

No CrossRef data available.
Article contents
An efficient method for generating a discrete uniform distribution using a biased random source
Published online by Cambridge University Press: 07 March 2023
Abstract
We present an efficient algorithm to generate a discrete uniform distribution on a set of p elements using a biased random source for p prime. The algorithm generalizes Von Neumann’s method and improves the computational efficiency of Dijkstra’s method. In addition, the algorithm is extended to generate a discrete uniform distribution on any finite set based on the prime factorization of integers. The average running time of the proposed algorithm is overall sublinear: 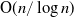 $\operatorname{O}\!(n/\log n)$.
$\operatorname{O}\!(n/\log n)$.
Keywords
MSC classification
Primary:
68W20: Randomized algorithms
Information
- Type
- Original Article
- Information
- Copyright
- © The Author(s), 2023. Published by Cambridge University Press on behalf of Applied Probability Trust
References
Dijkstra, E. W. (1990). Making a fair roulette from a possibly biased coin. Inf. Process. Lett. 36, 193.10.1016/0020-0190(90)90072-6CrossRefGoogle Scholar
Elias, P. (1972). The efficient construction of an unbiased random sequence. Ann. Math. Statist. 43, 865–870.10.1214/aoms/1177692552CrossRefGoogle Scholar
Hoeffding, W. and Simons, G. (1994). Unbiased coin tossing with a biased coin. Ann. Math. Statist. 41, 341–352.CrossRefGoogle Scholar
Jakimczuk, R. (2012). Sum of prime factors in the prime factorization of an integer. Int. Math. Forum 7, 2617–2621.Google Scholar
Pae, S. (2005). Random number generation using a biased source. Doctoral thesis, University of Illinois Urbana-Champaign.Google Scholar
Stout, Q. F. and Warren, B. (1984). Tree algorithms for unbiased coin tossing with a biased coin. Ann. Prob. 12, 212–222.10.1214/aop/1176993384CrossRefGoogle Scholar
Von Neumann, J. (1951). Various techniques used in connection with random digits. J. Res. Nat. Bureau Standards Appl. Math. 12, 36–38.Google Scholar