



1 Introduction
German-speaking Switzerland’s linguistic situation has been used as a textbook case for outlining ‘diglossia’ (Ferguson Reference Ferguson1959). Specifically, two context-dependent varieties are used; Alemannic (ALM) dialects, commonly referred to as Swiss German Footnote 1 or Mundart (verbatim ‘mouth kind’), for oral communication, and Swiss Standard German (SSG), also called Schriftdeutsch (verbatim ‘script German’), for written communication. In other words, in German-speaking Switzerland, everyone is a native speaker of a local dialect while SSG is learned at school. To a certain extent, both ALM and SSG can also be used in the other variety’s domain, and Swiss people generally code-switch quite quickly, indicating that we are not dealing with a standard-dialect continuum (Hove Reference Hove, Helen and Evelyn2008a: 71). Given this state of affairs, contact between the two varieties is inevitable, so it is not surprising that research has reported interferences on the phonetic, morphological, syntactic, and lexical level for a long time (see Panizzolo Reference Panizzolo1982, Meyer Reference Meyer1989). Regarding the specific topic of this study, i.e. vowels, there are only four acoustic studies on ALM dialects (Schmid Reference Schmid2004, Bigler Reference Bigler2007, Ruch Reference Ruch2015, Hove Reference Hove2020). Regarding SSG, vowels have been described in Hove (Reference Hove2002); Iivonen (Reference Iivonen1983) provided formant charts based on acoustic measurements. Only one study has compared ALM and SSG in Bern, St Gallen, and Zurich (Siebenhaar Reference Siebenhaar1994); however, only the SSG vowels were transcribed auditorily. The current study will thus, for the first time, systematically investigate the vowel qualities of four ALM dialects and their respective SSG varieties with an instrumental phonetic approach, providing a comparative acoustic analysis of the long vowels produced by the same speakers from Bern (BE), Chur (GR), Brig (VS) and Zurich (ZH).Footnote 2 In particular, it will analyse to which extent SSG vowel qualities are determined by the speakers’ dialect.
After a short description of ALM dialects and the SSG varieties spoken in German-speaking Switzerland, each variety’s long vowels will be illustrated, followed by a presentation of the research questions and hypotheses that have guided the current study.
1.1 Alemannic dialects in Switzerland
Swiss ALM dialects can be put into three subgroups: Low ALM, which can only be found in the city of Basel, High ALM, comprising the dialects of the northern half, and Highest ALM, spoken in the alpine southern half of German-speaking Switzerland (Christen, Glaser & Friedli Reference Christen, Glaser and Friedli2013: 29–30). As High and Highest ALM make up most of the dialects in German-speaking Switzerland, this study will focus on these two.
High and Highest ALM are defined by an average of multiple isoglosses that tend to divide German-speaking Switzerland into a northern and southern half. The most famous isogloss is hiatus diphthongisation. The northern half, i.e. High ALM, has developed a diphthong in Old High German (OHG) hiatus positions whereas the southern half, i.e. Highest ALM, maintained a monophthong (Hotzenköcherle Reference Hotzenköcherle1984: 33). For instance, the ALM equivalents of the standard German verb bauen ‘to build’ are traditionally pronounced with a diphthong as e.g. [ˈb̥ou̯.ə] in the northern half, and with a monophthong as e.g. [ˈb̥uː.ə] in the southern half. However, either dialect group is not as homogeneous as their names might suggest. Rather, along with the north–south divide, which itself is not a clear divide but a transition zone, there exists also an east–west divide that is based on multiple averaged phonetic, lexical, and morphosyntactic isoglosses. For instance, /l/-vocalisation is a phonetic phenomenon that separates the western parts from the eastern parts (Leemann et al. Reference Leemann, Kolly, Werlen, Britain and Studer-Joho2014). In most of the western parts, /l/ is vocalised to different variants of [u], whereas the east does not have a vocalised realisation of the phoneme /l/.Footnote 3 Nevertheless, there are many instances where the north–south and east–west divides are not as straightforward. Often, multiple variants exist for a word or a sound. However, those that do show a less complex scattering tend to group in accordance with these two axes.
In conclusion, when we overlap these two averaged isogloss divisions, we see that German-speaking Switzerland consists of four broad dialect regions as depicted in Figure 1, not considering Basel (where a Low ALM dialect is spoken) and Samnaun (where a Bavarian dialect is spoken).
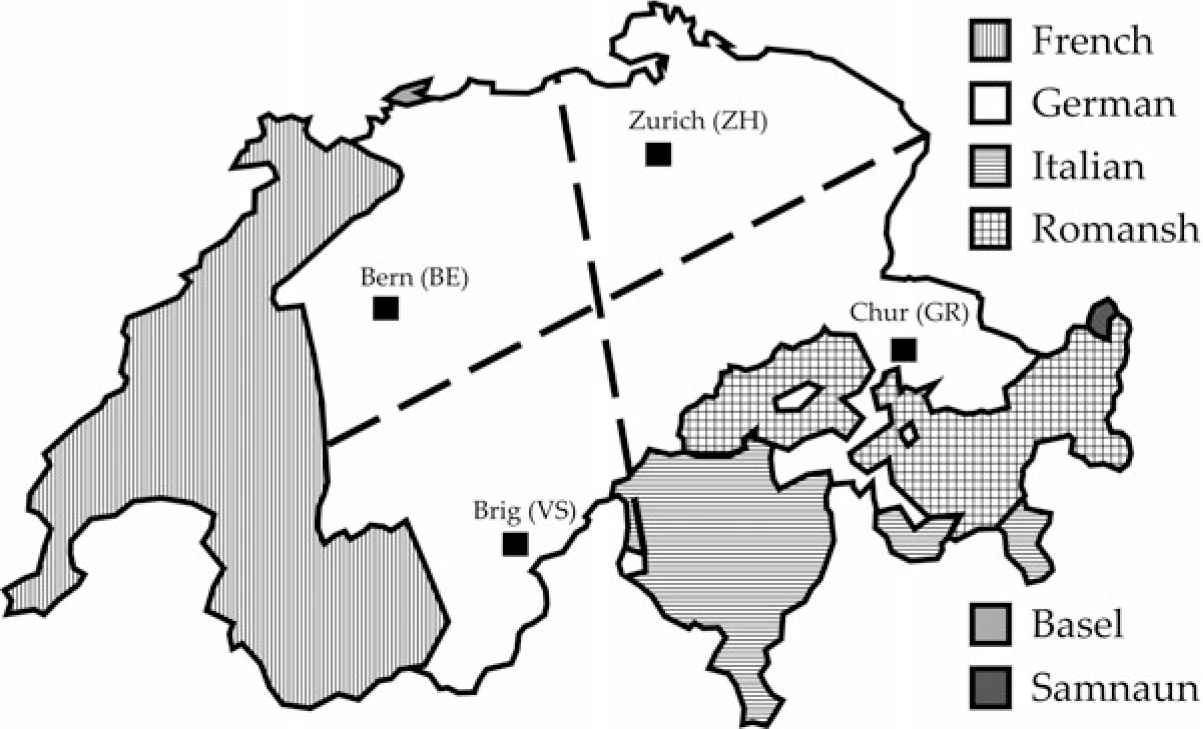
Figure 1 Linguistic map of Switzerland showing the location of the cities whose dialects were scrutinised within the four approximate dialectal quadrants.
1.2 Long-vowel inventories and formant measurements in Alemannic
In this section, the dialect-specific long-vowel repertoires and the respective formant measurements found in the literature will be summarised.
Marti (Reference Marti1985a) states that BE has the following long vowels: /iː yː ɪː ʏː ɛː œː æː ɑː ɔː ʊː uː/. However, BE – and western dialects in general – have lowered /iː yː uː/ if the vowels originate in lengthened MHG <ii üü uu> (Keller Reference Keller1961: 91–92). Yet the BE phoneme-to-grapheme mapping differs from e.g. the Lucerne (LU) one in that in BE these vowels are orthographically represented by <ii üü uu> (or <ìì ǜǜ ùù>) and transcribed as [ɪː ʏː ʊː], whereas in LU the conventional orthographic representations <ee öö oo> are transcribed as [eː 퀈ː oː]Footnote 4 (Fischer Reference Fischer1960; Marti Reference Marti1985b; Zihlmann & Leemann Reference Zihlmann and Adrian2016: 239). Based on auditory impression, the BE lowered /ɪː ʏː ʊː/ are similar to the other dialects’ /eː 퀈ː oː/; therefore, the BE long-vowel inventory was transcribed as [iː yː eː 퀈ː ɛː œː æː ɑː ɔː oː uː]. Note that the primary goal of the current study is the comparison of vowel qualities, not of phonemes; from a strictly phonological point of view, /ɪː ʏː ʊː/ occupy a different position in the BE vowel system compared to the vowels /eː 퀈ː oː/ of SSG or other ALM dialects (e.g. ZH). Moving on to GR, its long-vowel inventory has been described as /iː yː eː 퀈ː ɛː aː ɔː oː uː/ by Eckhardt (Reference Eckhardt1991: 36). As for VS, Werlen (Reference Werlen1977: 131) points out that its long vowel phonemes are /iː yː eː æː ɒː oː/. In the traditional variety, /uː/ does not exist as OHG ū has developed into /yː/ except before /v/. However, in loan words adopted into the lexicon after this sound change had occurred, as e.g. [ˈluːpə] ‘magnifying glass’, one does indeed encounter it (Wipf Reference Wipf1910: 35). Lastly, the long-vowel inventory of ZH has been described by Schmid (Reference Schmid2004: 97) and Fleischer & Schmid (Reference Fleischer and Stephan2006: 246–247) as containing the phonemes /iː yː eː 퀈ː ɛː œː æː ɒː oː uː/. Traditionally, more long vowels were ascribed to the ZH dialect. For instance, Weber (Reference Weber1987: 25, 30–31) claims that two phonemes exist for /iː/ and /ɪː/, e.g. [miːχ] ‘me’ and [ʋ̥ɪː] ‘wine’, /uː/ and /ʊː/, e.g. [b̥uːχ] ‘belly’ and [jʊːd̥] ‘Jew’, as well as /yː/ and /ʏː/, e.g. [tyːɾ] ‘door’ and [d̥ʏːɾ] ‘dry’. More recent studies suggest, however, that these distinctions are disappearing (see Schobinger Reference Schobinger2000: 118; Schmid Reference Schmid2004: 97–99; Fleischer & Schmid Reference Fleischer and Stephan2006: 247), which is why they were not included in the current study. To sum up the documentation of the dialect-specific long-vowel repertoires, two instances of subphonemic differences between the four dialects investigated in this study can be attested. The first one being the ALM <a>-sounds, which is /aː/ in GR, /ɒː/ in VS and ZH, and /ɑː/ in BE. Except for GR, where the respective word is not produced with an /aː/, the Linguistic Atlas of German-speaking Switzerland (SDS 1962: map 79) confirms these ALM vowel qualities for the <a>-sounds although for the creation of the SDS, the vowels were only transcribed auditorily. The second instance concerns the middle vowels <ee öö oo>, which in BE are realised in a slightly open fashion resembling /ɛː œː ɔː/, and in GR, VS, and ZH resembling /eː 퀈ː oː/ (SDS 1962: maps 95, 99, 102).
With regard to formant frequency measurements, for BE, VS, and ZH, Bigler (Reference Bigler2007) has provided an acoustic description of their vowel qualities. His dataset is based on stories read by one BE, one ZH, one female VS and one male VS speaker in 1952. Therefore, his corpus occasionally entails only a few repetitions of a phoneme, and sometimes even lacks a phoneme entirely. Moreover, formant frequencies – normalised with Pfitzinger’s (Reference Pfitzinger2003) method – are unfortunately only represented in vowel plots without tables containing specific measurements. Nevertheless, I extrapolated the approximate F1/F2 measurements for BE, VS, and ZH with a ruler and summarised them in Table 1. Regarding GR, no data have been reported so far.
Table 1 Mean F1 and F2 values (in Hz) for long vowels in the Alemannic dialects of Bern (BE; all speakers), Brig (VS; female speakers) and Zurich (ZH; male speakers), extrapolated from Bigler’s (Reference Bigler2007: 33, 42, 47, 51) formant charts.

As for BE, Bigler (Reference Bigler2007: 33) points out the overlap between /uː/ and /ʊː/ as well as /oː/ and /ɔː/. However, the values of /ʊː/ and /ɔː/ are only based on two measurements each, so it is unclear whether the plot is generalisable. Otherwise, the BE long-vowel inventory is straightforwardly separated and grouped in clear-cut vowel-quality categories. For VS, based on an analysis of a female and a male speaker from Brig, the same author found some surprising and rather counterintuitive results (Bigler Reference Bigler2007: 40–49). The female speaker’s /eː/ and /ɛː/ are unusually far apart from one another, and the formant values for /ɛː/ point to a higher and more fronted vowel than /eː/. However, given that both vowels were only recorded once each, these generalisations must be taken with a pinch of salt. As for the male speaker, only a few measurements per vowel were taken. Bigler (Reference Bigler2007: 47) states that /yː/ and /eː/ show little, and /oː/ much variation within each vowel quality. Yet again, this can most likely be explained by the small amount of data on which the analysis is based. As for ZH, Bigler’s (Reference Bigler2007: 51) data suggest that the long vowels measured are clearly distinct from one another given that there is no overlap, except /uː/ that shows an unusually great amount of variation. Nothing of this kind was mentioned by Schmid (Reference Schmid2004: 111), who also measured F1/F2 for ZH /iː yː uː/. He lists the mean values given here in Table 2, which were, however, not normalised and based on one female and two male speakers.
Table 2 Non-normalised mean F1 and F2 values (in Hz) in the Alemannic dialect of Zurich (ZH) (Schmid Reference Schmid2004: 111).

When overlapping Schmid’s (Reference Schmid2004) values with Bigler’s (Reference Bigler2007), it becomes clear that Schmid’s values are only somewhat compatible with Bigler’s values, which could be due to them not having been normalised. Schmid’s (Reference Schmid2004) values tend to be realised more on the periphery, especially /iː/, whose F2 is about 200 Hz higher compared to the results reported in Bigler (Reference Bigler2007).
In conclusion, only a few formant frequency measurements for ALM dialects exist so far.Footnote 5 Therefore, the current study will add to the documentation by means of a systematic analysis.
1.3 Long-vowel inventories and formant measurements in Swiss Standard German
Before the long-vowel inventories of SSG can be discussed, it is important to understand that SSG does not have prescriptive pronunciation rules despite having the term ‘standard’ in its name. As will become evident from the examples of this section, SSG often has several allophones available for a certain phoneme or phoneme cluster, each of which can affiliate the speaker to a specific group (Hove Reference Hove2002: 6–10). Some of them are more linguistically marked or, in other words, more stigmatised than others, yet all of them are understood by the speech community. It would thus be wrong to talk about prescriptive pronunciation rules in SSG. Rather, Hove (Reference Hove2002) has claimed that SSG is better to be understood as a set of linguistic conventions with different likelihoods of occurrence for the specific allophones depending on their markedness. The variety resulting from the allophones with the highest likelihood will henceforth be called typical SSG in this study.
German is a pluricentric language (Ammon Reference Ammon1995; Hove Reference Hove2002: 3–6; Haas & Hove 2009: 261), so several norms of the standard variety exist: one in Germany, one in Austria, and one in Switzerland. These varieties differ in multiple domains, including the phonetic one. In German Standard German (GSG), all long vowels, i.e. /iː yː eː 퀈ː ɛː aː oː uː/ (Kleiner, Knöbl & Mangold Reference Kleiner, Knöbl and Mangold2015: 32–33), are tense and have an equivalent lax short vowel except for /a/ where no qualitative V–Vː difference existsFootnote 6 (Kohler Reference Kohler1995: 170). This short–long dichotomy without qualitative differences theoretically also applies to GSG /ɛ/ but the opposition is not always maintained. This applies especially to the north of Germany, where /ɛː/ is often realised as [eː] (Becker Reference Becker1998: 15–20). The realisation of (former) /ɛː/ as [eː], which entails a merger of /ɛː/ and /eː/, is now also accepted in the prescriptive orthoepic dictionaries (Krech et al. Reference Krech, Stock, Hirschfeld and Anders2009: 58; Kleiner et al. Reference Kleiner, Knöbl and Mangold2015: 64–65).
To find out whether SSG also abides by these rules, Iivonen (Reference Iivonen1983) compared the standard variety of a German speaker from Düsseldorf with the one of a Swiss speaker from Dübendorf (canton of ZH). He has found that the Swiss speaker’s realisations of /eː 퀈ː oː/ are substantially more open than the German speaker’s equivalents and mentions that /aː/ is realised more in the back, i.e. as [ɒː]. Additionally, Iivonen (Reference Iivonen1983: 50) comments on the Swiss speaker having two intensity peaks in his long vowels, and some long vowels showing slight qualitative transitions, e.g. the /eː/ in /ˈjeːdən/ ‘every’ being realised as [e͡i], and the <a>-sound in /ˈʃaːdən/ ‘damage’ being realised as [ɑ͡ɒ]. To be able to properly transcribe these qualitative differences in SSG, Panizzolo (Reference Panizzolo1982: 14) introduces new symbols, namely [Eː] for a vocoid that lies between [eː] and [ɛː] regarding the degree of openness, and [Oː] for an equivalent vocoid between [oː] and [ɔː]. In addition, Iivonen (Reference Iivonen1983: 51) proposes [퀆ː] for a vocoid between [퀈ː] and [œː] as both phonemes are possible in ALM. Instead of Panizzolo’s (Reference Panizzolo1982) and Iivonen’s (Reference Iivonen1983) symbols [Eː 퀆ː Oː], henceforth the IPA-compliant symbols [e̞ː 퀈̞ː o̞ː] will be used. SSG entailing many more open vowel sounds compared to GSG has also been stated by Christen et al. (Reference Christen, Guntern, Hove and Petkova2010: 164), who have auditorily classified SSG vowel pronunciation of policemen from different ALM-speaking regions (including GR, VS, and ZH) on the basis of emergency call recordings. They claim that the rate of open vowels lies at about 9% for /iː uː/ and at about 33% for /yː/, while a change in vowel quality often occurs with a shortening of the long vowel. This itself correlates with the prosodic position of the vowel in an unstressed syllable (see also Schmid Reference Schmid2004: 109–111 for ZH). They attribute the higher rate for an open realisation of /yː/ to the frequent occurrence of the word für ‘for’, which has likely skewed their dataset as prepositions normally do not have an accent. Regarding /eː/, the policemen pronounced it as [ɛː] in only about 4% of the cases, and as [ɛ] in about 11%. However, as no SSG data were available from BE, in whose ALM dialect long vowels orthographically represented by <e> (or <ee>/<eh>) are produced with the open vowel [ɛː] per default, no conclusions regarding ALM inferences could be made for BE SSG (Christen et al. Reference Christen, Guntern, Hove and Petkova2010: 165). A similar picture presented itself for /ɛː/, which was also produced in a typical way in about 87% of the cases. Only 1% used [æː], and 12% used [eː], which is also an accepted realisation in Germany (Krech et al. Reference Krech, Stock, Hirschfeld and Anders2009: 58; Kleiner Reference Kleiner2011–; Kleiner et al. Reference Kleiner, Knöbl and Mangold2015: 64–65) but not very common in German-speaking Switzerland. As for /aː/, much variation has been found (Christen et al. Reference Christen, Guntern, Hove and Petkova2010: 167–168). Hove (Reference Hove2002: 65) claims that [ɑː] is closest to being accepted as the (typical) SSG norm, which Christen et al. (Reference Christen, Guntern, Hove and Petkova2010) confirmed as it had been used in 51% of the cases, while [aː] had been used in 30% of the cases, and [ɒː] in 18%. Among the dialects where [ɒː] has a high occurrence likelihood, VS and ZH are listed, while in GR, [ɑː] was the most common realisation. Nevertheless, every dialect scrutinised showed some degree of variation.
The [ɒː] realisation of ZH had already appeared in the formant charts provided by Iivonen (1983: 49; Reference Iivonen and Wolfgang1994: 325–327), who concluded that the ZH SSG <a>-sound is enounced lower and further in the back than in GSG. Also Brändle (Reference Brändle, Helen, Sibylle, Walter, Nadia and Hans2010: 13–14) claims that producing the <a>-sound as [ɒː] is typical of ZH speakers, which she attributes to the ZH SSG variety’s realisation being more prestigious than the dominant norm-based SSG variety’s [ɑː] (see Hove Reference Hove2002: 65).
Siebenhaar (Reference Siebenhaar1994), who analysed the ALM and SSG varieties of three speakers each from BE, ZH, and St Gallen (SG), found more ALM interference in BE SSG since western dialects have more open vowels. This was the case for /eː 퀈ː iː uː/ but not for /oː/, where SG and ZH speakers also showed open [ɔː]. SG speakers showed interference in the other direction as their ALM dialect contains more closed vowels. Regarding /aː/, Siebenhaar (Reference Siebenhaar1994) found clear ALM interferences for ZH and SG speakers, who produced SSG /aː/ with their dialectal [ɒː], and [aː] respectively. Furthermore, no instance of /ɛː/ being realised as [æː] in SSG was found, even though in the dialects this is often the case. Siebenhaar attributes this to the fact that only one target word in his dataset, i.e. Erklärung ‘explanation’, included this sound, and only three instances of it being pronounced were recorded.
In conclusion, SSG vowels are reported to be more open than GSG ones and seem to show considerable variation, especially /eː 퀈ː oː/ and /aː/. For simplicity’s sake, the current study will collectively refer to the realisations of SSG /aː/ as <a>-sounds, and in tables and figures, it will be transcribed as /ɑː/.
1.4 Research questions and hypotheses
To assess whether SSG shows vowel-quality interferences of ALM, first the initial situation in the dialects must be addressed. Therefore, the first research question (RQ) was formulated:
RQ1. Are there dialect-specific phonetic vowel qualities in ALM, and if so, what are the most salient differences between the four dialects?
This helps clarify one side of the comparison. The same needs to be done with SSG. Hence the second RQ:
-
RQ2. Are there dialect-induced vowel-quality differences in SSG, and if so, what are the most salient differences between the four regionally different variations of the SSG sound system?
Once we have measured the formants of both the dialects and the respective regionally different variations of the SSG sound system, we can compare the mean formant values of the dialects with the mean values of the regionally different variations of the SSG sound system, as well as the mean formant values of the different dialects and the mean formant values of the regionally different variations of the SSG sound system among each other. Therefore, the third RQ has resulted in the following:
-
RQ3. Do the dialect groups show the same or different vowel qualities in the two varieties of their repertoires (ALM and SSG)?
The three hypotheses (Hs) are as follows:
-
H1. There will be significant differences in vowel quality among the ALM dialects in that BE will show the unrounded open back vowel [ɑː], ZH and VS will show the rounded open back vowel [ɒː], and GR will show the unrounded open front vowel [aː].
-
H2. The vowel quality found in ALM is also supposed to be found in SSG, which implies that an influence from the dialect on the standard will be identified.
-
H3. No major differences between ALM and SSG are expected; nevertheless, given that SSG varieties allow for different interdialectal pronunciation norms, the possibility of changes towards a norm-based supraregional SSG cannot be ruled out.
At this point, it must be emphasised that the aims of the present study are above all descriptive: the main goals are to document how ALM speakers realise the qualities of long vowels in both their ALM dialect and their regional variety of SSG, and to which extent their pronunciation of SSG vowels is determined by idiosyncrasies. In other words, the focus is on regional and individual variation. It lies outside this study’s scope to investigate linguistic dynamics related to social factors (e.g. age, social class, etc.) or to dialect levelling (see Schmidt & Herrgen Reference Schmidt and Joachim2011; Kehrein Reference Kehrein2012, Reference Kehrein, Michael, Markus and Jürgen Erich2015). With a forensic application in mind, it is simply assumed that individuals with the same geographic and social background may adhere to different phonetic patterns, whatever the reasons for such speaker-dependent idiosyncrasies may be.
2 Methods
2.1 Speakers
Thirty-two speakers participated in the experiment, eight from each dialect region (see Figure 1 above), with 50% being female (age: 17–32 years; mean: 22.5 years; SD: 3.42). They were reimbursed with CHF 15.00 per 30 minutes of testing. Except one speaker, all subjects had a Matura degree (higher secondary education) and only three speakers did not graduate from university. It was a requirement that at least one of every speakers’ parents had to have grown up with the same dialect. Furthermore, it was an exclusion criterion if one parent had grown up in another German-speaking country or in another city of the ones scrutinised. To reduce possible dialect-contact interference, the speakers had to be residing in the city they had been raised in when the recording took place, and it was made sure that they had not spent more than three years outside that city. Only in a few cases (for GR and VS), the speakers were students in the cities of Bern or Zurich. As far as possible, care was thus taken to keep the four groups of speakers as homogeneous as possible, trying to minimise the potential effect of social factors such as age and level of education.Footnote 7
2.2 Wordlists
For each dialect and for SSG, a list of monosyllabic words containing the specific variety’s long vowels was created. For BE, this included /iː yː eː 퀈ː ɛː œː æː ɑː ɔː oː uː/, for GR /iː yː eː 퀈ː ɛː aː ɔː oː uː/, for VS /iː yː eː æː ɒː oː/, for ZH /iː yː eː 퀈ː ɛː œː æː ɒː oː uː/, and for SSG /iː yː eː 퀈ː ɛː aː oː uː/. All ALM words and vowel sounds were written in Dieth’s (Reference Dieth1938) spelling system, with which the speakers were familiarised beforehand. SSG words were written in standard German orthography. A complete word list with orthographic and phonetic transcriptions for each variety can be found in Table A1 in the appendix.
To minimise the potentially artificial nature of read speech, real words that belong to basic vocabulary instead of logatomes were chosen. The linguistic differences among the four ALM dialects and SSG did not permit to present the same word for each vowel in every variety. Thus, coarticulatory effects on formant frequencies cannot be fully excluded, as they could not be controlled in the data used in the study. However, measures to reduce such effects were taken, e.g. by measuring formants at the midpoint of the vowel (see Section 2.4). I will come back to this issue in the discussion of the data.
Lastly, for every variety, a list containing every single vowel sound was added. The vowels were recorded in isolation as steady vowel sounds to compare it to the vowel sounds in the real words.
2.3 Recording procedure and data processing
To familiarise the participants with the recording situation, prior to recording the target words, an interview was conducted in which metainformation on the speakers and their sociolinguistic background was collected. The answers to these questions were, however, not systematically analysed for this study as they are not directly relevant to its aim.
Once the interview had been completed, the actual experiment began. The participants were briefed to speak as naturally as possible to avoid hyperarticulation. The tokens were presented in generic carrier phrases, so that the target words would be uttered in a stressed mid-phrase position to exclude potential phrase-final lengthening effects. The variety-specific carrier phrases can be found in Table A2 in the appendix. The recording was organised in six blocks that started with the isolated vowel sounds in randomised order, and then went on to the real words in randomised order. These blocks alternated three times between the respective ALM word list and the SSG one. The recordings were conducted with SpeechRecorder, version 3.28.0 (Draxler & Jänsch Reference Draxler and Klaus2004). Whenever feasible, the participants were recorded at the University of Zurich in a sound-attenuated booth, which was the case for 13 participants. For this, the interface USBPre ® 2 by Sound Devices and the microphone NT2-A by RøDE were used; recordings were made at 16-bit/44.1 kHz in mono and stored as.WAV files on a personal computer. If it was not feasible for the participant to come to Zurich (which was the case for 19 participants), the recording took place at the participants’ houses using the same interface model (USBPre ® 2 by Sound Devices) but a different microphone Opus 54.16/3 by BeyerDynamic; again, recordings were made at 16-bit/44.1 kHz in mono and stored in the.WAV format.
Subsequently, the recordings were automatically segmented with a script (courtesy of Markus Jochim, LMU Munich) in R (R Core Team 2019), using the Munich AUtomatic Segmentation (MAUS) System (Schiel Reference Schiel1999, Kisler, Reichel & Schiel Reference Kisler, Reichel and Schiel2017) with the language setting General Swiss German for all ALM sentences and the language setting Standard German for SSG sentences. Thereafter, the processed audio files of the sentences were uploaded to the EMU Speech Database Management System (Winkelmann, Harrington & Jänsch Reference Winkelmann, Harrington and Jänsch2017) and the segmentation of each sentence was corrected by hand by the author (78%) and, for reasons of time, by two additional researchers (22%). The segmentation was mainly based on the observation of the wave form; in particular, it was made sure that the segments of the complete target words were accurate with each segment border always crossing at the closest zero crossing.
2.4 Analyses and statistics
Once all segments had been manually corrected, the F1 and F2 frequencies were obtained with an R script (courtesy of Markus Jochim, LMU Munich). The script measures the first five formants in a range up to 5500 Hz for women and up to 5000 Hz for men at the centre of each vowel segment via Praat (Boersma & Weenink Reference Boersma and David2019). In a few cases, the formant measurements were manually checked for accuracy if they appeared to be unrealistically low or high due to errors of the formant tracking algorithm; if this was the case, these values were excluded from the analysis.
The formant frequencies were then normalised with the Lobanov (Reference Lobanov1971) procedure using NORM (Thomas & Kendall Reference Thomas and Tyler2007), where the resulting z-normalised values were scaled back to Hz. Subsequently, the normalised formant frequencies were visualised with phonR (McCloy Reference McCloy2016). The resulting ellipses are calculated by using the tokens’ covariance and a 68% confidence level, by means of Hotelling’s (Reference Hotelling1931) T2T2 distribution, which equals roughly ± 1 standard deviation. Statistical analyses were also conducted in R (R Core Team 2019) and involved linear mixed-effects models (LMM) done with lme4 (Bates et al. Reference Bates, Martin, Ben and Steve2015). The dependent variable was either F1 or F2, while dialect or variety, sex and vowel quality were fixed factors (with interaction term). Post-hoc pairwise comparison tests (Tukey method) were done with lsmeans (Lenth Reference Lenth2016).
3 Results
3.1 Alemannic dialects
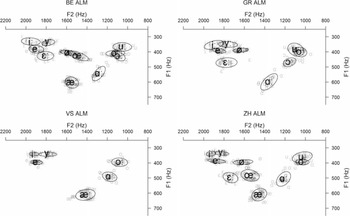
Figure 2 depicts each ALM dialect’s long vowels F1/F2 frequencies (in Hz). The corresponding F1/F2 measurements can be found in Table A3 in the appendix.
Both similarities and differences among the dialects can be observed. The high front vowels /iː yː/ are very similar in all dialects, which also applies to the high-mid vowels /eː 퀈ː oː/. Even BE <ìì ǜǜ ùù> that are traditionally transcribed as /ɪː ʏː ʊː/ (but as [eː 퀈ː oː] here) are congruent with the other three dialects’ /eː 퀈ː oː/. The vowels /ɛː œː ɔː/ are enunciated slightly higher in BE compared to GR, VS, and ZH. The back vowels /uː/ and /oː/ show much overlap. A clear distinction is visible for the low vowels in that BE shows <a>-sound values associated with [ɑː], VS and ZH have similar means associated with [ɒː] resembling GR /ɔː/, and GR shows values more closely resembling the other dialects’ /æː/, which makes sense as GR <aa> is typically transcribed as [aː].

Figure 2 Ellipses showing the distribution of the normalised F1 and F2 values (in Hz) of Alemannic long vowels by vowel quality. Top left: Bern (BE); top right: Chur (GR); bottom left: Brig (VS); bottom right: Zurich (ZH).
The LMM for vowel height with F1 as dependent variable, dialect and vowel quality as fixed factors (with interaction term), and random intercepts for speaker and word shows dialect (F(3,40.94) = 62.78, p < .001), vowel quality (F(10,830.86) = 1653.64, p < .001) and the interaction between dialect and vowel quality (F(22,830.88) = 32.66, p < .001) to be statistically significant. Post-hoc pairwise comparisons for each vowel independently revealed which dialects show statistically significantly different vowel height for the same phonological vowel. Table 3 summarises the results, whereby statistically not significant results are not listed.
Table 3 Statistically significant p-values of pairwise F1 comparisons between the four Alemannic dialects.

BE = Bern; GR = Chur; VS = Brig; ZH = Zurich
No statistically significant differences were found for /eː 퀈ː æː oː/. As for /iː/, the GR data show statistically significantly lower F1 values than in BE and ZH. The realisations of the phoneme /yː/ show only statistically significant differences between GR and ZH, while the other realisations were produced at approximately the same height. The open-mid vowels /ɛː œː/ are enunciated with a statistically significant difference in height in BE and ZH while the rest of the pairwise comparisons between the dialects did not yield statistically significant differences. Only one statistically significant height difference was found for /ɔː/, namely BE–GR. BE–GR was also statistically significantly different for /uː/ although there, GR–ZH show differences as well. The biggest height differences are displayed by <a>-sounds where both BE’s and GR’s F1 are statistically significantly different from all other dialects’ F1. VS and ZH realise their <a>-sounds at approximately the same height.
The LMM for vowel backness with F2 as dependent variable, dialect and vowel quality as fixed factors (with interaction term), and random intercepts for speaker and word shows dialect (F(3,31.41) = 8.28, p < .001), vowel quality (F(10,824.99) = 4042.97, p < .001) and the interaction between dialect and vowel quality (F(22,824.99) = 20.51, p < .001) to be statistically significant. The results of the post-hoc pairwise comparison for each vowel are independently summarised in Table 4. Statistically not significant comparisons are omitted.
Table 4 Statistically significant p-values of pairwise F2 comparisons between the four Alemannic dialects.

BE = Bern; GR = Chur; VS = Brig; ZH = Zurich
Comparable values are present in /eː ɛː 퀈ː œː oː ɔː/. Regarding /uː/, only GR–ZH showed statistically significant differences in backness. Furthermore, GR front vowels /iː yː/ are pronounced statistically significantly less in the front than in BE and ZH, respectively. Only one statistically significant backness difference was found for /æː/, namely BE–VS. Lastly, GR <a>-sounds are produced statistically significantly more in the front than in VS and ZH, and BE–ZH <a>-sounds also show statistically significant differences.
For each dialect’s <a>-sound an individual LMM with F1 or F2 as dependent variable, sex as fixed factor, and random intercepts for speaker was conducted. However, no ALM dialect showed statistically significant sex differences in F1 or F2.
3.2 Swiss Standard German varieties
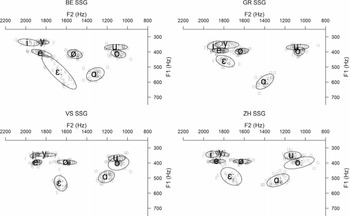
Figure 3 depicts F1/F2 frequencies of each SSG variety’s long vowels (in Hz). The corresponding F1/F2 measurements can be found in Table A4 in the appendix.

Figure 3 Ellipses showing the distribution of the normalised F1 and F2 values (in Hz) of Swiss Standard German (SSG) long vowels by vowel quality. Top left: Bern (BE); top right: Chur (GR); bottom left: Brig (VS); bottom right: Zurich (ZH).
As it has been the case in ALM, /iː yː/ are very similar in all the four SSG varieties, even though GR variants are produced minimally more in the centre and BE variants more on the periphery. As for /eː 퀈ː/, only BE tends to produce these vowels slightly lower. The vowels /oː uː/ have been produced in a similar fashion as well and yet again show a great deal of overlap. /ɛː/ has been produced in a more closed fashion by GR speakers, while BE and VS speakers produced it lower, and ZH speakers show a vowel height that lies somewhat between GR and BE/VS. For this vowel, BE shows a great variance, which will be described in more detail when considering each region’s varieties separately (see Figure 4, in Section 3.3 below). Lastly, the <a>-sound resembles more an [ɒː] for VS speakers, while BE speakers produced more an [ɑː]. ZH values for <a> lie somewhat in between the VS and BE ones. GR speakers enunciated <a> both the lowest as well as the most in the front, resembling their dialectal [aː].
The LMM with F1 (i.e. vowel height) as dependent factor, dialect and vowel quality as fixed factors (with interaction term), and random intercepts for speaker shows dialect (F(3,32.02) = 17.80, p < .001), vowel quality (F(7,740.63) = 1040.99, p <.001) and the interaction between dialect and vowel quality (F(21,740.63) = 23.89, p < .001) to be statistically highly significant. Post-hoc pairwise comparisons for each vowel independently revealed which dialects show a statistically significantly different vowel height for the same phonological vowel. The results are summarised in Table 5 (not statistically significant values are omitted).
Table 5 Statistically significant p-values of pairwise F1 comparisons between the four Swiss Standard German varieties.

BE = Bern; GR = Chur; VS = Brig; ZH = Zurich
Table 6 Statistically significant p-values of pairwise F2 comparisons between the four Swiss Standard German varieties.

BE = Bern; GR = Chur; VS = Brig; ZH = Zurich

Figure 4 Ellipses showing the distribution of the normalised F1 and F2 values (in Hz) of Alemannic (ALM) and Swiss Standard German (SSG) long vowels in Bern (BE) by vowel quality.
All four SSG varieties produced similarly high /oː/ as evident by the lack of statistically significant differences. Only BE–GR show some divergence although the difference is not statistically significant. As for /uː/, ZH’s variant is produced statistically significantly higher than the other three dialects’ ones. The vowels /iː yː/ both show statistically significant differences in vowel height for BE–GR, while /yː/ shows additional differences for GR–ZH. The F1s of /eː ɛː 퀈ː/ all differ statistically significantly for BE–GR. /eː 퀈ː/ also show statistically significant differences for BE–ZH. Moreover, a statistically significant difference in F1 has been found for /ɛː/ for GR–VS. The <a>-sounds show the most differences in that GR diverges from all the other varieties regarding vowel height, which also applies to BE. Only VS and ZH do not show statistically significant differences.
The LMM with F2 as dependent factor, dialect and vowel quality as fixed factors (with interaction term), and random intercepts for speaker shows vowel quality (F(7,740.42) = 3724.52, p < .001) and the interaction between dialect and vowel quality (F(21,740.43) = 16.64, p < .001) to be highly statistically significant, while dialect is not. This means that vowel backness is not only determined by vowel quality but also by the ALM dialect of the speaker. In other words, differences in vowel backness are dialect-specific. Here as well, the results of the post-hoc pairwise comparison for each vowel are independently summarised in Table 6. Statistically not significant results are not shown in the table.
The vowels /yː eː oː/ show no statistically significant difference. BE speakers produced both /iː/ and /퀈ː/ with a statistically significantly different F2 compared to all other dialects. GR /ɛː/ also differs statistically significantly from the BE and the VS realisation. As for /uː/, only one instance of statistically significant F2 difference was found, namely for GR–ZH. Finally, the <a>-sound from GR is produced more in the front than the other dialects’ ones. The same applies to BE, even though the BE–ZH <a>-sound difference is not statistically significant in SSG.
Once again, for all four SSG varieties’ <a>-sounds an individual LMM with F1 or F2 as dependent variable, sex as fixed factor, and random intercepts for speaker was run. As it had been the case for ALM, no SSG variety showed statistically significant sex differences in F1 or F2.
3.3 Comparison of Alemannic dialects and Swiss Standard German varieties
This section contrasts each dialect region’s ALM long-vowel inventory with the corresponding SSG one by means of overlapping F1/F2 ellipses. Grey contour lines as well as IPA symbols are used for ALM while SSG ones are printed in black. To visualise overlap, the area of the ellipses is transparent, and so overlap will result in darker hues. Unfortunately, as the regional ALM and SSG vowel inventories do not necessarily entail the same vowels, it is not possible to compare every ALM vowel with its corresponding SSG equivalent. Specifically, for BE the ALM vowels /œː æː ɔː/ cannot be compared to SSG. The same applies to GR ALM /ɔː/, VS ALM /æː/, ZH ALM /œː æː/ and VS SSG /퀈ː ɛː uː/ as the latter three do not exist in the VS dialect.
Figure 4 contrasts F1 and F2 frequencies of long vowels in the BE ALM dialect and the respective SSG variety.
While /iː yː uː/ and the <a>-sounds show great overlap, the situation with /eː ɛː 퀈ː oː/ is slightly less straightforward. SSG /eː/ lies somewhat between ALM [eː] and [ɛː]. Furthermore, SSG /ɛː/ has been produced lower than in ALM as a more canonical [ɛː] or [æː]. This is evident in the big size of the ellipsis, which indicates a large standard deviation, the overlap of the SSG [ɛː] and ALM [æː] ellipses, and the fact that some SSG [ɛː] tokens group among the ALM [æː] tokens. Similarly, SSG /퀈ː oː/ resemble more of ALM [œː ɔː] than typical [퀈ː oː]. In other words, [eː 퀈ː oː] are produced lower in the BE SSG variety than in its ALM dialect.
The LMM with F1 as dependent factor, variety and vowel quality as fixed factors (with interaction term), and random intercepts for speaker and word shows that vowel quality (F(7,374.08) = 432.216, p < .001), variety (F(1,374.17) = 61.90, p < .001), and the interaction between vowel quality and variety (F(7,37.08) = 27.40, p < .001) are statistically significant. Post-hoc pairwise comparison shows that only /ɛː/ has statistically significantly different vowel heights for ALM and SSG (p < .001). Furthermore, the LMM with F2 as dependent factor, variety and vowel quality as fixed factors (with interaction term), and random intercepts for speaker and word reveals statistical significance for the factors vowel quality (F(7,374.02) = 1859.95, p < .001), variety (F(1,374.06) = 8.85, p = .003), and the interaction between vowel quality and variety (F(7,374.02) = 17.37, p < .001). Post-hoc pairwise comparison reveals that the <a>-sound (p = .007) and /oː/ (p = .026) show statistically significant differences in vowel backness.
Figure 5 contrasts F1 and F2 frequencies of long vowels in the ALM dialect and the SSG variety of GR. GR speakers show a great vowel-quality overlap between ALM and SSG. As a matter of fact, all vowel qualities are practically congruent except /ɔː/, which does not exist in SSG.
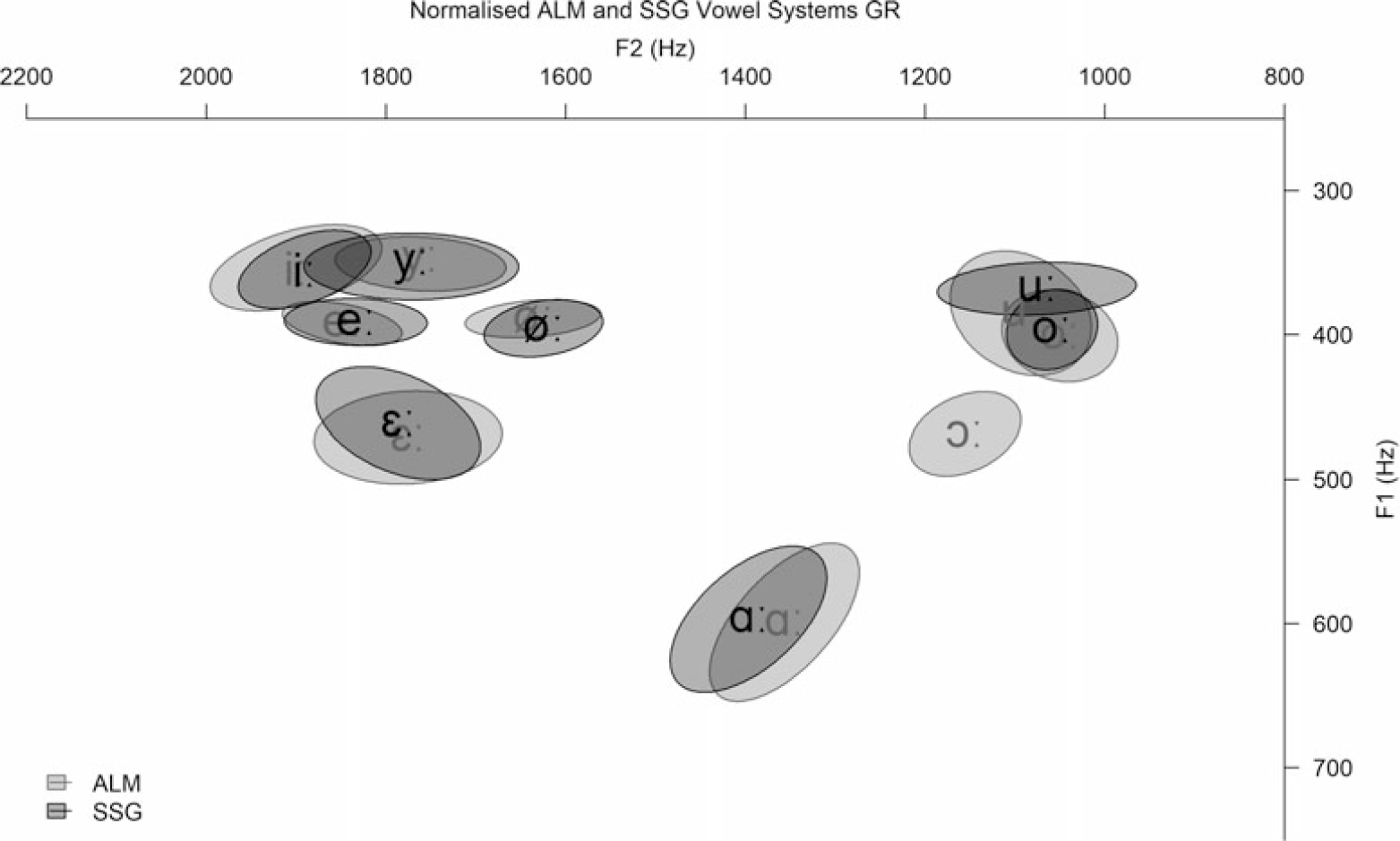
Figure 5 Ellipses showing the distribution of the normalised F1 and F2 values (in Hz) of Alemannic (ALM) and Swiss Standard German (SSG) long vowels in Chur (GR) by vowel quality.
The LMM with F1 as dependent factor, variety and vowel quality as fixed factors (with interaction term), and random intercepts for speaker and word shows only vowel quality to be a statistically significant factor (F(7,382) = 853.02, p < .001), whereas both variety and the interaction between variety and vowel quality are not. This means that vowel height is only determined by vowel quality and not by the ALM dialect background of the speaker. The same applies to the LLM with F2 as dependent factor, where only vowel quality yields a statistically significant effect as well (F(7,374.06) = 1979.84, p < .001). Therefore, vowel backness is also only determined by vowel quality.
Figure 6 contrasts F1 and F2 frequencies of long vowels in the ALM dialect and the SSG variety of VS. SSG /ɛː 퀈ː uː/ as well as ALM /æː/ cannot be compared because they do not have equivalents in the other variety.

Figure 6 Ellipses showing the distribution of the normalised F1 and F2 values (in Hz) of Alemannic (ALM) and Swiss Standard German (SSG) long vowels in Brig (VS) by vowel quality.
VS vowel qualities show a great deal of overlap as well. The most variation has been observed for /æː oː ɒː/. The realisations of /ɒː/ occasionally show formant values approaching [oː]. The vowels /퀈ː yː/ primarily vary in their backness (F2) as evident in the wide yet low-rise shape of the ellipses.
The LMM with F1 as dependent factor, variety and vowel quality as fixed factors (with interaction term), and random intercepts for speaker and word reveals that vowel quality (F(7,312) = 552.08, p < .001) is statistically significant but variety and the interaction between variety and vowel quality is not. For the LLM with F2 as dependent factor, only vowel quality turned out to be a statistically significant factor (F(7,304) = 2897.70, p < .001), while both variety and the interaction between vowel quality and variety are not.
Figure 7 contrasts F1 and F2 frequencies of long vowels in ZH ALM and its SSG variety. Once again, the ALM vowels /œː æː/ cannot be compared as they do not exist in SSG.
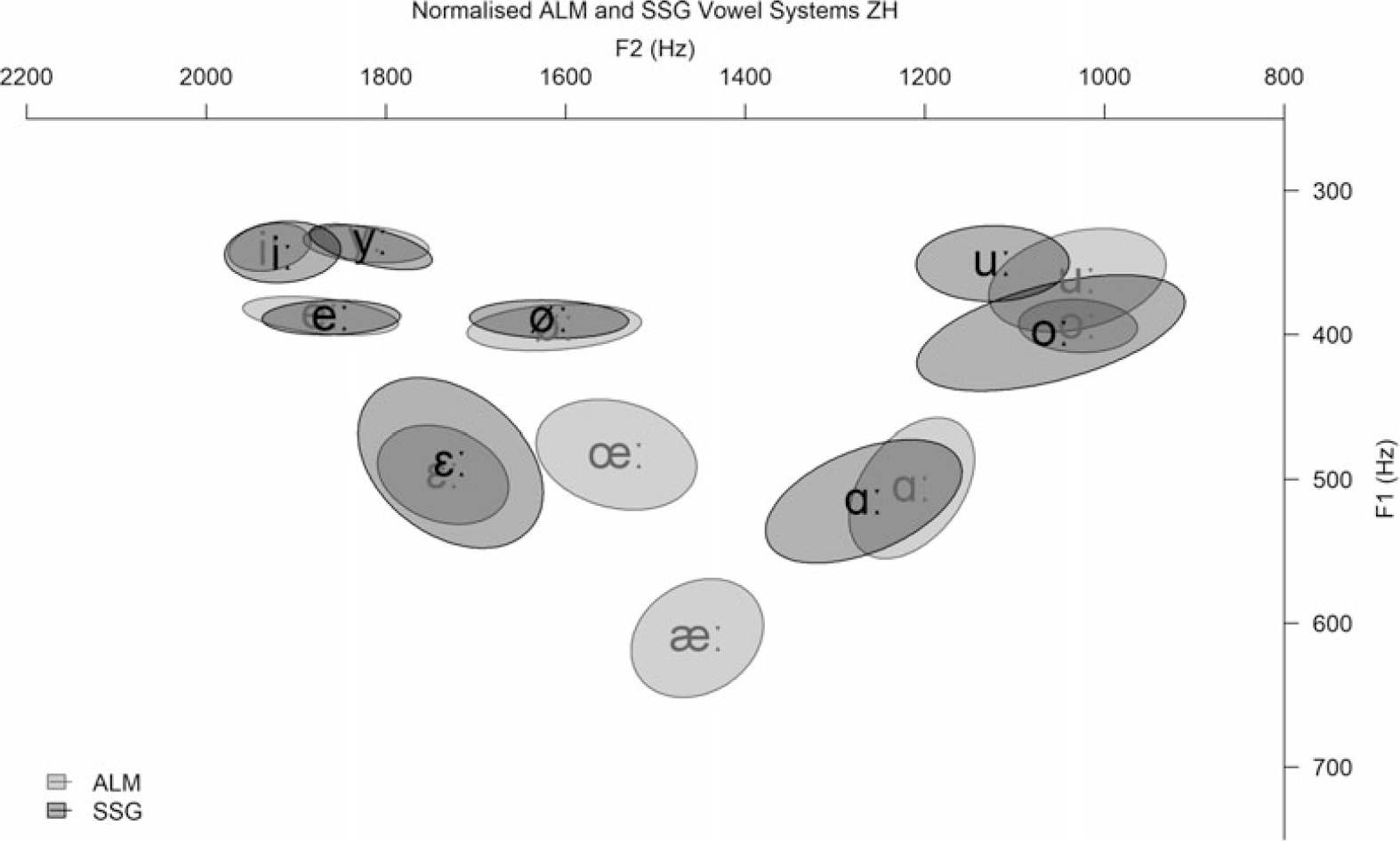
Figure 7 Ellipses showing the distribution of the normalised F1 and F2 values (in Hz) of Alemannic (ALM) and Swiss Standard German (SSG) long vowels in Zurich (ZH) by vowel quality.
ZH speakers show a great amount of overlap between ALM and SSG. Only <a>-sounds seem to be pronounced slightly more in the centre in SSG, resembling the BE ALM version of [ɑː] rather than ZH ALM [ɒː].
The LMM with F1 as dependent factor, variety and vowel quality as fixed factors (with interaction term), and random intercepts for speaker and word indicates that vowel quality is a statistically significant factor (F(7,379.30) = 611.12, p < .001) but neither variety nor the interaction between variety and vowel quality turned out to be statistically significant. Regarding the LMM with F2 as the dependent factor, vowel quality (F(7,379.12) = 2340.64, p < .001), variety (F(1,379.11) = 10.88, p = .001), and the interaction between the two (F(7,379.11) = 6.49, p < .001) all show statistically significant values. Post-hoc pairwise comparison shows that the two mean realisations of the <a>-sound have statistically significantly different F2 values (p < .001). All other vowels do not show any statistically significant F2 differences.
4 Discussion
4.1 Limitations of the study
Before discussing the results, a shortcoming of the present study concerning coarticulation must be addressed. The phonological environment of a vowel has been shown to influence its formant values (see Stevens & House Reference Stevens and House1963, Öhmann Reference Öhmann1966, Recasens Reference Recasens1984, Magen Reference Magen1997, Hillenbrand, Clark & Nearey Reference Hillenbrand, Clark and Nearey2001). Therefore, to mitigate against coarticulatory effects, three actions were taken. (i) Monosyllabic words were recorded to avoid vowel-to-vowel coarticulation (see Recasens Reference Recasens1984). This still leaves consonant-to-vowel coarticulatory effects, which could only be avoided if the words as well as the carrier phrase uttered in each dialect were entirely identical. However, this brings us to an inherent dilemma for the research design. When comparing different dialects, they must be made comparable but making them too comparable disposes of the dialectal differences that the research is meant to document in the first place. For this study, it was crucial that the subjects use their actual dialects. Artificial words that are the same in all varieties, i.e. highly controlled logatomes, were thus no option as they bear the risk that subjects do not use their dialectal system to pronounce them. Therefore, real words with dialect-specific carrier phrases were used, which means that the dialect-specific words used to measure vowel quality varied in their phonological environments. In other words, coarticulatory effects cannot be ruled out. To limit these effects, however, (ii) vowel formants were measured in the centre of each vowel, where the value is least affected by coarticulation. Furthermore, (iii) all vowel sounds were additionally recorded in isolation, i.e. as a steady vowel sound, and the respective formant values were compared to those in the real monosyllabic words. While the isolated vowels tended to be pronounced more on the periphery in each dialect, without exception none of the vowel formants measured for the real words differed statistically significantly from the vowel formants measured in the isolated vowels. To illustrate this, the vowel formants of the real words and isolated vowels of ZH speakers are plotted in Figure 8, and the respective vowel-formant values are summarised in Table 7.
Table 7 Mean values of normalised Zurich Alemannic F1/F2 measurements (in Hz) in isolated vowel sounds and vowel sounds in real words by vowel quality.


Figure 8 Ellipses showing the distribution of the normalised F1 and F2 values (in Hz) of isolated long-vowel sounds and long-vowel sounds in real words in Zurich Alemannic (ZH ALM) by vowel quality.
In sum, coarticulatory effects cannot be completely ruled out in this study. Nevertheless, given it is the first to use an instrumental phonetic approach for systematically analysing ALM and SSG long-vowel quality, future research should consider further measurements against coarticulatory effects, such as recording more words in multiple phonological environments for each vowel scrutinised.
4.2 Alemannic varieties
Starting with RQ1, i.e. whether there are dialect-induced vowel qualities in ALM, it must be concluded that both similarities and differences among the four dialects exist.
Let us begin with the high vowels /iː yː uː/. As for /iː/, BE and GR speakers do indeed pronounce this vowel in a statistically significantly different manner, given that the BE realisation is both higher and more in the front than the GR one, which in return is more centralised compared to BE. In fact, GR /iː/ tends to be lower than the ones of the other three dialects. Regarding F1, only the VS realisation did not pass the 5% threshold compared to GR. This is especially meaningful because the target word (excluding the carrier phrase) was the same in BE, GR and VS ALM, i.e. [v̥iːz̥] ‘nasty’. Moving on to /yː/, the GR realisation has yet again been produced more in the centre, although it is only statistically significantly different from the ZH variant, which again has much explanatory power given the target word was the same in GR and ZH ALM, i.e. [tyːf] ‘deep’. Thus, it can be said that ZH speakers produce their /yː/ more on the periphery than GR speakers. The same is true for /uː/, where GR speakers produced their variants statistically significantly less peripherally than ZH too. Once again, as the same target word was used in GR and ZH ALM, i.e. [puːɾ] ‘farmer’, this finding provides strong evidence for a different articulation.
As for [eː 퀈ː oː], the respective ellipses show much overlap among the dialects suggesting that these vowels are enunciated in a very similar position. The fact that no statistically significant differences for F1 or F2 were found supports this claim. The evidence is especially strong for [eː oː], as the target word was identical for the former in GR, VS, and ZH ALM, i.e. [z̥eː] ‘lake’, and for the latter in GR and VS ALM, i.e. [b̥oːt] ‘boat’. This overall result for [eː 퀈ː oː] is particularly interesting as in most dialects, the respective vowels are orthographically represented by <ee öö oo>, whereas in BE they are traditionally written as <ii üü uu> and phonetically transcribed as [ɪː ʏː ʊː] (Keller Reference Keller1961: 91–92). Indeed, the lowering of these vowels to [eː 퀈ː oː] has been reported in western dialects (Haas Reference Haas and Iwar1985: 96–97), and the data in this study support this claim for BE as well. It is, thus, questionable whether the phonetic transcription of [ɪː ʏː ʊː] in BE is appropriate. The great amount of overlap with the GR, VS, and ZH vowels /eː 퀈ː oː/ rather suggests that those vowels would be better transcribed as [eː 퀈ː oː] in BE as well. Therefore, their traditional transcription is based on SSG orthography and phonology rather than phonetics (see Zihlmann & Leemann Reference Zihlmann and Adrian2016: 239).
The vowels /ɛː œː ɔː/ show a bit more variation. BE variants are on average higher than in the other dialects, i.e. ZH for /ɛː œː/, and GR for /ɔː/, and occasionally even show overlap with BE [eː 퀈ː oː]. Only GR–BE /ɛː/ did not show any statistically significant differences. This is counterintuitive since phonological vowels should be distinct enough for them to be told apart and perceived as two different categories. Nevertheless, already in the SDS (1962: maps 95, 99, 102), the BE realisations are described as ‘neutral or slightly open’ and do therefore not embody canonical /ɛː œː ɔː/. The data summarised in Figure 2 suggest as well that BE realisation of /ɛː œː ɔː/ are not as open as the other dialects’ equivalents and that some BE speakers in fact produce it closer to /eː 퀈ː oː/. Bigler (Reference Bigler2007: 32–33) has also reported overlap among the close-mid and open-mid long (as well as the short) vowels /eː ɛː oː ɔː/ although the number of tokens with two observations was very low. When we zoom in a bit, we can see that this phenomenon is likely due to interspeaker variation present in BE in that some speakers do not vary /ɛː œː ɔː/ from /eː 퀈ː oː/ much. This could be caused by the orthographic representation of the words, which is identical or similar to SSG spelling and might therefore have triggered the standard pronunciation. Thus, either realisation occurs, which resulted in the mean in between /eː/ and /ɛː/. As for VS, Bigler’s (Reference Bigler2007: 40–49) finding of /ɛː/ being higher and more in the front than /eː/ cannot be confirmed with the results of the current study.
Lastly, as expected the <a>-sounds show much variation among the dialects, which confirms H1. As for F1, only VS–ZH is not statistically significantly different, which also applies to BE–ZH and VS–ZH for F2. When interpreting the vowel quality of the four dialects, the BE variant is best represented by [ɑː] as it has been reported by Keller (Reference Keller1961: 89). VS and ZH, in contrast, produce their variant higher and more in the back, resembling [ɒː] as reported in previous research (Keller Reference Keller1961: 36; Werlen Reference Werlen1977: 45; Schmid Reference Schmid2004: 97). Further evidence is provided by the fact that especially VS <a>-sounds, but also ZH ones to some degree, overlap with GR /ɔː/. This is congruent with Werlen’s (Reference Werlen1977: 45) comment that some regions, among which the city of Brig, show a tendency for [ɒː]. The GR <a>-sound quality is also no big surprise as it is produced the lowest and the most in the front, which can be transcribed as [aː] as stated by Eckhardt (Reference Eckhardt1991). Indeed, GR variants show considerable overlap with VS and ZH /æː/, which implies that the GR vowel is pronounced further in the front. In this context, it remains unclear as to why the BE /æː/ realisation is produced more in the front than in VS and ZH. While VS and ZH speakers do not pronounce /æː/ in statistically significantly different manner, the BE variant shows F2 values (1549 Hz) that imply that it is pronounced more peripherally than in VS (1415 Hz) and ZH (1454 Hz).
In conclusion, the study has found evidence that GR high vowels are enunciated less on the periphery than in the other dialects with /iː/ leading the way. Furthermore, the vowel quality analysis suggests that BE phoneme-to-grapheme mapping is based on phonological considerations and standard German orthography rather than on phonetic observations as its lowered high vowels traditionally transcribed as [ɪː ʏː ʊː] are phonetically identical with the other dialects’ realisations of /eː 퀈ː oː/. Moreover, BE ALM shows F1/F2 values for /ɛː œː ɔː/ that are not typical but more in between canonical /ɛː œː ɔː/ and /eː 퀈ː oː/ realisations. Lastly, the most appropriate regional vowel quality description of the ALM <a>-sounds are [ɑː] for BE, [aː] for GR, and [ɒː] for VS and ZH, thus confirming H1.
4.3 Swiss Standard German vowel qualities and Alemannic interferences
Regarding RQ2, i.e. whether dialect-induced vowel qualities in SSG exist, the situation is similar to ALM, which means that H2 is confirmed. Thus, the discussion of RQ3, i.e. whether the differences in SSG can be explained by ALM interferences, will be addressed as well. First, some methodological remarks must be made, however. Already Hove (Reference Hove, Helen and Evelyn2008b: 85) pointed out that most of the studies conducted so far are based on educated speakers who are to a certain degree skilled at speaking SSG as they are more likely to use it. This study is no exception since out of the 32 participants, only three did not graduate from university, and only one does not hold a higher secondary education degree. It is thus possible that less educated speakers would have shown more ALM inferences, i.e. more extreme results than what has been observed in this dataset. Having mentioned this, let us now proceed to the discussion of RQ2 and RQ3.
The ellipses of the vowels /iː yː uː/ show great overlap among the SSG varieties. However, regarding /iː/, evidence points at BE SSG speakers realising their variant more on the periphery. It is not only produced higher than in GR but also more in the front than in the remaining three regions. The GR, VS, and ZH SSG variants, in contrast, show comparable formant values, meaning that they are pronounced in a similar fashion. As for /yː/, only GR speakers differ in that they produce more centralised realisations. While no regional differences could be observed regarding vowel backness, GR SSG /yː/ is articulated lower than in BE and ZH SSG. This tendency for GR to produce high vowels less on the periphery has been observed in ALM as well and can thus be regarded as an interference. However, for /uː/ this does not necessarily hold true. Rather, it is mostly ZH speakers who produce /uː/ higher than speakers from the other three regions. Therefore, for GR true ALM interferences were only observed for /yː/.
Moving on to /eː 퀈ː oː/, little variation among the GR, VS, and ZH SSG varieties was observed, which implies that for these SSG varieties no region specificity exists for these three vowels. Only BE speakers diverge from the other three regions in that their mean [퀈ː] is statistically significantly further in the back and lower, and [eː] is statistically significantly lower compared to the other three variants. Regarding /oː/, despite not resulting in statistically significant differences, we can also find a tendency for BE /oː/ to be produced lower than in the other dialects’ SSG varieties. All in all, this confirms the impression that BE speakers realise their respective SSG variants in a similar way as in their ALM dialect, i.e. as open-mid rather than close-mid vowels (see Siebenhaar Reference Siebenhaar1994: 37). The observation made by Panizzolo (Reference Panizzolo1982: 14) and Iivonen (Reference Iivonen1983: 51) for SSG to show more open vowels can thus be confirmed for BE SSG, which would justify the use of /e̞ː 퀈̞ː o̞ː/ that represent vocoids between the close-mid and open-mid vowels as suggested by Panizzolo (Reference Panizzolo1982: 14) and Iivonen (Reference Iivonen1983: 51). Therefore, the BE SSG realisations of /eː 퀈ː/, and to some degree also of /oː/, can be regarded as shaped by ALM interference even though intra- and interspeaker differences were observed. For instance, one BE speaker produced both open-mid vowels and close-mid vowels when asked to pronounce a word containing /eː/. Similar observations were made for /oː/ and /퀈ː/ as well. Overall, Siebenhaar’s (Reference Siebenhaar1994: 38) comment stating that BE SSG shows comparatively more ALM interferences can thus be confirmed with regard to /eː 퀈ː oː/. Lastly, auditory impression suggests that /eː/ is not realised as a diphthong, i.e. [e͡i], as reported by Iivonen (Reference Iivonen1983: 50). However, as formant values were only measured in the centre of the vowel, this claim can be neither confirmed nor falsified by the analysis of the current study’s data.
More variation has been observed for /ɛː/. Yet again the most intra- and interspeaker differences occurred in BE SSG. Its pronunciation reaches from typical [ɛː] to [æː], which explains the very large size of the ellipse in Figure 3. Furthermore, looking at Figure 4 that contrasts BE ALM and SSG, one can see that SSG /ɛː/ intersects with the area associated with [ɛː] and [æː] in ALM. This shows that some BE speakers did indeed not always produce SSG <ä> as [ɛː] as it is done in prescriptive standard German but as [æː] as it is done in ALM. The realisation as [æː] might be caused by its common (yet unofficial) orthographic representation, i.e. <ä>, which is associated with [æː] in BE and can thus be regarded as an interference (Siebenhaar Reference Siebenhaar1994: 37). However, the speakers that show the most statistically significant differences regarding the pronunciation of /ɛː/ are from GR. Their realisations are both higher and more in the front than those from BE and VS. Only ZH /ɛː/ realisations did not result in statistically significant differences comparted to GR. Thus, the GR variant tends towards [eː] and even shows some overlap with BE SSG /eː/. Therefore, speakers from both BE and GR have regional pronunciation differences in SSG for /ɛː/, in that in BE they can be produced lower and in GR they tend to be produced higher than average. These findings are not compatible with Siebenhaar’s (Reference Siebenhaar1994: 39) ones, where no instances of [æː] were reported. However, they are consistent with Christen et al.’s (Reference Christen, Guntern, Hove and Petkova2010: 166) observations, who reported that 11% of /ɛː/ were realised as [æː], and 6% as [eː]. When considering the current study’s findings, it seems likely that Christen et al. (Reference Christen, Guntern, Hove and Petkova2010) could have found more than 11% [æː] if they had included BE speakers.
Similarly, SSG <a>-sounds show differences between the four regions too. Here, the BE variant is articulated between the GR one and the VS and ZH one on the vertical axis. On the horizontal axis, the only variant that is not significantly different from BE is ZH, which suggests that ZH speakers centralise their variant in SSG. Thus, the most suitable transcription of the BE SSG <a>-sound is [ɑː] as it is the case in ALM. Furthermore, the GR SSG realisation is both lower and more in the front than the ones from elsewhere, suggesting that the GR SSG <a>-sound is best transcribed by [aː]. This is only somewhat compatible to the existing literature as Christen et al. (Reference Christen, Guntern, Hove and Petkova2010: 167–168) report [ɑː] to be predominant in GR SSG. In contrast, <a>-sounds are articulated very similarly in VS and ZH as evident by the lack of statistically significant differences. They are enunciated further in the back, being closer to [ɒː]. For ZH, this has already been observed by Panizzolo (Reference Panizzolo1982: 15), Siebenhaar (Reference Siebenhaar1994: 38), Brändle (Reference Brändle, Helen, Sibylle, Walter, Nadia and Hans2010), and Christen et al. (Reference Christen, Guntern, Hove and Petkova2010: 168), even though all studies reported variation to different degrees. The variation that occurred can also be confirmed as the mean ZH SSG <a>-sound tends to be more centralised than its ALM equivalent, suggesting that it was produced as [ɑː] by some ZH speakers, i.e. in a less rounded way, which manifests itself in the higher formant values; as is well-known, lip rounding lowers the values for all formants (Ashby & Maidment Reference Ashby and John2005: 74). Therefore, it appears that some ZH speakers do not simply project their ALM vowel into SSG but produce intermediate realisations that gradually approach either the GSG target pronunciation or the supraregional SSG norm (Hove Reference Hove2002: 65), which are both enunciated further in the front. In addition, Iivonen’s (Reference Iivonen1983: 50) claim that the <a>-sound is realised as a diphthong, i.e. as [ɑ͡ɒ], is not supported by the auditory impression of the present study’s data. His description might thus be due to an idiosyncratic feature of the ZH SSG speaker that he analysed. However, given formant values were only measured in the centre of the vowel, this claim can be neither confirmed nor falsified by the analysis of the current study’s data. Lastly, Brändle’s (Reference Brändle, Helen, Sibylle, Walter, Nadia and Hans2010: 14) claim that [ɒː] is more often used by women in ZH SSG cannot be confirmed by this study. Rather, whether a ZH speaker chooses to use [ɒː] for the SSG <a>-sound does not appear to be linked to sex.
Regarding RQ3, i.e. whether the same dialect groups show the same or different vowel qualities in ALM and SSG, the results suggest that vowel qualities tend to stay mostly stable, thus generally confirming H3. Nevertheless, there are certain differences among the four regions. The most stable vowel quality system was found in GR, where the pronunciation of ALM and SSG was practically identical as evident by the lack of statistical significance for the factor variety and the interaction between variety and vowel quality. The two varieties from VS are also rather similar. For /iː yː eː oː/, there is practically no difference. Regarding <a>-sounds, the SSG one resembles its ALM equivalent although it is pronounced minimally less in the back. Whether this difference is salient is questionable, however. Moreover, because VS ALM /æː/ and SSG /ɛː/ do not have a direct equivalent in the other variety, RQ3 cannot be ultimately answered for these vowels. As for BE, only two instances of a statistically significant vowel-quality difference between ALM and SSG were observed. Namely for <a>-sounds and for /oː/, whose F2 differ depending on the variety. Otherwise, the vowel-quality system stays mostly stable with some caveats. While much overlap has been found for the high vowels /iː yː uː/, the mid-close vowels /eː 퀈ː oː/ did not include as clear-cut a distinction with [ɛː œː ɔː] as in the other regions, which is likely due to dialect-internal interspeaker variation. A reason for this could be that in BE ALM, the vowel qualities [ɛː œː ɔː] are associated with the graphemes <ee öö oo>, which does not hold true for standard German, where they are pronounced as [eː 퀈ː oː]. To avoid using stigmatised non-standard variants for /eː 퀈ː oː/ (see Haas & Hove 2009: 262), some speakers might thus pronounce them more in a standard way, which could explain why the SSG ellipsis expands over the frequencies of ALM /eː ɛː 퀈ː œː oː ɔː/. Consequently, the BE SSG vowel-quality system shows the biggest degree of variation. Lastly, ZH speakers show a very stable vowel-quality system as well. As a matter of fact, its vowels are the most clearly distinct from one another in both ALM and SSG, and the average F1/F2 values are very similar in ALM and SSG. There is only one exception: <a>-sounds are more centralised in SSG than in ALM due to both [ɑː] and [ɒː] being used as reported by Hove (Reference Hove2002: 65) and Brändle (Reference Brändle, Helen, Sibylle, Walter, Nadia and Hans2010: 13–14).
An issue that must be addressed is the question of why some dialectal variants remain stable in the speakers’ SSG while others are replaced. Recently published research that has dealt with linguistic variation on the vertical dimension in Chur (Eckhardt Reference Eckhardt2016) as well as in different regions of Germany (e.g. Kehrein Reference Kehrein2012, Reference Kehrein, Michael, Markus and Jürgen Erich2015; Vorberger Reference Vorberger2019) has introduced approaches to interpreting these dynamic processes by referring to currently discussed theories of linguistic dynamics. However, due to the relatively small number of speakers per region as well as the amount of interspeaker variation observed, it is questionable whether generalisable inferences on this issue can be made. It will thus have to be left to future research to shed more light on this topic.
In conclusion, for high vowels, only two instances of region specificity were found. BE SSG /iː/ was produced more on the periphery and GR SSG /yː/ more in the centre. Regarding [eː 퀈ː oː], BE SSG realisations not only tend to be lower but also tend to show more variation most likely due to ALM interference. As for /ɛː/, both BE and GR stand out in that BE speakers produced it either as [ɛː] or as [æː], while GR speakers showed a tendency in the other direction approaching [eː]. Finally, <a>-sounds were mostly adopted from ALM in that BE speakers used [ɑː], GR speakers [aː], and VS and ZH speakers [ɒː]. Some ZH speakers also opted for [ɑː] occasionally, which was not associated with sex, however. Generally, vowel quality in all four regions remains stable regardless of whether speakers use ALM or SSG. This means that vowel quality interferences do indeed take place. Having said this, minor quality changes were also observed. These mainly occurred, however, in BE, where speakers showed both typical SSG close-mid vowels and more dialectal open-mid vowels for the realisation of the vowels represented by the letters <ee öö oo>. Moreover, ZH speakers tended to show less rounded low back vowels in SSG than in their dialect, meaning that the <a>-sound was realised as both [ɑː] and [ɒː] in SSG rather than just [ɒː] as is the case in ALM. Speakers from GR and VS showed very stable vowel qualities, meaning that they did not change when ALM speakers switch to SSG.
5 Conclusion and suggestions for future research
This study for the first time systematically analysed the same speakers’ ALM and SSG long vowel qualities as well as their interrelation. For the dialectal dimension, the instrumental phonetic analysis confirms the auditory data of the SDS (1962), especially for mid-vowels and the <a>-sounds, and it can link the regional vowel-quality differences in SSG to these dialectal differences. In fact, the study has found that both the ALM and SSG varieties show a considerable amount of similarities with regard to vowel quality. However, they also differ in some respects. It was shown that GR high vowels tend to be lower than the ones of the other dialects in both ALM and SSG. Furthermore, BE ALM mid vowels behave differently from the other dialects’ mid vowels in both ALM and SSG. In ALM [eː 퀈ː oː], traditionally transcribed as [ɪː ʏː ʊː] or <ii üü uu>, have been found to be phonetically indistinguishable from GR, VS, and ZH [eː 퀈ː oː] or <ee öö oo>, suggesting that the BE dialectal phoneme-to-grapheme mapping is based on phonology and orthography rather than on phonetic considerations. Simultaneously, dialectal realisations of BE /ɛː œː ɔː/ are slightly higher than their canonical form, such that they sometimes may even overlap with /eː 퀈ː oː/, even though much variation has been observed. These fuzzy borders have implications for SSG as well, where /eː 퀈ː oː/ were realised as [eː 퀈ː oː], [ɛː œː ɔː], or as hybrids between the two versions, i.e. [e̞ː 퀈̞ː o̞ː]. This, however, only holds true for BE, whereas no such confusion was seen in GR, VS, or ZH. In SSG, BE speakers show a broad dispersion for /ɛː/ with some realisation as [eː], some as [ɛː], and some as [æː] due to it being orthographically represented as <ä>, which in ALM equals [æː]. In the other SSG varieties, [æː] was not observed for /ɛː/. Moreover, the different <a>-sound qualities turned out to be a good indicator of dialectal origin in both ALM and SSG. More precisely, the BE variant is best transcribed by [ɑː], the GR variant as a more fronted [aː], and the VS and ZH variant as [ɒː]. The results suggest that the speakers’ vowel quality stays rather stable when switching between the two varieties. Only BE and ZH showed statistically significant quality changes in that either speaker group fronted their realisations of <a>-sounds more in SSG, for which no correlation with sex could be identified.
This current study, of course, only serves as a starting point for understanding how ALM interrelates with SSG. To better comprehend region-specificity in ALM and SSG, future research must focus on additional aspects of vowel quality such as the stressed short vowel inventory, or the quality of both short and long vowels in unstressed lexical or prosodic positions, as southern dialects tend to reduce the vowel quality less (see Hove Reference Hove2020). It would also be advisable to include more words with the same target sound but a different phonological environment to control for coarticulatory effects. Other dialects could of course also be included in the analysis. Moreover, future research could take a more sociophonetic perspective on the relation between ALM and SSG vowel qualities. For instance, recording, at one single locality, a much higher number of speakers who in turn would have to be carefully selected in terms of age and level of education. Given the pluricentric status of standard German, one could also compare SSG varieties with various standard German varieties from Germany or Austria. Additionally, one could run perception experiments to find out which phonetic features are perceived as particularly dialectal in SSG. For instance, Kiesewalter (Reference Kiesewalter2019) analysed the German varieties of three speakers from Itzehoe (North Lower German dialect), Halle (Upper Saxon/Thuringia dialect), and Karlshuld (Middle Bavarian dialect) and proved among other findings that (i) subjectively norm-compliant to slightly dialectal features are desonorisation of /z/ in the syllable onset and the fronting of schwa, (ii) subjectively moderately dialectal features are lenition of /s/ word-internally and /nd/ assimilation, and (iii) subjectively strongly dialectal features are coronalisation of /ç/, i.e. pronouncing it as [ʃ], and vowel centralisation. Certainly, insights gathered in such studies could prove beneficial in a forensic setting for the purpose of speaker profiling.
Acknowledgements
This study was funded by the Swiss National Science Foundation (SNSF), grant Nr. 164377. Furthermore, I would like to thank Sandra Schwab, who was of great help during the statistical analysis. Very much appreciated is also the help of Marie-Anne Morand and Seraina Nadig, who assisted me during the arduous work of manually correcting the automatically segmented data. Moreover, without the valued help of Markus Jochim (LMU Munich) and his expertise in R, the analysis of the formant frequencies would not have been as smooth. I am also very grateful to the following three people, who each helped me find appropriate words for their native dialect: Christa Schneider (University of Bern) for BE, Oscar Eckhardt (Grisons Institute for Cultural Studies) for GR, and Sandro Bachmann for VS. Finally, I would like to thank the three anonymous reviewers of this paper for their valuable and helpful comments and suggestions.
Appendix. word list, carrier phrases, and mean F1/F2 measurements (normalised)
Table A1 Orthographic representation, phonetic transcription, and English translation of the target words used to elicit the eleven long vowels in the four Alemannic dialects and Swiss Standard German.

BE = Bern; GR = Chur; VS = Brig; ZH = Zurich; SSG = Swiss Standard German
Table A2 Carrier phrases used to elicit the target words containing the eleven long vowels in the four Alemannic dialects and Swiss Standard German.

BE = Bern; GR = Chur; VS = Brig; ZH = Zurich; SSG = Swiss Standard German
Table A3 Mean values of normalised Alemannic F1/F2 measurements (in Hz) by dialect and vowel quality.

BE = Bern; GR = Chur; VS = Brig; ZH = Zurich
Table A4 Mean values of normalised Swiss Standard German F1/F2 measurements (in Hz) by dialectal region and vowel quality.

BE = Bern; GR = Chur; VS = Brig; ZH = Zurich













 Open access
Open access