


No CrossRef data available.
Article contents
A Monte Carlo algorithm for the extrema of tempered stable processes
Part of:
Stochastic processes
Probabilistic methods, simulation and stochastic differential equations
Published online by Cambridge University Press: 30 June 2023
Abstract
We develop a novel Monte Carlo algorithm for the vector consisting of the supremum, the time at which the supremum is attained, and the position at a given (constant) time of an exponentially tempered Lévy process. The algorithm, based on the increments of the process without tempering, converges geometrically fast (as a function of the computational cost) for discontinuous and locally Lipschitz functions of the vector. We prove that the corresponding multilevel Monte Carlo estimator has optimal computational complexity (i.e. of order 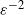 $\varepsilon^{-2}$ if the mean squared error is at most
$\varepsilon^{-2}$ if the mean squared error is at most 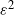 $\varepsilon^2$) and provide its central limit theorem (CLT). Using the CLT we construct confidence intervals for barrier option prices and various risk measures based on drawdown under the tempered stable (CGMY) model calibrated/estimated on real-world data. We provide non-asymptotic and asymptotic comparisons of our algorithm with existing approximations, leading to rule-of-thumb principles guiding users to the best method for a given set of parameters. We illustrate the performance of the algorithm with numerical examples.
$\varepsilon^2$) and provide its central limit theorem (CLT). Using the CLT we construct confidence intervals for barrier option prices and various risk measures based on drawdown under the tempered stable (CGMY) model calibrated/estimated on real-world data. We provide non-asymptotic and asymptotic comparisons of our algorithm with existing approximations, leading to rule-of-thumb principles guiding users to the best method for a given set of parameters. We illustrate the performance of the algorithm with numerical examples.
Keywords
MSC classification
Secondary:
65C05: Monte Carlo methods
Information
- Type
- Original Article
- Information
- Copyright
- © The Author(s), 2023. Published by Cambridge University Press on behalf of Applied Probability Trust
References
Andersen, L. and Lipton, A. (2013). Asymptotics for exponential Lévy processes and their volatility smile: survey and new results. Internat. J. Theoret. Appl. Finance 16, article no. 1350001, 98 pp.Google Scholar
Avram, F., Chan, T. and Usabel, M. (2002). On the valuation of constant barrier options under spectrally one-sided exponential Lévy models and Carr’s approximation for American puts. Stoch. Process. Appl. 100, 75–107.Google Scholar
Baurdoux, E., Palmowski, Z. and Pistorius, M. (2017). On future drawdowns of Lévy processes. Stoch. Process. Appl. 127, 2679–2698.Google Scholar
Ben Alaya, M. and Kebaier, A. (2015). Central limit theorem for the multilevel Monte Carlo Euler method. Ann. Appl. Prob. 25, 211–234.Google Scholar
Bisewski, K. and Ivanovs, J. (2020). Zooming-in on a Lévy process: failure to observe threshold exceedance over a dense grid. Electron. J. Prob. 25, 33 pp.Google Scholar
Blumenthal, R. M. and Getoor, R. K. (1961). Sample functions of stochastic processes with stationary independent increments. J. Math. Mech. 10, 493–516.Google Scholar
Carr, P., Geman, H., Madan, D. and Yor, M. (2002). The fine structure of asset returns: an empirical investigation. J. Business 75, 305–332.CrossRefGoogle Scholar
Carr, P., Zhang, H. and Hadjiliadis, O. (2011). Maximum drawdown insurance. Internat. J. Theoret. Appl. Finance 14, 1195–1230.Google Scholar
Chambers, J. M., Mallows, C. L. and Stuck, B. W. (1976). A method for simulating stable random variables. J. Amer. Statist. Assoc. 71, 340–344.Google Scholar
Cont, R. and Tankov, P. (2015). Financial Modelling with Jump Processes, 2nd edn. CRC Press, Boca Raton.Google Scholar
Downey, L. (2009). Ulcer Index (UI): what it is, how it works. Available at https://www.investopedia.com/ terms/u/ulcerindex.asp.Google Scholar
Figueroa-López, J. E. and Tankov, P. (2014). Small-time asymptotics of stopped Lévy bridges and simulation schemes with controlled bias. Bernoulli 20, 1126–1164.Google Scholar
Giles, M. B. and Xia, Y. (2017). Multilevel Monte Carlo for exponential Lévy models. Finance Stoch. 21, 995–1026.Google Scholar
Glasserman, P. (2004). Monte Carlo Methods in Financial Engineering. Springer, New York.Google Scholar
González Cázares, J. and Mijatović, A. (2022). Simulation of the drawdown and its duration in Lévy models via stick-breaking Gaussian approximation. Finance Stoch. 26, 671–732.CrossRefGoogle Scholar
González Cázares, J. I. and Mijatović, A. (2021). TSB-Algorithm (video). Available at https://youtu.be/FJG6A3zk2lI. Published on Prob-AM YouTube channel.Google Scholar
González Cázares, J. I., Mijatović, A. and Uribe Bravo, G. (2022). Geometrically convergent simulation of the extrema of Lévy processes. Math. Operat. Res. 47, 1141–1168.Google Scholar
Grabchak, M. (2019). Rejection sampling for tempered Lévy processes. Statist. Comput. 29, 549–558.Google Scholar
Hoel, H. and Krumscheid, S. (2019). Central limit theorems for multilevel Monte Carlo methods. J. Complexity 54, article no. 101407, 16 pp.Google Scholar
Ivanovs, J. (2018). Zooming in on a Lévy process at its supremum. Ann. Appl. Prob. 28, 912–940.Google Scholar
Kallenberg, O. (2002). Foundations of Modern Probability, 2nd edn. Springer, New York.Google Scholar
Kawai, R. and Masuda, H. (2011). On simulation of tempered stable random variates. J. Comput. Appl. Math. 235, 2873–2887.Google Scholar
Kim, K.-K. and Kim, S. (2016). Simulation of tempered stable Lévy bridges and its applications. Operat. Res. 64, 495–509.CrossRefGoogle Scholar
Klüppelberg, C., Kyprianou, A. E. and Maller, R. A. (2004). Ruin probabilities and overshoots for general Lévy insurance risk processes. Ann. Appl. Prob. 14, 1766–1801.Google Scholar
Kou, S. (2014). Lévy processes in asset pricing. In Encyclopedia of Quantitative Risk Analysis and Assessment, John Wiley, New York. Available at https://onlinelibrary.wiley.com/doi/abs/10.1002/ 9781118445112.stat03738.Google Scholar
Kudryavtsev, O. and Levendorski, S. (2009). Fast and accurate pricing of barrier options under Lévy processes. Finance Stoch. 13, 531–562.Google Scholar
Landriault, D., Li, B. and Zhang, H. (2017). On magnitude, asymptotics and duration of drawdowns for Lévy models. Bernoulli 23, 432–458.Google Scholar
Li, P., Zhao, W. and Zhou, W. (2015). Ruin probabilities and optimal investment when the stock price follows an exponential Lévy process. Appl. Math. Comput. 259, 1030–1045.Google Scholar
McLeish, D. (2011). A general method for debiasing a Monte Carlo estimator. Monte Carlo Meth. Appl. 17, 301–315.Google Scholar
Mordecki, E. (2003). Ruin probabilities for Lévy processes with mixed-exponential negative jumps. Theory Prob. Appl. 48, 188–194.Google Scholar
Pitman, J. and Uribe Bravo, G. (2012). The convex minorant of a Lévy process. Ann. Prob. 40, 1636–1674.Google Scholar
Poirot, J. and Tankov, P. (2006). Monte Carlo option pricing for tempered stable (CGMY) processes. Asia-Pacific Financial Markets 13, 327–344.Google Scholar
Rhee, C.-H. and Glynn, P. W. (2015). Unbiased estimation with square root convergence for SDE models. Operat. Res. 63, 1026–1043.Google Scholar
Sato, K.-I. (2013). Lévy Processes and Infinitely Divisible Distributions. Cambridge University Press.Google Scholar
Schoutens, W. (2003). Levy Processes in Finance: Pricing Financial Derivatives. John Wiley, New York.Google Scholar
Schoutens, W. (2006). Exotic options under Lévy models: an overview. J. Comput. Appl. Math. 189, 526–538.Google Scholar
Sornette, D. (2003). Why Stock Markets Crash: Critical Events in Complex Financial Systems. Princeton University Press.Google Scholar
Vihola, M. (2018). Unbiased estimators and multilevel Monte Carlo. Operat. Res. 66, 448–462.Google Scholar