

1. Introduction
In this work we analyze the characteristics and dynamics of organizations wherein members diverge in terms of capabilities and visions they hold, and interests which they pursue. How do organizations and society as a whole put together such distributed and possibly conflicting pieces of knowledge?
The question is one of the most fundamental in economics and has been often analyzed through the ‘Hayekian’ lenses of the superiority of decentralization in promoting the development and coordination of the dispersed pieces of knowledge in society. However, in the real world such coordination occurs only to a very limited extent via decentralized market transactions. As emphasized by Simon (Reference Simon1991), most human activities take place in social structures other than markets. In his famous metaphor of the visitor from Mars approaching Earth and able to spot activities within firms (and other institutions) marked in green and market transactions marked in blue, the visitor would see green as the dominant color with a few blue lines connecting green masses of different sizes (Simon, Reference Simon1991: 27). Moreover, the problem is not only, and perhaps not so much, one of coordinating given pieces of dispersed knowledge, but one of developing and modifying such knowledge, and indeed there is no dispute that hierarchical organizations are key actors in these processes.
The view which claims the superiority of perfect decentralization and coordination via market interaction implicitly assumes that knowledge is divided and somehow crystallized into separate pieces (modules, we could more properly say) which can be coordinated through the standardized interfaces provided by impersonal market transactions. In Simonian terms the implicit hypothesis is one of full decomposability of knowledge into quasi independent modules (Simon, Reference Simon1981). If instead the quasi independence hypothesis does not hold, or if the boundaries among the different pieces of knowledge should be often redrawn, perfect decentralization may no longer coordinate efficiently.
In this paper we start from an opposite assumption of ill-defined knowledge. Not only knowledge is distributed and there are strong and widespread interdependencies among the various pieces of knowledge but there is high uncertainty of where the relevant knowledge is located. Our artificial agents have different representations of the problem and all these representations, in principle, are partly correct and partly wrong. Similarly, also the principal of our organization has an incorrect representation of the problem and therefore is uncertain on how to allocate decisions. Our main result is that, in this world of high uncertainty about the location of the relevant knowledge, authority and power have indeed an important role.
We consider three types of power: the one of dividing the decision task into subtasks and allocating them to different agents; the one of overruling decisions autonomously taken by the agents; and a more subtle power of inducing the agents to modify their representations and preferences to increasingly align them to those of the principal. We analyze the role of these different types of power and show that, in general, power may increase coordination, control (by the principal) but also learning. More specifically, we could summarize the main results of our model with the maxim ‘divide, rule and learn’. By combining the power to impose a fine division of decisions together with the exercise of overruling power, the principal cannot only achieve coordination, control, and exploitation of the available knowledge, but also increase exploration and acquire relevant knowledge from agents. It is interesting to notice that our model suggests that this principle of dividing, ruling, and learning prescribes that agents should be always given decision rights on very few policies, even if their knowledge is broader. There is an advantage, within our model, to subdividing decision rights into small separate modules because this gives the principal more opportunities to increase both control and learning. Remarkably, the advantages of finely partitioning decision rights are such that it may pay off to assign to limit an agent’s decision rights even when this agent has valuable knowledge over a broader set of decision items. Decision rights should therefore be finely partitioned than knowledge, against the standard principle that decision rights should be co-located with the knowledge that is relevant to that decision (Hayek, Reference Hayek1945; Jensen and Meckling, Reference Jensen, Meckling, Werin and Wijkander1992).
The paper is organized as follows: in section 2 we discuss the various facets of power, a crucial but often neglected feature of organizations. Section 3 presents the simulation model and section 4 discusses the main results. Finally, in section 5 we draw some conclusions and implications.
2. Power, authority and hierarchies
A major ‘foundational’ dimension of organizations concerns their hierarchical authority-ridden nature and the associated notion of power. In social sciences, also in this respect, one finds two alternative archetypes.
According to the first one, that we could call the exchange view, power is not an autonomous dimension of social interaction and its notion does not have any clear analytical status. Indeed, market transactions are the normal and efficient coordination mode (Williamson states that ‘in the beginning there were markets’ (Williamson, Reference Williamson1975: 20)) and different forms of monitoring, authority, or specific types of power emerge only as possible efficient solutions to problems of market failure. Broadly speaking, and with important differences, this view is shared by theories which locate the raison d’être of the firm in transaction costs (Williamson, Reference Williamson1995), in shirking and monitoring costs (Alchian and Demsetz, Reference Alchian and Demsetz1972), in non-contractible residual rights of control (Grossman and Hart, Reference Grossman and Hart1986), in non-contractible access to critical resources (Rajan and Zingales, Reference Rajan and Zingales1998), etc.
The problem of interdependencies among pieces of knowledge or resources is indeed present in most of these theories. In particular, Alchian and Demsetz (Reference Alchian and Demsetz1972) consider the complementarities among members of a production team the main source of monitoring costs. Demsetz (Reference Demsetz1995) pushes this idea further and argues that the stronger the interdependencies the larger is the scope for authority (giving of direction, in his terminology): “‘The productive giving of directions requires confidence that these directions are carried out. [. . .] Reliability becomes more important to an organization as the productivities of its various parts become more interdependent. The military organization, at least during a war, is an outstanding example of interdependence. [. . .] This interdependency creates a demand for discipline that is stronger than in organizations in which spillover effects like this are not important’Footnote 1 (Demsetz, Reference Demsetz1995: 33).
The second archetype, which we shall (improperly) call the political view, holds on the contrary that: (a) an essential, although not unique, feature of organizations is their authoritative structure; (b) authority relations are inherently different from exchange relations; and (c) power must be considered an autonomous interpretative dimension. In the following we shall explore the implications of the latter perspective for coordination and learning.
The political view, of course, does not claim to be exhaustive: command and exchange coexist in different forms within and outside organizations. But it claims − at least as we interpret it − that the sole consideration of exchange relations prevents any first-order understanding of what goes on within the ‘organizational black box’, of the boundaries between organizations and of organizational dynamics.
Here we shall adopt a quite broad definition of power. First, power entails the ability of some agent (the ‘ruler’, the authority) to determine the set of actions available to the other agents (the ‘ruled’). Second, it involves the possibility of the authority to veto the decisions or intentions of the ruled ones. Third, power relates to the ability of the authority to influence or command the choice within the ‘allowed’ choice set (i.e. the span of control of the ‘ruled’), according to the deliberations of the ruler himself (this definition echoes in some ways the analysis contained in Luhmann (Reference Luhmann1979)). Here, in these respects, the units of analysis are the dimensionality and boundaries of the choice sets and the mechanisms by which authority is enforced.
As Herbert Simon puts it: ‘Authority in organizations is not used exclusively, or even mainly, to command specific actions. Most often, the command takes the form of a result to be produced (“repair this hinge”), or a principle to be applied (“all purchases must be made through the purchasing department”) or goal constraints (“manufacture as cheaply as possible consistent with quality”)’ (Simon, Reference Simon1991: 31). These aspects of command are part of what in the following we shall call ‘policies’.
Fourth, the most subtle exercise of power concerns the influence of the authority upon the preferences of the ruled themselves, so that, in Max Weber’s words, the conduct of the ruled is such that it is ‘as if the rules had made the content of the command the maxim of their conduct for its own sake’ (Weber, Reference Weber1978: 946). That easily accounts for the fact that ‘organizations can be highly productive even though the relation between their goals and the material rewards received by employees, if it exists at all, is extremely indirect and tenuous’ (Simon, Reference Simon1991: 38).
Obedience, docility, identification in the role and in the organization are central elements of such processes of adaptive learning and coordination (classic discussion of these processes are in Milgram (Reference Milgram1974), Simon (Reference Simon1976), Simon (Reference Simon1981), Simon (Reference Simon1993), Lindblom (Reference Lindblom1977), Lukes (Reference Lukes2005), and Moore (Reference Moore1958)). Docility offers the inclination to ‘depend on suggestions, recommendation, persuasion and information obtained through social channels as a major basis for choice’ (Simon, Reference Simon1993: 156). And, emphatically, such inputs are not inputs to an inferential (let alone Bayesian) decision process. Both cognitive frames and preferences are endogenous to the very process of social adaptation and social learning.
It is crucial to note that the social endogeneity of identity building is exactly the opposite to any type of decision-theoretic model: one learns socially not only what one can do, but, more fundamentally, what one wants, the very interpretation of the natural and social environment one lives in, and, ultimately, the very self-perception and identity of the agents. The conjecture we shall explore in the following is that in many circumstances such processes of cognitive and behavioral adaptation yield also much more efficient and quicker coordination patterns.
In the next section we introduce a simple model, which tries to formalize the above-mentioned notions of power within an organizational decision-making framework characterized by high degrees of interdependence among the individual decisions.
3. The model
3.1 Policies, preferences and delegation
We model an organization that combines together dispersed pieces of knowledge in order to accomplish an organizational task; the model is an extension and generalization of the one contained in Marengo and Pasquali (Reference Marengo and Pasquali2012). Our model has also some points in common with Siggelkow and Rivkin (Reference Siggelkow and Rivkin2005), who also study delegation of decisions in a complex search problem where decisions are interdependent. However, in relation to the latter paper, we introduce some important new elements: our organization is made by agents who have a subjective representation of the problem the organization is facing and this representation involves, for each agent, all the organizational decisions and not only the decisions which are delegated to him/her. In other words, we want to model an organization in which agents have a different representation of the entire organizational problem and not simply a local knowledge of the subset of policies allocated to them, like in Siggelkow and Rivkin (Reference Siggelkow and Rivkin2005). In our model agents are delegated a subset of decisions, but they take such decisions according to their subjective representation (subjective landscape) of the entire organizational problem. In this way we study the interplay between the extent of delegation and heterogeneity of knowledge, representations, visions, in a model in which delegation does not only create a problem of coordination, but may also allow to allocate decisions to those who have a more powerful representation or better knowledge.
Our paper also has some elements in common with Woodard (Reference Woodard2010). Though the contexts of the two models are quite different (in spite of the similarity in the modeling techniques), the two papers share insight that institutional mechanisms that promote stability (convergence to equilibrium) can lead to higher performance, even when equilibria are randomly distributed in value and agents lack the ability to select effectively among them.
In our model we suppose that the organization has to take a set of interrelated decisions (or implement a set of policies, or perform a set task). Policy vectors can be ranked, with a complete and transitive order relation, from best to worst. We suppose that there is a ‘true’, objective, and exogenously given ranking which is in principle unknown to the members of the organization. The latter is composed by a principal and a set of agents. The principal and each agent have their own subjective and heterogeneous rankings of the policy vectors, which reflect their heterogeneous knowledge. The principal does not take any decision directly but only allocates them to the agents and chooses the agenda, i.e. the sequence with which decisions have to be taken. In addition she can also overrule the agents’ decisions by exerting authority.
We will introduce the notion of organizational landscape, which, for each possible policy vector, gives the set of vectors that can be reached from it. Such a set is determined by the individual preferences (rankings), the allocation of decisions and the agenda (that together we call organizational structure), and the frequency and mode of authority interventions. We will study the properties of such an organizational landscape as a function of both the organizational structure and, especially, authority. In particular we will analyze the ruggedness of the resulting landscape, i.e. the number and locations of local and global optima, and therefore the set of possible outcomes and the likelihood and expected time to achieve one of them.
Since the principal and the agents have, in principle, a subjective ranking of the policy vectors which has no similarity to the objective one, also the resulting organizational landscape has no relation to the true one. However, in a second set of simulations we will introduce some simple learning mechanisms through which principal and/or agents will try and learn the real ranking of policy vectors and consequently adapt their subjective ranking and the resulting organizational landscape. We will use a very simple learning algorithm based on actual trial-and-error: only by implementing and experimenting different policy vectors can our artificial agents learn their true relative performance and consequently update their own subjective rankings. Thus, rugged organizational landscapes, with their multiplicity of organizational equilibria, have a learning advantage as they allow higher rates of experimentation.
Our model has some elements in common with NK fitness landscape models (Kauffman, Reference Kauffman1993; Levinthal, Reference Levinthal1997), but also some important differences. First, instead of attributing arbitrary fitness values to policy vectors we only rank them. Second, we do not limit search to one bit mutation algorithms: our agents may mutate up to all the policies under their control. In this respect our model belongs more to the literature on modularity in complex systems (Ethiraj and Levinthal, Reference Ethiraj and Levinthal2004; Brusoni et al., Reference Brusoni, Marengo, Prencipe and Valente2007), and can be considered as a model in which a complex decision task is decomposed into modules and the resulting modules are delegated to diverse agents.
To be more precise, we suppose that the organization is fully characterized by n (binary, for simplicity) policies P = {p 1, p 2, . . ., pn}. Policies are interrelated, in the sense that the value of, say, switching policy i from 0 to 1 depends on the current value of other policies (possibly of all the other n − 1 policies). We suppose that policy vectors can be ranked from best to worst according to their ‘objective’ performance in the given environment. We call ‘policy landscape’ the mapping between the 2n binary vectors of policies to their ranks, i.e. to the set of integers in the interval [1, 2n], where rank 1 is attributed to the best policy vector and rank 2n to the worst one. Since policies are interrelated, the policy landscape is, in general, ‘rugged’, meaning that small changes in a policy vector (e.g. changing only one policy) may result in large changes of rank. Thus, searching the policy landscape is a complex task.
The organization is formed by one principal and a set of agents A = {a 1, a 2, . . ., ah}, with 1 ⩽ h ⩽ n. Members of the organization are heterogeneous in their beliefs or views of the organizational landscape. The principal and each agent hold their own subjective ranking of the policy environment which is, in general, different from other agents’ and different from the ‘true’ one. These differences reflect the heterogeneity of knowledge among individuals who hold different representations of the world in which they operate.
Agents can therefore be characterized by their competence, i.e. the extent to which their individual landscape is correlated to the true one. The degree of competence of an agent can be measured by Spearman’s rank correlation between his own ordering and the true one. Such competence may be subject to adaptive change through a learning process by which an agent tries to adjust his own landscape either to the true one or to the principal’s. The agent’s propensity to adapt his own landscape to the principal’s can be considered as an indicator of the agent’s docility, as mentioned above (Simon, Reference Simon1993).
We assume that the principal does not perform directly any task but simply allocates them to the different agents. Let di⊆P be a generic non-empty subset of the set of policies. We define an allocation of decision rights as a partitionFootnote 2 of the set of policies, i.e. a set of non-empty subsets D = {d 1, d 2, . . ., dk} such that
 \begin{equation*}
\bigcup _{i=1}^k d_i=P \text{ with } d_i\bigcap d_j = \emptyset \text{,} \forall i\ne j.
\end{equation*}
\begin{equation*}
\bigcup _{i=1}^k d_i=P \text{ with } d_i\bigcap d_j = \emptyset \text{,} \forall i\ne j.
\end{equation*}We call organizational structure O a mapping from the domain set D to the co-domain set A of agents, i.e. a mapping that assigns each subset of policies to one and only one agent, i.e. O: D↦A. The image of O is a subset of the set of agents containing as many agents as the number of subset into which P is partitioned, i.e. the cardinality k of D.
Finally, the organizational structure may also be characterized by an agenda α = a i 1, a i 2, . . ., a ik, that is a permutation of the subset of agents which form the image of O. This permutation states the sequence in which agents are called to perform their tasks.
As already mentioned, we suppose that the principal does not choose any policy directly, but can:
(1) freely choose and modify the organizational structure (that is the partition of policies and their allocation to agents);
(2) exert direct power by vetoing or overruling the agents’ decisions;
(3) exert indirect power through influence by making the agents’ landscapes progressively more and more aligned with her own.
3.2 Organizational decision making and organizational landscape
We assume that agents, although they are assigned only a subset of policies, take their decisions by considering their preference profiles over the entire vector of policies. In particular, when asked to decide, an agent will choose the policies under his control that, given the current state of the other policy items that are not under his control, produce the overall vector of policies which ranks higher in his own ordering. To give an example, assume that the set of policies is made of four binary policies, that agent i is allocated the first policy, and that the current policy vector is 0101. Then agent i will choose to implement policy 0 if 0101≻1101 in his own ordering, and policy 1 if 1101≻0101. Of course, because of interdependencies among policies, his preference between 0 and 1 might well be reversed when the three policies not under his control have current values which differ from 101.
We assume that at the outset an initial ‘status quo’ policy vector is (randomly) given.Footnote 3 Then the first (according to the agenda) agent may modify the policies under his control. He generates all the sub-vectors for the policies under his control and chooses the one that, together with the status quo policies that are not under his control, will produce the vector he prefers.
With some probability 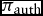 $\pi _{\text{auth}}$ the principal may exert authority and overrule the agent’s decision. We consider two possible kinds of authority: a simple veto power and a fiat. In the former case the principal can simply veto a policy change proposed by an agent, in which case the current status quo is preserved, even if the agent preferred a change. In the case of fiat the principal does not only have the choice between the status quo and the changes proposed by the agent but can impose to the agent, within his subset of policies, the one she prefers, i.e. the agent is de facto replaced by the principal for the current decision.
$\pi _{\text{auth}}$ the principal may exert authority and overrule the agent’s decision. We consider two possible kinds of authority: a simple veto power and a fiat. In the former case the principal can simply veto a policy change proposed by an agent, in which case the current status quo is preserved, even if the agent preferred a change. In the case of fiat the principal does not only have the choice between the status quo and the changes proposed by the agent but can impose to the agent, within his subset of policies, the one she prefers, i.e. the agent is de facto replaced by the principal for the current decision.
When the first agent in the agenda has taken a decision (and possibly the principal has overruled it), the value he (or the principal in his behalf) has chosen for the policies under his control becomes part of the new status quo. Then the second (according to the agenda) agent operates on this new status quo in the same way: he evaluates all the alternatives for the set of policies under his control and chooses those that inserted in the new status quo produce the overall policy vector which ranks higher for him. Then again the principal may veto or overrule such a choice. The same procedure is then repeated for the third, fourth, . . ., 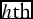 $h\text{th}$ agents in the agenda.
$h\text{th}$ agents in the agenda.
Once all the agents have acted on the policies under their control, we consider two alternative options. The first alternative is that the agenda may be repeated over and over again until an equilibrium or a cycle is reached. An organizational equilibrium is a policy vector whereby no agent (nor the principal, in the case of fiat) wants to modify items under his (her) control according to the procedure outlined above. An organizational cycle is a sequence of policy vectors that keep being repeated in the same order, without ever reaching an equilibrium.Footnote 4
A second alternative instead does not allow the agenda to be repeated after all the h agents have acted once (and the principal has possibly vetoed or overruled their decisions). The resulting policy vector will not be in general an equilibrium, in the sense that some agents would still like to revise their decisions after observing the new status quo, but they are not allowed to do it. We will call this resulting policy vector an organizational outcome, to distinguish it from an organizational equilibrium which may be reached with agenda repetition. Of course without agenda repetition cycles are not possible and an organizational outcome is always reached.
Finally, the procedure is repeated starting from all the possible 2n policy vectors as initial conditions.
The initial conditions (individual rankings of the policy vectors held by the principal and the agents), the organizational structure and the mode and likelihood of the exercise of authority determine, altogether, an organizational landscape, i.e. a neighborhood structure which, for every policy vector, indicates which are the vectors that can be reached, given the organizational structure, the decision-making procedure and the individual rankings of the policy vectors. In section 3.4 we will study some properties of the organizational landscape in relation to the organizational structure and the decision-making procedure. We will especially analyze the determinants of the ruggedness or smoothness of the landscape along with the location of local and global optima.
But before that, in the next subsection, we describe three learning mechanisms we will use in a second family of simulations. As already mentioned, the organizational landscape is built as an aggregation of the individual landscapes. The latter are subjective rankings of the policy vectors which we suppose are initially randomly generated and are subject to learning and adaptation.
3.3 Learning and adaptation of preferences
We implement three types of learning and adaptation: the first two concern, respectively, the principal and the agents that adapt their own rankings to the ‘true’ one, while the third one implies that agents adapt their own rankings to the principal’s. In all the three cases we use a very simple procedure for adaptive learning based exclusively on actually experienced feedbacks.
Let us first describe adaptations to the ‘true’ ranking of policy vectors. They take place only when a new organizational decision is reached (either an organizational equilibrium, in the case of agenda repetition, or an organizational outcome, in the case without agenda repetition),Footnote 5 the corresponding policy vector is implemented, and a feedback from the environment is received. In particular, we suppose that principal and agents can observe only whether the new policy vector is better or worse than the previous one in terms of the ‘true’ ranking. If the previous policy vector 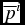 $\overline{p}^i$ ranked worse (better) than the new one
$\overline{p}^i$ ranked worse (better) than the new one 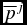 $\overline{p}^j$, with some probability
$\overline{p}^j$, with some probability 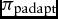 $\pi _{\text{padapt}}$ for the principal and
$\pi _{\text{padapt}}$ for the principal and 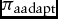 $\pi _{\text{aadapt}}$ for the agents those who ranked
$\pi _{\text{aadapt}}$ for the agents those who ranked 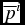 $\overline{p}^i$ better (worse) than
$\overline{p}^i$ better (worse) than 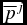 $\overline{p}^j$ will swap the positions of the two vectors in their rankings. If, instead, either the individual preference is in accordance with the environment’s, or the organizational decision process has produced a cycle and no equilibrium has been implemented, no adaptation occurs.
$\overline{p}^j$ will swap the positions of the two vectors in their rankings. If, instead, either the individual preference is in accordance with the environment’s, or the organizational decision process has produced a cycle and no equilibrium has been implemented, no adaptation occurs.
Moreover, agents can also adapt their rankings to the principal’s with probability 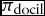 $\pi _{\text{docil}}$, which is a measure of the agents’ propensity to conform to the principal, i.e. of their docility. Also in this case we suppose that adaptation can only occur through a very simple mechanism based on actual observation. We suppose that whenever the principal overrules an agent’s decision (either by veto or by fiat) and imposes policy vector
$\pi _{\text{docil}}$, which is a measure of the agents’ propensity to conform to the principal, i.e. of their docility. Also in this case we suppose that adaptation can only occur through a very simple mechanism based on actual observation. We suppose that whenever the principal overrules an agent’s decision (either by veto or by fiat) and imposes policy vector 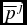 $\overline{p}^j$ over
$\overline{p}^j$ over 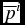 $\overline{p}^i$ chosen by the agent, the overruled agent learns that for the principal
$\overline{p}^i$ chosen by the agent, the overruled agent learns that for the principal 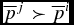 $\overline{p}^j \succ \overline{p}^i$ and with probability
$\overline{p}^j \succ \overline{p}^i$ and with probability 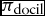 $\pi _{\text{docil}}$ will swap the positions of the two vectors in his own ranking. If, instead, the principal does not overrule the agent’s decision, either because she does not exert authority or because she shares with the agent the same preference, no such adaptation occurs.
$\pi _{\text{docil}}$ will swap the positions of the two vectors in his own ranking. If, instead, the principal does not overrule the agent’s decision, either because she does not exert authority or because she shares with the agent the same preference, no such adaptation occurs.
3.4 Simulations
We will simulate the organizational decision-making process described so far, comparing different organizational structures and analyzing the role of authority (in the three versions of veto power, fiat, and influence), with learning by the principal and/or by the agents, each of them controlled by the corresponding probabilities.
We simulate randomly generated policy landscapesFootnote 6 with n = 8 policy items and up to eight agents with randomly generated preferences. We test the following organizational structures with 1, 2, 4, and 8 agents:
(1) O1:a 1 ← {1, 2, 3, 4, 5, 6, 7, 8},
(2) O2:a 1 ← {1, 2, 3, 4}, a 2 ← {5, 6, 7, 8} with agenda α = a 1, a 2,
(3) O4:a 1 ← {1, 2}, a 2 ← {3, 4}, a 3 ← {5, 6}, a 4 ← {7, 8} with agenda α = a 1, a 2, a 3, a 4,
(4) O8:a 1 ← {1}, a 2 ← {2}, a 3 ← {3}, a 4 ← {4}, a 5 ← {5}, a 6 ← {6}, a 7 ← {7}, a 8 ← {8} with agenda α = a 1, a 2, . . ., a 8.
In what follows, we study the properties of decision making in randomly generated policy landscapes (that is the true ordering of policy vectors). In each simulation we study the outcome for every initial status quo and we repeat the exercise for 1,000 different randomly generated problems.
4. Results
We will concentrate on the role of organizational structure, authority, learning, and docility. We will consider the performance of organizations in randomly generated policy landscapes. As indicators of performance we shall use the following:
(1) average performance, i.e. the average true ranking of all the attainable organizational equilibria;
(2) best performance, i.e. the true ranking of the best attainable organizational equilibrium;
(3) average control, i.e. the average ranking according to the principal’s preferences of all the attainable organizational equilibria;
(4) best control, i.e. the ranking according to the principal’s preferences of the best attainable organizational equilibrium;
(5) principal’s competence, i.e. the final correlation between the principal’s ranking and the true one.
4.1 Organizational structure
The role of organizational structure when neither authority nor learning is in place has been already analyzed in Marengo and Pasquali (Reference Marengo and Pasquali2012). Since these results are the points of departure also for the simulations we develop here, we report them here again. Table 1 shows that the decision process with agenda repetition in O8 ends up in a cycle in 78% of cases. If it does not lead to a cycle, it stops in about three different organizational equilibria. On the contrary, in O1 all decisions are delegated to one agent, therefore only one organizational equilibrium is possible (the policy vector preferred by the agent) and no cycles may occur (because all agents have transitive preferences). This however is the extreme case whereby there is no coordination problem because all the knowledge is embodied in one autocratic ruler, who is in every respect both principal and agent. In some respect, this case resembles central planning: the coordination problem is solved by construction and the performance at equilibrium fully depends on the quality of the knowledge of the central planner itself.
Table 1. Number of organizational equilibria for different organizations

Source: Marengo and Pasquali (Reference Marengo and Pasquali2012), 1305
Notes: n = 8. 1,000 simulations. Standard deviation in brackets.
Table 2 reports instead the number of organizational outcomes when the agenda is not repeated. In this case cycles cannot occur and therefore the number of different outcomes is much greater than the number of different equilibria reported in Table 1, except when all policies are delegated to a single agent. In the latter case there is a unique outcome which is also the unique equilibrium.
Table 2. Number of organizational outcomes for different organizations

Source: Marengo and Pasquali (Reference Marengo and Pasquali2012), p.1306 Notes: n = 8. 1,000 simulations. Standard deviation in brackets.
Each equilibrium or outcome has a basin of attraction, i.e. a set of initial policy vectors starting from which that equilibrium or outcome may be attained. The size of such basin of attractionFootnote 7 does not seem to have any significant relation to the rank of the equilibrium or outcome itself. In particular, higher ranked equilibria or outcomes do not have in general larger basins of attraction than lower ranked ones.
Also, the distribution of equilibria and outcomes is random. Since there is, in general, no relation whatsoever among the ‘true’, the principal’s and the agents’ rankings, equilibria, and outcomes are also randomly distributed with respect to their position in the true and the principal’s rankings. However, the higher the number of equilibria or outcomes, the higher the likelihood that some of them rank high in the true or in the principal’s ordering. Thus, with organizational structures in which delegation is finely partitioned (and especially when agenda repetition is not allowed) there exists the possibility for the principal to obtain high levels of control (i.e. an organizational equilibrium or outcome close to her preferred policy vector) and/or higher performance (i.e. an organizational equilibrium or outcome close to the policy vector which ranks higher in the environment) only by appropriately choosing the initial status quo, i.e. an initial condition within the basin of attraction of the preferred equilibrium and outcome. In other words, finely partitioned organizational structures give the principal a higher possibility to manipulate organizational decisions, even without using authority.Footnote 8 It is important to stress that what we propose here are a kind of ‘possibility’ results: a higher number of organizational equilibria increases the possibility for the principal to select, among the many outcomes, the one which is closer to her preferred policy vector. Of course this does not imply that the principal will be actually able to select this most preferred equilibrium. However, if the principal starts from a status quo which is equal or close to her preferred policy vector she will likely obtain an equilibrium close to this policy vector. Actually, since the larger the number of local optima the smaller is their basin of attraction, if there are many local optima the principal will almost certainly obtain a policy vector close to the preferred one, by starting from nearby initial conditions. On the contrary, if there exists only one organizational equilibrium this will always be reached from any initial status quo.
It is worth stressing that finely partitioned structures only give the possibility to attain these preferred equilibria or outcomes, and that this possibility can be exploited only if the principal can choose (by locating in its basin of attraction), among the many equilibria or outcomes, one which ranks higher in terms of control or performance. Moreover, since in principle there is no correlation between the objective and the principal’s rankings, there is also no relation between control and performance. Later in the paper we will introduce some learning mechanisms and analyze under which conditions the location of good equilibria and outcomes can be learned and control and performance can be aligned. But first, in the following simulation exercises, we will show that the use of authority greatly increases the scope for manipulability.
4.2 Authority
We just mentioned the advantages of highly partitioned structures, but we also reminded that, if agenda repetition is allowed, they tend to produce higher numbers of cycles. Authority can indeed prevent the latter.
Table 3 shows the number of optima and cycles and the values of the best attained control and performance for different values of the probability that the principal vetoes a policy change she does not like in the O8 organizational structure. Note that control and performance are measured as losses from the optimum, i.e. as rank distance between the actual policy vector and the most wanted or most fit one. Thus a loss of control 0 means that the principal obtains exactly her most preferred policy vector and a loss of performance 0 means that the chosen equilibrium is the best policy vector in the true ranking.
Table 3. The effect of veto in O8

P = Probability; N. = Number; perform. = performance.
The results change somehow if instead of the mere power to veto changes of the status quo that are against her preferences, the principal can impose by fiat her most preferred subset of policies to each agent. Table 4 summarizes these results. Obviously if the principal always intervenes by fiat she can get full control, but the number of possible equilibria and best performance are considerably lower than when only veto power can be exerted. Also, the reduction of cycles is less sharp than when veto is used.
Table 4. The effect of fiat in O8

P = Probability; N. = Number; perform. = performance.
Using fiat in organizations with coarser partitions of decisions makes control even easier, but the outcome is worse in terms of performance (and, as we will see below, also in terms of learning), because coarser organizations produce a smaller amount of possible organizational equilibria. For instance, Table 5 presents the results obtained by increasing levels of probability of intervention by fiat in a O2-type organization.
Table 5. The effect of fiat in O2

P = Probability; N. = Number; perform. = performance.
If we consider the case in which agenda repetition is not allowed and an organizational outcome is reached after all agents have taken their decisions only once, we find that stronger results. In this case we already noticed that the number of organizational outcomes is larger and the use of veto or fiat power makes it even larger. These findings are reported in Table 6 for veto power (similar results are obtained for fiat power).
Table 6. The effect of veto in O8, without agenda repetition

P = Probability; N. = Number; perform. = performance.
Not too surprisingly, throughout our simulation experiments ‘more power’ – in terms of depth and probabilities of its exercise – yields more organizational control over agents’ behaviors. And with that also comes easier coordinating properties of the organization itself.
Interestingly, also organizational performance grows with the exercise of authority, but up to a point. There is no monotonicity here and there appear to be three ‘phases’ in the system, namely: (1) with no or low exercise of authority coordination is difficult and organizational performance is low; (2) with robust exercise of authority coordination is easy and performance high; (3) with extremely deep and detailed exercise of authority coordination is easy but performance is worse. The reason of the latter worsening of performance is exactly a consequence of the higher level of control that is achieved by more frequent use of veto or fiat power. Limited use of authority increases coordination and generates a landscape with multiple equilibria or outcomes, but if the frequency in the use of authority increases further the number of equilibria and outcomes begin shrinking as control further increases and the organizational landscapes become more similar to the principal’s landscape (which is single-peaked by definition).
As we shall shortly see, these properties are broadly corroborated by set-ups involving different types of learning.
4.3 Competence
Competence can be defined in our framework as the correlation between the individual subjective rankings of policy vectors and the true one. Individuals whose ranking is more correlated with the true one have a better representation of the environment in which the organization operates. The question we briefly address in this subsection is where more competent individuals should be placed in our organization. The question is not all new and has been already addressed in some papers (see for instance Garicano (Reference Garicano2000) and Garicano and Rossi-Hansberg (Reference Garicano and Rossi-Hansberg2006)), but here we develop it in our framework of highly heterogeneous agents and delegation.
First, and quite trivially, if the principal is fully competent (i.e. knows the right ranking of policy vectors), she should exercise a maximum degree of authority by always overruling the agents’ decision which are not in accordance with her preferences. In this limit case the principal should not delegate, or, equivalently, delegate all decisions to only one agent and always overrule him.
More interesting is the case in which the principal is more competent than all the agents but her correlation with the true ranking is less than one. In this case we are back to a case in which highest control and highest performance can be achieved by partitioning and delegating decisions (structure O8 allows to achieve the highest levels of control and performance) together with the exercise of an intermediate level of authority.
Let us now turn to agents’ competence. We have built populations of agents characterized by different degrees of competence, i.e. correlation between their subjective ranking and the true one, and we have tested whether delegating more decisions to more competent agents always increases performance. The answer in general is no, except in the limit case in which one agent is fully or almost fully competent (his ranking is equal to or very highly correlated with the true one) and all or almost all decisions are delegated to him. As the competence of the most competent agent decreases the highest performing organizational structure quickly switches to O8, thus more competent agents are delegated as few decisions as less competent ones.
Both results show a clear discontinuity: if the allocation of decisions is (almost) optimal and someone’s competence is (almost) maximum, then the most competent agent should also be given highest decision power, otherwise there is no reason to give more power to more competent agents. It must be noticed that this result is strictly dependent on our rather extreme assumption on complexity: since both the organizational and the true landscapes are randomly generated, they both tend to be uncorrelated, therefore two policy vectors which are relatively close (in Hamming distance) may be far away in ranking both in the organizational and in the true landscape. In less complex environments, where instead policy vectors which differ in very few policy items are also very close in ranking, indeed more competent agents should be allocated a larger portion of the decisions.
4.4 Learning
In our model learning can only take place through trial-and-error: by experimenting different organizational equilibria the principal and the agents can acquire information on the relative value of different policy vectors and adapt accordingly their subjective rankings. Therefore, the existence of a multiplicity of organizational equilibria is a fundamental driver for learning. As we have already pointed out, the number of organizational equilibria or outcome is higher either when decisions are highly partitioned and authority is used in order to prevent cycles or when the agenda is not repeated. A careful balance between partition of decisions and use of authority is therefore needed to increase learning.
Figure 1 plots the average Spearman rank correlation coefficient for organizations O8 and O2 for different values of veto probabilities when  $\pi _{\text{padapt}}=1$ (i.e. the principal always updates her ranking when new organizational equilibria are tested in the environment) and when the agenda can be repeated. It is worth noting the inverted U-shape of the relation between the use of veto power and principal’s adaptation in O8: too little use of veto power decreases learning because of the high frequency of cycles, too much use of it because it decreases exploration (many policy changes that would produce good organizational equilibria are vetoed).
$\pi _{\text{padapt}}=1$ (i.e. the principal always updates her ranking when new organizational equilibria are tested in the environment) and when the agenda can be repeated. It is worth noting the inverted U-shape of the relation between the use of veto power and principal’s adaptation in O8: too little use of veto power decreases learning because of the high frequency of cycles, too much use of it because it decreases exploration (many policy changes that would produce good organizational equilibria are vetoed).

Figure 1. The effect of veto power on principal’s learning in O8 and O2.
In O2 instead this inverted U-shape does not appear and learning steadily (though slowly) increases with the frequency of veto.
A similar, but even stronger, result is obtained also when fiat instead of veto power is considered, as shown in Figure 2.

Figure 2. The effect of fiat power on principal’s learning in O8 and O2.
If we do not allow for agenda repetition we obtain very similar patterns (for the sake of brevity we do not report the corresponding graphs), but the values of the average Spearman rank correlation coefficients are significantly higher than the ones obtained with repetition because, as we showed above, without agenda repetition the number of organizational outcomes is considerably higher and therefore there can be more exploration.
A similar inverted U-shaped relation can be found also for the relation between probability of intervention by fiat and average performance, while average control increases, as shown in Figure 3 (where  $\pi _{\text{padapt}}=1$). Moreover, the impact of fiat power is higher the higher the decentralization of knowledge and decision rights (compare O8 and O2).
$\pi _{\text{padapt}}=1$). Moreover, the impact of fiat power is higher the higher the decentralization of knowledge and decision rights (compare O8 and O2).

Figure 3. The effect of fiat power and principal’s adaptation on performance and control in O8.
Interestingly enough, if we allow adaptation not only by the principal but also by the agents we do not observe any significant improvement on the principal’s learning in O8, but we do in O2, as shown in Figure 4.

Figure 4. The effect of veto power and agents’ adaptation on principal’s learning in O8 and O2.
The result is even stronger if fiat instead of veto power is considered: in this case allowing agent to adapt has a negative effect on principal’s learning (see Figure 5).

Figure 5. The effect of fiat power on principal’s learning in O8 with and without agent adaptation.
The reason for this seemingly counter-intuitive result is that learning by the agents decreases coordination and makes the organizational landscape unstable in the organizational structure O8 with many agents. The instability instead is much lower in O2 where only two agents must coordinate. Indeed, these results appear to suggest that an organizational set-up particularly conducive to learning involves multiple decentralized searches but also a centralized ‘exploitation’ of the outcomes of such exploratory efforts.
Figure 6 shows the effect of veto power on average agents’ learning in O8 and O2.

Figure 6. The effect of veto power on agents’ learning in O8 and O2.
Finally we can introduce agent’s adaptation to the principal’s preferences, what we called agent’s docility. Obviously agent’s docility greatly increases principal’s control, provided the principal exerts some authority,Footnote 9 as shown by Figure 7, where we plot average and best control for different values of veto probability when 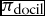 $\pi _{\text{docil}}$ is set to 1 in organization O8.
$\pi _{\text{docil}}$ is set to 1 in organization O8.

Figure 7. The effect of veto power on control with agents’ docility in O8.
However, docility decreases learning by the principal and performance: as agents adapt their preferences to the principal’s, exploration of new possible equilibria decreases and the scope for learning by the principal is reduced, as is average performance. If we let 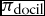 $\pi _{\text{docil}}$ vary between 0 and 1 we obtain a decay in principal’s learning: Figure 8 plots Spearman’s correlation between the principal’s ranking and the true one as an indicator of principal’s learning when
$\pi _{\text{docil}}$ vary between 0 and 1 we obtain a decay in principal’s learning: Figure 8 plots Spearman’s correlation between the principal’s ranking and the true one as an indicator of principal’s learning when  $\pi _{\text{padapt}}=1$ and in the two extreme cases in which
$\pi _{\text{padapt}}=1$ and in the two extreme cases in which 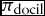 $\pi _{\text{docil}}$ is either 0 or 1 and shows that learning by the principal is significantly higher in the former case. Figure 9 plots instead average performance in both cases and shows that also performance decreases with higher values of agents’ docility. It is however interesting to notice that the decay in principal’s learning and performance begins only when veto power is exercised by the principal with some frequency (approximately more than 0.15 or 0.2), and that below that threshold docility seems to have on the contrary a small positive effect on learning and performance. The reason is that docility makes coordination easier (agents slowly converge to a common ranking of policy vectors, i.e. the one of the principal) and decreases the number of cycles, which tends to be high when veto and fiat are infrequently used.
$\pi _{\text{docil}}$ is either 0 or 1 and shows that learning by the principal is significantly higher in the former case. Figure 9 plots instead average performance in both cases and shows that also performance decreases with higher values of agents’ docility. It is however interesting to notice that the decay in principal’s learning and performance begins only when veto power is exercised by the principal with some frequency (approximately more than 0.15 or 0.2), and that below that threshold docility seems to have on the contrary a small positive effect on learning and performance. The reason is that docility makes coordination easier (agents slowly converge to a common ranking of policy vectors, i.e. the one of the principal) and decreases the number of cycles, which tends to be high when veto and fiat are infrequently used.

Figure 8. Principal’s learning with high or low agents’ docility in O8 for different probabilities of veto.

Figure 9. Average and best performance with high or low agents’ docility in O8 for different probabilities of veto.
Finally, by considering together the results presented so far, we can outline a possible evolutionary pattern of organizations in relation to the environment they face. When facing a new ill-structured problem, high heterogeneity, cognitive diversity, and conflict are conducive to high levels of exploration and an organizational structure with finely partitioned decision rights may further enhance it. However, at the same time, diversity and conflict must be balanced by a considerable authority intervention, in order to preserve coordination and control. As learning proceeds and the principal acquires a better representation of the problem (and of course if the environment is stable) the structure of delegation becomes less relevant and docility can effectively substitute veto and fiat power.
5. Conclusions
Power and authority, on the one side, and cognitive and behavioral adaptation, on the other, are fundamental dimensions of an economic organization or, for that matter, of all social institutions. In this work we have presented a simple computational model which allows to analyze some of the links between these two dimensions. First, we show, not surprisingly, that authority and power exercise significantly facilitates coordination. Second, and much less intuitive, a robust exercise of veto and fiat power by a super-imposed authority greatly enhances also organizational performance up to a point: ubiquitous exercise of power yields easy coordination but worsens performance. Hence the third finding: higher organizational performance comes together with some balance between decentralized local coordination on the one hand and centralized authority on the other.
These properties are corroborated and indeed strengthened when one allows for organizational learning, both by the principal and by the agents. Our fourth result is that the exercise of authority not only makes coordination easier, but also collective learning more effective. However, the proposition holds as long as some balance between exploration and exploitation is preserved. A too-strict exercise of authority degrades the learning abilities of the organization. Moreover, the most effective organizational set-ups appear to be those in which exploration (learning) is decentralized while exploitation (the ensuing coordinating rules) is centralized by the principal.
What about ‘docility’, that is adaptation by the agents in their cognition, preferences, and behavioral rules? Our fifth set of findings shows that docility is the ‘high powered’ version (and indeed largely substitute) of authority. It is more effective than the latter in achieving coordination, but it can hinder exploration if too strong and fast. An organization made of fully docile members coordinates very smoothly but learns relatively little, since all the learning has to be picked up by the principal, loosing all the efficacy of decentralized search.
Our model is highly simplified, but captures, we believe, some fundamental aspects of the tension between centralized and decentralized decision making in complex organizations where decisions are highly interdependent. Our main point is that power and authority are institutional mechanisms that can produce stability in such circumstances and lead to higher organizational performance. Decentralized decision making in a setting characterized by high degrees of complexity and interdependence usually fails to produce some stable outcome, but if combined with the exercise of some authority it can on the contrary produce a variety of outcomes, increasing the possibility of both coordination and learning.
Acknowledgements
We thank three anonymous referees and the guest editor of the special issue for very detailed and useful comments which have greatly contributed to improving the paper. The usual caveats apply.















