



1 Introduction
The purpose of this paper is to examine Voice Onset Time (VOT), one of the major acoustic correlates of voicing, in oral stops in Blackfoot (ISO 639-3: bla), an Algonquian language spoken in Southern Alberta, Canada and Northern Montana, USA (Frantz Reference Frantz2017). Voicing is not distinctive in Blackfoot: all obstruents (oral and glottal stops, fricatives and affricates) are phonemically voiceless, and all nasal stops, approximants and vowels are phonemically voiced (Frantz Reference Frantz2017, Weber Reference Weber2020). (The full phonemic inventory is presented in Section 2.) The lack of voicing contrast goes back to Proto-Algonquian (Bloomfield Reference Bloomfield, Osgood and Hoijer1946; Goddard Reference Goddard1974, Reference Goddard, Campbell and Mithun1979; Thomason Reference Thomason, Asher and Brown2006) and is well-documented for the daughter languages (e.g. Arapaho and Atsina: Goddard Reference Goddard1974, Reference Goddard, Campbell and Mithun1979; Kakadelis Reference Kakadelis2018; Cree: Mackenzie Reference Mackenzie1980; Wolfart Reference Wolfart and Goddard1996; Okimāsis & Wolvengrey Reference Okimāsis and Wolvengrey2008; Wolvengrey Reference Wolvengrey2011: 9–10; Hodgson Reference Hodgson2021; Michif: Rosen et al. Reference Rosen, Stewart, Pesch-Johnson and Sammons2019). To our knowledge there are very few if any instrumental investigations of the acoustic properties of Algonquian oral stops. Descriptions tend to be impressionistic and usually define them simply as voiceless unaspirated. What little acoustic work there is appears to support this. Recent work on Cree by Hodgson (Reference Hodgson2021) shows VOT in the speech of one speaker of Plains Cree in the short-lag (voiceless unaspirated) range. Kakadelis (Reference Kakadelis2018) reports similar results for coronal and dorsal stops in Arapaho, with its labial stop best described as phonetically voiced, occurring commonly with negative VOT. Rosen et al. (Reference Rosen, Stewart, Pesch-Johnson and Sammons2019) draw comparable conclusions for Michif; this last language is particularly interesting since Michif is a mixed language with source vocabulary from French and Cree, but the data suggest a phonological system with a single set of oral stops undifferentiated by voicing, as in Cree, rather than a double set, as in French. The only work available on Blackfoot is a preliminary study reported by Hall (Reference Hall2010) based on one speaker, suggesting again that average VOT values are in the short-lag range, fairly close to those for word-initial voiced stops in English. The current investigation is the first systematic acoustic study of the Blackfoot oral stop consonants.
Hodgson (Reference Hodgson2021) introduces the term ‘single series languages’ for languages without a stop voicing contrast. Investigations of single-series languages are generally rare compared to those with voicing contrast, presumably because the lack of a phonological contrast somehow makes them less interesting from a descriptive and theoretical point of view. For instance, a recent special issue of Journal of Phonetics (Cho, Docherty & Whalen Reference Cho, Docherty and Whalen2018a) entitled Marking 50 Years of Research on Voice Onset Time does not include a single language without voicing contrast among the 19 languages discussed in 11 contributions (Cho, Whalen & Docherty Reference Cho, Whalen and Docherty2018b); and an important textbook on acoustic analysis of speech discusses the acoustics of VOT exclusively in the context of its contribution to the voicing distinction (Kent & Read Reference Kent and Read2002: 150–154). A recent example of a detailed study of three languages without a voicing contrast is Kakadelis (Reference Kakadelis2018), who mentions that another reason for the relative lack of studies of languages without voicing contrast may be the fact that such languages are often ‘endangered, under-documented, or not spoken widely’ (1).
Nevertheless, there are some obvious theoretical, historical, descriptive and applied reasons for examining VOT in single-series languages. Theoretical reasons include questions about the range of VOT values occurring in such languages, and the effect of the phonetic environment on their production: a central question is whether languages without a voicing contrast have the same or similar VOT values and allophonic variation, or whether such values are language-specific in the same way that languages with a voicing contrast may choose a different range along the VOT spectrum to express their phonemic distinctions (Cho et al. Reference Cho, Whalen and Docherty2018b, Garvin Reference Garvin2018, Kakadelis Reference Kakadelis2018). Historical reasons include questions about what happens in language contact situations when one of the languages in contact has a voicing contrast and the other one does not (Rosen et al. Reference Rosen, Stewart, Pesch-Johnson and Sammons2019; Hodgson Reference Hodgson2021: 11). Descriptive reasons include the fact that, depending on one’s definition of ‘voicing contrast’, up to 20
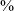 of the world’s languages have been estimated not to have a voicing distinction (Maddieson Reference Maddieson, Dryer and Haspelmath2013), implying that this is not a rare phenomenon and does deserve attention. Applied reasons include questions related to (first and second) language learning and accent acquisition (Riney & Takagi Reference Riney and Takagi2008; Kong, Beckman & Edwards Reference Kong, Beckman and Edwards2012; Turner et al. Reference Turner, Netelenbos, Rosen and Li2014; Netelenbos, Li & Rosen Reference Netelenbos, Li and Rosen2016; Kakadelis Reference Kakadelis2018: 37–38), and orthography design for minority languages in bilingual contexts where the majority language (which tends to be the one whose orthography is adapted to be used for the minority language) has a voicing distinction and the minority one does not (Hinton Reference Hinton, Cahill and Rice2014, Garvin Reference Garvin2018). In fact, the work reported in this paper was originally prompted by a desire to better understand the continuing disagreement in the Blackfoot-speaking community about which letters to use to write Blackfoot oral stops: the <p t k> series, as in the standard orthography developed by linguist Donald G. Frantz (Frantz Reference Frantz, MacCormack and Wurm1978, Reference Frantz1993, Reference Frantz2017), or the <b d g> series, as preferred by many community members, at least in some environments (Genee Reference Genee2020). The frequent preference to use <b d g> in representing Blackfoot stops is partly due to the influence of the English orthography, which denotes its series of phonetically voiceless unaspirated stops with these three letters.
of the world’s languages have been estimated not to have a voicing distinction (Maddieson Reference Maddieson, Dryer and Haspelmath2013), implying that this is not a rare phenomenon and does deserve attention. Applied reasons include questions related to (first and second) language learning and accent acquisition (Riney & Takagi Reference Riney and Takagi2008; Kong, Beckman & Edwards Reference Kong, Beckman and Edwards2012; Turner et al. Reference Turner, Netelenbos, Rosen and Li2014; Netelenbos, Li & Rosen Reference Netelenbos, Li and Rosen2016; Kakadelis Reference Kakadelis2018: 37–38), and orthography design for minority languages in bilingual contexts where the majority language (which tends to be the one whose orthography is adapted to be used for the minority language) has a voicing distinction and the minority one does not (Hinton Reference Hinton, Cahill and Rice2014, Garvin Reference Garvin2018). In fact, the work reported in this paper was originally prompted by a desire to better understand the continuing disagreement in the Blackfoot-speaking community about which letters to use to write Blackfoot oral stops: the <p t k> series, as in the standard orthography developed by linguist Donald G. Frantz (Frantz Reference Frantz, MacCormack and Wurm1978, Reference Frantz1993, Reference Frantz2017), or the <b d g> series, as preferred by many community members, at least in some environments (Genee Reference Genee2020). The frequent preference to use <b d g> in representing Blackfoot stops is partly due to the influence of the English orthography, which denotes its series of phonetically voiceless unaspirated stops with these three letters.
After Lisker & Abramson (Reference Lisker and Abramson1964) introduced VOT as a way of classifying voicing distinctions in oral stops, a large body of work has explored VOT as an acoustic measure that helps distinguish homorganic stops into commonly two or three, or occasionally four phonemically distinct categories in individual languages (Abramson & Whalen Reference Abramson and Whalen2017, Cho et al. Reference Cho, Whalen and Docherty2018b).Footnote 1 From an articulatory perspective, VOT is ‘defined as the temporal relation between the moment of the release of the stop and the onset of glottal pulsing’ (Abramson & Whalen Reference Abramson and Whalen2017: 76). Taking the burst associated with the stop release as the zero point, VOT is then measured in milliseconds, with negative values when the voicing begins before the burst (voicing lead), and positive values when it begins after the burst (voicing lag).
Subsequent work has refined the nature and measurement of VOT in word-initial vs. word-medial and word-final position, expanded its application to fricatives and affricates (Abramson & Whalen Reference Abramson and Whalen2017: 79–81), and identified other factors affecting VOT, such as place of articulation, length and quality of the following sonorant, and prominence. Word-initial VOT values tend to be longer than word-medial ones, especially when the word-medial stop is intervocalic or intersonorant (Flege & Brown Reference Flege and Brown1982, Kakadelis Reference Kakadelis2018); intervocalic stops are often fully voiced during the closure, with a negative VOT (Davidson Reference Davidson2016). More anterior places of articulation are associated with shorter VOT values (e.g. /t/ shows shorter VOT than /k/, Lisker & Abrahamson Reference Lisker and Abramson1964, Klatt Reference Klatt1975, Cho & Ladefoged Reference Cho and Ladefoged1999, Abdelli-Berruh Reference Abdelli-Beruh2009, Bijankhan & Nourbaksh Reference Bijankhan and Nourbaksh2009, Kakadelis Reference Kakadelis2018, Chodroff, Golden & Wilson Reference Chodroff, Golden and Wilson2019). VOT values are longer before long vowels compared to short vowels (Taff et al. Reference Taff, Lorna Rozelle, Ladefoged, Dirks and Wegelin2001, Hodgson Reference Hodgson2021). Following high vowels are sometimes associated with longer VOT (Klatt Reference Klatt1975, Bijankhan & Nourbaksh Reference Bijankhan and Nourbaksh2009, Garvin Reference Garvin2018, Hodgson Reference Hodgson2021). Presence of prominence on the syllable following the stop is likewise correlated with longer VOT (Davidson Reference Davidson2016).
Language-specific social correlations have also been reported. Social correlates of VOT include gender (e.g. Auzou et al. Reference Auzou, Canan Özsancak, Morris, Eustache and Hannequin2000, Bijankhan & Nourbakhsh Reference Bijankhan and Nourbaksh2009, Li Reference Li2013, Kharlamov Reference Kharlamov2018, Kleber Reference Kleber2018) and age (e.g. Auzou et al. Reference Auzou, Canan Özsancak, Morris, Eustache and Hannequin2000, Kleber Reference Kleber2018). Many of these correlations, however, are confounded by speech rate, which varies with age and gender (Swartz Reference Swartz1992, Morris, McCrea & Herring Reference Morris, McCrea and Herring2008). As Cho et al. (Reference Cho, Whalen and Docherty2018b: 59–60) mention, sociophonetic work in the area of VOT is scarce and remains very much a desideratum in the field.
Languages with a stop voicing contrast usually have contrastive voicing associated with two or three VOT ranges, depending on the nature of the contrast. In so-called ‘aspirating’ two-way languages such as English, German and Persian, both categories are mainly associated with positive VOT: the ‘voiced’ category is associated with a short-lag positive VOT, while the ‘voiceless’ category is associated with a long-lag positive VOT (e.g. Lisker & Abramson Reference Lisker and Abramson1964, Auzou et al. Reference Auzou, Canan Özsancak, Morris, Eustache and Hannequin2000, Bijankhan & Nourbakhsh Reference Bijankhan and Nourbaksh2009, Beckman, Jessen & Ringen Reference Beckman, Jessen and Ringen2013, Cho et al. Reference Cho, Whalen and Docherty2018b, Kakadelis Reference Kakadelis2018). In so-called ‘true voicing’ two-way languages such as French, Spanish, Russian, Hungarian, and many Arabic dialects, the ‘voiced’ category is associated with negative VOT (pre-voicing) while the ‘voiceless’ category is associated with short-lag VOT (e.g. Flege & Eefting Reference Flege and Eefting1987, Auzou et al. Reference Auzou, Canan Özsancak, Morris, Eustache and Hannequin2000, Beckman et al. Reference Beckman, Jessen and Ringen2013, Netelenbos et al. Reference Netelenbos, Li and Rosen2016, Al-Tamimi & Khattab Reference Al-Tamimi and Khattab2018, Cho et al. Reference Cho, Whalen and Docherty2018b). Some languages such as Swedish use non-adjacent ranges, skipping the short-lag range to contrast negative VOT with long-lag VOT (Helgason & Ringen Reference Helgason and Ringen2008). Languages with a three-way contrast use all three ranges, distinguishing categories usually called ‘voiced’, ‘voiceless’ and ‘(voiceless) aspirated’ by means of voicing lead, short lag and long lag VOT values respectively. Finally, languages with more than three contrasts employ additional laryngeal settings to create the contrasts (Cho et al. Reference Cho, Whalen and Docherty2018b: 54).
The stops in single-series languages theoretically have the entire spectrum from long lead to long lag available, but they are often described as voiceless unaspirated, i.e. as having a short lag VOT; some approaches consider this a kind of default or unmarked setting (Maddieson Reference Maddieson1984; Kakadelis Reference Kakadelis2018: 51–58). However, even these languages show a range of language-specific variation in the actual production of stops. Kakadelis (Reference Kakadelis2018) reports, on the basis of a detailed investigation of three languages without a voicing contrast (Bardi, Nahuatl, and Arapaho, an Algonquian language), that general correlational trends, such as the tendency for more posterior places of articulation to be associated with longer VOT values and a tendency for less prevoicing in phrase-initial compared to phrase-medial or -final contexts, are confirmed in such languages; however, ‘the ratio and distribution of tokens with positive versus negative VOT differed significantly’ (266), with stops in Bardi being mainly voiced (with voice lead), while in Arapaho and Nahuatl the labial stops have negative VOTs with the coronal and velar stops having positive VOTs, with quite significant differences in the size of the leads or lags. Hodgson (Reference Hodgson2021: 27) summarizes mean VOT distributions reported in the literature on eight single-series languages, confirming the general correlation with place of articulation alongside a broad language-specific variability in mean VOT ranges.
Our primary goal in this paper is to contribute to the study of VOT in languages without a voicing contrast by describing VOT patterns in Blackfoot. The secondary goal is to provide an in-depth investigation of how the VOT of these stop consonants correlates with different linguistic environments and speaker demographics. Our final goal is to validate our data-collection methods, which needed to be somewhat unorthodox due to the context and current state of the language. From a practical point of view, we also wished to shed light on the common preference of many Blackfoot speakers to use the letters <b d g> to represent Blackfoot stops in writing.
2 The Blackfoot language
Blackfoot (ISO 639-3: bla) is an endangered Algonquian language spoken in four First Nation communities in Alberta, Canada and Montana, USA, which together make up the Blackfoot Confederacy. Its Indigenous name is Niitsi’powahsin (‘Real/original language’) or Siksikai’powahsin (‘Blackfoot language’). There is dialectal variation between the language as spoken in each community (see Figure 1), but the varieties are fully mutually intelligible. A systematic description of dialect variation is lacking.

Figure 1 Blackfoot Nations in Alberta and Montana: A. = Siksika Nation, B. = Piikani (Peigan) Nation, C. = Kainai (Blood) Nation, D. = Aamsskaapipikani (Piegan Blackfeet, Montana) Nation. Map courtesy Kevin McManigal.
Estimates regarding speaker numbers range from about 3,000 to about 5,000 speakers, approximately 15
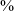 of the total population, with fluent speakers tending to belong to older generations. Among the younger generations there are many so-called ‘silent speakers’ or ‘fluent listeners’, who have significant passive understanding but limited conversational fluency. There is little intergenerational transmission and there are very few if any monolingual speakers (Genee & Junker Reference Genee and Junker2018). The standard orthography developed by Frantz (Reference Frantz, MacCormack and Wurm1978, Reference Frantz1993, Reference Frantz2017) was officially adopted by the Canadian Nation schoolboards in 1975 (Frantz Reference Frantz2017: 185) but has not found general acceptance or universal implementation. Fluent elderly speakers tend not to be proficient in it, and several alternative orthographies and spelling systems, including a syllabary, are also in use in the community (Genee Reference Genee2020).
of the total population, with fluent speakers tending to belong to older generations. Among the younger generations there are many so-called ‘silent speakers’ or ‘fluent listeners’, who have significant passive understanding but limited conversational fluency. There is little intergenerational transmission and there are very few if any monolingual speakers (Genee & Junker Reference Genee and Junker2018). The standard orthography developed by Frantz (Reference Frantz, MacCormack and Wurm1978, Reference Frantz1993, Reference Frantz2017) was officially adopted by the Canadian Nation schoolboards in 1975 (Frantz Reference Frantz2017: 185) but has not found general acceptance or universal implementation. Fluent elderly speakers tend not to be proficient in it, and several alternative orthographies and spelling systems, including a syllabary, are also in use in the community (Genee Reference Genee2020).
Blackfoot is a polysynthetic language with extensive inflectional and derivational morphology (Frantz Reference Frantz2017, Genee Reference Genee, Keizer and Olbertz2018). This section introduces the Blackfoot phonemic inventory and the main phonological and morphophonological factors that we considered during our data collection and analysis.
Table 1 Blackfoot consonant system.

Table 2 Blackfoot vowel system.

Blackfoot’s phonemic inventory is usually given a in Tables 1 and 2 (Frantz Reference Frantz2017, Elfner Reference Elfner2006a, b; but see Weber Reference Weber2020 for a different inventory; see Derrick & Weber Reference Derrick and Weber2023 for a discussion of the lack of consensus regarding the Blackfoot phonemic inventory).
Consonants can be singleton or geminate, except for glottal stop, the glottal and velar fricatives, and approximants.Footnote 2 Geminate stops do not occur word-initially. /x/ is palatal [ç] after a high front vowel. Vowels can also be singleton or geminate, and have the following common allophones: high front: [ɪ]; high back: [u ʊ]; low: [ʌ].
Two common allophonic processes affected our data collection:
-
(i) Vowels are voiceless in many contexts, especially short vowels word-finally and between voiceless consonants (Bliss & Glougie Reference Bliss, Glougie, Bliss and Girard2009, Gick et al. Reference Gick, Bliss, Michelson and Radanov2012, Prins Reference Prins2019). These environments were excluded from our analysis because there was no voice onset.
-
(ii) Assibilation turns all underlying /ti(ː)/ sequences into [t͡si(ː)]. This resulted in a significant systematic gap in our data for /t/, since only sequences of [ta(ː)] and [to(ː)] are possible.
Two other important factors were:
-
(iii) Orthographic <Vh> sequences do not contain a vowel, but a syllabic dorsal fricative with secondary palatalization (after /i/) or rounding (after /o/) (Miyashita Reference Miyashita, Noodin and Macauley2017).Footnote 3 Both orthographic <ih> and <iih> are pronounced as [s] or [sː] by many speakers.
-
(iv) Long vowels do not occur before a dorsal fricative. Orthographic <VVh> sequences contain a short vowel followed by a dorsal fricative (Frantz Reference Frantz2017, Miyashita Reference Miyashita, Noodin and Macauley2017).
Blackfoot is generally described as a pitch accent language (Taylor Reference Taylor1969, Van Der Mark Reference Van Der Mark2002, Weber Reference Weber, Macaulay, Noodin and Valentine2016, Fish & Miyashita Reference Fish, Miyashita, Jon Reyhner, Lockard and Sakiestewa Gilbert2017, Frantz Reference Frantz2017). Both long and short vowels can be accented or unaccented, and some long vowels are characterized by a falling pitch pattern. Pitch accent is optionally represented in the orthography by means of acute accents.
3 Methodology
3.1 Data
We collected words with stop consonants occurring in different positions, with varying pitch accent patterns on the following vowel, and followed by long vs. short vowels of different quality. Data were collected for non-geminate oral stops in word-initial and word-medial position in all available environments. Geminate stops were excluded due to their limited distribution, in particular their non-occurrence in word-initial position. (Hodgson Reference Hodgson2021 excludes geminates from her investigation of Cree for similar reasons). We did not use carrier phrases, so word-initial tokens are in effect utterance-initial tokens. Only the six monophthongs /i iː a aː o oː/ were included, as it was not possible to get a full set of diphthongs in our stimuli collection. Where possible we included accented and unaccented vowels. This meant that for /p/ and /k/ there were twelve distinct following vowels, but for /t/ the environments with following /i iː/ were missing because /t/+/i(ː)/ always assibilates (see Section 2 above).
We aimed to include three different tokens for each environment, but this was not always possible. Table 3 lists the environments with an example of each involving the labial stop /p/.
Table 3 List of phonological environments that were controlled for and sample stimulus words elicited for each environment with target stop consonant /p/, in orthographic and broad phonetic transcription. Bold marks the target stop consonant and its pertinent phonological environment.
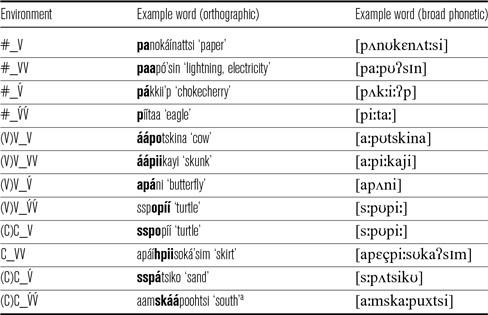
aAn example for this environment with /p/ was not available.
3.2 Speakers and data collection procedure
Data were originally collected from 19 adult native speakers of the Kainai (Blood) dialect of Blackfoot.Footnote 4 Data from six speakers had to be excluded: two due to insufficient audio quality; three because the recordings were incomplete; and one because English only was reported as the first language on the demographics form. The remaining 13 speakers were between 34 and 77 years old with a median age of 59 years. There were eight female speakers aged 34–69 years, with a median age of 57.5 years, and five male speakers aged 49–77 years, with a median age of 61 years. All speakers self-identified as fluent in Blackfoot and English, and all indicated that their L1 was either Blackfoot alone or Blackfoot and English. Details are presented in Table 4.
Table 4 Speakers.

Recording sessions took place in the Blackfoot Language Resources lab at the University of Lethbridge or in the speaker’s home. The latter was necessary as some speakers were unable to travel or indicated that they preferred to be interviewed in their own environment. Attempts were made to ensure the different locations did not result in significantly different levels of formality that might affect the speech produced. In both cases, the atmosphere was informal and relaxed. Participants were able to be accompanied by a family member or friend if desired, and were offered refreshments before the recording began; they were seated comfortably and given breaks when needed. The principal fieldworker was a familiar person.
Recordings were made with a Roland Edirol R-09HR handheld recorder and a NexxTech lapel microphone at a sampling rate of 44.1 kHz and 24-bit resolution.
Speakers either sat in front of a laptop computer or were given a paper printout of the stimuli. Many speakers of Blackfoot are not able to read Blackfoot, so we were unable to present the stimuli in written form. We chose not to have the participants simply repeat the stimuli given by the fieldworker so as not to prime the speaker with an initial pronunciation.
Two kinds of stimuli were presented: pictures and written English words/short phrases. Participants were asked to say the Blackfoot word for the pictures and to translate the written English words and short phrases into spoken Blackfoot. They were asked to repeat each target three times, with the second one being used for analysis. There were a total of 79 picture stimuli and 49 translation stimuli. The type of stimulus did not significantly affect VOT (see Table 7 below). All picture stimuli elicited one-word responses. With a few exceptions all translation stimuli also elicited one-word responses in Blackfoot, so that most tokens were single words. Exceptions were four questions containing a question word (tsimáá ‘where’; tsá ‘what’, takáá ‘who’) plus verb and one phrase consisting of two words (aapinákosi nitáákssko’too ‘I will come back tomorrow’).
Instructions were given in English, but the main fieldworker was an intermediate speaker of Blackfoot and would sometimes whisper a prompt if the speaker could not remember a word. Several rounds of pilot elicitations eliminated stimuli that were likely to be deemed culturally inappropriate or to elicit too many different responses. Even then, some responses had to be discarded because they did not elicit the intended word.
3.3 Acoustic analysis
Praat (version 6.1.41, Boersma & Weenink Reference Boersma and Weenink2019) was used to segment the recordings into individual words and to mark sound boundaries and acoustic events. For each target stop consonant, two acoustic events were marked: the stop burst and the voice onset (see Figure 2). The burst was defined by the spike or a cluster of spikes of energy in the waveform occurring at the beginning of the closure release. Voice onset is where voicing starts immediately preceding or following the consonant as evident from the presence of the voicing bar in the spectrogram. Voice Onset Time (VOT) was calculated by subtracting the stop burst time from that of the voice onset. Five undergraduate research assistants were trained to mark the acoustic events and discussed their markings in a separate meeting to ensure compatibility and to reach consensus on difficult cases. Their markings had an interrater reliability of above 90
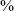 as measured by Pearson’s correlation coefficient, and the VOT measurement differences between raters were within 2 milliseconds of each other. Our study thus confirmed the tendency for the reliability of manual VOT measurements to be very high (Auzou et al. Reference Auzou, Canan Özsancak, Morris, Eustache and Hannequin2000: 134).
as measured by Pearson’s correlation coefficient, and the VOT measurement differences between raters were within 2 milliseconds of each other. Our study thus confirmed the tendency for the reliability of manual VOT measurements to be very high (Auzou et al. Reference Auzou, Canan Özsancak, Morris, Eustache and Hannequin2000: 134).
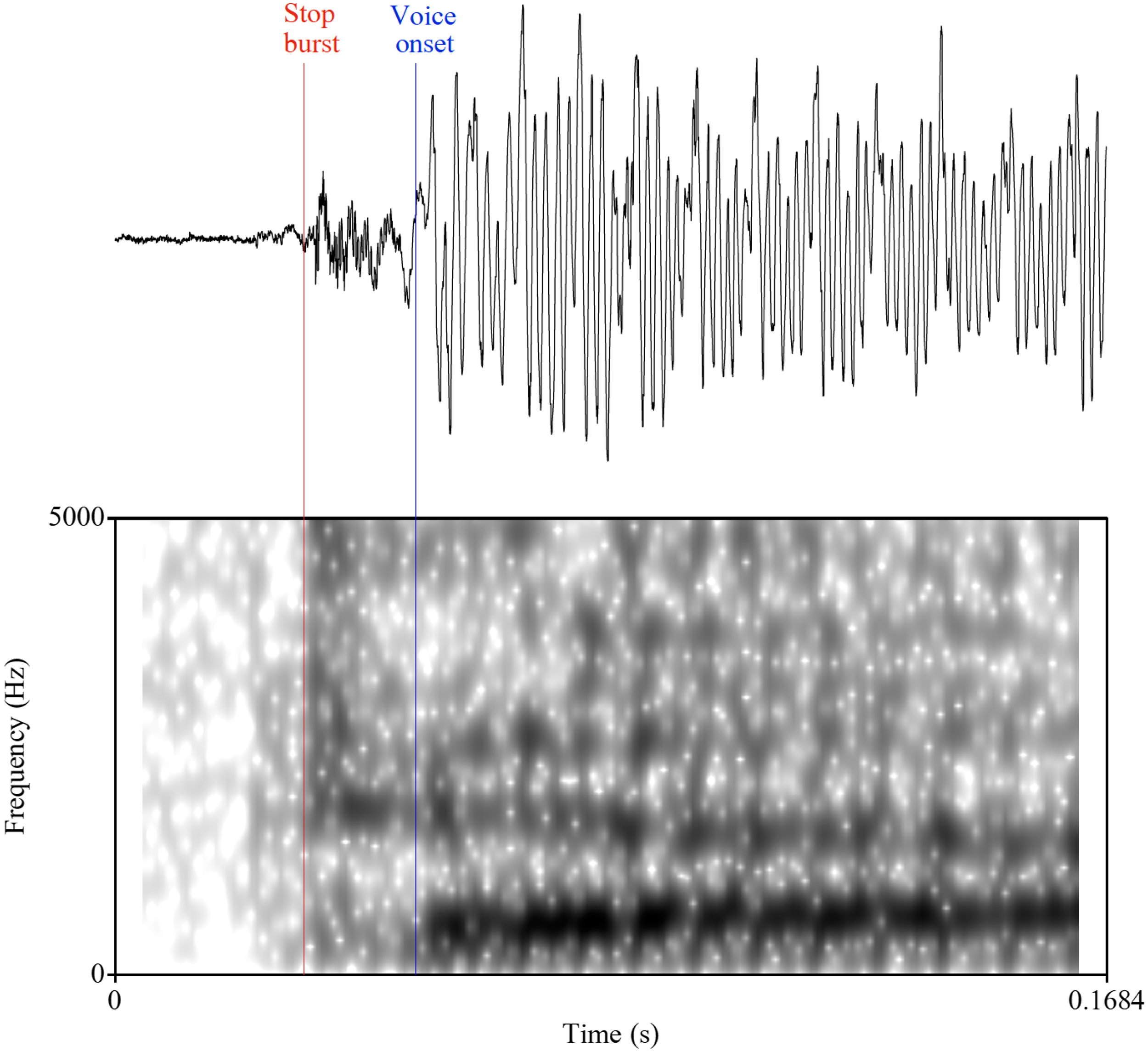
Figure 2 Demonstration of the two acoustic events marked in Praat: Stop burst of /t/ and voice onset of the following vowel /aː/ in the word /piːtaː/ ‘eagle’ produced by a male Blackfoot speaker.
3.4 Statistical analysis
A combination of linguistic, socio-indexical, and experimental factors was examined in the statistical analysis. As discussed in Section 2, linguistic factors that may affect VOT include: place of articulation (Lisker & Abrahamson Reference Lisker and Abramson1964, Klatt Reference Klatt1975, Cho & Ladefoged Reference Cho and Ladefoged1999, Abdelli-Berruh Reference Abdelli-Beruh2009, Bijankhan & Nourbaksh Reference Bijankhan and Nourbaksh2009, Chodroff et al. Reference Chodroff, Golden and Wilson2019); position in the word (Flege & Brown Reference Flege and Brown1982, Davidson Reference Davidson2016); length and quality of the following vowel (Klatt Reference Klatt1975, Cho & Ladefoged Reference Cho and Ladefoged1999, Taff et al. Reference Taff, Lorna Rozelle, Ladefoged, Dirks and Wegelin2001, Bijankhan & Nourbaksh Reference Bijankhan and Nourbaksh2009, Garvin Reference Garvin2018); and presence or absence of prominence following the stop (Flege & Brown Reference Flege and Brown1982, Davidson Reference Davidson2016). Socio-indexical factors that may affect VOT include gender and age (Bijankhan & Nourbakhsh Reference Bijankhan and Nourbaksh2009, Li Reference Li2013, Kharlamov Reference Kharlamov2018, Kleber Reference Kleber2018, Swartz Reference Swartz1992, Morris et al. Reference Morris, McCrea and Herring2008). In addition, we added task type as an experimental factor; the goal here was to investigate whether the methods used to collect our data affected the nature of the data.
Using R (R Core Team, 2019), a linear mixed effects model was constructed to identify the effect of linguistic, socio-indexical, and experimental factors on VOT values. The linguistic factors include: the place of articulation of the target stop consonant (three levels: /p/, /t/, and /k/); the following vowel (two levels: /a/ vs. /o/); and the prosodic characteristics of the following vowel such as length (two levels: long vs. short) and pitch accent pattern (two levels: accented vs. unaccented). The socio-indexical factors were speakers’ age and gender (two levels: male vs. female). The experimental factor refers to the two types of experiments (picture-naming vs. translation) in which participants were engaged. Thus, the fixed effects components of the model were: target consonant; quality of the following vowel; length of the following vowel; pitch accent pattern of the following vowel; speakers’ age (coded as continuous); speaker’s gender; and task type. Since the fixed effect factor ‘target consonant’ has three categories: /p/ (reference level), /t/, and /k/, post-hoc pair-wise comparison was conducted using the R package emmeans (Lenth Reference Lenth2021). With respect to the following vowel, due to the systematic gap in vowel /i/ preceded by /t/, only the vowels /a/ and /o/ were included in the model. Individual speakers and words were included as random intercepts, and a by-participant random slope that varies with target consonant was included to further account for repeated measures. The statistical analysis was conducted using the R package lme4 (Bates et al. Reference Bates, Mächler, Bolker and Walker2015a, b; Table 7 below includes the R code used for the model). Overall model fit was assessed through the pseudo r 2 (Nakagawa & Shielzeth Reference Nakagawa and Schielzeth2013) calculated using the r.squaredGLMM function in the R package MuMIn (Bartoń Reference Bartoń2020). In linear modeling, r 2 measures the proportion of variance explained by the model and thus serves as a metric for assessing model fitness. The calculation and interpretation of r 2 , however, is less straightforward due to the hierarchical structure of the mixed effects model. Pseudo r 2 is then obtained which computes two r 2 values: marginal r 2 and conditional r 2 . Marginal r 2 is the variance explained by the fixed effects in the model while conditional r 2 is the amount of variance accounted for by both the fixed effects and the random effects. r 2 values above 0.06, 0.16, and 0.36 were considered as small, medium and large respectively (Plonsky & Oswald Reference Plonsky and Oswald2014).
Table 5 Summary statistics (mean and sd) of VOT values for the three target stop consonants in the three vowel contexts, for each gender group.

Table 6 Mean VOT ranges for English voiceless and voiced stop consonants based on Auzou et al.’s (Reference Auzou, Canan Özsancak, Morris, Eustache and Hannequin2000: 139) review of 12 studies of VOT in English as summarized in Kent & Read (Reference Kent and Read2002: 151) compared with Blackfoot VOT ranges found in this study.

4 Results
4.1 Summary statistics and comparison to English
Table 5 lists the summary statistics of VOT values for the three consonant targets followed by the three vowel qualities /a/, /i/ (only for /p/ and /k/), and /o/, for male speakers and female speakers respectively. As shown in the table, VOT values increase as the place of articulation progresses farther back into the oral cavity: the velar /k/ has the longest VOT, followed by the alveolar /t/, with the bilabial /p/ having shortest VOT. Further comparison between Blackfoot and English (Table 6) suggests that the range of VOT values for the Blackfoot stop consonants corresponds most closely to the English voiced stop consonant series.
Table 7 Results of the linear mixed effects model on VOT (ms). The fixed effects are target stop consonant, the following vowel, task type, word position, the length and pitch accent pattern of the following vowel, as well as speakers’ age and sex. Bold in the last column marks statistical significance.


Figure 3 VOT distributions for the three stop consonants followed by long vs. short vowel /o/ and vowel /a/.
4.2 Results of linear mixed effects model: Linguistic factors
Table 7 outlines the statistical results of the linear mixed effects model that systematically tests all factors of interest. First, there is a significant effect of place of articulation. VOTs for velar stops are 10.986 ms longer than for bilabial stops and 9.729 ms longer than for alveolar stops. Post-hoc pairwise comparison did not find significant difference in VOT values between alveolar and bilabial stops. The greater difference between /k/ and /p, t/ (as compared to that between /p/ and /t/) is evident also from Table 5 and Figure 3. The lack of significant difference between /p/ and /t/ and the presence of the significant difference between /k/ and /t, p/ suggests that the increment is not linear. Second, a significant vowel effect was identified. Stop consonants followed by the high back vowel /o/ have an average of 3.293 ms longer VOT values than those followed by the low vowel /a/. Finally, when followed by a long vowel, stop consonants have 1.632 ms longer VOT values than when followed by a short vowel, and this effect is significant, as illustrated in Figure 3. It is to be noted that the effect sizes for vowel quality and length are small and need to be interpreted with caution; this awaits verification with a larger number of participants and a broader range of data in future research. The effects for word position and accent pattern were both substantively small and statistically insignificant. That is, VOT values do not significantly vary with the position in which the stop consonants occur within a word or with the presence or absence of a following accented vowel.
4.3 Results of linear mixed effects model: Socio-indexical and experimental factors
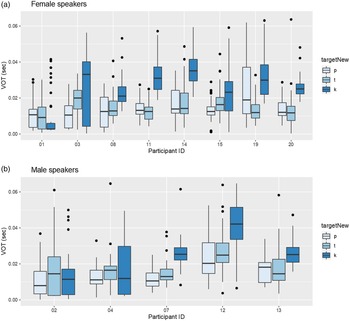
The results of the linear mixed effects model in Table 7 suggest no effect for the socio-indexical and experimental factors. As illustrated in Figure 4, which displays boxplots for each individual speaker for each gender, there is a wide range of variability in VOT values in both gender groups. No clear differences can be identified between male and female speakers. Age was found to show a substantively small trend that nearly reaches the bar of significance. The specific task in which participants were engaged did not make a significant difference with regard to VOT values; this was a very robust finding, with a substantively very small effect size and very low significance.

Figure 4 Boxplots of VOT ranges of individual speakers, separated by gender.
5 Discussion
To summarize, our data confirm the traditional impressionistic description of Algonquian stops as phonetically voiceless unaspirated. Table 5 shows that mean VOT values in our study ranged from 11.6 ms for /p/ followed by /a(ː)/ to 32.7 for /k/ followed by /i(ː)/ (both for female speakers). This is in line with findings from the sparse acoustic work on Algonquian stops. Hall (Reference Hall2010) reports means between 13–24 ms for one Blackfoot speaker from Montana; Kakadelis (Reference Kakadelis2018: 272) reports a generalized mean of 28 ms for Arapaho; Hodgson’s (Reference Hodgson2021: i, 53–54) study of Cree reports means between 11.6–25.6 ms; and Rosen et al. (Reference Rosen, Stewart, Pesch-Johnson and Sammons2019) found means between 18–48 ms for Michif.
These comparisons should be interpreted carefully, however, especially in light of the differences between the data used in the studies. Hall (Reference Hall2010) analyzed an unknown number of tokens selected from target words elicited from one speaker of Piegan Blackfeet (Montana). Kakadelis (Reference Kakadelis2018: 157) analyzed 522 oral stops from a total of about an hour of spontaneous narrative produced by five speakers of Arapaho. Hodgson (Reference Hodgson2021: 38–43) analyzed 660 tokens selected from about two hours of a publicly available online corpus of narratives produced by one speaker of Plains Cree. Rosen et al. (Reference Rosen, Stewart, Pesch-Johnson and Sammons2019) analyzed 446 tokens from semi-directed ‘Pear Story’ narratives produced by 10 speakers of Michif. We analyzed 2096 tokens from 13 different speakers produced in a controlled experimental setting. Interestingly, Rosen et al. (Reference Rosen, Stewart, Pesch-Johnson and Sammons2019) report that the polysynthetic nature of Michif resulted in a dearth of nouns in their data, while we were able to assemble a data set with just over 60
 nouns in a more controlled environment. This suggests that, in addition to the expected differences related to levels of formality and genre, different data types and collection methods may also result in differences between the word categories that end up in one’s data set. In the case of the Michif data reported in Rosen et al. (Reference Rosen, Stewart, Pesch-Johnson and Sammons2019) this resulted in a shortage of French-origin words which limited their ability to draw conclusions regarding variation related to the Cree vs. French contributions to the phonological system of a mixed language. Other possible effects of unbalanced word categories await further investigations.
nouns in a more controlled environment. This suggests that, in addition to the expected differences related to levels of formality and genre, different data types and collection methods may also result in differences between the word categories that end up in one’s data set. In the case of the Michif data reported in Rosen et al. (Reference Rosen, Stewart, Pesch-Johnson and Sammons2019) this resulted in a shortage of French-origin words which limited their ability to draw conclusions regarding variation related to the Cree vs. French contributions to the phonological system of a mixed language. Other possible effects of unbalanced word categories await further investigations.
The VOT ranges found in our data also agree with the ranges found in other languages without a voicing contrast as reported in some of the literature. Kakadelis (Reference Kakadelis2018), in a detailed study of stops in three languages without voicing contrast, found mean VOT ranges between 23 ms and 28 ms. It has been suggested that there is something basic about the short-lag VOT, perhaps due to the relative articulatory ease of producing stop consonants that do not involve voicing or aspiration (Kong et al. Reference Kong, Beckman and Edwards2012); this may also be related to the fact that the short-lag VOT range seems to be the anchor range from which other contrastive categories emerge in infants’ babbling and children’s early speech production in languages with a stop voicing contrast (Macken & Barton Reference Macken and Barton1980; Hitchcock & Koenig Reference Hitchcock and Koenig2013). However, such generalizations need to be balanced against the fact that individual single-series languages may employ language-specific ranges that do not overlap with those of other single-series languages, as shown by Hodgson’s (Reference Hodgson2021: 73) comparison of VOT in nine language varieties. An illustrative example is modern Māori: with mean VOT values between 50ms and 66ms (Hodgson Reference Hodgson2021: 26), Modern Māori’s range falls entirely outside of that covered by Blackfoot and the languages investigated by Kakadelis (Reference Kakadelis2018).
Our study confirms that Blackfoot VOT values are in the range corresponding to English voiced (short lag) stops, reported to have mean ranges between 1–20 ms for /b/, 0–21 ms for /d/, and 14–35 ms for /ɡ/ (Auzou et al. Reference Auzou, Canan Özsancak, Morris, Eustache and Hannequin2000: 139; Kent & Read Reference Kent and Read2002: 151). This is important as it goes some way to explaining difficulties surrounding the acceptance and implementation of the standard spelling system developed by linguist Donald G. Frantz in the 1970s (Frantz Reference Frantz, MacCormack and Wurm1978, Reference Frantz1993, Reference Frantz2017). After analyzing the Blackfoot stops as phonetically voiceless unaspirated, Frantz understandably chose the letters <p t k> for the orthography. The orthography he developed was officially adopted by the Canadian Blackfoot Nation schoolboards in 1975, but it continues to lack universal acceptance. Such a situation is by no means unique to Blackfoot; similar disagreements in other North-American Indigenous communities are described by Hinton (Reference Hinton, Cahill and Rice2014), who coined the term ‘orthography wars’. Writers of Blackfoot who have not been trained in the standard orthography often use the letters <b d g>, digraphs consisting of these letters followed by <h> (<bh dh gh>), or digraphs combining the English voiceless and voiced letters (<bp td kg>), especially in contexts where English voiceless stops would have the long VOT associated with aspiration (Genee Reference Genee2020). The finding that Blackfoot stops have VOTs that are very similar to those of English voiced (short lag) stops also supports some practices commonly seen in L2 teaching contexts when teachers explain how to pronounce the Blackfoot letters <p t k>, or correct L2 pronunciations of Blackfoot stops pronounced with too much aspiration: the learner is often told to ‘make it sound more like a b/d/g’. Our work here shows that producing Blackfoot stops with VOTs closer to those of English voiced (short lag) stops should in fact result in more native-like pronunciations (see Garvin’s (Reference Garvin2018) comments on Northern Shoshoni for similar points). We hope to investigate this in future work comparing L1 with L2 speakers. We also hope to use these results to develop targeted pronunciation exercises for L2 learners allowing students to compare their own VOT with that of a fluent speaker through self-recording into Praat or a dedicated CALL application based on visualization of Voice Onset Time (compare work by Fish & Miyashita Reference Fish, Miyashita, Jon Reyhner, Lockard and Sakiestewa Gilbert2017 on the visualization of pitch accent patterns in Blackfoot).
Significant effects were found for three of the five linguistics factors investigated (i.e. place of articulation of the target stop consonant and quality and length of the following vowel), while no significant effects were found for the other two linguistics factors (i.e. pitch accent pattern of the following vowel and word position of the target consonant) nor for the socio-indexical and experimental factors.
The Blackfoot data confirm three cross-linguistic tendencies familiar from the literature on VOT (see Section 1). First, longer VOT values were found to correlate with more posterior places of articulation. As shown in Table 7, this correlation was strong and highly significant, confirming a cross-linguistic trend that is very well established in the literature (Lisker & Abrahamson Reference Lisker and Abramson1964, Klatt Reference Klatt1975, Cho & Ladefoged Reference Cho and Ladefoged1999, Abdelli-Berruh Reference Abdelli-Beruh2009, Bijankhan & Nourbaksh Reference Bijankhan and Nourbaksh2009, Chodroff et al. Reference Chodroff, Golden and Wilson2019).
Second, stops followed by high vowels were found to have longer VOTs than those followed by low vowels. This correlation was also highly significant and confirms a well-established cross-linguistic trend (Klatt Reference Klatt1975, Taff et al. Reference Taff, Lorna Rozelle, Ladefoged, Dirks and Wegelin2001, Bijankhan & Nourbaksh Reference Bijankhan and Nourbaksh2009). Recall, however, that our findings here are limited by the systematic gap in the data caused by the non-occurrence of [t+i(ː)].
Third, longer VOT values were found to correlate with longer following vowels (Klatt Reference Klatt1975, Taff et al. Reference Taff, Lorna Rozelle, Ladefoged, Dirks and Wegelin2001, Bijankhan & Nourbaksh Reference Bijankhan and Nourbaksh2009).
These three findings confirm results reported for the Algonquian language Cree, although it must be noted that the correlation of longer VOT with a longer following vowel was only confirmed for /p/ in Hodgson’s (Reference Hodgson2021) study. For Arapaho, the first tendency is confirmed, while the second and third were not addressed in the study by Kakadelis (Reference Kakadelis2018).
Interestingly, our data did not confirm the cross-linguistic tendency for word-initial stops to have longer VOTs than word-medial ones, especially intersonorants (Flege & Brown Reference Flege and Brown1982, Davidson Reference Davidson2016, Kakadelis Reference Kakadelis2018). In contrast, we found no significant differences between word-initial and word-medial stops, and therefore no correlation with position in the word. This result was a bit surprising, given that it appears to be a robust finding in the literature (Flege & Brown Reference Flege and Brown1982, Davidson Reference Davidson2016; the expected pattern was also confirmed for Cree in Hodgson Reference Hodgson2021). Derrick & Weber’s (Reference Derrick and Weber2023) Blackfoot data, obtained from the speech of a single speaker of Kainai Blackfoot, also appear to mirror the cross-linguistic tendency, contrasting with our results. They even found some negative VOTs, mainly in word-medial contexts after a voiced segment, but also a few cases of true word-initial pre-voicing; it should be noted however that their data included all obstruents, including geminates and affricates, and are therefore not fully comparable to ours. Further investigation with more speakers and a wider range of segment types and phonological contexts is warranted. Kakadelis’ (Reference Kakadelis2018: 177) study of Arapaho reports that ‘[t]he phonological context does not seem to significantly affect the direction of VOT across place of articulation’, which seems to be more in line with our Blackfoot findings.
The effects of socio-indexical factors such as age and gender on VOT are only rarely studied, and where they are, results appear to be mixed (Swartz Reference Swartz1992, Auzou et al. Reference Auzou, Canan Özsancak, Morris, Eustache and Hannequin2000, Morris et al. Reference Morris, McCrea and Herring2008, Bijankhan & Nourbaksh Reference Bijankhan and Nourbaksh2009, Kharlamov Reference Kharlamov2018, Kleber Reference Kleber2018). We did not find significant effects for gender or age in our data. Age came closest to reaching significance (p = .089). It might be possible to find a stronger effect when including a larger range of different age groups. Auzou et al. (Reference Auzou, Canan Özsancak, Morris, Eustache and Hannequin2000: 138–140) suggest that VOT is more variable in very young children and in older adults. Since our study did not include children, we were unable to investigate this aspect. Given the very low rates of home transmission, the window may have closed on being able to study this age group, although it may be still possible to study second language acquisition of VOT in school-aged children, along the lines of comparable studies for French in Canadian immersion contexts (e.g. Netelenbos et al. Reference Netelenbos, Li and Rosen2016). We hope to investigate other socio-indexical factors in future work with more participants and speakers from the other dialect areas.
The lack of an effect related to the experimental condition was a particularly robust finding with important methodological implications for research on endangered minority languages. Collecting the data needed for our study was challenging for a number of reasons. First, basic nouns are easier to elicit than verbs, but we were not able to include all required phonological conditions that way and had to include some verbal expressions. However, due to the polysynthetic nature of the language, verb words tend to be very long: the exact form produced in elicitation conditions can be unpredictable and sometimes varied even between successive pronunciations of the same word by the same speaker. Second, pilot sessions led to the elimination of several words that were either not deemed culturally appropriate or whose prompts elicited too many variant responses between speakers. This resulted in the loss of some otherwise very suitable items from our initial target list, which then had to be replaced. Third, limited Blackfoot literacy amongst the participants meant that we could not ask them to read a word list. Fourth, limited Blackfoot fluency amongst the field workers meant we could not use word repetition as an elicitation method. In order to mitigate these challenges we designed two different tasks: a picture elicitation task and an English-to-Blackfoot translation task. The choice between picture and translation task was made on practical grounds: any word that could be represented by a picture in an unambiguous manner was elicited that way, and translation prompts were used for words that could not be elicited with a picture. The fact that no difference was found between these two conditions confirms that the elicitation method is not a confounding factor, and that the pragmatic approach we used is suitable for collecting data in the often less-than-straightforward conditions surrounding endangered minority languages. Speakers quickly understood what was asked of them, enjoyed both task types, responded positively, and did not get tired or frustrated too quickly. This is important for future research on Blackfoot and other endangered languages with mainly elderly speakers who are not accustomed to these kinds of formal academic activities.
6 Conclusion
This study supports a description of Blackfoot oral stops as voiceless unaspirated, with VOTs falling in the short-lag range. Several cross-linguistic tendencies were confirmed, in particular the correlation of longer VOT values with more posterior places of articulation and with longer and higher following vowels. A tendency for shorter VOT in word-medial position was not confirmed, nor did we find a correlation between VOT and following accent. We also found no correlation with socio-indexical factors or experimental condition. Given the scarcity of socio-phonetic work, potential differences in VOT especially between genders, ages and dialects warrant further investigation, as does the potential for different data types to produce differences in VOT. Further applied work might include the development of targeted pronunciation instruction for L2 learners.
Acknowledgements
The participants who contributed their voices, and without whom this study would not have been possible, requested to remain anonymous; we express our sincere gratitude to them. Jessie Black Water, Mahaliah Peddle and Brittany Wichers collected the data. Mahaliah Peddle and Brittany Wichers selected the stimuli, prepared the data collection materials, and assisted with bibliography. Zoie Hansen, Catherine Kwan, Chris Hatton, Steven Timms, and Brittany Wichers conducted event marking in Praat. Mizuki Miyashita provided early feedback on the experiment design and data collection procedure. Doug Whalen gave very useful comments and references in response to our presentation at the 52nd Algonquian Conference. We thank the audiences of the 2020 Montana/Alberta Conference on Linguistics (mACOL) and the 52nd Algonquian Conference for probing questions. Last but not least, we gratefully acknowledge excellent detailed comments and suggestions from three anonymous reviewers for JIPA, and from associate editor Marzena Żygis, who shepherded our paper through the review process.
Competing interests
The authors declare none.











 Open access
Open access