


The similarities and differences between native (L1) and nonnative (L2) sentence processing are widely debated (e.g., Clahsen & Felser, Reference Clahsen and Felser2006, Reference Clahsen and Felser2018; Cunnings, Reference Cunnings2017; Grüter & Rohde, Reference Grüter and Rohde2013; Hopp, Reference Hopp2014; Kaan, Reference Kaan2014; McDonald, Reference McDonald2006). Some theories propose that L2 processing employs different parsing mechanisms from L1 processing (e.g., Clahsen & Felser, Reference Clahsen and Felser2006; Jiang, Reference Jiang2004). Alternatively, others have argued that L1 and L2 processing employ similar mechanisms and that L2ers construct syntactic analyses in the same way as L1ers (e.g., Cunnings, Reference Cunnings2017; Hopp, Reference Hopp2014; Kaan, Reference Kaan2014). Under such accounts, observable differences between groups are argued to be nonqualitative. In addition, the extent to which L1 and L2 parsing are modulated by individual differences is also debated (e.g., Hopp, Reference Hopp2014; McDonald, Reference McDonald2006; Tanner, Inoue, & Osterout, Reference Tanner, Inoue and Osterhout2014). For example, Hopp (Reference Hopp2014) argued that lexical automaticity plays a role in nativelike performance by L2ers, with more efficient lexical processing leading L2ers to behave more like L1ers during sentence processing.
Relevant to this debate are studies that have examined how L1ers and L2ers resolve ambiguous relative clauses (RCs), using offline and online tasks with sentences such as (1) (e.g., Carreiras & Clifton, Reference Carreiras and Clifton1999; Cuetos & Mitchell, Reference Cuetos and Mitchell1988; Dussias, Reference Dussias2003; Felser, Roberts, Marinis, & Gross, Reference Felser, Roberts, Marinis and Gross2003; Maia, Fernándex, & Lourenço-Gomes, 2007; Pan, Schimke, & Felser, Reference Pan, Schimke and Felser2015; Rothman, Reference Rothman2010; Scheepers et al., Reference Scheepers, Sturt, Martin, Myachykov, Teevan and Viskupova2011).
(1a) The brother of the man who bought himself some books lived here.
(1b) We knew the brother of the man who bought himself some books.
In (1) the RC is embedded to modify a complex noun phrase (NP; “the brother of the man”), which either serves as the syntactic subject (1a) or object (1b) of the sentence. In both sentences, the RC (“who bought himself …”) is ambiguous, as it can be interpreted as referring back to either the local NP “the man” (low attachment) or the nonlocal NP “the brother” (high attachment). English readers tend to prefer low attachment (e.g., Cuetos & Mitchell, Reference Cuetos and Mitchell1988; Gibson, Pearlmutter, Canseco-González, & Hickok, Reference Gibson, Pearlmutter, Canseco-González and Hickok1996). However, low attachment is not a universal tendency and attachment preferences vary across languages (e.g., Cuetos & Mitchell, Reference Cuetos and Mitchell1988; Hemforth et al., Reference Hemforth, Fernandez, Clifton, Frazier, Konieczny and Walter2015; Zagar, Pynte, & Rativeau Reference Zagar, Pynte and Rativeau1997). In addition, whether L1 and L2 readers show similar attachment preferences has been contested, especially in the case where the L1 and L2 display distinct attachment preferences. While some studies suggest L2ers do not show any clear attachment preferences (e.g., Felser, Roberts, et al., Reference Felser, Roberts, Marinis and Gross2003; Omaki, Reference Omaki2005), others have argued that L2ers can behave similarly to L1ers, even when their L1 displays an opposite tendency and especially if individual differences in L2 processing are considered (e.g., Dekydtspotter, Donaldson, Edmondam Fultz, & Petrush, Reference Dekydtspotter, Donaldson, Edmonds, Fultz and Petrush2008; Hopp, Reference Hopp2014).
Linguistic factors also influence attachment preferences (e.g., Desmet, Brysbaert, & de Baecke, Reference Desmet, Brysbaert and de Baecke2002; Desmet, de Baecke, Drieghe, Brysbaert, & Vonk, Reference Desmet, de Baecke, Drieghe, Brysbaert and Vonk2006; Fodor, Reference Fodor2002). Most important for present purposes, some L1 studies suggest that the syntactic position of the constituent that the RC modifies influences attachment preferences of sentences such as (1) (e.g., Hemforth et al., Reference Hemforth, Fernandez, Clifton, Frazier, Konieczny and Walter2015; Hemforth, Konieczny, Seelig, & Walter, Reference Hemforth, Konieczny, Seelig and Walter2000). Whether L2ers are sensitive to such subtle differences is, however, yet to be systematically explored.
Against the above background, we conducted a study on RC attachment in L1and L2 English speakers, testing the syntactic position of the RC. To tease apart different accounts of L1 and L2 processing, we aimed to test the extent to which L2ers can process and interpret RCs as in (1) in a nativelike way. To examine whether individual differences influence how nativelike L2 processing can become in this domain (Hopp, Reference Hopp2014), we also investigated how individual differences in working memory, lexical processing, and for L2ers proficiency, influence L1 and L2 RC resolution offline and during processing.
Relative clauses in L1 processing
A large literature has contested how parsing preferences influence the processing of RCs (e.g., Cuetos & Mitchell, Reference Cuetos and Mitchell1988, and much subsequent literature), and two competing principles are believed to influence low versus high attachment. Late closure (Frazier, Reference Frazier1979) or recency (Gibson et al., Reference Gibson, Pearlmutter, Canseco-González and Hickok1996) predicts that new material is attached to the most recently processed constituent. In contrast, predicate proximity (Gibson et al., Reference Gibson, Pearlmutter, Canseco-González and Hickok1996) holds that incoming material is preferably attached as close as possible to the head of a predicate. Therefore, readers who follow late closure or recency favor low attachment of the RC to the local NP. Alternatively, readers who are guided by predicate proximity prefer high attachment to the nonlocal NP. As mentioned above, English L1ers generally have a low attachment preference for ambiguous RCs as in (1) in offline tasks (e.g., Cuetos & Mitchell, Reference Cuetos and Mitchell1988). In tasks that measure online processing, researchers have manipulated agreement features to force either high or low attachment, as in (2a) and (2b), respectively. These studies have typically shown shorter reading times at the disambiguating word (“was/were”) for RCs that attach low than those that attach high in English (e.g., Felser, Roberts, et al., Reference Felser, Roberts, Marinis and Gross2003; Hopp, Reference Hopp2014; Omaki, Reference Omaki2005). However, the low attachment preference of English is not universal, and a high attachment preference has been attested in offline and online tasks in L1 studies of various other languages (e.g., Bidaoui, Foote, & Abrunasser, Reference Bidaoui, Foote and Abunasser2016; Brysbaert & Mitchell, Reference Brysbaert and Mitchell1996; Carreiras, Salillas, & Barber, Reference Carreiras, Salillas and Barber2004; Chernova & Chernigovskaya, Reference Chernova and Chernigovskaya2015; de Vincenzi & Job, Reference de Vincenzi and Job1993; Maia, Costa, Fernández, & Lourenço-Gomes, Reference Maia, Costa, Fernández and Lourenço-Gomes2004; Papadopoulou & Clahsen, Reference Papadopoulou and Clahsen2003).
(2a) The man blamed the brothers of the boy who were smiling all the time.
(2b) The man blamed the brothers of the boy who was smiling all the time.
Determining the robustness of the low attachment preference in L1 English is complicated by studies testing three different types of RCs together. For example, van Gompel, Pickering, Pearson, and Liversedge (Reference Van Gompel, Pickering, Pearson and Liversedge2005) compared reading times for sentences that force high attachment, as in (3a), low attachment, as in (3b), and a globally ambiguous condition, as in (3c).
(3a) The governor of the province that will be retiring after the troubles is very rich.
(3b) The province of the governor that will be retiring after the troubles is very rich.
(3c) The bodyguard of the governor that will be retiring after the troubles is very rich.
Van Gompel et al.’s (Reference Van Gompel, Pickering, Pearson and Liversedge2005) results suggested that, instead of showing a low attachment reading time advantage, the English L1ers they tested demonstrated an “ambiguity advantage,” with shorter reading times for ambiguous sentences such as (3c) than sentences where the RC was forced to attach either high, as in (3a), or low, as in (3b). Furthermore, the forced low attachment sentences were not significantly different from the high attachment ones in terms of reading times. These findings were interpreted as supporting an “unrestricted race model” of ambiguity resolution (Traxler, Pickering, & Clifton Reference Traxler, Pickering and Clifton1998; van Gompel, Puckering, & Traxler, Reference Van Gompel, Pickering, Traxler and Kennedy2000). The faster reading times for (3c) were taken to indicate that readers variably attached the RC either high or low across trials. Example (3c) is thus easiest because whichever attachment was initially computed at “that” will turn out to be plausible once the verb “retiring” is encountered. For both (3a) and (3b), whichever attachment is initially computed at “that” will be incorrect 50% of the time at the verb, leading to (3a) and (3b) having equally longer reading times compared to (3c). Therefore, these results suggest that L1ers of English may not have as strong a low attachment preference as claimed, variably attaching instead to either available site. The fact that the ambiguous condition had faster reading times compared to the disambiguated conditions was also taken as evidence against the idea that the two possible interpretations in the ambiguous condition competed for activation in parallel as otherwise, van Gompel et al. (Reference Van Gompel, Pickering, Pearson and Liversedge2005) reasoned, the ambiguous condition should have had longer reading times due to competition.
A number of studies have examined how various linguistic factors influence attachment preferences, including whether attachment choices in L1ers are modulated by whether the complex NP the RC modifies is in subject position as in (1a) or object position as in (1b) (e.g., Hemforth et al., Reference Hemforth, Fernandez, Clifton, Frazier, Konieczny and Walter2015; Kim & Christianson, Reference Kim and Christianson2017). Hemforth et al. (Reference Hemforth, Fernandez, Clifton, Frazier, Konieczny and Walter2015) found a stronger high attachment preference for NPs in object position in German and Spanish. In contrast, the syntactic position did not influence attachment preferences in English and French, with English showing a general low attachment preference. However, this study tested offline preferences only, and did not test online processing.
Researchers have also examined how participant-level individual differences influence attachment resolution. This includes work examining the role of working memory, as measured by reading span tasks, although results have been mixed (e.g., Kim & Christianson, Reference Kim and Christianson2013, Reference Kim and Christianson2017; Payne et al., 2014; Swets, Desmet, Hambrick, & Ferreira, Reference Swets, Desmet, Hambrick and Ferreira2007). Some studies reported that the low attachment preference in English increases as a function of higher reading span scores in either offline (Kim & Christianson, Reference Kim and Christianson2013; Omaki, Reference Omaki2005; Swets et al., Reference Swets, Desmet, Hambrick and Ferreira2007) or online measures (Kim & Christianson, Reference Kim and Christianson2013; Payne et al., Reference Payne, Grison, Gao, Christianson, Morrow and Stine-Morrow2014), suggesting that high-span individuals prefer attaching low more often than low-span individuals. However, results have been interpreted differently across these studies. Some researchers (e.g., Omaki, Reference Omaki2005) interpret these results from a resource limitation perspective whereas others (e.g., Kim & Christianson, Reference Kim and Christianson2013; Swets et al., Reference Swets, Desmet, Hambrick and Ferreira2007) see this as evidence for a chunking-based account in which high-span and low-span readers chunk the RC differently, leading to different NPs being more salient.
Other studies observed the reverse pattern online (Felser, Marinis, & Clahsen, Reference Felser, Marinis and Clahsen2003; Traxler, Reference Traxler2007) or no such effects offline (Felser, Marinis, et al., Reference Felser, Marinis and Clahsen2003). For example, Traxler (Reference Traxler2007) found that high-span individuals preferred high attachment while low-span readers preferred low attachment in an eye-tracking study. Traxler claimed that high-span individuals are more sensitive to discourse-salience and are drawn to the head NP rather than the subordinate NP, while low-span individuals may simply rely on linear distance.
Finally, Kim and Christianson (Reference Kim and Christianson2017) and Payne et al. (Reference Payne, Grison, Gao, Christianson, Morrow and Stine-Morrow2014) found that L1 readers with higher reading spans have greater difficulty processing globally ambiguous RCs than readers with lower spans in an online self-paced reading task. Kim and Christianson (Reference Kim and Christianson2017) interpreted this as indicating that high-span readers can hold the two potential interpretations in mind at the same time, which leads to competition between high and low attachment that is not found in lower span readers.
Relative clauses in L2 processing
The question of whether L2 learners show the same parsing preferences as L1 speakers has been widely examined. Some L2 studies found non-nativelike attachment preferences in L2ers (e.g., Dinçtopal-Deniz, Reference Dinçtopal-Deniz2010; Felser, Roberts, et al., Reference Felser, Roberts, Marinis and Gross2003; Fernández, Reference Fernández2003; Omaki, Reference Omaki2005; Papadopoulou & Clahsen, Reference Papadopoulou and Clahsen2003). For example, Felser, Roberts, et al. (Reference Felser, Roberts, Marinis and Gross2003) tested sentences such as (2) in an offline task and an online self-paced reading task. They found that in both measures, the L2ers did not exhibit any structural preferences. These findings led to the conclusion that L2 processing is different from L1 processing when processing is guided by structural information.
In contrast, other studies have lent support to the claim that L2 parsing is guided by structure-based information in either offline or online tasks, or both (e.g., Bidaoui et al., Reference Bidaoui, Foote and Abunasser2016; Hopp, Reference Hopp2014; Witzel, Witzel, & Nicol Reference Witzel, Witzel and Nicol2012). For example, Hopp (Reference Hopp2014) investigated online attachment preferences of advanced German speakers of L2 English using sentences such as (2) during eye tracking and found that the L2ers preferred to attach low, which was in line with the L1 results.
Less is known about how RC position modulates L2er’s attachment choices, and we are aware of only one study that has examined this issue. Kim and Christianson (Reference Kim and Christianson2017) conducted a study with Korean learners of English using sentences such as (1a) and (1b) and found the L2er’s offline attachment preferences were not influenced by RC position. Syntactic position also was not found to influence online processing in self-paced reading. However, Kim and Christianson tested globally ambiguous sentences only, and did not test sentences disambiguated to high or low attachment.
Individual differences have also been examined in L2 attachment resolution. For example, Dekydtspotter et al. (Reference Dekydtspotter, Donaldson, Edmonds, Fultz and Petrush2008) reported more nativelike attachment preferences as proficiency increased in an online study of L2 French. Hopp (Reference Hopp2014) investigated the role of working memory, as measured by a reading span task, and lexical efficiency, tested using a lexical decision task, in both offline and online attachment resolution. Offline, increased reading span scores correlated with an increased low attachment preference, replicating some previous L1 English findings (e.g., Swets et al., Reference Swets, Desmet, Hambrick and Ferreira2007). The results from an eye-tracking experiment suggested that even though the L2 group as a whole did not show any clear attachment preferences for sentences such as (4), where the ambiguity is not resolved immediately, a low attachment preference emerged when individual differences in lexical automaticity were considered, with the L2 individuals with high lexical automaticity preferring low attachment. Reading span scores, however, were not significantly correlated with online processing.
(4) The doctor examined the mother of the boy who had badly injured herself with the knife.
Finally, Kim and Christianson (Reference Kim and Christianson2017) tested individual differences in English RCs during self-paced reading in Korean learners of English. They found that high-span L2ers had longer reading times for sentences containing globally ambiguous RCs relative to those with low-span scores. As similar patterns were observed when these L2ers processed their L1, Korean, Kim and Christianson concluded that high-span readers are more likely to consider both interpretations of ambiguous RCs in parallel than low-span readers, in both their L1 and their L2.
The present study
The mixed findings in previous L2 studies suggest that L2 attachment resolution is influenced by a wide variety of factors. However, the role that the syntactic position of the RC may play in influencing L2 attachment resolution has not been systematically examined. Furthermore, while existing studies have examined whether or not L1ers consider different potential attachment choices in parallel (e.g., Traxler et al., Reference Traxler, Pickering and Clifton1998), the extent to which L2 comprehension may involve parallel competition between multiple possible analyses has not been examined extensively. Although Kim and Christianson (Reference Kim and Christianson2017) examined this issue in globally ambiguous RCs, to our knowledge, no existing published study has tested this issue by directly comparing the processing of ambiguous RCs to those disambiguated low and high.
As such, we employed a similar design to van Gompel et al.’s (Reference Van Gompel, Pickering, Pearson and Liversedge2005) L1 study. We tested RCs in subject and object position, as in (5) and (6), respectively. We tested globally ambiguous sentences, as in (5a) and (6a), and compared them to sentences that forced low attachment, as in (5b) and (6b), and sentences that forced high attachment, as in (5c) and (6c). Given that some previous L2 studies have reported no differences between high and low attachment conditions during processing (e.g., Felser, Roberts, et al., Reference Felser, Roberts, Marinis and Gross2003; Papadopoulou & Clahsen, Reference Papadopoulou and Clahsen2003), our approach of including a globally ambiguous condition provides an important control for comparing low and high attachment sentences.
(5a) Subject-modifying RC, ambiguous
The brother of the man who accidentally hurt himself yesterday afternoon lived in town.
(5b) Subject-modifying RC, low attachment
The sister of the man who accidentally hurt himself yesterday afternoon lived in town.
(5c) Subject-modifying RC, high attachment
The brother of the woman who accidentally hurt himself yesterday afternoon lived in town.
(6a) Object-modifying RC, ambiguous
We saw the brother of the man who accidentally hurt himself yesterday afternoon.
(6b) Object-modifying RC, low attachment
We saw the sister of the man who accidentally hurt himself yesterday afternoon.
(6c) Object-modifying RC, high attachment
We saw the brother of the woman who accidentally hurt himself yesterday afternoon.
… Luckily it wasn’t serious in the end.
If L1ers demonstrate a low attachment preference, as predicted by the garden path model (Frazier, Reference Frazier and Coltheart1987), reading times should be longer in (5c) and (6c), where low attachment is not possible, compared to conditions (5a), (5b), (6a) and (6b), where it is. In contrast, if L1ers randomly attach either low or high, as predicted by the unrestricted race model (e.g., van Gompel et al., Reference Van Gompel, Pickering, Traxler and Kennedy2000), reading times should be longer in disambiguating conditions (5b), (5c), (6b) and (6c) compared to ambiguous (5a) and (6a). Such findings would support the “ambiguity advantage”. If L1ers consider both low and high attachment in parallel, longer reading times should be expected in (5a) and (6a) than in (5b), (5c), (6b), and (6c), due to the competition between the two possible interpretations (e.g., MacDonald, Reference MacDonald1994; Tabor & Tanenhaus, Reference Tabor and Tanenhaus1999).
If L1 and L2 processing are qualitatively similar, the L2ers should behave like the L1ers. On the contrary, if they are different, L2ers should show different reading time patterns to the L1ers. For example, if L2ers do not show any clear preferences between low and high attachment (e.g., Felser, Roberts, et al., Reference Felser, Roberts, Marinis and Gross2003), then (5b) and (5c) and (6b) and (6c) should not differ. If this effect results from L2ers exhibiting variable attachment, then (5b), (5c), (6b), and (6c) should have longer reading times than ambiguous (5a) and (6a). In contrast, if L2ers do not clearly resolve the RC at all during online processing, they may show no significant differences between any conditions.
In addition, our study addresses another important gap in the literature by examining individual differences in this domain. To our knowledge, all other existing studies examining individual differences have tested either L1 speakers or L2 speakers but not both within the same study. If L1 and L2 processing are similar, we would expect that individual differences should impact L1 and L2 processing similarly. As such, we examined how individual differences in reading span and lexical automaticity affect both offline and online ambiguity resolution in L1ers and L2ers. Based on prior findings, we predicted both L1 and L2 individuals with higher reading spans should prefer low attachment more than those with low-span scores for globally ambiguous sentences in offline comprehension (e.g., Hopp, Reference Hopp2014; Swets et al., Reference Swets, Desmet, Hambrick and Ferreira2007). For online processing, we expected L2ers with higher levels of lexical automaticity to behave more nativelike, and should show a stronger low attachment preference (Hopp, Reference Hopp2014). If L1 and L2 processing are qualitatively similar, lexical automaticity may influence L1 and L2 processing in a similar way. Finally, we also expected L2ers with higher proficiency to exhibit a more nativelike pattern during attachment resolution (Dekydtspotter et al., Reference Dekydtspotter, Donaldson, Edmonds, Fultz and Petrush2008).
Method
Participants
The experiment was conducted with 66 English L1 speakers and 66 English L2 speakers with a first language that is reported to have a high attachment preference. This included Spanish, Italian, German, Dutch, French, Russian, Portuguese, Greek, and Arabic. All participants were recruited from the University of Reading and surrounding areas. L1 participants were university students who participated in the study for course credit or a small payment. The L2 speakers were either students or were working in the local community at the time of testing. Their English proficiency was measured by a short version of the Oxford Placement Test. Their proficiency scores ranged from 30 to 60 out of 60 (mean = 48, SD = 0.93), representing intermediate to advanced level. All participants had normal or corrected-to-normal vision.
Materials
We combined an offline judgement and an online reading task to test participant’s attachment preferences. The offline task consisted of 20 experimental items as in (7) and 40 fillers, which were pseudo-randomized in a Latin-square design. We tested participants’ offline attachment preferences for ambiguous RCs such as (7a) and (7b) in cases where the RC is in subject or object position.
(7a) Subject-modifying RC
The brother of the man who often bought himself some books got married yesterday.
(7b) Object-modifying RC
We met the brother of the man who often bought himself some books.
Question: Who bought himself some books?
Answer options: The brother/The man
Participants only saw one condition of each pair and, therefore, read 10 sentences such as (7a) and 10 sentences such as (7b). To indicate their attachment preferences, participants needed to answer comprehension questions such as “Who bought himself some books?” by choosing one of the two individuals shown in those sentences (i.e., either “the brother” or “the man”). The order of the options was counterbalanced. The choice of high attachment was coded as value 0 and low attachment was coded as 1. As such, a value toward 1 indicates a low attachment preference.
In the online reading task, we monitored participant’s eye movements as they read a series of texts. The materials for this task consisted of 36 experimental items such as (5) and (6) and 80 fillers, randomized in a Latin-square design. The experimental items contained a critical first sentence and a wrap-up sentence. The experimental items manipulated the position of the RC such that the RC was either in subject position (5a) to (5c) or object position (6a) to (6c). Half of the items contained a masculine reflexive (“himself”) and half a feminine reflexive (“herself”). The temporarily ambiguous RCs were disambiguated at the reflexive via gender match between the reflexive and the local or nonlocal NP. Examples (5a) and (6a) are globally ambiguous as the reflexive matches the gender of both NPs. Examples (5b) and (6b) are forced to attach low as the reflexive only matches the gender of the local NP whereas (5c) and (6c) are forced to attach high due to the gender match between the reflexive and the nonlocal NP. A full list of experimental materials for the offline and online tasks can be found in the online-only Supplementary materials.
We ran two additional tasks with both the L1 and L2 participants to investigate potential individual differences. To tap into working memory, a reading span task adapted from Daneman and Carpenter (Reference Daneman and Carpenter1980) was administered to both groups. The participants read aloud sets of sentences presented one by one on a computer screen, as in (8) and (9). Half the sentences were grammatical and half ungrammatical. After each sentence, participants judged whether it was grammatical or ungrammatical by pressing “1” or “2” on the keyboard. In the meantime, they had to memorize the final word of each sentence, underlined in (8) and (9). After the last sentence of a set, “RECALL” appeared onscreen and participants had to recall the to-be-remembered words, which were recorded by the experimenter. The set size increased from two sentences to five sentences as the experiment progressed. There were three sets at each set size, and participants completed all sets. The reading span score was calculated by dividing the total number of correctly recalled words by the total number of words that needed to be recalled.
(8) The young boy listened to music in his bedroom for hours. (Grammatical)
(9) *The old man picked up the phone his to spoke and daughter. (Ungrammatical)
A second individual differences task measured levels of lexical automaticity, using a lexical decision task adapted from Hopp (Reference Hopp2014). There were 80 words in total, half of which were real English words and the other half were nonwords following English phonotactics rules. The order in which the words were presented was randomized. Participants needed to decide as quickly as possible whether the word they saw was a real English word or not. They were instructed to rest two fingers from their preferred hand on the “1” and “2” keys, pressing “1” for real English words and “2” for nonwords. Reaction times and accuracy were recorded. Following Hopp (Reference Hopp2014), lexical automaticity was calculated by dividing the standard deviation of the reaction times to the real English words judged correctly by their average reaction times. For the L2 learners, a vocabulary screening task was administered at the end of the second session to test if they were familiar with the meaning (and gender) of the critical vocabulary (i.e., the NPs in the RCs).
Procedure
The study was conducted in two sessions at least 3 days apart. In the first session, participants completed the background questionnaire, which provided information on language experience. This was followed by the main reading experiment where eye movements were monitored by an SR Research Eyelink 1000 eye tracker. Although viewing was binocular, the eye-movement record was recorded for the right eye only. The experiment began with a calibration procedure on a 9-point grid, and calibration was adjusted as needed between trials. The stimuli were presented onscreen in black letters. Before each sentence, a fixation marker appeared onscreen above the first word to be displayed. Upon fixating the marker, the sentence appeared. Participants were told to read as naturally as possible and to make sure they understood the sentences. All sentences were followed by a yes/no comprehension question that was answered by a push-button response. Comprehension questions did not probe attachment of the RC in the critical sentences. Participants familiarized themselves with the procedure by first completing some practice trials before the main experiment. In the main experiment, experimental and filler items were pseudo-randomized in a Latin-square design across six presentation lists that were completed by the same number of participants.
In the second session, participants first completed the reading span task and then the lexical decision task. Following that, they completed the offline attachment preference task. In addition, L2 speakers completed the proficiency test.
Data analysis
For the eye-tracking data, reading times were calculated at two regions of text. The reflexive region consisted of the critical reflexive, while the spillover region contained the rest of the clause, as exemplified in (5) and (6) using underlining. We calculated three reading time measures at each region. First pass times summed the duration of fixations in a region entered from the left up until it was exited for the first time. Regression path times summed the duration of fixations starting when a region was first entered and up until but not including the first fixation in a region to the right. Total reading times refer to the duration of all fixations in a region regardless of when they occurred.
Trials in which a region was not fixated were treated as missing data. Fixations less than 80 ms were combined with any neighboring fixations if they were within one character of each other. All other fixations less than 80 ms, as well as all those over 800 ms, were removed. Due to a typographic error, the responses from one item in condition (6c) (object modifying RC, high attachment) were removed before analysis. Trials with excessive track loss were also removed, accounting for less than 1% of the data. Based on the vocabulary screening task, trials with critical vocabulary that the L2ers did not know were removed before analysis, accounting for less than 1% of the data.
Analysis was conducted using mixed-effects models (Baayen, Davidson, & Bates, Reference Baayen, Davidson and Bates2008). For the offline task, a generalized mixed model was used containing sum coded (–1/1) fixed effects of group (L1/L2), position (subject RC/object RC), and their interaction. For the eye-movement data, reading times were log-transformed to minimise skew (see Vasishth & Nicenboim, Reference Vasishth and Nicenboim2016). Mixed models included sum coded fixed effects of group (L1/L2) and position (subject RC/object RC). The three-condition ambiguity manipulation involved two treatment-coded contrasts. One contrast, low attachment (LA), compared the low attachment condition to the globally ambiguous condition, while the second contrast, high attachment (HA), compared the high attachment condition to the globally ambiguous condition. In the case of any interactions between position and the LA and/or the HA contrast, follow-up comparisons were conducted at the two levels of position. For interactions with group, additional analyses were conducted for each group separately.
All models were fit using the maximal random effects structure that converged (Barr, Reference Barr2013; Barr, Levy, Scheepers, & Tily, Reference Barr, Levy, Scheepers and Tily2013). When the maximal model failed to converge, the random correlations were removed first. If the model still failed to converge, the random effect with the least variance was iteratively removed until the model converged.
We first conducted a main analysis as above to test for between-groups effects. We then conducted a series of additional analyses with three individual differences measures (working memory, lexical automaticity, and L2 proficiency) by adding each predictor separately into the maximal model, using the same method to achieve convergence. We analyzed each individual differences measure separately to avoid issues related to multicollinearity. The three individual differences measures were included as centred, continuous predictors in each model, along with relevant interactions. The data and analysis code for our experiments is available at the Open Science Framework website (https://osf.io/tvakf/).
Results
Individual differences measures and offline results
For reading span scores, the L1 (mean = 0.71, SD = 0.107) and L2 (mean = 0.72, SD = 0.117) groups did not differ significantly (estimate = 0.001, SE = 0.002, t = 0.801, p = .423), despite the fact that the task was presented in English. L1ers did however have significantly faster lexical automaticity than L2ers (L1 mean = 0.25, SD = 0.116; L2 mean = 0.34, SD = 0.155; estimate = 0.04, SE = 0.002, t = 16.41, p < .001).
The results from the offline task are shown in Table 1. The proportions here are descriptively all above 0.70 indicating a low attachment preference. Analysis revealed a significant effect of position (estimate = 0.329, SE = 0.065, z = 4.99, p < .001), with the low attachment preference being stronger in object-modifying RCs than subject-modifying RCs in both groups. Neither the effect of group nor interaction was significant (both z < 0.18, both p > .23).
Table 1. Low attachment preferences in the offline task (standard errors in parentheses)

Eye-tracking results
Accuracy to the comprehension questions was 95% for both groups (all participants scored above 82%), indicating all participants paid attention. A summary of the reading time data and statistical analysis is shown in Tables 2 and 3, respectively. For brevity, main effects of group were found in each measure at each region, indicating slower reading times for the L2ers. We also do not discuss main effects of position, or Position × Group interactions, below, as these are difficult to interpret on their own, but further interactions between position, group, and LA or HA are informative about attachment preferences.
Table 2. Summary of reading times in milliseconds (standard errors in parentheses)
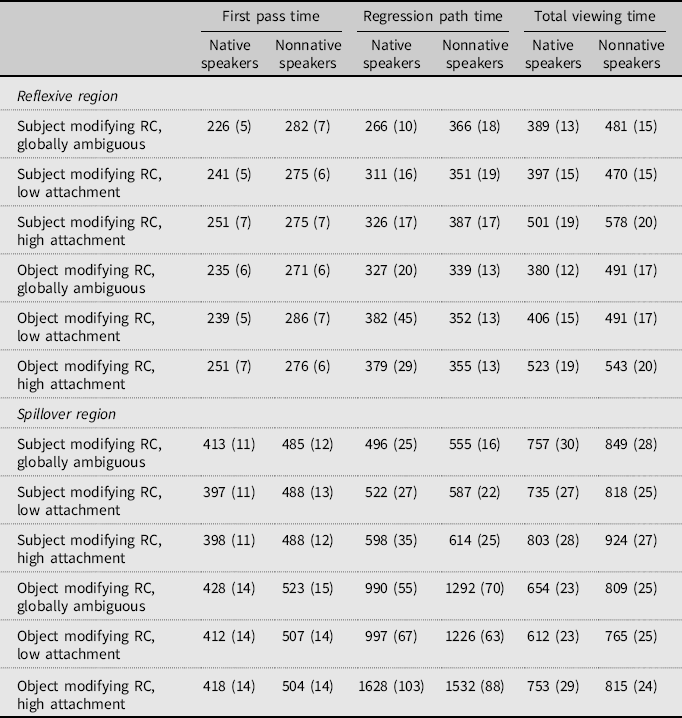
Table 3. Summary of the statistical analysis
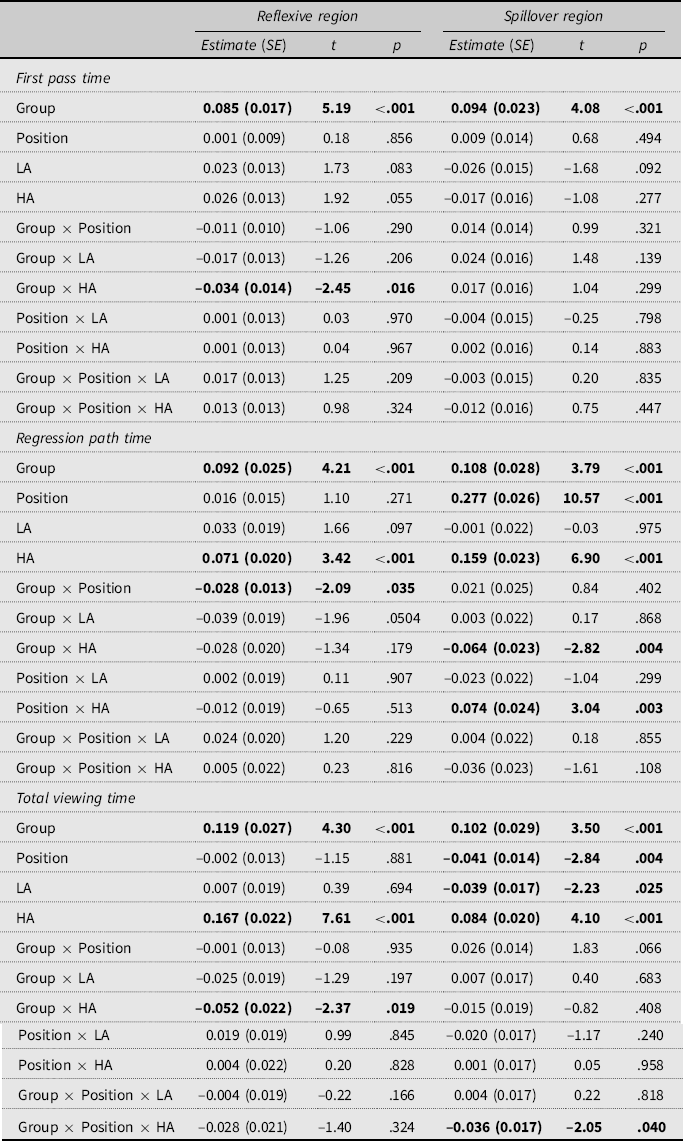
Note: LA, low attachment. HA, high attachment.
At the reflexive region, in first-pass reading times we observed a significant interaction between group and HA. Separate analyses on each group revealed that the L1 group showed significantly longer reading times for the high attachment than globally ambiguous condition (estimate = 0.061, SE = 0.021, t = 2.92, p = .005), whereas the L2 group showed no significant differences (estimate = –0.007, SE = 0.02, t = –0.35, p = .728).
Moving onto regression path time, the HA effect was significant with longer reading times for high attachment RCs relative to ambiguous RCs. There were also numerical trends for an LA effect that differed across groups, with L1ers, but not L2ers, tending to show longer reading times in LA than ambiguous conditions. However, neither the LA effect nor the Group × LA interaction was significant.
In terms of total reading times, the HA effect was statistically significant with longer reading times for high attachment RCs than ambiguous ones. There was also a significant Group × HA interaction. Follow-up analyses revealed that the HA effect was present in both groups but with a larger effect in the L1 group (estimate = 0.221, SE = 0.034, t = 6.48, p < .001) compared to the L2 group (estimate = 0.12, SE = 0.03, t = 4.27, p < .001). This is illustrated in Figure 1.
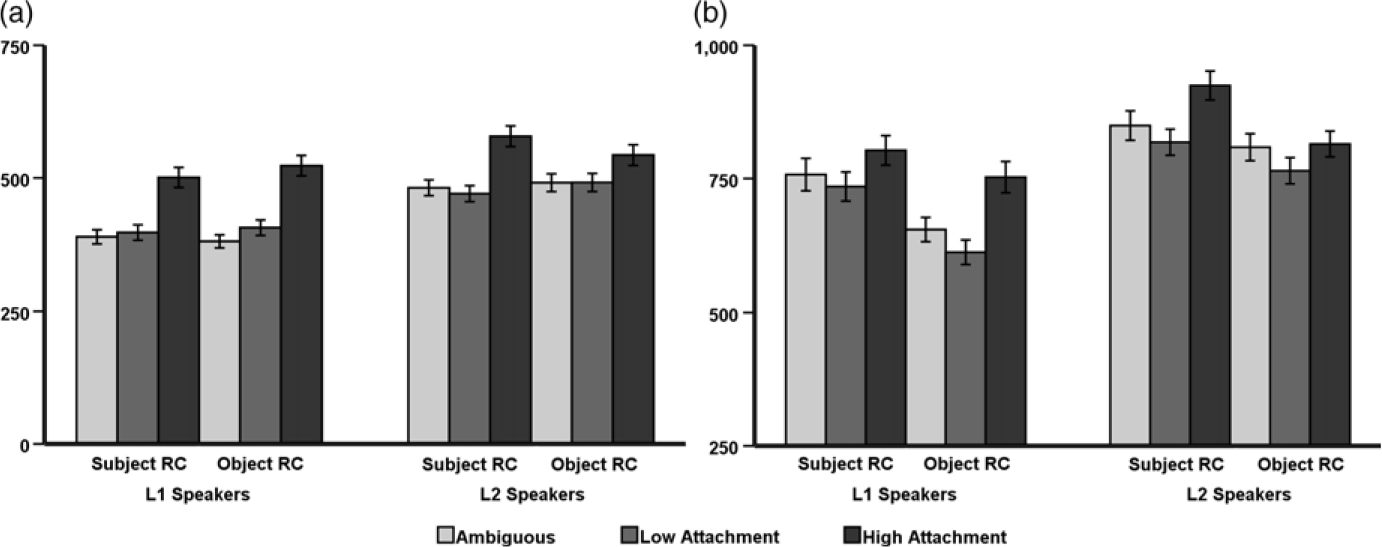
Figure 1. Total viewing times at the (a) reflexive region and (b) spillover region.
At the spillover region, no significant effects were found for first-pass reading time. For regression path time, there were three significant effects: the HA effect, the Group × HA interaction, and the Position × HA interaction. To test the HA effect that was modulated by an interaction with group, we conducted separate analyses for each group. These results found that both L1ers and L2ers had significantly longer reading times for high attachment RCs than the ambiguous baseline, but the effect was larger in the L1 group (estimate = 0.21, SE = 0.05, t = 4.63, p < .001) than the L2 group (estimate = 0.09, SE = 0.04, t = 2.18, p = .036). To examine the Position × HA interaction we tested HA effects in each position, collapsed across groups. These indicated that the HA effect was significant in both positions but with a smaller effect for subject position (estimate = 0.086, SE = 0.03, t = 3.33, p < .001) than object position (estimate = 0.231, SE = 0.045, t = 5.15, p < .001).
With respect to total reading times, a significant LA effect was observed across the groups. Here, however, shorter reading times were found for low attachment RCs compared to globally ambiguous ones. The effect of HA was also significant, with longer reading times for the high attachment condition than the baseline condition. This was, however, modulated by a significant three-way interaction between group, position, and HA, which is illustrated in Figure 1. The follow-up analyses indicated that in the subject position, The HA effect was significant in the L2 group (estimate = 0.105, SE = 0.038, t = 2.79, p = .009), while the same numerical trend was not significant in the L1 group (estimate = 0.065, SE = 0.037, t = 1.73, p = .084). In object position, the HA effect was significant in the L1 group (estimate = 0.138, SE = 0.039, t = 3.53, p < .001), but not in the L2 group (estimate = 0.04, SE = 0.033, t = 1.19, p = .234).
Individual differences analysis: Offline task
Reading span scores, lexical automaticity and proficiency were included in separate models to examine their correlation with attachment preferences. In the reading span model, the main effect of position was still significant (estimate = 0.337, SE = 0.071, z = 4.73, p < .001), as was the effect of reading span (estimate = 6.600, SE =1.553, z = 4.25, p < .001), in the absence of any further significant effects or interactions (all z < 0.12, all p > .24). The results here indicated that reading span scores were positively correlated with the low attachment preference in both groups (see Figure 2).
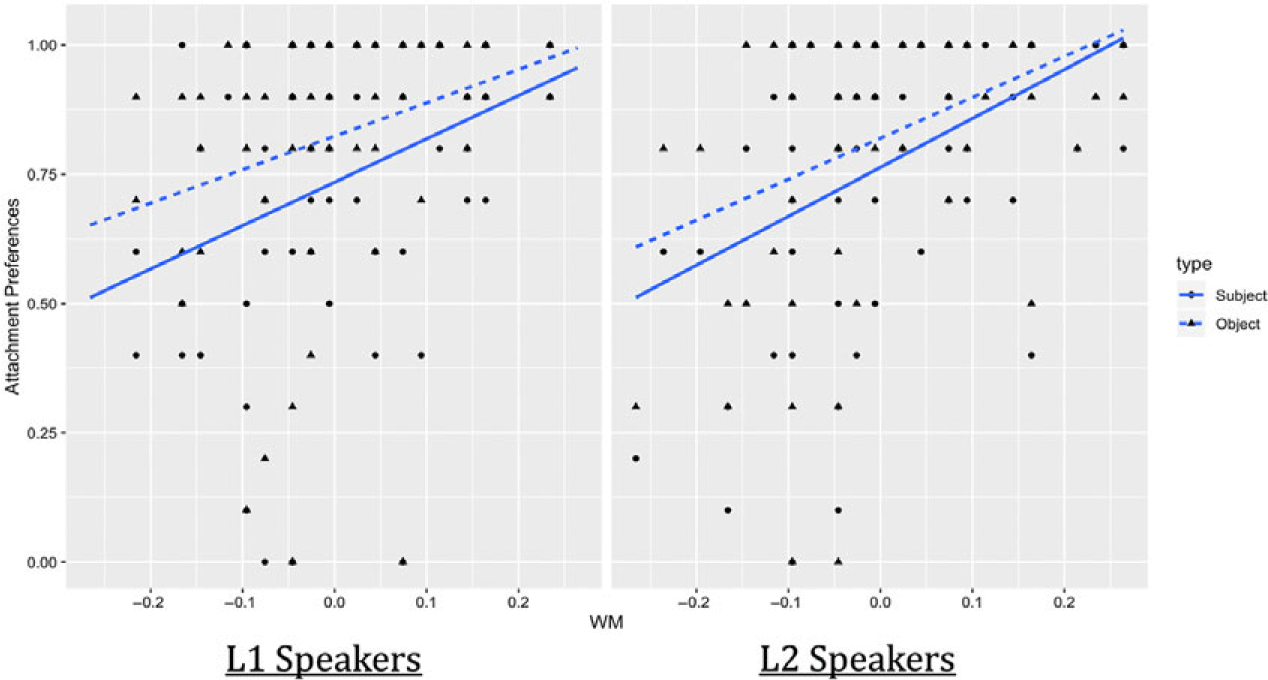
Figure 2. Interaction between reading span and attachment preferences for each position and group.
In the lexical automaticity model, apart from the significant effect of position (estimate = 0.355, SE = 0.061, z = 5.76, p < .001), there was no significant effects or interactions (all z < 0.51, all p > .14). In the proficiency model, the effect of position (estimate = 0.273, SE = 0.082, z = 3.31, p < .001) and the effect of proficiency (estimate = 0.085, SE = 0.028, z = 2.96, p < .01) were significant, but the Position × Proficiency interaction was not significant (estimate = 0.016, SE = 0.011, z = 1.54, p = .123). The proficiency model suggested language proficiency was positively correlated with the low attachment preference in the L2 group.
Individual differences analysis: Reading times
Lexical automaticity
At the reflexive region, there were numerical trends in first-pass reading time for readers with high lexical automaticity to have shorter reading times, but the main effect of lexical automaticity was not significant (estimate = 0.237, SE = 0.121, t = 1.94, p = .052). We also observed numerical trends that the HA effect in both positions found in the main analysis in the L1 group was largely driven by those with high lexical efficiency, while the L2 group did not differ. However, the interaction between group, lexical automaticity, position, and HA was not significant (estimate = –0.200, SE = 0.103, t = –1.92, p = .054).
A significant three-way interaction between lexical automaticity, position, and HA was observed for total reading times at the reflexive region (estimate = 0.314, SE = 0.153, t = 2.04, p = .041). This is illustrated in Figure 3. We can see that in subject position, individuals with high and with low levels of lexical automaticity behaved quite similarly, whereas in object position, the HA effect seemed larger for individuals with lower levels of lexical automaticity compared to the highly automatized participants.

Figure 3. Interaction between lexical automaticity and total reading times for each position across groups.
At the spillover region, we only found a numerical trend for first-pass reading times to be longer in less automatized individuals. However, the main effect of lexical automaticity was not significant (estimate = 0.308, SE = 0.175, t = 1.76, p = .079).
Reading span and proficiency
Regarding individual differences in reading span, we did not observe any statistically significant main effects or interactions of theoretical interest (all t < 1.83, all p > .07). In terms of proficiency, no effects of theoretical interest were significant (all t <1.65, all p > .101).
Discussion
This study aimed to investigate parsing strategies in L1 and L2 RC attachment, more specifically whether attachment preferences were influenced by RC position and/or individual differences. The results showed that both L1 and L2 groups demonstrated a clear low-attachment preference, modulated by syntactic position of the RC in both offline and online tasks. We also observed some interactions between individual differences and offline/online attachment preferences. The implications of our results are discussed in more detail below.
Attachment preferences and sentence processing in native and nonnative speakers
In the offline task, both L1 and L2 groups preferred low attachment over high attachment for both types of RCs. The L1 result is generally in line with the L1 literature. The L2 results, however, differ from some previous findings where L2ers from an L1 that prefers high attachment demonstrated null preferences (e.g., Felser, Roberts, et al., Reference Felser, Roberts, Marinis and Gross2003; Kim & Christianson, Reference Kim and Christianson2017; Omaki, Reference Omaki2005; Papadopoulou & Clahsen, Reference Papadopoulou and Clahsen2003) in offline measures. Even though some previous studies (e.g., Felser, Roberts, et al., Reference Felser, Roberts, Marinis and Gross2003; Omaki, Reference Omaki2005) tested L2ers in an English-speaking country, their participants might differ from those included in this study regarding the amount of exposure, the degree of, and opportunity for usage of English, or English proficiency. Regardless, our results indicated that L2ers did not significantly differ from the L1ers in their offline attachment preferences.
For online processing, both groups exhibited a low-attachment preference even though they differed during certain stages of processing. An absent LA effect and a clear HA effect were observed in both groups across several measures, especially total reading times, suggesting a low-attachment preference in L1ers and L2ers (see Figure 1). However, there is some evidence showing that the HA effect was delayed and smaller in the L2ers, even though the effect was in the same direction for both groups. During first-pass reading time, only L1ers showed the HA effect, suggesting that they preferred low attachment whereas L2ers did not show any preferences in this measure. Both groups showed the HA effect in total reading time at the reflexive region, regression path time and total reading time at the spillover region, although the effect was larger for the L1ers in some measures. We argue that this suggests slower but not qualitatively different processing for L2ers, who showed the same HA effect as L1ers, albeit delayed and numerically smaller.
The online results are generally in line with accounts that predict a low attachment preference in L1 English (e.g., Felser, Roberts, et al., Reference Felser, Roberts, Marinis and Gross2003; Hopp, Reference Hopp2014). Our data do not fully replicate the “ambiguity advantage” observed in previous studies (e.g., Traxler et al., Reference Traxler, Pickering and Clifton1998; van Gompel et al., Reference Van Gompel, Pickering, Pearson and Liversedge2005). In regression path times at the reflexive, there were numerical trends for the ambiguous condition to have shorter reading times than both disambiguated conditions, though the LA comparisons were not fully reliable here. Across the majority of measures, although longer reading times were observed for high attachment conditions, the globally ambiguous conditions did not have significantly longer reading times than the low attachment conditions. This might be partially supportive of the “ambiguity advantage” in that this pattern of results does not suggest competition in the ambiguous conditions. However, we did find some evidence of competition in one measure, namely, total viewing times at the spillover region, where the ambiguous condition had longer reading times than the low attachment condition. This might indicate an initial preference for low attachment with delayed competition between the two attachment sites at the spillover region. We do not draw any strong conclusions about the ambiguity advantage here, but note that we did not find any L1/L2 differences in this regard. Thus, our clearest finding across measures was the low-attachment preference for both L1 and L2 readers.
The L2 online results corroborate findings that L2ers can show online structural preferences (e.g., Bidaoui et al., Reference Bidaoui, Foote and Abunasser2016; Hopp, Reference Hopp2014). However, in Hopp (Reference Hopp2014), the L2 group (as a whole) only showed the low-attachment preference for sentences that are immediately disambiguated by a copula but not for sentences that are disambiguated later, as used in our study. Our study thus also indicates that L2ers can exhibit online attachment preferences in sentences with later disambiguation. Our results stand in stark contrast with other studies showing that L2ers failed to show structural preferences (e.g., Felser, Roberts, et al., Reference Felser, Roberts, Marinis and Gross2003; Omaki, Reference Omaki2005; Papadopoulou & Clahsen, Reference Papadopoulou and Clahsen2003), which could be due to methodological differences. Most L2 studies that failed to attest attachment preferences employed self-paced reading, which does not allow information from rereading and later processing stages to be captured. In addition, with self-paced reading, individuals with poorer memory might have impoverished representations of the previous text when they reach the critical region, while eye tracking allows for more naturalistic reading. Future research is required here to examine how these methodological issues may influence attachment resolution in L1 and L2 processing.
Recall that syntactic position interacted with offline attachment resolution as both groups preferred attaching low more often when the RC modified the object of the main verb compared to when it modified the subject. This suggests that the low-attachment preference was stronger for object-modifying RCs in L1 and L2ers alike. It could be the case that since the high attachment site is the subject and always first-mentioned in the subject-modifying RC, it receives more discourse salience than the low-attachment site, leading to a slightly weaker low-attachment bias in the subject-modifying RC condition. The offline findings are inconsistent with Hemforth et al. (Reference Hemforth, Fernandez, Clifton, Frazier, Konieczny and Walter2015) and Kim and Christianson (Reference Kim and Christianson2017), who did not find effects of position in English RCs. However, both these studies had smaller samples than the current study (48 and 34 participants, respectively, compared to 132 in our experiment).
The position effect was also attested during online processing. In regression path times at the spillover region, both groups showed larger HA effects in object-modifying RCs compared to subject-modifying RCs, suggesting a stronger low-attachment preference for object-modifying RCs in both groups. We propose that high attachment in object-modifying RCs was more demanding due to the attenuated prominence of the high attachment site in these sentences. This interplay of syntactic position and attachment choices across the groups suggests that discourse-level information was processed similarly in L1 and L2 readers.
Individual differences in attachment preferences
Working memory as measured by reading span interacted with offline attachment preferences in both the L1 and L2 groups. The offline results suggested that participants with high-span preferred low attachment more than those with low span, which is consistent with most previous offline studies (e.g., Kim & Christianson, Reference Kim and Christianson2013; Omaki, Reference Omaki2005; Swets et al., Reference Swets, Desmet, Hambrick and Ferreira2007; but see Felser, Marinis, et al., Reference Felser, Marinis and Clahsen2003). However, our study did not aim to tease apart different accounts of this correlation, and we cannot distinguish between whether this suggests different prosodic processing strategies (e.g., Swets et al., Reference Swets, Desmet, Hambrick and Ferreira2007) or resource limitations (e.g., Omaki, Reference Omaki2005). Important for present purposes, we did not find significant differences between L1ers and L2ers in this regard, suggesting that individual differences in reading span influence L1 and L2 processing in a similar way. We also found L2 proficiency interacted with offline attachment preferences, suggesting L2ers with higher proficiency attached low more often than those with lower proficiency. The finding on proficiency is compatible with the online finding from Dekydtspotter et al. (Reference Dekydtspotter, Donaldson, Edmonds, Fultz and Petrush2008) that participants with higher levels of proficiency showed a nativelike attachment preference.
For online processing at the reflexive region, there was a trend during first-pass times that L1ers with fast lexical access exhibited the HA effect, but not L1ers with slower lexical efficiency or L2ers. This might suggest that lexical processing efficiency influences whether readers show attachment effects in early stages of processing, and it is compatible with claims that some aspects of lexical processing need to be complete before syntactic integration begins (e.g., Hopp, Reference Hopp2016; Tily, Fedorenko, & Gibson, Reference Tily, Fedorenko and Gibson2010).
During later stages of processing, lexical automaticity modulated L1 and L2 processing to a similar extent. Both highly and less automatized L1/L2 individuals preferred low attachment. However, differences appeared with regard to the high attachment condition particularly in object-modifying RCs, where the difficulty associated with high attachment was reduced in those individuals with higher lexical automaticity (see Figure 3). As discussed above, forcing high attachment RCs in object position seemed particularly difficult to parse, indexed by the stronger low attachment preference in object position from our offline and online findings. Hence, it could be the case that individuals with faster lexical access overcame the linguistic conflict and completed reanalysis more quickly compared to individuals with slower access, when processing difficulty increased. Taken together, our results suggest that faster lexical access can facilitate attachment resolution in both L1 and L2 processing.
Our findings in terms of lexical automaticity are not entirely consistent with Hopp (Reference Hopp2014). For sentences that were not immediately disambiguated, as tested in our study, Hopp (Reference Hopp2014) found that attachment preferences only emerged for L2ers with high levels of lexical automaticity, while L2ers with low lexical automaticity did not show any significant differences between conditions. However, our results present a different pattern where the individuals with lower levels of lexical automaticity exhibited larger effects. These apparently opposing findings might be due to differences at the group level. Specifically, the L2 group as a whole in Hopp (Reference Hopp2014) did not show any attachment preferences for nonlocally disambiguated sentences, while the L2 group in our study did. It could thus be that the L2ers in Hopp (Reference Hopp2014) did not have as efficient lexical processing as those tested in our study at the group level. This would not be so odd when one considers the context of testing. Whereas Hopp’s participants were tested in a nonnative English environment (Germany), our participants were tested in native immersion (the United Kingdom).
Our online findings did not replicate our offline working memory and proficiency effects or any previously reported effects in relation to working memory or proficiency. The null effects of reading span during online processing fail to replicate some previous findings (e.g., Payne et al., Reference Payne, Grison, Gao, Christianson, Morrow and Stine-Morrow2014; Traxler, Reference Traxler2007), but they are consistent with Hopp (Reference Hopp2014), who also did not observe effects of reading span during online reading. One possibility is that the spread of reading span scores in our study was less than in Payne et al. (Reference Payne, Grison, Gao, Christianson, Morrow and Stine-Morrow2014) and Traxler (Reference Traxler2007), potentially making reading span effects more difficult to observe. Note however that our combined L1/L2 sample is larger than previous studies. Therefore, sample size may also play a role in these mixed findings. Further replications with large samples are required to tease these issues apart.
Finally, although we tested only L2ers whose L1 has previously been reported to have a high attachment preference, our L2 group did comprise speakers from different L1 backgrounds. The two largest subgroups included L1 Italian speakers (n = 16) and L1 Spanish speakers (n = 11), while smaller subgroups of below 10 participants included L1 Dutch, German, French, Portuguese, Russian, Greek, and Arabic speakers. As these groups are not large enough for inferential analysis, especially for the eye-tracking data, we only descriptively examined how each subgroup behaved in the offline task. Here, all subgroups descriptively indicated a low attachment preference by choosing low attachment more than 65% of the time in the offline task. Thus, we do not believe that a single subgroup was responsible for our findings. However, given differences in the number of participants across the subgroups and in the strength of attachment biases across languages, this may have affected our results. Hence, future research will need to examine how specific L1 backgrounds may influence L2 attachment resolution.
Conclusion
We argue that our results suggest quantitative rather than qualitative differences between L1ers and L2ers in attachment resolution. Both groups showed similar parsing preferences online, though the effects were smaller and delayed in L2ers. In addition, our results suggest that the syntactic position of the RC influences ambiguity resolution, which we argued results from differences in discourse salience between RCs in subject and object position. Of importance, this effect of discourse salience appeared to modulate L1 and L2 processing in a similar way. L1 and L2 attachment resolution also interacted with individual differences in a largely similar way across groups, with better lexical processing efficiency being related to quicker linguistic conflict resolution in both L1 and L2 processing. In sum, our results suggest similar processing strategies in ambiguity resolution are possible in L1 and L2 comprehension, and highlight the importance of considering both linguistic factors and individual differences when examining the similarities and differences between L1 and L2 sentence processing.







 Open access
Open access