\bigg({-}\mu_k\beta_k\nu_N(1-\varepsilon)\int_{\delta}^{t}g(u)\,\textrm{d} u\bigg) + \mathbb{P}\big(B_N^{k-1}(\delta,\varepsilon,g,\nu_N)^\textrm{c}\big), \\[5pt] \mathbb{P}(\sigma_k>\beta_kt) &\geq \mathbb{P}\big(B_N^{k-1}(\delta,\varepsilon,g,\nu_N)\big) \exp\!\bigg({-}\nu_N(1+\varepsilon)\beta_k\mu_k\int_{\delta}^{t}g(u)\,\textrm{d} u\bigg) \\[5pt] &\quad - \frac{\gamma_d^{k-1}(d!)^{k-1}}{(d(k-1)+k)!}\delta^{d(k-1)+k}. \end{align*}
\begin{align*} \mathbb{P}(\sigma_k>\beta_k t) & \leq \exp\!\bigg({-}\mu_k\beta_k\nu_N(1-\varepsilon)\int_{\delta}^{t}g(u)\,\textrm{d} u\bigg) + \mathbb{P}\big(B_N^{k-1}(\delta,\varepsilon,g,\nu_N)^\textrm{c}\big), \\[5pt] \mathbb{P}(\sigma_k>\beta_kt) &\geq \mathbb{P}\big(B_N^{k-1}(\delta,\varepsilon,g,\nu_N)\big) \exp\!\bigg({-}\nu_N(1+\varepsilon)\beta_k\mu_k\int_{\delta}^{t}g(u)\,\textrm{d} u\bigg) \\[5pt] &\quad - \frac{\gamma_d^{k-1}(d!)^{k-1}}{(d(k-1)+k)!}\delta^{d(k-1)+k}. \end{align*}
Taking
 $N\to\infty$
and then
$N\to\infty$
and then
 $\varepsilon,\delta\to 0$
, we get the desired result.
$\varepsilon,\delta\to 0$
, we get the desired result.
We also need to approximate the expected volume of type k or higher regions,
 $\mathbb{E}[Y_k(t)]$
, with a deterministic function, as well as making sure that
$\mathbb{E}[Y_k(t)]$
, with a deterministic function, as well as making sure that
 $Y_k(t)$
is well approximated by its expectation. Lemma 5 is a restatement of [Reference Foo, Leder and Schweinsberg11, Lemmas 5 and 8]. It is important to note that for this result, the time t may depend on N.
$Y_k(t)$
is well approximated by its expectation. Lemma 5 is a restatement of [Reference Foo, Leder and Schweinsberg11, Lemmas 5 and 8]. It is important to note that for this result, the time t may depend on N.
Lemma 5.
Fix a positive integer k. Suppose
 $\mu_j\alpha^d t^{d+1}\to 0$
for all
$\mu_j\alpha^d t^{d+1}\to 0$
for all
 $j\in \{1,\ldots,k\}$
. Also suppose
$j\in \{1,\ldots,k\}$
. Also suppose
 $t \leq N^{1/d}/(2\alpha)$
. Then
$t \leq N^{1/d}/(2\alpha)$
. Then
-
(i) Setting
$\displaystyle v_k(t)\;:\!=\;\frac{\gamma_d^k(d!)^k}{(k(d+1))!} \Bigg(\prod_{i=1}^{k}\mu_i\Bigg)N\alpha^{kd}t^{k(d+1)}$
, we have
$\mathbb{E}[Y_k(t)]\sim v_k(t)$
. -
(ii) If, in addition, we assume
$\displaystyle \Bigg(\prod_{i=1}^{k}\mu_i\Bigg) N\alpha^{(k-1)d}t^{(k-1)d+k}\to\infty$
, then, for all
$\varepsilon>0$
,
\begin{align*}\lim_{N\to\infty}\mathbb{P}((1-\varepsilon)\mathbb{E}[Y_k(t)] \leq Y_k(t)\leq (1+\varepsilon)\mathbb{E}[Y_k(t)])=1.\end{align*}





Remark 3. Lemma 5 in [Reference Foo, Leder and Schweinsberg11] omits the necessary hypothesis
 $t \leq N^{1/d}/(2\alpha)$
. This hypothesis ensures that a growing ball of mutations cannot begin to wrap around the torus and overlap itself before time t, which is needed for the formula for
$t \leq N^{1/d}/(2\alpha)$
. This hypothesis ensures that a growing ball of mutations cannot begin to wrap around the torus and overlap itself before time t, which is needed for the formula for
 $\mathbb{E}[\Lambda_{k-1}(t)]$
in [Reference Foo, Leder and Schweinsberg11, (15)] to be exact. This equation is used in the proof of [Reference Foo, Leder and Schweinsberg11, Lemma 5]. Note that the hypothesis
$\mathbb{E}[\Lambda_{k-1}(t)]$
in [Reference Foo, Leder and Schweinsberg11, (15)] to be exact. This equation is used in the proof of [Reference Foo, Leder and Schweinsberg11, Lemma 5]. Note that the hypothesis
 $t \leq N^{1/d}/(2\alpha)$
is also needed for [Reference Foo, Leder and Schweinsberg11, Lemma 8], because its proof uses [Reference Foo, Leder and Schweinsberg11, Lemma 5]. However, because it is easily verified that this hypothesis is satisfied in [Reference Foo, Leder and Schweinsberg11] whenever these lemmas are used, all of the main results in [Reference Foo, Leder and Schweinsberg11] are correct without additional hypotheses.
$t \leq N^{1/d}/(2\alpha)$
is also needed for [Reference Foo, Leder and Schweinsberg11, Lemma 8], because its proof uses [Reference Foo, Leder and Schweinsberg11, Lemma 5]. However, because it is easily verified that this hypothesis is satisfied in [Reference Foo, Leder and Schweinsberg11] whenever these lemmas are used, all of the main results in [Reference Foo, Leder and Schweinsberg11] are correct without additional hypotheses.
The next lemma states that if
 $\mu_1\gg \alpha/N^{(d+1)/d}$
, then
$\mu_1\gg \alpha/N^{(d+1)/d}$
, then
 $\beta_l$
is much smaller than the time it takes for a mutation to spread to the entire torus.
$\beta_l$
is much smaller than the time it takes for a mutation to spread to the entire torus.
Lemma 6.
Suppose
 $\mu_1\gg \alpha/N^{(d+1)/d}$
and (2) holds. Then
$\mu_1\gg \alpha/N^{(d+1)/d}$
and (2) holds. Then
 $\beta_l \ll N^{1/d}/\alpha$
for any
$\beta_l \ll N^{1/d}/\alpha$
for any
 $l\in \mathbb{N}$
.
$l\in \mathbb{N}$
.
Proof. By (2), we have
 $\mu_1,\ldots,\mu_l\gg \alpha/N^{(d+1)/d}$
. Thus
$\mu_1,\ldots,\mu_l\gg \alpha/N^{(d+1)/d}$
. Thus
 \begin{align*}\prod_{i=1}^{l}\mu_i\gg \frac{\alpha^l}{N^{l(1+1/d)}}.\end{align*}
\begin{align*}\prod_{i=1}^{l}\mu_i\gg \frac{\alpha^l}{N^{l(1+1/d)}}.\end{align*}
On the other hand by simplifying,
 \begin{equation*} \beta_l\ll \frac{N^{1/d}}{\alpha} \iff N\alpha^{(l-1)d}\prod_{i=1}^{l}\mu_i \gg \bigg(\frac{\alpha}{N^{1/d}}\bigg)^{(l-1)d+l} \iff \prod_{i=1}^{l}\mu_i \gg \frac{\alpha^{l}}{N^{l(1+1/d)}}. \end{equation*}
\begin{equation*} \beta_l\ll \frac{N^{1/d}}{\alpha} \iff N\alpha^{(l-1)d}\prod_{i=1}^{l}\mu_i \gg \bigg(\frac{\alpha}{N^{1/d}}\bigg)^{(l-1)d+l} \iff \prod_{i=1}^{l}\mu_i \gg \frac{\alpha^{l}}{N^{l(1+1/d)}}. \end{equation*}
This proves the lemma.
Proof of Theorem
3. In view of Lemma 4, we will choose
 $(\nu_N)_{N=1}^{\infty}$
and a continuous non-negative function
$(\nu_N)_{N=1}^{\infty}$
and a continuous non-negative function
 $g_k$
such that
$g_k$
such that
 $\lim_{N\to \infty}\nu_N\beta_k\mu_k$
exists and
$\lim_{N\to \infty}\nu_N\beta_k\mu_k$
exists and
 $\mathbb{P}\big(B_N^{k-1}(\delta,\varepsilon,g_k,\nu_N)\big)\to 1$
as
$\mathbb{P}\big(B_N^{k-1}(\delta,\varepsilon,g_k,\nu_N)\big)\to 1$
as
 $N\to \infty$
. We set
$N\to \infty$
. We set
 $\nu_N=1/(\beta_k \mu_k)$
, and, as in the proof of [Reference Foo, Leder and Schweinsberg11, Theorem 10], set
$\nu_N=1/(\beta_k \mu_k)$
, and, as in the proof of [Reference Foo, Leder and Schweinsberg11, Theorem 10], set
 \begin{align*}g_k(t)\;:\!=\;\frac{\gamma_d^{k-1}(d!)^{k-1}t^{(k-1)(d+1)}}{((k-1)(d+1))!}.\end{align*}
\begin{align*}g_k(t)\;:\!=\;\frac{\gamma_d^{k-1}(d!)^{k-1}t^{(k-1)(d+1)}}{((k-1)(d+1))!}.\end{align*}
A lengthy calculation shows that
 $\beta_k\mu_kv_{k-1}(\beta_kt)=g_k(t)$
. On the other hand, by the last assumption in the theorem, we have
$\beta_k\mu_kv_{k-1}(\beta_kt)=g_k(t)$
. On the other hand, by the last assumption in the theorem, we have
 $\mu_k\alpha^d\beta_{k-1}^{d+1}\to 0$
. By Lemma 2, this is equivalent to
$\mu_k\alpha^d\beta_{k-1}^{d+1}\to 0$
. By Lemma 2, this is equivalent to
 $\mu_k\alpha^d\beta_{k}^{d+1}\to 0$
. Because of (2), this implies that
$\mu_k\alpha^d\beta_{k}^{d+1}\to 0$
. Because of (2), this implies that
 $\mu_j\alpha^d(\beta_k t)^{d+1}\to 0$
for all
$\mu_j\alpha^d(\beta_k t)^{d+1}\to 0$
for all
 $j\in \{1,\ldots,k\}$
. Also, because of Lemma 6, we have
$j\in \{1,\ldots,k\}$
. Also, because of Lemma 6, we have
 $\beta_k\ll N^{1/d}/(2\alpha)$
. Hence the hypotheses of Lemma 5 are satisfied, and by the first result in Lemma 5 applied to
$\beta_k\ll N^{1/d}/(2\alpha)$
. Hence the hypotheses of Lemma 5 are satisfied, and by the first result in Lemma 5 applied to
 $k-1$
, it follows that
$k-1$
, it follows that
 $v_{k-1}(\beta_k t)\sim\mathbb{E}[Y_{k-1}(\beta_kt)]$
, which implies
$v_{k-1}(\beta_k t)\sim\mathbb{E}[Y_{k-1}(\beta_kt)]$
, which implies
 \begin{align*}\lim_{N\to \infty}\beta_k\mu_k \mathbb{E}[Y_{k-1}(\beta_k t)] = \lim_{N\to\infty }\beta_k\mu_kv_{k-1}(\beta_kt)=g_k(t).\end{align*}
\begin{align*}\lim_{N\to \infty}\beta_k\mu_k \mathbb{E}[Y_{k-1}(\beta_k t)] = \lim_{N\to\infty }\beta_k\mu_kv_{k-1}(\beta_kt)=g_k(t).\end{align*}
Hence, (14) of Lemma 3 is satisfied. A direct calculation gives
 \begin{align*}\Bigg(\prod_{i=1}^{k-1}\mu_i\Bigg)N\alpha^{(k-2)d}\beta_k^{(k-2)d+k-1} = \frac{1}{\mu_k\alpha^d \beta_k^{d+1}}\to \infty,\end{align*}
\begin{align*}\Bigg(\prod_{i=1}^{k-1}\mu_i\Bigg)N\alpha^{(k-2)d}\beta_k^{(k-2)d+k-1} = \frac{1}{\mu_k\alpha^d \beta_k^{d+1}}\to \infty,\end{align*}
which by the second result of Lemma 5 is sufficient to give (13). Therefore, Lemma 3 guarantees that
 $\mathbb{P}\big(B_N^{k-1}(\delta,\varepsilon,g_k,\nu_N)\big)\to 1$
as
$\mathbb{P}\big(B_N^{k-1}(\delta,\varepsilon,g_k,\nu_N)\big)\to 1$
as
 $N\to\infty$
. Then, Lemma 4 gives us
$N\to\infty$
. Then, Lemma 4 gives us
 \begin{align*} \lim_{N\to\infty}\mathbb{P}(\sigma_k>\beta_k t) & = \lim_{N\to\infty } \exp\!\bigg({-}\nu_N\beta_k\mu_k\int_{0}^{t}g_k(u)\,\textrm{d} u\bigg) \\[5pt] &= \exp\!\bigg({-}\int_{0}^{t}\frac{\gamma_d^{k-1}(d!)^{k-1}u^{(k-1)(d+1)}}{((k-1)(d+1))!}\,\textrm{d} u\bigg) \\[5pt] &= \exp\!\bigg({-}\frac{\gamma_d^{k-1}(d!)^{k-1}}{(d(k-1)+k)!}t^{d(k-1)+k}\bigg), \end{align*}
\begin{align*} \lim_{N\to\infty}\mathbb{P}(\sigma_k>\beta_k t) & = \lim_{N\to\infty } \exp\!\bigg({-}\nu_N\beta_k\mu_k\int_{0}^{t}g_k(u)\,\textrm{d} u\bigg) \\[5pt] &= \exp\!\bigg({-}\int_{0}^{t}\frac{\gamma_d^{k-1}(d!)^{k-1}u^{(k-1)(d+1)}}{((k-1)(d+1))!}\,\textrm{d} u\bigg) \\[5pt] &= \exp\!\bigg({-}\frac{\gamma_d^{k-1}(d!)^{k-1}}{(d(k-1)+k)!}t^{d(k-1)+k}\bigg), \end{align*}
completing the proof.
3.4. Proof of Theorem 4
Now we turn to proving Theorem 4, which is a hybrid of Theorems 2 and 3. In particular, we assume that there is some
 $l\in\mathbb{N}$
such that the mutation rates
$l\in\mathbb{N}$
such that the mutation rates
 $\mu_1,\mu_2,\ldots,\mu_l$
fall under the regime of Theorem 3, and all subsequent mutation rates
$\mu_1,\mu_2,\ldots,\mu_l$
fall under the regime of Theorem 3, and all subsequent mutation rates
 $\mu_{l+1},\ldots,\mu_k$
are large enough that all mutations after the first type l mutation occur quickly, as in Theorem 2.
$\mu_{l+1},\ldots,\mu_k$
are large enough that all mutations after the first type l mutation occur quickly, as in Theorem 2.
Proof of Theorem
4. For ease of notation, set, for
 $j\in\mathbb{N}$
and
$j\in\mathbb{N}$
and
 $t\geq 0$
,
$t\geq 0$
,
 \begin{equation*} f_j(t)\;:\!=\;\exp\!\bigg({-}\frac{\gamma_d^{j-1}(d!)^{j-1}t^{d(j-1)+j}}{(d(j-1)+j)!}\bigg). \end{equation*}
\begin{equation*} f_j(t)\;:\!=\;\exp\!\bigg({-}\frac{\gamma_d^{j-1}(d!)^{j-1}t^{d(j-1)+j}}{(d(j-1)+j)!}\bigg). \end{equation*}
For
 $\varepsilon>0$
, we have the inequalities
$\varepsilon>0$
, we have the inequalities
 \begin{align*}\mathbb{P}(\sigma_l>\beta_l t)\leq \mathbb{P}(\sigma_k>\beta_l t) \leq \mathbb{P}(\sigma_l>\beta_l(t-\varepsilon))+\mathbb{P}(\sigma_k-\sigma_l>\beta_l\varepsilon).\end{align*}
\begin{align*}\mathbb{P}(\sigma_l>\beta_l t)\leq \mathbb{P}(\sigma_k>\beta_l t) \leq \mathbb{P}(\sigma_l>\beta_l(t-\varepsilon))+\mathbb{P}(\sigma_k-\sigma_l>\beta_l\varepsilon).\end{align*}
Taking
 $N\to \infty$
and using Theorem 3 (noting that
$N\to \infty$
and using Theorem 3 (noting that
 $l\geq 2$
), we have
$l\geq 2$
), we have
 \begin{align*}f_l(t)\leq \lim_{N\to\infty} \mathbb{P}(\sigma_k>\beta_l t) \leq f_l(t-\varepsilon )+\lim_{N\to \infty}\mathbb{P}(\sigma_k-\sigma_l>\beta_l\varepsilon).\end{align*}
\begin{align*}f_l(t)\leq \lim_{N\to\infty} \mathbb{P}(\sigma_k>\beta_l t) \leq f_l(t-\varepsilon )+\lim_{N\to \infty}\mathbb{P}(\sigma_k-\sigma_l>\beta_l\varepsilon).\end{align*}
Since
 $f_l$
is continuous, the result follows (by taking
$f_l$
is continuous, the result follows (by taking
 $\varepsilon\to 0$
) once we show that, for each fixed
$\varepsilon\to 0$
) once we show that, for each fixed
 $\varepsilon>0$
,
$\varepsilon>0$
,
 \begin{equation} \lim_{N\to\infty}\mathbb{P}(\sigma_k-\sigma_l>\beta_l\varepsilon)=0. \end{equation}
\begin{equation} \lim_{N\to\infty}\mathbb{P}(\sigma_k-\sigma_l>\beta_l\varepsilon)=0. \end{equation}
Notice that because
 \begin{align*}\{\sigma_k-\sigma_l>\beta_l\varepsilon\} \subseteq \bigcup_{j=l}^{k-1}\bigg\{\sigma_{j+1}-\sigma_j>\frac{\beta_l\varepsilon}{k-l}\bigg\},\end{align*}
\begin{align*}\{\sigma_k-\sigma_l>\beta_l\varepsilon\} \subseteq \bigcup_{j=l}^{k-1}\bigg\{\sigma_{j+1}-\sigma_j>\frac{\beta_l\varepsilon}{k-l}\bigg\},\end{align*}
it suffices to show that, for all
 $j\in \{l,\ldots,k-1\}$
,
$j\in \{l,\ldots,k-1\}$
,
 $\mathbb{P}(\sigma_{j+1}-\sigma_j>\beta_l\varepsilon)\to 0$
. By Lemma 1, we have
$\mathbb{P}(\sigma_{j+1}-\sigma_j>\beta_l\varepsilon)\to 0$
. By Lemma 1, we have
 \begin{equation*} \mathbb{P}(\sigma_{j+1}-\sigma_j>\beta_l\varepsilon) = \mathbb{E}\bigg[\exp\!\bigg({-}\int_{\sigma_j}^{\beta_l\varepsilon+\sigma_j}\mu_{j+1}Y_j(s)\,\textrm{d} s\bigg)\bigg]. \end{equation*}
\begin{equation*} \mathbb{P}(\sigma_{j+1}-\sigma_j>\beta_l\varepsilon) = \mathbb{E}\bigg[\exp\!\bigg({-}\int_{\sigma_j}^{\beta_l\varepsilon+\sigma_j}\mu_{j+1}Y_j(s)\,\textrm{d} s\bigg)\bigg]. \end{equation*}
Hence, by the dominated convergence theorem, to show that
 $\mathbb{P}(\sigma_{j+1}-\sigma_j>\beta_l\varepsilon)\to 0$
, it suffices to show that
$\mathbb{P}(\sigma_{j+1}-\sigma_j>\beta_l\varepsilon)\to 0$
, it suffices to show that
 $\int_{\sigma_j}^{\beta_l\varepsilon+\sigma_j}\mu_{j+1}Y_j(s)\,\textrm{d} s\to \infty$
almost surely. By Lemma 6 we have
$\int_{\sigma_j}^{\beta_l\varepsilon+\sigma_j}\mu_{j+1}Y_j(s)\,\textrm{d} s\to \infty$
almost surely. By Lemma 6 we have
 $\beta_l\ll N^{1/d}/\alpha$
, so
$\beta_l\ll N^{1/d}/\alpha$
, so
 $ \beta_l\varepsilon \leq N^{1/d}/(2\alpha)$
for large enough N. That is,
$ \beta_l\varepsilon \leq N^{1/d}/(2\alpha)$
for large enough N. That is,
 $\beta_l\varepsilon$
does not exceed the time it takes for a mutation to wrap around the torus. Hence, we have the lower bound
$\beta_l\varepsilon$
does not exceed the time it takes for a mutation to wrap around the torus. Hence, we have the lower bound
 $Y_j(s)\geq \gamma_d\alpha^d (s-\sigma_j)^d$
for
$Y_j(s)\geq \gamma_d\alpha^d (s-\sigma_j)^d$
for
 $s\in [\sigma_j,\sigma_j+\beta_l\varepsilon]$
, and
$s\in [\sigma_j,\sigma_j+\beta_l\varepsilon]$
, and
 \begin{equation} \int_{\sigma_j}^{\beta_l\varepsilon+\sigma_j}\mu_{j+1}Y_j(s)\,\textrm{d} s \geq \int_{\sigma_j}^{\beta_l\varepsilon+\sigma_j}\mu_{j+1}\gamma_d\alpha^d(s-\sigma_j)^d \,\textrm{d} s = \frac{\mu_{j+1}\gamma_d \alpha^d}{d+1}(\beta_l \varepsilon)^{d+1}. \end{equation}
\begin{equation} \int_{\sigma_j}^{\beta_l\varepsilon+\sigma_j}\mu_{j+1}Y_j(s)\,\textrm{d} s \geq \int_{\sigma_j}^{\beta_l\varepsilon+\sigma_j}\mu_{j+1}\gamma_d\alpha^d(s-\sigma_j)^d \,\textrm{d} s = \frac{\mu_{j+1}\gamma_d \alpha^d}{d+1}(\beta_l \varepsilon)^{d+1}. \end{equation}
By the second assumption in the theorem, we have
 $\mu_{l+1}\gg 1/\big(\alpha^d\beta_l^{d+1}\big)$
. Because of (2), we have
$\mu_{l+1}\gg 1/\big(\alpha^d\beta_l^{d+1}\big)$
. Because of (2), we have
 $\mu_{j+1}\gg 1/\big(\alpha^d\beta_l^{d+1}\big)$
. It follows that the right-hand side of (16) tends to infinity as
$\mu_{j+1}\gg 1/\big(\alpha^d\beta_l^{d+1}\big)$
. It follows that the right-hand side of (16) tends to infinity as
 $N\to \infty$
, which completes the proof.
$N\to \infty$
, which completes the proof.
4. Proofs of limit theorems for distances between mutations
For each
 $j\geq 1$
, we define
$j\geq 1$
, we define
 $\sigma_j^{(2)}$
to be the time at which the second type j mutation occurs, i.e.
$\sigma_j^{(2)}$
to be the time at which the second type j mutation occurs, i.e.
 \begin{align*}\sigma_j^{(2)}\;:\!=\;\inf\{t>\sigma_j\colon (x, t) \in \Pi_j \mbox{ and } x \in \psi_{j-1}(t) \mbox{ for some }x \in \mathcal{T} \}.\end{align*}
\begin{align*}\sigma_j^{(2)}\;:\!=\;\inf\{t>\sigma_j\colon (x, t) \in \Pi_j \mbox{ and } x \in \psi_{j-1}(t) \mbox{ for some }x \in \mathcal{T} \}.\end{align*}
Note that
 $\sigma_j^{(2)}$
is defined to be the first time, after time
$\sigma_j^{(2)}$
is defined to be the first time, after time
 $\sigma_j$
, that a point of
$\sigma_j$
, that a point of
 $\Pi_j$
lands in a region of type
$\Pi_j$
lands in a region of type
 $j-1$
or higher. If this point lands in a region of type
$j-1$
or higher. If this point lands in a region of type
 $j-1$
, then a new type j ball will begin to grow. If this point lands in a region of type j or higher, then the evolution of the process is unaffected. Also recall from (1) that
$j-1$
, then a new type j ball will begin to grow. If this point lands in a region of type j or higher, then the evolution of the process is unaffected. Also recall from (1) that
 $\kappa_j\;:\!=\;(\mu_j\alpha^d)^{-1/(d+1)}$
.
$\kappa_j\;:\!=\;(\mu_j\alpha^d)^{-1/(d+1)}$
.
4.1. Proof of Theorem 5
We begin with an upper bound for the time between first mutations of consecutive types.
Lemma 7.
Assume
 $\mu_1\gg \alpha/N^{(d+1)/d}$
. Suppose i and j are positive integers. Then, for each fixed
$\mu_1\gg \alpha/N^{(d+1)/d}$
. Suppose i and j are positive integers. Then, for each fixed
 $t>0$
, we have, for all sufficiently large N,
$t>0$
, we have, for all sufficiently large N,
 \begin{align*}\mathbb{P}(\sigma_{j+1}-\sigma_j>\kappa_{i}t) \leq \exp\!\bigg({-}\frac{\gamma_d}{d+1}\cdot \frac{\mu_{j+1}}{\mu_i}t^{d+1}\bigg).\end{align*}
\begin{align*}\mathbb{P}(\sigma_{j+1}-\sigma_j>\kappa_{i}t) \leq \exp\!\bigg({-}\frac{\gamma_d}{d+1}\cdot \frac{\mu_{j+1}}{\mu_i}t^{d+1}\bigg).\end{align*}
Proof. Using Lemma 1, we have
 \begin{align*}\mathbb{P}(\sigma_{j+1}-\sigma_j>\kappa_i t) = \mathbb{E}\bigg[\exp\!\bigg({-}\int_{\sigma_j}^{\sigma_j+\kappa_{i}t}\mu_{j+1}Y_j(s)\,\textrm{d} s\bigg)\bigg].\end{align*}
\begin{align*}\mathbb{P}(\sigma_{j+1}-\sigma_j>\kappa_i t) = \mathbb{E}\bigg[\exp\!\bigg({-}\int_{\sigma_j}^{\sigma_j+\kappa_{i}t}\mu_{j+1}Y_j(s)\,\textrm{d} s\bigg)\bigg].\end{align*}
Because of
 $\mu_1\gg \alpha/N^{(d+1)/d}$
and (2), for all sufficiently large N we have
$\mu_1\gg \alpha/N^{(d+1)/d}$
and (2), for all sufficiently large N we have
 $\kappa_{i}t<L/(2\alpha)$
. Thus,
$\kappa_{i}t<L/(2\alpha)$
. Thus,
 $Y_j(s)\geq \gamma_d \alpha^d(s-\sigma_j)^d$
for
$Y_j(s)\geq \gamma_d \alpha^d(s-\sigma_j)^d$
for
 $s\in [\sigma_j,\sigma_j+\kappa_{i}t]$
. Then,
$s\in [\sigma_j,\sigma_j+\kappa_{i}t]$
. Then,

This completes the proof.
By Lemma 7, when
 $\mu_1\gg \alpha/N^{(d+1)/d}$
the interarrival time
$\mu_1\gg \alpha/N^{(d+1)/d}$
the interarrival time
 $\sigma_{j}-\sigma_{j-1}$
is at most the same order of magnitude as
$\sigma_{j}-\sigma_{j-1}$
is at most the same order of magnitude as
 $\kappa_{j}$
. Lemma 8 further shows that if, in addition,
$\kappa_{j}$
. Lemma 8 further shows that if, in addition,
 $\mu_j\ll \mu_{j+1}\ll \mu_{j+2}\ll \cdots$
, then mutations of type
$\mu_j\ll \mu_{j+1}\ll \mu_{j+2}\ll \cdots$
, then mutations of type
 $m > j$
appear on an even faster time scale.
$m > j$
appear on an even faster time scale.
Lemma 8.
Assume
 $\mu_1\gg \alpha/N^{(d+1)/d}$
. Suppose j is a positive integer, and
$\mu_1\gg \alpha/N^{(d+1)/d}$
. Suppose j is a positive integer, and
 $\mu_j\ll \mu_{j+1} \ll \mu_{j+2} \ll \cdots$
. Then
$\mu_j\ll \mu_{j+1} \ll \mu_{j+2} \ll \cdots$
. Then
 $(\sigma_m-\sigma_j)/\kappa_j\to_p 0$
for every
$(\sigma_m-\sigma_j)/\kappa_j\to_p 0$
for every
 $m>j$
.
$m>j$
.
Proof. Using (2), we get
 \begin{align*}\frac{\sigma_m-\sigma_j}{\kappa_j}=\sum_{i=j}^{m-1}\frac{\sigma_{i+1}-\sigma_i}{\kappa_j} \lesssim \sum_{i=j}^{m-1}\frac{\sigma_{i+1}-\sigma_i}{\kappa_i},\end{align*}
\begin{align*}\frac{\sigma_m-\sigma_j}{\kappa_j}=\sum_{i=j}^{m-1}\frac{\sigma_{i+1}-\sigma_i}{\kappa_j} \lesssim \sum_{i=j}^{m-1}\frac{\sigma_{i+1}-\sigma_i}{\kappa_i},\end{align*}
so it suffices to show that
 $(\sigma_{i+1} - \sigma_i)/\kappa_i \rightarrow_p 0$
for all
$(\sigma_{i+1} - \sigma_i)/\kappa_i \rightarrow_p 0$
for all
 $i \in \{j, j+1, \dots, m-1\}$
. Let
$i \in \{j, j+1, \dots, m-1\}$
. Let
 $\varepsilon>0$
. Using Lemma 7, we have, for all sufficiently large N,
$\varepsilon>0$
. Using Lemma 7, we have, for all sufficiently large N,
 \begin{align*}\mathbb{P}(\sigma_{i+1}-\sigma_i>\kappa_i\varepsilon) \leq \exp\!\bigg({-}\frac{\gamma_d}{d+1}\cdot \frac{\mu_{i+1}}{\mu_{i}}\varepsilon^{d+1}\bigg).\end{align*}
\begin{align*}\mathbb{P}(\sigma_{i+1}-\sigma_i>\kappa_i\varepsilon) \leq \exp\!\bigg({-}\frac{\gamma_d}{d+1}\cdot \frac{\mu_{i+1}}{\mu_{i}}\varepsilon^{d+1}\bigg).\end{align*}
Then,
 $\mathbb{P}(\sigma_{i+1}-\sigma_i>\kappa_i\varepsilon)\to 0$
because
$\mathbb{P}(\sigma_{i+1}-\sigma_i>\kappa_i\varepsilon)\to 0$
because
 $\mu_{i+1}/\mu_i\to \infty$
, as desired.
$\mu_{i+1}/\mu_i\to \infty$
, as desired.
Next, we want to show that the balls from different mutation types become nested, as in Fig. 2. That is, for any
 $i\geq 1$
and
$i\geq 1$
and
 $j>i$
, we have
$j>i$
, we have
 $\mathbb{P}(\sigma_j<\sigma_i^{(2)})\to 1$
, meaning that a type j mutation appears before a second type i mutation can appear. We first prove the case when
$\mathbb{P}(\sigma_j<\sigma_i^{(2)})\to 1$
, meaning that a type j mutation appears before a second type i mutation can appear. We first prove the case when
 $i=1$
in Lemma 9, assuming the same hypotheses as in Theorem 2.
$i=1$
in Lemma 9, assuming the same hypotheses as in Theorem 2.
Lemma 9. Suppose (2) holds, and suppose
 $\mu_1 \gg \alpha/N^{(d+1)/d}$
and
$\mu_1 \gg \alpha/N^{(d+1)/d}$
and
 $\mu_2\gg (N\mu_1)^{d+1}/\alpha^d$
. Then:
$\mu_2\gg (N\mu_1)^{d+1}/\alpha^d$
. Then:
(i) For all
 $t>0$
,
$t>0$
,
 $\mathbb{P}\big(\sigma_2+\kappa_2t<\sigma_1^{(2)}\big)\to 1$
.
$\mathbb{P}\big(\sigma_2+\kappa_2t<\sigma_1^{(2)}\big)\to 1$
.
(ii) For every
 $j\geq 2$
,
$j\geq 2$
,
 $\mathbb{P}\big(\sigma_j<\sigma_1^{(2)}\big)\to 1$
.
$\mathbb{P}\big(\sigma_j<\sigma_1^{(2)}\big)\to 1$
.
Proof. To prove (i), let
 $\varepsilon>0$
. It was shown in the proof of Theorem 2 that
$\varepsilon>0$
. It was shown in the proof of Theorem 2 that
 $N\mu_1(\sigma_2-\sigma_1)\to_p 0$
. Also, the assumption
$N\mu_1(\sigma_2-\sigma_1)\to_p 0$
. Also, the assumption
 $\mu_2\gg (N\mu_1)^{d+1}/\alpha^d$
implies
$\mu_2\gg (N\mu_1)^{d+1}/\alpha^d$
implies
 $N\mu_1\kappa_2 t\to 0$
. Thus,
$N\mu_1\kappa_2 t\to 0$
. Thus,
 $N\mu_1(\sigma_2-\sigma_1)+N\mu_1\kappa_2t\to_p 0$
. Therefore, for all sufficiently large N,
$N\mu_1(\sigma_2-\sigma_1)+N\mu_1\kappa_2t\to_p 0$
. Therefore, for all sufficiently large N,
 \begin{align*}\mathbb{P}(N\mu_1(\sigma_2-\sigma_1)+N\mu_1\kappa_2 t<\varepsilon)> 1-\varepsilon.\end{align*}
\begin{align*}\mathbb{P}(N\mu_1(\sigma_2-\sigma_1)+N\mu_1\kappa_2 t<\varepsilon)> 1-\varepsilon.\end{align*}
On the other hand, because
 $N\mu_1(\sigma_1^{(2)}-\sigma_1)$
has an
$N\mu_1(\sigma_1^{(2)}-\sigma_1)$
has an
 $\text{Exponential}(1)$
distribution,
$\text{Exponential}(1)$
distribution,
 \begin{align*}\mathbb{P}(N\mu_1\big(\sigma_1^{(2)}-\sigma_1\big)>\varepsilon)=\textrm{e}^{-\varepsilon}>1-\varepsilon.\end{align*}
\begin{align*}\mathbb{P}(N\mu_1\big(\sigma_1^{(2)}-\sigma_1\big)>\varepsilon)=\textrm{e}^{-\varepsilon}>1-\varepsilon.\end{align*}
Combining the above, we find
 \begin{equation*} \mathbb{P}\big(\sigma_2+\kappa_2 t<\sigma_1^{(2)}\big) \geq \mathbb{P}(N\mu_1(\sigma_2-\sigma_1)+N\mu_1\kappa_2 t<\varepsilon < N\mu_1\big(\sigma_1^{(2)}-\sigma_1\big)) > 1-2\varepsilon. \end{equation*}
\begin{equation*} \mathbb{P}\big(\sigma_2+\kappa_2 t<\sigma_1^{(2)}\big) \geq \mathbb{P}(N\mu_1(\sigma_2-\sigma_1)+N\mu_1\kappa_2 t<\varepsilon < N\mu_1\big(\sigma_1^{(2)}-\sigma_1\big)) > 1-2\varepsilon. \end{equation*}
This proves (i). For (ii), by the proof of Theorem 2 again, we have
 $N\mu_1(\sigma_i-\sigma_{i-1})\to_p 0$
for every
$N\mu_1(\sigma_i-\sigma_{i-1})\to_p 0$
for every
 $i\geq 2$
. Thus,
$i\geq 2$
. Thus,
 \begin{align*}N\mu_1(\sigma_j-\sigma_1)=\sum_{i=2}^{j}N\mu_1(\sigma_i-\sigma_{i-1})\to_\textrm{p} 0,\end{align*}
\begin{align*}N\mu_1(\sigma_j-\sigma_1)=\sum_{i=2}^{j}N\mu_1(\sigma_i-\sigma_{i-1})\to_\textrm{p} 0,\end{align*}
and the rest of the proof is essentially the same as that of (i); we just replace
 $N\mu_1(\sigma_2-\sigma_1)+N\mu_1\kappa_2 t$
with
$N\mu_1(\sigma_2-\sigma_1)+N\mu_1\kappa_2 t$
with
 $N\mu_1(\sigma_j-\sigma_1)$
.
$N\mu_1(\sigma_j-\sigma_1)$
.
In Lemma 10, we establish that
 $\sigma_{j}^{(2)}-\sigma_{j}>\kappa_{j}\delta$
with high probability. Then, for
$\sigma_{j}^{(2)}-\sigma_{j}>\kappa_{j}\delta$
with high probability. Then, for
 $k>j$
, since
$k>j$
, since
 $(\sigma_{k}-\sigma_j)/\kappa_{j}\to_p 0$
by Lemma 8, it will follow that
$(\sigma_{k}-\sigma_j)/\kappa_{j}\to_p 0$
by Lemma 8, it will follow that
 $\sigma_{k}-\sigma_j<\kappa_{j}\delta$
with high probability. It will then follow that
$\sigma_{k}-\sigma_j<\kappa_{j}\delta$
with high probability. It will then follow that
 $\mathbb{P}\big(\sigma_{k}<\sigma_j^{(2)}\big)\to 1$
, which we show in Lemma 11.
$\mathbb{P}\big(\sigma_{k}<\sigma_j^{(2)}\big)\to 1$
, which we show in Lemma 11.
Lemma 10.
Suppose (2) holds, and suppose
 $\mu_1\gg \alpha/N^{(d+1)/d}$
. Let
$\mu_1\gg \alpha/N^{(d+1)/d}$
. Let
 $i \geq 2$
. Define the events
$i \geq 2$
. Define the events
 $A\;:\!=\;\{\sigma_i-\sigma_{i-1}<\kappa_i t\}$
and
$A\;:\!=\;\{\sigma_i-\sigma_{i-1}<\kappa_i t\}$
and
 $B\;:\!=\;\big\{\sigma_{i}+\kappa_{i}\delta<\sigma_{i-1}^{(2)}\big\}$
. Then, for any fixed
$B\;:\!=\;\big\{\sigma_{i}+\kappa_{i}\delta<\sigma_{i-1}^{(2)}\big\}$
. Then, for any fixed
 $t>0$
and
$t>0$
and
 $\delta>0$
, for sufficiently large N we have
$\delta>0$
, for sufficiently large N we have
 \begin{align*}\mathbb{P}\big(\sigma_{i}^{(2)}-\sigma_{i}>\kappa_{i}\delta\big) \geq \exp\!\bigg({-}\frac{\gamma_d}{d+1}[(t+\delta)^{d+1}-t^{d+1}]\bigg) - \mathbb{P}(A^\textrm{c}) - \mathbb{P}(B^\textrm{c}).\end{align*}
\begin{align*}\mathbb{P}\big(\sigma_{i}^{(2)}-\sigma_{i}>\kappa_{i}\delta\big) \geq \exp\!\bigg({-}\frac{\gamma_d}{d+1}[(t+\delta)^{d+1}-t^{d+1}]\bigg) - \mathbb{P}(A^\textrm{c}) - \mathbb{P}(B^\textrm{c}).\end{align*}
Proof. Reasoning as in the proof of Lemma 1, we have
 \begin{equation} \mathbb{P}\big(\sigma_{i}^{(2)}-\sigma_{i}>\kappa_{i}\delta\big) = \mathbb{E}\bigg[\exp\!\bigg({-}\int_{0}^{\kappa_{i}\delta}\mu_{i}Y_{i-1}(s+\sigma_{i})\,\textrm{d} s\bigg)\bigg]. \end{equation}
\begin{equation} \mathbb{P}\big(\sigma_{i}^{(2)}-\sigma_{i}>\kappa_{i}\delta\big) = \mathbb{E}\bigg[\exp\!\bigg({-}\int_{0}^{\kappa_{i}\delta}\mu_{i}Y_{i-1}(s+\sigma_{i})\,\textrm{d} s\bigg)\bigg]. \end{equation}
Because of
 $\mu_1\gg \alpha/N^{(d+1)/d}$
and (2), for sufficiently large N we have
$\mu_1\gg \alpha/N^{(d+1)/d}$
and (2), for sufficiently large N we have
 $\kappa_i(t+\delta)<L/(2\alpha)$
. Thus, on the event A, we have
$\kappa_i(t+\delta)<L/(2\alpha)$
. Thus, on the event A, we have
 $\kappa_i\delta+(\sigma_i-\sigma_{i-1})<L/(2\alpha)$
. Therefore, on the event
$\kappa_i\delta+(\sigma_i-\sigma_{i-1})<L/(2\alpha)$
. Therefore, on the event
 $A \cap B$
, for all
$A \cap B$
, for all
 $s\in [0,\kappa_i\delta]$
we have, for sufficiently large N,
$s\in [0,\kappa_i\delta]$
we have, for sufficiently large N,
 \begin{equation*} Y_{i-1}(s+\sigma_i) = \gamma_d\alpha^d(s+\sigma_i-\sigma_{i-1})^{d}\leq \gamma_d\alpha^d(s+\kappa_it)^{d}. \end{equation*}
\begin{equation*} Y_{i-1}(s+\sigma_i) = \gamma_d\alpha^d(s+\sigma_i-\sigma_{i-1})^{d}\leq \gamma_d\alpha^d(s+\kappa_it)^{d}. \end{equation*}
Thus, for sufficiently large N,
 \begin{align} \exp\!\bigg({-}\int_{0}^{\kappa_{i}\delta}\mu_{i}Y_{i-1}(s+\sigma_{i})\,\textrm{d} s\bigg) &\geq \exp\!\bigg({-}\int_0^{\kappa_{i}\delta}\mu_{i}\gamma_d\alpha^d(s+\kappa_{i}t)^d \,\textrm{d} s\bigg) \textbf{1}_{A \cap B} \nonumber \\[5pt] &\geq \exp\!\bigg({-}\int_0^{\kappa_{i}\delta}\mu_{i}\gamma_d\alpha^d(s+\kappa_{i}t)^d \,\textrm{d} s\bigg) - \textbf{1}_{A^\textrm{c}} - \textbf{1}_{B^\textrm{c}}. \end{align}
\begin{align} \exp\!\bigg({-}\int_{0}^{\kappa_{i}\delta}\mu_{i}Y_{i-1}(s+\sigma_{i})\,\textrm{d} s\bigg) &\geq \exp\!\bigg({-}\int_0^{\kappa_{i}\delta}\mu_{i}\gamma_d\alpha^d(s+\kappa_{i}t)^d \,\textrm{d} s\bigg) \textbf{1}_{A \cap B} \nonumber \\[5pt] &\geq \exp\!\bigg({-}\int_0^{\kappa_{i}\delta}\mu_{i}\gamma_d\alpha^d(s+\kappa_{i}t)^d \,\textrm{d} s\bigg) - \textbf{1}_{A^\textrm{c}} - \textbf{1}_{B^\textrm{c}}. \end{align}
It follows from (17) and (18) that, for sufficiently large N,
 \begin{align*} \mathbb{P}\big(\sigma_{i}^{(2)}-\sigma_{i}>\kappa_{i}\delta\big) & \geq \exp\!\bigg({-}\int_0^{\kappa_{i}\delta}\mu_{i}\gamma_d\alpha^d(s+\kappa_{i}t)^d \,\textrm{d} s\bigg) - \mathbb{P}(A^\textrm{c}) - \mathbb{P}(B^\textrm{c}) \\[5pt] &= \exp\!\bigg({-}\frac{\mu_{i}\gamma_d\alpha^d}{d+1} [(\kappa_{i}\delta+\kappa_{i}t)^{d+1}-(\kappa_{i}t)^{d+1}]\bigg) - \mathbb{P}(A^\textrm{c}) - \mathbb{P}(B^\textrm{c}) \\[5pt] &= \exp\!\bigg({-}\frac{\gamma_d}{d+1}[(t+\delta)^{d+1}-t^{d+1}]\bigg) - \mathbb{P}(A^\textrm{c}) - \mathbb{P}(B^\textrm{c}), \end{align*}
\begin{align*} \mathbb{P}\big(\sigma_{i}^{(2)}-\sigma_{i}>\kappa_{i}\delta\big) & \geq \exp\!\bigg({-}\int_0^{\kappa_{i}\delta}\mu_{i}\gamma_d\alpha^d(s+\kappa_{i}t)^d \,\textrm{d} s\bigg) - \mathbb{P}(A^\textrm{c}) - \mathbb{P}(B^\textrm{c}) \\[5pt] &= \exp\!\bigg({-}\frac{\mu_{i}\gamma_d\alpha^d}{d+1} [(\kappa_{i}\delta+\kappa_{i}t)^{d+1}-(\kappa_{i}t)^{d+1}]\bigg) - \mathbb{P}(A^\textrm{c}) - \mathbb{P}(B^\textrm{c}) \\[5pt] &= \exp\!\bigg({-}\frac{\gamma_d}{d+1}[(t+\delta)^{d+1}-t^{d+1}]\bigg) - \mathbb{P}(A^\textrm{c}) - \mathbb{P}(B^\textrm{c}), \end{align*}
as claimed.
In Lemma 11 we give sufficient conditions for
 $\mathbb{P}\big(\sigma_j<\sigma_i^{(2)}\big)\to 1$
for
$\mathbb{P}\big(\sigma_j<\sigma_i^{(2)}\big)\to 1$
for
 $j>i\geq 1$
, which implies that we obtain nested balls, as in Fig. 2.
$j>i\geq 1$
, which implies that we obtain nested balls, as in Fig. 2.
Lemma 11. Assume
 $\mu_1\gg \alpha/N^{(d+1)/d}$
,
$\mu_1\gg \alpha/N^{(d+1)/d}$
,
 $\mu_2\gg (N\mu_1)^{d+1}/\alpha^d$
, and
$\mu_2\gg (N\mu_1)^{d+1}/\alpha^d$
, and
 $\mu_j\ll \mu_{j+1}$
for
$\mu_j\ll \mu_{j+1}$
for
 $j\geq 2$
. Then, for every
$j\geq 2$
. Then, for every
 $i\geq 1$
and
$i\geq 1$
and
 $j>i$
,
$j>i$
,
 \begin{equation} \mathbb{P}\big(\sigma_j<\sigma_i^{(2)}\big)\to 1. \end{equation}
\begin{equation} \mathbb{P}\big(\sigma_j<\sigma_i^{(2)}\big)\to 1. \end{equation}
Proof. The result in (19) when
 $i = 1$
was proved in part (ii) of Lemma 9. To establish the result when
$i = 1$
was proved in part (ii) of Lemma 9. To establish the result when
 $i \geq 2$
, we will show that, for all
$i \geq 2$
, we will show that, for all
 $i \geq 2$
and all
$i \geq 2$
and all
 $\varepsilon > 0$
, there exists
$\varepsilon > 0$
, there exists
 $\delta > 0$
such that, for sufficiently large N,
$\delta > 0$
such that, for sufficiently large N,
 \begin{align} \mathbb{P}\big(\sigma_{i-1}^{(2)} > \sigma_{i} + \kappa_{i} \delta\big) > 1 - \varepsilon , \end{align}
\begin{align} \mathbb{P}\big(\sigma_{i-1}^{(2)} > \sigma_{i} + \kappa_{i} \delta\big) > 1 - \varepsilon , \end{align}
 \begin{align} \mathbb{P}\big(\sigma_{i}^{(2)} > \sigma_{i} + \kappa_{i} \delta\big) > 1 - \varepsilon. \end{align}
\begin{align} \mathbb{P}\big(\sigma_{i}^{(2)} > \sigma_{i} + \kappa_{i} \delta\big) > 1 - \varepsilon. \end{align}
Assume for now that
 $i \geq 2$
, and that (20) and (21) hold. Let
$i \geq 2$
, and that (20) and (21) hold. Let
 $\varepsilon > 0$
, and choose
$\varepsilon > 0$
, and choose
 $\delta > 0$
to satisfy (21). Lemma 8 implies that if
$\delta > 0$
to satisfy (21). Lemma 8 implies that if
 $j > i$
then
$j > i$
then
 $\mathbb{P}(\sigma_j-\sigma_i < \kappa_i \delta) > 1 - \varepsilon$
for sufficiently large N. It follows that
$\mathbb{P}(\sigma_j-\sigma_i < \kappa_i \delta) > 1 - \varepsilon$
for sufficiently large N. It follows that
 \begin{align*}\mathbb{P}\big(\sigma_j<\sigma_i^{(2)}\big) \geq \mathbb{P}\big(\sigma_i^{(2)} > \sigma_i + \kappa_i \delta > \sigma_j\big) >1-2\varepsilon\end{align*}
\begin{align*}\mathbb{P}\big(\sigma_j<\sigma_i^{(2)}\big) \geq \mathbb{P}\big(\sigma_i^{(2)} > \sigma_i + \kappa_i \delta > \sigma_j\big) >1-2\varepsilon\end{align*}
for sufficiently large N, which implies (19).
It remains to prove (20) and (21); we proceed by induction. The result (20) when
 $i = 2$
is part (i) of Lemma 9. Therefore, it suffices to show that (20) implies (21), and that if (21) holds for some
$i = 2$
is part (i) of Lemma 9. Therefore, it suffices to show that (20) implies (21), and that if (21) holds for some
 $i \geq 2$
, then (20) holds with
$i \geq 2$
, then (20) holds with
 $i+1$
in place of i.
$i+1$
in place of i.
To deduce (21) from (20), we first let
 $\varepsilon > 0$
and use Lemma 7 to choose
$\varepsilon > 0$
and use Lemma 7 to choose
 $t > 0$
large enough that
$t > 0$
large enough that
 \begin{align*}\mathbb{P}(\sigma_i-\sigma_{i-1}>\kappa_{i}t) \leq \exp\!\bigg({-}\frac{\gamma_d}{d+1}t^{d+1}\bigg) < \frac{\varepsilon}{3}.\end{align*}
\begin{align*}\mathbb{P}(\sigma_i-\sigma_{i-1}>\kappa_{i}t) \leq \exp\!\bigg({-}\frac{\gamma_d}{d+1}t^{d+1}\bigg) < \frac{\varepsilon}{3}.\end{align*}
Then choose
 $\delta > 0$
small enough that (20) holds with
$\delta > 0$
small enough that (20) holds with
 $\varepsilon/3$
in place of
$\varepsilon/3$
in place of
 $\varepsilon$
for sufficiently large N, and
$\varepsilon$
for sufficiently large N, and
 \begin{align*}\exp\! \bigg( {-} \frac{\gamma_d}{d+1}[(t+\delta)^{d+1} - t^{d+1}] \bigg) > 1 - \frac{\varepsilon}{3}.\end{align*}
\begin{align*}\exp\! \bigg( {-} \frac{\gamma_d}{d+1}[(t+\delta)^{d+1} - t^{d+1}] \bigg) > 1 - \frac{\varepsilon}{3}.\end{align*}
It now follows from Lemma 10, that for sufficiently large N,
 \begin{align*}\mathbb{P}\big(\sigma_{i}^{(2)} > \sigma_{i} + \kappa_{i} \delta\big) > 1 - \frac{\varepsilon}{3} - \frac{\varepsilon}{3} - \frac{\varepsilon}{3} = 1 - \varepsilon,\end{align*}
\begin{align*}\mathbb{P}\big(\sigma_{i}^{(2)} > \sigma_{i} + \kappa_{i} \delta\big) > 1 - \frac{\varepsilon}{3} - \frac{\varepsilon}{3} - \frac{\varepsilon}{3} = 1 - \varepsilon,\end{align*}
so (21) holds.
Next, suppose (21) holds for some
 $i \geq 2$
. Let
$i \geq 2$
. Let
 $\varepsilon > 0$
. By (21), there exists
$\varepsilon > 0$
. By (21), there exists
 $\delta > 0$
such that, for sufficiently large N,
$\delta > 0$
such that, for sufficiently large N,
 \begin{align*}\mathbb{P}\big(\sigma_{i}^{(2)} > \sigma_{i} + \kappa_{i} \delta\big) > 1 - \frac{\varepsilon}{2}.\end{align*}
\begin{align*}\mathbb{P}\big(\sigma_{i}^{(2)} > \sigma_{i} + \kappa_{i} \delta\big) > 1 - \frac{\varepsilon}{2}.\end{align*}
By Lemma 8 and the fact that
 $\mu_i\ll \mu_{i+1}$
, we have
$\mu_i\ll \mu_{i+1}$
, we have
 $(\sigma_{i+1}-\sigma_i)/\kappa_i+\delta(\kappa_{i+1}/\kappa_i)\to_\textrm{p} 0$
. Thus, for sufficiently large N,
$(\sigma_{i+1}-\sigma_i)/\kappa_i+\delta(\kappa_{i+1}/\kappa_i)\to_\textrm{p} 0$
. Thus, for sufficiently large N,
 \begin{align*}\mathbb{P}\bigg(\frac{\sigma_{i+1}-\sigma_i}{\kappa_i} + \frac{\kappa_{i+1} \delta}{\kappa_i}<\delta\bigg)>1-\frac{\varepsilon}{2},\end{align*}
\begin{align*}\mathbb{P}\bigg(\frac{\sigma_{i+1}-\sigma_i}{\kappa_i} + \frac{\kappa_{i+1} \delta}{\kappa_i}<\delta\bigg)>1-\frac{\varepsilon}{2},\end{align*}
and therefore
 \begin{align*}\mathbb{P}\big(\sigma_i^{(2)}>\sigma_{i+1}+\kappa_{i+1}\delta\big) \geq \mathbb{P}\big(\sigma_i^{(2)}-\sigma_i > \kappa_i \delta> \sigma_{i+1} + \kappa_{i+1} \delta-\sigma_i\big)>1-\varepsilon,\end{align*}
\begin{align*}\mathbb{P}\big(\sigma_i^{(2)}>\sigma_{i+1}+\kappa_{i+1}\delta\big) \geq \mathbb{P}\big(\sigma_i^{(2)}-\sigma_i > \kappa_i \delta> \sigma_{i+1} + \kappa_{i+1} \delta-\sigma_i\big)>1-\varepsilon,\end{align*}
which is (20) with
 $i+1$
in place of i.
$i+1$
in place of i.
We now find the limiting distribution of distances between mutations of consecutive types.
Lemma 12. Suppose
 $\mu_1\gg\alpha/N^{(d+1)/d}$
,
$\mu_1\gg\alpha/N^{(d+1)/d}$
,
 $\mu_2\gg (N\mu_1)^{d+1}/\alpha^d$
, and
$\mu_2\gg (N\mu_1)^{d+1}/\alpha^d$
, and
 $\mu_j\ll \mu_{j+1}$
for
$\mu_j\ll \mu_{j+1}$
for
 $j\geq 2$
. Then, for all
$j\geq 2$
. Then, for all
 $s>0$
,
$s>0$
,
 \begin{equation} \mathbb{P}\bigg(\frac{D_{j+1}}{\alpha\kappa_{j+1}}\leq s\bigg) \to \int_{0}^{\infty}\gamma_d(t \wedge s)^d\exp\!\Bigg({-}\frac{\gamma_dt^{d+1}}{d+1}\bigg)\,\textrm{d} t. \end{equation}
\begin{equation} \mathbb{P}\bigg(\frac{D_{j+1}}{\alpha\kappa_{j+1}}\leq s\bigg) \to \int_{0}^{\infty}\gamma_d(t \wedge s)^d\exp\!\Bigg({-}\frac{\gamma_dt^{d+1}}{d+1}\bigg)\,\textrm{d} t. \end{equation}
Proof. Define the event
 $A\;:\!=\;\bigcap_{i=1}^{j}\{\sigma_{j+1}<\sigma_i^{(2)}\}$
. On the event A, the first type
$A\;:\!=\;\bigcap_{i=1}^{j}\{\sigma_{j+1}<\sigma_i^{(2)}\}$
. On the event A, the first type
 $j+1$
mutation appears before the second mutation of any type
$j+1$
mutation appears before the second mutation of any type
 $i \in \{1, \dots, j\}$
. By Lemma 11, we have
$i \in \{1, \dots, j\}$
. By Lemma 11, we have
 $\mathbb{P}(A)\to 1$
. As a result, it will be sufficient for us to consider a modified version of our process in which, for
$\mathbb{P}(A)\to 1$
. As a result, it will be sufficient for us to consider a modified version of our process in which, for
 $i \in \{1, \dots, j\}$
, only the first type i mutation is permitted to occur. Note that this modified process can be constructed from the same sequence of independent Poisson processes
$i \in \{1, \dots, j\}$
, only the first type i mutation is permitted to occur. Note that this modified process can be constructed from the same sequence of independent Poisson processes
 $(\Pi_i)_{i=1}^{\infty}$
as the original process. However, in the modified process, all points of
$(\Pi_i)_{i=1}^{\infty}$
as the original process. However, in the modified process, all points of
 $\Pi_i$
after time
$\Pi_i$
after time
 $\sigma_i$
are disregarded. On the event A, the first
$\sigma_i$
are disregarded. On the event A, the first
 $j+1$
mutations will occur at exactly the same times and locations in the original process as in the modified process. Therefore, because
$j+1$
mutations will occur at exactly the same times and locations in the original process as in the modified process. Therefore, because
 $\mathbb{P}(A) \rightarrow 1$
, it suffices to prove (22) for this modified process. For the rest of the proof we will work with this modified process, which makes exact calculations possible.
$\mathbb{P}(A) \rightarrow 1$
, it suffices to prove (22) for this modified process. For the rest of the proof we will work with this modified process, which makes exact calculations possible.
Let
 $K\in (s,\infty)$
be a constant which does not depend on N. Our assumptions imply that
$K\in (s,\infty)$
be a constant which does not depend on N. Our assumptions imply that
 $\mu_{j+1}\gg\mu_1\gg\alpha/N^{(d+1)/d}$
. Thus, there is an
$\mu_{j+1}\gg\mu_1\gg\alpha/N^{(d+1)/d}$
. Thus, there is an
 $N_K$
such that for
$N_K$
such that for
 $N \geq N_K$
we have
$N \geq N_K$
we have
 $\kappa_{j+1}t< L/(2\alpha)$
for all
$\kappa_{j+1}t< L/(2\alpha)$
for all
 $t\in[0,K]$
. It follows that
$t\in[0,K]$
. It follows that
 $Y_{j}(s)=\gamma_d\alpha^d(s-\sigma_j)^d$
for
$Y_{j}(s)=\gamma_d\alpha^d(s-\sigma_j)^d$
for
 $s\in [\sigma_j,\sigma_j+\kappa_{j+1}K]$
. Therefore, reasoning as in the proof of Lemma 7, we get
$s\in [\sigma_j,\sigma_j+\kappa_{j+1}K]$
. Therefore, reasoning as in the proof of Lemma 7, we get
 \begin{equation} \mathbb{P}(\sigma_{j+1}-\sigma_j>\kappa_{j+1}t) = \exp\!\Bigg({-}\frac{\gamma_d}{d+1}t^{d+1}\bigg). \end{equation}
\begin{equation} \mathbb{P}(\sigma_{j+1}-\sigma_j>\kappa_{j+1}t) = \exp\!\Bigg({-}\frac{\gamma_d}{d+1}t^{d+1}\bigg). \end{equation}
It follows that, for
 $N \geq N_K$
, the probability density of
$N \geq N_K$
, the probability density of
 $(\sigma_{j+1}-\sigma_j)/\kappa_{j+1}$
restricted to [0, K] is
$(\sigma_{j+1}-\sigma_j)/\kappa_{j+1}$
restricted to [0, K] is
 \begin{align*}f(t)\;:\!=\;\gamma_d t^d\exp\!\bigg({-}\frac{\gamma_d}{d+1}t^{d+1}\bigg).\end{align*}
\begin{align*}f(t)\;:\!=\;\gamma_d t^d\exp\!\bigg({-}\frac{\gamma_d}{d+1}t^{d+1}\bigg).\end{align*}
For
 $N \geq N_K$
and
$N \geq N_K$
and
 $t \in [0,K]$
, conditional on the event
$t \in [0,K]$
, conditional on the event
 $\{\sigma_{j+1}-\sigma_j=\kappa_{j+1}t\}$
, the location of the first type
$\{\sigma_{j+1}-\sigma_j=\kappa_{j+1}t\}$
, the location of the first type
 $j+1$
mutation is a uniformly random point on a d-dimensional ball of radius
$j+1$
mutation is a uniformly random point on a d-dimensional ball of radius
 $\alpha\kappa_{j+1}t$
, which means
$\alpha\kappa_{j+1}t$
, which means
 \begin{align*}\mathbb{P}\bigg(\frac{D_{j+1}}{\alpha\kappa_{j+1}} \leq s\mid\frac{\sigma_{j+1}-\sigma_j}{\kappa_{j+1}}=t \bigg) = \textbf{1}_{\{s>t\}} + \frac{\gamma_d(\alpha\kappa_{j+1}s)^d}{\gamma_d(\alpha\kappa_{j+1}t)^d}\textbf{1}_{\{s\leq t\}} = \textbf{1}_{\{s>t\}}+\frac{s^d}{t^d}\textbf{1}_{\{s\leq t\}}.\end{align*}
\begin{align*}\mathbb{P}\bigg(\frac{D_{j+1}}{\alpha\kappa_{j+1}} \leq s\mid\frac{\sigma_{j+1}-\sigma_j}{\kappa_{j+1}}=t \bigg) = \textbf{1}_{\{s>t\}} + \frac{\gamma_d(\alpha\kappa_{j+1}s)^d}{\gamma_d(\alpha\kappa_{j+1}t)^d}\textbf{1}_{\{s\leq t\}} = \textbf{1}_{\{s>t\}}+\frac{s^d}{t^d}\textbf{1}_{\{s\leq t\}}.\end{align*}
It follows that, for
 $N \geq N_K$
,
$N \geq N_K$
,
 \begin{align*} \mathbb{P}\bigg(\frac{D_{j+1}}{\alpha\kappa_{j+1}}\leq s \bigg) &= \int_0^K f(t) \bigg( \textbf{1}_{\{s>t\}}+\frac{s^d}{t^d}\textbf{1}_{\{s\leq t\}} \bigg) \, \textrm{d} t + \mathbb{P} \bigg( \frac{D_{j+1}}{\alpha\kappa_{j+1}}\leq s, \: \frac{\sigma_{j+1}-\sigma_j}{\kappa_{j+1}} > K \bigg) \\[5pt] &= \int_0^K \gamma_d(t \wedge s)^d\exp\!\bigg({-}\frac{\gamma_dt^{d+1}}{d+1}\bigg) \, \textrm{d} t + \mathbb{P} \bigg( \frac{D_{j+1}}{\alpha\kappa_{j+1}}\leq s, \: \frac{\sigma_{j+1}-\sigma_j}{\kappa_{j+1}} > K \bigg). \end{align*}
\begin{align*} \mathbb{P}\bigg(\frac{D_{j+1}}{\alpha\kappa_{j+1}}\leq s \bigg) &= \int_0^K f(t) \bigg( \textbf{1}_{\{s>t\}}+\frac{s^d}{t^d}\textbf{1}_{\{s\leq t\}} \bigg) \, \textrm{d} t + \mathbb{P} \bigg( \frac{D_{j+1}}{\alpha\kappa_{j+1}}\leq s, \: \frac{\sigma_{j+1}-\sigma_j}{\kappa_{j+1}} > K \bigg) \\[5pt] &= \int_0^K \gamma_d(t \wedge s)^d\exp\!\bigg({-}\frac{\gamma_dt^{d+1}}{d+1}\bigg) \, \textrm{d} t + \mathbb{P} \bigg( \frac{D_{j+1}}{\alpha\kappa_{j+1}}\leq s, \: \frac{\sigma_{j+1}-\sigma_j}{\kappa_{j+1}} > K \bigg). \end{align*}
Because (23) implies that
 \begin{align*}\lim_{K \rightarrow \infty} \lim_{N \rightarrow \infty} \mathbb{P} \bigg( \frac{D_{j+1}}{\alpha\kappa_{j+1}}\leq s, \: \frac{\sigma_{j+1}-\sigma_j}{\kappa_{j+1}} > K \bigg) = 0,\end{align*}
\begin{align*}\lim_{K \rightarrow \infty} \lim_{N \rightarrow \infty} \mathbb{P} \bigg( \frac{D_{j+1}}{\alpha\kappa_{j+1}}\leq s, \: \frac{\sigma_{j+1}-\sigma_j}{\kappa_{j+1}} > K \bigg) = 0,\end{align*}
the result (22) follows by letting
 $N \rightarrow \infty$
and then
$N \rightarrow \infty$
and then
 $K \rightarrow \infty$
.
$K \rightarrow \infty$
.
Proof of Theorem
5. Lemma 12 proves the case when
 $k=j+1$
, so assume that
$k=j+1$
, so assume that
 $k\geq j+2$
. The triangle inequality implies that
$k\geq j+2$
. The triangle inequality implies that
 \begin{align*}D_{j+1}-(D_{j+2}+\cdots+D_{k})\leq D_{j,k}\leq D_{j+1}+(D_{j+2}+\cdots+D_{k}).\end{align*}
\begin{align*}D_{j+1}-(D_{j+2}+\cdots+D_{k})\leq D_{j,k}\leq D_{j+1}+(D_{j+2}+\cdots+D_{k}).\end{align*}
Suppose
 $j+2 \leq i \leq k$
. We know from Lemma 12 that
$j+2 \leq i \leq k$
. We know from Lemma 12 that
 $D_i/(\alpha \kappa_i)$
converges in distribution to a non-degenerate random variable as
$D_i/(\alpha \kappa_i)$
converges in distribution to a non-degenerate random variable as
 $N \rightarrow \infty$
. Because
$N \rightarrow \infty$
. Because
 $\kappa_{j+1}/\kappa_i \rightarrow \infty$
by the assumption in (9), it follows that
$\kappa_{j+1}/\kappa_i \rightarrow \infty$
by the assumption in (9), it follows that
 $D_i/(\alpha \kappa_{j+1}) \to_\textrm{p} 0$
. Therefore,
$D_i/(\alpha \kappa_{j+1}) \to_\textrm{p} 0$
. Therefore,
 \begin{align*}(D_{j+2}+\cdots +D_{k})/(\alpha\kappa_{j+1})\to_\textrm{p} 0.\end{align*}
\begin{align*}(D_{j+2}+\cdots +D_{k})/(\alpha\kappa_{j+1})\to_\textrm{p} 0.\end{align*}
Thus, Theorem 5 follows from Lemma 12 and Slutsky’s theorem.
4.2. Proof of Theorem 6
Having found a limiting distribution for distances between mutations in the setting of Theorem 2, we now prove a similar result in the setting of Theorem 4, where once the first type l mutation appears, all subsequent mutations appear in nested balls.
We begin with a result that bounds
 $\sigma_l^{(2)}-\sigma_l$
away from zero with high probability, on the time scale
$\sigma_l^{(2)}-\sigma_l$
away from zero with high probability, on the time scale
 $\beta_l$
.
$\beta_l$
.
Lemma 13.
Assume the same hypotheses as Theorem 4. Then, for all
 $\varepsilon>0$
, there is
$\varepsilon>0$
, there is
 $r>0$
such that
$r>0$
such that
 $\liminf_{N\to\infty}\mathbb{P}\big(\sigma_l^{(2)}-\sigma_l>\beta_l r\big)>1-\varepsilon$
.
$\liminf_{N\to\infty}\mathbb{P}\big(\sigma_l^{(2)}-\sigma_l>\beta_l r\big)>1-\varepsilon$
.
Proof. Let
 $\varepsilon>0$
. Using Theorem 3, choose a large
$\varepsilon>0$
. Using Theorem 3, choose a large
 $t>0$
so that
$t>0$
so that
 \begin{align} \lim_{N\to\infty}\mathbb{P}(\sigma_l\leq \beta_l t)>1-\frac{\varepsilon}{2}. \end{align}
\begin{align} \lim_{N\to\infty}\mathbb{P}(\sigma_l\leq \beta_l t)>1-\frac{\varepsilon}{2}. \end{align}
Now set, as in the proof of Theorem 3,
 \begin{align*}g(s)\;:\!=\;\frac{\gamma_d^{l-1}(d!)^{l-1}s^{(l-1)(d+1)}}{((l-1)(d+1))!}.\end{align*}
\begin{align*}g(s)\;:\!=\;\frac{\gamma_d^{l-1}(d!)^{l-1}s^{(l-1)(d+1)}}{((l-1)(d+1))!}.\end{align*}
It is clear that we can choose a small
 $r>0$
so that
$r>0$
so that
 \begin{align} \exp\!\bigg({-}\int_t^{t+r}g(s)\,\textrm{d} s\bigg)>1-\frac{\varepsilon}{2}. \end{align}
\begin{align} \exp\!\bigg({-}\int_t^{t+r}g(s)\,\textrm{d} s\bigg)>1-\frac{\varepsilon}{2}. \end{align}
Having chosen
 $t>0$
and
$t>0$
and
 $r>0$
, choose
$r>0$
, choose
 $\delta>0$
so that
$\delta>0$
so that
 $[t,t+r]\subseteq [\delta,\delta^{-1}]$
. Then, for any
$[t,t+r]\subseteq [\delta,\delta^{-1}]$
. Then, for any
 $\lambda>0$
, define, as in Lemma 4, the event
$\lambda>0$
, define, as in Lemma 4, the event
 \begin{align*}B \;:\!=\; B_N^{l-1}\bigg(\delta,\lambda,g,\frac{1}{\mu_l\beta_l}\bigg) = \bigg\{\frac{g(u)(1-\lambda)}{\beta_l\mu_l}\leq Y_{l-1}(\beta_lu) \leq \frac{g(u)(1+\lambda)}{\beta_l\mu_l},\enspace \text{for all } u\in[\delta,\delta^{-1}]\bigg\}.\end{align*}
\begin{align*}B \;:\!=\; B_N^{l-1}\bigg(\delta,\lambda,g,\frac{1}{\mu_l\beta_l}\bigg) = \bigg\{\frac{g(u)(1-\lambda)}{\beta_l\mu_l}\leq Y_{l-1}(\beta_lu) \leq \frac{g(u)(1+\lambda)}{\beta_l\mu_l},\enspace \text{for all } u\in[\delta,\delta^{-1}]\bigg\}.\end{align*}
Now we calculate
 \begin{align} \mathbb{P}\big(\sigma_l^{(2)}-\sigma_l>\beta_l r\big) & = \mathbb{E}\bigg[\exp\!\bigg({-}\int_{\sigma_l}^{\sigma_l+\beta_l r}\mu_lY_{l-1}(s)\,\textrm{d} s\bigg)\bigg] \nonumber \\[5pt] & \geq \mathbb{E}\bigg[\exp\!\bigg({-}\int_{\sigma_l}^{\sigma_l+\beta_l r}\mu_lY_{l-1}(s)\,\textrm{d} s\bigg) \textbf{1}_{\{\sigma_l\leq \beta_l t\}}\textbf{1}_{B}\bigg]. \end{align}
\begin{align} \mathbb{P}\big(\sigma_l^{(2)}-\sigma_l>\beta_l r\big) & = \mathbb{E}\bigg[\exp\!\bigg({-}\int_{\sigma_l}^{\sigma_l+\beta_l r}\mu_lY_{l-1}(s)\,\textrm{d} s\bigg)\bigg] \nonumber \\[5pt] & \geq \mathbb{E}\bigg[\exp\!\bigg({-}\int_{\sigma_l}^{\sigma_l+\beta_l r}\mu_lY_{l-1}(s)\,\textrm{d} s\bigg) \textbf{1}_{\{\sigma_l\leq \beta_l t\}}\textbf{1}_{B}\bigg]. \end{align}
Because
 $Y_{l-1}(s)$
is monotone increasing in s, on the event
$Y_{l-1}(s)$
is monotone increasing in s, on the event
 $\{\sigma_l\leq \beta_l t\}\cap B$
we have
$\{\sigma_l\leq \beta_l t\}\cap B$
we have
 \begin{align*}\int_{\sigma_l}^{\sigma_l+\beta_l r}\mu_lY_{l-1}(s)\,\textrm{d} s \leq \int_{\beta_l t}^{\beta_l(t+r)}\mu_l Y_{l-1}(s)\, \textrm{d} s \leq (1+\lambda) \int_{t}^{t+r}g(s)\,\textrm{d} s.\end{align*}
\begin{align*}\int_{\sigma_l}^{\sigma_l+\beta_l r}\mu_lY_{l-1}(s)\,\textrm{d} s \leq \int_{\beta_l t}^{\beta_l(t+r)}\mu_l Y_{l-1}(s)\, \textrm{d} s \leq (1+\lambda) \int_{t}^{t+r}g(s)\,\textrm{d} s.\end{align*}
Using the above and (26), we have
 \begin{align*}\mathbb{P}\big(\sigma_l^{(2)}-\sigma_l>\beta_l r\big) \geq \exp\!\bigg({-}(1+\lambda)\int_t^{t+r}g(s)\,\textrm{d} s\bigg)\mathbb{P}(\{\sigma_l\leq \beta_l t\} \cap B).\end{align*}
\begin{align*}\mathbb{P}\big(\sigma_l^{(2)}-\sigma_l>\beta_l r\big) \geq \exp\!\bigg({-}(1+\lambda)\int_t^{t+r}g(s)\,\textrm{d} s\bigg)\mathbb{P}(\{\sigma_l\leq \beta_l t\} \cap B).\end{align*}
Now take
 $N\to\infty$
. Using that
$N\to\infty$
. Using that
 $\mathbb{P}(B)\to 1$
as shown in the proof of Theorem 3, and using (24), we have
$\mathbb{P}(B)\to 1$
as shown in the proof of Theorem 3, and using (24), we have
 \begin{align*} \liminf_{N\to\infty}\mathbb{P}\big(\sigma_l^{(2)}-\sigma_l>\beta_l r\big) & \geq \exp\!\bigg({-}(1+\lambda)\int_t^{t+r}g(s)\,\textrm{d} s\bigg) \cdot \liminf_{N\to\infty}\mathbb{P}(\sigma_l\leq \beta_l t) \\[5pt] & > \exp\!\bigg({-}(1+\lambda)\int_t^{t+r}g(s)\,\textrm{d} s\bigg)\bigg(1-\frac{\varepsilon}{2}\bigg). \end{align*}
\begin{align*} \liminf_{N\to\infty}\mathbb{P}\big(\sigma_l^{(2)}-\sigma_l>\beta_l r\big) & \geq \exp\!\bigg({-}(1+\lambda)\int_t^{t+r}g(s)\,\textrm{d} s\bigg) \cdot \liminf_{N\to\infty}\mathbb{P}(\sigma_l\leq \beta_l t) \\[5pt] & > \exp\!\bigg({-}(1+\lambda)\int_t^{t+r}g(s)\,\textrm{d} s\bigg)\bigg(1-\frac{\varepsilon}{2}\bigg). \end{align*}
Since
 $\lambda>0$
is arbitrary, (25) implies
$\lambda>0$
is arbitrary, (25) implies
 $\liminf_{N\to\infty}\mathbb{P}\big(\sigma_l^{(2)}-\sigma_l>\beta_l r\big) > (1-\varepsilon/2)^2 > 1-\varepsilon$
, completing the proof.
$\liminf_{N\to\infty}\mathbb{P}\big(\sigma_l^{(2)}-\sigma_l>\beta_l r\big) > (1-\varepsilon/2)^2 > 1-\varepsilon$
, completing the proof.
Using Lemma 13, we prove an analog of Lemma 9 in the setting of Theorem 4.
Lemma 14. Assume the same hypotheses as Theorem 4. Then:
-
(i) For all
$t>0$
,
$\mathbb{P}\big(\sigma_{l+1}+\kappa_{l+1}t<\sigma_{l}^{(2)}\big)\to 1$
. -
(ii) For every
$k\geq l+1$
,
$\mathbb{P}\big(\sigma_{k}<\sigma_l^{(2)}\big)\to 1$
.




Proof. Let
 $\varepsilon>0$
. Lemma 13 implies that there is
$\varepsilon>0$
. Lemma 13 implies that there is
 $r>0$
such that, for sufficiently large N,
$r>0$
such that, for sufficiently large N,
 \begin{equation} \mathbb{P}\big(\sigma_l^{(2)}-\sigma_l>\beta_lr\big)>1-\varepsilon. \end{equation}
\begin{equation} \mathbb{P}\big(\sigma_l^{(2)}-\sigma_l>\beta_lr\big)>1-\varepsilon. \end{equation}
Now note that
 $(\sigma_{l+1}-\sigma_l)/\beta_l\to_p 0$
by (15) in the proof of Theorem 4. Also, our assumption that
$(\sigma_{l+1}-\sigma_l)/\beta_l\to_p 0$
by (15) in the proof of Theorem 4. Also, our assumption that
 $\mu_{l+1}\gg 1/\big(\alpha^d\beta_l^{d+1}\big)$
is equivalent to
$\mu_{l+1}\gg 1/\big(\alpha^d\beta_l^{d+1}\big)$
is equivalent to
 $\kappa_{l+1}\ll \beta_l$
. It follows that, for sufficiently large N,
$\kappa_{l+1}\ll \beta_l$
. It follows that, for sufficiently large N,
 $\mathbb{P}((\sigma_{l+1}-\sigma_l+\kappa_{l+1}t)/\beta_l<r)>1-\varepsilon$
. This estimate along with (27) imply that
$\mathbb{P}((\sigma_{l+1}-\sigma_l+\kappa_{l+1}t)/\beta_l<r)>1-\varepsilon$
. This estimate along with (27) imply that
 $\mathbb{P}\big(\sigma_{l+1}+\kappa_{l+1}t<\sigma_l^{(2)}\big)>1-2\varepsilon$
for sufficiently large N. This proves the first statement. The second statement is proved similarly, using instead that
$\mathbb{P}\big(\sigma_{l+1}+\kappa_{l+1}t<\sigma_l^{(2)}\big)>1-2\varepsilon$
for sufficiently large N. This proves the first statement. The second statement is proved similarly, using instead that
 $(\sigma_k-\sigma_l)/\beta_l\to_\textrm{p} 0$
by (15).
$(\sigma_k-\sigma_l)/\beta_l\to_\textrm{p} 0$
by (15).
At this point, we have proved that, for
 $k>l$
, the first type k mutation occurs before
$k>l$
, the first type k mutation occurs before
 $\sigma_l^{(2)}$
with probability tending to 1 as
$\sigma_l^{(2)}$
with probability tending to 1 as
 $N\to \infty$
. This implies that in the setting of Theorem 4, we can disregard the type
$N\to \infty$
. This implies that in the setting of Theorem 4, we can disregard the type
 $1,\ldots,l-1$
mutations and regard the first type l mutation as the first type 1 mutation, and then prove Theorem 6 by following the same argument used to prove Theorem 5.
$1,\ldots,l-1$
mutations and regard the first type l mutation as the first type 1 mutation, and then prove Theorem 6 by following the same argument used to prove Theorem 5.
Proof of Theorem
6. Relabel the type
 $l,l+1,l+2,\ldots$
mutations as type
$l,l+1,l+2,\ldots$
mutations as type
 $1,2,3,\ldots$
mutations, and repeat the arguments in Lemmas 7–12 and in the proof of Theorem 5. The only difference is that we have to apply Lemma 14 instead of Lemma 9. Note that type l mutations do not appear at the same rate as type 1 mutations, so we needed a different technique to establish
$1,2,3,\ldots$
mutations, and repeat the arguments in Lemmas 7–12 and in the proof of Theorem 5. The only difference is that we have to apply Lemma 14 instead of Lemma 9. Note that type l mutations do not appear at the same rate as type 1 mutations, so we needed a different technique to establish
 $\mathbb{P}\big(\sigma_j<\sigma_l^{(2)}\big)\to 1$
for
$\mathbb{P}\big(\sigma_j<\sigma_l^{(2)}\big)\to 1$
for
 $j>l$
.
$j>l$
.
Acknowledgements
The authors thank Jasmine Foo for suggesting the problem of looking at the case of increasing mutation rates, and bringing to their attention the references [Reference Loeb and Loeb16, Reference Prindle, Fox and Loeb22].
Funding information
JS was supported in part by NSF Grant DMS-1707953.
Competing interests
There were no competing interests to declare which arose during the preparation or publication process of this article.





