


Impact Statement
Many complex problems in computational engineering can be described by parametrized differential equations while boundary conditions or material properties may not be fully known, for example, in thermal-fluid or solid mechanics systems. These ill-defined problems cannot be solved with standard numerical methods but if some sparse data are available, progress can be made by recasting them as large-scale minimization problems. Here, we review physics-informed neural networks (PINNs) and physics-informed graph networks (PIGNs) that integrate seamlessly data and mathematical physics models, even in partially understood or uncertain contexts. Using automatic differentiation in PINNs and external graph calculus in PIGNs, the physical laws are enforced by penalizing the residuals on random points in the space–time domain for PINNs and on the nodes of a graph in PIGNs.
1. Introduction
Physics-informed machine learning (PIML) involves the use of neural networks, graph networks or Gaussian process regression to simulate physical and biomedical systems, using a combination of mathematical models and multimodality data (Raissi et al., Reference Raissi, Perdikaris and Karniadakis2018, Reference Raissi, Perdikaris and Karniadakis2019; Karniadakis et al., Reference Karniadakis, Kevrekidis, Lu, Perdikaris, Wang and Yang2021; Gao et al., Reference Gao, Zahr and Wang2022).
Physics-informed neural networks (PINNs) (Raissi et al., Reference Raissi, Perdikaris and Karniadakis2019) can solve a partial differential equation (PDE) by directly incorporating the PDE into the loss function of the neural network (NN) and employing automatic differentiation to represent all the differential operators. Hence, PINNs do not require any mesh generation, thus avoiding a tremendous cost that has hindered progress in computational engineering, especially for moving and deformable domains. They can easily be applied to any known PDE, but also to different types of differential equations, including fractional PDEs (Pang et al., Reference Pang, Lu and Karniadakis2019), integro-differential equations (Lu et al., Reference Lu, Meng, Mao and Karniadakis2021a), or stochastic PDEs (Zhang et al., Reference Zhang, Lu, Guo and Karniadakis2019, Reference Zhang, Guo and Karniadakis2020a). PINNs are very simple to implement, and even the most elaborate codes contain less than 1,000 lines. Unlike traditional numerical approaches, the same exact code is able to treat both forward and inverse problems. Hence, different simulation scenarios, as shown in Figure 1, can be executed without any extra effort, other than preparing the input data. These advantages have been demonstrated across different fields, for example, in fluid mechanics (Mao et al., Reference Mao, Jagtap and Karniadakis2020; Raissi et al., Reference Raissi, Yazdani and Karniadakis2020), optics (Chen et al., Reference Chen, Lu, Karniadakis and Dal Negro2020; Lu et al., Reference Lu, Pestourie, Yao, Wang, Verdugo and Johnson2021b), systems biology (Yazdani et al., Reference Yazdani, Lu, Raissi and Karniadakis2020), geophysics (Waheed et al., Reference Waheed, Haghighat, Alkhalifah, Song and Hao2020), nondestructive evaluation of materials (Shukla et al., Reference Shukla, Di Leoni, Blackshire, Sparkman and Karniadakis2020, Reference Shukla, Jagtap, Blackshire, Sparkman and Karniadakis2021a), and biomedicine (Sahli Costabal et al., Reference Sahli Costabal, Yang, Perdikaris, Hurtado and Kuhl2020; Goswami et al., Reference Goswami, Sharma, Pruthi and Gupta2021; Yin et al., Reference Yin, Zheng, Humphrey and Karniadakis2021).
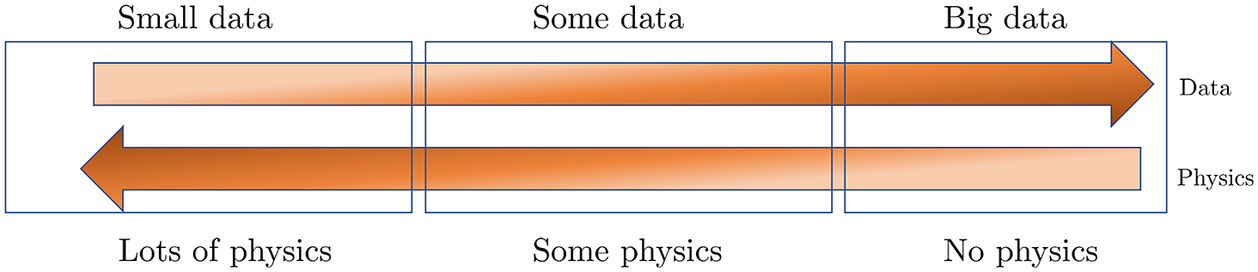
Figure 1. Physics versus Data. Simulating and forecasting the response of real-world problems requires both data and physical models. In many applications throughout physics, engineering and biomedicine we have some data and we can describe some but not all physical process. Physics-informed machine learning enables seamless integration of data and models. On the left, we have the classical paradigm of well posed problems. On the right, we depict black-box type system identification. Most real-life applications fall in the middle of this diagram.
Graph neural networks (GNNs) and specifically physics-informed graph networks (PIGNs) have emerged as an alternative method, as they can be particularly effective for composite physical systems where a state evolves as a function of its neighboring states, forming dynamic relational graphs instead of grids. In contrast to PINNs, these models apply message-passing between a small number of moving and interacting objects, which deviate from PDEs that are strictly differential functions. Another application of GNNs and PIGNs is the discovery of PDEs from sparse data, see for example, Iakovlev et al. (Reference Iakovlev, Heinonen and Lähdesmäki2020). The authors combined message passing neural networks with the method of lines and neural Ordinary Differential Equation (ODE) (Chen et al., Reference Chen, Rubanova, Bettencourt, Duvenaud, Bengio, Wallach, Larochelle, Grauman, Cesa-Bianchi and Garnett2018) and obtained good results for advection–diffusion, heat equation and Burgers equation in one dimension. Similar work was done in Kumar and Chakraborty (Reference Kumar and Chakraborty2021), where the authors designed a PIGN called GrADE for learning the system dynamics from data, for example, the one-dimensional and two-dimensional Burgers equations. GrADE combines a GNN that can handle unstructured data with neural ODE to represent the temporal domain. In addition, the authors used the graph attention (GAT) for embedding of nodes during aggregation. A somewhat different approach was proposed in Gao et al. (Reference Gao, Zahr and Wang2022), where the authors introduced the graph convolution operation into physics-informed learning and combined it with finite elements in order to handle unstructured meshes for fluid mechanics and solid mechanics applications. GNNs have also been proposed for solving ordinary differential equations (GNODE) (Poli et al., Reference Poli, Massaroli, Park, Yamashita, Asama and Park2019) in modeling continuous-time signals on graphs. This work was extended in Seo and Liu (Reference Seo and Liu2019) for PDEs and for applications to climate, where a recurrent architecture was proposed to incorporate physics on graph networks, see Figure 2. We note that in this architecture the physics is not directly applied to the input observations but rather to the latent representations.

Figure 2. Recurrent architecture to incorporate physics in graph networks. The blue blocks contain learnable parameters while the orange blocks are objective functions. The middle core block can be repeated as many times as the required time steps (T). Schematic adapted from Seo and Liu (Reference Seo and Liu2019).
One of the major limitations of the original PINN algorithm is the large computational cost associated with the training of the neural networks, especially for forward multiscale problems. To reduce the computational cost, Jagtap et al. (Reference Jagtap, Kharazmi and Karniadakis2020) introduced a domain decomposition-based PINN for conservation laws, namely conservative PINN (cPINN), where continuity of the states as well as their fluxes across subdomain interfaces is enforced to connect the subdomains together. In subsequent work, Jagtap and Karniadakis (Reference Jagtap and Karniadakis2020) applied domain decomposition to general PDEs using the so-called extended PINN (XPINN). Unlike cPINN, which offers space decomposition, XPINN offers both space–time domain decomposition for any irregular, nonconvex geometry thereby reducing the computational cost effectively. By exploiting the decomposition process of the cPINN/XPINN methods and its implicit mapping onto modern heterogeneous computing platforms, the training time of the network can be reduced to a great extent. Another domain decomposition method applied to the variational formulation of PINNs was proposed in Kharazmi et al. (Reference Kharazmi, Zhang and Karniadakis2021). Referred to as the hp-VPINN method, it mimics the well-known spectral element method (Karniadakis et al., Reference Karniadakis, Karniadakis and Sherwin2005), which exhibits dual h-p convergence. An effective parallel implementation of PINNs was reported in Shukla et al. (Reference Shukla, Jagtap and Karniadakis2021b). Similarly, drawing on existing parallel frameworks for standard GNNs, one can scale up PIGNs for simulating complex systems or systems.
This chapter is organized as follows. In the next section, we review the PINN formulation and the scalable extensions, and provide prototypical examples. In the subsequent section, we review popular variants of GNNs (spectral, spatial, and graph-attention) before discussing their relationship to traditional PDE discretizations and introducing PIGNs, which employ a graph exterior calculus; we also discuss scalability of GNNs.
2. Physics-Informed Neural Networks
We consider the following PDE for the solution
 $ u\left(\mathbf{x},t\right) $
parametrized by the parameters
$ u\left(\mathbf{x},t\right) $
parametrized by the parameters
 $ \lambda $
defined on a domain
$ \lambda $
defined on a domain
 $ \Omega $
:
$ \Omega $
:
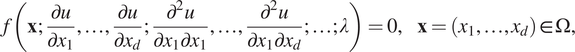 $$ f\left(\mathbf{x};\frac{\partial u}{\partial {x}_1},\dots, \frac{\partial u}{\partial {x}_d};\frac{\partial^2u}{\partial {x}_1\partial {x}_1},\dots, \frac{\partial^2u}{\partial {x}_1\partial {x}_d};\dots; \lambda \right)=0,\hskip1em \mathbf{x}=\left({x}_1,\dots, {x}_d\right)\in \Omega, $$
$$ f\left(\mathbf{x};\frac{\partial u}{\partial {x}_1},\dots, \frac{\partial u}{\partial {x}_d};\frac{\partial^2u}{\partial {x}_1\partial {x}_1},\dots, \frac{\partial^2u}{\partial {x}_1\partial {x}_d};\dots; \lambda \right)=0,\hskip1em \mathbf{x}=\left({x}_1,\dots, {x}_d\right)\in \Omega, $$
with the boundary conditions
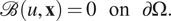 $$ \mathrm{\mathcal{B}}\left(u,\mathbf{x}\right)=0\hskip1em \mathrm{on}\hskip1em \mathrm{\partial \Omega }. $$
$$ \mathrm{\mathcal{B}}\left(u,\mathbf{x}\right)=0\hskip1em \mathrm{on}\hskip1em \mathrm{\partial \Omega }. $$
In PINNs, the initial conditions are treated similarly as the boundary conditions.
A schematic of a PINN for Equation (1) is shown in Figure 3. Specifically, in order to solve the parametrized PDE via PINNs, we construct a deep NN
 $ \hat{u}\left(\mathbf{x};\boldsymbol{\theta} \right) $
with the trainable parameters
$ \hat{u}\left(\mathbf{x};\boldsymbol{\theta} \right) $
with the trainable parameters
 $ \boldsymbol{\theta} $
. We incorporate the constraints implied by the PDE as well as the boundary and initial conditions in the loss function. To evaluate the residual of the PDE and the boundary/initial conditions, we introduce a set of random points inside the domain (
$ \boldsymbol{\theta} $
. We incorporate the constraints implied by the PDE as well as the boundary and initial conditions in the loss function. To evaluate the residual of the PDE and the boundary/initial conditions, we introduce a set of random points inside the domain (
 $ {\mathcal{T}}_f $
) and another random set of points on the boundary (
$ {\mathcal{T}}_f $
) and another random set of points on the boundary (
 $ {\mathcal{T}}_b $
). The loss function is then defined as Raissi et al. (Reference Raissi, Perdikaris and Karniadakis2019) and Lu et al. (Reference Lu, Meng, Mao and Karniadakis2021a)
$ {\mathcal{T}}_b $
). The loss function is then defined as Raissi et al. (Reference Raissi, Perdikaris and Karniadakis2019) and Lu et al. (Reference Lu, Meng, Mao and Karniadakis2021a)
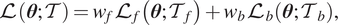 $$ \mathrm{\mathcal{L}}\left(\boldsymbol{\theta}; \mathcal{T}\right)={w}_f{\mathrm{\mathcal{L}}}_f\left(\boldsymbol{\theta}; {\mathcal{T}}_f\right)+{w}_b{\mathrm{\mathcal{L}}}_b\left(\boldsymbol{\theta}; {\mathcal{T}}_b\right), $$
$$ \mathrm{\mathcal{L}}\left(\boldsymbol{\theta}; \mathcal{T}\right)={w}_f{\mathrm{\mathcal{L}}}_f\left(\boldsymbol{\theta}; {\mathcal{T}}_f\right)+{w}_b{\mathrm{\mathcal{L}}}_b\left(\boldsymbol{\theta}; {\mathcal{T}}_b\right), $$
where
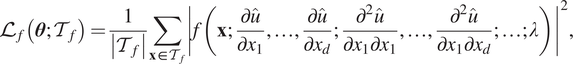 $$ {\mathrm{\mathcal{L}}}_f\left(\boldsymbol{\theta}; {\mathcal{T}}_f\right)=\frac{1}{\left|{\mathcal{T}}_f\right|}\sum \limits_{\mathbf{x}\in {\mathcal{T}}_f}{\left|f\left(\mathbf{x};\frac{\partial \hat{u}}{\partial {x}_1},\dots, \frac{\partial \hat{u}}{\partial {x}_d};\frac{\partial^2\hat{u}}{\partial {x}_1\partial {x}_1},\dots, \frac{\partial^2\hat{u}}{\partial {x}_1\partial {x}_d};\dots; \lambda \right)\right|}^2, $$
$$ {\mathrm{\mathcal{L}}}_f\left(\boldsymbol{\theta}; {\mathcal{T}}_f\right)=\frac{1}{\left|{\mathcal{T}}_f\right|}\sum \limits_{\mathbf{x}\in {\mathcal{T}}_f}{\left|f\left(\mathbf{x};\frac{\partial \hat{u}}{\partial {x}_1},\dots, \frac{\partial \hat{u}}{\partial {x}_d};\frac{\partial^2\hat{u}}{\partial {x}_1\partial {x}_1},\dots, \frac{\partial^2\hat{u}}{\partial {x}_1\partial {x}_d};\dots; \lambda \right)\right|}^2, $$
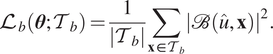 $$ {\mathrm{\mathcal{L}}}_b\left(\boldsymbol{\theta}; {\mathcal{T}}_b\right)=\frac{1}{\left|{\mathcal{T}}_b\right|}\sum \limits_{\mathbf{x}\in {\mathcal{T}}_b}{\left|\mathrm{\mathcal{B}}\left(\hat{u},\mathbf{x}\right)\right|}^2. $$
$$ {\mathrm{\mathcal{L}}}_b\left(\boldsymbol{\theta}; {\mathcal{T}}_b\right)=\frac{1}{\left|{\mathcal{T}}_b\right|}\sum \limits_{\mathbf{x}\in {\mathcal{T}}_b}{\left|\mathrm{\mathcal{B}}\left(\hat{u},\mathbf{x}\right)\right|}^2. $$
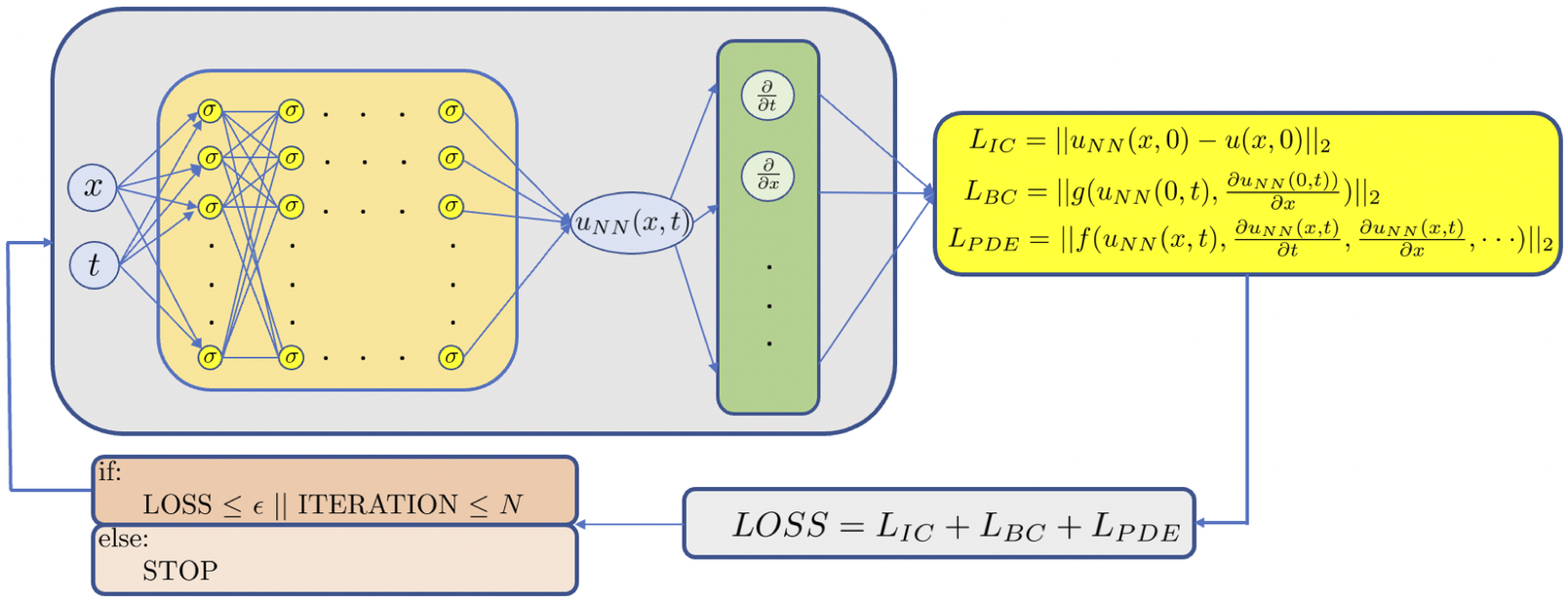
Figure 3. Schematic of PINN. The left part represents the data NN whereas the right part represents the physics-informed NN. All differential operators are obtained via automatic differentiation, hence no mesh generation is required to solve the PDE.
Here,
 $ {w}_f $
and
$ {w}_f $
and
 $ {w}_b $
are the weights, and their choice is very important, especially for multiscale problems; below we show an effective algorithm on how to learn these weights, which can be a function of space–time, directly from the data.
$ {w}_b $
are the weights, and their choice is very important, especially for multiscale problems; below we show an effective algorithm on how to learn these weights, which can be a function of space–time, directly from the data.
One main advantage of PINNs is that the same formulation can be used not only for forward problems but also for inverse PDE-based problems. If the parameter
 $ \lambda $
in Equation (1) is unknown, and instead we have some extra measurements of
$ \lambda $
in Equation (1) is unknown, and instead we have some extra measurements of
 $ u $
on the set of points
$ u $
on the set of points
 $ {\mathcal{T}}_i $
, then we add an additional data loss (Raissi et al., Reference Raissi, Perdikaris and Karniadakis2019; Lu et al., Reference Lu, Meng, Mao and Karniadakis2021a) as
$ {\mathcal{T}}_i $
, then we add an additional data loss (Raissi et al., Reference Raissi, Perdikaris and Karniadakis2019; Lu et al., Reference Lu, Meng, Mao and Karniadakis2021a) as
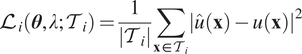 $$ {\mathrm{\mathcal{L}}}_i\left(\boldsymbol{\theta}, \lambda; {\mathcal{T}}_i\right)=\frac{1}{\left|{\mathcal{T}}_i\right|}\sum \limits_{\mathbf{x}\in {\mathcal{T}}_i}{\left|\hat{u}\left(\mathbf{x}\right)-u\left(\mathbf{x}\right)\right|}^2 $$
$$ {\mathrm{\mathcal{L}}}_i\left(\boldsymbol{\theta}, \lambda; {\mathcal{T}}_i\right)=\frac{1}{\left|{\mathcal{T}}_i\right|}\sum \limits_{\mathbf{x}\in {\mathcal{T}}_i}{\left|\hat{u}\left(\mathbf{x}\right)-u\left(\mathbf{x}\right)\right|}^2 $$
to learn the unknown parameters simultaneously with the solution
 $ u $
. We can recast the loss function as
$ u $
. We can recast the loss function as
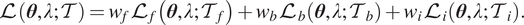 $$ \mathrm{\mathcal{L}}\left(\boldsymbol{\theta}, \lambda; \mathcal{T}\right)={w}_f{\mathrm{\mathcal{L}}}_f\left(\boldsymbol{\theta}, \lambda; {\mathcal{T}}_f\right)+{w}_b{\mathrm{\mathcal{L}}}_b\left(\boldsymbol{\theta}, \lambda; {\mathcal{T}}_b\right)+{w}_i{\mathrm{\mathcal{L}}}_i\left(\boldsymbol{\theta}, \lambda; {\mathcal{T}}_i\right). $$
$$ \mathrm{\mathcal{L}}\left(\boldsymbol{\theta}, \lambda; \mathcal{T}\right)={w}_f{\mathrm{\mathcal{L}}}_f\left(\boldsymbol{\theta}, \lambda; {\mathcal{T}}_f\right)+{w}_b{\mathrm{\mathcal{L}}}_b\left(\boldsymbol{\theta}, \lambda; {\mathcal{T}}_b\right)+{w}_i{\mathrm{\mathcal{L}}}_i\left(\boldsymbol{\theta}, \lambda; {\mathcal{T}}_i\right). $$
2.1. Self-adaptive loss weights
In some cases, it is possible to enforce the boundary conditions automatically by modifying the network architecture (Lagaris et al., Reference Lagaris, Likas and Fotiadis1998; Pang et al., Reference Pang, Lu and Karniadakis2019; Lagari et al., Reference Lagari, Tsoukalas, Safarkhani and Lagaris2020; Lu et al., Reference Lu, Pestourie, Yao, Wang, Verdugo and Johnson2021b;). A more general approach was proposed by McClenny and Braga-Neto (Reference McClenny and Braga-Neto2020), which we explain next and give a simple example of a boundary layer problem. Let us consider a boundary layer problem defined by an ODE as follows:
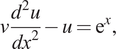 $$ \nu \frac{d^2u}{dx^2}-u={\mathrm{e}}^x, $$
$$ \nu \frac{d^2u}{dx^2}-u={\mathrm{e}}^x, $$
where
 $ x\in \left[-1,1\right] $
,
$ x\in \left[-1,1\right] $
,
 $ u\left[-1\right]=1 $
,
$ u\left[-1\right]=1 $
,
 $ u\left[1\right]=0 $
, and viscosity
$ u\left[1\right]=0 $
, and viscosity
 $ \nu ={10}^{-3} $
.
$ \nu ={10}^{-3} $
.
To compute the solution of (4), the loss function for self-adaptive PINN is defined as
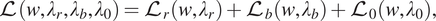 $$ \mathrm{\mathcal{L}}\left(w,{\lambda}_r,{\lambda}_b,{\lambda}_0\right)={\mathrm{\mathcal{L}}}_r\left(w,{\lambda}_r\right)+{\mathrm{\mathcal{L}}}_b\left(w,{\lambda}_b\right)+{\mathrm{\mathcal{L}}}_0\left(w,{\lambda}_0\right), $$
$$ \mathrm{\mathcal{L}}\left(w,{\lambda}_r,{\lambda}_b,{\lambda}_0\right)={\mathrm{\mathcal{L}}}_r\left(w,{\lambda}_r\right)+{\mathrm{\mathcal{L}}}_b\left(w,{\lambda}_b\right)+{\mathrm{\mathcal{L}}}_0\left(w,{\lambda}_0\right), $$
where
 $ {\lambda}_r=\left({\lambda}_r^1,\dots, {\lambda}_r^{N_r}\right),{\lambda}_b=\left({\lambda}_b^1,\dots, {\lambda}_b^{N_b}\right) $
, and
$ {\lambda}_r=\left({\lambda}_r^1,\dots, {\lambda}_r^{N_r}\right),{\lambda}_b=\left({\lambda}_b^1,\dots, {\lambda}_b^{N_b}\right) $
, and
 $ {\lambda}_n=\left({\lambda}_0^1,\dots, {\lambda}_0^{N_0}\right) $
are trainable self-adaptation weights for the initial, boundary, and collocation points, respectively, and
$ {\lambda}_n=\left({\lambda}_0^1,\dots, {\lambda}_0^{N_0}\right) $
are trainable self-adaptation weights for the initial, boundary, and collocation points, respectively, and
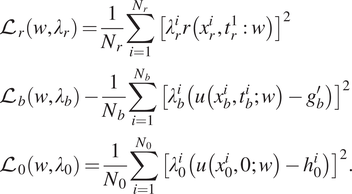 $$ {\displaystyle \begin{array}{l}{\mathrm{\mathcal{L}}}_r\left(w,{\lambda}_r\right)=\frac{1}{N_r}\sum \limits_{i=1}^{N_r}{\left[{\lambda}_r^ir\left({x}_r^i,{t}_r^1:w\right)\right]}^2\\ {}{\mathrm{\mathcal{L}}}_b\left(w,{\lambda}_b\right)-\frac{1}{N_b}\sum \limits_{i=1}^{N_b}{\left[{\lambda}_b^i\left(u\left({x}_b^i,{t}_b^i;w\right)-{g}_b^{\prime}\right)\right]}^2\\ {}{\mathrm{\mathcal{L}}}_0\left(w,{\lambda}_0\right)=\frac{1}{N_0}\sum \limits_{i=1}^{N_0}{\left[{\lambda}_0^i\left(u\left({x}_0^i,0;w\right)-{h}_0^i\right)\right]}^2.\end{array}} $$
$$ {\displaystyle \begin{array}{l}{\mathrm{\mathcal{L}}}_r\left(w,{\lambda}_r\right)=\frac{1}{N_r}\sum \limits_{i=1}^{N_r}{\left[{\lambda}_r^ir\left({x}_r^i,{t}_r^1:w\right)\right]}^2\\ {}{\mathrm{\mathcal{L}}}_b\left(w,{\lambda}_b\right)-\frac{1}{N_b}\sum \limits_{i=1}^{N_b}{\left[{\lambda}_b^i\left(u\left({x}_b^i,{t}_b^i;w\right)-{g}_b^{\prime}\right)\right]}^2\\ {}{\mathrm{\mathcal{L}}}_0\left(w,{\lambda}_0\right)=\frac{1}{N_0}\sum \limits_{i=1}^{N_0}{\left[{\lambda}_0^i\left(u\left({x}_0^i,0;w\right)-{h}_0^i\right)\right]}^2.\end{array}} $$
The key feature of self-adaptive PINNs is that the loss
 $ \mathrm{\mathcal{L}}\left(w,{\lambda}_r,{\lambda}_b,{\lambda}_0\right) $
is minimized with respect to the network weights
$ \mathrm{\mathcal{L}}\left(w,{\lambda}_r,{\lambda}_b,{\lambda}_0\right) $
is minimized with respect to the network weights
 $ w $
, as usual, but is maximized with respect to the self-adaptation weights
$ w $
, as usual, but is maximized with respect to the self-adaptation weights
 $ {\lambda}_r,{\lambda}_b,{\lambda}_0 $
; in other words, in training we seek a saddle point
$ {\lambda}_r,{\lambda}_b,{\lambda}_0 $
; in other words, in training we seek a saddle point
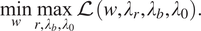 $$ \underset{w}{\min}\underset{r,{\lambda}_b,{\lambda}_0}{\max}\mathrm{\mathcal{L}}\left(w,{\lambda}_r,{\lambda}_b,{\lambda}_0\right). $$
$$ \underset{w}{\min}\underset{r,{\lambda}_b,{\lambda}_0}{\max}\mathrm{\mathcal{L}}\left(w,{\lambda}_r,{\lambda}_b,{\lambda}_0\right). $$
This can be accomplished by a gradient descent–ascent procedure, with updates given by
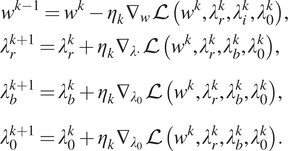 $$ {\displaystyle \begin{array}{l}{w}^{k-1}={w}^k-{\eta}_k{\nabla}_w\mathrm{\mathcal{L}}\left({w}^k,{\lambda}_r^k,{\lambda}_i^k,{\lambda}_0^k\right),\\ {}\phantom{\rule{0ex}{1.5em}}{\lambda}_r^{k+1}={\lambda}_r^k+{\eta}_k{\nabla}_{\lambda \cdot}\mathrm{\mathcal{L}}\left({w}^k,{\lambda}_r^k,{\lambda}_b^k,{\lambda}_0^k\right),\\ {}\phantom{\rule{0ex}{1.5em}}{\lambda}_b^{k+1}={\lambda}_b^k+{\eta}_k{\nabla}_{\lambda_0}\mathrm{\mathcal{L}}\left({w}^k,{\lambda}_r^k,{\lambda}_b^k,{\lambda}_0^k\right),\\ {}\phantom{\rule{0ex}{1.5em}}{\lambda}_0^{k+1}={\lambda}_0^k+{\eta}_k{\nabla}_{\lambda_0}\mathrm{\mathcal{L}}\left({w}^k,{\lambda}_r^k,{\lambda}_b^k,{\lambda}_0^k\right).\end{array}} $$
$$ {\displaystyle \begin{array}{l}{w}^{k-1}={w}^k-{\eta}_k{\nabla}_w\mathrm{\mathcal{L}}\left({w}^k,{\lambda}_r^k,{\lambda}_i^k,{\lambda}_0^k\right),\\ {}\phantom{\rule{0ex}{1.5em}}{\lambda}_r^{k+1}={\lambda}_r^k+{\eta}_k{\nabla}_{\lambda \cdot}\mathrm{\mathcal{L}}\left({w}^k,{\lambda}_r^k,{\lambda}_b^k,{\lambda}_0^k\right),\\ {}\phantom{\rule{0ex}{1.5em}}{\lambda}_b^{k+1}={\lambda}_b^k+{\eta}_k{\nabla}_{\lambda_0}\mathrm{\mathcal{L}}\left({w}^k,{\lambda}_r^k,{\lambda}_b^k,{\lambda}_0^k\right),\\ {}\phantom{\rule{0ex}{1.5em}}{\lambda}_0^{k+1}={\lambda}_0^k+{\eta}_k{\nabla}_{\lambda_0}\mathrm{\mathcal{L}}\left({w}^k,{\lambda}_r^k,{\lambda}_b^k,{\lambda}_0^k\right).\end{array}} $$
In the case of vanilla PINN, the
 $ \lambda $
’s are positive constant scalars, which weight the solution equally and do not adapt to the regularity of the solution. However, in self-adaptive PINN, initial, boundary or collocation points in stiff regions of the solution automatically emphasize more these terms in the loss function, hence forcing the approximation to improve on those regions as shown in Figure 4.
$ \lambda $
’s are positive constant scalars, which weight the solution equally and do not adapt to the regularity of the solution. However, in self-adaptive PINN, initial, boundary or collocation points in stiff regions of the solution automatically emphasize more these terms in the loss function, hence forcing the approximation to improve on those regions as shown in Figure 4.
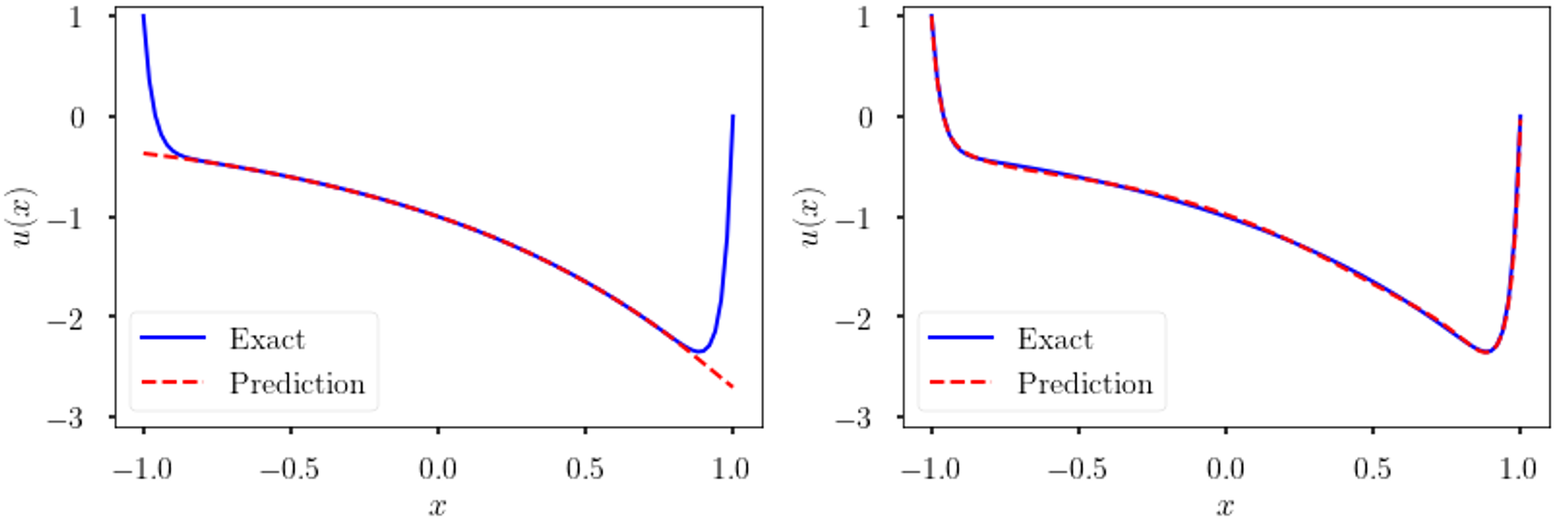
Figure 4. Self-adaptive weights. Solution of (4) using vanilla PINN (left) and self-adaptive PINNs(right). The self-adaptive PINN can capture the boundary layers whereas the vanilla PINN fails.
2.2. Gradient-enhanced training of PINNs
In the standard PINN algorithm we minimize the residual
 $ f $
of the PDE in the
$ f $
of the PDE in the
 $ {L}_2 $
-norm but it may be beneficial to minimize it in the Sobolev norm, and this makes sense since the derivatives of
$ {L}_2 $
-norm but it may be beneficial to minimize it in the Sobolev norm, and this makes sense since the derivatives of
 $ f $
are also zero. This was proposed in Yu et al. (Reference Yu, Lu, Meng and Karniadakis2021) in the gradient-enhanced PINNs (gPINNs), that is,
$ f $
are also zero. This was proposed in Yu et al. (Reference Yu, Lu, Meng and Karniadakis2021) in the gradient-enhanced PINNs (gPINNs), that is,
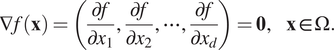 $$ \nabla f\left(\mathbf{x}\right)=\left(\frac{\partial f}{\partial {x}_1},\frac{\partial f}{\partial {x}_2},\cdots, \frac{\partial f}{\partial {x}_d}\right)=\mathbf{0},\hskip1em \mathbf{x}\in \Omega . $$
$$ \nabla f\left(\mathbf{x}\right)=\left(\frac{\partial f}{\partial {x}_1},\frac{\partial f}{\partial {x}_2},\cdots, \frac{\partial f}{\partial {x}_d}\right)=\mathbf{0},\hskip1em \mathbf{x}\in \Omega . $$
Hence, the loss function of gPINNs is:
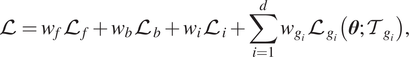 $$ \mathrm{\mathcal{L}}={w}_f{\mathrm{\mathcal{L}}}_f+{w}_b{\mathrm{\mathcal{L}}}_b+{w}_i{\mathrm{\mathcal{L}}}_i+\sum \limits_{i=1}^d{w}_{g_i}{\mathrm{\mathcal{L}}}_{g_i}\left(\boldsymbol{\theta}; {\mathcal{T}}_{g_i}\right), $$
$$ \mathrm{\mathcal{L}}={w}_f{\mathrm{\mathcal{L}}}_f+{w}_b{\mathrm{\mathcal{L}}}_b+{w}_i{\mathrm{\mathcal{L}}}_i+\sum \limits_{i=1}^d{w}_{g_i}{\mathrm{\mathcal{L}}}_{g_i}\left(\boldsymbol{\theta}; {\mathcal{T}}_{g_i}\right), $$
where
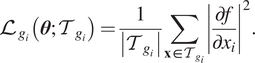 $$ {\mathrm{\mathcal{L}}}_{g_i}\left(\boldsymbol{\theta}; {\mathcal{T}}_{g_i}\right)=\frac{1}{\left|{\mathcal{T}}_{g_i}\right|}\sum \limits_{\mathbf{x}\in {\mathcal{T}}_{g_i}}{\left|\frac{\partial f}{\partial {x}_i}\right|}^2. $$
$$ {\mathrm{\mathcal{L}}}_{g_i}\left(\boldsymbol{\theta}; {\mathcal{T}}_{g_i}\right)=\frac{1}{\left|{\mathcal{T}}_{g_i}\right|}\sum \limits_{\mathbf{x}\in {\mathcal{T}}_{g_i}}{\left|\frac{\partial f}{\partial {x}_i}\right|}^2. $$
Here,
 $ {\mathcal{T}}_{g_i} $
is the set of residual points for the derivative
$ {\mathcal{T}}_{g_i} $
is the set of residual points for the derivative
 $ \frac{\partial f}{\partial {x}_i} $
, and in general,
$ \frac{\partial f}{\partial {x}_i} $
, and in general,
 $ {\mathcal{T}}_f $
and
$ {\mathcal{T}}_f $
and
 $ {\mathcal{T}}_{g_i} $
(
$ {\mathcal{T}}_{g_i} $
(
 $ i=1,\cdots, d $
) can be different.
$ i=1,\cdots, d $
) can be different.
For example, for the Poisson’s equation
 $ \Delta u=f $
in 1D, the additional loss term is
$ \Delta u=f $
in 1D, the additional loss term is
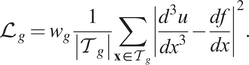 $$ {\mathrm{\mathcal{L}}}_g={w}_g\frac{1}{\left|{\mathcal{T}}_g\right|}\sum \limits_{\mathbf{x}\in {\mathcal{T}}_g}{\left|\frac{d^3u}{dx^3}-\frac{df}{dx}\right|}^2. $$
$$ {\mathrm{\mathcal{L}}}_g={w}_g\frac{1}{\left|{\mathcal{T}}_g\right|}\sum \limits_{\mathbf{x}\in {\mathcal{T}}_g}{\left|\frac{d^3u}{dx^3}-\frac{df}{dx}\right|}^2. $$
Next, we present a comparison between PINNs and gPINNs based on the work of Yu et al. (Reference Yu, Lu, Meng and Karniadakis2021) for the following diffusion equation
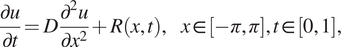 $$ \frac{\partial u}{\partial t}=D\frac{\partial^2u}{\partial {x}^2}+R\left(x,t\right),\hskip1em x\in \left[-\pi, \pi \right],t\in \left[0,1\right], $$
$$ \frac{\partial u}{\partial t}=D\frac{\partial^2u}{\partial {x}^2}+R\left(x,t\right),\hskip1em x\in \left[-\pi, \pi \right],t\in \left[0,1\right], $$
where
 $ D=1 $
. Here,
$ D=1 $
. Here,
 $ R $
is given by:
$ R $
is given by:
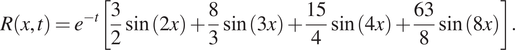 $$ R\left(x,t\right)={e}^{-t}\left[\frac{3}{2}\sin (2x)+\frac{8}{3}\sin (3x)+\frac{15}{4}\sin (4x)+\frac{63}{8}\sin (8x)\right]. $$
$$ R\left(x,t\right)={e}^{-t}\left[\frac{3}{2}\sin (2x)+\frac{8}{3}\sin (3x)+\frac{15}{4}\sin (4x)+\frac{63}{8}\sin (8x)\right]. $$
The initial and boundary conditions are:
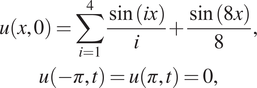 $$ {\displaystyle \begin{array}{c}u\left(x,0\right)=\sum \limits_{i=1}^4\frac{\sin (ix)}{i}+\frac{\sin (8x)}{8},\\ {}u\left(-\pi, t\right)=u\left(\pi, t\right)=0,\end{array}} $$
$$ {\displaystyle \begin{array}{c}u\left(x,0\right)=\sum \limits_{i=1}^4\frac{\sin (ix)}{i}+\frac{\sin (8x)}{8},\\ {}u\left(-\pi, t\right)=u\left(\pi, t\right)=0,\end{array}} $$
corresponding to the analytical solution for
 $ u $
:
$ u $
:
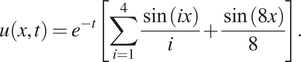 $$ u\left(x,t\right)={e}^{-t}\left[\sum \limits_{i=1}^4\frac{\sin (ix)}{i}+\frac{\sin (8x)}{8}\right]. $$
$$ u\left(x,t\right)={e}^{-t}\left[\sum \limits_{i=1}^4\frac{\sin (ix)}{i}+\frac{\sin (8x)}{8}\right]. $$
We have two loss terms of the gradient, and the total loss function is
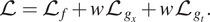 $$ \mathrm{\mathcal{L}}={\mathrm{\mathcal{L}}}_f+w{\mathrm{\mathcal{L}}}_{g_x}+w{\mathrm{\mathcal{L}}}_{g_t}. $$
$$ \mathrm{\mathcal{L}}={\mathrm{\mathcal{L}}}_f+w{\mathrm{\mathcal{L}}}_{g_x}+w{\mathrm{\mathcal{L}}}_{g_t}. $$
We see in Figure 5 that gPINN results with the values of
 $ w=0.01 $
, 0.1, and 1 all outperform PINN by up to two orders of magnitude. However, we note that while gPINN reaches 1%
$ w=0.01 $
, 0.1, and 1 all outperform PINN by up to two orders of magnitude. However, we note that while gPINN reaches 1%
 $ {L}^2 $
relative error of
$ {L}^2 $
relative error of
 $ u $
by using only 40 training points, and PINN requires more than 100 points to reach the same accuracy, gPINN is almost twice as expensive as PINN due to extra expensive automatic differentiation.
$ u $
by using only 40 training points, and PINN requires more than 100 points to reach the same accuracy, gPINN is almost twice as expensive as PINN due to extra expensive automatic differentiation.
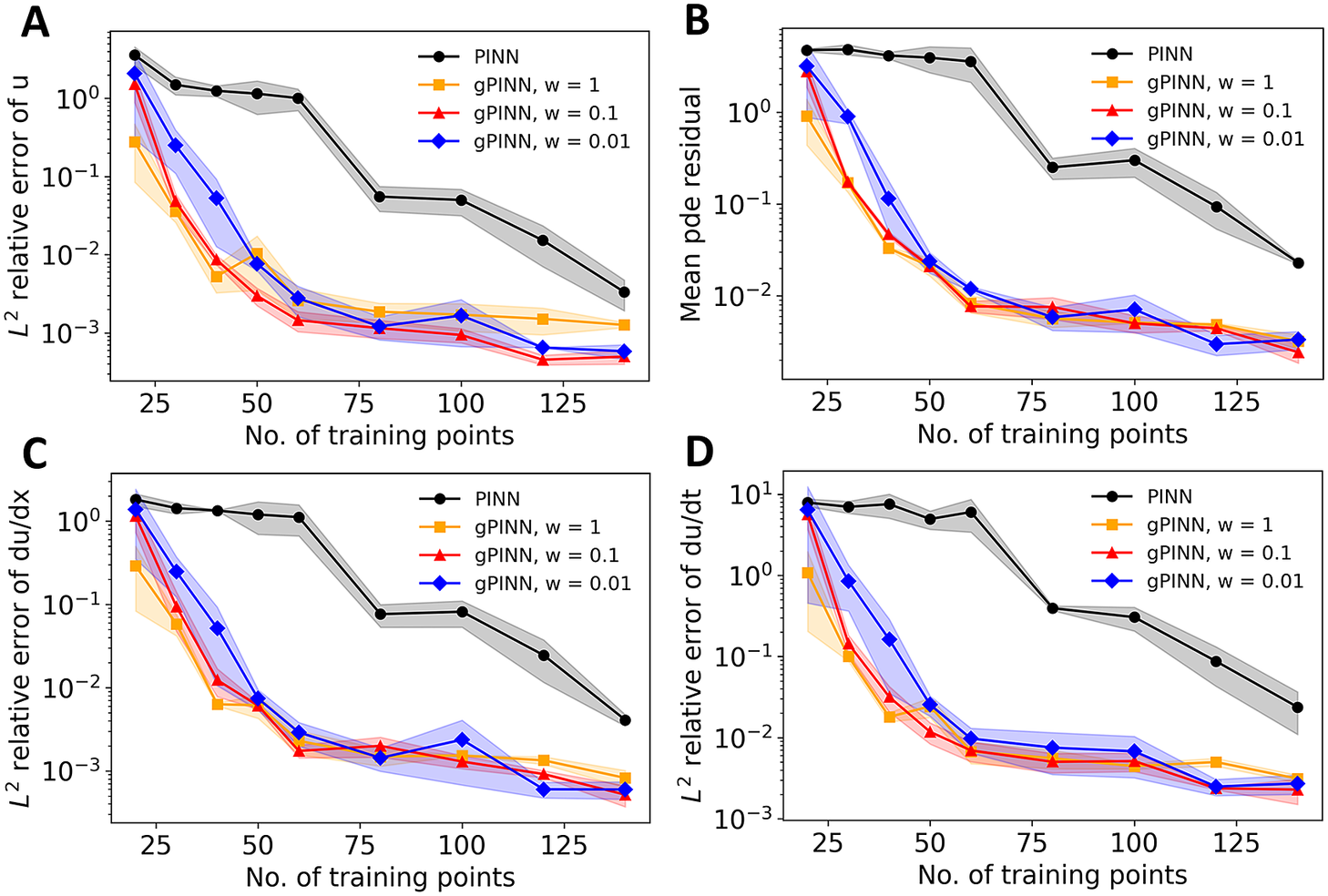
Figure 5. Comparison between PINN and gPINN. (a)
 $ {L}^2 $
relative error of
$ {L}^2 $
relative error of
 $ u $
for PINN and gPINN with
$ u $
for PINN and gPINN with
 $ w= $
1, 0.1, and 0.01. (b) Mean absolute value of the PDE residual. (c)
$ w= $
1, 0.1, and 0.01. (b) Mean absolute value of the PDE residual. (c)
 $ {L}^2 $
relative error of
$ {L}^2 $
relative error of
 $ \frac{du}{dx} $
. (d)
$ \frac{du}{dx} $
. (d)
 $ {L}^2 $
relative error of
$ {L}^2 $
relative error of
 $ \frac{du}{dt} $
(figure is from Yu et al., Reference Yu, Lu, Meng and Karniadakis2021).
$ \frac{du}{dt} $
(figure is from Yu et al., Reference Yu, Lu, Meng and Karniadakis2021).
2.3. Scalable PINNs
As discussed above, PINNs can efficiently tackle both forward problems, where the solution of governing physical law is inferred, as well as ill-posed inverse problems, where the unknown physics and/or free parameters in the governing equations are to inferred from the available multi-modal measurements. However, one of the major concerns with PINNs is the large computational cost associated with the training of the neural networks, especially for forward multiscale problems. To improve the scalability and reduce the computational cost, Jagtap et al. (Reference Jagtap, Kharazmi and Karniadakis2020) introduced a domain decomposition-based (in-space) PINN for conservation laws, namely conservative PINN (cPINN), where continuity of the state variables as well as their fluxes across subdomain interfaces is used to obtain the global solution from the local solutions in the subdomains. In subsequent work, Jagtap and Karniadakis (Reference Jagtap and Karniadakis2020) applied domain decomposition to general PDEs using the so-called extended PINN (XPINN). Unlike cPINN, which offers space decomposition, XPINN offers both space–time domain decomposition for any irregular, nonconvex geometry thereby reducing the computational cost effectively. By exploiting the decomposition process of the cPINN/XPINN methods and its implicit mapping on the modern heterogeneous computing platforms, the training time of the network can be reduced to a great extent.
There are currently two existing approaches for distributed training of neural networks, namely, the data-parallel approach (Sergeev and Del Balso, Reference Sergeev and Del Balso2018) and the model parallel approach, which are agnostic to physics-based priors. The data-parallel approach is based on the single instruction and multiple data (SIMD) parallel programming model, which results in a simple performance model driven by weak scaling. A block diagram showing the basic building blocks of the data-parallel approach is shown in Figure 6a for a four processors or coprocessors system. The programming model used for the data-parallel approach falls into the regime of message passing interface (MPI) + X system, where X is chosen as CPU(s) or GPU(s), depending on the size of the input data. In the data-parallel approach, the data is uniformly split into a number of chunks (
 $ {D}_1,\dots, {D}_4 $
in Figure 6a), equal to the number of processors. The neural network (NN) model is initialized with the same parameters on all the processes as shown in Figure 6a. These neural networks are working on different chunks of the data, and therefore, work on different loss functions as shown by
$ {D}_1,\dots, {D}_4 $
in Figure 6a), equal to the number of processors. The neural network (NN) model is initialized with the same parameters on all the processes as shown in Figure 6a. These neural networks are working on different chunks of the data, and therefore, work on different loss functions as shown by
 $ {\mathcal{J}}_1,\dots, {\mathcal{J}}_4 $
in Figure 6a.
$ {\mathcal{J}}_1,\dots, {\mathcal{J}}_4 $
in Figure 6a.
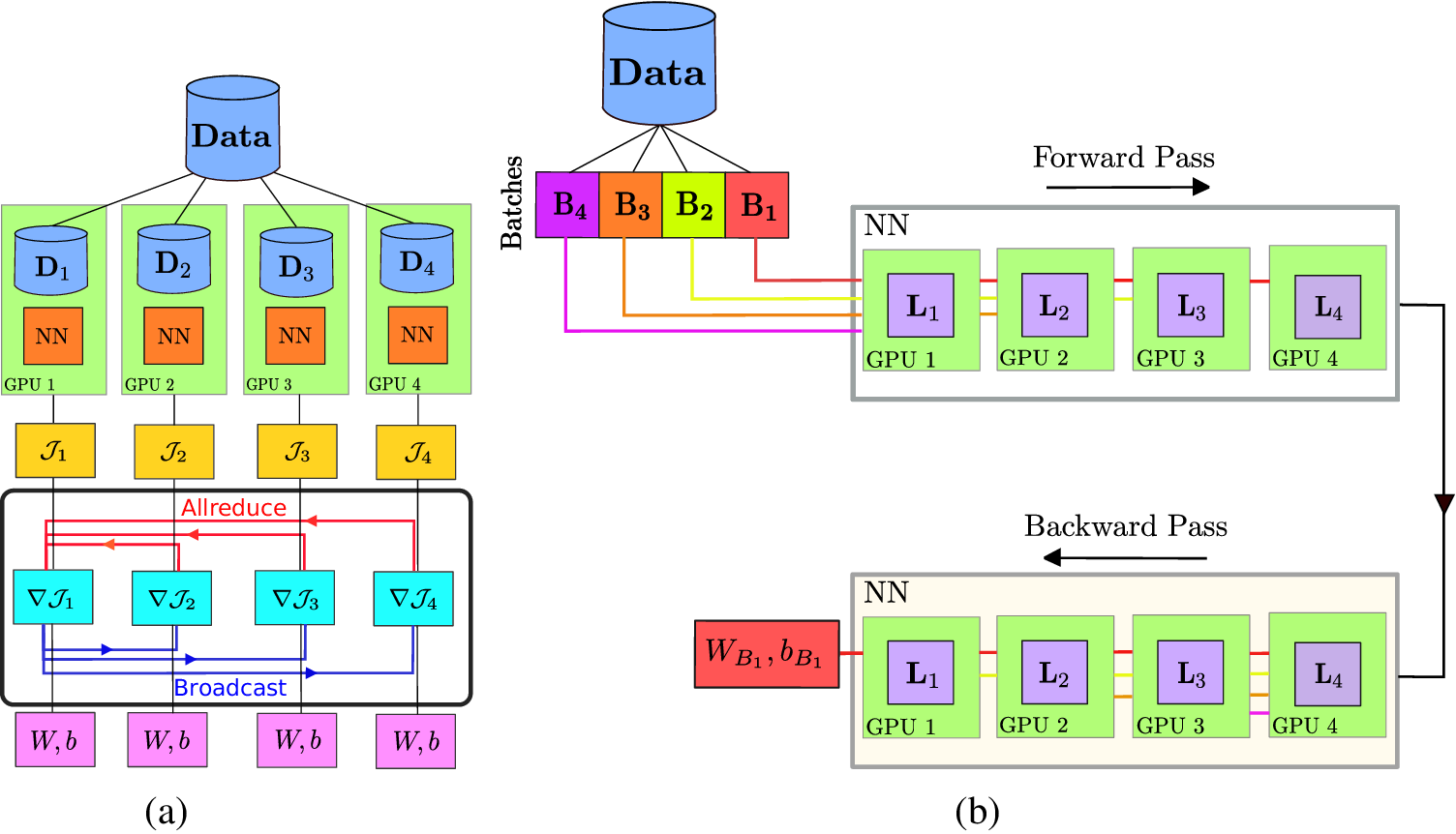
Figure 6. Schematic of the implementation of data and model parallel algorithms. (a) Method for the data-parallel approach, where the same neural network model, represented by NN, is loaded by each processor but works on a different chunk of input data. Synchronization of training (gradient of loss) is performed after the computation of loss on each processor via “allreduce” and “broadcast” operations represented by horizontal red and blue lines. (b) Represents the model parallel approach, where each layer of the model (represented by
 $ {L}_1\dots {L}_4 $
) is loaded on a processor and each processor works on a batch of data
$ {L}_1\dots {L}_4 $
) is loaded on a processor and each processor works on a batch of data
 $ \left({B}_1\dots {B}_4\right) $
. Forward and backward passes are performed by using a pipeline approach. Adapted from Shukla et al. (Reference Shukla, Jagtap and Karniadakis2021b).
$ \left({B}_1\dots {B}_4\right) $
. Forward and backward passes are performed by using a pipeline approach. Adapted from Shukla et al. (Reference Shukla, Jagtap and Karniadakis2021b).
NVIDIA also introduced the parallel code MODULUS (Hennigh et al., Reference Hennigh, Narasimhan, Nabian, Subramaniam, Tangsali, Rietmann, Ferrandis, Byeon, Fang and Choudhry2020), which implements the standard PINN-based multiphysics simulation framework. The underlying idea of MODULUS is to solve the differential equation by modeling the mass balance condition as a hard constraint as well as a global constraint. MODULUS provides the functionality for multi-GPU and multinode implementation based on the data-parallel approach (Figure 6a).
To ensure a consistent neural network model (defined with same weights and biases) across all the processes and during each epoch or iteration of training, a distributed optimizer is used, which averages out the gradient of loss values (
 $ \nabla {\mathcal{J}}_1,\dots, \nabla {\mathcal{J}}_4 $
in Figure 6a) on the root processor through an “allreduce” operation. Subsequently, the averaged gradient of the loss function is sent to all the processors in the communicator world through a broadcast operation (collective communication). Then, the parameters of the model are updated through an optimizer. An additional component, which arises in the data-parallel approach, is the increase in global batch size with the number of processes. Goyal et al. (Reference Goyal, Dollár, Girshick, Noordhuis, Wesolowski, Kyrola, Tulloch, Jia and He2017) addressed this issue by multiplying the learning rate with the number of processes in the communicator. We note that in the data-parallel approach the model size (size of neural network parameters) remains uniform on each processor or GPU and that imposes a problem for large models to be trained on GPUs as they have fixed memory.
$ \nabla {\mathcal{J}}_1,\dots, \nabla {\mathcal{J}}_4 $
in Figure 6a) on the root processor through an “allreduce” operation. Subsequently, the averaged gradient of the loss function is sent to all the processors in the communicator world through a broadcast operation (collective communication). Then, the parameters of the model are updated through an optimizer. An additional component, which arises in the data-parallel approach, is the increase in global batch size with the number of processes. Goyal et al. (Reference Goyal, Dollár, Girshick, Noordhuis, Wesolowski, Kyrola, Tulloch, Jia and He2017) addressed this issue by multiplying the learning rate with the number of processes in the communicator. We note that in the data-parallel approach the model size (size of neural network parameters) remains uniform on each processor or GPU and that imposes a problem for large models to be trained on GPUs as they have fixed memory.
To circumvent this issue, another distributed algorithm approach namely, the model parallel approach is proposed. A block diagram of the algorithm in the model parallel approach is shown in Figure 6b, which can be interpreted as a classic example of pipeline algorithm (Rajbhandari et al., Reference Rajbhandari, Rasley, Ruwase and He2020). In the model parallel approach, data is first divided into small batches (
 $ {\mathbf{B}}_1,\dots, {\mathbf{B}}_4 $
in Figure 6b) and each hidden layer (
$ {\mathbf{B}}_1,\dots, {\mathbf{B}}_4 $
in Figure 6b) and each hidden layer (
 $ {\mathbf{L}}_1,\dots, {\mathbf{L}}_4 $
in Figure 6b) is distributed to a processor (or GPU). During the forward pass, once
$ {\mathbf{L}}_1,\dots, {\mathbf{L}}_4 $
in Figure 6b) is distributed to a processor (or GPU). During the forward pass, once
 $ {\mathbf{B}}_1 $
is processed by
$ {\mathbf{B}}_1 $
is processed by
 $ {\mathbf{L}}_1 $
, the output of
$ {\mathbf{L}}_1 $
, the output of
 $ {\mathbf{L}}_1 $
is passed as the input to
$ {\mathbf{L}}_1 $
is passed as the input to
 $ {\mathbf{L}}_2 $
and
$ {\mathbf{L}}_2 $
and
 $ {\mathbf{L}}_1 $
will start working on
$ {\mathbf{L}}_1 $
will start working on
 $ {\mathbf{B}}_2 $
and so on. Once
$ {\mathbf{B}}_2 $
and so on. Once
 $ {\mathbf{L}}_4 $
finishes working,
$ {\mathbf{L}}_4 $
finishes working,
 $ {\mathbf{B}}_1 $
the backward pass (optimization process) will kickoff, thus, completing epochs of training in a pipeline mode. We note that the implementation of both algorithms is problem agnostic and does not incorporate any prior information on solutions to be approximated, which makes the performance of these algorithms to be dependent on the data size and model parameters. In the literature, the implementation of data and model parallel approaches is primarily carried out for problems pertaining to the classification and natural language processing (Goyal et al., Reference Goyal, Dollár, Girshick, Noordhuis, Wesolowski, Kyrola, Tulloch, Jia and He2017; Rasley et al., Reference Rasley, Rajbhandari, Ruwase and He2020), which are based on large amounts of training data. Therefore, the efficiency of data and the model parallel approach for scientific machine learning is not explored, which is primarily dominated by the high-dimensional and sparse data set. Apart from these two classical approaches, recently Xu et al. (Reference Xu, Zhu and Darve2020a) deployed the topological concurrency on data structures of neural network parameters. In brief, this implementation could be comprehended as task-based parallelism and it is rooted in the idea of model-based parallelism. Additionally, it also provides interactivity with other discretization-based solvers such as Fenics (Alnæs et al., Reference Alnæs, Blechta, Hake, Johansson, Kehlet, Logg, Richardson, Ring, Rognes and Wells2015).
$ {\mathbf{B}}_1 $
the backward pass (optimization process) will kickoff, thus, completing epochs of training in a pipeline mode. We note that the implementation of both algorithms is problem agnostic and does not incorporate any prior information on solutions to be approximated, which makes the performance of these algorithms to be dependent on the data size and model parameters. In the literature, the implementation of data and model parallel approaches is primarily carried out for problems pertaining to the classification and natural language processing (Goyal et al., Reference Goyal, Dollár, Girshick, Noordhuis, Wesolowski, Kyrola, Tulloch, Jia and He2017; Rasley et al., Reference Rasley, Rajbhandari, Ruwase and He2020), which are based on large amounts of training data. Therefore, the efficiency of data and the model parallel approach for scientific machine learning is not explored, which is primarily dominated by the high-dimensional and sparse data set. Apart from these two classical approaches, recently Xu et al. (Reference Xu, Zhu and Darve2020a) deployed the topological concurrency on data structures of neural network parameters. In brief, this implementation could be comprehended as task-based parallelism and it is rooted in the idea of model-based parallelism. Additionally, it also provides interactivity with other discretization-based solvers such as Fenics (Alnæs et al., Reference Alnæs, Blechta, Hake, Johansson, Kehlet, Logg, Richardson, Ring, Rognes and Wells2015).
The main advantage of cPINN and XPINN over data and model parallel approaches (including the work of Xu et al., Reference Xu, Zhu and Darve2020a) is their adaptivity for all hyperparameters of the neural network in each subdomain. In the vanilla data-parallel approach, the training across processors is synchronized by averaging the gradient of loss function across and subsequently broadcasting, enforcing the same network architectures on each processor. In PIML, the solution of the underlying physical laws is inferred based on a small amount of data, where the chosen neural network architecture depends on the complexity and regularity of the solutions to be recovered. To address this issue, the synchronization of the training process across all the processors has to be achieved by the physics of the problem, and therefore cPINNs and XPINNs come to the rescue. The convergence of the solution based on a single domain is constrained by its global approximation, which is relatively slow. On the other hand, computation of the solution based on local approximation by using the local neural networks can result in fast convergence. With regards to computational aspects, the domain decomposition-based approach requires a point-to-point communication protocol with a very small size of the buffer. However, for the data-parallel approach, it requires one allreduce operation and one broadcast operation with each having the buffer size equal to the number of parameters of the neural network, which makes communication across the processor slower. Moreover, for problems involving heterogeneous physics the data/model parallel approaches are not adequate, whereas cPINNs/XPINNs can easily handle such multiphysics problems. Therefore, domain decomposition approaches paired with physics-based synchronization help more than the vanilla data-parallel approaches.
The implementation of cPINN and XPINN on distributed and heterogeneous computing architectures are discussed in detail by Shukla et al. (Reference Shukla, Jagtap and Karniadakis2021b). The core idea of implementation is based on the domain decomposition approach, where in each subdomain we compute the corresponding solution, and the residuals and solutions at shared edges or planes are passed using MPI as shown in Figure 7 to be averaged. Figure 8 shows the weak scaling of cPINN and XPINN for up to 24 GPUs measured on the supercomputer Summit of Oak Ridge National Laboratory. The weak scaling of cPINN and XPINN shows a very good agreement between observed and theoretical performance. The weak scaling also shows that XPINN has less throughput than the cPINN, which could be easily justified as computation of flux typically requires one order less auto-differentiation computation than computation of residuals for XPINN. Shukla et al. (Reference Shukla, Jagtap and Karniadakis2021b) carried out a detailed strong and weak scaling along with communication and computation times required for both methods.
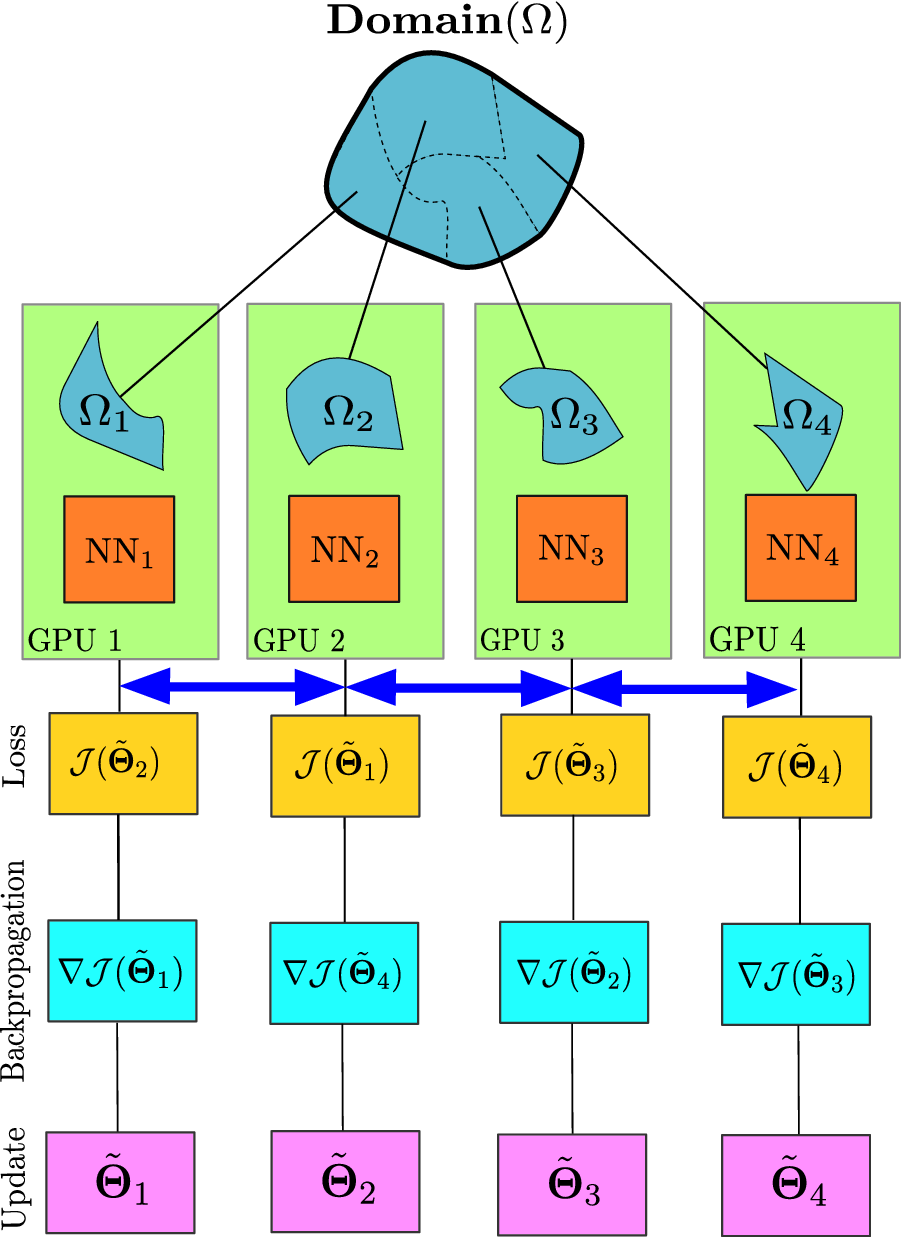
Figure 7. Parallel PINNs. Building blocks of distributed cPINN and XPINN methodologies deployed on a heterogeneous computing platform. The domain
 $ \Omega $
is decomposed into several subdomains
$ \Omega $
is decomposed into several subdomains
 $ {\Omega}_1,\dots, {\Omega}_4 $
equal to the number of processors, and individual neural networks (NN
$ {\Omega}_1,\dots, {\Omega}_4 $
equal to the number of processors, and individual neural networks (NN
 $ {}_1,\dots, $
NN
$ {}_1,\dots, $
NN
 $ {}_4 $
) are employed in each subdomain, which gives separate loss functions
$ {}_4 $
) are employed in each subdomain, which gives separate loss functions
 $ \mathcal{J}({\tilde{\Theta}}_q),q=1,\dots, 4 $
coupled through the interface conditions (shown by the double-headed blue arrow). The trainable parameters are updated by finding the gradient of loss function individually for each network and penalizing the continuity of interface conditions.
$ \mathcal{J}({\tilde{\Theta}}_q),q=1,\dots, 4 $
coupled through the interface conditions (shown by the double-headed blue arrow). The trainable parameters are updated by finding the gradient of loss function individually for each network and penalizing the continuity of interface conditions.
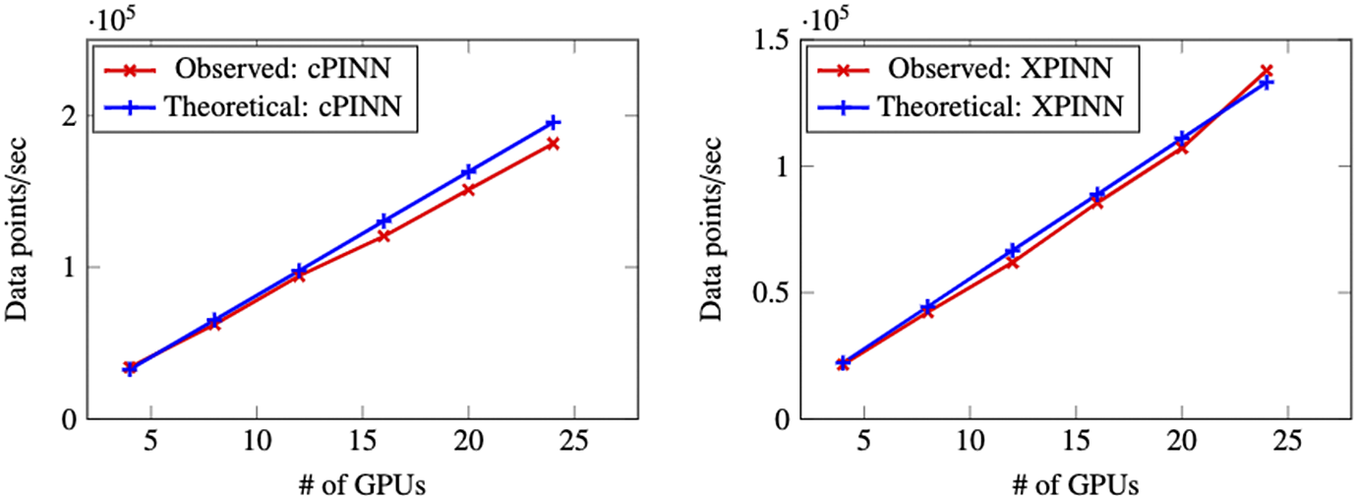
Figure 8. Two-dimensional incompressible Navier–Stokes equations: Weak GPU scaling for the distributed cPINN (left) and XPINN (right) algorithms.
2.4. Inverse problem with parallel PINNs
To validate the scalability of cPINN and XPINN for a very large inverse problem, we solve the steady-state heat conduction problem over a domain represented by the USA map. The governing equation for the steady-state heat conduction problem is written as
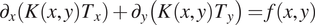 $$ {\partial}_x\left(K\left(x,y\right){T}_x\right)+{\partial}_y\left(K\left(x,y\right){T}_y\right)=f\left(x,y\right) $$
$$ {\partial}_x\left(K\left(x,y\right){T}_x\right)+{\partial}_y\left(K\left(x,y\right){T}_y\right)=f\left(x,y\right) $$
with Dirichlet boundary conditions for temperature
 $ T $
and thermal conductivity
$ T $
and thermal conductivity
 $ K $
, obtained from the exact solution. The forcing term
$ K $
, obtained from the exact solution. The forcing term
 $ f\left(x,y\right) $
is obtained from the exact solution for variable thermal conductivity and temperature, which is assumed to be of the form
$ f\left(x,y\right) $
is obtained from the exact solution for variable thermal conductivity and temperature, which is assumed to be of the form
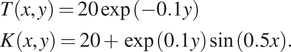 $$ {\displaystyle \begin{array}{l}T\left(x,y\right)=20\exp \left(-0.1y\right)\\ {}K\left(x,y\right)=20+\exp (0.1y)\sin (0.5x).\end{array}} $$
$$ {\displaystyle \begin{array}{l}T\left(x,y\right)=20\exp \left(-0.1y\right)\\ {}K\left(x,y\right)=20+\exp (0.1y)\sin (0.5x).\end{array}} $$
Materials whose thermal conductivity is a function of space are the so-called functionally graded materials, which are a particular type of composite materials. The material domain is chosen to be a map of the United States divided into 10 subdomains as shown in Figure 9. The interfaces between these subdomains are shown by the dashed blue line whereas the domain boundary is shown by the solid green line. The boundary and the training data is available for every subdomain. Unlike cPINN, XPINN can easily handle such complex subdomains with arbitrarily shaped interfaces, thus, providing greater flexibility in terms of domain subdivision. Figure 9(right) shows the residual, training data, and interface points in blue dot, red cross, and black asterisk, respectively, over the entire domain.
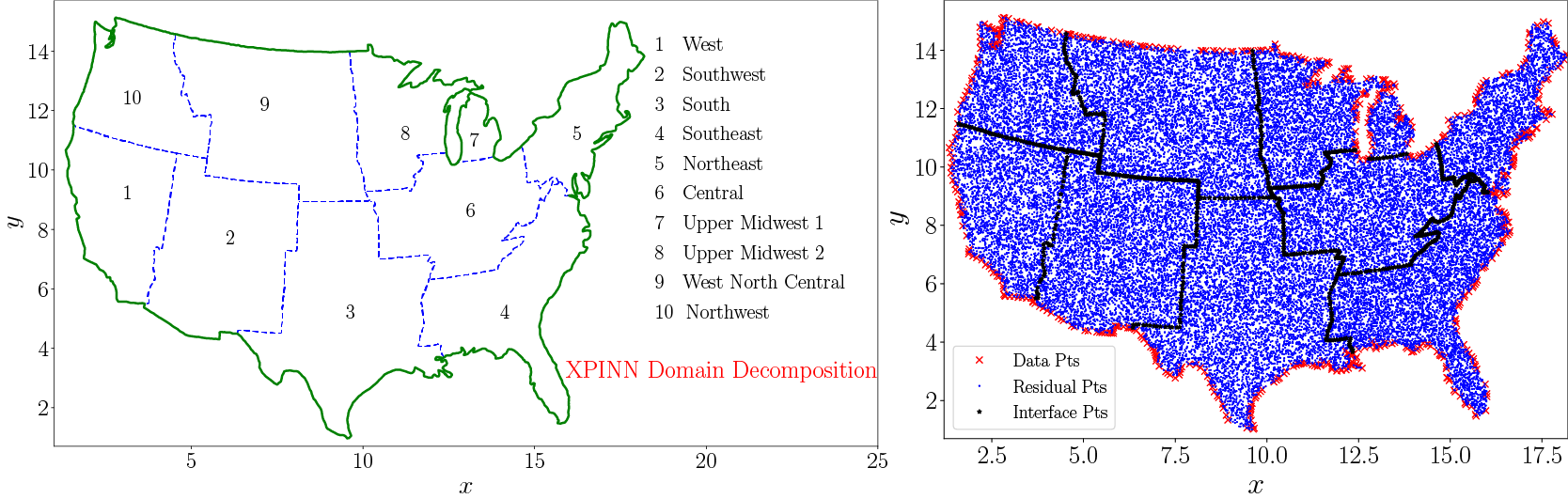
Figure 9. Steady-state heat conduction with variable conductivity: Domain decomposition of the US map into 10 regions (left) and the corresponding data, residual, and interface points in these regions (right).
In this inverse problem, the temperature is assumed to be known in the domain but the variable thermal conductivity is unknown. The aim is to infer the unknown thermal conductivity of the material from a few data points for
 $ K $
available along the boundary line and temperature values available inside the domain. We employed a single PINN in each subdomain, and the details about the network’s architecture are given in Table 1. In each subdomain, we used 3 hidden-layers with 80 neurons in each layer, and the learning rate is 6e-3, which is fixed for all networks.
$ K $
available along the boundary line and temperature values available inside the domain. We employed a single PINN in each subdomain, and the details about the network’s architecture are given in Table 1. In each subdomain, we used 3 hidden-layers with 80 neurons in each layer, and the learning rate is 6e-3, which is fixed for all networks.
Table 1. Steady-state heat conduction with variable conductivity: Neural network architecture in each subdomain.
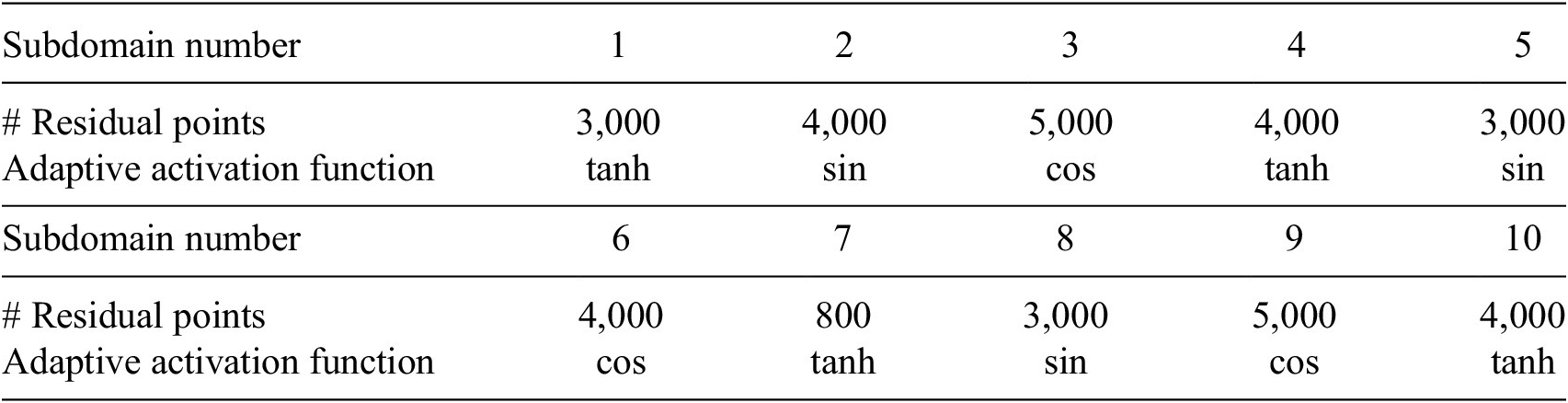
Figure 10 (top row) shows the predicted values of temperature and thermal conductivity. The absolute point-wise errors are given in the bottom row. The XPINN method accurately inferred the thermal conductivity, which shows that XPINN can easily handle highly irregular and nonconvex interfaces.
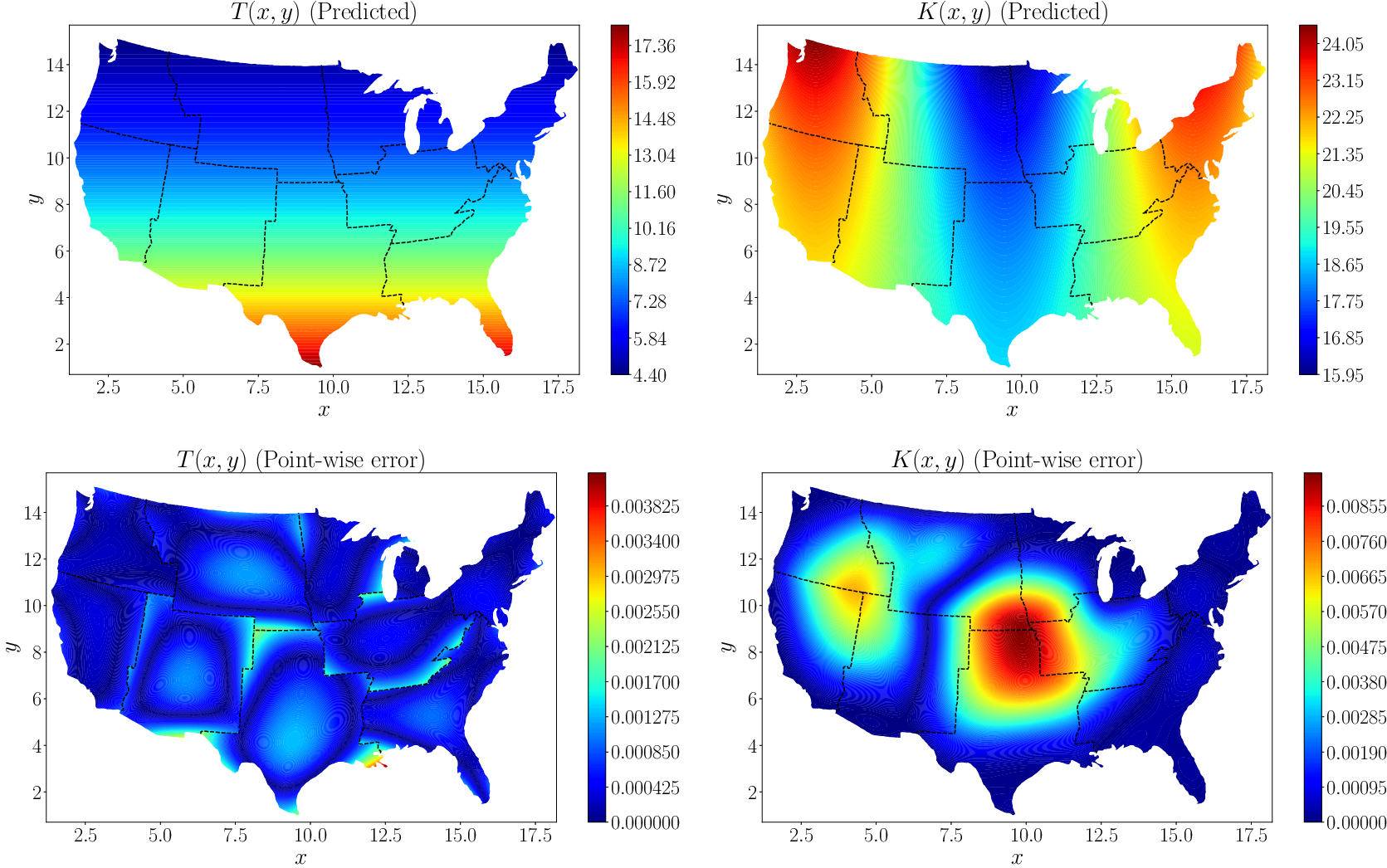
Figure 10. Steady-state heat conduction with variable conductivity: The first row shows the contour plots for the predicted temperature
 $ T\left(x,y\right) $
and thermal conductivity
$ T\left(x,y\right) $
and thermal conductivity
 $ K\left(x,y\right) $
while the second row shows the corresponding absolute point-wise errors. Adapted from Shukla et al. (Reference Shukla, Jagtap and Karniadakis2021b)).
$ K\left(x,y\right) $
while the second row shows the corresponding absolute point-wise errors. Adapted from Shukla et al. (Reference Shukla, Jagtap and Karniadakis2021b)).
Figure 11 represents the performance of the parallel XPINN algorithm deployed for solving the inverse heat conduction problem. The performance is measured for the data points given in Table 1. The left subfigure in Figure 11 represents the wall time and scaling of the parallel XPINN algorithm on CPUs by computing the solution in each domain using one CPUs. The continuity of solution on the shared boundaries of the subdomain is imposed by passing the solution on each domain boundary to the neighboring subdomains though MPI protocols. Here, each CPU corresponds to a rank mapped by node, and Intel’s Xeon(R) Gold 6126 CPUs are used for measurement. First, we measured the wall time of the algorithm on one CPU and considered it as baseline data
 $ \left(1\mathrm{X}\right) $
for the scaling. Thereafter, we computed the wall time for 10 CPUs, leading to a
$ \left(1\mathrm{X}\right) $
for the scaling. Thereafter, we computed the wall time for 10 CPUs, leading to a
 $ \left(9\mathrm{X}\right) $
and
$ \left(9\mathrm{X}\right) $
and
 $ \left(10\mathrm{X}\right) $
for single (32-bit float) and double-precision (64-bit float) computation, respectively. The scaling for double-precision is relatively better as the communication process is shadowed by the computation time due to more time being spent on double-precision arithmetic. However, double-precision-based computation increases wall time by a factor of
$ \left(10\mathrm{X}\right) $
for single (32-bit float) and double-precision (64-bit float) computation, respectively. The scaling for double-precision is relatively better as the communication process is shadowed by the computation time due to more time being spent on double-precision arithmetic. However, double-precision-based computation increases wall time by a factor of
 $ 2.5 $
for single and multiple CPU-based implementations.
$ 2.5 $
for single and multiple CPU-based implementations.
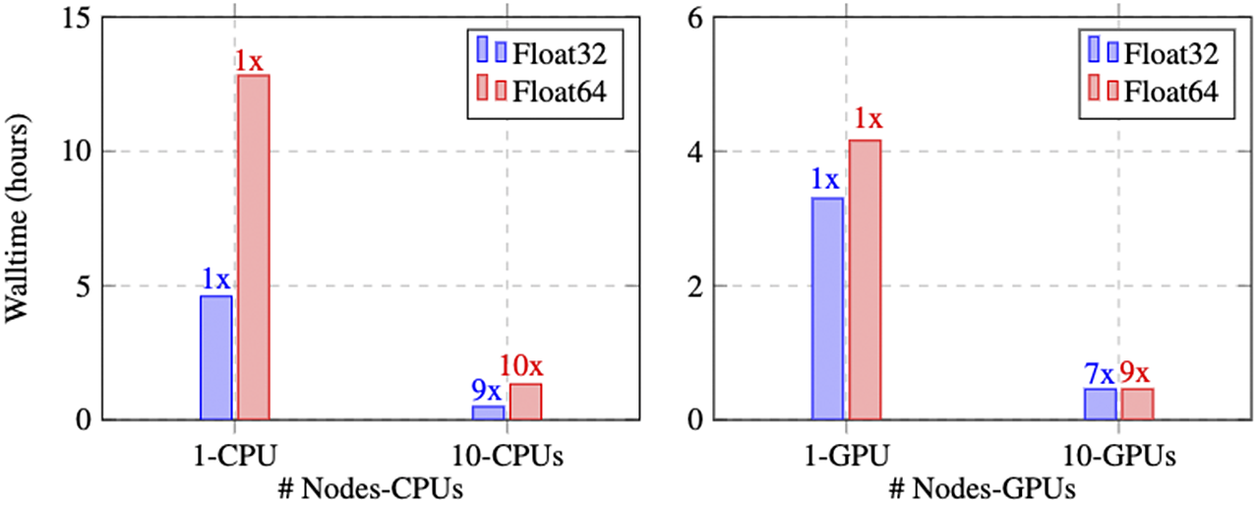
Figure 11. Steady-state heat conduction with variable conductivity: Walltime and speedup of parallel XPINN algorithm on CPUs and GPUs implemented for the inverse heat conduction problem in (11); (a) speedup and wall time for the parallel XPINN code on Intel’s Xeon(R) Gold 6126 CPU. The speed and wall time is measured for computations performed with single (Float32) and double-precision numbers (Float64); (b) speedup and wall time, measured for single- and double-precision operations, on Nvidia’s V100 GPUs. Adapted from Shukla et al. (Reference Shukla, Jagtap and Karniadakis2021b)).
Next, we report the walltime and GPU-based implementation. The algorithm is implemented on Nvidia V100 GPUs with 16 GB memories. The hardware architecture is similar to that reported in the example of incompressible Navier–Stokes equations. The right subfigure of Figure 11 represents the walltime with 1 and 10 GPUs for single- and double-precision arithmetic. On a single GPU, considered as
 $ \left(1\mathrm{X}\right) $
model the wall time for double-precision arithmetic 30% more than that received for single-precision. In the multi-GPU implementation, one GPU is used for each subdomain, and here one rank mapped by the node corresponds to the combination of 1CPU + 1GPU. The walltime for 10-GPUs (10 Nodes or 10 ranks) yields a scaling
$ \left(1\mathrm{X}\right) $
model the wall time for double-precision arithmetic 30% more than that received for single-precision. In the multi-GPU implementation, one GPU is used for each subdomain, and here one rank mapped by the node corresponds to the combination of 1CPU + 1GPU. The walltime for 10-GPUs (10 Nodes or 10 ranks) yields a scaling
 $ \left(7\mathrm{X}\right) $
and
$ \left(7\mathrm{X}\right) $
and
 $ \left(9\mathrm{X}\right) $
for single- and double-precision arithmetic. We note that the residual points in each subdomain are not enough to saturate the GPUs and therefore more time is spent on fetching the data to memory and inter-GPU communication. To provide more intuition in the purview of the current implementation, for a typical V100 (16 GB) memory, the single-precision performance is 14 TFLOPs with a memory bandwidth of 900 GB/s and therefore for each byte of transfer (memory to GPU core) 15.6 instruction (FLOPs/Bandwidth) needs to be issued to occupy the GPUs completely. In the context of the current problem, the partition and therefore the load on GPUs (or CPUs) are static and does not change throughout the computation; thus, subdomain 7, endowed with only 800 residual points, has to wait until all the GPUs (or CPUs) complete their work for the respective subdomain. This also results in slight sublinear performance. However, the performance presented in Figure 11 shows a very good linear scaling for CPUs on a heterogeneous (CPU + GPU) architecture. Additionally, the scaling of the presented algorithm on CPUs only architecture concurs with the idea of Daghaghi et al. (Reference Daghaghi, Meisburger, Zhao and Shrivastava2021), where the authors try to revisit the algorithms used in machine learning to make them faster on CPUs rather than getting fixated with one-dimensional development of specific hardware to run the matrix multiplication faster. In this test case, the partition of the domain is performed by manually choosing the interface points. This was done to show the efficacy of the XPINN algorithm for nonconvex or irregular subdomains. In such complex subdomains, the distribution system often faces the problem of load imbalance, which can seriously degrade the performance of the system. A more efficient approach could be utilized to decompose the domain such that the subdomains are packed optimally for internode or interprocess communication. A suitable point cloud (Rusu and Cousins, Reference Rusu and Cousins2011) or K-way partition (Karypis and Kumar, Reference Karypis and Kumar2009) based approach will result in further optimizing the communication.
$ \left(9\mathrm{X}\right) $
for single- and double-precision arithmetic. We note that the residual points in each subdomain are not enough to saturate the GPUs and therefore more time is spent on fetching the data to memory and inter-GPU communication. To provide more intuition in the purview of the current implementation, for a typical V100 (16 GB) memory, the single-precision performance is 14 TFLOPs with a memory bandwidth of 900 GB/s and therefore for each byte of transfer (memory to GPU core) 15.6 instruction (FLOPs/Bandwidth) needs to be issued to occupy the GPUs completely. In the context of the current problem, the partition and therefore the load on GPUs (or CPUs) are static and does not change throughout the computation; thus, subdomain 7, endowed with only 800 residual points, has to wait until all the GPUs (or CPUs) complete their work for the respective subdomain. This also results in slight sublinear performance. However, the performance presented in Figure 11 shows a very good linear scaling for CPUs on a heterogeneous (CPU + GPU) architecture. Additionally, the scaling of the presented algorithm on CPUs only architecture concurs with the idea of Daghaghi et al. (Reference Daghaghi, Meisburger, Zhao and Shrivastava2021), where the authors try to revisit the algorithms used in machine learning to make them faster on CPUs rather than getting fixated with one-dimensional development of specific hardware to run the matrix multiplication faster. In this test case, the partition of the domain is performed by manually choosing the interface points. This was done to show the efficacy of the XPINN algorithm for nonconvex or irregular subdomains. In such complex subdomains, the distribution system often faces the problem of load imbalance, which can seriously degrade the performance of the system. A more efficient approach could be utilized to decompose the domain such that the subdomains are packed optimally for internode or interprocess communication. A suitable point cloud (Rusu and Cousins, Reference Rusu and Cousins2011) or K-way partition (Karypis and Kumar, Reference Karypis and Kumar2009) based approach will result in further optimizing the communication.
3. Graph Neural Networks
In contrast to more traditional machine learning (ML) data handled in image recognition or natural language processing, scientific data is fundamentally unstructured, requiring processing of polygonal finite element meshes, LIDAR point clouds, Lagrangian drifters, and other data formats involving scattered collections of differential forms. This poses both challenges and opportunities. Convolutional networks serve as a foundation for image processing, and are able to employ weight-sharing by exploiting the Cartesian structure of pixels, but cannot be applied in unstructured settings where stencils vary in size and shape from node to node. Unstructured data do, however, encode nontrivial topological information regarding connectivity, allowing application of ideas from topological data analysis and combinatorial Hodge theory (Carlsson, Reference Carlsson2009; Jiang et al., Reference Jiang, Lim, Yao and Ye2011; Bubenik, Reference Bubenik2015; Wasserman, Reference Wasserman2018). In contrast, GNNs form a class of deep neural network methods designed to handle unstructured data. Graphs serve as a flexible topological structure, which may be used for learning useful latent “graph-level,” “node-level,” or “edge-level” representations of data for diverse graph prediction tasks and analytics (Monti et al., Reference Monti, Boscaini, Masci, Rodola, Svoboda and Bronstein2017).
This unstructured nature enables GNNs to naturally handle a wide range of graph analytics problems (i.e., node classification, link prediction, data visualization, graph clustering community detection, anomaly detection) and have been applied effectively across a diverse range of domains, for example, protein structure prediction (Jumper et al., Reference Jumper, Evans, Pritzel, Green, Figurnov, Ronneberger, Tunyasuvunakool, Bates, Ždek, Potapenko, Bridgland, Meyer, SAA, Ballard, Cowie, Romera-Paredes, Nikolov, Jain, Adler, Back, Petersen, Reiman, Clancy, Zielinski, Steinegger, Pacholska, Berghammer, Bodenstein, Silver, Vinyals, Senior, Kavukcuoglu, Kohli and Hassabis2021), untangling the mathematics of knots (Davies et al., Reference Davies, Veličković, Buesing, Blackwell, Zheng, Tomašev, Tanburn, Battaglia, Blundell, Juhász, Lackenby, Williamson, Hassabis and Kohli2021), brain networks (Rosenthal et al., Reference Rosenthal, Váša, Griffa, Hagmann, Amico, Goñi, Avidan and Sporns2018; Xu et al., Reference Xu, Wang, Zhang, Pantazis, Wang and Li2020b, Reference Xu, Sanz, Garces, Maestu, Li and Pantazis2021a) in brain imaging, molecular networks (Liu et al., Reference Liu, Sun, Jia, Ma, Xing, Wu, Gao, Sun, Boulnois and Fan2019) in drug discovery, protein–protein interaction networks (Kashyap et al., Reference Kashyap, Kumar, Agarwal, Misra, Phadke and Kapoor2018) in genetics, social networks (Wang et al., Reference Wang, Feng, Chen, Yin, Guo and Chu2019b) in social media, bank-asset networks (Zhou and Li, Reference Zhou and Li2019) in finance, and publication networks (West et al., Reference West, Wesley-Smith and Bergstrom2016) in scientific collaborations.
In this section, we consider the task of fitting dynamics to data defined on a set of nodes
 $ \mathcal{N} $
, often associated with an embedding as vertices
$ \mathcal{N} $
, often associated with an embedding as vertices
 $ \mathcal{V}\subset {\mathrm{\mathbb{R}}}^d $
. We will consider the graph
$ \mathcal{V}\subset {\mathrm{\mathbb{R}}}^d $
. We will consider the graph
 $ \mathcal{G}=\left(\mathcal{V},\mathrm{\mathcal{E}}\right) $
, where
$ \mathcal{G}=\left(\mathcal{V},\mathrm{\mathcal{E}}\right) $
, where
 $ \mathrm{\mathcal{E}} $
represents the edge set denoted by
$ \mathrm{\mathcal{E}} $
represents the edge set denoted by
 $ \mathrm{\mathcal{E}}\subseteq \left(\begin{array}{l}\mathcal{V}\\ {}2\end{array}\right) $
. We will also consider higher-order k-cliques consisting of ordered k-tuples of nodes, where for example, an edge
$ \mathrm{\mathcal{E}}\subseteq \left(\begin{array}{l}\mathcal{V}\\ {}2\end{array}\right) $
. We will also consider higher-order k-cliques consisting of ordered k-tuples of nodes, where for example, an edge
 $ e\in \mathrm{\mathcal{E}} $
corresponds to a 2-clique. We associate scalar values
$ e\in \mathrm{\mathcal{E}} $
corresponds to a 2-clique. We associate scalar values
 $ \boldsymbol{x} $
with nodes, edges, or both, and aim to either learn dynamics (
$ \boldsymbol{x} $
with nodes, edges, or both, and aim to either learn dynamics (
 $ \dot{\boldsymbol{x}}=L\left(\boldsymbol{x};\theta \right) $
) or boundary value problems (
$ \dot{\boldsymbol{x}}=L\left(\boldsymbol{x};\theta \right) $
) or boundary value problems (
 $ L\left(\boldsymbol{x};\theta \right)=f $
) for learnable parameters
$ L\left(\boldsymbol{x};\theta \right)=f $
) for learnable parameters
 $ \theta $
.
$ \theta $
.
We present three approaches: (a) methods which aim to learn operators via finite difference-like stencils, (b) GNNs which represent operators by learning update and aggregation maps, and (c) graph calculus methods, which relate learnable operators to graph analogs of the familiar vector calculus div/grad/curl. First, we survey prevailing strategies and architectures for traditional GNNs.
3.1. Basics of GNNs
Broadly, GNNs may be classified into three major categories: (a) Spectral GNNs, which locally aggregate connected node information by solving eigenproblems in the spectral domain. (b) Spatial GNNs, which perform graph convolution via aggregating node neighbor information from the first-hop neighbors in the spatial graph domain. (c) Graph attention networks (GATs), which leverage the self-attention mechanism for hidden feature aggregation. We recall first some mathematical definitions before presenting each in turn.
3.1.1. Notation and mathematical preliminaries
Consider a node
 $ {v}_i\in \mathcal{V} $
and
$ {v}_i\in \mathcal{V} $
and
 $ {e}_{i,j}=\{{v}_i,{v}_j\}\in \mathrm{\mathcal{E}} $
indicating either a directed or undirected edge between nodes
$ {e}_{i,j}=\{{v}_i,{v}_j\}\in \mathrm{\mathcal{E}} $
indicating either a directed or undirected edge between nodes
 $ {v}_i $
and
$ {v}_i $
and
 $ {v}_j $
. By
$ {v}_j $
. By
 $ j\sim i $
, we denote neighbors
$ j\sim i $
, we denote neighbors
 $ j $
with corresponding edges
$ j $
with corresponding edges
 $ \left(i,j\right) $
coincident upon node
$ \left(i,j\right) $
coincident upon node
 $ i $
.
$ i $
.
 $ \mathbf{A}\in {\mathrm{\mathbb{R}}}^{N\times N} $
corresponds to the adjacency matrix of
$ \mathbf{A}\in {\mathrm{\mathbb{R}}}^{N\times N} $
corresponds to the adjacency matrix of
 $ \mathcal{G} $
. When
$ \mathcal{G} $
. When
 $ \mathcal{G} $
is binary (or “unweighted”),
$ \mathcal{G} $
is binary (or “unweighted”),
 $ {\mathbf{A}}_{i,j}=1 $
if there is an edge between nodes
$ {\mathbf{A}}_{i,j}=1 $
if there is an edge between nodes
 $ {v}_i $
and
$ {v}_i $
and
 $ {v}_j $
, else 0. If
$ {v}_j $
, else 0. If
 $ \mathcal{G} $
is a weighted graph,
$ \mathcal{G} $
is a weighted graph,
 $ {\mathbf{A}}_{i,j}={w}_{\mathrm{ij}} $
when there is an edge between nodes
$ {\mathbf{A}}_{i,j}={w}_{\mathrm{ij}} $
when there is an edge between nodes
 $ {v}_i $
and
$ {v}_i $
and
 $ {v}_j $
. A graph is homogeneous if all nodes and edges are of a single type, and vice versa, the graph is heterogeneous if it consists of multiple types of nodes and edges. Additionally, each node may be associated with features (or attributes)
$ {v}_j $
. A graph is homogeneous if all nodes and edges are of a single type, and vice versa, the graph is heterogeneous if it consists of multiple types of nodes and edges. Additionally, each node may be associated with features (or attributes)
 $ \mathbf{x}\in {\mathrm{\mathbb{R}}}^{N\times F} $
referring to the node attribute matrix of
$ \mathbf{x}\in {\mathrm{\mathbb{R}}}^{N\times F} $
referring to the node attribute matrix of
 $ \mathcal{G} $
. The entry
$ \mathcal{G} $
. The entry
 $ {x}_i\in \mathbf{x} $
corresponds to the node feature vector of node
$ {x}_i\in \mathbf{x} $
corresponds to the node feature vector of node
 $ {v}_i $
. The graph Laplacian matrix is an
$ {v}_i $
. The graph Laplacian matrix is an
 $ N\times N $
matrix defined as
$ N\times N $
matrix defined as
 $ \mathbf{L}=\mathbf{D}-\mathbf{A} $
, where
$ \mathbf{L}=\mathbf{D}-\mathbf{A} $
, where
 $ \mathbf{D} $
is a
$ \mathbf{D} $
is a
 $ N\times N $
diagonal node degree matrix whose
$ N\times N $
diagonal node degree matrix whose
 $ i $
th element is the degree of the node
$ i $
th element is the degree of the node
 $ i $
, that is,
$ i $
, that is,
 $ \mathbf{D}\left(i,i\right)={\sum}_{j=1}^N{A}_{i,j} $
.
$ \mathbf{D}\left(i,i\right)={\sum}_{j=1}^N{A}_{i,j} $
.
3.1.2. Spectral methods
The main idea of spectral GNN approaches is to use Eigen-decompositions of the graph Laplacian matrix
 $ \mathbf{L} $
to generalize spatial convolutions to graph structured data. This allows simultaneous access to information over short and long time scales (Bruna et al., Reference Bruna, Zaremba, Szlam and LeCun2013). Spectral graph convolutions are defined in the spectral domain based on the graph Fourier transform.
$ \mathbf{L} $
to generalize spatial convolutions to graph structured data. This allows simultaneous access to information over short and long time scales (Bruna et al., Reference Bruna, Zaremba, Szlam and LeCun2013). Spectral graph convolutions are defined in the spectral domain based on the graph Fourier transform.
Specifically, the normalized self-adjoint positive-semidefinite graph Laplacian matrix
 $ \mathbf{L} $
describes diffusion over a graph (Chung and Graham, Reference Chung and Graham1997), and can be factorized by
$ \mathbf{L} $
describes diffusion over a graph (Chung and Graham, Reference Chung and Graham1997), and can be factorized by
 $ \mathbf{L}=U\Lambda {U}^T $
.
$ \mathbf{L}=U\Lambda {U}^T $
.
 $ U $
is
$ U $
is
 $ N\times N $
matrix whose
$ N\times N $
matrix whose
 $ l $
th column is the eigenvector (
$ l $
th column is the eigenvector (
 $ {u}_l $
) of
$ {u}_l $
) of
 $ \mathbf{L} $
;
$ \mathbf{L} $
;
 $ \Lambda $
is a diagonal matrix whose diagonal elements
$ \Lambda $
is a diagonal matrix whose diagonal elements
 $ {\lambda}_l=\Lambda \left(l,l\right) $
(
$ {\lambda}_l=\Lambda \left(l,l\right) $
(
 $ l\in {\mathrm{\mathcal{R}}}^N $
) are the corresponding eigenvalues. We can apply the operation
$ l\in {\mathrm{\mathcal{R}}}^N $
) are the corresponding eigenvalues. We can apply the operation
 $ {U}^T\phi $
to project data
$ {U}^T\phi $
to project data
 $ \phi $
from graph nodes into the spectral domain, where features can be decomposed into a sum of orthogonal graphlets or motifs (i.e., eigenvectors) that make up
$ \phi $
from graph nodes into the spectral domain, where features can be decomposed into a sum of orthogonal graphlets or motifs (i.e., eigenvectors) that make up
 $ \mathcal{G} $
. Typically, eigenvectors with the smallest eigenvalues may be used to distinguish vertices that will be slowest to share information under diffusion or message passing. Projecting vertex features onto these eigenvectors and processing the projected graph signal is equivalent to augmenting message passing with a nonlinear low-pass filter.
$ \mathcal{G} $
. Typically, eigenvectors with the smallest eigenvalues may be used to distinguish vertices that will be slowest to share information under diffusion or message passing. Projecting vertex features onto these eigenvectors and processing the projected graph signal is equivalent to augmenting message passing with a nonlinear low-pass filter.
Recently, many spectral GNN variants have been proposed, for example, Bruna et al. (Reference Bruna, Zaremba, Szlam and LeCun2013) and Kipf and Welling (Reference Kipf and Welling2016). The main workflow of spectral GNNs follows four main steps: (a) transform the graph to the spectral domain using the graph Laplacian eigenfunctions (see Equation (12)); (b) perform the same transformation on the graph convolutional filters; (c) apply convolutions in the spectral domain; (d) transform from the spectral domain back to the original graph domain (see Equation (13)):
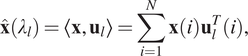 $$ \hat{\mathbf{x}}\left({\lambda}_l\right)=\left\langle \mathbf{x},{\mathbf{u}}_l\right\rangle =\sum \limits_{i=1}^N\mathbf{x}(i){\mathbf{u}}_l^T(i), $$
$$ \hat{\mathbf{x}}\left({\lambda}_l\right)=\left\langle \mathbf{x},{\mathbf{u}}_l\right\rangle =\sum \limits_{i=1}^N\mathbf{x}(i){\mathbf{u}}_l^T(i), $$
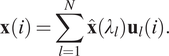 $$ \mathbf{x}(i)=\sum \limits_{l=1}^N\hat{\mathbf{x}}\left({\lambda}_l\right){\mathbf{u}}_l(i). $$
$$ \mathbf{x}(i)=\sum \limits_{l=1}^N\hat{\mathbf{x}}\left({\lambda}_l\right){\mathbf{u}}_l(i). $$
The detailed spectral graph convolution operation is described in Equation (14), where
 $ U $
is the eigenvector matrix,
$ U $
is the eigenvector matrix,
 $ {X}^{(k)} $
represents the node feature map at the
$ {X}^{(k)} $
represents the node feature map at the
 $ k $
th layer, and
$ k $
th layer, and
 $ {W}^{(k)} $
denotes the learnable spectral graph convolutional filters at the
$ {W}^{(k)} $
denotes the learnable spectral graph convolutional filters at the
 $ k $
th layer.
$ k $
th layer.
 $$ {X}^{\left(k+1\right)}=U\left({U}^T{X}^{(k)}\odot {U}^T{W}^{(k)}\right). $$
$$ {X}^{\left(k+1\right)}=U\left({U}^T{X}^{(k)}\odot {U}^T{W}^{(k)}\right). $$
However, the aforementioned spectral GNN methods share a few significant weaknesses: the Laplacian eigenfunctions are inconsistent across different domains, and therefore the method generalizes poorly across different geometries. Moreover, the spectral convolution filter is applied for the whole graph without considering the local graph structure property. In addition, the graph Fourier transform has high cost in computation. To solve the locality and efficiency problem, ChebNets (Defferrard et al., Reference Defferrard, Bresson and Vandergheynst2016) employs the Chebyshev polynomial basis to represent spectral convolution filter instead of graph Laplacian eigenvectors.
3.1.3. Spatial methods
Spatial methods involve a form of learnable message-passing that propagates information over the graph via a local aggregation (or diffusion) process. Graph convolutions are defined directly on the graph topology in spatial methods (Atwood and Towsley, Reference Atwood and Towsley2016; Niepert et al., Reference Niepert, Ahmed and Kutzkov2016; Gilmer et al., Reference Gilmer, Schoenholz, Riley, Vinyals and Dahl2017). Spatial Graph Convolutional Networks (GCNs) directly ignore the “edge attributes” as well as the crucial “messages” sent by nodes along edges in the graph, however, the Message Passing Neural Networks (MPNNs) can effectively make use of this information to update node states. MPNN consists of three main phases: message passing, readout, and classification. Message passing consists of: (a) A node feature transformation based on some sort of projection. (b) Node feature aggregation with a permutation-invariant function, for example, averaging, sum, or concatenation. (c) A node feature update via the current states and representations aggregated from each node’s neighborhood. Specifically, the message passing runs for
 $ T $
time steps, and includes two key components: message functions
$ T $
time steps, and includes two key components: message functions
 $ {M}_t $
and node update functions
$ {M}_t $
and node update functions
 $ {U}_t $
. The hidden states
$ {U}_t $
. The hidden states
 $ {h}_i^t $
at each node in the graph are updated based on Equation (15) with the current state (
$ {h}_i^t $
at each node in the graph are updated based on Equation (15) with the current state (
 $ {h}_i^t $
) and the aggregated messages
$ {h}_i^t $
) and the aggregated messages
 $ {m}_i^{t+1} $
, which are computed from neighboring nodes’ feature (
$ {m}_i^{t+1} $
, which are computed from neighboring nodes’ feature (
 $ {h}_j^t $
) and edge features (
$ {h}_j^t $
) and edge features (
 $ {e}_{\mathrm{ij}} $
) according to Equation (16).
$ {e}_{\mathrm{ij}} $
) according to Equation (16).
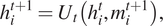 $$ {h}_i^{t+1}={U}_t\left({h}_i^t,{m}_i^{t+1}\right), $$
$$ {h}_i^{t+1}={U}_t\left({h}_i^t,{m}_i^{t+1}\right), $$
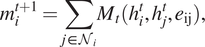 $$ {m}_i^{t+1}=\sum \limits_{j\in {\mathcal{N}}_i}{M}_t({h}_i^t,{h}_j^t,{e}_{\mathrm{ij}}), $$
$$ {m}_i^{t+1}=\sum \limits_{j\in {\mathcal{N}}_i}{M}_t({h}_i^t,{h}_j^t,{e}_{\mathrm{ij}}), $$
where
 $ {\mathcal{N}}_i $
denotes the neighbors of node
$ {\mathcal{N}}_i $
denotes the neighbors of node
 $ i $
. The readout phase computes a feature vector for the whole graph using some readout function
$ i $
. The readout phase computes a feature vector for the whole graph using some readout function
 $ R $
according to
$ R $
according to
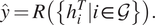 $$ \hat{y}=R\left(\left\{{h}_i^T|i\in \mathcal{G}\right\}\right). $$
$$ \hat{y}=R\left(\left\{{h}_i^T|i\in \mathcal{G}\right\}\right). $$
The message functions
 $ {M}_t $
, node update functions
$ {M}_t $
, node update functions
 $ {U}_t $
and readout function (
$ {U}_t $
and readout function (
 $ R $
) are all learned differentiable functions. Additionally,
$ R $
) are all learned differentiable functions. Additionally,
 $ R $
must be invariant to node permutation (i.e., graph isomorphism) to guarantee identical output for equivalent graphs.
$ R $
must be invariant to node permutation (i.e., graph isomorphism) to guarantee identical output for equivalent graphs.
3.1.4. Graph attention networks
In spectral and spatial GNN models, the message aggregation operations from nodes’ neighborhoods are mostly guided by the graph structure, which weights contributions from neighboring nodes equally. In contrast, GATs (Veličković et al., Reference Veličković, Cucurull, Casanova, Romero, Lio and Bengio2017) assign during aggregation a learnable propagation weight via a “self-attention” function (
 $ \alpha $
), defined in Equation (17). Specifically, given the node pair feature vectors (
$ \alpha $
), defined in Equation (17). Specifically, given the node pair feature vectors (
 $ {\overrightarrow{h}}_i $
and
$ {\overrightarrow{h}}_i $
and
 $ {\overrightarrow{h}}_j $
), the attention coefficients (
$ {\overrightarrow{h}}_j $
), the attention coefficients (
 $ {e}_{i,j} $
) between nodes
$ {e}_{i,j} $
) between nodes
 $ i $
and
$ i $
and
 $ j $
can be computed by using a self-attention mechanism
$ j $
can be computed by using a self-attention mechanism
 $ a:{\mathrm{\mathbb{R}}}^{F^{\prime }}\times {\mathrm{\mathbb{R}}}^{F^{\prime }}\to \mathrm{\mathbb{R}} $
(
$ a:{\mathrm{\mathbb{R}}}^{F^{\prime }}\times {\mathrm{\mathbb{R}}}^{F^{\prime }}\to \mathrm{\mathbb{R}} $
(
 $ {F}^{\prime } $
is the node feature size), which is usually implemented by a single-layer feed-forward neural network. To this end, the attention mechanism can help identify the importance of interactions between each node neighbor. Here,
$ {F}^{\prime } $
is the node feature size), which is usually implemented by a single-layer feed-forward neural network. To this end, the attention mechanism can help identify the importance of interactions between each node neighbor. Here,
 $ {c}_{i,j} $
reflects the importance of node
$ {c}_{i,j} $
reflects the importance of node
 $ j $
’s feature to node
$ j $
’s feature to node
 $ i $
. For better comparability across all nodes in the graph, the normalized attention coefficients (
$ i $
. For better comparability across all nodes in the graph, the normalized attention coefficients (
 $ {\alpha}_{i,j} $
) between node pair
$ {\alpha}_{i,j} $
) between node pair
 $ \left(i,j\right) $
can be defined as a softmax function (see Equation (17)), where
$ \left(i,j\right) $
can be defined as a softmax function (see Equation (17)), where
 $ {\mathcal{N}}_i $
denote the neigborhood of node
$ {\mathcal{N}}_i $
denote the neigborhood of node
 $ i $
, that is, first-order neighbors.
$ i $
, that is, first-order neighbors.
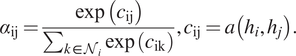 $$ {\alpha}_{\mathrm{ij}}=\frac{\exp \left({c}_{\mathrm{ij}}\right)}{\sum_{k\in {\mathcal{N}}_i}\exp \left({c}_{\mathrm{ik}}\right)},{c}_{\mathrm{ij}}=a\left({h}_i,{h}_j\right). $$
$$ {\alpha}_{\mathrm{ij}}=\frac{\exp \left({c}_{\mathrm{ij}}\right)}{\sum_{k\in {\mathcal{N}}_i}\exp \left({c}_{\mathrm{ik}}\right)},{c}_{\mathrm{ij}}=a\left({h}_i,{h}_j\right). $$
In practice, a multihead attention mechanism has been widely used in GATs which can stabilize the process by using
 $ K $
independent attention mechanisms to achieve the transformation. The corresponding learned node feature for node
$ K $
independent attention mechanisms to achieve the transformation. The corresponding learned node feature for node
 $ i $
with multihead attention mechanism (Vaswani et al., Reference Vaswani, Shazeer, Parmar, Uszkoreit, Jones, Gomez, Kaiser and Polosukhin2017) is shown in Equation (18).
$ i $
with multihead attention mechanism (Vaswani et al., Reference Vaswani, Shazeer, Parmar, Uszkoreit, Jones, Gomez, Kaiser and Polosukhin2017) is shown in Equation (18).
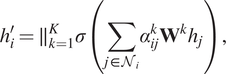 $$ {h}_i^{\prime }={\parallel}_{k=1}^K\sigma \left(\sum \limits_{j\in {\mathcal{N}}_i}{\alpha}_{ij}^k{\mathbf{W}}^k{h}_j\right), $$
$$ {h}_i^{\prime }={\parallel}_{k=1}^K\sigma \left(\sum \limits_{j\in {\mathcal{N}}_i}{\alpha}_{ij}^k{\mathbf{W}}^k{h}_j\right), $$
where
 $ {\alpha}_{\mathrm{ij}}^k $
denotes the attention coefficients derived by the
$ {\alpha}_{\mathrm{ij}}^k $
denotes the attention coefficients derived by the
 $ k $
th attention head;
$ k $
th attention head;
 $ {\mathbf{W}}^k $
is the weight matrix specifying the linear transformation of the
$ {\mathbf{W}}^k $
is the weight matrix specifying the linear transformation of the
 $ k $
th attention head;
$ k $
th attention head;
 $ \sigma $
is the nonlinear activation function;
$ \sigma $
is the nonlinear activation function;
 $ \parallel $
represents ultimate concatenation, sum or average operation for the features learned by
$ \parallel $
represents ultimate concatenation, sum or average operation for the features learned by
 $ K $
independent attention heads.
$ K $
independent attention heads.
In summary, GCNs are a special case of GATs which use the spectral normalized graph adjacency matrix to serve the role of the attention function. GATs are a special case of MPNNs with hidden feature aggregation by using self-attention mechanism as message passing rule. All methods share common inductive bias and node/edge permutation invariance properties. Lastly, there are also some works (DyRep [Trivedi et al., Reference Trivedi, Farajtabar, Biswal and Zha2019], EvolveGCN [Pareja et al., Reference Pareja, Domeniconi, Chen, Ma, Suzumura, Kanezashi, Kaler, Schardl and Leiserson2020], TGN [Rossi et al., Reference Rossi, Chamberlain, Frasca, Eynard, Monti and Bronstein2020], DynG2G [Xu et al., Reference Xu, Singh and Karniadakis2021b], etc.) for dynamic graph structure data inference (climate network, traffic network, etc.).
3.2. Learning stencil operators
In this section, we consider learning operators expressed via a discrete stencil
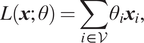 $$ L\left(\boldsymbol{x};\theta \right)=\sum \limits_{i\in \mathcal{V}}{\theta}_i{\boldsymbol{x}}_i, $$
$$ L\left(\boldsymbol{x};\theta \right)=\sum \limits_{i\in \mathcal{V}}{\theta}_i{\boldsymbol{x}}_i, $$
where the learnable parameters
 $ {\theta}_i $
correspond to stencil coefficients. An attractive feature of this simple setup is that differential operators may be encoded as a finite difference stencil. However, unlike traditional finite difference methods, often we consider a fixed size graph and do not consider a sequence of refined grids which converge to some continuum operator. Therefore, we are more interested in recovering an effective discrete operator in the traditional finite difference sense.
$ {\theta}_i $
correspond to stencil coefficients. An attractive feature of this simple setup is that differential operators may be encoded as a finite difference stencil. However, unlike traditional finite difference methods, often we consider a fixed size graph and do not consider a sequence of refined grids which converge to some continuum operator. Therefore, we are more interested in recovering an effective discrete operator in the traditional finite difference sense.
In Bar-Sinai et al. (Reference Bar-Sinai, Hoyer, Hickey and Brenner2019), the authors repurpose a convolutional network to this end. We note that this corresponds to a graph in which
 $ \mathcal{V} $
consists of a Cartesian grid of nodes, while
$ \mathcal{V} $
consists of a Cartesian grid of nodes, while
 $ \mathrm{\mathcal{E}}=\left\{\left(i,j\right)\hskip0.1em |\Big],{\left|{x}_i-{x}_j\right|}_1<\varepsilon \right\} $
consists of neighbor nodes in an
$ \mathrm{\mathcal{E}}=\left\{\left(i,j\right)\hskip0.1em |\Big],{\left|{x}_i-{x}_j\right|}_1<\varepsilon \right\} $
consists of neighbor nodes in an
 $ \varepsilon $
ball in the taxicab norm; see also Figure 12. While simple, this work is extremely interpretable, and the authors demonstrate an ability to learn stencils for Burgers, Korteweg–de Vries, and Kuramoto–Sivashinsky equations with improved error compared to a naive application of the finite difference method. We recall from introductory finite difference methods (Gustafsson et al., Reference Gustafsson, Kreiss and Oliger1995) that schemes such as the Lax–Wendroff or Macormack schemes introduce higher-order dissipation or dispersion into a discrete operator to achieve improved accuracy or stability. A simple Taylor series analysis reveals such schemes incorporate higher-order differential correction terms which depend on the spatiotemporal resolution, hence learning finite difference stencils may also learn similar higher-order corrections from data.
$ \varepsilon $
ball in the taxicab norm; see also Figure 12. While simple, this work is extremely interpretable, and the authors demonstrate an ability to learn stencils for Burgers, Korteweg–de Vries, and Kuramoto–Sivashinsky equations with improved error compared to a naive application of the finite difference method. We recall from introductory finite difference methods (Gustafsson et al., Reference Gustafsson, Kreiss and Oliger1995) that schemes such as the Lax–Wendroff or Macormack schemes introduce higher-order dissipation or dispersion into a discrete operator to achieve improved accuracy or stability. A simple Taylor series analysis reveals such schemes incorporate higher-order differential correction terms which depend on the spatiotemporal resolution, hence learning finite difference stencils may also learn similar higher-order corrections from data.
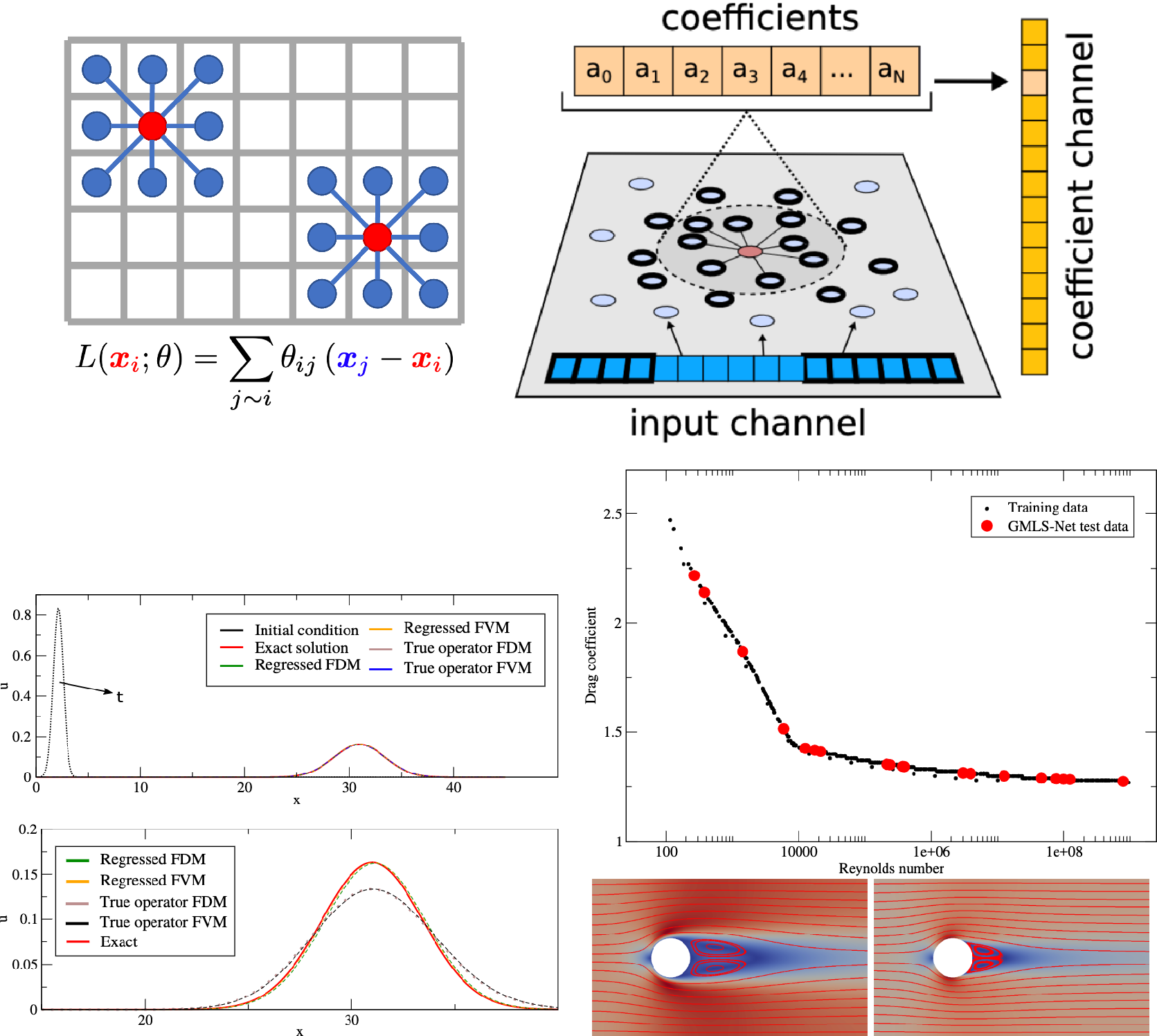
Figure 12. Learning operators from stencils. From left to right, top to bottom: (a) On a Cartesian grid of data, CNNs may employ weight-sharing to fit finite-difference operators to data (Bar-Sinai et al., Reference Bar-Sinai, Hoyer, Hickey and Brenner2019). (b) On unstructured data, similar weight-sharing may be achieved by lifting data first to a space of polynomial coefficients and learning how an operator acts on polynomials. (c) Learning operators as difference stencils allows learning of higher-order corrections. Shown here at a CFL condition of 10, a stencil learned from an analytic solution to the advection–diffusion problem does not exhibit the numerical dissipation of a traditional finite difference/volume discretization of the PDE. (d) Beyond learning physics, these frameworks can be used for supervised learning tasks on unstructured scientific data. Shown here, the drag force acting on a cylinder is regressed from nodal velocities on an unstructured finite volume mesh. Figures adapted from Trask et al. (Reference Trask, Patel, Gross and Atzberger2019).
The requirement of a Cartesian node set is, however, restrictive and precludes application to complex geometries. In Trask et al. (Reference Trask, Patel, Gross and Atzberger2019) unstructured data is handled by finding a polynomial fit to data at each node of an unstructure
 $ \varepsilon - $
ball graph and then providing the resulting coefficient weights to a multilayer perceptron.
$ \varepsilon - $
ball graph and then providing the resulting coefficient weights to a multilayer perceptron.
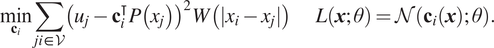 $$ \underset{{\mathbf{c}}_i}{\min}\sum \limits_{ji\in \mathcal{V}}{\left({u}_j-{\mathbf{c}}_i^{\intercal }P\left({x}_j\right)\right)}^2W\left(|{x}_i-{x}_j|\right)\hskip2em L\left(\boldsymbol{x};\theta \right)=\mathcal{N}\left({\mathbf{c}}_i\left(\boldsymbol{x}\right);\theta \right). $$
$$ \underset{{\mathbf{c}}_i}{\min}\sum \limits_{ji\in \mathcal{V}}{\left({u}_j-{\mathbf{c}}_i^{\intercal }P\left({x}_j\right)\right)}^2W\left(|{x}_i-{x}_j|\right)\hskip2em L\left(\boldsymbol{x};\theta \right)=\mathcal{N}\left({\mathbf{c}}_i\left(\boldsymbol{x}\right);\theta \right). $$
Here,
 $ P $
denotes a vector of polynomial basis functions,
$ P $
denotes a vector of polynomial basis functions,
 $ W $
denotes a radial kernel with support
$ W $
denotes a radial kernel with support
 $ {B}_{\varepsilon}\left({x}_i\right) $
, and
$ {B}_{\varepsilon}\left({x}_i\right) $
, and
 $ \mathcal{N} $
denotes a multilayer perceptron with weights and biases
$ \mathcal{N} $
denotes a multilayer perceptron with weights and biases
 $ \theta $
taking the optimal polynomial reconstruction as input. In Trask et al. (Reference Trask, Patel, Gross and Atzberger2019), this architecture is shown to be effective for both learning physical operators on unstructured data as well as offering an alternative to spectral GNNs for supervised learning on structured and unstructured data; see Figure 12. This framework builds upon the generalized moving least squares (GMLS) theory, which has traditionally been used to develop finite difference discretizations on unstructured points (Mirzaei et al., Reference Mirzaei, Schaback and Dehghan2012). In relation to spectral GNNs, replacing a global spectral approximation with a localized polynomial approximation, which may be trivially accelerated with GPUs (Kuberry et al., Reference Kuberry, Bosler and Trask2019) is attractive from both performance and approximation perspectives.
$ \theta $
taking the optimal polynomial reconstruction as input. In Trask et al. (Reference Trask, Patel, Gross and Atzberger2019), this architecture is shown to be effective for both learning physical operators on unstructured data as well as offering an alternative to spectral GNNs for supervised learning on structured and unstructured data; see Figure 12. This framework builds upon the generalized moving least squares (GMLS) theory, which has traditionally been used to develop finite difference discretizations on unstructured points (Mirzaei et al., Reference Mirzaei, Schaback and Dehghan2012). In relation to spectral GNNs, replacing a global spectral approximation with a localized polynomial approximation, which may be trivially accelerated with GPUs (Kuberry et al., Reference Kuberry, Bosler and Trask2019) is attractive from both performance and approximation perspectives.
3.3. Physics-informed graph networks
The stencil formulation of the previous section prompts a natural interpretation of GNNs in the context of finite difference methods. In staggered finite difference schemes for PDEs, one uses a stencil to compute a conservation balance (e.g., a divergence operator for conservation of fluxes in marker-and-cell schemes for transport (Harlow and Welch, Reference Harlow and Welch1965), or a curl operator for circulations in the Yee scheme for electromagnetism (Yee, Reference Yee1966) from fluxes/circulations computed on a dual grid. The aggregation step of GNNs admits interpretation as a graph divergence, with message passing corresponding to learning fluxes/circulations. In Kumar and Chakraborty (Reference Kumar and Chakraborty2021), the authors apply this viewpoint, using an attention mechanism (Veličković et al., Reference Veličković, Cucurull, Casanova, Romero, Liò and Bengio2018) to learn messages from data. They demonstrate accurate prediction of solution operators for the viscous Burgers equations in one- and two-dimensions.
In Pfaff et al. (Reference Pfaff, Fortunato, Sanchez-Gonzalez and Battaglia2020), the authors consider a similar message-passing GNN where the graph is taken to be a traditional simulation mesh. By augmenting the network with edge features encoding the displacement of the domain from a reference configuration, they demonstrate how GNNs may be used to train surrogates of physics-based models from high-fidelity simulations on unstructured meshes in either an Eulerian or Lagrangian configuration. They demonstrate speed ups of
 $ 10-100\times $
for cloth dynamics, elasticity, and compressible flows and attribute good generalization beyond parameters used in training to invariances preserved by the GNN architecture. Also, worth noting is favorable comparison against convolutional methods, where message-passing GNNs provide improved accuracy.
$ 10-100\times $
for cloth dynamics, elasticity, and compressible flows and attribute good generalization beyond parameters used in training to invariances preserved by the GNN architecture. Also, worth noting is favorable comparison against convolutional methods, where message-passing GNNs provide improved accuracy.
Whereas this is a useful perspective of learning operators to mimic integral balance equations corresponding to PDE models of physics, for design of “systems-of-systems” one may use a graph to represent individual subsystems as nodes and their interactions via edges. This often corresponds to characterizing a control volume consisting of an entire subsystem, rather than an infinitesimal volume. In Hall et al. (Reference Hall, Taverniers, Katsoulakis and Tartakovsky2021), the authors develop graph informed neural networks (GINNs) which employ a probabilistic graph model to perform system scale design of supercapacitor dynamics and a Langmuir adsorption model. While the Bayesian network architecture is distinct from the GNN architectures discussed in the previous section, their work provides an example of how graph architectures may be used to replace computationally intensive bottlenecks in system dynamics. In other frameworks aligning more closely with GNNs, similar strategies may be used to learn and design, for example, system-level circuit design with constituent data-driven device physics (Gao et al., Reference Gao, Huang, Trask and Reza2020) or heat transfer of industrial buildings (Drgoňa et al., Reference Drgoňa, Tuor, Chandan and Vrabie2021).
3.4. Graph exterior calculus
Exterior calculus has been used as a tool for designing mimetic discretizations of PDEs, which preserve structure and properties from continuum solutions such as conservation, maximum principles, nonoscillatory solutions near material discontinuities, and preservation of invariants (Arnold et al., Reference Arnold, Bochev, Lehoucq, Nicolaides and Shashkov2007). These methods exploit connections to the generalized Stokes theorem to construct a data-driven
 $ deRhamcomplex $
—a commuting diagram (see Figure 13) which allows a unified analysis of discretizations spanning mixed finite elements, staggered finite difference schemes, and mimetic difference methods (Bochev and Hyman, Reference Bochev and Hyman2006). Graphs admit a similar combinatorial de Rham complex based upon graph extensions of the familiar vector calculus div/grad/curl, which allows rigorous analysis of Hodge Laplacians generalizing the previously discussed graph Laplacian. We discuss several recent works which use this as a basis for machine learning.
$ deRhamcomplex $
—a commuting diagram (see Figure 13) which allows a unified analysis of discretizations spanning mixed finite elements, staggered finite difference schemes, and mimetic difference methods (Bochev and Hyman, Reference Bochev and Hyman2006). Graphs admit a similar combinatorial de Rham complex based upon graph extensions of the familiar vector calculus div/grad/curl, which allows rigorous analysis of Hodge Laplacians generalizing the previously discussed graph Laplacian. We discuss several recent works which use this as a basis for machine learning.
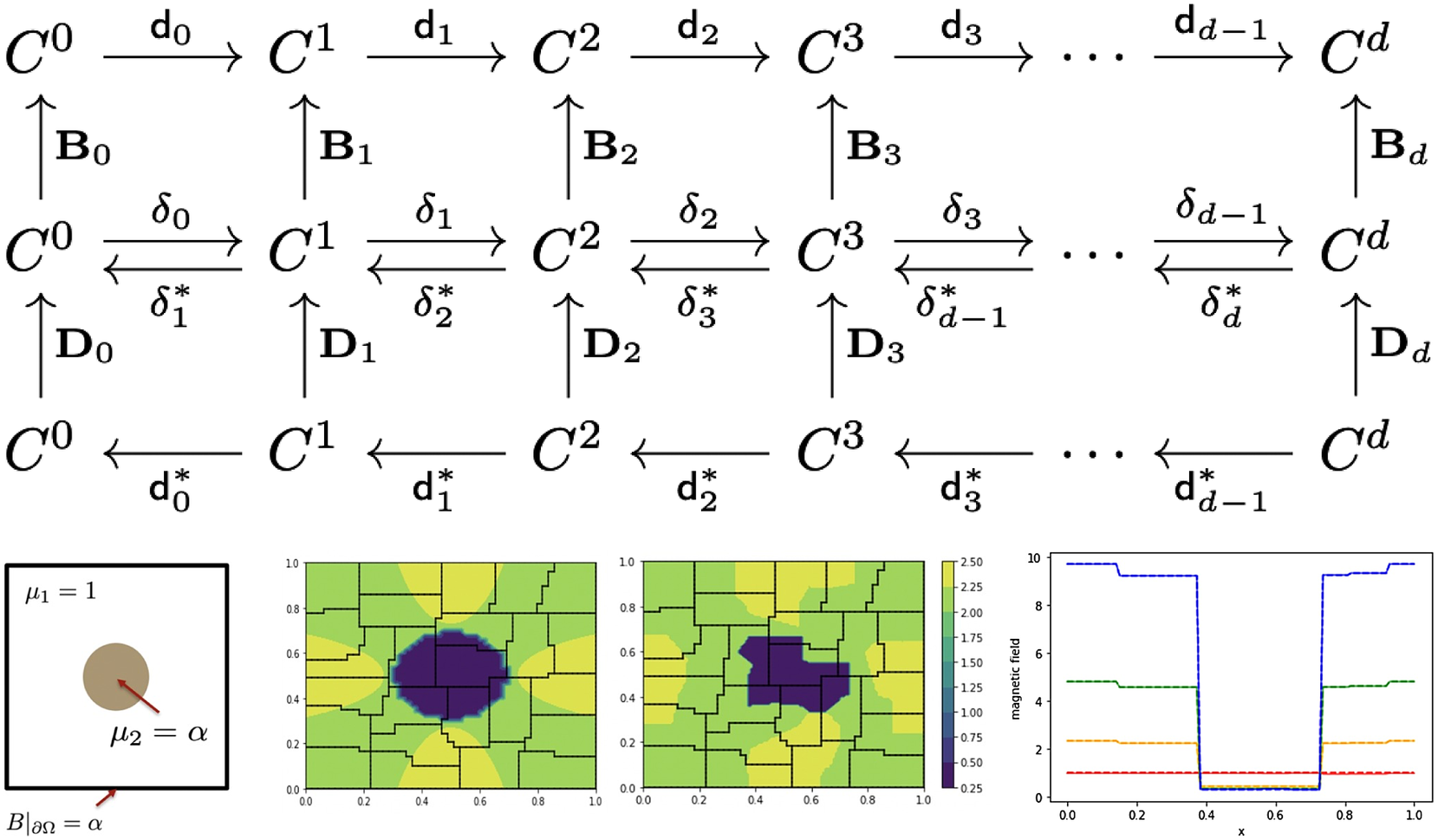
Figure 13. Graph exterior calculus for physics-informed GNNs. Top: The graph calculus div/grad/curl (
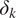 $ {\delta}_k $
) and their adjoint (
$ {\delta}_k $
) and their adjoint (
 $ {\delta}_k^{\ast } $
) may be augmented with machine learnable metric information (
$ {\delta}_k^{\ast } $
) may be augmented with machine learnable metric information (
 $ {\mathbf{B}}_k,{\mathbf{D}}_k $
) to obtain a de Rham complex, which preserves algebraic structure related to stability and physical invariances. Bottom, left to right: To construct a surrogate for a heterogeneous magnetostatics inclusion problem parameterized by the jump in permittivity
$ {\mathbf{B}}_k,{\mathbf{D}}_k $
) to obtain a de Rham complex, which preserves algebraic structure related to stability and physical invariances. Bottom, left to right: To construct a surrogate for a heterogeneous magnetostatics inclusion problem parameterized by the jump in permittivity
 $ \alpha $
(a), we train a GNN to reproduce solution moments of a high-fidelity solution (b) on a coarse grid (c) while preserving conservation structure. A plot of the magnetic field across
$ \alpha $
(a), we train a GNN to reproduce solution moments of a high-fidelity solution (b) on a coarse grid (c) while preserving conservation structure. A plot of the magnetic field across
 $ y=0.5 $
reveals the predicted solution (dashed) matches the data (solid) to machine precision for a range of jumps (
$ y=0.5 $
reveals the predicted solution (dashed) matches the data (solid) to machine precision for a range of jumps (
 $ \alpha =\mathrm{1,2,4,8} $
in red/yellow/green/blue, respectively), demonstrating the scheme handles jumps in material properties for problems with nontrivial null-spaces, similar to mimetic PDE discretizations. Figure adapted from Trask et al. (Reference Trask, Huang and Hu2022).
$ \alpha =\mathrm{1,2,4,8} $
in red/yellow/green/blue, respectively), demonstrating the scheme handles jumps in material properties for problems with nontrivial null-spaces, similar to mimetic PDE discretizations. Figure adapted from Trask et al. (Reference Trask, Huang and Hu2022).
Given a collection of
 $ k- $
cliques with associated scalar values, one may define a graph calculus. Denote the scalar value associated with a
$ k- $
cliques with associated scalar values, one may define a graph calculus. Denote the scalar value associated with a
 $ k- $
clique
$ k- $
clique
 $ {f}_{i_1,\dots, {i}_k} $
, which is by convention skew-symmetric with respect to an odd permutation of subset indices. For example, a combinatorial gradient maps 1-cliques to 2-cliques
$ {f}_{i_1,\dots, {i}_k} $
, which is by convention skew-symmetric with respect to an odd permutation of subset indices. For example, a combinatorial gradient maps 1-cliques to 2-cliques
 $$ {\left(\operatorname{grad}\hskip0.1em \phi \right)}_{\mathrm{ij}}={\phi}_j-{\phi}_i, $$
$$ {\left(\operatorname{grad}\hskip0.1em \phi \right)}_{\mathrm{ij}}={\phi}_j-{\phi}_i, $$
and a combinatorial curl maps 2-cliques to 3-cliques
 $$ {\left(\operatorname{grad}\hskip0.1em \psi \right)}_{\mathrm{ij}\mathrm{k}}={\psi}_{\mathrm{ij}}+{\psi}_{\mathrm{jk}}+{\psi}_{\mathrm{ki}}. $$
$$ {\left(\operatorname{grad}\hskip0.1em \psi \right)}_{\mathrm{ij}\mathrm{k}}={\psi}_{\mathrm{ij}}+{\psi}_{\mathrm{jk}}+{\psi}_{\mathrm{ki}}. $$
One may also introduce adjoint operators; for example the following combinatorial divergence is adjoint to the gradient
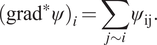 $$ {\left({\operatorname{grad}}^{\ast}\psi \right)}_i=\sum \limits_{j\sim i}{\psi}_{\mathrm{ij}}. $$
$$ {\left({\operatorname{grad}}^{\ast}\psi \right)}_i=\sum \limits_{j\sim i}{\psi}_{\mathrm{ij}}. $$
Hence, we may easily interpret the aggregation step of a traditional GNN as a DNN composed with the combinatorial divergence.
These operators mimic algebraic structure from the familiar vector calculus. They form an exact sequence by guaranteeing
 $ \operatorname{div}\hskip0.1em \operatorname{curl}=\operatorname{curl}\hskip0.1em \operatorname{grad}=0 $
, and may be used to construct a graph Laplacian
$ \operatorname{div}\hskip0.1em \operatorname{curl}=\operatorname{curl}\hskip0.1em \operatorname{grad}=0 $
, and may be used to construct a graph Laplacian
 $ \delta ={\operatorname{grad}}^{\ast}\circ \operatorname{grad} $
and higher-order Hodge Laplacians with well-characterized spectra, a Lax–Milgram theory, Poincare inequalities, and a Hodge decomposition, all of which function analogously to the familiar vector calculus setting.
$ \delta ={\operatorname{grad}}^{\ast}\circ \operatorname{grad} $
and higher-order Hodge Laplacians with well-characterized spectra, a Lax–Milgram theory, Poincare inequalities, and a Hodge decomposition, all of which function analogously to the familiar vector calculus setting.
In Seo and Liu (Reference Seo and Liu2019), the authors use this vector calculus to fit Hodge-Laplacian operators to diffusion processes on scattered data, introducing a PINN-style regularizer to fit a GNN to data while penalizing deviations from an assumed diffusion; see also Figure 2. For example, for a diffusion problem, penalizing an explicit Euler update of the form
 $ {\boldsymbol{x}}^{n+1}={\boldsymbol{x}}^n+\alpha {\operatorname{grad}}^{\ast}\circ \operatorname{grad}\;{\boldsymbol{x}}^n $
promotes diffusion, where
$ {\boldsymbol{x}}^{n+1}={\boldsymbol{x}}^n+\alpha {\operatorname{grad}}^{\ast}\circ \operatorname{grad}\;{\boldsymbol{x}}^n $
promotes diffusion, where
 $ n $
denotes a given timestep. This process is limited to describing diffusion processes only.
$ n $
denotes a given timestep. This process is limited to describing diffusion processes only.
In Trask et al. (Reference Trask, Huang and Hu2022), the graph calculus is used to learn boundary value problems associated with conservation balances, such as conservation of flux or circulation. For example, a conservation law consisting of a diffusive plus nonlinear flux may be learned
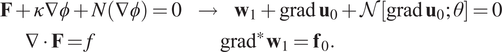 $$ {\displaystyle \begin{array}{l}\mathbf{F}+\kappa \nabla \phi +N\left(\nabla \phi \right)=0\hskip1em \to \hskip1em {\mathbf{w}}_1+\operatorname{grad}\hskip0.22em {\mathbf{u}}_0+\mathcal{N}\left[\operatorname{grad}\hskip0.22em {\mathbf{u}}_0;\theta \right]=0\\ {}\hskip2em \nabla \cdot \mathbf{F}=f\hskip10em {\operatorname{grad}}^{\ast}\hskip0.1em {\mathbf{w}}_1={\mathbf{f}}_0.\end{array}} $$
$$ {\displaystyle \begin{array}{l}\mathbf{F}+\kappa \nabla \phi +N\left(\nabla \phi \right)=0\hskip1em \to \hskip1em {\mathbf{w}}_1+\operatorname{grad}\hskip0.22em {\mathbf{u}}_0+\mathcal{N}\left[\operatorname{grad}\hskip0.22em {\mathbf{u}}_0;\theta \right]=0\\ {}\hskip2em \nabla \cdot \mathbf{F}=f\hskip10em {\operatorname{grad}}^{\ast}\hskip0.1em {\mathbf{w}}_1={\mathbf{f}}_0.\end{array}} $$
Here, subscripts
 $ 0 $
and
$ 0 $
and
 $ 1 $
denote scalar values associated with
$ 1 $
denote scalar values associated with
 $ 1- $
and
$ 1- $
and
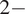 $ 2- $
cliques respectively, N is a nonlinearity, and
$ 2- $
cliques respectively, N is a nonlinearity, and
 $ \mathcal{N} $
denotes a trainable neural network with parameters
$ \mathcal{N} $
denotes a trainable neural network with parameters
 $ \theta $
. An additional parameterization of a Hodge star operator provides a means of learning metric information. This generalizes the GNNs discussed previously: the first equation corresponds to an update function on edges encoding fluxes, while the second corresponds to an aggregate step enforcing conservation of flux. One arrives at an operator of the form
$ \theta $
. An additional parameterization of a Hodge star operator provides a means of learning metric information. This generalizes the GNNs discussed previously: the first equation corresponds to an update function on edges encoding fluxes, while the second corresponds to an aggregate step enforcing conservation of flux. One arrives at an operator of the form
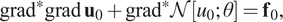 $$ {\operatorname{grad}}^{\ast}\operatorname{grad}\hskip0.22em {\mathbf{u}}_0+{\operatorname{grad}}^{\ast}\mathcal{N}\left[{u}_0;\theta \right]={\mathbf{f}}_0, $$
$$ {\operatorname{grad}}^{\ast}\operatorname{grad}\hskip0.22em {\mathbf{u}}_0+{\operatorname{grad}}^{\ast}\mathcal{N}\left[{u}_0;\theta \right]={\mathbf{f}}_0, $$
so the operator is a nonlinear perturbation of a Hodge-Laplacian. This can equivalently be given in variational form, where the solution
 $ {\boldsymbol{u}}_0 $
satisfies for all
$ {\boldsymbol{u}}_0 $
satisfies for all
 $ v $
$ v $
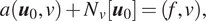 $$ a\left({\boldsymbol{u}}_0,v\right)+{N}_v\left[{\boldsymbol{u}}_0\right]=\left(f,v\right), $$
$$ a\left({\boldsymbol{u}}_0,v\right)+{N}_v\left[{\boldsymbol{u}}_0\right]=\left(f,v\right), $$
with
 $ a $
denoting an elliptic bilinear form. This can rigorously be shown to have a unique solution, and therefore an equality constrained optimization strategy can be applied to fit such models to data while exactly enforcing physics, independent of available data.
$ a $
denoting an elliptic bilinear form. This can rigorously be shown to have a unique solution, and therefore an equality constrained optimization strategy can be applied to fit such models to data while exactly enforcing physics, independent of available data.
A key feature of this framework is the ability to handle nontrivial null-spaces which arise from involution constraints in electromagnetism. This yields an attractive framework for AI/ML-enabled data-driven modeling in microelectronics and magneto-hydrodynamics which mandate structure preservation (Bochev et al., Reference Bochev, Hu, Robinson and Tuminaro2003; Gao et al., Reference Gao, Huang, Trask and Reza2020). We comment, however, that this notion of compatibility is appropriate for nonlinear elliptic problems. Other notions of compatibility are important for other problems; for example, geometric mechanics is important for dynamical systems while for flow problems it is necessary to consider Lie derivatives for advection operators (Marsden et al., Reference Marsden, Patrick and Shkoller1998; Lee et al., Reference Lee, Trask and Stinis2021; Hernández et al., Reference Hernández, Badas, Chinesta and Cueto2022).
In nonphysics based applications, the graph exterior calculus plays an important role in topological data analysis. For example, statistical ranking may be used to indicate preferences as a flow on a graph of options (Jiang et al., Reference Jiang, Lim, Yao and Ye2011), and the Betti numbers of a graph corresponding to the null-space of combinatorial Hodge Laplacians may be used to identify connected components and other geometric features in datasets (Carlsson, Reference Carlsson2009).
3.5. Scalable GNNs
There are several GNN frameworks available which utilize modern distributed and heterogeneous computing architectures to train over large graph-based data structures. The usage of these frameworks depends on (a) whether to employ full-graph or mini-batch training, and (b) whether they are optimized for CPU-only or hardware accelerated computing architectures. Frameworks for distributed and full graph training for CPU and GPUs were rigorously developed in Jia et al. (Reference Jia, Lin, Gao, Zaharia and Aiken2020), Hall et al. (Reference Hall, Taverniers, Katsoulakis and Tartakovsky2021), and Md et al. (Reference Md, Misra, Ma, Mohanty, Georganas, Heinecke, Kalamkar, Ahmed and Avancha2021), whereas for mini-batch based graph training, packages were developed and optimized for CPU-based clusters (Tripathy et al., Reference Tripathy, Yelick and Buluç2020; Zhang et al., Reference Zhang, Huang, Liu, Hu, Song, Ge, Zhang, Wang, Zhou, Shuang and Qi2020b). It is necessary to note that full-graph training requires many epochs in comparison to mini-batch training and also converges to lower accuracy (Wilson and Martinez, Reference Wilson and Martinez2003; LeCun et al., Reference LeCun, Bottou, Orr and Müller2012; Keskar et al., Reference Keskar, Mudigere, Nocedal, Smelyanskiy and Tang2016; Zheng et al., Reference Zheng, Song, Yang, LaSalle, Su, Wang, Ma and Karypis2021).
When considering hardware acceleration of GNNs, it is imperative to consider whether GPUs will be beneficial to the training of GNNs. For GPU acceleration of GNN training to be effective, we require a high on-GPU compute intensity relative to transfer of data between the CPU and GPU. In general, GNNs require irregular memory access and computation due to their unstructured nature. This is in contrast to training of dense networks which consist of matrix vector product kernels over layers of regular size. Therefore, for the training of large graphs, we require efficient strategies to move data from CPU to GPU and mitigate latency.
A second challenge for implementing GNNs on distrbuted frameworks is how to effectively load balance across mini-batches. Ideally, we aim to simultaneously balance both the vertices/edges across processors and the amount of data to be transferred from memory to register. Load balancing is also required to synchronize the parameter update across all processes during backprop.
Natural graph networks (de Haan et al., Reference de Haan, Cohen and Welling2020) treat complex and heterogeneous graphs with varying nodal feature sizes. To efficiently train heterogeneous graph architectures on hybrid CPU/GPUs based clusters, Zheng et al. (Reference Zheng, Song, Yang, LaSalle, Su, Wang, Ma and Karypis2021) proposed the DistDGLv2 framework, which is based on the deep graph library (DGL) (Wang et al., Reference Wang, Zheng, Ye, Gan, Li, Song, Zhou, Ma, Yu, Gai, Xiao, He, Karypis, Li and Zhang2019a). In this framework, mini-batch training is performed on GPUs, whereas the graph structure along with the vertices and edges are stored in CPU memory. The authors have shown a
 $ 20\times $
speedup for the GraphSage benchmark (Hamilton et al., Reference Hamilton, Ying and Leskovec2017) and a
$ 20\times $
speedup for the GraphSage benchmark (Hamilton et al., Reference Hamilton, Ying and Leskovec2017) and a
 $ 36\times $
speedup on GAT benchmarks (Velickovic et al., Reference Velickovic, Cucurull, Casanova and Romero2018) using 64 GPUs on Amazon’s EC2 cluster. Similar to Zeng et al. (Reference Zeng, Zhou, Srivastava, Kannan and Prasanna2019), Bruss et al. (Reference Bruss, Khazane, Rider, Serpe, Nagrecha and Hines2019) propose a distributed framework for CPU-based clusters.
$ 36\times $
speedup on GAT benchmarks (Velickovic et al., Reference Velickovic, Cucurull, Casanova and Romero2018) using 64 GPUs on Amazon’s EC2 cluster. Similar to Zeng et al. (Reference Zeng, Zhou, Srivastava, Kannan and Prasanna2019), Bruss et al. (Reference Bruss, Khazane, Rider, Serpe, Nagrecha and Hines2019) propose a distributed framework for CPU-based clusters.
In a more general setting, scaling of unstructured graph algorithms is an important problem. Within the Department of Energy, the ExaGraph Co-design Center is a component of the Exascale Computing Project, which aims to develop broadly applicable graph kernels for exascale computation (1 exaflop =
 $ {10}^{18} $
flops) in applications spanning power grid, biology, chemistry, wind energy, and national security (Acer et al., Reference Acer, Azad, Boman, Buluç, Devine, Ferdous, Gawande, Ghosh, Halappanavar, Kalyanaraman, Khan, Minutoli, Pothen, Rajamanickam, Selvitopi, Tallent and Tumeo2021). The project aims to codesign algorithms, computing architecture, and hardware to build combinatorial kernels impacting general graph computation in addition to GNNs.
$ {10}^{18} $
flops) in applications spanning power grid, biology, chemistry, wind energy, and national security (Acer et al., Reference Acer, Azad, Boman, Buluç, Devine, Ferdous, Gawande, Ghosh, Halappanavar, Kalyanaraman, Khan, Minutoli, Pothen, Rajamanickam, Selvitopi, Tallent and Tumeo2021). The project aims to codesign algorithms, computing architecture, and hardware to build combinatorial kernels impacting general graph computation in addition to GNNs.
4. Summary and Outlook
Unlike traditional machine learning, in scientific machine learning there are not big data available, and moreover, the few measurements available may be for auxiliary variables and not on the domain boundaries to provide proper boundary conditions. Physics-informed learning has emerged as a powerful approach in tackling such ill-defined problems and can use synergistically any available data from measurements together with data that are computed based on the physics of the problem and the corresponding governing equations. This can be done on random points as in PINNs or on the nodes of a graph as in GNNs.
PINNs and their extensions are relatively new methods that can tackle such problems, and they are especially effective for inverse problems, which may be challenging for traditional numerical methods. However, for realistic applications, new PINN implementations are needed that are amenable to multi-GPU computing. At the present time, a hybrid multi-GPU/multi-CPU paradigm based on domain decomposition seems to emerge as the most efficient solution but more work is required both on algorithms as well as on implementation, including mixed precision calculations that can significantly speed up PINNs.
GNNs offer effective alternative solutions, especially for unstructured data and very complex systems. Here, we have reviewed spectral methods, spatial methods and GATs that can all be used in the context of physics-informed learning, including discovering smart finite difference stencils and operators. We also reviewed PIGNs, where graph exterior calculus is used explicitly to construct the various differential operators on graphs, and preliminary results for simulation physical systems are very promising. In contrast to PINNs, PIGNs may impose inductive biases corresponding to exact enforcement of integral balances rather than differential operators. There are already several parallel frameworks for scaling up GNNs but the new effort should be directed toward scaling physics-informed GNNs.
Finally, we want to comment on the connection between graphs and PDEs. It seems that the scientific machine learning community is importing ideas from graph theory and algorithms to solve PDEs, which is largely true and could be exploited even further. For example, graph embedding methods offer drastic dimensionality reduction for complex data both for static and dynamic graphs, see Xu (Reference Xu2021), hence, graph embedding could also be exploited in the context of complex dynamical systems by the PDE community. However, recently there has been an effort to design new GNNs based on PDE theory, see, for example, the so-called “GRAND” scheme of Chamberlain et al. (Reference Chamberlain, Rowbottom, Gorinova, Bronstein, Webb and Rossi2021), where standard PDE tools are used to understand existing GNN architectures and subsequently develop a broader class of GNNs that are stable even for very deep networks. Specifically, the authors of Chamberlain et al. (Reference Chamberlain, Rowbottom, Gorinova, Bronstein, Webb and Rossi2021) have shown that many popular GNN architectures can be derived from a universal mathematical framework by choosing different forms of diffusion equations and time-discretization schemes. Hence, what we see emerging is a reciprocal “pull–push” relationship between graph theory and algorithms on one side and PDE theory and algorithms on the other side that will be beneficial in greatly accelerating the emerging field of scientific machine learning.
Data Availability Statement
Tensorflow based Python codes and data to reproduce Figure 12 can be obtained at https://github.com/rgp62/gmls-nets. However, the same implementation using PyTorch based python codes can be found at https://github.com/atzberg/gmls-nets. A detail description and implementation of domain decomposition algorithms shown in Figure 7 can be found in paper https://www.sciencedirect.com/science/article/pii/S0021999121005787. A detail description and implementation detail to reproduce results in Figure 5 can be found in https://arxiv.org/pdf/2111.02801.pdf.
Author Contributions
All authors wrote and edited the paper. All authors approved the final submitted draft.
Funding Statement
This research was supported by the DOE project PhILMs (no. DE-SC0019453) and the OSD/AFOSR MURI grant FA9550-20-1-0358. N.T.’s research was supported by the Department of Energy early career research program. Sandia National Laboratories is a multimission laboratory managed and operated by National Technology and Engineering Solutions of Sandia, LLC, a wholly owned subsidiary of Honeywell International, Inc., for the U.S. Department of Energy’s National Nuclear Security Administration under contract DE-NA0003525. This paper describes objective technical results and analysis. Any subjective views or opinions that might be expressed in the paper do not necessarily represent the views of the U.S. Department of Energy or the United States Government.
Competing Interests
The authors declare no competing interests exist.





































 Open access
Open access
Comments
No Comments have been published for this article.