


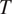
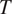
1. Introduction
Across languages, morphology often fails to mark grammatically relevant distinctions in some contexts. For instance, Danish marks the gender of third person pronouns in the singular, as shown in (1a), but fails to do so in the plural, as shown in (1b). In the plural, a single form is used, whether the referent is a group containing only female individuals, male individuals or both.

Cases where morphological paradigms are less rich than what the free combination of grammatical features available in a language would lead us to expect are known as cases of syncretism (e.g. Greenberg Reference Greenberg1966: 27; Baerman, Brown & Corbett Reference Baerman, Brown and Corbett2005). For instance, gender is syncretic in plural pronouns but not in singular pronouns in Danish. Interestingly, the range of attested syncretic patterns is more restricted than what is logically possible: across languages, some grammatical contexts favor the syncretic expression of other grammatical features and cross-linguistic generalizations about patterns of syncretism often have an implicational form (Greenberg Reference Greenberg and Greenberg1963, Reference Greenberg1966). For instance, gender is often syncretic in plural pronouns but less so in singular pronouns and, cross-linguistically, the presence of gender distinctions in the plural asymmetrically entails the presence of gender distinctions in the singular (see Greenberg’s Reference Greenberg and Greenberg1963 Universal 45).
What is the source of syncretism? Why do some grammatical contexts favor syncretism of other grammatical features and why do generalizations in this domain have an implicational form? Since Greenberg’s (Reference Greenberg and Greenberg1963) seminal work, several concurrent analyses have been proposed to answer these questions, ranging from frequency-based explanations (e.g. Greenberg Reference Greenberg1966; Croft Reference Croft1990; Jäger Reference Jäger2007; Haspelmath & Sims Reference Haspelmath and Sims2010) to structural explanations based on Universal Grammar (e.g. Harley & Ritter Reference Harley and Ritter2002). This paper adopts a specific version of the frequency-based approach, where morphological patterns are shaped by communicative biases towards accurate message transmission and low resource cost (e.g. Martinet Reference Martinet1962; Jäger Reference Jäger2007; Piantadosi, Tily & Gibson Reference Piantadosi, Tily and Gibson2012; Gibson et al. Reference Gibson, Futrell, Piantadosi, Dautriche, Mahowald, Bergen and Levy2019). Under this view, syncretism arises when the resource cost of expressing a grammatical distinction morphologically in a context is not compensated by a large enough gain in decoding accuracy. Language variation results from different ways of resolving the conflict between minimizing resource cost on the speaker’s part (which favors small morphological paradigms) and maximizing decoding accuracy on the listener’s part (which favors morphological paradigms that are as large as allowed by the free combination of available grammatical features). The interaction of these two conflicting goals takes place in a synchronic model of the speaker’s morphological productions using weighted constraints (Smolensky & Legendre Reference Smolensky and Legendre2006). These constraint-based models are widely used in phonology to derive implicational generalizations in sound patterns.
Section 2 shows how this approach, together with the assumption that grammatical features are drawn from the same probability distributions across languages, predicts that cross-linguistic generalizations about morphological syncretism should have an implicational form. More specifically, this approach predicts that grammatical contexts that are less probable or more informative about a target grammatical feature
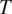 $ T $
should favor syncretism of
$ T $
should favor syncretism of
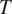 $ T $
cross-linguistically. Section 3 shows how the theory derives the typology of syncretism in three well-known case studies: gender syncretism based on number, gender syncretism based on person, and aspect syncretism based on tense. Section 4 extends the model introduced in Section 2 to deal with more complex cases where the cost of syncretism is not independent from context to context. The extended model is applied successfully to another well-known case study: case syncretism based on animacy.
$ T $
cross-linguistically. Section 3 shows how the theory derives the typology of syncretism in three well-known case studies: gender syncretism based on number, gender syncretism based on person, and aspect syncretism based on tense. Section 4 extends the model introduced in Section 2 to deal with more complex cases where the cost of syncretism is not independent from context to context. The extended model is applied successfully to another well-known case study: case syncretism based on animacy.
The four generalizations addressed in Sections 3 and 4 are, to the author’s knowledge, among the most discussed implicational generalizations in morphological syncretism. They therefore constitute a plausible set of cases against which models of syncretism should be evaluated. Section 5 discusses alternative analyses that do not rely on synchronic (possibly implicit) communicative biases and shows that they all fail on at least one of the four case studies. In particular, the current approach is compared with the closely related frequency-based approach where morphological asymmetries arise diachronically in the transmission from one generation to the next, but crucially without any specific bias towards communicatively efficient patterns from learners or speakers (e.g. Haspelmath & Sims Reference Haspelmath and Sims2010: ch. 12). In this approach, syncretism arises when one of the values of a grammatical feature is rare in a grammatical context in speakers’ productions and therefore the corresponding morph fails to be correctly learned by learners of the language (Haspelmath & Sims Reference Haspelmath and Sims2010: 272–273). The paper shows that the two approaches make different predictions when the recoverability of a grammatical feature is high in a given grammatical context but the values of the relevant feature all occur frequently in this context: the synchronic model predicts that syncretism should be likely in this case, due to high recoverability, whereas the diachronic model predicts that syncretism should be unlikely, due to high frequency. The case study on gender syncretism based on person discussed in Section 3 will be shown to support the model assuming synchronic communicative biases on the part of learners or speakers.
The idea that communicative efficiency plays a role in shaping linguistic patterns across languages, and in particular morphological patterns, is not new (e.g. Martinet Reference Martinet1962; Hawkins Reference Hawkins2004; Jäger Reference Jäger2007; Piantadosi et al. Reference Piantadosi, Tily and Gibson2012; Gibson et al. Reference Gibson, Futrell, Piantadosi, Dautriche, Mahowald, Bergen and Levy2019; Haspelmath Reference Haspelmath2021). In particular, a growing body of experimental evidence has accumulated that speakers make communicatively efficient choices when producing morphology (e.g. Kurumada & Jaeger Reference Kurumada and Jaeger2015) and that learners may reshape their morphological input in order to improve its efficiency (e.g. Fedzechkina, Jaeger & Newport Reference Fedzechkina, Jaeger and Newport2012). The specific contribution that this paper makes to this research theme is threefold. First, it focuses specifically on the question of whether a feature is expressed syncretically or not in a given context (i.e. whether the different values of that feature are expressed ambiguously or not). This question differs from the question that is more often addressed in the literature on morphological marking across languages (e.g. Haspelmath Reference Haspelmath2021), namely the question of how a given feature value is expressed morphologically (through overt or zero marking). Second, the paper includes a comparison of different approaches to syncretism: all four approaches considered here are shown to make different predictions on the four case studies in the paper, a fact that has not been noted before, to the author’s knowledge. Finally, the analysis is couched in a grammatical model familiar to linguists, and in particular to phonologists, namely a model with weighted constraints. Adopting a common framework to account for phonology and morphology is a step towards a better understanding of the similarity between morphological syncretism and phonological neutralization (Greenberg Reference Greenberg1966: 29; Martinet Reference Martinet1968), as will be discussed in Section 6.
2. Model
This section proposes a model of the syntax-morphology interface where the mapping from grammatical features to morphs is regulated by two constraints: a constraint that aims to minimize misinterpretation of the morphology on the part of the hearer and a constraint that aims to minimize the size of morphological paradigms. It is not possible to satisfy completely both constraints as they correspond to contradictory demands: minimizing ambiguity is only possible at the cost of making the morphology more complex. Language variation comes from different ways of resolving the conflict between universal, but contradictory, demands.
The model focuses on the simplest case where a binary grammatical feature
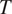 $ T $
with two exhaustive and mutually exclusive feature values
$ T $
with two exhaustive and mutually exclusive feature values
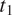 $ {t}_1 $
and
$ {t}_1 $
and
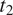 $ {t}_2 $
(e.g. sex-based gender, with feature values ‘feminine’ and ‘masculine’) is targeted by syncretism in a grammatical context
$ {t}_2 $
(e.g. sex-based gender, with feature values ‘feminine’ and ‘masculine’) is targeted by syncretism in a grammatical context
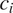 $ {c}_i $
(belonging to a grammatical feature
$ {c}_i $
(belonging to a grammatical feature
 $ C $
; e.g. ‘plural’ belonging to the feature ‘number’). There are cases where non-binary grammatical features are subject to syncretism. For instance, Latin does not distinguish masculine, feminine, and neuter nouns in the dative and ablative plural (e.g. Latin -is is used to mark the ablative plural of masculine, feminine, and neuter nouns, as in domin-is ‘master’-masc.abl.pl, ros-is ‘rose’-fem.abl.pl’, and uerb-is ‘word’-neut.abl.pl). In this case, syncretism therefore targets a ternary feature. However, these cases are relatively marginal in the literature on implicational generalizations: in particular, the four case studies treated in this paper all involve binary grammatical features. As a consequence, cases of syncretism targeting non-binary features will be left aside here. There are also cases of syncretism that do not involve a single grammatical feature but combinations of grammatical features. For instance, in Latin, the same morph -ae conveys the genitive singular and the nominative plural of feminine nouns (e.g. famili-ae ‘family’-gen.sg/nom.pl). The two combinations of feature values (genitive singular vs. nominative plural) do not form a minimal pair: both case and number vary. These patterns are often treated as involving accidental or arbitrary homophony (see Baerman et al. Reference Baerman, Brown and Corbett2005 on the distinction between accidental and systematic syncretism). Accidental syncretism is not prominent in the literature on implicational generalizations and therefore will be left aside as well.
$ C $
; e.g. ‘plural’ belonging to the feature ‘number’). There are cases where non-binary grammatical features are subject to syncretism. For instance, Latin does not distinguish masculine, feminine, and neuter nouns in the dative and ablative plural (e.g. Latin -is is used to mark the ablative plural of masculine, feminine, and neuter nouns, as in domin-is ‘master’-masc.abl.pl, ros-is ‘rose’-fem.abl.pl’, and uerb-is ‘word’-neut.abl.pl). In this case, syncretism therefore targets a ternary feature. However, these cases are relatively marginal in the literature on implicational generalizations: in particular, the four case studies treated in this paper all involve binary grammatical features. As a consequence, cases of syncretism targeting non-binary features will be left aside here. There are also cases of syncretism that do not involve a single grammatical feature but combinations of grammatical features. For instance, in Latin, the same morph -ae conveys the genitive singular and the nominative plural of feminine nouns (e.g. famili-ae ‘family’-gen.sg/nom.pl). The two combinations of feature values (genitive singular vs. nominative plural) do not form a minimal pair: both case and number vary. These patterns are often treated as involving accidental or arbitrary homophony (see Baerman et al. Reference Baerman, Brown and Corbett2005 on the distinction between accidental and systematic syncretism). Accidental syncretism is not prominent in the literature on implicational generalizations and therefore will be left aside as well.
Technically, not expressing a grammatically relevant distinction morphologically in a particular grammatical context incurs a cost, called the ‘ambiguity cost’ of a paradigm (see Section 2.1). Expressing this grammatical distinction morphologically also incurs a cost, called the ‘size cost’ of a paradigm (see Section 2.2). The size of a paradigm (i.e. the number of distinct cells in this paradigm) is used as a proxy for resource cost: smaller paradigms should be easier to store, process, and produce. Morphological paradigms are evaluated with respect to a weighted sum of their ambiguity and size costs (see Section 2.3), as in Harmonic Grammar (HG) (Smolensky & Legendre Reference Smolensky and Legendre2006). These costs contain (i) a language-universal component, namely the definitions of the costs, and (ii) a language-specific component, represented by language-specific, positive weights associated with each constraint. Different choices of weights will result in different trade-offs between clarity and morphological complexity. Section 2.4 describes how this model predicts the existence of implicational generalizations in patterns of morphological syncretism.
2.1 Ambiguity cost
Formally, the ambiguity cost of mapping values
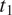 $ {t}_1 $
and
$ {t}_1 $
and
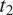 $ {t}_2 $
of a binary grammatical feature
$ {t}_2 $
of a binary grammatical feature
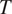 $ T $
to the same morph
$ T $
to the same morph
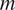 $ m $
in a grammatical context
$ m $
in a grammatical context
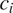 $ {c}_i $
is assumed to be proportional to the probability that the hearer misinterprets
$ {c}_i $
is assumed to be proportional to the probability that the hearer misinterprets
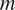 $ m $
in
$ m $
in
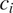 $ {c}_i $
. The hearer misinterprets
$ {c}_i $
. The hearer misinterprets
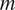 $ m $
when they interpret a speaker uttering
$ m $
when they interpret a speaker uttering
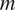 $ m $
and intending
$ m $
and intending
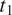 $ {t}_1 $
as intending
$ {t}_1 $
as intending
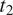 $ {t}_2 $
or the other way around. Note that the model implies that the hearer always assumes that the speaker meant either
$ {t}_2 $
or the other way around. Note that the model implies that the hearer always assumes that the speaker meant either
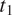 $ {t}_1 $
or
$ {t}_1 $
or
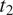 $ {t}_2 $
when using a syncretic form to convey
$ {t}_2 $
when using a syncretic form to convey
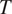 $ T $
. In other words, the model assumes that syncretic morphology is semantically ambiguous (
$ T $
. In other words, the model assumes that syncretic morphology is semantically ambiguous (
 $ m $
means
$ m $
means
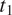 $ {t}_1 $
or means
$ {t}_1 $
or means
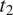 $ {t}_2 $
) rather than semantically underspecified (
$ {t}_2 $
) rather than semantically underspecified (
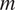 $ m $
denotes the disjunction of the two feature values
$ m $
denotes the disjunction of the two feature values
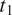 $ {t}_1 $
and
$ {t}_1 $
and
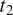 $ {t}_2 $
). This assumption will be further discussed at the end of this section.
$ {t}_2 $
). This assumption will be further discussed at the end of this section.
The probability of error is noted as
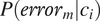 $ P\left({error}_m|{c}_i\right) $
: it corresponds to the conditional probability that the hearer misinterprets
$ P\left({error}_m|{c}_i\right) $
: it corresponds to the conditional probability that the hearer misinterprets
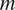 $ m $
given that the grammatical context is
$ m $
given that the grammatical context is
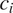 $ {c}_i $
. Sections 2 and 3 focus on cases where this probability can be assumed to be independent of whether
$ {c}_i $
. Sections 2 and 3 focus on cases where this probability can be assumed to be independent of whether
 $ T $
is syncretic in another context
$ T $
is syncretic in another context
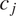 $ {c}_j $
. Section 4 will extend the model to cases where the independence assumption does not hold.
$ {c}_j $
. Section 4 will extend the model to cases where the independence assumption does not hold.
The hearer is assumed to use the strategy that minimizes the probability that they will make an error: they default to the most likely feature value among
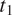 $ {t}_1 $
and
$ {t}_1 $
and
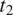 $ {t}_2 $
in
$ {t}_2 $
in
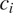 $ {c}_i $
in case of syncretism. Because
$ {c}_i $
in case of syncretism. Because
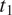 $ {t}_1 $
and
$ {t}_1 $
and
 $ {t}_2 $
are the only values available for the grammatical feature
$ {t}_2 $
are the only values available for the grammatical feature
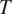 $ T $
(because
$ T $
(because
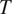 $ T $
is binary by assumption) and cannot co-occur in
$ T $
is binary by assumption) and cannot co-occur in
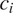 $ {c}_i $
(because
$ {c}_i $
(because
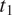 $ {t}_1 $
and
$ {t}_1 $
and
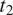 $ {t}_2 $
are mutually exclusive by assumption), the two conditional probabilities
$ {t}_2 $
are mutually exclusive by assumption), the two conditional probabilities
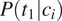 $ P\left({t}_1|{c}_i\right) $
and
$ P\left({t}_1|{c}_i\right) $
and
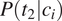 $ P\left({t}_2|{c}_i\right) $
sum to one. As a consequence, the probability of error in
$ P\left({t}_2|{c}_i\right) $
sum to one. As a consequence, the probability of error in
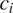 $ {c}_i $
will be equal to the probability of the least likely feature value in
$ {c}_i $
will be equal to the probability of the least likely feature value in
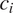 $ {c}_i $
in Equation (1).
$ {c}_i $
in Equation (1).
 $$ P\left({error}_m|{c}_i\right)=\min \left\{P\left({t}_1|{c}_i\right),P\left({t}_2|{c}_i\right)\right\} $$
$$ P\left({error}_m|{c}_i\right)=\min \left\{P\left({t}_1|{c}_i\right),P\left({t}_2|{c}_i\right)\right\} $$
This approach predicts that, in case of syncretism, the probability of error will be smaller in contexts where the two feature values are more imbalanced. For instance, in a context
 $ {c}_i $
where the two feature values have imbalanced probabilities, e.g.
$ {c}_i $
where the two feature values have imbalanced probabilities, e.g.
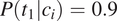 $ P\left({t}_1|{c}_i\right)=0.9 $
and
$ P\left({t}_1|{c}_i\right)=0.9 $
and
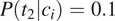 $ P\left({t}_2|{c}_i\right)=0.1 $
, the probability of incorrectly identifying the feature value intended by the speaker is rather small (here it is equal to 0.1). In a context
$ P\left({t}_2|{c}_i\right)=0.1 $
, the probability of incorrectly identifying the feature value intended by the speaker is rather small (here it is equal to 0.1). In a context
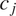 $ {c}_j $
where the probabilities are closer to 0.5, e.g.
$ {c}_j $
where the probabilities are closer to 0.5, e.g.
 $ P\left({t}_1|{c}_j\right)=0.6 $
and
$ P\left({t}_1|{c}_j\right)=0.6 $
and
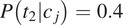 $ P\left({t}_2|{c}_j\right)=0.4 $
, the probability of error is larger (here it is equal to 0.4). As one of the two feature values becomes less likely relative to the other one, the probability of error in case of syncretism decreases.Footnote
2
$ P\left({t}_2|{c}_j\right)=0.4 $
, the probability of error is larger (here it is equal to 0.4). As one of the two feature values becomes less likely relative to the other one, the probability of error in case of syncretism decreases.Footnote
2
To obtain the contribution of syncretic morphology
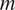 $ m $
in context
$ m $
in context
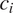 $ {c}_i $
to the overall probability of error, the conditional probability
$ {c}_i $
to the overall probability of error, the conditional probability
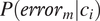 $ P\left({error}_m|{c}_i\right) $
is multiplied by the probability of context
$ P\left({error}_m|{c}_i\right) $
is multiplied by the probability of context
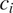 $ {c}_i $
,
$ {c}_i $
,
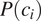 $ P\left({c}_i\right) $
. This captures the following intuition: the more frequent the context conditioning the syncretic expression of a grammatical distinction, the larger the number of errors on the part of the listener.
$ P\left({c}_i\right) $
. This captures the following intuition: the more frequent the context conditioning the syncretic expression of a grammatical distinction, the larger the number of errors on the part of the listener.
The ambiguity cost of mapping
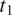 $ {t}_1 $
and
$ {t}_1 $
and
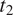 $ {t}_2 $
to two different morphs
$ {t}_2 $
to two different morphs
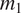 $ {m}_1 $
and
$ {m}_1 $
and
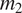 $ {m}_2 $
is assumed to be equal to zero. If the two feature values are distinguished morphologically (and assuming that the likelihood of misidentifying two phonetically distinct morphs is negligible), a hearer can deterministically recover the meaning intended by the speaker.
$ {m}_2 $
is assumed to be equal to zero. If the two feature values are distinguished morphologically (and assuming that the likelihood of misidentifying two phonetically distinct morphs is negligible), a hearer can deterministically recover the meaning intended by the speaker.
To account for the fact that languages show different degrees of syncretism, languages are further assumed to vary in the importance attributed to minimizing misinterpretation. This is implemented by multiplying the ambiguity cost defined above by a language-specific, positive weight
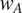 $ {w}_A $
, where
$ {w}_A $
, where
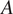 $ A $
stands for ambiguity. The weight on the ambiguity cost is also assumed to be specific to a particular grammatical feature: a language therefore has potentially different weights for each grammatical feature (but this weight is the same for a given feature across contexts). This allows a language to adopt different morphological strategies for different grammatical features.
$ A $
stands for ambiguity. The weight on the ambiguity cost is also assumed to be specific to a particular grammatical feature: a language therefore has potentially different weights for each grammatical feature (but this weight is the same for a given feature across contexts). This allows a language to adopt different morphological strategies for different grammatical features.
In sum, the ambiguity cost for the syncretic and non-syncretic expressions of two feature values
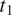 $ {t}_1 $
and
$ {t}_1 $
and
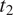 $ {t}_2 $
in a context
$ {t}_2 $
in a context
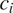 $ {c}_i $
and a language with ambiguity weight
$ {c}_i $
and a language with ambiguity weight
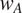 $ {w}_A $
for that feature can be written as in Equation (2).
$ {w}_A $
for that feature can be written as in Equation (2).
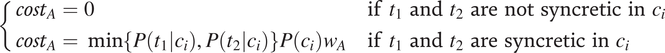 $$ \left\{\begin{array}{ll}{cost}_A=0& \mathrm{if}\hskip0.3em {t}_1\hskip0.3em \mathrm{and}\hskip0.3em {t}_2\hskip0.3em \mathrm{are}\hskip0.3em \mathrm{not}\hskip0.3em \mathrm{syncretic}\hskip0.3em \mathrm{in}\hskip0.3em {c}_i\\ {}{cost}_A=\min \left\{P\left({t}_1|{c}_i\right),P\left({t}_2|{c}_i\right)\right\}P\left({c}_i\right){w}_A& \mathrm{if}\hskip0.3em {t}_1\hskip0.3em \mathrm{and}\hskip0.3em {t}_2\hskip0.3em \mathrm{are}\hskip0.3em \mathrm{syncretic}\hskip0.3em \mathrm{in}\hskip0.3em {c}_i\end{array}\right. $$
$$ \left\{\begin{array}{ll}{cost}_A=0& \mathrm{if}\hskip0.3em {t}_1\hskip0.3em \mathrm{and}\hskip0.3em {t}_2\hskip0.3em \mathrm{are}\hskip0.3em \mathrm{not}\hskip0.3em \mathrm{syncretic}\hskip0.3em \mathrm{in}\hskip0.3em {c}_i\\ {}{cost}_A=\min \left\{P\left({t}_1|{c}_i\right),P\left({t}_2|{c}_i\right)\right\}P\left({c}_i\right){w}_A& \mathrm{if}\hskip0.3em {t}_1\hskip0.3em \mathrm{and}\hskip0.3em {t}_2\hskip0.3em \mathrm{are}\hskip0.3em \mathrm{syncretic}\hskip0.3em \mathrm{in}\hskip0.3em {c}_i\end{array}\right. $$
As pointed out at the beginning of this section, the model assumes that a syncretic morph is semantically ambiguous rather than semantically underspecified. However, the model could probably be restated in terms of underspecification. In particular, syncretism should lead to more uncertainty about the speaker’s message under the syncretism-as-underspecification view as well. For instance, if a speaker uses a morph conveying an underspecified predicate including both animate and inanimate referents in its denotation to refer to an animate referent, the hearer will be more likely to make an incorrect identification of the intended referent than if the speaker uses a morph strictly denoting the set of animate referents. Indeed, the set of animates is a strict subset of the set of animates and inanimates. The syncretism-as-ambiguity view was adopted here mainly for practical purposes. It is easier to represent the choice between two alternative features (for instance, animate and inanimate) than between multiple referents (in the case of pronominal gender, for instance). Also, under the ambiguity view, one can easily obtain information on the frequencies of features using corpus data and then infer the ambiguity cost of syncretism using Equation (2).
2.2 Size cost
For the same underlying feature system, a paradigm with syncretism includes a smaller number of distinct word forms than a morphological paradigm without syncretism. Syncretism therefore allows for a reduction of the size of the mental lexicon. For instance, the paradigm of English animate third person pronouns features gender syncretism in the plural and contains three distinct word forms (he, she, they). The corresponding paradigm in French maintains a gender distinction across both numbers but does so at the cost of increasing the size of the paradigm: the French paradigm contains four instead of three distinct word forms (il, elle, ils, elles).Footnote 3
Several benefits follow from having a smaller lexicon in general. A smaller lexicon provides an obvious advantage in terms of storage. As Croft (Reference Croft1990: 254) puts it, ‘minimizing the number of distinct linguistic forms that must be acquired and retained presumably minimizes the load on memory’. A smaller lexicon also provides benefits in terms of production and processing cost. Indeed, if there are fewer words in a lexicon, these words are allowed to be shorter, more frequent, and more probable phonotactically, making production and processing more efficient (e.g. Jaeger & Tily Reference Jaeger and Tily2011; Piantadosi et al. Reference Piantadosi, Tily and Gibson2012).Footnote 4 For practical purposes, the size of the paradigm will be used as a proxy for storage, production, and processing costs in the remainder of the paper.
The size cost of having two distinct morphs to express two feature values is assumed to be equal to one for any context. The size cost of having a single morph to express the two feature values is assumed to be equal to zero for any context. The probability of the context is not assumed to play a role in this cost for the following reason: although contexts that are more frequent should increase the overall processing cost of a morphological distinction as compared to less frequent contexts (in the same way as ambiguity in more frequent contexts resulted in a larger ambiguity cost), more frequent forms are also easier to process, according to the well-known word frequency effect (Brysbaert, Mandera & Keuleers Reference Brysbaert, Mandera and Keuleers2018). A simple way to accommodate these contradictory effects is to assume that they cancel each other.
Languages are further assumed to vary in the importance they attribute to minimizing the size of morphological paradigms. This is implemented by multiplying the size cost in syncretic and non-syncretic contexts by a language-specific, positive weight
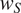 $ {w}_S $
, where
$ {w}_S $
, where
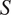 $ S $
stands for size. As for the ambiguity cost, the weight on the size cost is assumed to be specific to a particular grammatical feature and constant for all contexts in which this feature occurs.
$ S $
stands for size. As for the ambiguity cost, the weight on the size cost is assumed to be specific to a particular grammatical feature and constant for all contexts in which this feature occurs.
In sum, the size cost for syncretic and non-syncretic expressions of two feature values
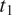 $ {t}_1 $
and
$ {t}_1 $
and
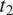 $ {t}_2 $
in a context
$ {t}_2 $
in a context
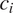 $ {c}_i $
and a language with weight
$ {c}_i $
and a language with weight
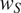 $ {w}_S $
for that particular feature can be written as in Equation (3).
$ {w}_S $
for that particular feature can be written as in Equation (3).
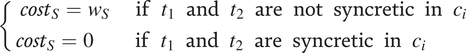 $$ \left\{\begin{array}{cc}{cost}_S={w}_S& \mathrm{if}\hskip0.5em {t}_1\hskip0.5em \mathrm{and}\hskip0.5em {t}_2\hskip0.5em \mathrm{are}\hskip0.5em \mathrm{not}\hskip0.5em \mathrm{syncretic}\hskip0.5em \mathrm{in}\hskip0.5em {c}_i\\ {}{cost}_S=0\hskip1em & \mathrm{if}\hskip0.5em {t}_1\hskip0.5em \mathrm{and}\hskip0.5em {t}_2\hskip0.5em \mathrm{are}\hskip0.5em \mathrm{syncretic}\hskip0.5em \mathrm{in}\hskip0.5em {c}_{i\hskip4.5em }\end{array}\right. $$
$$ \left\{\begin{array}{cc}{cost}_S={w}_S& \mathrm{if}\hskip0.5em {t}_1\hskip0.5em \mathrm{and}\hskip0.5em {t}_2\hskip0.5em \mathrm{are}\hskip0.5em \mathrm{not}\hskip0.5em \mathrm{syncretic}\hskip0.5em \mathrm{in}\hskip0.5em {c}_i\\ {}{cost}_S=0\hskip1em & \mathrm{if}\hskip0.5em {t}_1\hskip0.5em \mathrm{and}\hskip0.5em {t}_2\hskip0.5em \mathrm{are}\hskip0.5em \mathrm{syncretic}\hskip0.5em \mathrm{in}\hskip0.5em {c}_{i\hskip4.5em }\end{array}\right. $$
2.3 Balancing ambiguity and size
The preference for syncretism or no syncretism depends on which of the ambiguity cost or size cost is larger. It is equally good to have syncretism or no syncretism in a given context if the two costs as defined in Equation (2) and (3) are equal, that is if Equation (4) holds.
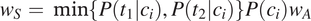 $$ {w}_S=\min \left\{P\left({t}_1|{c}_i\right),P\left({t}_2|{c}_i\right)\right\}P\left({c}_i\right){w}_A $$
$$ {w}_S=\min \left\{P\left({t}_1|{c}_i\right),P\left({t}_2|{c}_i\right)\right\}P\left({c}_i\right){w}_A $$
Assuming trivially that
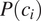 $ P\left({c}_i\right) $
is non-null, Equation (4) is equivalent to Equation (5).
$ P\left({c}_i\right) $
is non-null, Equation (4) is equivalent to Equation (5).
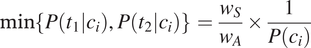 $$ \min \left\{P\left({t}_1|{c}_i\right),P\left({t}_2|{c}_i\right)\right\}=\frac{w_S}{w_A}\times \frac{1}{P\left({c}_i\right)} $$
$$ \min \left\{P\left({t}_1|{c}_i\right),P\left({t}_2|{c}_i\right)\right\}=\frac{w_S}{w_A}\times \frac{1}{P\left({c}_i\right)} $$
Assuming trivially that all probabilities are non-null, it is possible to take the natural logarithm of both sides of Equation (5) to obtain Equation (6). The logarithmic transformation makes it possible to express
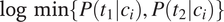 $ \log \min \left\{P\left({t}_1|{c}_i\right),P\left({t}_2|{c}_i\right)\right\} $
as a linear function of
$ \log \min \left\{P\left({t}_1|{c}_i\right),P\left({t}_2|{c}_i\right)\right\} $
as a linear function of
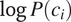 $ \log P\left({c}_i\right) $
.
$ \log P\left({c}_i\right) $
.
 $$ \log \left(\min \left\{P\left({t}_1|{c}_i\right),P\left({t}_2|{c}_i\right)\right\}\right)=-\log P\left({c}_i\right)+\left(\log {w}_S-\log {w}_A\right) $$
$$ \log \left(\min \left\{P\left({t}_1|{c}_i\right),P\left({t}_2|{c}_i\right)\right\}\right)=-\log P\left({c}_i\right)+\left(\log {w}_S-\log {w}_A\right) $$
Equation (6) is the equation of a line with slope
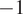 $ -1 $
and intercept
$ -1 $
and intercept
 $ \log {w}_S-\log {w}_A $
. This line is graphically represented in Figure 1 for arbitrarily chosen weights.
$ \log {w}_S-\log {w}_A $
. This line is graphically represented in Figure 1 for arbitrarily chosen weights.
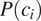 $ P\left({c}_i\right) $
takes values between 0 and 1. Therefore
$ P\left({c}_i\right) $
takes values between 0 and 1. Therefore
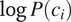 $ \log P\left({c}_i\right) $
takes values between
$ \log P\left({c}_i\right) $
takes values between
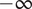 $ -\infty $
and 0. The probability
$ -\infty $
and 0. The probability
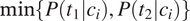 $ \min \left\{P\left({t}_1|{c}_i\right),P\left({t}_2|{c}_i\right)\right\} $
takes values between 0 and 0.5. It cannot be larger than 0.5 because it is defined as the smaller of two probabilities summing to one. Therefore
$ \min \left\{P\left({t}_1|{c}_i\right),P\left({t}_2|{c}_i\right)\right\} $
takes values between 0 and 0.5. It cannot be larger than 0.5 because it is defined as the smaller of two probabilities summing to one. Therefore
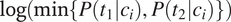 $ \log \left(\min \left\{P\left({t}_1|{c}_i\right),P\left({t}_2|{c}_i\right)\right\}\right) $
takes values between
$ \log \left(\min \left\{P\left({t}_1|{c}_i\right),P\left({t}_2|{c}_i\right)\right\}\right) $
takes values between
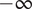 $ -\infty $
and
$ -\infty $
and
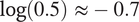 $ \log (0.5)\hskip0.3em \approx -0.7 $
. Accordingly, the area above
$ \log (0.5)\hskip0.3em \approx -0.7 $
. Accordingly, the area above
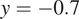 $ y=-0.7 $
is grayed out in Figure 1.
$ y=-0.7 $
is grayed out in Figure 1.
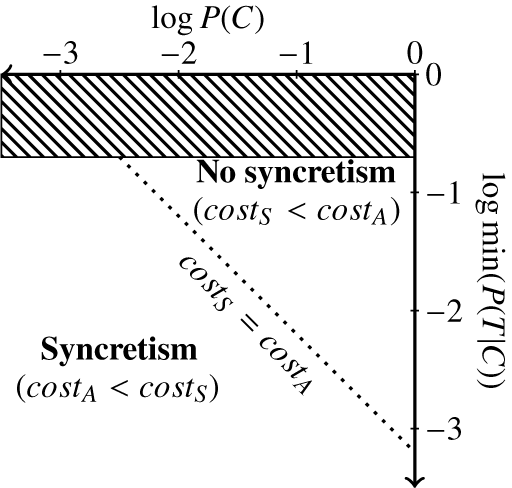
Figure 1 Morphological expression (syncretism vs. no syncretism) of a target grammatical (binary) feature
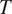 $ T $
depending on the grammatical context
$ T $
depending on the grammatical context
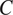 $ C $
where it occurs (with arbitrarily chosen weights for the ambiguity and size costs).
$ C $
where it occurs (with arbitrarily chosen weights for the ambiguity and size costs).
The dotted line depicted in Figure 1 corresponds to values of
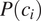 $ P\left({c}_i\right) $
and
$ P\left({c}_i\right) $
and
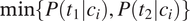 $ \min \left\{P\left({t}_1|{c}_i\right),P\left({t}_2|{c}_i\right)\right\} $
for which the syncretic and non-syncretic expressions of
$ \min \left\{P\left({t}_1|{c}_i\right),P\left({t}_2|{c}_i\right)\right\} $
for which the syncretic and non-syncretic expressions of
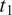 $ {t}_1 $
and
$ {t}_1 $
and
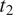 $ {t}_2 $
in context
$ {t}_2 $
in context
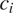 $ {c}_i $
have the same cost. The area under the line corresponds to contexts where the cost of adding a morphological distinction outweighs the benefit in terms of disambiguation, namely, where syncretism is enforced. The area above the line corresponds to contexts where the interpretative benefit of adding a morphological distinction outweighs the cost in terms of size, namely, where syncretism is banned.
$ {c}_i $
have the same cost. The area under the line corresponds to contexts where the cost of adding a morphological distinction outweighs the benefit in terms of disambiguation, namely, where syncretism is enforced. The area above the line corresponds to contexts where the interpretative benefit of adding a morphological distinction outweighs the cost in terms of size, namely, where syncretism is banned.
The intercept varies as a function of
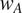 $ {w}_A $
and
$ {w}_A $
and
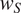 $ {w}_S $
: the larger
$ {w}_S $
: the larger
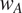 $ {w}_A $
is with respect to
$ {w}_A $
is with respect to
 $ {w}_S $
, the smaller the intercept
$ {w}_S $
, the smaller the intercept
 $ \log {w}_S-\log {w}_A $
and the smaller the set of contexts allowing for syncretism of
$ \log {w}_S-\log {w}_A $
and the smaller the set of contexts allowing for syncretism of
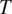 $ T $
. This captures the desired effect: as it becomes more important to increase decoding accuracy, morphological distinctions are made in a larger set of contexts (and therefore morphological paradigms get larger). However, the slope does not vary as a function of the weights and is therefore constant and equal to
$ T $
. This captures the desired effect: as it becomes more important to increase decoding accuracy, morphological distinctions are made in a larger set of contexts (and therefore morphological paradigms get larger). However, the slope does not vary as a function of the weights and is therefore constant and equal to
 $ -1 $
across languages.
$ -1 $
across languages.
2.4 Deriving implicational generalizations
Analyses using frequency asymmetries to explain typological generalizations about linguistic patterns hypothesize that these frequency asymmetries are universal (Greenberg Reference Greenberg1966; Croft Reference Croft1990; Jäger Reference Jäger2007). This paper follows this tradition. In the specific model discussed here, the hypothesis of universal frequency asymmetries is formalized by positing that, for all grammatical features
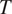 $ T $
and
$ T $
and
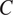 $ C $
, the joint probability distribution of the two features,
$ C $
, the joint probability distribution of the two features,
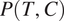 $ P\left(T,C\right) $
, is fixed across languages. This hypothesis will remain an assumption throughout this work.
$ P\left(T,C\right) $
, is fixed across languages. This hypothesis will remain an assumption throughout this work.
With this assumption in place, the main locus of typological variation predicted by the model lies in the weights
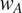 $ {w}_A $
and
$ {w}_A $
and
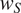 $ {w}_S $
. Because the slope of the line separating syncretic and non-syncretic contexts in the probability space is constant across languages (see Section 2.3), the following prediction is made: the presence of syncretism in some contexts asymmetrically entails the presence of syncretism in other contexts.
$ {w}_S $
. Because the slope of the line separating syncretic and non-syncretic contexts in the probability space is constant across languages (see Section 2.3), the following prediction is made: the presence of syncretism in some contexts asymmetrically entails the presence of syncretism in other contexts.
This is illustrated in Figure 2, for two grammatical contexts
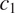 $ {c}_1 $
and
$ {c}_1 $
and
 $ {c}_2 $
. Among the four logically possible ways of expressing the distinction between
$ {c}_2 $
. Among the four logically possible ways of expressing the distinction between
 $ {t}_1 $
and
$ {t}_1 $
and
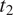 $ {t}_2 $
in
$ {t}_2 $
in
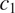 $ {c}_1 $
and
$ {c}_1 $
and
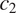 $ {c}_2 $
, only three are predicted to be attested: the pattern without syncretism in any of the two contexts (Figure 2a), the pattern with syncretism only in
$ {c}_2 $
, only three are predicted to be attested: the pattern without syncretism in any of the two contexts (Figure 2a), the pattern with syncretism only in
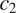 $ {c}_2 $
(Figure 2b) and the pattern with syncretism across the two contexts (Figure 2c). The pattern with syncretism only in
$ {c}_2 $
(Figure 2b) and the pattern with syncretism across the two contexts (Figure 2c). The pattern with syncretism only in
 $ {c}_1 $
is predicted to be impossible: there is no line with slope equal to
$ {c}_1 $
is predicted to be impossible: there is no line with slope equal to
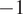 $ -1 $
that is above
$ -1 $
that is above
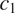 $ {c}_1 $
and under
$ {c}_1 $
and under
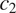 $ {c}_2 $
. In other words, the following implicational generalization is derived: syncretism in context
$ {c}_2 $
. In other words, the following implicational generalization is derived: syncretism in context
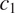 $ {c}_1 $
entails syncretism in context
$ {c}_1 $
entails syncretism in context
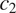 $ {c}_2 $
(or equivalently, a morphological distinction in
$ {c}_2 $
(or equivalently, a morphological distinction in
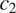 $ {c}_2 $
entails a morphological distinction in
$ {c}_2 $
entails a morphological distinction in
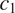 $ {c}_1 $
).
$ {c}_1 $
).

Figure 2 Deriving an implicational generalization in morphological syncretism.
The model derives implicational generalizations in the typology of morphological syncretism and predicts furthermore that contexts that lead to fewer identification errors of
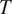 $ T $
in case of syncretism should favor syncretism of
$ T $
in case of syncretism should favor syncretism of
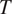 $ T $
. Indeed, if a morphological distinction can be made only in one of two contexts, the model predicts that it will be in the context where the probability of error is the smaller. Indeed, the size cost of a morphological distinction is not context-dependent (see Section 2.2 for justification). Therefore, the choice to neutralize a morphological distinction in a context
$ T $
. Indeed, if a morphological distinction can be made only in one of two contexts, the model predicts that it will be in the context where the probability of error is the smaller. Indeed, the size cost of a morphological distinction is not context-dependent (see Section 2.2 for justification). Therefore, the choice to neutralize a morphological distinction in a context
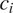 $ {c}_i $
or a context
$ {c}_i $
or a context
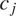 $ {c}_j $
only depends on the ambiguity cost of syncretic morphology in the two contexts: whichever context corresponds to the larger ambiguity cost for the syncretic expression of
$ {c}_j $
only depends on the ambiguity cost of syncretic morphology in the two contexts: whichever context corresponds to the larger ambiguity cost for the syncretic expression of
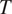 $ T $
should be more likely to distinguish
$ T $
should be more likely to distinguish
 $ {t}_1 $
and
$ {t}_1 $
and
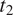 $ {t}_2 $
morphologically. Because the weight on the ambiguity cost relative to
$ {t}_2 $
morphologically. Because the weight on the ambiguity cost relative to
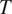 $ T $
is assumed to be the same for the two contexts in a given language, which context will favor syncretism will ultimately depend on the relationship between the probabilities of misidentifying
$ T $
is assumed to be the same for the two contexts in a given language, which context will favor syncretism will ultimately depend on the relationship between the probabilities of misidentifying
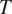 $ T $
in the two contexts. Context
$ T $
in the two contexts. Context
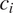 $ {c}_i $
will favor syncretism of
$ {c}_i $
will favor syncretism of
 $ T $
and context
$ T $
and context
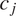 $ {c}_j $
will favor the non-syncretic expression of
$ {c}_j $
will favor the non-syncretic expression of
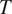 $ T $
in the language if the probability of misidentifying
$ T $
in the language if the probability of misidentifying
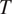 $ T $
is smaller in
$ T $
is smaller in
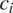 $ {c}_i $
than in
$ {c}_i $
than in
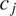 $ {c}_j $
, that is, if the following inequality holds:
$ {c}_j $
, that is, if the following inequality holds:
 $$ \min \left\{P\left({t}_1|{c}_i\right),P\left({t}_2|{c}_i\right)\right\}P\left({c}_i\right)<\min \left\{P\left({t}_1|{c}_j\right),P\left({t}_2|{c}_j\right)\right\}P\left({c}_j\right) $$
$$ \min \left\{P\left({t}_1|{c}_i\right),P\left({t}_2|{c}_i\right)\right\}P\left({c}_i\right)<\min \left\{P\left({t}_1|{c}_j\right),P\left({t}_2|{c}_j\right)\right\}P\left({c}_j\right) $$
or equivalently:
 $$ \min \left\{P\left({t}_1,{c}_i\right),P\left({t}_2,{c}_i\right)\right\}<\min \left\{P\left({t}_1,{c}_j\right),P\left({t}_2,{c}_j\right)\right\}\Big) $$
$$ \min \left\{P\left({t}_1,{c}_i\right),P\left({t}_2,{c}_i\right)\right\}<\min \left\{P\left({t}_1,{c}_j\right),P\left({t}_2,{c}_j\right)\right\}\Big) $$
As shown in Equation (7), two probabilities contribute to the overall probabilities of error shown in Equation (8): the probability of the grammatical context,
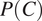 $ P(C) $
, and the conditional probability distribution of the target grammatical feature given that context,
$ P(C) $
, and the conditional probability distribution of the target grammatical feature given that context,
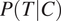 $ P\left(T|C\right) $
. The two paragraphs below explain how these two probabilities should affect the morphological expression of
$ P\left(T|C\right) $
. The two paragraphs below explain how these two probabilities should affect the morphological expression of
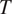 $ T $
, pointing to places in the literature where the role of these probabilities has been discussed in connection with morphological syncretism.
$ T $
, pointing to places in the literature where the role of these probabilities has been discussed in connection with morphological syncretism.
Probability of the context. Everything else being equal, syncretism in a context with a larger probability should entail syncretism in a context with a smaller probability (see the x-axis in Figure 2). The reason is that, everything else being equal, syncretism in a context that is more probable will result in more errors on the part of the listener than syncretism in a context that is less probable. If a speaker is willing to neutralize a morphological distinction in a context where it is more helpful to the listener, then they should also be willing to neutralize it in a context where it is less helpful to the listener. The hypothesis that a grammatical context that is less probable is more likely to favor syncretism of another grammatical feature is well known in the literature (e.g. Croft Reference Croft1990: 72, 158; Haspelmath & Sims Reference Haspelmath and Sims2010: ch. 12) and dates back at least to Greenberg (Reference Greenberg1966).
Conditional probability of the target grammatical feature. Everything else being equal, syncretism in a context
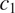 $ {c}_1 $
where the probability distribution
$ {c}_1 $
where the probability distribution
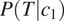 $ P\left(T|{c}_1\right) $
is less skewed towards one of the two feature values should entail syncretism in a context
$ P\left(T|{c}_1\right) $
is less skewed towards one of the two feature values should entail syncretism in a context
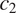 $ {c}_2 $
where
$ {c}_2 $
where
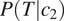 $ P\left(T|{c}_2\right) $
is more skewed (see the y-axis in Figure 2;
$ P\left(T|{c}_2\right) $
is more skewed (see the y-axis in Figure 2;
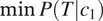 $ \min P\left(T|{c}_1\right) $
is closer to 0.5 than
$ \min P\left(T|{c}_1\right) $
is closer to 0.5 than
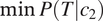 $ \min P\left(T|{c}_2\right) $
, and therefore
$ \min P\left(T|{c}_2\right) $
, and therefore
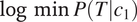 $ \log \min P\left(T|{c}_1\right) $
is closer to
$ \log \min P\left(T|{c}_1\right) $
is closer to
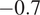 $ -0.7 $
than
$ -0.7 $
than
 $ \log \min P\left(T|{c}_2\right) $
). The reason is that defaulting to the most likely interpretation should result in more identification errors on the hearer’s part in case the conditional probability distribution is less skewed (e.g. in
$ \log \min P\left(T|{c}_2\right) $
). The reason is that defaulting to the most likely interpretation should result in more identification errors on the hearer’s part in case the conditional probability distribution is less skewed (e.g. in
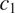 $ {c}_1 $
than in
$ {c}_1 $
than in
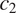 $ {c}_2 $
). If a speaker is willing to neutralize a morphological distinction in a context where this distinction would be more helpful to the listener (e.g.
$ {c}_2 $
). If a speaker is willing to neutralize a morphological distinction in a context where this distinction would be more helpful to the listener (e.g.
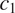 $ {c}_1 $
in the example in Figure 2), they should also be willing to neutralize it in a context where it would be less helpful to the listener (e.g.
$ {c}_1 $
in the example in Figure 2), they should also be willing to neutralize it in a context where it would be less helpful to the listener (e.g.
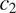 $ {c}_2 $
in the example in Figure 2). This prediction can be restated in information-theoretic terms: if there is syncretism in a context that is less informative about a grammatical feature
$ {c}_2 $
in the example in Figure 2). This prediction can be restated in information-theoretic terms: if there is syncretism in a context that is less informative about a grammatical feature
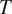 $ T $
(e.g.
$ T $
(e.g.
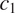 $ {c}_1 $
in the example in Figure 2), there should be syncretism in a context that is more informative about
$ {c}_1 $
in the example in Figure 2), there should be syncretism in a context that is more informative about
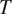 $ T $
(e.g.
$ T $
(e.g.
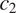 $ {c}_2 $
in the example in Figure 2).
$ {c}_2 $
in the example in Figure 2).
The latter prediction does not seem to have received as much emphasis in the literature on syncretism as the former one. For instance, Haspelmath and Sims’s (Reference Haspelmath and Sims2010: ch. 12) morphology textbook only highlights the probability of the context. In the present approach, the conditional probability of the target grammatical feature is crucial because it reflects how informative the context is about that feature. The relevance of conditional probability to linguistic patterns has been emphasized more generally in information-theoretic accounts of lexical ambiguity (Piantadosi et al. Reference Piantadosi, Tily and Gibson2012).
3. Case studies
The approach presented in Section 2 makes specific predictions about contexts that should favor morphological syncretism typologically (see Section 2.4). This section argues that these predictions are borne out in three well-known case studies. Sections 3.1 and 3.2 focus on two implicational generalizations involving gender syncretism in pronouns. Section 3.3 focuses on the typology of aspect syncretism.
Most probabilities used in the paper are estimated using corpus frequencies. Spoken language is usually considered as more relevant than written language for typological purposes, on the assumption that typology is shaped by communicative interactions between speakers (e.g. Croft Reference Croft1990; Jäger Reference Jäger2007). For this reason, corpora of spoken speech or written corpora that are closest to speech (e.g. corpora of dialogs, corpora of subtitles) will be given preference. In two cases though (gender in duals and gender in first/second person pronouns), no corpora were available to estimate the relevant probabilities. In these cases, a specific probability value was chosen for concreteness, either by assuming random sampling (see Section 3.1 on duals) or by assuming a very low probability of error for the identification of gender in first and second person pronouns (see Section 3.2).
3.1 Gender syncretism based on number
3.1.1 Greenberg’s Universal 45
Greenberg’s Universal 45 is probably one of the most famous implicational generalizations involving syncretism. It states that if there are any gender distinctions in the plural of the pronoun, there are also some gender distinctions in the singular (Greenberg Reference Greenberg and Greenberg1963: 60). As stated, this generalization is supposed to apply to all pronouns. However, it is typically mentioned in the typological literature about third person pronouns. Also, the quantitative data in Siewierska (Reference Siewierska, Dryer and Haspelmath2013) directly support a narrower version of Universal 45 applying to third person pronouns only: her data do not specify how the expression of gender differs in singular vs. plural first and second persons cross-linguistically.
Siewierska’s (Reference Siewierska, Dryer and Haspelmath2013) survey is summarized in Table 1 as a contingency table classifying languages according to whether they mark gender in singular and plural third person pronouns. These data support Greenberg’s Universal 45, in a statistical sense: languages with gender distinctions in plural pronouns only are very few (there is only one such language in her survey) compared to the three other types of languages.Footnote 5 The question of how to deal with exceptions in the present model, which only derives absolute implicational generalizations, is left aside for now (see Section 5.2).
Table 1 Greenberg’s Universal 45: Gender distinctions in third person pronouns (Siewierska Reference Siewierska, Dryer and Haspelmath2013).

Examples of third person pronoun paradigms with different types of gender syncretism in the singular and in the plural are shown in Table 2, going from Spanish (with a gender distinction in both numbers) in Table 2a to Turkish (without any gender distinction in any number) in Table 2d. Syncretic forms are enclosed in boxes, following the convention in Baerman et al. (Reference Baerman, Brown and Corbett2005).
Table 2 Examples of third person pronoun paradigms with various degrees of gender syncretism.

In languages that maintain a gender distinction in the plural (e.g. Spanish in Table 2a), one of the two forms is typically used to refer to mixed groups. In Spanish, the masculine is used to refer to both male-only groups and mixed groups. In Buin, the feminine form is used to refer to both female-only groups and mixed groups (Laycock Reference Laycock2003: xv). But there are also some languages that use a special form to refer to mixed groups (e.g. Vanimo; Plank & Schellinger Reference Plank and Schellinger1997: 76). This variability in the way mixed groups are treated morphologically will not be addressed further in this paper.Footnote 6
Among the two patterns of contextual syncretism represented by Danish (Table 2b) and Tahaggart Tuareg (Table 2c), the former one is the most common across languages. Indeed, Tahaggart Tuareg (Table 2c) has gender distinctions in the plural only and is therefore an exception to Universal 45. Plank & Schellinger (Reference Plank and Schellinger1997: 62–65) list a handful of additional exceptions which were not part of Siewierska’s sample.
3.1.2 Deriving Greenberg’s Universal 45
The theory laid out in Section 2 predicts that plural pronouns should favor gender syncretism as compared to singular pronouns if the probability of misidentifying gender is smaller in plurals than in singulars in case of gender syncretism, namely, if the following holds (where gender 1 and gender 2 refer to the two values of the relevant binary gender feature, e.g. masc and fem):
 $$ \min \left\{P\left({\mathrm{GENDER}}_1,\mathrm{PL}\right),P\left({\mathrm{GENDER}}_2,\mathrm{PL}\right)\right\}<\min \left\{P\left({\mathrm{GENDER}}_1,\mathrm{SG}\right),P\left({\mathrm{GENDER}}_2,\mathrm{SG}\right)\right\} $$
$$ \min \left\{P\left({\mathrm{GENDER}}_1,\mathrm{PL}\right),P\left({\mathrm{GENDER}}_2,\mathrm{PL}\right)\right\}<\min \left\{P\left({\mathrm{GENDER}}_1,\mathrm{SG}\right),P\left({\mathrm{GENDER}}_2,\mathrm{SG}\right)\right\} $$
This equation is likely to generally hold for two reasons. First, in nominal categories, singular is more frequent than plural cross-linguistically (Greenberg Reference Greenberg1966: 32; Croft Reference Croft1990: 157), that is,
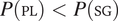 $ P\left(\mathrm{PL}\right)<P\left(\mathrm{SG}\right) $
. Second, the probability distribution of gender conditioned on number should be more skewed in the plural than in the singular, that is,
$ P\left(\mathrm{PL}\right)<P\left(\mathrm{SG}\right) $
. Second, the probability distribution of gender conditioned on number should be more skewed in the plural than in the singular, that is,
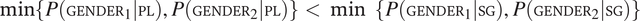 $ \min \left\{P\left({\mathrm{GENDER}}_1|\mathrm{PL}\right),P\left({\mathrm{GENDER}}_2|\mathrm{PL}\right)\right\}<\min \left\{P\left({\mathrm{GENDER}}_1|\mathrm{SG}\right),P\left({\mathrm{GENDER}}_2|\mathrm{SG}\right)\right\} $
. The most common gender distinction used across languages is based on sex (male/female; Corbett Reference Corbett, Dryer and Haspelmath2013). In the singular, sex-based gender partitions the set of individuals in roughly two equal groups: assuming random sampling, the probability that any random individual belongs to one of the two groups is roughly equal to 0.5. Beyond sex-based gender, equal likelihood of feature values seems to be a common property of two-gender systems (whether gender is entirely semantic or partly semantic and partly lexical), as noted by Polinsky & Van Everbroeck (Reference Polinsky and van Everbroeck2003: 359): ‘many two-gender systems have a roughly equal balance in both type and token frequency across the two genders’. However, this property does not extend to plurals. Indeed, a binary gender predicate that partitions the set of individuals in two equal-sized groups does not partition the corresponding set of groups of individuals into two equal-sized compartments. For instance, sex-based gender partitions a set of individuals including two men and two women in two equal-sized groups but does not partition the corresponding set of groups of individuals in two equal-sized compartments: among the 11 groups that can be formed from this set of four individuals, 10 are in the extension of masc (assuming a language like Spanish where masc is the default gender value, covering both only-male groups and mixed groups) and only one in the extension of fem (i.e. the group that contains the two women).Footnote
7
$ \min \left\{P\left({\mathrm{GENDER}}_1|\mathrm{PL}\right),P\left({\mathrm{GENDER}}_2|\mathrm{PL}\right)\right\}<\min \left\{P\left({\mathrm{GENDER}}_1|\mathrm{SG}\right),P\left({\mathrm{GENDER}}_2|\mathrm{SG}\right)\right\} $
. The most common gender distinction used across languages is based on sex (male/female; Corbett Reference Corbett, Dryer and Haspelmath2013). In the singular, sex-based gender partitions the set of individuals in roughly two equal groups: assuming random sampling, the probability that any random individual belongs to one of the two groups is roughly equal to 0.5. Beyond sex-based gender, equal likelihood of feature values seems to be a common property of two-gender systems (whether gender is entirely semantic or partly semantic and partly lexical), as noted by Polinsky & Van Everbroeck (Reference Polinsky and van Everbroeck2003: 359): ‘many two-gender systems have a roughly equal balance in both type and token frequency across the two genders’. However, this property does not extend to plurals. Indeed, a binary gender predicate that partitions the set of individuals in two equal-sized groups does not partition the corresponding set of groups of individuals into two equal-sized compartments. For instance, sex-based gender partitions a set of individuals including two men and two women in two equal-sized groups but does not partition the corresponding set of groups of individuals in two equal-sized compartments: among the 11 groups that can be formed from this set of four individuals, 10 are in the extension of masc (assuming a language like Spanish where masc is the default gender value, covering both only-male groups and mixed groups) and only one in the extension of fem (i.e. the group that contains the two women).Footnote
7
This very general reasoning is also supported by corpus data. Data from Cuetos et al.’s (Reference Cuetos, Glez-Nosti, Barbón and Brysbaert2011) corpus of Spanish subtitles (Table 3) are used to illustrate this point. In this corpus, the cumulated frequency of singular pronouns ella ‘she’ and él ‘he’ is larger than the cumulated frequency of the corresponding plural pronouns (ellas ‘they’-fem and ellos ‘they’-masc), in accordance with the hypothesis that singular pronouns are more frequent than plural pronouns. Moreover, the frequency distribution of gender values is more skewed in the plural than in the singular. Indeed, in the plural, the masculine form is much more frequent than the feminine form (arguably because masculine plural forms refer to both mixed and male-only groups in Spanish). In the singular, the two feature values are almost equally likely, in accordance with Polinsky & Van Everbroeck’s (Reference Polinsky and van Everbroeck2003) observation on two-gender systems. As a consequence, the prediction in Equation 9 is supported: the probability of gender misidentification is smaller in the plural (
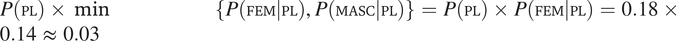 $ P\left(\mathrm{PL}\right)\times \min \left\{P\left(\mathrm{FEM}|\mathrm{PL}\right),P\left(\mathrm{MASC}|\mathrm{PL}\right)\right\}=P\left(\mathrm{PL}\right)\times P\left(\mathrm{FEM}|\mathrm{PL}\right)=0.18\times 0.14\hskip0.3em \approx \hskip0.3em 0.03 $
) than in the singular (
$ P\left(\mathrm{PL}\right)\times \min \left\{P\left(\mathrm{FEM}|\mathrm{PL}\right),P\left(\mathrm{MASC}|\mathrm{PL}\right)\right\}=P\left(\mathrm{PL}\right)\times P\left(\mathrm{FEM}|\mathrm{PL}\right)=0.18\times 0.14\hskip0.3em \approx \hskip0.3em 0.03 $
) than in the singular (
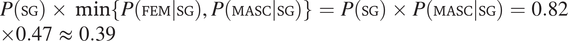 $ P\left(\mathrm{SG}\right)\times \min \left\{P\left(\mathrm{FEM}|\mathrm{SG}\right),P\left(\mathrm{MASC}|\mathrm{SG}\right)\right\}=P\left(\mathrm{SG}\right)\times P\left(\mathrm{MASC}|\mathrm{SG}\right)=0.82\times 0.47\hskip0.3em \approx \hskip0.3em 0.39 $
) and, as a consequence, gender syncretism is correctly predicted to arise preferentially in the plural.
$ P\left(\mathrm{SG}\right)\times \min \left\{P\left(\mathrm{FEM}|\mathrm{SG}\right),P\left(\mathrm{MASC}|\mathrm{SG}\right)\right\}=P\left(\mathrm{SG}\right)\times P\left(\mathrm{MASC}|\mathrm{SG}\right)=0.82\times 0.47\hskip0.3em \approx \hskip0.3em 0.39 $
) and, as a consequence, gender syncretism is correctly predicted to arise preferentially in the plural.
Table 3 Frequency of number and frequency of gender conditioned on number in Spanish subject tonic pronouns in SUBTLEX-ESP (corpus size: 41 million words): frequency per million of words (Freq 1) and relative frequencies (Freq 2).

3.1.3 The case of duals
So far, only singular and plural numbers have been considered. What happens in languages that have more than one non-singular number category, e.g. languages with plurals and duals? To the author’s knowledge, there is no comprehensive typological survey on gender syncretism across different non-singular numbers. Some languages maintain gender distinctions across all three numbers, as illustrated by Murui Huitoto in Table 4a. Furthermore, the two possible patterns of contextual syncretism involving duals and plurals are attested (Tables 4b and 4c). But further typological surveys are needed to establish whether one of these two patterns is more frequent across languages.
Table 4 Examples of pronoun paradigms with dual number.

Although the typology of gender syncretism in non-singular numbers does not seem to have been investigated in detail, it is still possible to consider what predictions the current model derives. The model predicts that duals should favor gender syncretism as compared to plurals if the following holds:
 $$ \min \left\{P\left(\mathrm{FEM},\mathrm{DU}\right),P\left(\mathrm{MASC},\mathrm{DU}\right)\right\}<\min \left\{P\left(\mathrm{FEM},\mathrm{PL}\right),P\left(\mathrm{MASC},\mathrm{PL}\right)\right\} $$
$$ \min \left\{P\left(\mathrm{FEM},\mathrm{DU}\right),P\left(\mathrm{MASC},\mathrm{DU}\right)\right\}<\min \left\{P\left(\mathrm{FEM},\mathrm{PL}\right),P\left(\mathrm{MASC},\mathrm{PL}\right)\right\} $$
Greenberg (Reference Greenberg1966: 32) notes that the dual is about five times less likely than the plural in a Sanskrit corpus (see Table 5), suggesting that
 $ P\left(\mathrm{DU}\right)<P\left(\mathrm{PL}\right) $
. However, the distribution of gender should theoretically be less skewed towards one of the two gender values in the dual than in the plural (i.e.
$ P\left(\mathrm{DU}\right)<P\left(\mathrm{PL}\right) $
. However, the distribution of gender should theoretically be less skewed towards one of the two gender values in the dual than in the plural (i.e.
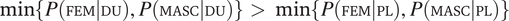 $ \min \left\{P\left(\mathrm{FEM}|\mathrm{DU}\right),P\left(\mathrm{MASC}|\mathrm{DU}\right)\right\}>\min \left\{P\left(\mathrm{FEM}|\mathrm{PL}\right),P\left(\mathrm{MASC}|\mathrm{PL}\right)\right\} $
). Indeed, assuming simple random sampling, a group containing two individuals should be more likely to be female-only (or male-only) than a group containing more individuals. For concreteness, if female individuals are as likely to form referents for duals than male individuals, the probability of feminine duals should be equal to
$ \min \left\{P\left(\mathrm{FEM}|\mathrm{DU}\right),P\left(\mathrm{MASC}|\mathrm{DU}\right)\right\}>\min \left\{P\left(\mathrm{FEM}|\mathrm{PL}\right),P\left(\mathrm{MASC}|\mathrm{PL}\right)\right\} $
). Indeed, assuming simple random sampling, a group containing two individuals should be more likely to be female-only (or male-only) than a group containing more individuals. For concreteness, if female individuals are as likely to form referents for duals than male individuals, the probability of feminine duals should be equal to
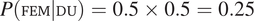 $ P\left(\mathrm{FEM}|\mathrm{DU}\right)=0.5\times 0.5=0.25 $
and the probability of masculine duals to
$ P\left(\mathrm{FEM}|\mathrm{DU}\right)=0.5\times 0.5=0.25 $
and the probability of masculine duals to
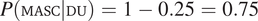 $ P\left(\mathrm{MASC}|\mathrm{DU}\right)=1-0.25=0.75 $
,Footnote
8 and therefore
$ P\left(\mathrm{MASC}|\mathrm{DU}\right)=1-0.25=0.75 $
,Footnote
8 and therefore
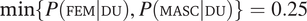 $ \min \left\{P\left(\mathrm{FEM}|\mathrm{DU}\right),P\left(\mathrm{MASC}|\mathrm{DU}\right)\right\}=0.25 $
. This number is larger than what we would expect for plurals referring to groups with size larger than two (under the same sampling assumptions). Also, it is larger than the smallest of the two conditional probabilities of gender in the plural observed in the Spanish corpus (
$ \min \left\{P\left(\mathrm{FEM}|\mathrm{DU}\right),P\left(\mathrm{MASC}|\mathrm{DU}\right)\right\}=0.25 $
. This number is larger than what we would expect for plurals referring to groups with size larger than two (under the same sampling assumptions). Also, it is larger than the smallest of the two conditional probabilities of gender in the plural observed in the Spanish corpus (
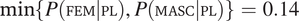 $ \min \left\{P\left(\mathrm{FEM}|\mathrm{PL}\right),P\left(\mathrm{MASC}|\mathrm{PL}\right)\right\}=0.14 $
; see Table 3). But the probability of duals is probably low enough to compensate for this asymmetry in conditional probabilities (see Table 5). Indeed, in case of gender syncretism, the probability of error is still predicted to be larger in the plural (
$ \min \left\{P\left(\mathrm{FEM}|\mathrm{PL}\right),P\left(\mathrm{MASC}|\mathrm{PL}\right)\right\}=0.14 $
; see Table 3). But the probability of duals is probably low enough to compensate for this asymmetry in conditional probabilities (see Table 5). Indeed, in case of gender syncretism, the probability of error is still predicted to be larger in the plural (
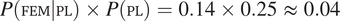 $ P\left(\mathrm{FEM}|\mathrm{PL}\right)\times P\left(\mathrm{PL}\right)=0.14\times 0.25\hskip0.3em \approx \hskip0.3em 0.04 $
) than in the dual (
$ P\left(\mathrm{FEM}|\mathrm{PL}\right)\times P\left(\mathrm{PL}\right)=0.14\times 0.25\hskip0.3em \approx \hskip0.3em 0.04 $
) than in the dual (
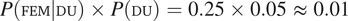 $ P\left(\mathrm{FEM}|\mathrm{DU}\right)\times P\left(\mathrm{DU}\right)=0.25\times 0.05\hskip0.3em \approx \hskip0.3em 0.01 $
). Under the assumptions described above, the theory therefore predicts that gender distinctions in dual pronouns should asymmetrically entail gender distinctions in plural pronouns. Lavukaleve (in Table 4) should then be analyzed as an exception. Note that this prediction is compatible with the classic markedness-based approach according to which duals are more marked and hence less likely to feature gender distinctions than plurals (see Section 5.1 for further discussion).
$ P\left(\mathrm{FEM}|\mathrm{DU}\right)\times P\left(\mathrm{DU}\right)=0.25\times 0.05\hskip0.3em \approx \hskip0.3em 0.01 $
). Under the assumptions described above, the theory therefore predicts that gender distinctions in dual pronouns should asymmetrically entail gender distinctions in plural pronouns. Lavukaleve (in Table 4) should then be analyzed as an exception. Note that this prediction is compatible with the classic markedness-based approach according to which duals are more marked and hence less likely to feature gender distinctions than plurals (see Section 5.1 for further discussion).
Table 5 Frequency of singular, plural, and dual nouns in Sanskrit (Greenberg Reference Greenberg1966: 32; sample size: 93,277 nouns).

3.1.4 Summary
The predictions of the theory are plotted in Figure 3. The three numbers (singular, plural, dual) are plotted according to their estimated log probabilities (x-axis; based on the frequencies in Table 5) and the smallest of the two conditional log probabilities of gender (masculine vs. feminine) in the corresponding number (y-axis; based on the frequencies in Table 3 for singulars and plurals and assuming random sampling for duals). The dotted lines correspond to different trade-offs between the size and ambiguity costs: the more densely dotted the line is, the larger the weight on the ambiguity cost is with respect to the weight on the size cost and the richer the morphological paradigm is.

Figure 3 Model predictions for gender syncretism based on number in pronouns.
The theory predicts that, as the weight on the ambiguity cost decreases with respect to the weight on the size cost, the masculine/feminine gender distinction should be lost first in the dual (Murui Huitoto vs. Arabic), then in the plural (Arabic vs. Danish), and finally in the singular (Danish vs. Turkish). The prediction concerning singulars vs. plurals is supported by typological data. The prediction concerning plurals vs. duals would need to be further tested, as current typological surveys do not clearly establish which of the two patterns of contextual syncretism (syncretism in plurals only or syncretism in duals only) is more frequent. The few languages that do not conform to Greenberg’s Universal 45 (e.g. Tahhagart Tuareg in Table 2c) are not derived by the current model, due to the fact that this model is deterministic (see Section 2). The problem of exceptions will be further discussed in Section 5.2.
3.2 Gender syncretism based on person
3.2.1 Greenberg’s Universal 44
Another of Greenberg’s implicational generalizations refers to gender syncretism in pronouns. Universal 44 states that if a language has gender distinctions in the first person, it always has gender distinctions in the second or third person or in both (Greenberg Reference Greenberg and Greenberg1963). Based on her survey of 378 languages, Siewierska (Reference Siewierska, Dryer and Haspelmath2013) provides evidence for a slightly different version of this generalization that distinguishes non-third vs. third person pronouns: if a language has gender distinctions in non-third persons (i.e. first or second person), it has gender distinctions in the third person (modulo some exceptions). The data supporting this generalization is shown in Table 6: languages with gender distinctions only in non-third person pronouns are very few (there are only two such languages in her survey) compared to the three other types of languages. Because this generalization differs from Greenberg’s original formulation, it is referred to as Universal 44′ here.
Table 6 Greenberg’s Universal 44′ (Siewierska Reference Siewierska, Dryer and Haspelmath2013).

In her survey, Siewierska (Reference Siewierska, Dryer and Haspelmath2013) does not distinguish between singular and plural non-third person pronouns. However, she suggests that all 20 languages with gender distinctions in first or second person pronouns have them in the singular but not necessarily in the plural: ‘the gender distinctions in question may involve just the singular, or any combination of both singular and non-singular’. Therefore, the data in Table 6 hold for singular first and second person pronouns but not necessarily for plural first and second person pronouns. As a consequence, the remainder of this paper will focus on singular pronouns.
Table 7 provides examples of pronoun paradigms with different types of gender syncretism based on person, going from Ngala (with a gender distinction across all three persons) in Table 7a to Turkish (without any gender distinction) in Table 7d. Among the exceptions to Universal 44′, Siewierska (Reference Siewierska, Dryer and Haspelmath2013) cites Iraqw (not shown here).
Table 7 Examples of singular pronoun paradigms with different types of gender syncretism based on person.

3.2.2 Deriving Universal 44′
The theory laid out in Section 2 predicts that singular first/second person pronouns should favor gender syncretism as compared to singular third person pronouns if the probability of misidentifying gender is smaller in non-third person pronouns than in third person pronouns in case of gender syncretism. This prediction is very likely to be correct: because first and second person pronouns refer to discourse participants, it should be easier for a listener to guess the gender of the referent denoted by a given token of first or second person pronoun than the gender of the referent denoted by a given token of third person pronoun (Heath Reference Heath1975: 96; Corbett Reference Corbett1991: 321; Plank & Schellinger Reference Plank and Schellinger1997: 65). The reason is that information about the gender of discourse participants is provided by the extra-linguistic context, through visual and auditory cues. Similar cues are not guaranteed to be systematically present to identify the referent’s gender in case of third person pronouns. Therefore, for a given pronoun token, the probability distribution of gender should be much more skewed towards one of the two values in case this pronoun is first or second person than in case it is third person.
Assume the conditional probability of misidentifying the gender value of gender-syncretic pronouns is vanishingly low for non-third person pronouns but close to one half for third person pronouns (as found in Spanish, see Table 3). To obtain the overall probability of error for each person, this conditional probability must be multiplied by the probability of each person feature. The frequencies of Spanish pronouns in Table 8 may be used as estimates for the corresponding probabilities. In the absence of strong frequency asymmetries between the three persons, gender syncretism should mainly be driven by the conditional probability of misidentifying gender in the three persons. This probability is expected to be much lower in non-third person pronouns than in third person pronouns, as discussed above. Accordingly, gender syncretism in third person pronouns is predicted to entail gender syncretism in non-third person pronouns. Note that this prediction is made despite the fact that the first person pronoun has the highest frequency in the Spanish corpus. This prediction would not follow in a model that only considers the probability of the context: indeed, first person pronouns are more frequent than second and third person pronouns (at least in the Spanish corpus considered here) and therefore would be incorrectly predicted to favor gender distinctions cross-linguistically (see Section 5 for further discussion).
Table 8 Frequency of person features in Spanish based on SUBTLEX-ESP (Cuetos et al. Reference Cuetos, Glez-Nosti, Barbón and Brysbaert2011; corpus size: 41 million words): frequency per million of words (Freq 1) and relative frequencies (Freq 2).

The predictions of the theory are plotted in Figure 4. For concreteness, a very low probability of 0.01 was hypothesized for incorrect gender identification in non-third person pronouns. The other probabilities were estimated using the frequencies of Spanish pronouns in Tables 3 and 8. The theory correctly captures Universal 44′: as the weight on the ambiguity cost decreases with respect to the weight on the size cost, the masculine/feminine gender distinction disappears first in non-third person pronouns (Ngala vs. Murui Huitoto) and then in third person pronouns (Murui Huitoto vs. Turkish). Because the second person pronoun is less frequent than the first person pronoun (see Table 8) and because of the simplifying assumption that the probability of gender errors is identical in first and second person pronouns in the absence of gender distinctions, the theory currently predicts that a gender distinction in the first person should asymmetrically entail a gender distinction in the second person. This is problematic to derive a language like Hausa, which has gender distinctions in second but not in first person pronouns (Table 7c). However, it is possible that the probability of incorrect gender identification is smaller for first person pronouns on the reasonable assumption that there are more reliable cues to identify the speaker’s than the addressee’s gender (e.g. the speaker’s voice). In that case, the predictions could be different, with gender distinctions in first person pronouns asymmetrically implying gender distinctions in second person pronouns (as per Greenberg’s original Universal 44). Unfortunately, Siewierska (Reference Siewierska, Dryer and Haspelmath2013) does not specify how many among the 20 languages with gender distinctions in first or second persons in her sample have distinctions in both first and second person pronouns, only in first person pronouns, or only in second person pronouns. The typology of gender marking in first and second person pronouns should be investigated in more detail. However, this uncertainty does not affect the main result established in this section: under the reasonable assumption that gender is much easier to identify for discourse participants than for referents that are not present in the discourse context, the theory derives the basic asymmetry between third and non-third person pronouns with respect to gender syncretism.

Figure 4 Model predictions for gender syncretism based on person in pronouns.
3.3 Aspect syncretism based on tense
3.3.1 Implicational generalizations
Aspect conveys two kinds of information about a situation: how it is categorized ontologically, as an event or a state, and how it is viewed, as perfective or imperfective (Comrie Reference Comrie1976; Smith Reference Smith1997). Smith (Reference Smith1997) refers to the former distinction as situation type and to the latter one as viewpoint aspect. This section focuses on viewpoint aspect given that this aspectual category shows interesting interactions with tense. With the imperfective aspect (ipfv), an event or state is presented as ongoing or habitual, as illustrated in (2a) with the French imperfective aspect (the imperfect). The ongoing-event reading will be referred to as the progressive reading. With the perfective aspect (pfv), the event or state is presented as complete, as illustrated in (2b) with the French perfective aspect (the simple past).Footnote 9

The imperfective/perfective distinction is widespread across languages: in a sample of 222 languages, Dahl & Velupillai (Reference Dahl, Velupillai, Dryer and Haspelmath2013b) found that 101 languages distinguish the two aspects morphologically. However, the presence of this distinction also depends on the tense of the sentence (Dahl Reference Dahl1985: 81–83; Bybee & Dahl Reference Bybee and Dahl1989: 83; Malchukov Reference Malchukov, Hogeweg, de Hoop and Malchukov2009). Tense is a linguistic category that relates the time of a situation to a reference time, usually the utterance time (Comrie Reference Comrie1985). Three basic tenses are usually distinguished: present, past, and future. In its most basic use, the present tense locates a situation as simultaneous with the utterance. In the past tense, the situation is located as anterior to the utterance. In the future tense, it is located as posterior to the utterance.
The interaction between viewpoint aspect and tense can be illustrated with French. In the past, the imperfective form is only compatible with progressive and habitual readings, as shown in (2a). In the future, it is also compatible with the perfective reading (Smith Reference Smith1997: 78). The sentence in (3) can mean that a complete event of Jean singing will happen after Marie enters the office (perfective interpretation). Progressive and habitual readings are also available: the sentence in (3) can also mean that the event of singing will be ongoing when Marie enters (progressive interpretation) or that Jean will sing or be singing whenever Marie enters the office (habitual interpretation).

Given that there is no formal counterpart of the past perfective (or simple past) in the future in French and because imperfective forms are compatible with the three aspectual readings in this tense, French presents a case of aspect syncretism based on tense: aspect is syncretic in the future but not in the past.
Interestingly, the range of attested syncretic patterns is more restricted than what would be expected if the expression of aspect was independent of tense. Among the eight possible patterns of aspect syncretism in the three tenses, only four seem to be attested (Malchukov Reference Malchukov, Hogeweg, de Hoop and Malchukov2009): languages with a perfective/imperfective distinction in all tenses (e.g. Slovenian; Močnik Reference Močnik2008: 5), languages with a perfective/imperfective distinction in past and future tenses only (e.g. Modern Greek; Holton, Mackridge & Philippaki-Warburton Reference Holton, Mackridge and Philippaki-Warburton1997: 223–228), languages with a perfective/imperfective distinction in the past only (e.g. French; Martinet Reference Martinet1968: 18; see also Bybee & Dahl Reference Bybee and Dahl1989: 43 for other examples), and languages without perfective/imperfective distinction in any tense (e.g. German; Reyle, Rossdeutscher & Kamp Reference Reyle, Rossdeutscher and Kamp2007). The four types of languages are illustrated in Table 9.
Table 9 Attested patterns of aspect syncretism across tenses.
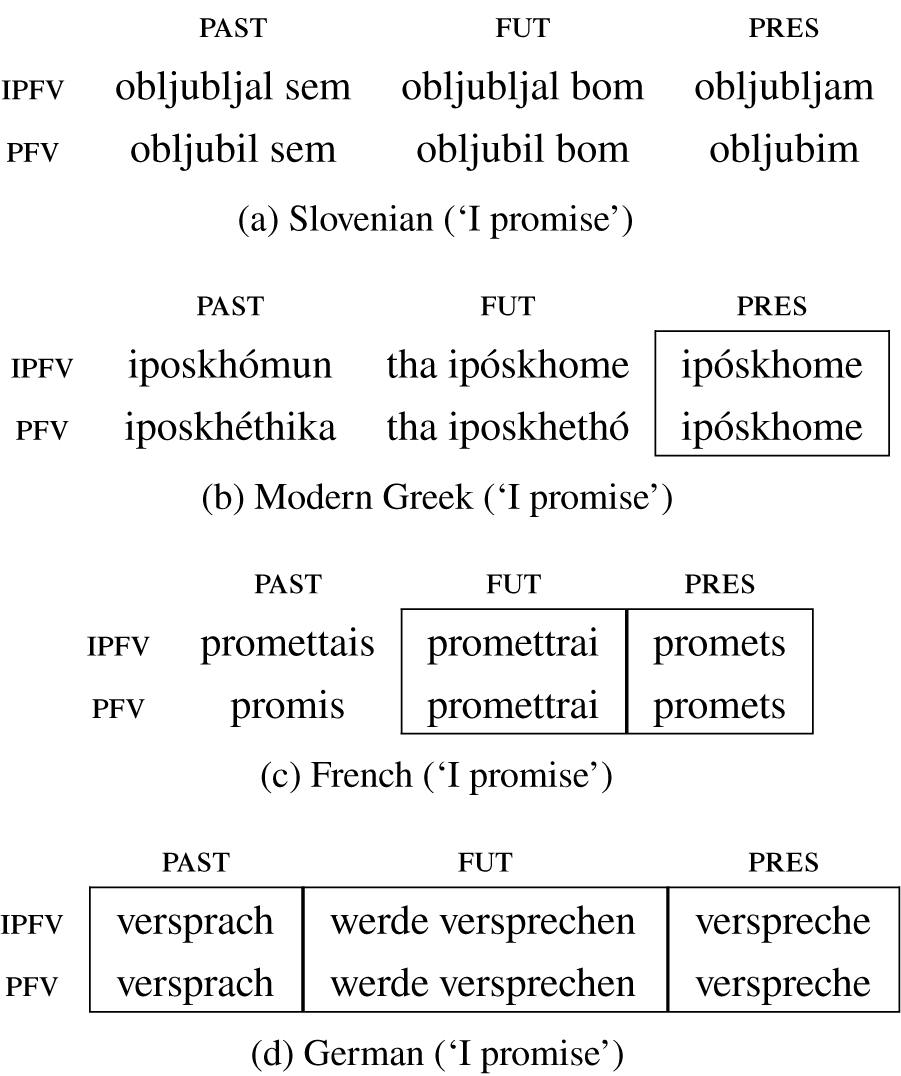
In case of aspect syncretism, the imperfective form is generally used as a default: for instance, in Greek and French, the only form available in the present tense formally corresponds to the imperfective form in the past tense (see Iatridou Reference Iatridou2000; Reyle et al. Reference Reyle, Rossdeutscher and Kamp2007, among others, for the interpretation of imperfective as a default).
This typology can be described with two implicational generalizations. The presence of a perfective morph in the present asymmetrically entails the presence of a perfective morph in the future and in the past. The presence of a perfective morph in the future asymmetrically entails the presence of a perfective morph in the past.
3.3.2 Motivating the morphological analysis
In this paper, the lack of perfective morph in the present tense (e.g. in Greek, French, and German in Table 9) is analyzed as a case of morphological syncretism: both perfective and imperfective readings are available in the present tense but the morphology fails to mark this distinction overtly. This analysis is found in Bertinetto & Bianchi (Reference Bertinetto and Bianchi2003: 588), according to whom ‘the present [is] an aspectually ambiguous tense’ in languages with only imperfective morphology in the present tense.
However, there is an alternative analysis according to which the absence of perfective morph in the present tense in these languages is due to a semantic incompatibility between present and perfective (Giorgi & Pianesi Reference Giorgi and Pianesi1997: 160–162). This semantic incompatibility is sometimes referred to as the ‘present perfective paradox’ in the literature (Malchukov Reference Malchukov, Hogeweg, de Hoop and Malchukov2009; De Wit Reference De Wit2017). According to this analysis, languages fail to have a perfective morph in the present tense because perfective readings are unavailable in semantically present sentences. This section motivates the morphological analysis assumed in the present paper against the semantic analysis.
First, the semantic analysis cannot easily account for languages where the combination of present temporal reference and semantically perfective aspect does occur and is expressed morphologically through the combination of present morphology and perfective morphology. This possibility is found in a number of Slavic languages, including Polish, Czech, and Slovenian, among others (Dickey Reference Dickey2000; Žagar Reference Žagar2011). For instance, in Slovenian, morphologically present perfective sentences can entail that a complete event in the denotation of the verbal phrase happens exactly at the moment of utterance (Žagar Reference Žagar2011; Močnik Reference Močnik2008: ch. 3). This is the case in performative utterances with perfective and present morphology such as priznam ‘I admit’, prisežem ‘I swear’, and obljubim ‘I promise’. Second, the semantic analysis cannot easily account for the existence of present perfective readings for morphologically present imperfective sentences in languages without perfective morph in the present (e.g. Greek, French, and German in Table 9). These readings are available in performative utterances (e.g. I promise to come) and in so-called reportive contexts (e.g. Mary wins the race, as uttered by a sportscaster as Mary crosses the finish line), as acknowledged by many authors (e.g. Dowty Reference Dowty1979: 167, 189–190; Parsons Reference Parsons1990: 30). For instance, in Russian, morphologically imperfective performative sentences do occur, as shown in (4), and their most salient aspectual interpretation is perfective: the speaker is typically understood as having promised to come after uttering (4). This entailment would not go through if, among perfective and progressive interpretations, only the progressive interpretation was available: sentences with achievement predicates like promise and progressive morphology (e.g. I am promising to come) do not entail completion of the event (see Dowty Reference Dowty1979: 133).

Finally, based on the semantics of present and perfective, there is no clear reason for why present perfective sentences should never be true, rather than true under very restricted conditions. For instance, Parsons (Reference Parsons1990: 31) shows how his semantic system for tense and aspect predicts that a present perfective sentence should be true only if the event described by the sentence coincides temporally with the utterance of this sentence (see also Bary Reference Bary2012: 41–42). Outside of performative and reportive contexts, this condition is hard to satisfy: as Parsons puts it,
The speaker must usually be observing the scene in order to be sure of getting the time right, and the sentence cannot be used in anticipation of the culmination or recapitulation – it must be used exactly once and exactly at the right time. Such uses are rare.
All these problems can be avoided if the lack of perfective morph in the present tense is analyzed as morphological syncretism. Under this analysis, one expects languages to be able to have the imperfective-perfective distinction expressed morphologically in the present tense: hence, the fact that there are languages such as Slovenian is not problematic. In languages without perfective morph in the present, morphologically present imperfective sentences are expected to be aspectually ambiguous: hence, the fact that present tense sentences in Russian are compatible with the event being completed at the moment of utterance is expected. Finally, the fact that semantically perfective present sentences are rare follows from basic pragmatic principles, as proposed by Parsons (Reference Parsons1990).
3.3.3 Deriving the implicational generalizations
The theory laid out in Section 2 predicts that present tense should favor aspect syncretism as compared to past and future tenses and that future tense should favor aspect syncretism as compared to past tense if the probability of misidentifying aspect is smaller in the present than in the future and in the future than in the past, that is, if the following inequalities hold:
 $$ \min \left\{P\left(\mathrm{IPFV},\mathrm{PRES}\right),P\left(\mathrm{PFV},\mathrm{PRES}\right)\right\}<\min \left\{P\left(\mathrm{IPFV},\mathrm{FUT}\right),P\left(\mathrm{IPFV},\mathrm{FUT}\right)\right\} $$
$$ \min \left\{P\left(\mathrm{IPFV},\mathrm{PRES}\right),P\left(\mathrm{PFV},\mathrm{PRES}\right)\right\}<\min \left\{P\left(\mathrm{IPFV},\mathrm{FUT}\right),P\left(\mathrm{IPFV},\mathrm{FUT}\right)\right\} $$
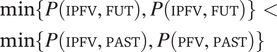 $$ \min \left\{P\left(\mathrm{IPFV},\mathrm{FUT}\right),P\left(\mathrm{IPFV},\mathrm{FUT}\right)\right\}<\min \left\{P\left(\mathrm{IPFV},\mathrm{PAST}\right),P\left(\mathrm{PFV},\mathrm{PAST}\right)\right\} $$
$$ \min \left\{P\left(\mathrm{IPFV},\mathrm{FUT}\right),P\left(\mathrm{IPFV},\mathrm{FUT}\right)\right\}<\min \left\{P\left(\mathrm{IPFV},\mathrm{PAST}\right),P\left(\mathrm{PFV},\mathrm{PAST}\right)\right\} $$
As seen above, the truth conditions of a present perfective sentence are arguably hard to be met. The event in the denotation of the verbal phrase has to coincide with the utterance time for a perfective present sentence to be true (Parsons Reference Parsons1990; Bary Reference Bary2012). This happens only with verbs that denote very short events whose run time can match the length of the utterance (e.g. in performative and reportive contexts). In future and past tenses, there is no such constraint: the reference time picked up by the tense morpheme can be large enough to include the run time of virtually any complete event. As a result, the probability of aspect conditioned on tense should be highly skewed towards the imperfective in the present tense and more balanced between perfective and imperfective in the past and in the future. Hence, Equation 11 is likely to hold. In addition, sentences are much more likely to be about past events than about future events, as shown by corpus data (see Josselson Reference Josselson1953 on Russian; Szagun Reference Szagun1978 on English and German). Therefore, Equation 12 is likely to hold too.
Some of these hypotheses were tested quantitatively, using a set of 1,000 sentences randomly sampled from a corpus of French subtitles (New & Spinelli Reference New and Spinelli2013). Each sentence was annotated with its temporal interpretation (past, present, future) as judged by a French native speaker (the author).Footnote 10 Sentences with past and present interpretations were further annotated with their aspectual interpretation (perfective, imperfective). This was not done for future sentences because it was harder to determine aspect in this case, due to the absence of morphological aspect marking in French and to the absence of contextual information in New & Spinelli’s corpus. These clues were also absent in temporally present sentences, but aspect was easier to determine there due to the aspectual restrictions discussed above. For past sentences, sentences in the imparfait were annotated as imperfective and sentences in the passé composé or simple past as perfective. The results are presented in Table 10.
Table 10 Count and frequency of temporal and aspectual interpretations in a corpus of French subtitles (New & Spinelli Reference New and Spinelli2013; sample size=1,000 sentences).

As a consequence of the difficulty with annotating aspectual information for future sentences, only the hypothesis concerning the asymmetry between past and present (i.e. present tense favors aspect syncretism as compared to past tense cross-linguistically) was tested, as in Equation (13). It should be noted that this asymmetry is the most robustly documented in the typological literature. Hence, it is the most important one to account for.
 $$ \min \left\{P\left(\mathrm{IPFV},\mathrm{PRES}\right),P\left(\mathrm{IPFV},\mathrm{PRES}\right)\right\}<\min \left\{P\left(\mathrm{IPFV},\mathrm{PAST}\right),P\left(\mathrm{PFV},\mathrm{PAST}\right)\right\} $$
$$ \min \left\{P\left(\mathrm{IPFV},\mathrm{PRES}\right),P\left(\mathrm{IPFV},\mathrm{PRES}\right)\right\}<\min \left\{P\left(\mathrm{IPFV},\mathrm{PAST}\right),P\left(\mathrm{PFV},\mathrm{PAST}\right)\right\} $$
In case of aspect syncretism, the probability of aspect misidentification is predicted to be smaller in the present (
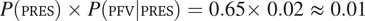 $ P\left(\mathrm{PRES}\right)\times P\left(\mathrm{PFV}|\mathrm{PRES}\right)=0.65\times 0.02\hskip0.3em \approx \hskip0.3em 0.01 $
) than in the past (
$ P\left(\mathrm{PRES}\right)\times P\left(\mathrm{PFV}|\mathrm{PRES}\right)=0.65\times 0.02\hskip0.3em \approx \hskip0.3em 0.01 $
) than in the past (
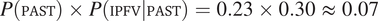 $ P\left(\mathrm{PAST}\right)\times P\left(\mathrm{IPFV}|\mathrm{PAST}\right)=0.23\times 0.30\hskip0.3em \approx \hskip0.3em 0.07 $
). As a consequence, present tense is correctly predicted to favor aspect syncretism as compared to past tense. Note that the model derives this prediction despite the fact that present tense is more likely than past tense in the corpus. This prediction would not be derived in a model that only considers the probability of the context (see Section 5 for further discussion). As expected, future interpretations are less frequent than past and present interpretations. However, the absence of aspectual information on future sentences does not make it possible to further test the model’s predictions.
$ P\left(\mathrm{PAST}\right)\times P\left(\mathrm{IPFV}|\mathrm{PAST}\right)=0.23\times 0.30\hskip0.3em \approx \hskip0.3em 0.07 $
). As a consequence, present tense is correctly predicted to favor aspect syncretism as compared to past tense. Note that the model derives this prediction despite the fact that present tense is more likely than past tense in the corpus. This prediction would not be derived in a model that only considers the probability of the context (see Section 5 for further discussion). As expected, future interpretations are less frequent than past and present interpretations. However, the absence of aspectual information on future sentences does not make it possible to further test the model’s predictions.
The predictions of the theory regarding past and present are plotted in Figure 5. The two contexts are plotted according to their estimated log probabilities (x-axis) and the smallest of the two conditional log probabilities of aspect conditioned on the corresponding tense (y-axis). The theory correctly captures the relevant implicational generalization: as the weight on the ambiguity cost decreases with respect to the weight on the size cost, the perfective-imperfective distinction is lost first in the present (Slovenian vs. Greek) and then in the past (French vs. German).
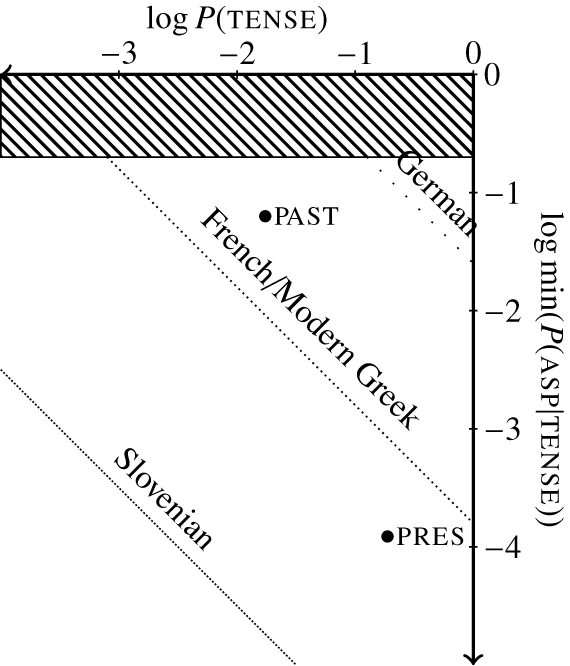
Figure 5 Model predictions for aspect syncretism based on tense.
4. Model extension
The model developed in Section 2 assumes that the computation of the ambiguity cost is independent from context to context. As a consequence, this model is suited to derive patterns where the choice of expressing a grammatical distinction morphologically in a given context does not depend on whether this distinction is expressed morphologically in another context. However, there are cases where the independence assumption clearly does not hold. Case syncretism constitutes a good example. In the Latin sentence (5), the syncretism of nominative and accusative cases for the neuter noun uerbum ‘word’ is harmless: it is possible to deterministically infer that the case is accusative because (i) the masculine homo ‘man’ is unambiguously nominative (the accusative is hominem) and (ii) a transitive verb only allows for a single nominative argument.Footnote 11 However, if masculine nouns were also syncretic for case in (5), syncretism in neuters would be potentially harmful: in the absence of other clues (e.g. word order, if word order is free, or world knowledge, if the verb is compatible with both neuter and non-neuter subjects and objects), there would be no way to decide deterministically which argument is the subject and which argument is the object.

Section 4.1 shows how this type of syncretism may be treated in the present model and Section 4.2 shows how the typology of case syncretism based on animacy can be derived assuming this extended version of the model. This study on case syncretism adds to a large body of evidence suggesting that case marking is shaped by considerations of communicative efficiency (Comrie Reference Comrie1981; Fedzechkina et al. Reference Fedzechkina, Jaeger and Newport2012).
4.1 Extending the model
In a situation where the specific value of a binary grammatical feature
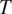 $ T $
(taking values
$ T $
(taking values
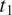 $ {t}_1 $
and
$ {t}_1 $
and
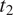 $ {t}_2 $
) in a word
$ {t}_2 $
) in a word
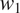 $ {w}_1 $
deterministically conditions the specific value of this feature in another word
$ {w}_1 $
deterministically conditions the specific value of this feature in another word
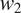 $ {w}_2 $
in the same sentence, the ambiguity cost of not expressing
$ {w}_2 $
in the same sentence, the ambiguity cost of not expressing
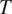 $ T $
morphologically in contexts
$ T $
morphologically in contexts
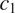 $ {c}_1 $
and/or
$ {c}_1 $
and/or
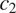 $ {c}_2 $
must be calculated across the two words
$ {c}_2 $
must be calculated across the two words
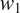 $ {w}_1 $
and
$ {w}_1 $
and
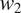 $ {w}_2 $
. There are four paradigms to consider: (a)
$ {w}_2 $
. There are four paradigms to consider: (a)
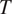 $ T $
is syncretic in neither context
$ T $
is syncretic in neither context
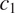 $ {c}_1 $
and
$ {c}_1 $
and
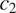 $ {c}_2 $
, (b)
$ {c}_2 $
, (b)
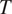 $ T $
is syncretic only in
$ T $
is syncretic only in
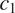 $ {c}_1 $
, (c)
$ {c}_1 $
, (c)
 $ T $
is syncretic only in
$ T $
is syncretic only in
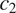 $ {c}_2 $
, and (d)
$ {c}_2 $
, and (d)
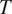 $ T $
is syncretic in both contexts.
$ T $
is syncretic in both contexts.
Table 11 shows the ambiguity and size costs of each paradigm (a)–(d) (before multiplying by language-specific weights). For (a), the ambiguity cost is equal to zero because
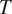 $ T $
is always conveyed unambiguously. The size cost of (a) is equal to two because there is a morphological distinction between
$ T $
is always conveyed unambiguously. The size cost of (a) is equal to two because there is a morphological distinction between
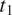 $ {t}_1 $
and
$ {t}_1 $
and
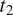 $ {t}_2 $
in the two contexts. For (b), the ambiguity cost is equal to the probability of misidentifying the values of
$ {t}_2 $
in the two contexts. For (b), the ambiguity cost is equal to the probability of misidentifying the values of
 $ T $
for
$ T $
for
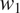 $ {w}_1 $
and
$ {w}_1 $
and
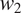 $ {w}_2 $
when the context is
$ {w}_2 $
when the context is
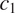 $ {c}_1 $
in both words.Footnote
12 This probability is equal to the probability that the context is
$ {c}_1 $
in both words.Footnote
12 This probability is equal to the probability that the context is
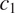 $ {c}_1 $
in both words, divided by two (assuming that the two words are as likely to have the feature value
$ {c}_1 $
in both words, divided by two (assuming that the two words are as likely to have the feature value
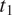 $ {t}_1 $
as the feature value
$ {t}_1 $
as the feature value
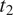 $ {t}_2 $
). For (c), the ambiguity cost is equal to the probability of misidentifying the values of
$ {t}_2 $
). For (c), the ambiguity cost is equal to the probability of misidentifying the values of
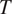 $ T $
for
$ T $
for
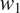 $ {w}_1 $
and
$ {w}_1 $
and
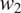 $ {w}_2 $
when the context is
$ {w}_2 $
when the context is
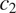 $ {c}_2 $
in both words. This probability is equal to the probability that the context is
$ {c}_2 $
in both words. This probability is equal to the probability that the context is
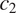 $ {c}_2 $
in both words, divided by two. For both (b) and (c), the size cost is equal to one because there is a morphological distinction only in one context. For (d),
$ {c}_2 $
in both words, divided by two. For both (b) and (c), the size cost is equal to one because there is a morphological distinction only in one context. For (d),
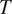 $ T $
is always conveyed ambiguously: the ambiguity cost is equal to the sum of the probabilities of misidentification across all contexts.
$ T $
is always conveyed ambiguously: the ambiguity cost is equal to the sum of the probabilities of misidentification across all contexts.
Table 11 Size cost and ambiguity cost for the four types of paradigms.
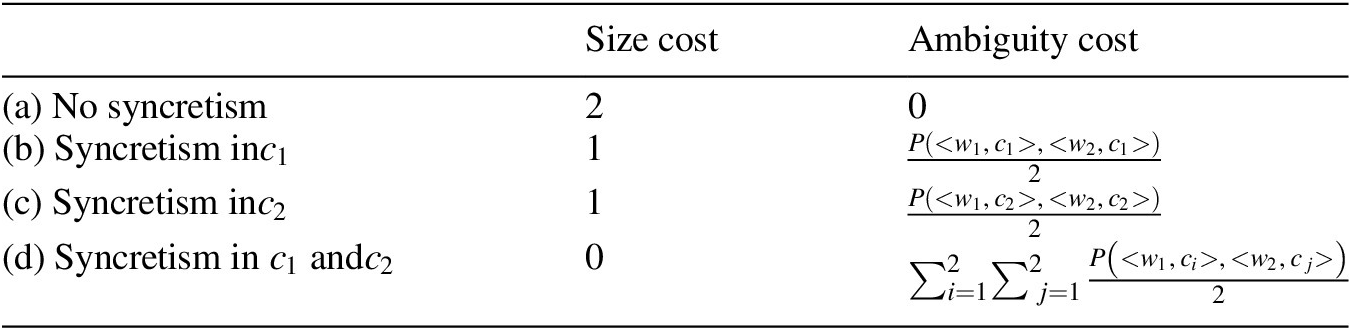
Paradigms (b) and (c) tie on the size cost. The preference for one or the other paradigm will therefore be entirely determined by their relative ambiguity costs. Assuming that the probabilities for the combinations of grammatical contexts across the two words
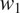 $ {w}_1 $
and
$ {w}_1 $
and
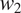 $ {w}_2 $
are the same across languages, only one of (b) or (c) will ever be able to win over the other (whichever one happens to have the smaller ambiguity cost). Which one has the smaller ambiguity cost ultimately depends on the relationship between
$ {w}_2 $
are the same across languages, only one of (b) or (c) will ever be able to win over the other (whichever one happens to have the smaller ambiguity cost). Which one has the smaller ambiguity cost ultimately depends on the relationship between
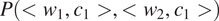 $ P\left(<{w}_1,{c}_1>,<{w}_2,{c}_1>\right) $
and
$ P\left(<{w}_1,{c}_1>,<{w}_2,{c}_1>\right) $
and
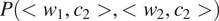 $ P\left(<{w}_1,{c}_2>,<{w}_2,{c}_2>\right) $
: for instance, if
$ P\left(<{w}_1,{c}_2>,<{w}_2,{c}_2>\right) $
: for instance, if
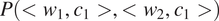 $ P\left(<{w}_1,{c}_1>,<{w}_2,{c}_1>\right) $
is smaller than
$ P\left(<{w}_1,{c}_1>,<{w}_2,{c}_1>\right) $
is smaller than
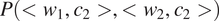 $ P\left(<{w}_1,{c}_2>,<{w}_2,{c}_2>\right) $
, then (b) wins over (c), due to its smaller ambiguity cost. For concreteness assume that, among (b) and (c), (b) has the smaller ambiguity cost. The present approach then predicts that only (a), (b), and (c) should be attested across languages. In other words, it predicts that syncretism of
$ P\left(<{w}_1,{c}_2>,<{w}_2,{c}_2>\right) $
, then (b) wins over (c), due to its smaller ambiguity cost. For concreteness assume that, among (b) and (c), (b) has the smaller ambiguity cost. The present approach then predicts that only (a), (b), and (c) should be attested across languages. In other words, it predicts that syncretism of
 $ T $
in
$ T $
in
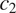 $ {c}_2 $
should entail syncretism of
$ {c}_2 $
should entail syncretism of
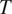 $ T $
in
$ T $
in
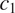 $ {c}_1 $
. As a consequence, the model also predicts implicational generalizations for this more complex case of morphological syncretism. More specifically, it predicts that syncretism of
$ {c}_1 $
. As a consequence, the model also predicts implicational generalizations for this more complex case of morphological syncretism. More specifically, it predicts that syncretism of
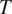 $ T $
should happen preferentially in the grammatical context that is least likely to co-occur with both words
$ T $
should happen preferentially in the grammatical context that is least likely to co-occur with both words
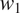 $ {w}_1 $
and
$ {w}_1 $
and
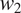 $ {w}_2 $
.
$ {w}_2 $
.
4.2 Case syncretism based on animacy
4.2.1 Implicational generalizations
Case refers to the morphological marking of syntactic roles in a verb phrase. There are two broad systems that are found cross-linguistically: nominative-accusative languages and ergative-absolutive languages. In nominative-accusative languages, subjects of transitive and intransitive verbs are marked with nominative case and objects of transitive verbs are marked with accusative case. In ergative-absolutive languages, subjects of transitive verbs are marked with ergative case whereas subjects of intransitive verbs and objects of transitive verbs are marked with absolutive case (Comrie Reference Comrie1981).
The morphological marking of syntactic roles depends on animacy cross-linguistically: it has been observed that higher animacy nominals are more likely to have distinct nominative and accusative forms than lower animacy nominals (Silverstein Reference Silverstein and Richard1976; Baerman et al. Reference Baerman, Brown and Corbett2005: 40–49; Baerman & Corbett Reference Baerman, Corbett, Dryer and Haspelmath2013). For instance, in Telugu (Table 12), nominals referring to animates have distinct nominative and accusative forms but nominals referring to inanimates do not (Baerman et al. Reference Baerman, Brown and Corbett2005: 47). The absence (or rarity) of languages with a nominative-accusative distinction only in inanimates points to the following implicational generalization: if a language distinguishes nominative and accusative cases morphologically in inanimates, then it also distinguishes them in animates.
Table 12 Telugu (Krishnamurti & Wynn Reference Krishnamurti and Wynn1985: 88–89).
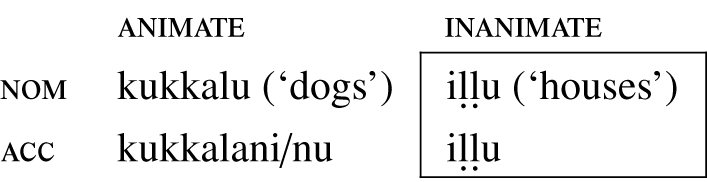
Although lower animacy nominals are more likely to have distinct ergative and absolutive forms in inanimates than in animates (Silverstein Reference Silverstein and Richard1976; Baerman & Corbett Reference Baerman, Corbett, Dryer and Haspelmath2013), Baerman et al. (Reference Baerman, Brown and Corbett2005: 47) note that there is no language in their sample with an ergative-absolutive distinction in inanimates and no case distinction at all in animates: languages with distinct ergative and absolutive forms for inanimates either also have this distinction in animates (and then are fully ergative languages) or have distinct nominative and accusative forms in animates (and then are languages with split-ergativity).
However, the implicational generalization as stated above (i.e. distinct nominative and accusative forms in inanimates entails distinct nominative and accusative forms in animates) does not exclude this type of languages (i.e. a language with an ergative-absolutive distinction in inanimates and no case distinction at all in animates). These languages can also be excluded if the implicational generalization is restated specifically in terms of the distinction between subject and object of transitive verbs: if a language distinguishes subject and object of transitive verbs morphologically in inanimates, it distinguishes them in animates. This implicational generalization is satisfied by (i) languages which maintain the two relevant syntactic roles morphologically distinct across animates and inanimates (i.e. fully ergative-absolutive languages, fully nominative-accusative languages, and languages with split ergativity based on animacy), (ii) languages with a nominative-accusative system only for animates and no case distinction for inanimates, and (iii) languages which never distinguish subjects and objects of transitive verbs morphologically.
The restatement of the implicational generalization in terms of the distinction between subject and object of transitive verbs is in line with Comrie’s (Reference Comrie1981) analysis of the typology of case marking systems. As seen above, there are two broad systems of case marking: nominative-accusative and ergative-absolutive systems. In both systems, subjects and objects of transitive verbs are morphologically distinct. The absence of a third system where subjects and objects of transitive verbs are conveyed by the same form whereas subjects of intransitive verbs are conveyed by a distinct form can be understood functionally (Comrie Reference Comrie1981: 120):
The discriminatory function of case marking will show itself most clearly in the transitive construction, where there is a need to distinguish between [the subject] and [the object], rather than in the intransitive construction, where [the subject] alone occurs.
In some languages, case syncretism is not based on literal animacy but on the neuter/non-neuter distinction, which broadly correlates with animacy. In these languages, neuter nominals typically only refer to inanimate entities whereas non-neuter nominals typically refer to animates, but can also refer to inanimates (Baerman et al. Reference Baerman, Brown and Corbett2005: 47). In these languages, the presence of a morphological distinction between subject and object of transitive verbs in neuters asymmetrically entails the presence of this distinction in non-neuters (i.e. feminine and masculine nominals): there are languages with a nominative-accusative distinction across neuter and non-neuter genders (Table 13a), languages with case distinctions only in non-neuters (Table 13b), languages with no case distinction in any gender (Table 13c), but seemingly no language with a nominative-accusative distinction only in neuters.
Table 13 Attested patterns of case syncretism across neuters and non-neuters.
4.2.2 Deriving the implicational generalizations
According to the analysis in Section 4.1, inanimates should favor case syncretism if the subject and the object of a transitive verb are less likely to be both inanimates than both animates. This hypothesis is supported by evidence from a corpus of spoken Swedish (Table 14). This corpus is a subset of the corpus ‘Samtal i Göteborg’ (Conversations in Gothenburg): it contains about 60,000 words and was hand-annotated for syntactic roles and animacy by Dahl (Reference Dahl2000). In this corpus, inanimates are less likely to co-occur as subject and object in a transitive sentence than animates are (
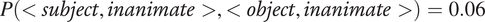 $ P\left(< subject, inanimate>,< object, inanimate>\right)=0.06 $
vs.
$ P\left(< subject, inanimate>,< object, inanimate>\right)=0.06 $
vs.
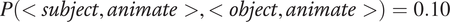 $ P\left(< subject, animate>,< object, animate>\right)=0.10 $
). The conclusion drawn from the Swedish data is corroborated by data from a small corpus of spoken Sacapultec (Mayan), where no transitive sentence has both an inanimate subject and an inanimate object (Du Bois Reference Du Bois1987: 841).
$ P\left(< subject, animate>,< object, animate>\right)=0.10 $
). The conclusion drawn from the Swedish data is corroborated by data from a small corpus of spoken Sacapultec (Mayan), where no transitive sentence has both an inanimate subject and an inanimate object (Du Bois Reference Du Bois1987: 841).
Table 14 Count and frequency of grammatical function in transitive sentences conditioned on animacy in Swedish (Jäger Reference Jäger2007: 80).

Similarly, neuters should favor case syncretism as compared to non-neuters if the subject and the object of a transitive verb are less likely to be both neuter than both non-neuter. This hypothesis is likely to be correct. As noted by Baerman et al. (Reference Baerman, Brown and Corbett2005: 47), the set of neuter nouns is typically a subset of the set of inanimate nouns and the set of non-neuter nouns a superset of the set of animate nouns. As a consequence, (i) the probability of a neuter subject co-occurring with a neuter object should be smaller than the probability of an inanimate subject co-occurring with an inanimate object and (ii) the probability of a non-neuter subject co-occurring with a non-neuter object should be larger than the probability of an animate subject co-occurring with an animate object. Based on the Swedish data and by transitivity, a neuter subject should therefore be less likely to co-occur with a neuter object than a non-neuter subject with a non-neuter object.
5. Discussion
The preceding sections show how the theory of syncretism described in Sections 2 and 4.1 can account for the contexts favoring syncretism in four detailed case studies. Section 5.1 discusses three alternative accounts which do not rely directly on synchronic principles of communicative efficiency. Section 5.2 briefly discusses the problem of exceptions to implicational generalizations and how to generate them in the present framework.
5.1 Alternative theories
5.1.1 Structural approach
In some accounts, syncretism arises preferentially in contexts that are structurally complex. The motivation is a limit on complexity: adding morphological distinctions adds complexity to the grammar. Assuming that there is a language-specific threshold on grammatical complexity, if a language allows an amount
 $ x $
of complexity, then it will also allow an amount of complexity smaller than
$ x $
of complexity, then it will also allow an amount of complexity smaller than
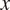 $ x $
. This general approach is referred to as the ‘structural approach’ in this paper because typological generalizations about the syntax-morphology interface are derived only from structural properties of the syntax and morphology (without reference to the way they are put to use).
$ x $
. This general approach is referred to as the ‘structural approach’ in this paper because typological generalizations about the syntax-morphology interface are derived only from structural properties of the syntax and morphology (without reference to the way they are put to use).
This approach is represented by Harley & Ritter (Reference Harley and Ritter2002). These authors propose a feature geometry for pronoun structures that is able to capture the universals relative to gender syncretism in pronouns. In their geometry, duals are structurally more complex than plurals and singulars (Harley & Ritter Reference Harley and Ritter2002: 492) and plurals are more complex than singulars (Harley & Ritter Reference Harley and Ritter2002: 514–515). Combined with the assumption that syncretism in contexts that are structurally less complex entails syncretism in contexts that are more complex, this system predicts that gender syncretism should happen preferentially in duals, then in plurals, and finally in singulars. Also, in their system, non-third person pronouns are structurally more complex than third person pronouns (Harley & Ritter Reference Harley and Ritter2002: 488) and this explains why they favor gender syncretism.
How does this theory extend to the other case studies treated in this paper? The authors do not include case features in their feature geometry for pronouns (see Harley & Ritter Reference Harley and Ritter2002: 507 for a justification). However, this could a priori be done. For their analysis to account for the typology of case syncretism based on animacy, inanimates would need to be structurally more complex than animates. For the typology of case syncretism based on the neuter/non-neuter distinction, neuters would need to be structurally more complex than non-neuters. However, these predictions are not directly compatible with the feature geometry assumed by Harley & Ritter (Reference Harley and Ritter2002: 486): in their geometry, the node Inanimate/Neuter is less marked (i.e. less complex) than the node Animate and therefore inanimates and neuters should allow for richer case distinctions than animates and non-neuters, contrary to fact.
It is unclear how to extend the structural approach to the typology of aspect syncretism. There are several reasons to think that present tense should be the simplest tense structurally and yet it favors aspect syncretism. Present tense is more basic than past and future tenses in the sense that these tenses are defined with respect to the present tense semantically. One way out would be to assume that present and perfective are semantically incompatible and therefore the absence of perfective morph in the present in languages like French or Greek is not due to syncretism. However, this approach suffers from a number of problems discussed in Section 3.3. Furthermore, under the structural approach, future should probably be the tense favoring aspect syncretism cross-linguistically, as it is semantically more complex than the other tenses (e.g. Klecha Reference Klecha2014 on the hypothesis that future is a modal operator) and often morphologically more complex: inflectional futures often derive from periphrastic constructions (Dahl & Velupillai Reference Dahl, Velupillai, Dryer and Haspelmath2013a).
5.1.2 Markedness approach
In the markedness approach, morphological distinctions are richer in contexts that are more frequent. This approach is represented by Greenberg (Reference Greenberg1966), who established markedness scales based on the frequency of grammatical features and used them to explain the typology of morphological syncretism (see Croft Reference Croft1990: 92–93 for a list of markedness scales extracted from Greenberg’s work).
This approach can be illustrated with the typology of gender syncretism based on number (Universal 45). The higher frequency of singulars over plurals provides evidence for a scale where singular is less marked than plural (singular
 $ < $
plural). This scale explains why gender syncretism is favored in plurals (Universal 45).
$ < $
plural). This scale explains why gender syncretism is favored in plurals (Universal 45).
In both the markedness-based approach and the present approach, the probability of the grammatical context plays a role in deriving typological tendencies in patterns of syncretism. However, in the present approach, the conditional probability of the target grammatical feature given that context also matters. This probability was crucial to derive the typology of gender syncretism based on person (Section 3.2) and the typology of aspect syncretism based on tense (Section 3.3). It is unclear how these patterns can be derived without appealing to the concept of conditional probability: first person pronouns and present tense are highly frequent feature values and therefore, under the markedness approach, should not particularly favor gender syncretism and aspect syncretism, respectively.
5.1.3 Diachronic approach
The present approach assumes that there is an explicit synchronic principle that favors more informative paradigms in speakers’ productions (see Fedzechkina et al. Reference Fedzechkina, Jaeger and Newport2012, among others, for experimental evidence). However, there are alternative approaches where functionalist principles shaping morphological patterns do not play out at the synchronic level but only at a diachronic level (e.g. Croft Reference Croft1990: ch. 9).
Haspelmath (Reference Haspelmath2006: 48) sketches a diachronic scenario to explain implicational generalizations in syncretic patterns without requiring a synchronic principle favoring small and unambiguous paradigms. In this scenario, syncretism arises as the result of imperfect learning: some morphological combinations are less frequent in the learner’s input and therefore harder to remember and, for this reason, get lost over time.
This diachronic scenario explains why aspect syncretism is favored in the present tense: the combination of perfective aspect and present tense is infrequent (for the pragmatic reasons exposed in Section 3.3) and therefore learners should tend to assume that only the imperfective morph is available in this tense. It also explains why plural pronouns favor gender syncretism. Plural pronouns are less frequent than singular pronouns and therefore gender distinctions get lost in the plural first. For instance, a system with full gender distinctions across numbers (e.g. Murui Huitoto; see Table 4a) should tend to be reinterpreted by learners as a system without gender distinctions in the plural (e.g. Danish; see Table 2b). Pidgin Hausa provides a concrete example of loss of gender distinctions in pronoun paradigms: Standard Hausa has masculine and feminine pronouns yā ‘he’ and tā ‘she’ but Pidgin Hausa generalized the masculine form yā to both genders (Heine & Reh Reference Heine and Reh1984: 42), arguably because this form was more frequent. Finally, this diachronic scenario can also account for the preference to neutralize case distinctions in inanimates: as shown in Table 14, inanimate subjects of transitive sentences are less frequent (
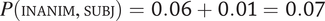 $ P\left(\mathrm{INANIM},\mathrm{SUBJ}\right)=0.06+0.01=0.07 $
) than animate objects of transitive sentences (
$ P\left(\mathrm{INANIM},\mathrm{SUBJ}\right)=0.06+0.01=0.07 $
) than animate objects of transitive sentences (
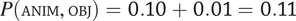 $ P\left(\mathrm{ANIM},\mathrm{OBJ}\right)=0.10+0.01=0.11 $
) and therefore the morphs expressing the combination inanimates + subjects should be harder to memorize by learners.
$ P\left(\mathrm{ANIM},\mathrm{OBJ}\right)=0.10+0.01=0.11 $
) and therefore the morphs expressing the combination inanimates + subjects should be harder to memorize by learners.
However, the diachronic approach sketched by Haspelmath fails on the typology of gender syncretism based on person. First person pronouns should be frequent in the learner’s input. Assuming that a first person pronoun is roughly as likely to be feminine as masculine in the learner’s input, a learner should receive a large amount of evidence for positing gender distinctions in first person pronouns. Why then should gender distinctions be underrepresented in this case?
Furthermore, the analysis based on imperfect learning is only suited to describe cases where a richer morphological system gets poorer, but not cases where a poorer morphological system gets richer. However, such cases are attested. For instance, Ancient Greek had a perfective/imperfective morphological distinction in the past only (Bary Reference Bary2009). This distinction was later extended to the future tense: Modern Greek distinguishes perfective and imperfective aspects in both past and future tenses (see Table 9a). Analyses have been proposed to account for the creation of new morphological distinctions without resorting to synchronic principles of communicative efficiency, though. One analysis relies on grammaticalization. Grammaticalization describes a process by which a former lexical element is integrated into a paradigm (Croft Reference Croft1990: 234). Combinations of lexical elements that are more frequent are expected to be grammaticalized earlier than combinations that are less frequent (Bybee Reference Bybee2006: 719–721). However, like the analysis based on imperfect learning, this analysis fails to account for the typology of gender syncretism based on person. Singular non-third pronouns should be highly frequent under both genders (masculine and feminine) and therefore it is unclear why gender distinctions should not grammaticalize there at least as fast as in third person pronouns.
5.1.4 Summary
To summarize, among the four approaches discussed in this paper, only the approach assuming communicative biases in language users (learners or speakers) makes the correct predictions for all case studies considered here. The structural approach does not generalize well beyond the case studies it was designed to account for. The markedness-based and diachronic approaches make predictions that are closer to the approach based on communicative efficiency but they fail on some case studies, in particular on the typology of gender based on person in pronouns. This failure is crucially due to the fact that these theories give no role to a feature’s recoverability in context.
5.2 Exceptions
The implicational generalizations discussed in this paper and whose validity has been tested through large typological surveys (i.e. Greenberg’s Universals 45 and 44; see Sections 3.1 and 3.2) admit exceptions. To the author’s knowledge, there are no exceptions reported for the other implicational generalizations (i.e. aspect syncretism and case syncretism; see Sections 3.3 and 4.2) but this could be because they have not been tested as extensively. Also, as shown by Piantadosi & Gibson (Reference Piantadosi and Gibson2014), although it is in principle possible to find absolute linguistic universals using cross-linguistic surveys and typological statistics, the number of independent languages necessary to do so is generally unachievable. Therefore, even if there were no exception to an implicational generalization in a typological survey, this most likely would not guarantee that this generalization is an absolute universal.
However, as outlined in Section 2, the present approach only derives absolute, exceptionless implicational universals. How to deal with exceptions then? Exceptions are problematic not only for the approach proposed here but also for the other approaches discussed in Section 5.1. Fortunately, there are probabilistic implementations of the kind of weighted grammars used in this paper that predict non-null probabilities for candidates that have zero probabilities in a deterministic framework (e.g. stochastic Harmonic Grammar). In these probabilistic approaches, the algorithm evaluating linguistic forms is no longer conceived as specifying a single winner but a probability distribution over candidate forms. Patterns that violate implicational generalizations can be generated in the probabilistic approach but they remain less likely than patterns that do not violate them (Magri Reference Magri2018).
6. Conclusion
This paper has shown that, if syncretism is treated as motivated by constraints requiring morphological paradigms to be both small and unambiguous, a number of implicational generalizations fall out. In particular, the account successfully predicts the contexts favoring syncretism in four case studies whereas alternative analyses only account for some of the patterns. The crucial advantage of the current approach is that it takes into account the contextual recoverability of the feature targeted by syncretism.
The approach of morphological syncretism proposed in this paper is conceptually close to the phonetically-based approach of contextual neutralization in phonology (e.g. Flemming Reference Flemming2002). In Flemming’s model, contextual neutralization of phonemes arises as the result of the interaction of three functionally motivated constraints: a constraint favoring large phoneme inventories, a constraint favoring the minimal expenditure of effort in producing phonemes, and a constraint favoring perceptually distinct contrasts. Contextual neutralization arises when the additional effort necessary to maintain a large number of phonemes in a given context is not compensated by a sufficient gain in perceptual distinctiveness. This approach to phonological neutralization is also able to account for phonological implicational universals. For instance, the fact that the presence of contrasts involving consonant place of articulation in word-final positions asymmetrically entails the presence of these contrasts pre-vocalically follows from the hypothesis that place contrasts are universally more distinct pre-vocalically than word-finally (Jun Reference Jun, Hayes, Kirchner and Steriade2004). If speakers are willing to put a lot of effort in order to maintain sufficiently distinct contrasts word-finally, then they should be willing to maintain these contrasts pre-vocalically as it should require less effort to do so in this context.
The present analysis is conceptually similar because it also involves a trade-off between a constraint favoring large inventories (cf. the ambiguity cost) and a constraint favoring small inventories (cf. the size cost). Probabilities of grammatical features play the same role in the analysis of syncretism as perceptual distinctiveness in the analysis of contextual phonological neutralization: they provide a measure of the listener’s ability to recover underlying distinctions (grammatical features in the morphological case vs. phonemes in the phonological case) from the linguistic signal. The analysis of syncretism presented in this paper together with the phonetic analysis of phonological neutralization provide a rationale for the long observed parallel between morphological syncretism and contextual phonological neutralization: syncretism and phonological neutralization are similar in their typological manifestations because both arise as a result of language being a way of transmitting information under cognitive (perceptual, articulatory, processing, etc.) constraints.
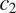
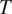
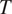






















 Open access
Open access