


It is widely acknowledged that adult learners can experience difficulty acquiring the system of phonological contrasts in a second language (L2). One consequence of this difficulty is spurious homophony (see, e.g., Ota, Hartsuiker, & Haywood, Reference Ota, Hartsuiker and Haywood2009; Weber & Cutler, Reference Weber and Cutler2004), where learners confuse minimally contrastive lexical items in the L2 resulting from an inability to encode and/or process a novel L2 phonological contrast (e.g., native Japanese speakers may confuse the English words “read” and “lead” due to difficulty with the English /r/–/l/ contrast). The past several years have seen an increase in research activity focused on exploring the roles of lexical encoding and processing in learners’ ability to distinguish L2 words differentiated by novel contrasts (e.g., Cutler, Weber, & Otake, Reference Cutler, Weber and Otake2006; Darcy et al., Reference Darcy, Dekydtspotter, Sprouse, Glover, Kaden and McGuire2012; Hayes-Harb & Masuda, Reference Hayes-Harb and Masuda2008). There has also been a concurrent increase in research exploring the role that orthographic input may play in L2 learners’ lexical and phonological development (e.g., Bassetti, Reference Bassetti2006, Reference Bassetti, Piske and Young-Scholten2008; Cutler, Treiman, & van Ooijen, Reference Cutler, Treiman and van Ooijen2010; Detey & Nespoulous, Reference Detey and Nespoulous2008; Escudero, Hayes-Harb, & Mitterer, Reference Escudero, Hayes-Harb and Mitterer2008; Escudero & Wanrooij, Reference Escudero and Wanrooij2010; Hayes-Harb, Nicol, & Barker, Reference Hayes-Harb, Nicol and Barker2010; Simon, Chambless, & Alves, Reference Simon, Chambless and Alves2010; Ziegler, Muneaux, & Grainger, Reference Ziegler, Muneaux and Grainger2003). Especially in formal L2 instructional contexts, adult learners are typically exposed to written and spoken language simultaneously; for this reason, insights concerning how these two types of input may interact with one another are crucial to our understanding of L2 development.
Recent work has provided evidence that orthographic input may provide a benefit to learners with respect to lexical–phonological development (e.g., Escudero et al., Reference Escudero, Hayes-Harb and Mitterer2008) as well as evidence that there are circumstances where orthographic input interferes with learners’ developing lexical–phonological systems (e.g., Bassetti, Reference Bassetti2006; Hayes-Harb et al., Reference Hayes-Harb, Nicol and Barker2010). At this point, the role that written input may play in L2 learners’ memory for L2 words is perhaps best understood in cases where the first and second languages both use the same (or very similar) writing systems (e.g., English and Dutch in Escudero et al., Reference Escudero, Hayes-Harb and Mitterer2008). However, fewer studies have examined the role of unfamiliar orthographic information in learners’ ability to remember the phonological forms of words (e.g., Showalter & Hayes-Harb, Reference Showalter and Hayes-Harb2013). In the present study, we examined the influence of written forms presented in an entirely unfamiliar orthography on the acquisition of L2 words differentiated by a novel phonological contrast.
BACKGROUND
Recent studies have provided evidence that the availability of written forms in the L2 input can aid learners’ memory for the phonological forms of newly learned words. These studies have explored cases where learners who are exposed to words’ written forms exhibit more accurate memory for the phonological forms of words than do learners who do not see written forms. For example, Escudero et al. (Reference Escudero, Hayes-Harb and Mitterer2008) found that the availability of written forms supported native Dutch speakers’ ability to distinguish the phonological forms of newly learned English (non)words in lexical memory. Native Dutch speakers have difficulty perceiving and producing the English /æ/–/ε/ contrast (e.g., “bat” vs. “bet”; see, e.g., Weber & Cutler, Reference Weber and Cutler2004). However, Escudero et al. hypothesized that when new auditory words contrasted by /æ/ and /ɛ/ were accompanied by their written forms (e.g., “tenzer” for [tɛn . . .] and “tandek” for [tæn . . .]) in the input to Dutch learners of English, this would facilitate the Dutch speakers’ memories for the words’ phonological forms. In the study, one group of participants saw spelled English nonwords and heard auditory forms, while the other group only heard the forms. Patterns of lexical confusion revealed by eye-tracking data indicated that only the participants exposed to the orthographic forms had created lexical representations that contrasted the /æ/ and /ɛ/ vowels in the first syllables of the newly learned words. Thus, orthographic information in the study facilitated participants’ ability to encode the novel contrast in their lexical representations.
There are cases where orthographic information may be neither a help nor a hindrance to learners. For example, Simon et al. (Reference Simon, Chambless and Alves2010) examined whether orthographic information would support learners’ ability to acquire a novel phonological contrast. The French vowel contrast /u/–/y/ is notoriously difficult for English speakers, who lack the high, front vowel /y/. Participants in the orthographic and auditory information group saw pictures (e.g., a boat, a banana, and glasses) and heard triplet auditory forms (e.g., [styg]–[stug]–[stig]) while seeing the corresponding orthographic representations (e.g., <stûgue>–<stougue>–<stigue>). It was found that orthographic information only minimally aided participants, with performance not significantly above the auditory only group. Thus, in some cases, orthographic information may not affect learners’ ability to remember the phonological forms of words (a conclusion that is supported by the findings of Escudero, Reference Escudero2015 [this issue]).
Finally, there is also evidence that written input can interfere with learners’ lexical–phonological development, specifically in cases where the first and the second language use the same set of graphemes but employ different grapheme–phoneme correspondence rules. Hayes-Harb et al. (Reference Hayes-Harb, Nicol and Barker2010) found that when the spelled forms of words presented during a word-learning phase did not follow English grapheme–phoneme correspondences (e.g., the auditory word [togɛg], associated with a picture of a button was written as <thogeg>), native English speakers misremembered the phonological forms of the words according to their spellings (e.g., at test, they incorrectly accepted [Ɵogɛg] as matching the picture of the button). The results of Hayes-Harb et al. suggest that learners who interpret grapheme–phoneme correspondences in novel words following first language (L1) correspondences may remember the novel phonological forms incorrectly. Similar effects of mismatches between native and L2 spelling conventions for native speakers of Italian learning English are reported by Bassetti and Atkinson (Reference Bassetti and Atkinson2015 [this issue]).
Bassetti (Reference Bassetti2006) demonstrated that a learner's L1 spelling conventions can hinder acquisition of phonological forms in the L2. She found that native English speakers learning Chinese interpreted Pinyin, a Roman alphabet representation of Mandarin, using L1 grapheme–phoneme correspondences. When asked to segment and to count diphthongs and triphthongs in Mandarin listening tasks (e.g., for <gui>–[guei] and <wei>–[uei]), native English-speaking learners of Mandarin in this study counted and segmented fewer vowels than were present (i.e., [gui]), presumably due to inferences they made about the phonological forms of the utterances based on how they were spelled in Pinyin.
The studies discussed thus far have considered cases where learners encounter L2 written forms in a familiar writing system. Showalter and Hayes-Harb (Reference Showalter and Hayes-Harb2013) investigated whether novel written information (in this case, diacritic tone marks) can similarly influence learners’ memory for the phonological forms of newly learned L2 words. One group of participants heard auditory forms and saw segment sequences in pseudo-Mandarin with diacritic marks representing the four-tone contrast in Mandarin (e.g., <fián>), while another group received orthographic information without tone diacritics (e.g., <fian>). The final test assessed whether participants had made lexical representations between the auditory forms and pictures. Participants in the tone marks condition performed more accurately, suggesting that the availability of the diacritics had facilitated their memory for the phonological forms of words. Showalter and Hayes-Harb demonstrated that learners are able to make use of novel orthographic information, in this case, diacritic information.
The studies discussed thus far have provided evidence that learners can make inferences about the phonological forms of newly learned L2 words based on information provided by written forms, and that these inferences are sometimes helpful and sometimes not. Why is orthographic input helpful in some cases and not in others? One possibility is that the auditory contrasts explored in the various studies may differ in their perceptibility to subjects. For example, the novel vowel contrasts in the Simon et al. (Reference Simon, Chambless and Alves2010) study may have been so difficult that the orthographic input was ultimately unusable by subjects. This issue will be taken up in more detail in the Discussion section.
Another possibility is that a learner's ability to benefit from the availability of L2 written input, at least when the L1 and L2 employ the same writing system, may have to do with the relationship between the relevant grapheme–phoneme correspondences in the L1 and the L2 (i.e., whether they are “congruent” or “incongruent”). Hayes-Harb et al. (Reference Hayes-Harb, Nicol and Barker2010) found that incongruency between the L1 and L2 grapheme–phoneme correspondences served to interfere with their subjects’ ability to remember the phonological forms of words; Escudero, Simon, and Mulak (Reference Escudero, Simon and Mulak2014) report a similar effect of incongruency with native Spanish learners of Dutch, and Young-Scholten and Langer (Reference Young-Scholten and Langer2015 [this issue]) provide evidence that this orthographic effect also occurs in production of the L2 (e.g., German <s>–[z] by English speakers). In contrast, Escudero et al.'s (Reference Escudero, Hayes-Harb and Mitterer2008) subjects presumably benefitted from the relative congruency between English and Dutch grapheme–phoneme correspondences (i.e., the letters “a” and “e” map to separate vowel phonemes in both languages). Rafat (Reference Rafat2015 [this issue]) reports a similar effect for native speakers of English and Spanish rhotics, where the availability of spelled forms (with rhotics represented by <r>) appears to increase the likelihood that subjects produce the corresponding segments as rhotics (as opposed to, e.g., fricatives).
To the extent that “incongruency” between grapheme–phoneme correspondences in the L1 and the L2 may interfere with L2 word-form learning, difficulty associated with novel graphemic forms in the input may be offset by the fact that there are no native grapheme–phoneme correspondences to “override” in cases where the L2 uses a different writing system. This hypothesis is supported by the finding by Showalter and Hayes-Harb (Reference Showalter and Hayes-Harb2013) that native English speakers experienced a benefit from the availability of diacritic tone marks in learning to distinguish among lexical tone minimal quadruplets. Thus, when the majority of the orthographic symbols are familiar and novel graphemic forms cue a novel phonological contrast, learners may benefit from the availability of written forms. In the present study, we ask, can learners benefit from written forms made up of entirely unfamiliar symbols? To address this question, we examined native English speakers’ acquisition of Arabic-like words differentiated by the voiceless velar–uvular stop contrast and written in the Arabic script.
EXPERIMENT 1
Experiment 1 was designed to determine whether native English speakers can benefit from the availability of written input in an entirely novel script when learning the phonological forms of new L2 words. Previous studies have primarily focused on orthographic input cases where the graphemes and, for the most part, the phonemes were familiar in some way to the learners. To investigate whether learners are able to invoke a more abstract type of knowledge, that is, the expectation that written forms will provide useful information about the phonological forms of words, we selected the Arabic alphabet, which is entirely different from the Roman alphabet. The Arabic alphabet differs from the Roman alphabet as used in English with respect to the inventory of phonemes represented by the writing system, the letters themselves, the representation of vowel phonemes (i.e., short vowels are indicated via diacritics if at all), and the directionality of the script (Arabic is written right to left). In order to maximize consistency with previous studies (e.g., Escudero et al., Reference Escudero, Hayes-Harb and Mitterer2008; Showalter & Hayes-Harb, Reference Showalter and Hayes-Harb2013), we neither directed participants’ attention to the written forms nor instructed them in any way about the Arabic script.
Participants
Thirty native English speakers between the ages of 18 and 58 were recruited from undergraduate courses at the University of Utah. No participant had a history of neurological, speech, hearing, or language-processing disorders, or any experience with the Arabic language or a language written in a similar script, as reported on a background questionnaire. Participants were randomly assigned to the “Arabic script” and the “control” word-learning conditions. Participants in the Arabic script condition consisted of 5 males and 10 females (n = 5; mean age = 26.4), and participants in the control condition consisted of 3 males and 12 females (n = 15; mean age = 29.4).
Stimuli
All stimuli in Experiment 1 were Arabic nonwords created in a C1VC2V template, three of which were of the form C1V1C2V2 and three of the form C1V1C2V1 (e.g., [kita], [kini]). There were 6 minimal pairs, contrasted by the velar–uvular contrast /k/–/q/ (e.g., [kubu]–[qubu]), for a total of 12 unique words. The contrasting segments /k/ and /q/ appear in word-initial position, which was chosen for its perceptual salience. All vowels are long (i.e., /a:, u:, i:/) and thus were represented in the written forms via letters (as opposed to diacritics).
Two male talkers of Jordanian Arabic (ages 30 and 21) produced the nonwords. The talkers had been in the United States for nearly equivalent lengths of time (2 and 2.5 years). The talkers were shown the nonwords written in Arabic and were asked to produce each one three times. The second production of each nonword was extracted from the recordings for use in the present study.
Each nonword was randomly assigned an object picture (from the Bank of Standardized Stimuli; Brodeur, Dionne-Dostie, Montreuil, & Lepage, Reference Brodeur, Dionne-Dostie, Montreuil and Lepage2010; Creative Commons, n.d.); this assignment was identical for all subjects. Table 1 provides the orthographic representations, auditory forms, and the pictured meaning for each nonword.
Table 1. Experiment 1 auditory and visual stimuli

Procedure
Experiment 1 consisted of a word-learning phase, a criterion test phase, and a final test phase. All phases of the experiment were conducted within an hour-long session. The word-learning phase for the Arabic script condition participants involved simultaneously hearing the auditory form of each word, seeing the picture, and seeing the written form (e.g., hear [kubu], see a picture of glasses, and see the orthographic representation). The Arabic script condition participants saw the words written in the Arabic script (e.g., ![]() ), and the control condition saw the meaningless Arabic letter sequence <
), and the control condition saw the meaningless Arabic letter sequence <![]() >, roughly analogous to <XXXX>, used as a control form in studies of Roman orthography. Use of this control written form ensured that participants in both groups experienced similar amounts of visual information.
>, roughly analogous to <XXXX>, used as a control form in studies of Roman orthography. Use of this control written form ensured that participants in both groups experienced similar amounts of visual information.
In both word-learning conditions, each of the auditory words, along with its corresponding picture and written form, was presented twice per block, totaling 24 items per block. The block was presented four times in a different, random order each time and for each participant, for a total of 96 exposures to the new words (12 words × 2 presentations/block × 4 blocks). Participants were not required to register any responses during the word-learning phase; they were simply instructed to learn the words and their meanings as well as possible.
The purpose of the criterion test was to assess whether the participants had generally learned the word meanings. Each trial of the criterion test involved the presentation of an auditory word and a picture without a written form (see Figure 1 for examples). There were 48 trials in the criterion test: 24 trials involved matched items (e.g., see picture of [kita], hear [kita]) and 24 trials involved mismatched items (e.g., see picture of [kita], hear [qaʃu]), presented in a different random order for each participant. Participants had 3 s to respond YES (the picture and the auditory word are matched) or NO (they are not matched) by pressing keys on the computer keyboard. If participants did not respond within the 3-s time allotment, their answer was considered incorrect, and the program moved to the next trial. The criterion test did not probe participants’ ability to discriminate the velar–uvular contrast, but rather their ability to distinguish completely different words (e.g., [kita]–[qaʃu]); thus the criterion test trials did not involve minimal pairs. Participants were required to reach 90% accuracy on the criterion test before continuing to the final test phase, and they were allowed to complete the word learning–criterion test cycle as many times as necessary to reach the criterion.
Figure 1. Example criterion test items.
The final test phase trials were identical to those in the criterion test, except that participants were tested on their ability to discriminate the velar–uvular pairs (see Figure 2 for example test items). As in the criterion test, there were 24 matched and 24 mismatched trials. The 24 mismatched trials included 12 trials with [k] auditory forms and [q] pictures and 12 trials with [q] auditory forms and [k] pictures.

Figure 2. Example final test items.
The entire experiment was conducted in a sound-attenuated booth. Stimuli were presented and responses collected on a computer using DMDX software (Forster & Forster, Reference Forster and Forster2003). Auditory stimuli were presented over headphones, and participants pressed keys on a computer keyboard to register responses.
Results
The mean number of word learning–criterion test cycles required was 3.66 (range = 1–8) for subjects in the Arabic script group and 3.00 (range = 1–6) for subjects in the control group. There was not a significant difference in the number of cycles required to reach criterion between the two groups, t (28) = 1.00, p = .326, indicating that the two groups of subjects did not differ overall in the amount of exposure they had to the new words.
Table 2 presents the results of Experiment 1. An analysis of variance (ANOVA) was conducted with word-learning group (two levels: Arabic script and control) as a between-subjects variable, item type (two levels: matched and mismatched) as a within-subjects variable, and proportion correct as the dependent variable. The main effect of item type was significant, with more accurate performance on matched than mismatched items, F (1, 28) = 135.983, p < .005, partial η2 = 0.829. However, neither the main effect of group, F (1, 28) = 0.151, p = .701, partial η2 = 0.151, nor the interaction of group and item type, F (1, 28) = 0.024, p = .877, partial η2 = 0.001, was significant. In addition, the proportion correct scores were converted to d-primes in order to assess subjects’ ability to detect the difference between matched and mismatched items. These d-primes were submitted to an ANOVA with subject group as a between-subjects variable. Given the proportion of correct results above, the effect of subject group on d-primes was not significant, F (1, 28) = 0.486, p = .492, partial η2 = 0.017.
Table 2. Experiment 1 mean (standard deviation) proportion correct and d-prime scores by word learning group
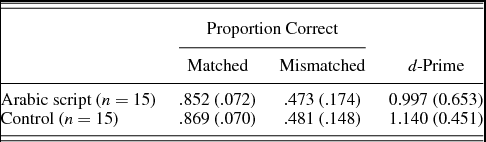
The results of Experiment 1 thus do not provide evidence that the written forms presented during the word-learning phase impacted subjects’ ability to learn the phonological forms of the novel L2 words. That is, the native English learners did not appear to benefit from the availability of the spelled forms of the words during the word-learning phase when discriminating between the newly learned velar–uvular minimal pairs at test. Given that previous experiments with similar designs and amounts of exposure (e.g., Escudero et al., Reference Escudero, Hayes-Harb and Mitterer2008; Showalter & Hayes-Harb, Reference Showalter and Hayes-Harb2013) have revealed significant effects of the availability of written forms on memory for the phonological forms of newly learned words, we next sought to understand what might distinguish the present case from the previous studies. To this end, we conducted several follow-up experiments to explore possible explanations for the lack of an effect of written input in Experiment 1. We explored the possibility that the Arabic script was simply uninterpretable to subjects given the combination of its novel symbols and its directionality (Arabic script is written from right to left). In Experiment 2, we attempted to alleviate some of the visual difficulty of the Arabic script by providing explicit instruction about written Arabic prior to the word-learning phase.
EXPERIMENT 2
It is possible that the participants in Experiment 1 did not know where to look when reading the Arabic script because they were unaware that the right sides of the written words held the graphemes that encoded the novel phonological contrast. It is also possible that the participants did not realize that the forms written in the Arabic script contained multiple graphemes, and that they experienced difficulty “extracting” individual graphemes from the written forms. In order to moderate the difficulty of the Arabic script, in Experiment 2, participants were given instruction about the Arabic writing system before they began the word-learning phase.
Participants and stimuli
Four male and four female participants were included in Experiment 2 (n = 8; mean age = 20.7 years) in a word-learning condition called “Arabic script + instruction.” The control group data comes from Experiment 1. They met all criteria as described for Experiment 1 participants. All of the auditory forms, object pictures, and written forms were identical to those in Experiment 1.
Procedure
The word-learning, criterion test, and final test phases were identical to Experiment 1. However, before participants began the word-learning phase, they were given instructions about the Arabic writing system. They were told that the Arabic script is read from right to left and not left to right as in English, and completed example trials with an arrow pointing to the right side of the orthographic representation to focus their attention on the right side of the word. Figure 3 presents screen shots from the instruction phase of Experiment 2.
Figure 3. Unlike English, which is written from left to right, this new language is written from right to left. For example, the two words written in the top panel differ only in their first sounds. The letters representing the first sound appear on the right-hand side of the word. Contrast this with a language such aas English, which is written from left to right, where the letter representing the first sound is on the left side of the word in the second panel. The third panel contains one more example from the new language. The two words differ only in their first letters.
Results
The performance of subjects in this new word-learning condition was compared to that of the control group from Experiment 1 in order to determine whether the addition of explicit instruction about the Arabic script might render the Arabic written forms more helpful to learners. The mean number of word learning–criterion test cycles required for subjects in the Arabic script + instruction condition was 3.250 (range = 1–6). A Mann–Whitney test (given unequal sample sizes) indicated that the difference in number of word-learning cycles required by the Arabic script + instruction group and the control group from Experiment 1 (3.000) was not significant (U = 57, p = .841).
Table 3 presents the proportion correct and the d-prime scores for subjects in the Arabic script + instruction group. A Mann–Whitney test indicated that the difference in d-prime scores between the Arabic script + instruction group (1.026) and the control group from Experiment 1 (1.140) was not significant (U = 58, p = .897).
Table 3. Experiment 2 mean (standard deviation) proportion correct and d-prime scores

Again, we did not find any benefit of the availability of written forms for this novel contrast and this novel script. Participants in Experiment 2 appear to have performed slightly less accurately than both Arabic script and control subjects from Experiment 1, despite the addition of explicit instruction about the Arabic writing system (though it may be worth noting that Experiment 2 involved only eight participants). In Experiment 3, we attempted to alleviate the script difficulty in a different way: by presenting the written forms in the familiar Roman alphabet.
EXPERIMENT 3
The Arabic velar–uvular contrast may be sufficiently difficult for native English speakers to perceive that even with the availability of (unfamiliar) written forms that support the contrast, native English speakers are unable to learn to distinguish the newly learned minimal pairs. In an effort to isolate the challenge posed by this particular novel phonological contrast, in Experiment 3, we attempted to remove as much script difficulty as possible by presenting written forms using the Roman alphabet. We reasoned that if subjects still have difficulty learning to discriminate the newly learned minimal pairs, it may be that the auditory contrast is so difficult that even when written forms are available, they may simply be unusable.
Participants
One male and seven female subjects participated in Experiment 3 (mean age = 21.1 years), in a word-learning condition called “Roman script.” Subjects met all requirements described for Experiment 1 participants.
Stimuli and procedures
All of the auditory and picture stimuli were identical to those used in Experiments 1 and 2. Experiment 3 differed from Experiments 1 and 2 in that written forms were in the Roman alphabet (e.g., <kubu>). It is important to note that the voiceless uvular stop /q/ was represented with the grapheme <q> (e.g., /qubu/, <qubu>). This meant that the native English speakers were exposed to a novel grapheme–phoneme correspondence, given that the uvular /q/ is not present in English and <q> is typically associated with English /k/. All phases within Experiment 3 were identical to those in Experiments 1 and 2.
Results
The performance of subjects in the Roman script condition was compared to that of both the Arabic script group and the control group from Experiment 1 in order to determine whether there are differences in the benefit derived from Roman versus Arabic written forms and whether the availability of Roman written forms improves performance over no written forms. The mean number of word learning–criterion test cycles required for subjects in the Roman script condition was 2.50 (range = 1–5). Mann–Whitney tests reveal that there was no difference in number of word-learning cycles required between the Roman script group and either the Arabic script group (3.667; U = 42.5, p = .245) or the control group (3.000; U = 49, p = .466).
Table 4 presents the proportion correct and the d-prime scores for subjects in the Roman script group. A Mann–Whitney test (given unequal sample sizes) indicated that the Roman script group performed significantly less accurately than both Experiment 1's control group (U = 14, p = .003) and the Arabic script group (U = 22, p = .014).
Table 4. Experiment 3 mean (standard deviation) proportion correct and d-prime scores
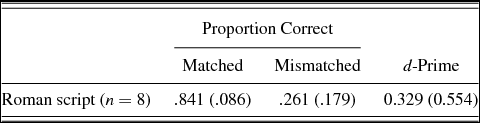
These results suggest that any difficulty associated with the Arabic script was not fully responsible for the lower than expected performance of the learners in Experiments 1 and 2. The availability for written forms in the Roman script appears to have suppressed subjects’ ability to discriminate the newly learned minimal pairs. It is possible that in transliterating Arabic to English in this way, we led subjects to believe that the phonological forms associated with words spelled with <k> and with <q> were not different, because in English both <k> and <q> map to the phoneme /k/ (e.g., “king,” “queen”). In addition, subjects may be familiar with written forms such as “Iraq” (typically pronounced [əɹæk] in American English) and “Qatar” (often pronounced [kɑtɑɹ] or [kʌɾəɹ]). Thus, the written forms may have inadvertently served to confirm their perception of [q] as /k/ in the auditory input.
In Experiment 4, we pursued an entirely different type of modification to the study design: the number of talkers represented in the auditory stimuli. In pilot studies for Showalter and Hayes-Harb (Reference Showalter and Hayes-Harb2013), we found that the novel lexical tone contrast was too difficult for subjects to learn when the new words were presented in two voices; however, when we reduced the number of talkers to one (as in the experiments reported in Showalter & Hayes-Harb, Reference Showalter and Hayes-Harb2013), subjects were better able to distinguish the newly learned minimal pairs, and differences in performance between subjects in the written forms and the control groups emerged. There are at least two possible explanations for this result: (a) given that the targeted auditory contrast was entirely novel, it may be the case that the variability between the two talkers obscured the variability associated with the novel contrast, and/or (b) one of the two original talkers (i.e., the one removed from the study) produced the lexical tone contrasts in ways that were not as discriminable to subjects, while the talker whose productions were preserved in the ultimate experiments produced them in ways that subjects were able to detect. In the context of the present study, we can explore the effects of two versus one talker, in addition to the individual effects of the two talkers. In Experiment 4, we thus reduced the number of talkers from two to one.
EXPERIMENT 4
Participants
Experiment 4 involved two new groups of subjects, each consisting of six males and nine females (average age per group 21.3 and 25.9). Subjects were randomly assigned to “Talker 1–Arabic script” and Talker 1–control” word-learning conditions.
Stimuli and procedures
All pictures were identical to those presented in Experiments 1–3. Written forms were identical to those in Experiment 1 (i.e., Arabic script). Auditory forms were those of one of the talkers from Experiments 1–3, which we refer to as “Talker 1.”
Results
The mean number of word learning–criterion test cycles required for subjects in the Talker 1–Arabic script group was 2.400 (range = 1–6) and for the Talker 1–control group was 1.600 (1–3), and the difference between the two groups was significant, t (28) = 2.145, p = .041.
Table 5 presents the proportion correct and d-prime results for these two new word-learning groups. An ANOVA was conducted with word-learning group (two levels: Talker 1–Arabic script and Talker 1–control) as a between-subjects variable, item type as a within-subjects variable, and proportion correct as the dependent variable. The main effect of item type was significant, with more accurate performance on matched than mismatched items, F (1, 28) = 69.803, p < .005, partial η2 = 0.714. However, neither the main effect of group, F (1, 28) = 1.464, p = .236, partial η2 = 0.050, nor the interaction of group and item type, F (1, 28) = 2.192, p = .150, partial η2 = 0.073, was significant. There was similarly no difference between groups in the d-prime scores, F (1, 28) = 0.911, p = .348, partial η2 = 0.031. Thus, even when the number of talkers was reduced from two to one, no significant differences in performance emerged between subjects who were presented with written forms and those who were not.
Table 5. Experiment 4 mean (standard deviation) proportion correct and d-prime scores by word learning group
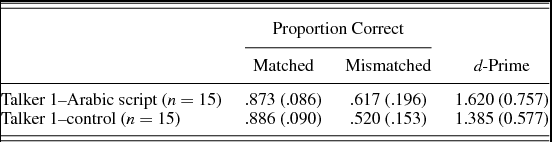
Talker 1 versus Talker 2
As mentioned above, it is possible that the improved performance of subjects in the Showalter and Hayes-Harb (Reference Showalter and Hayes-Harb2013) study over that of subjects in pilot experiments was due to the reduction in the number of talkers from two to one and/or the accessibility of the targeted contrast in the selected talker's speech over that of the other talker. In the interest of determining whether the particular talker chosen impacted subjects’ performance in Experiment 4, we performed one final experiment, which we will call Experiment 4x. Experiment 4x is identical to Experiment 4, except that instead of Talker 1, we used stimuli produced by the second of the two original talkers (Talker 2), in order to determine whether performance on this talker's speech improved over that of Talker 1. In addition, we ran only the Arabic script word-learning condition. Table 6 presents the results of this final experiment.
Table 6. Experiment 4x mean (standard deviation) proportion correct and d-prime scores by word learning group
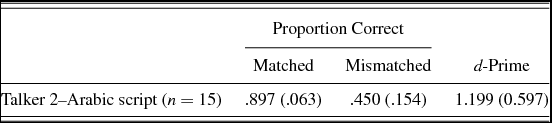
The mean number of word learning–criterion test cycles required for subjects in the Talker 2–Arabic script group was 2.533 (range = 1–4), and this did not differ significantly from the Talker 1–Arabic script group, t (28) = –0.325, p = .748. An ANOVA with word-learning group (two levels: Talker 1–Arabic script and Talker 2–Arabic script) as a between-subjects variable and item type as a within-subjects variable revealed a significant effect of item type, F (1, 28) = 104.902, p < .005, partial η2 = 0.789, a nonsignificant (but marginal) effect of word-learning condition, F (1, 28) = 3.963, p = .056, partial η2 = 0.124, and a significant interaction of the two, F (1, 28) = 7.738, p = .010, partial η2 = 0.217, on proportion correct scores. However, there was no significant difference in d-prime scores between the two word learning-groups, F (1, 28) = 2.859, p = .102, partial η2 = 0.093. Together, we may interpret these findings as indicating that while subjects may have performed slightly more accurately on Talker 1's than Talker 2's voice with respect to mismatched items, the Talker 1 and Talker 2 word-learning groups did not differ overall in their ability to discriminate the newly learned minimal pairs.
One versus two talkers
In order to assess whether subjects experienced a benefit from listening to a single as opposed to two talkers during the experiment, we compared performance by subjects in the Arabic script word-learning condition from Experiment 1 (with both talkers) to the Talker 1–Arabic script and the Talker 2–Arabic script word-learning conditions separately. We found that performance in Experiment 4 (Talker 1) was more accurate than that in Experiment 1 (with both talkers), F (1, 28) = 5.817, p = .023, partial η2 = 0.172; however, performance in Experiment 4x (Talker 2) was not, F (1, 28) = 0.779, p = .385, partial η2 = 0.027. We have thus provided some evidence that in cases where the talkers presented during the word-learning and testing phases are identical, subjects may be more successful at discriminating newly learned minimal pairs when the auditory input comes from a single talker as opposed to two talkers. However, the benefit of a single talker appears to be moderated by properties of the specific talker, such that some talkers lead to more accurate performance than others.
DISCUSSION
The series of experiments in the present study were designed to explore whether native English speakers can extend their ability to infer the phonological forms of newly learned words from written forms in a way that allows them to benefit from a novel script, in this case, Arabic. However, the present results are inconclusive given the apparent difficulty of the combination of this novel script (Arabic) and the novel contrast (/k/–/q/). In Experiment 1, we found that participants experienced a great deal of difficulty distinguishing the /k/–/q/ minimal pairs at test even when they had the support of Arabic written forms in their input. Experiment 2 represents an attempt to alleviate the novel script difficulty by providing instruction on how to read Arabic script, drawing subjects’ attention to the position of the symbols that reflected the novel contrast (i.e., the rightmost graphemes in the words). Learners experienced no apparent benefit from this instruction. In the third experiment, we abandoned the novel script in favor of Roman transliteration of the Arabic words in an effort to isolate the difficulty associated with the auditory contrast. However, accuracy at test actually decreased under these conditions, perhaps because the transliteration scheme we used (i.e., /k/–<k>and /q/–<q>) may have inadvertently led subjects to neutralize the auditory contrast, given that both <q> and <k> map to /k/ in English. Given previous findings with respect to the effect of multiple talkers in this type of experiment (i.e., where trained and tested talkers are identical and no generalization to new talkers is required), in Experiment 4 we attempted to alleviate the difficulty of the auditory contrast by reducing the number of trained/tested talkers to one. Performance accuracy did increase, but only minimally. Figure 4 presents the d-primes from the seven word-learning conditions explored in Experiments 1–4.
Figure 4. Summary of d-primes from Experiments 1–4.
Here we will discuss the results in Figure 4 in terms of three main findings. The first finding is that we have (descriptive) evidence that performance on a single talker is greater than that with two talkers. The Talker 1–Arabic script condition elicited the highest d-prime scores; however, there was no significant beneficial effect of the presence of the written forms, given the minimal difference between Talker 1–Arabic script and Talker 1–control group performance. In addition, even the Talker 2–Arabic script group's mean d-prime (1.199), which was lower than the d-primes for Talker 1,Footnote 1 was slightly higher than that of the highest two-talker condition (which was the control condition from Experiment 1; d-prime = 1.140). This finding is consistent with the findings of Showalter and Hayes-Harb (Reference Showalter and Hayes-Harb2013 and pilot experiments), and it may not be unexpected: if trained and tested talkers are identical, the less intertalker variability present in the auditory input, the less phonologically irrelevant variability there is to obscure the phonologically relevant variability associated with the contrast. To our knowledge, there has been no systematic examination of the effects of single versus multiple talkers in L2 word-learning studies where trained and tested talkers are identical. However, it has been found that a word-learning phase involving multiple talkers can lead to significantly more accurate performance with new talkers at test (Perrachione, Lee, Ha, & Wong, Reference Perrachione, Lee, Ha and Wong2011; Shehata, Reference Shehata2013).
A second finding is that providing written forms in the Roman alphabet (Experiment 3) was not helpful, and it led to performance that was significantly lower than that of participants who saw no written forms (i.e., control participants in Experiment 1). Of the seven word-learning conditions explored in the present study, the Roman script group was the only group whose d-prime was not significantly above zero, t (7) = 1.680, p = .137; all other groups were significantly above zero at p < .003. Thus our attempt at making subjects’ acquisition of the minimal pairs easier by providing familiar written symbols had the inadvertent effect of significantly reducing their performance accuracy at test relative to the two-talker control group in Experiment 1. This finding is not inconsistent with the findings of some previous studies looking at the influence of novel grapheme–phoneme correspondences on L2 word learning. As mentioned above, Simon et al. (Reference Simon, Chambless and Alves2010) found that native English speakers do not significantly benefit from the availability of written forms when learning French words when the written forms involve novel grapheme–phoneme correspondences. In addition, Hayes-Harb et al. (Reference Hayes-Harb, Nicol and Barker2010) demonstrated that native language grapheme–phoneme correspondences may be sufficiently powerful to cause subjects to misremember the phonological forms of newly learned words. We have thus provided further evidence that the transfer of native language grapheme–phoneme correspondences may be difficult to overcome, such that any anticipated benefit associated with familiar graphemes may be overridden by mismatches between the ways the L1 and the L2 connect graphemes to phonemes (for discussion, see Pytlyk, Reference Pytlyk2011).
Our third finding is that despite a number of manipulations to the word-learning phase of the study, we have not found any evidence that native English speakers can benefit from the availability of written forms when learning Arabic-like minimal pairs differentiated by the /k/–/q/ contrast. It should be noted that the type and amount of exposure to the new words in the present study was very similar to that in the Showalter and Hayes-Harb (Reference Showalter and Hayes-Harb2013) study, which indicated a positive effect of written input, even when some of the written input (i.e., the tone marks) was novel and the auditory contrast (i.e., lexical tone) was relatively difficult (see, e.g., Wong & Perrachione, Reference Wong and Perrachione2007). Why, then, were learners consistently unable to benefit from the various written input conditions in the present study? First, it may be that the auditory contrast (i.e., /k/–/q/) was simply too difficult for the native English listeners to reliably perceive: this particular contrast has received little if any attention in the L2 speech perception and production literature. However, Arabic language textbooks aimed at native English learners acknowledge its difficulty (and its similarity to English /k/). For example, Schulz, Krahl, and Reuschel (Reference Schulz, Krahl and Reuschel2000) tell learners that /q/ is “like [k] articulated with emphasis” and that it requires “special practice” (p. 2), and Brustad, Al-Batal, and Al-Tonsi (Reference Brustad, Al-Batal and Al-Tonsi1995) call /q/ the “emphatic counterpart to k” (p. 97). Arabic /q/ is thus quite similar to English /k/ and may be quite difficult for native English listeners to accurately perceive. Second, we have found that neither Arabic script nor Romanized Arabic were sufficient in the present case to support our subjects’ ability to distinguish the minimal pairs at test, even when the Arabic written forms were accompanied by explicit instruction about the Arabic writing system. However, we have not ruled out the possibility that some kind of written input might help learners overcome this difficulty with these /k/–/q/ minimal pairs. This is a topic in need of future research. It is possible that a combination of familiar Roman letters (e.g., <k>) and a novel (i.e., non-Roman) symbol for the phoneme /q/ would support native English speakers’ ability to acquire the lexical contrast. Such an instructional strategy, while inauthentic, would not be unlike the addition of lexical stress marks in Russian texts aimed at L2 learners or the use of Pinyin for learners of Mandarin.
There are a number of limitations in the present research. The first is that an hour-long word-learning session, as in the present experiments, does not adequately capture the duration and complexity of typical L2 acquisition. Especially in instructed settings, native English-speaking learners of Arabic are typically exposed to the Arabic graphemes one at a time, provided with information (varying in sophistication) about the production of the corresponding phonemes, and are given opportunities to practice reading and writing the graphemes. In the present study, the relatively short exposure to the orthographic forms and subjects’ apparent inability to benefit from the written input suggests that learners might require more opportunity than that provided inside of a 1-hr session in order for the availability of the Arabic written forms to be facilitative of their minimal pair learning. Even the explicit instruction we provided in Experiment 2 was superficial and was aimed, not at teaching grapheme–phoneme correspondences, but rather at orienting subjects to the directionality of the Arabic script. One might ask whether the participants in these experiments paid any attention to the orthographic representations during the word-learning phases, especially given that, with the exception of Experiment 2, they were given no information about the written forms. We have not (with the exception of Experiment 2) investigated the extent to which learners can make use of written forms once they are taught to interpret those forms, but we have investigated whether the availability of written forms in the input enhances their ability to learn words’ phonological forms. We assume that in order to make effective use of written information, participants must, at the very least, expect the written forms to provide useful information. While subjects in Showalter and Hayes-Harb (Reference Showalter and Hayes-Harb2013) were previously unfamiliar with, and received no instruction during the experiment about, diacritic tone marks, they nonetheless were able to use the marks to learn something about the phonological forms of new words. In the present case, with the Arabic script and a novel segmental contrast, native English speakers did not experience the same benefit from written forms.
A second limitation of the present work concerns talker variability in novel word learning. In pilot studies for Showalter and Hayes-Harb (Reference Showalter and Hayes-Harb2013) as well as in the present study, we have found that by reducing the number of talkers from two to one, participants can experience improvement in their ability to discriminate newly learned minimally contrastive words. Because the focus in these studies is on learners’ ability to lexically encode and use representations that distinguish novel contrasts, and not specifically on their ability to generalize to new talkers, we have reduced intertalker variability as much as possible in order to make the task of learning words as easy as possible. However, it is worth noting that this methodological choice is made at the expense of ecological validity, and further work exploring orthographic input effects with multiple talkers is needed in order to better understand authentic L2 acquisition.
Conclusion
Previous studies have demonstrated that the availability of orthographic information in the L2 input can impact how a learner remembers the phonological forms of words, whether in a facilitative manner (e.g., Escudero et al., Reference Escudero, Hayes-Harb and Mitterer2008) or in a manner that hinders performance (e.g., Hayes-Harb et al., Reference Hayes-Harb, Nicol and Barker2010). Written input may also have no observable effect, as in the present study and in Simon et al. (Reference Simon, Chambless and Alves2010). Together these findings suggest that the relationship between written and auditory input in L2 word learning is complex, and that we are just beginning to identify and understand the interplay of various relevant factors. Here we have provided evidence that when written forms are presented in an entirely novel script, learners (at first exposure) may be unable to use the written input in a beneficial manner. This may especially be the case when written forms presented in a novel script are accompanied by a particularly difficult auditory contrast. We have made some attempt to tease apart the independent contributions of the written form difficulty and the auditory contrast difficulty by manipulating the word-learning phase in a number of ways, though a number of questions remain concerning the perceptibility of the Arabic /k/–/q/ contrast for native English speakers, the challenge posed by the Arabic writing system, the kinds of explicit Arabic writing instruction that may benefit learners, and the utility of Roman transliteration in Arabic language pedagogy.
ACKNOWLEDGMENTS
We are grateful to members of the Speech Acquisition Lab at the University of Utah for their assistance in data collection, to the study participants, and for the helpful comments of the anonymous reviewers.









