

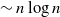
Crossref Citations
This article has been cited by the following publications. This list is generated based on data provided by Crossref.
Zhou, Weilian
Yi, Haidong
Mishne, Gal
and
Chi, Eric
2021.
Scalable Algorithms for Convex Clustering.
p.
1.
Zhao, Jun
Jaffe, Ariel
Li, Henry
Lindenbaum, Ofir
Sefik, Esen
Jackson, Ruaidhrí
Cheng, Xiuyuan
Flavell, Richard A.
and
Kluger, Yuval
2021.
Detection of differentially abundant cell subpopulations in scRNA-seq data.
Proceedings of the National Academy of Sciences,
Vol. 118,
Issue. 22,
Shen, Chao
and
Wu, Hau-Tieng
2022.
Scalability and robustness of spectral embedding: landmark diffusion is all you need.
Information and Inference: A Journal of the IMA,
Vol. 11,
Issue. 4,
p.
1527.
Ruys, William
Ghafouri, Ali
Chen, Chao
and
Biros, George
2025.
Scalable KNN Graph Construction for Heterogeneous Architectures.
ACM Transactions on Parallel Computing,
Vol. 12,
Issue. 3,
p.
1.