


1. Introduction
In recent years, artificial intelligence technologies such as service robots, autonomous driving, and AR/VR have rapidly developed and demonstrated broad applications. A key commonality among these applications is the need for high-precision modeling of scenes, including semantic objects such as cars and people. To achieve the above functions, a fundamental and important technology – simultaneous localization and mapping (SLAM) – is indispensable. On the other hand, most SLAM [Reference Zhang and Singh1–Reference Behley and Stachniss4] systems based on the assumption of rigid scenes are not applicable in dynamic scenes with moving objects. Firstly, during the localization and mapping process, the framework designed for static scenes will introduce disturbances to the estimation problem due to the emergence of dynamic objects. The system may even crash as a result. Secondly, the classic SLAM system can only construct 3D maps with static backgrounds. They cannot provide the foreground semantic object information required for upper-level planning and control tasks. The robots may appear clumsy and unreliable in practical work. Therefore, it is necessary to focus on dynamic SLAM technology to improve the adaptability of navigation systems in real scenarios.
Currently, some studies have used geometric constraints or prior semantic methods to process dynamic objects within the perception range of the sensor. Methods with geometric constraints [Reference Deschaud5–Reference Tan, Liu, Dong, Zhang and Bao8] use spatial clustering, motion segmentation, background model, or reprojection error checking to separate abnormal data associations before state estimation. For learning-based methods, refs. [Reference Ruchti and Burgard9, Reference Pfreundschuh, Hendrikx, Reijgwart, Dubé, Siegwart and Cramariuc10] and [Reference Cheng, Sun and Meng11] directly identify moving objects in a single scan or image through the trained network model. Refs. [Reference Chen, Wang, Wang, Deng, Wang and Zhang12] and [Reference Chen, Milioto, Palazzolo, Giguere, Behley and Stachniss13] use a semantic segmentation network [Reference Milioto, Vizzo, Behley and Stachniss14] to obtain point-level semantic labels in the lidar scan and realize 3D map construction with scene semantics (roads, buildings). Undoubtedly, compared to schemes that check abnormal geometric constraints, SLAM systems which correctly introduce and use semantic information have more potential for application. Firstly, the semantic and geometric information can both be considered to ensure that invalid measurements are recognized. Meanwhile, the semantic map constructed by SLAM systems can provide richer decision-making information for the navigation system.
On the other hand, although the methods mentioned above can improve the robustness of the system in dynamic scenes, semantic SLAM systems such as refs. [Reference Chen, Wang, Wang, Deng, Wang and Zhang12, Reference Chen, Milioto, Palazzolo, Giguere, Behley and Stachniss13] focus more on extracting and processing background semantic information. They cannot stably track and represent dynamic objects in the map coordinate, which is also necessary for many actual robot systems. In this work, we will solve this problem by using a lidar sensor that provides highly accurate point cloud data. Noting that moving objects are often only observed from a local perspective, the geometric point cloud constraints may sometimes fail to estimate the 6-DOF object motion. We further consider using the information obtained from the perception module to balance the accuracy and robustness of object tracking.
Based on the above analysis, a least-square estimator is proposed that takes into account both semantic and geometric information to perform reliable multi-object tracking (SGF-MOT). Combined with the estimation results of ego odometry, the absolute localization for each object can be calculated. The mapping module uses the absolute trajectory tracking list for dynamic semantic object detection. Then, the accumulated error of ego and object odometry is eliminated. Finally, we realize the construction of a 4D scene map. Figure 1 shows the scene map created by the MLO system. The main contributions of this paper are as follows:
-
A complete multi-object lidar odometry system (MLO) can provide the absolute localization of both robot and semantic objects and build a 4D scene map (the robot, semantic object localization, and long-term static map).
-
A least-square estimator considering the bounding box planes and the geometric point cloud is used for object state updating in the multi-object tracking (MOT) module. The semantic bounding boxes ensure the correct optimization direction. The relative motion model eliminates the point cloud distortion caused by robot and object motion. Using point clouds with direct measurement further improves the estimation accuracy.
-
A dynamic object detection method based on the absolute trajectory tracking list that can identify slow-moving semantic objects.
The rest of this paper is structured as follows. First, in Section 2, we discuss related works. Then, the proposed MLO system is described in Section 3. The experimental setup, results, and discussion will be presented in Section 4. Finally, Section 5 is the conclusion.

Figure 1. The proposed MLO system testing on sequence 0926-0013 in the KITTI-raw dataset. The upper part of the picture shows the point cloud map, tracking trajectories of the robot and semantic objects generated by the MLO system. The lower part of the picture (for visualization only) gives the semantic bounding box and absolute motion speed of each object successfully tracked in the synchronized image.
2. Related works
2.1. MOT
For the MOT method based on point cloud data, object recognition and tracking are the two main steps of most solutions. In the beginning, traditional methods focused on object extraction from spatial distribution information of point clouds. Then, object tracking is realized by constructing geometric error constraints and a corresponding estimator. Moosmann et al. [Reference Moosmann and Fraichard6] proposed a local convexity criterion for geometric object detection. Then, the MOT task was implemented by the point-to-plane ICP [Reference Chen and Medioni15] algorithm. Dewan et al. [Reference Dewan, Caselitz, Tipaldi and Burgard16] used the RANSAC [Reference Fischler and Bolles17] algorithm to compute the motion model sequentially. Then, a Bayesian approach was proposed for matching the object point cloud with the corresponding motion model. Ferri et al. [Reference Dewan, Caselitz, Tipaldi and Burgard18] proposed a rigid scene flow algorithm for tracking non-rigid objects that can also handle the pedestrian. Sualeh et al. [Reference Sualeh and Kim19] used a cluster point cloud for fitting 3D bounding boxes (3D-BB). The boxes were tracked by the Kalman filter [Reference Kalman20] algorithm.
Recently, the learning-based recognition method on point clouds has brought new solutions to the MOT problem. They can provide richer and more stable recognition information, such as the bounding box with object category and motion direction. Weng et al. [Reference Weng, Wang, Held and Kitani21] detected semantic objects by Point-RCNN [Reference Shi, Wang and Li22] network model and tracked the 3D-BB with a Kalman filter. Kim et al. [Reference Kim, Ošep and Leal-Taixé23] used 2D/3D-BB detected in image and point clouds for filter tracking, achieving better tracking accuracy. Wang et al. [Reference Wang, Cai, Wang and Liu24] and Huang et al. [Reference Huang and Hao25] designed an end-to-end MOT framework using different deep-learning models to complete object detection and data association tasks.
In summary, optimization-based tracking methods that rely on the geometric constraints of point clouds require a reliable initial guess. If the estimator’s initial value is poor, many point-level data associations may provide the wrong direction at the early stage of the calculation. Extracting bounding boxes from the point cloud (directly fitting or using a network model) and tracking them by the filter-based methods [Reference Llamazares, Molinos and Ocaña26] is more stable but sacrifices high-precision measured point clouds. In our SGF-MOT module, we use semantic bounding box planes and geometric point cloud distributions simultaneously in a least-squares estimator, achieving a better balance between tracking accuracy and robustness.
2.2. Dynamic aware 3D lidar SLAM
At present, 3D lidar SLAM systems are mainly divided into two categories: feature-based and matching-based. Zhang et al. [Reference Zhang and Singh1] and Shan et al. [Reference Shan and Englot2] extracted stable environment structure features (edge and surface) based on scan line roughness for reliable robot localization and lidar mapping. Meanwhile, Shan et al. [Reference Shan and Englot2] also considered ground constraints to improve the accuracy and efficiency of estimation. Liu et al. [Reference Liu and Zhang27] proposed a novel lidar bundle adjustment (BA) [Reference Triggs, McLauchlan, Hartley and Fitzgibbon28] method, which depends only on the robot poses. The feature landmarks and robot poses can be optimized for high-precision lidar mapping by minimizing the eigenvalue. In the matching-based method, Behley et al. [Reference Behley and Stachniss4] used surfel to model the environment and designed a projection data association method for ego localization. Dellenbach et al. [Reference Dellenbach, Deschaud, Jacquet and Goulette29] proposed a continuous-time ICP algorithm for lidar odometry estimation. Their method considered both the constraint of inter-frame discontinuity and the correction of in-scan motion distortion. The above systems rely on the assumption of the rigid scene and cannot work stably in a highly dynamic scene.
To solve the above problems, some studies proposed geometric methods such as background model [Reference Park, Cho and Shin7], local convexity [Reference Moosmann and Fraichard6], and point cloud clustering [Reference Deschaud5] to detect and eliminate unreliable information. Meanwhile, with the development of deep-learning technology, some semantic-based lidar SLAM can also process dynamic objects within the field of view. Pfreundschuh et al. [Reference Pfreundschuh, Hendrikx, Reijgwart, Dubé, Siegwart and Cramariuc10] designed a method to automatically label dynamic object points when the 3D-MinNet detection model was trained. The static point cloud after detection will be input into the LOAM [Reference Zhang and Singh1] framework to enable reliable mapping. Sualeh et al. [Reference Liu, Sun and Liu30] further considered the space-time constraints of sequence frames when training the dynamic object detection model. Both refs. [Reference Chen, Wang, Wang, Deng, Wang and Zhang12] and [Reference Chen, Milioto, Palazzolo, Giguere, Behley and Stachniss13] using semantic segmentation networks realize semantic scene mapping. In addition, they detect dynamic objects through point-by-point checks from the object point cloud.
In contrast to these approaches, our proposed system, MLO, integrates the results of robust ego localization and the SGF-MOT module to achieve accurate and reliable localization of instance objects in the map coordinate. Additionally, our system uses an absolute trajectory tracking list to detect dynamic objects in the scene, creating a 4D scene map that includes both robot and semantic object positions as well as the static environment.
2.3. Robust SLAM with multi-sensor fusion
To overcome the shortcomings of a single sensor, some researchers are considering combining two or three types of sensors to improve the adaptability of SLAM systems in complex scenarios. Unlike lidar, the camera can provide images with rich color information. Thus, visual SLAM has also received widespread attention. According to the different front-end methods, visual SLAM can mainly be divided into feature-based methods [Reference Klein and Murray31, Reference Pire, Baravalle, D’alessandro and Civera32], semi-direct methods [Reference Forster, Pizzoli and Scaramuzza33], or direct methods [Reference Newcombe, Lovegrove and Davison34, Reference Engel, Schöps and Cremers35]. Among them, the feature-based method is more robust to illumination and rotational motion, while the direct method has more application potential because it can construct dense or semi-dense maps. In the field of visual-lidar fusion SLAM, ref. [Reference Zhang and Singh36] used a monocular camera with higher frequencies for initial pose estimation, providing more accurate initial values for lidar odometry and constructing point cloud maps. Meanwhile, the author also used point cloud information to solve the scale uncertainty problem in monocular visual odometry. In refs. [Reference Shin, Park and Kim37, Reference Huang, Ma, Mu, Fu and Hu38], depth information measured by lidar was integrated into the feature-based [Reference Mur-Artal, Montiel and Tardos3] or direct [Reference Engel, Koltun and Cremers39] visual SLAM framework for 3D pixel or feature landmark initialization. The system further improves the local mapping accuracy in the back-end by the BA algorithm.
The Inertial Measurement Unit (IMU), as an internal high-frequency sensor that is not affected by the external environment, has significant advantages in dealing with problems such as intense motion and complex scenes. In refs. [Reference Zhang and Singh1, Reference Shan, Englot, Meyers, Wang, Ratti and Rus40], the IMU measurement was used to eliminate the motion distortion of lidar point clouds and provided reasonable initial values for the lidar odometry. In addition, ref. [Reference Shan, Englot, Meyers, Wang, Ratti and Rus40] further used GPS to reduce the accumulative error generated by lidar odometry. Refs. [Reference Campos, Elvira, Rodríguez, Montiel and Tardós41, Reference Leutenegger, Furgale, Rabaud, Chli, Konolige and Siegwart42] tracked feature points extracted from images and combined IMU pre-integration technology to construct the tightly coupled visual-inertial SLAM system. They can achieve high-precision sparse feature mapping through the BA algorithm. Recently, ref. [Reference Shan, Englot, Ratti and Rus43] proposed a visual-inertial, lidar-inertial odometry fusion system, which can effectively work when either odometry fails and cope with textureless scenes such as white walls.
Undoubtedly, by combining multiple sensors, the fusion system can utilize richer measurement information to enhance the robustness of robots working in complex motion states or low-texture scenes. However, when the fusion system operates without targeted images or point cloud data processing in a dynamic environment, dynamic measurement information can still lead to significant estimation errors in the localization and mapping processes. In this paper, we compare the proposed semantic lidar odometry (MLO) with other advanced multi-sensor fusion SLAM frameworks to fully analyze the advantages and disadvantages of the MLO system in complex dynamic scenarios.

Figure 2. The proposed MLO system framework. The orange box is the key part of this paper; it includes the semantic-geometric fusion multi-object tracking method (SGF-MOT), which will be discussed in detail. A 4D scene mapping module is also introduced for maintaining the long-term static map and movable object map separately, which can be used to further navigation applications.
3. Method
The MLO system proposed in this paper can be divided into three modules: multi-task fusion perception, semantic lidar odometry, and 4D scene mapping. Figure 2 shows the flowchart of the MLO system. Firstly, the ground and objects are detected and refined by information fusion. Then, the proposed SGF-MOT tracker is integrated into the odometry module to achieve robust and accurate object tracking. After dynamic object detection, the mapping module uses both static objects and environment feature sets [Reference Zhang and Singh1] to eliminate accumulated errors.
3.1. Notation definition
The notation and coordinates used in this paper are defined as follows: In the odometry coordinate
 $o$
and frame
$o$
and frame
 $ i$
, the robot pose is
$ i$
, the robot pose is
 ${\textbf{T}}_{ol}^i \in{\rm{SE}}(3)$
. Meanwhile, the observed semantic object has pose
${\textbf{T}}_{ol}^i \in{\rm{SE}}(3)$
. Meanwhile, the observed semantic object has pose
 ${\textbf{T}}_{ot}^i \in{\rm{SE}}(3)$
. In the mapping module, the corrected robot pose in the map coordinate
${\textbf{T}}_{ot}^i \in{\rm{SE}}(3)$
. In the mapping module, the corrected robot pose in the map coordinate
 $m$
is
$m$
is
 ${\textbf{T}}_{ml}^i \in{\rm{SE}}(3)$
, and the correction matrix which transforms the object from the odometry coordinate
${\textbf{T}}_{ml}^i \in{\rm{SE}}(3)$
, and the correction matrix which transforms the object from the odometry coordinate
 $ o$
to the map coordinate
$ o$
to the map coordinate
 $m$
is
$m$
is
 ${\textbf{T}}_{mo}^{i} \in{\rm{SE}}(3)$
.
${\textbf{T}}_{mo}^{i} \in{\rm{SE}}(3)$
.
3.2. Multi-task fusion perception
For point cloud
 ${{\boldsymbol{\Phi}}^i}$
in frame i, we run the parallel object detection algorithm and ground feature extraction algorithm to obtain the original ground and object point cloud. Then, we detect and eliminate the intersection point in the ground feature set and foreground object by the marked labels and perform background feature extraction. Figure 3 shows the detection results of the multi-task fusion perception module.
${{\boldsymbol{\Phi}}^i}$
in frame i, we run the parallel object detection algorithm and ground feature extraction algorithm to obtain the original ground and object point cloud. Then, we detect and eliminate the intersection point in the ground feature set and foreground object by the marked labels and perform background feature extraction. Figure 3 shows the detection results of the multi-task fusion perception module.

Figure 3. The multi-task fusion perception module testing on sequence 0926-0056 in the KITTI-raw dataset. The semantic object point clouds are composed of pink points. Yellow points form the ground feature set. Green and red points form the background edge and surface feature sets, respectively. The image projection results with the same timestamp are used for visualization only.
3.2.1. Ground feature extraction
First, we adjust ground parameters in the point cloud using the iterative PCA algorithm proposed in ref. [Reference Zermas, Izzat and Papanikolopoulos44] and mark the corresponding points near the ground in the point cloud
 ${\boldsymbol{\Phi}}_g^i$
(1: ground point, 0: background point).
${\boldsymbol{\Phi}}_g^i$
(1: ground point, 0: background point).
Assume
 ${t^{i - 1}}$
and
${t^{i - 1}}$
and
 ${t^{i}}$
are the beginning and end time of current frame
${t^{i}}$
are the beginning and end time of current frame
 $i$
respectively. Meanwhile, the sampling time of the k-th raw point
$i$
respectively. Meanwhile, the sampling time of the k-th raw point
 ${}^l{{\textbf{p}}_{i,k}}$
in the lidar coordinate
${}^l{{\textbf{p}}_{i,k}}$
in the lidar coordinate
 $ l$
is
$ l$
is
 ${t_k}$
, and the relative timestamp
${t_k}$
, and the relative timestamp
 ${}^r{t_k}$
used to correct motion distortion can be calculated as follows:
${}^r{t_k}$
used to correct motion distortion can be calculated as follows:
 \begin{align}{}^r{t_k} = \frac{{{t_k} -{t^i}}}{{{t^{i - 1}} -{t^i}}} \end{align}
\begin{align}{}^r{t_k} = \frac{{{t_k} -{t^i}}}{{{t^{i - 1}} -{t^i}}} \end{align}
Then, the current point cloud is uniformly segmented according to the scan line. Through the point-by-point verification of ground markings in the point cloud
 ${\boldsymbol{\Phi}}_g^i$
, it is possible to record whether each segment contains the ground point or background point labels. For segments containing ground or background points, the segment head and tail point ID pairs are stored in the ground container
${\boldsymbol{\Phi}}_g^i$
, it is possible to record whether each segment contains the ground point or background point labels. For segments containing ground or background points, the segment head and tail point ID pairs are stored in the ground container
 ${{\textbf{V}}_g}$
or background container
${{\textbf{V}}_g}$
or background container
 ${{\textbf{V}}_b}$
, respectively.
${{\textbf{V}}_b}$
, respectively.
Based on the calculated roughness (the calculation formula can be found in ref. [Reference Zhang and Singh1]) and the segmented point ID pairs contained in the ground container
 ${{\textbf{V}}_g}$
, ground feature set
${{\textbf{V}}_g}$
, ground feature set
 ${\boldsymbol{\chi }}_f^i$
can be extracted from point cloud segments containing ground points. The roughness prior
${\boldsymbol{\chi }}_f^i$
can be extracted from point cloud segments containing ground points. The roughness prior
 ${R_{a}}$
used for subsequent inspection of background surface feature points is obtained as follows:
${R_{a}}$
used for subsequent inspection of background surface feature points is obtained as follows:
 \begin{align}{R_{a}} = \sum \limits _{o = 1}^N c_o\Big/N_c \end{align}
\begin{align}{R_{a}} = \sum \limits _{o = 1}^N c_o\Big/N_c \end{align}
where
 ${c_o}$
is the
${c_o}$
is the
 $o$
-th ground point roughness.
$o$
-th ground point roughness.
 ${\boldsymbol{\chi }}_c^i$
represents the candidate ground feature set obtained by downsampling, and
${\boldsymbol{\chi }}_c^i$
represents the candidate ground feature set obtained by downsampling, and
 ${N_c}$
is the corresponding number of ground points.
${N_c}$
is the corresponding number of ground points.
For non-ground point cloud segments that are searched by ID pairs in the background container
 ${{\textbf{V}}_b}$
, only point roughness is calculated and sorted here. After that, the information fusion module will neatly select the background feature sets.
${{\textbf{V}}_b}$
, only point roughness is calculated and sorted here. After that, the information fusion module will neatly select the background feature sets.
3.2.2. Semantic object detection
To identify the semantic objects and their corresponding 3D-BB in the point cloud, we use 3DSSD [Reference Yang, Sun, Liu and Jia45], a point-based single-stage object detection model, to perform these tasks. Assuming that k-th 3D-BB in frame
 $ i$
is:
$ i$
is:
 \begin{align}{{\boldsymbol{\tau }}^{k,i}} ={\left [{{x^{k,i}},{y^{k,i}},{z^{k,i}},{l^{k,i}},{w^{k,i}},{h^{k,i}},ya{w^{k,i}}} \right ]^T} \end{align}
\begin{align}{{\boldsymbol{\tau }}^{k,i}} ={\left [{{x^{k,i}},{y^{k,i}},{z^{k,i}},{l^{k,i}},{w^{k,i}},{h^{k,i}},ya{w^{k,i}}} \right ]^T} \end{align}
where the object position in the lidar coordinate
 $ l$
is
$ l$
is
 $ \left ({x,y,z} \right )$
. The length, width, and height of 3D-BB are
$ \left ({x,y,z} \right )$
. The length, width, and height of 3D-BB are
 $ \left ({l,w,h} \right )$
, and
$ \left ({l,w,h} \right )$
, and
 $ yaw$
is the yaw angle for the object in the lidar coordinate
$ yaw$
is the yaw angle for the object in the lidar coordinate
 $ l$
. Assuming
$ l$
. Assuming
 ${{\boldsymbol{\gamma }}^{k,i}}$
denotes the object point cloud enclosed by 3D-BB and each 3D point is marked with an independent object ID in
${{\boldsymbol{\gamma }}^{k,i}}$
denotes the object point cloud enclosed by 3D-BB and each 3D point is marked with an independent object ID in
 ${\boldsymbol{\Phi}}_s^i$
. Object semantic confidence is represented as
${\boldsymbol{\Phi}}_s^i$
. Object semantic confidence is represented as
 ${\mu ^{k,i}}$
.
${\mu ^{k,i}}$
.
3.2.3. Information fusion
The 3D-BB, obtained by the semantic detection module, usually encloses both object and ground points. Meanwhile, the ground feature set computed by Section 3.2.1 may also have points belonging to objects. If the object is in motion, the static ground points in the object point cloud and the moving object points in the ground feature set will lead to errors in the pose estimation of the object and the robot, respectively. Therefore, we need to eliminate ambiguous intersection information through a mutual correction step.
Specifically, the object points in the ground feature sets
 ${\boldsymbol{\chi }}_f^i$
and
${\boldsymbol{\chi }}_f^i$
and
 ${\boldsymbol{\chi }}_c^i$
are deleted by the marked object ID in
${\boldsymbol{\chi }}_c^i$
are deleted by the marked object ID in
 ${\boldsymbol{\Phi}}_s^i$
. The ground point in object point cloud
${\boldsymbol{\Phi}}_s^i$
. The ground point in object point cloud
 ${{\boldsymbol{\gamma }}^{k,i}}$
is removed through the label in
${{\boldsymbol{\gamma }}^{k,i}}$
is removed through the label in
 ${\boldsymbol{\Phi}}_g^i$
. This ambiguous information is not considered in the subsequent SLAM and MOT tasks.
${\boldsymbol{\Phi}}_g^i$
. This ambiguous information is not considered in the subsequent SLAM and MOT tasks.
Based on the ID pairs contained in
 ${{\textbf{V}}_b}$
and computed point roughness, we perform two feature extractions: The candidate object edge feature set
${{\textbf{V}}_b}$
and computed point roughness, we perform two feature extractions: The candidate object edge feature set
 ${\boldsymbol{\gamma }}_c^{k,i}$
is extracted from the point clouds belonging to objects, which is used in the mapping module to eliminate accumulated errors. Subsequently, the background edge feature set
${\boldsymbol{\gamma }}_c^{k,i}$
is extracted from the point clouds belonging to objects, which is used in the mapping module to eliminate accumulated errors. Subsequently, the background edge feature set
 ${\boldsymbol{\psi }}_f^i$
, surface feature set
${\boldsymbol{\psi }}_f^i$
, surface feature set
 ${\boldsymbol{\zeta }}_f^i$
, and the corresponding candidate sets
${\boldsymbol{\zeta }}_f^i$
, and the corresponding candidate sets
 ${\boldsymbol{\psi }}_c^i$
,
${\boldsymbol{\psi }}_c^i$
,
 ${\boldsymbol{\zeta }}_c^i$
are extracted from the non-semantic and non-ground point clouds, and they will participate in both localization and mapping modules.
${\boldsymbol{\zeta }}_c^i$
are extracted from the non-semantic and non-ground point clouds, and they will participate in both localization and mapping modules.
Finally, we define the point-to-line error term
 ${\textbf{e}}_{{e_k}}$
and the point-to-surface error term
${\textbf{e}}_{{e_k}}$
and the point-to-surface error term
 ${\textbf{e}}_{{s_k}}$
in the lidar coordinate
${\textbf{e}}_{{s_k}}$
in the lidar coordinate
 $ l$
, which are used for ego pose estimation in Section 3.3.1:
$ l$
, which are used for ego pose estimation in Section 3.3.1:
 \begin{align} {{\textbf{e}}_{{e_k}}} = \frac{{\left |{({}^l{\textbf{p}}_{i,k}^e -{}^l\bar{\textbf{p}}_{i - 1,m}^e) \times ({}^l{\textbf{p}}_{i,k}^e -{}^l\bar{\textbf{p}}_{i - 1,n}^e)} \right |}}{{\left |{{}^l\bar{\textbf{p}}_{i - 1,m}^e -{}^l\bar{\textbf{p}}_{i - 1,n}^e} \right |}} \end{align}
\begin{align} {{\textbf{e}}_{{e_k}}} = \frac{{\left |{({}^l{\textbf{p}}_{i,k}^e -{}^l\bar{\textbf{p}}_{i - 1,m}^e) \times ({}^l{\textbf{p}}_{i,k}^e -{}^l\bar{\textbf{p}}_{i - 1,n}^e)} \right |}}{{\left |{{}^l\bar{\textbf{p}}_{i - 1,m}^e -{}^l\bar{\textbf{p}}_{i - 1,n}^e} \right |}} \end{align}
 \begin{align} {{\textbf{e}}_{{s_k}}} = \frac{{\left | \begin{array}{c} \left ({{}^l{\textbf{p}}_{i,k}^s -{}^l\bar{\textbf{p}}_{i - 1,m}^s} \right )\\[5pt] ({}^l\bar{\textbf{p}}_{i - 1,m}^s -{}^l\bar{\textbf{p}}_{i - 1,n}^s) \times ({}^l\bar{\textbf{p}}_{i - 1,m}^s -{}^l\bar{\textbf{p}}_{i - 1,o}^s) \end{array} \right |}}{{\left |{({}^l\bar{\textbf{p}}_{i - 1,m}^s -{}^l\bar{\textbf{p}}_{i - 1,n}^s) \times ({}^l\bar{\textbf{p}}_{i - 1,m}^s -{}^l\bar{\textbf{p}}_{i - 1,o}^s)} \right |}} \end{align}
\begin{align} {{\textbf{e}}_{{s_k}}} = \frac{{\left | \begin{array}{c} \left ({{}^l{\textbf{p}}_{i,k}^s -{}^l\bar{\textbf{p}}_{i - 1,m}^s} \right )\\[5pt] ({}^l\bar{\textbf{p}}_{i - 1,m}^s -{}^l\bar{\textbf{p}}_{i - 1,n}^s) \times ({}^l\bar{\textbf{p}}_{i - 1,m}^s -{}^l\bar{\textbf{p}}_{i - 1,o}^s) \end{array} \right |}}{{\left |{({}^l\bar{\textbf{p}}_{i - 1,m}^s -{}^l\bar{\textbf{p}}_{i - 1,n}^s) \times ({}^l\bar{\textbf{p}}_{i - 1,m}^s -{}^l\bar{\textbf{p}}_{i - 1,o}^s)} \right |}} \end{align}
where
 $ k$
represents the edge or surface point indices in the current frame.
$ k$
represents the edge or surface point indices in the current frame.
 $ m,n,o$
represent the point indices of matching edge line or planar patch in the last frame. For the raw edge point
$ m,n,o$
represent the point indices of matching edge line or planar patch in the last frame. For the raw edge point
 ${}^l{\textbf{p}}_{i,k}^e$
in the set
${}^l{\textbf{p}}_{i,k}^e$
in the set
 ${\boldsymbol{\psi }}_f^i$
,
${\boldsymbol{\psi }}_f^i$
,
 ${}^l\bar{\textbf{p}}_{i - 1,m}^e$
and
${}^l\bar{\textbf{p}}_{i - 1,m}^e$
and
 ${}^l\bar{\textbf{p}}_{i - 1,n}^e$
are the matching points in the set
${}^l\bar{\textbf{p}}_{i - 1,n}^e$
are the matching points in the set
 ${\bar{\boldsymbol{\psi }}}_c^{i - 1}$
that make up the edge line in the last frame without motion distortion. Similarly,
${\bar{\boldsymbol{\psi }}}_c^{i - 1}$
that make up the edge line in the last frame without motion distortion. Similarly,
 ${}^l{\textbf{p}}_{i,k}^s$
is the raw surface point in the set
${}^l{\textbf{p}}_{i,k}^s$
is the raw surface point in the set
 ${\boldsymbol{\zeta }}_f^i$
.
${\boldsymbol{\zeta }}_f^i$
.
 ${}^l\bar{\textbf{p}}_{i - 1,m}^s$
,
${}^l\bar{\textbf{p}}_{i - 1,m}^s$
,
 ${}^l\bar{\textbf{p}}_{i - 1,n}^s$
, and
${}^l\bar{\textbf{p}}_{i - 1,n}^s$
, and
 ${}^l\bar{\textbf{p}}_{i - 1,o}^s$
are the points that consist of the corresponding planar patch in the set
${}^l\bar{\textbf{p}}_{i - 1,o}^s$
are the points that consist of the corresponding planar patch in the set
 ${\bar{\boldsymbol{\chi }}}_c^{i - 1}$
or
${\bar{\boldsymbol{\chi }}}_c^{i - 1}$
or
 ${\bar{\boldsymbol{\zeta }}}_c^{i - 1}$
.
${\bar{\boldsymbol{\zeta }}}_c^{i - 1}$
.
3.3. Semantic lidar odometry
The semantic lidar odometry module simultaneously estimates the absolute motion increment of the robot and the relative motion increment of the semantic object. Then, the absolute motion of each object in the odometry coordinate
 $ o$
can be calculated. Figure 4 shows the transformation of objects and the robot in the odometry coordinate.
$ o$
can be calculated. Figure 4 shows the transformation of objects and the robot in the odometry coordinate.

Figure 4. Notation and coordinates. White solid cuboids and dashed cuboids are the detected objects and corresponding 3D-BB. Colored cylinders are the robot with lidar. Robot and object pose in the odometry coordinate are the solid lines. Object motion increments in the body-fixed coordinate are the dashed lines. Red parallelograms and cubes are the plane features generated by 3D-BB and matched voxels. Green parallelogram and dot are the semantic plane feature and geometric object point in current frame.
3.3.1. Robust ego odometry
When the semantic object detection module makes the missing detection problem, the accuracy of the ego-motion estimation will be reduced by some unknown moving object points included in the ground or background feature sets. Accordingly, we solve this problem by using Algorithm 1 to perform a geometric consistency checking on current feature sets (
 ${\boldsymbol{\chi }}_f^i$
,
${\boldsymbol{\chi }}_f^i$
,
 ${\boldsymbol{\psi }}_f^i$
,
${\boldsymbol{\psi }}_f^i$
,
 ${\boldsymbol{\zeta }}_f^i$
). The checked feature sets are defined as (
${\boldsymbol{\zeta }}_f^i$
). The checked feature sets are defined as (
 ${\tilde{\boldsymbol{\chi }}}_f^i$
,
${\tilde{\boldsymbol{\chi }}}_f^i$
,
 ${\tilde{\boldsymbol{\psi }}}_f^i$
,
${\tilde{\boldsymbol{\psi }}}_f^i$
,
 ${\tilde{\boldsymbol{\zeta }}}_f^i$
).
${\tilde{\boldsymbol{\zeta }}}_f^i$
).
Algorithm 1. Geometric consistency feature checking.

Considering the different degrees of freedom (DOF) constraints provided by the ground and background feature sets in estimating the robot pose and the computational efficiency problem, a two-step algorithm proposed in ref. [Reference Shan and Englot2] is used to estimate the ego-motion. First, we compute 3-DOF increment
 $ [{t_z},{\theta _{roll}},{\theta _{pitch}}]$
by the checked ground feature set
$ [{t_z},{\theta _{roll}},{\theta _{pitch}}]$
by the checked ground feature set
 ${\tilde{\boldsymbol{\chi }}}_f^i$
and the candidate feature set
${\tilde{\boldsymbol{\chi }}}_f^i$
and the candidate feature set
 ${\bar{\boldsymbol{\chi }}}_c^{i - 1}$
that corrected the motion distortion. Then, another 3-DOF increment
${\bar{\boldsymbol{\chi }}}_c^{i - 1}$
that corrected the motion distortion. Then, another 3-DOF increment
 $ [{t_x},{t_y},{\theta _{yaw}}]$
is estimated by surface feature points in
$ [{t_x},{t_y},{\theta _{yaw}}]$
is estimated by surface feature points in
 ${\tilde{\boldsymbol{\zeta }}}_f^i$
with smaller roughness than
${\tilde{\boldsymbol{\zeta }}}_f^i$
with smaller roughness than
 ${R_{a}}$
, edge feature set
${R_{a}}$
, edge feature set
 ${\tilde{\boldsymbol{\psi }}}_f^i$
, and corresponding candidate sets. Finally, we accumulate the 6-DOF increment
${\tilde{\boldsymbol{\psi }}}_f^i$
, and corresponding candidate sets. Finally, we accumulate the 6-DOF increment
 ${}_l^{i - 1}{{\boldsymbol{\delta }}^i} = [{t_x},{t_y},{t_z},{\theta _{roll}},{\theta _{pitch}},{\theta _{yaw}}]$
to compute the robot pose
${}_l^{i - 1}{{\boldsymbol{\delta }}^i} = [{t_x},{t_y},{t_z},{\theta _{roll}},{\theta _{pitch}},{\theta _{yaw}}]$
to compute the robot pose
 ${\textbf{T}}_{ol}^i$
in the odometry coordinate
${\textbf{T}}_{ol}^i$
in the odometry coordinate
 $ o$
.
$ o$
.
3.3.2. Semantic-geometric fusion MOT
To track semantic objects robustly and accurately, a least-squares estimator combining semantic box planes and geometric object points is designed for the MOT module. Before entering the increment estimation process, we use the Kuhn-Munkres [Reference Kuhn46] algorithm to obtain the object data association between frames.
Specifically, we need to construct the association matrix using some error functions that can evaluate the similarity of the object between frames: (1) The position error term
 ${{\textbf{e}}_p}$
is computed by the distance between the object’s predicted position which is inferred by the last motion model and object’s detection position. (2) The yaw angle increment of the object forms the direction error term
${{\textbf{e}}_p}$
is computed by the distance between the object’s predicted position which is inferred by the last motion model and object’s detection position. (2) The yaw angle increment of the object forms the direction error term
 ${{\textbf{e}}_d}$
. (3) The difference in the semantic 3D-BB size between the objects constructs the scale error term
${{\textbf{e}}_d}$
. (3) The difference in the semantic 3D-BB size between the objects constructs the scale error term
 ${{\textbf{e}}_s}$
. Further details on error calculation can be found in ref. [47].
${{\textbf{e}}_s}$
. Further details on error calculation can be found in ref. [47].
For objects that are tracked in the last frame but no matching relationship is currently found, we use the last calculated motion model to infer their positions in the subsequent two frames. If a successful match is still not found, they are removed.
Considering that the object point cloud
 ${{\boldsymbol{\gamma }}^{i}}$
(object ID
${{\boldsymbol{\gamma }}^{i}}$
(object ID
 $ k$
is omitted) obtained by direct measurement has motion distortion when the robot and object are in motion, we use the VG-ICP [Reference Koide, Yokozuka, Oishi and Banno48] algorithm and the relative motion model based on linear interpolation to construct the geometric cost function.
$ k$
is omitted) obtained by direct measurement has motion distortion when the robot and object are in motion, we use the VG-ICP [Reference Koide, Yokozuka, Oishi and Banno48] algorithm and the relative motion model based on linear interpolation to construct the geometric cost function.
Assuming the
 $j$
-th raw object point in the lidar coordinate
$j$
-th raw object point in the lidar coordinate
 $ l$
is
$ l$
is
 ${}^l{\textbf{p}}_{i,j}^g$
, and it has a relative timestamp
${}^l{\textbf{p}}_{i,j}^g$
, and it has a relative timestamp
 ${}^r{t_j}$
.
${}^r{t_j}$
.
 ${}_l^{i - 1}{{\textbf{H}}^i} \in{\rm{SE}}(3)$
is the transformation between interval
${}_l^{i - 1}{{\textbf{H}}^i} \in{\rm{SE}}(3)$
is the transformation between interval
 $ \left [{{t^{i - 1}},{t^i}} \right ]$
. Then, the distortion-corrected transformation
$ \left [{{t^{i - 1}},{t^i}} \right ]$
. Then, the distortion-corrected transformation
 ${}_l^{i - 1}{\textbf{H}}_j^i$
for each raw object point can be calculated:
${}_l^{i - 1}{\textbf{H}}_j^i$
for each raw object point can be calculated:
 \begin{align}{}_l^{i - 1}{\textbf{H}}_j^i ={}^r{t_j}{{\textbf{H}}^i} \end{align}
\begin{align}{}_l^{i - 1}{\textbf{H}}_j^i ={}^r{t_j}{{\textbf{H}}^i} \end{align}
We use
 ${}_l^{i - 1}{{\textbf{R}}^i}$
and
${}_l^{i - 1}{{\textbf{R}}^i}$
and
 ${}_l^{i - 1}{{\textbf{t}}^i}$
to represent the rotational and translational components of the increment
${}_l^{i - 1}{{\textbf{t}}^i}$
to represent the rotational and translational components of the increment
 ${}_l^{i - 1}{{\textbf{H}}^i}$
. The geometric error term
${}_l^{i - 1}{{\textbf{H}}^i}$
. The geometric error term
 ${{\textbf{e}}_{g_j}}$
from the distribution to the multi-distribution can be defined as follows:
${{\textbf{e}}_{g_j}}$
from the distribution to the multi-distribution can be defined as follows:
 \begin{align}{{\textbf{e}}_{{g_j}}} = \frac{{\sum{{}^l\bar{\textbf{p}}_{i - 1,m}^g} }}{{{N_j}}} -{}_l^{i - 1}{\textbf{H}}_j^i{}^l{\textbf{p}}_{i,j}^g \end{align}
\begin{align}{{\textbf{e}}_{{g_j}}} = \frac{{\sum{{}^l\bar{\textbf{p}}_{i - 1,m}^g} }}{{{N_j}}} -{}_l^{i - 1}{\textbf{H}}_j^i{}^l{\textbf{p}}_{i,j}^g \end{align}
For the matched voxel
 ${}^l\bar{\textbf{v}}_{i - 1}^g$
of the current object point
${}^l\bar{\textbf{v}}_{i - 1}^g$
of the current object point
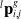 ${}^l{\textbf{p}}_{i,j}^g$
at the end time of the last frame, it encloses
${}^l{\textbf{p}}_{i,j}^g$
at the end time of the last frame, it encloses
 ${N_j}$
object points
${N_j}$
object points
 ${}^l\bar{\textbf{p}}_{i - 1,m}^g$
that have corrected the motion distortion. The covariance matrix
${}^l\bar{\textbf{p}}_{i - 1,m}^g$
that have corrected the motion distortion. The covariance matrix
 ${{\boldsymbol{\Omega}}_j}$
corresponding to the error term
${{\boldsymbol{\Omega}}_j}$
corresponding to the error term
 ${{\textbf{e}}_{g_j}}$
is as follows:
${{\textbf{e}}_{g_j}}$
is as follows:
 \begin{align}{{\boldsymbol{\Omega}}_j} = \frac{{\sum{C^g_{i - 1,m}} }}{{{N_j}}} -{}_l^{i - 1}{\textbf{H}}_j^i C_{i,j}^g{}_l^{i - 1}{\textbf{H}}{_j^{i }}^T \end{align}
\begin{align}{{\boldsymbol{\Omega}}_j} = \frac{{\sum{C^g_{i - 1,m}} }}{{{N_j}}} -{}_l^{i - 1}{\textbf{H}}_j^i C_{i,j}^g{}_l^{i - 1}{\textbf{H}}{_j^{i }}^T \end{align}
 $ C_{i - 1,m}^g$
and
$ C_{i - 1,m}^g$
and
 $ C_{i,j}^g$
denote the covariance matrix. They describe the surrounding shape distribution of the point in the matched voxel and point
$ C_{i,j}^g$
denote the covariance matrix. They describe the surrounding shape distribution of the point in the matched voxel and point
 ${}^l{\textbf{p}}_{i,j}^g$
.
${}^l{\textbf{p}}_{i,j}^g$
.
Note that objects detected in a single frame always have less constrained information. Meanwhile, the inaccurate initial value of the estimator at the beginning of the optimization may also lead to poor matchings. Eq. (7) sometimes fails to constrain the 6-DOF motion estimation. Therefore, while using geometric constraints of the point cloud, this work also introduces semantic constraints on increment estimation to ensure the correct direction of convergence.
Specifically, we model a 3D-BB
 ${{\boldsymbol{\tau }}^i}$
as a cuboid containing six planes. Each plane is represented by the normal vector
${{\boldsymbol{\tau }}^i}$
as a cuboid containing six planes. Each plane is represented by the normal vector
 $\textbf{n}$
(
$\textbf{n}$
(
 ${\left \|{\textbf{n}} \right \|_2} = 1$
) and the distance
${\left \|{\textbf{n}} \right \|_2} = 1$
) and the distance
 $d$
from the origin to the plane, that is
$d$
from the origin to the plane, that is
 ${\boldsymbol{\pi }} = [{\textbf{n}},d]$
. Unlike the geometric point cloud error with iterative matching for estimation, the matching relationships for 3D-BB planes are directly available. Then, using the closest point
${\boldsymbol{\pi }} = [{\textbf{n}},d]$
. Unlike the geometric point cloud error with iterative matching for estimation, the matching relationships for 3D-BB planes are directly available. Then, using the closest point
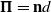 ${\boldsymbol{\Pi}} ={\textbf{n}}d$
proposed in ref. [Reference Geneva, Eckenhoff, Yang and Huang49], we can construct the plane-to-plane semantic error term
${\boldsymbol{\Pi}} ={\textbf{n}}d$
proposed in ref. [Reference Geneva, Eckenhoff, Yang and Huang49], we can construct the plane-to-plane semantic error term
 ${{\textbf{e}}_{{b_r}}}$
:
${{\textbf{e}}_{{b_r}}}$
:
 \begin{align}{{\textbf{e}}_{{b_r}}} ={}^l{\boldsymbol{\Pi}}_{i - 1,r}^b -{}^l{\boldsymbol{\hat{\Pi }}}_{i - 1,r}^b \end{align}
\begin{align}{{\textbf{e}}_{{b_r}}} ={}^l{\boldsymbol{\Pi}}_{i - 1,r}^b -{}^l{\boldsymbol{\hat{\Pi }}}_{i - 1,r}^b \end{align}
 ${}^l{\boldsymbol{\Pi}}_{i - 1,r}^b$
and
${}^l{\boldsymbol{\Pi}}_{i - 1,r}^b$
and
 ${}^l{\boldsymbol{\hat{\Pi }}}_{i - 1,r}^b$
are the r-th measured and estimated planes on 3D-BB in frame
${}^l{\boldsymbol{\hat{\Pi }}}_{i - 1,r}^b$
are the r-th measured and estimated planes on 3D-BB in frame
 $ i$
in the lidar coordinate
$ i$
in the lidar coordinate
 $ l$
. As described in ref. [Reference Hartley and Zisserman50], the motion transformation of a plane is defined as:
$ l$
. As described in ref. [Reference Hartley and Zisserman50], the motion transformation of a plane is defined as:
 \begin{align} \left [ \begin{array}{l}{}^l{\textbf{n}}_{i - 1,r}^b\\[5pt] {}^ld_{i - 1,r}^b \end{array} \right ] = \left [ \begin{array}{l@{\quad}l}{}_l^{i - 1}{{\textbf{R}}^i} & {\textbf{0}}\\[5pt] -{({}_l^{i - 1}{{\textbf{R}}^{i T}}{}_l^{i - 1}{{\textbf{t}}^i})^T} & 1 \end{array} \right ]\left [ \begin{array}{l}{}^l{\textbf{n}}_{i,r}^b\\[5pt] {}^ld_{i,r}^b \end{array} \right ] \end{align}
\begin{align} \left [ \begin{array}{l}{}^l{\textbf{n}}_{i - 1,r}^b\\[5pt] {}^ld_{i - 1,r}^b \end{array} \right ] = \left [ \begin{array}{l@{\quad}l}{}_l^{i - 1}{{\textbf{R}}^i} & {\textbf{0}}\\[5pt] -{({}_l^{i - 1}{{\textbf{R}}^{i T}}{}_l^{i - 1}{{\textbf{t}}^i})^T} & 1 \end{array} \right ]\left [ \begin{array}{l}{}^l{\textbf{n}}_{i,r}^b\\[5pt] {}^ld_{i,r}^b \end{array} \right ] \end{align}
Taking Eq. (10) into
 ${}^l{\boldsymbol{\hat{\Pi }}}_{i - 1,r}^b$
, we can further obtain:
${}^l{\boldsymbol{\hat{\Pi }}}_{i - 1,r}^b$
, we can further obtain:
 \begin{align}{}^l{\boldsymbol{\hat{\Pi }}}_{i - 1,r}^b = \left ({{}_l^{i - 1}{\textbf{R}}_j^i{}^l{\textbf{n}}_{i,r}^b } \right )\left ({ -{}_l^{i - 1}{\textbf{t}}{{_j^i}^T}{}_l^{i - 1}{\textbf{R}}_j^i{}^l{\textbf{n}}_{i,r}^b + d} \right ) \end{align}
\begin{align}{}^l{\boldsymbol{\hat{\Pi }}}_{i - 1,r}^b = \left ({{}_l^{i - 1}{\textbf{R}}_j^i{}^l{\textbf{n}}_{i,r}^b } \right )\left ({ -{}_l^{i - 1}{\textbf{t}}{{_j^i}^T}{}_l^{i - 1}{\textbf{R}}_j^i{}^l{\textbf{n}}_{i,r}^b + d} \right ) \end{align}
When using the least-squares method to estimate
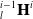 ${}_l^{i - 1}{{\textbf{H}}^i}$
, it is necessary to obtain the derivative of
${}_l^{i - 1}{{\textbf{H}}^i}$
, it is necessary to obtain the derivative of
 ${{\textbf{e}}_{{b_r}}}$
with respect to
${{\textbf{e}}_{{b_r}}}$
with respect to
 ${}_l^{i - 1}{{\textbf{H}}^i}$
:
${}_l^{i - 1}{{\textbf{H}}^i}$
:
 \begin{align} \frac{{\partial{{\textbf{e}}_{{b_r}}}}}{{\partial{\delta _{{}_l^{i - 1}{\boldsymbol{\theta }}_j^i}}}}= -{\left [{{\textbf{F}}{}_l^{i - 1}{\textbf{t}}{{_j^i}^T}{\textbf{F}}} \right ]_ \times }-{\textbf{F}{}_l^{i - 1}{\textbf{t}}{{_j^i}^T }{\left [{\textbf{F}} \right ]_ \times } } +{\left [{{\textbf{F}}d} \right ]_ \times } \end{align}
\begin{align} \frac{{\partial{{\textbf{e}}_{{b_r}}}}}{{\partial{\delta _{{}_l^{i - 1}{\boldsymbol{\theta }}_j^i}}}}= -{\left [{{\textbf{F}}{}_l^{i - 1}{\textbf{t}}{{_j^i}^T}{\textbf{F}}} \right ]_ \times }-{\textbf{F}{}_l^{i - 1}{\textbf{t}}{{_j^i}^T }{\left [{\textbf{F}} \right ]_ \times } } +{\left [{{\textbf{F}}d} \right ]_ \times } \end{align}
 \begin{align} \frac{{\partial{{\textbf{e}}_{{b_r}}}}}{{\partial{\delta _{{}_l^{i - 1}{\textbf{t}}_j^i}}}} ={\textbf{F}}{{\textbf{F}}^T} \end{align}
\begin{align} \frac{{\partial{{\textbf{e}}_{{b_r}}}}}{{\partial{\delta _{{}_l^{i - 1}{\textbf{t}}_j^i}}}} ={\textbf{F}}{{\textbf{F}}^T} \end{align}
where
 ${\textbf{F}} ={}_l^{i - 1}{\textbf{R}}_j^i{}^l{\textbf{n}}_{i,r}^b$
,
${\textbf{F}} ={}_l^{i - 1}{\textbf{R}}_j^i{}^l{\textbf{n}}_{i,r}^b$
,
 $ \frac{{\partial{{\textbf{e}}_{{b_r}}}}}{{\partial{\delta _{{}_l^{i - 1}{\boldsymbol{\theta }}_j^i}}}}$
, and
$ \frac{{\partial{{\textbf{e}}_{{b_r}}}}}{{\partial{\delta _{{}_l^{i - 1}{\boldsymbol{\theta }}_j^i}}}}$
, and
 $ \frac{{\partial{{\textbf{e}}_{{b_r}}}}}{{\partial{\delta _{{}_l^{i - 1}{\textbf{t}}_j^i}}}}$
represent the Jacobians of the error term
$ \frac{{\partial{{\textbf{e}}_{{b_r}}}}}{{\partial{\delta _{{}_l^{i - 1}{\textbf{t}}_j^i}}}}$
represent the Jacobians of the error term
 ${{\textbf{e}}_{{b_r}}}$
w.r.t. the rotation and translation components. The detailed derivation of Eqs. (12) and (13) can be found in Appendix.
${{\textbf{e}}_{{b_r}}}$
w.r.t. the rotation and translation components. The detailed derivation of Eqs. (12) and (13) can be found in Appendix.
Finally, Eq. (14) is the comprehensive cost function for the estimation of
 ${}_l^{i - 1}{{\textbf{H}}^i}$
considering the semantic confidence
${}_l^{i - 1}{{\textbf{H}}^i}$
considering the semantic confidence
 $\mu ^i$
:
$\mu ^i$
:
 \begin{align} \mathop{\arg \min }\limits _{{}_l^{i - 1}{{\textbf{H}}^i}} \frac{{2 -{\mu ^i}}}{{2{N_g}}}\sum \limits _{j = 1}^{{N_g}}{\left ({{N_j}{\textbf{e}}_{g_j}^T{\boldsymbol{\Omega}}_j^{ - 1}{{\textbf{e}}_{g_j}}} \right )} + \frac{{{\mu ^i}}}{{2{N_b}}}\sum \limits _{r = 1}^{{N_b}}{\left ({{\textbf{e}}_{b_r}^T{{\textbf{e}}_{b_r}}} \right )} \end{align}
\begin{align} \mathop{\arg \min }\limits _{{}_l^{i - 1}{{\textbf{H}}^i}} \frac{{2 -{\mu ^i}}}{{2{N_g}}}\sum \limits _{j = 1}^{{N_g}}{\left ({{N_j}{\textbf{e}}_{g_j}^T{\boldsymbol{\Omega}}_j^{ - 1}{{\textbf{e}}_{g_j}}} \right )} + \frac{{{\mu ^i}}}{{2{N_b}}}\sum \limits _{r = 1}^{{N_b}}{\left ({{\textbf{e}}_{b_r}^T{{\textbf{e}}_{b_r}}} \right )} \end{align}
where
 ${N_g}$
is the point number in the object point cloud.
${N_g}$
is the point number in the object point cloud.
 ${N_b}$
is the plane number on 3D-BB.
${N_b}$
is the plane number on 3D-BB.
In this paper, we use the Levenberg-Marquardt [Reference Madsen, Nielsen and Tingleff51] algorithm to solve Eq. (14) and the estimated relative increment to get the motion-distorted object point cloud
 ${{\bar{\boldsymbol{\gamma }}}^i}$
and object edge feature set
${{\bar{\boldsymbol{\gamma }}}^i}$
and object edge feature set
 ${\bar{\boldsymbol{\gamma }}}_c^i$
.
${\bar{\boldsymbol{\gamma }}}_c^i$
.
 ${{\bar{\boldsymbol{\gamma }}}^i}$
and
${{\bar{\boldsymbol{\gamma }}}^i}$
and
 ${\bar{\boldsymbol{\gamma }}}_c^i$
will be used for object tracking in the next frame and accumulated error elimination in the mapping module.
${\bar{\boldsymbol{\gamma }}}_c^i$
will be used for object tracking in the next frame and accumulated error elimination in the mapping module.
3.3.3. Object odometry
The aim of object odometry is to get each object pose in odometry coordinate
 $o$
. First, using the results calculated above, we can compute the object motion increment
$o$
. First, using the results calculated above, we can compute the object motion increment
 ${}_l^i{{\textbf{X}}^{i - 1}}$
in the lidar coordinate
${}_l^i{{\textbf{X}}^{i - 1}}$
in the lidar coordinate
 $l$
:
$l$
:
 \begin{align}{}_l^i{{\textbf{X}}^{i - 1}} ={}_l^{i - 1}{{\boldsymbol{\delta }}^i}{}_l^i{{\textbf{H}}^{i - 1}} \end{align}
\begin{align}{}_l^i{{\textbf{X}}^{i - 1}} ={}_l^{i - 1}{{\boldsymbol{\delta }}^i}{}_l^i{{\textbf{H}}^{i - 1}} \end{align}
Suppose the transformation from object to robot in the frame
 $i-1$
is
$i-1$
is
 ${}^{i - 1}{{\textbf{L}}_{lt}}$
. The absolute increment of object motion in the body-fixed coordinate [Reference Henein, Zhang, Mahony and Ila52] can be expressed as:
${}^{i - 1}{{\textbf{L}}_{lt}}$
. The absolute increment of object motion in the body-fixed coordinate [Reference Henein, Zhang, Mahony and Ila52] can be expressed as:
 \begin{align}{}_t^{i - 1}{{\textbf{X}}^i} ={}^{i - 1}{\textbf{L}}_{lt}^{ - 1}{}_l^i{{\textbf{X}}^{i - 1}}{}^{i - 1}{{\textbf{L}}_{lt}} \end{align}
\begin{align}{}_t^{i - 1}{{\textbf{X}}^i} ={}^{i - 1}{\textbf{L}}_{lt}^{ - 1}{}_l^i{{\textbf{X}}^{i - 1}}{}^{i - 1}{{\textbf{L}}_{lt}} \end{align}
Finally, we accumulate the increment
 ${}_t^{i - 1}{{\textbf{X}}^i}$
to obtain the object pose
${}_t^{i - 1}{{\textbf{X}}^i}$
to obtain the object pose
 ${\textbf{T}}_{ot}^i$
in the odometry coordinate
${\textbf{T}}_{ot}^i$
in the odometry coordinate
 $o$
. For an object detected at the first frame, we compute its initial pose
$o$
. For an object detected at the first frame, we compute its initial pose
 ${{\textbf{T}}_{ot}}$
in the odometry coordinate
${{\textbf{T}}_{ot}}$
in the odometry coordinate
 $o$
based on the current robot pose
$o$
based on the current robot pose
 ${{\textbf{T}}_{ol}}$
and the transformation
${{\textbf{T}}_{ol}}$
and the transformation
 ${{\textbf{L}}_{lt}}$
inferred from the semantic detection module.
${{\textbf{L}}_{lt}}$
inferred from the semantic detection module.
3.4. 4D scene mapping
To generate a long-term static map that can be reused, we maintain an absolute trajectory tracking list (ATTL) for processing semantic objects in the field of view. The list contains the unique id, continuous tracking trajectory, accumulated static map, and motion state of each object.

Figure 5.
Dynamic object detection based on ATTL. The blue boxes represent the object’s predicted pose, and orange boxes represent their tracking trajectories that have corrected the accumulated error. Objects with IDs 37 and 84 are in a normal tracking state. The object with ID 12 will be initialized as a static object, and the object with ID 145 will be deleted because the current frame does not observe it.
 $ \Delta{\textbf{T}}$
is used to determine the current motion state of each object.
$ \Delta{\textbf{T}}$
is used to determine the current motion state of each object.
3.4.1. Dynamic object detection
As shown in Fig. 5, the ATTL maintained in the mapping module is used to analyze the motion state of each instance object. First, each object in the current frame is matched with the unique ID generated by the SGF-MOT module and maintained in ATTL. Then, we use the current error correction matrix
 ${\textbf{T}}_{mo}^{i - 1}$
to predict the object pose
${\textbf{T}}_{mo}^{i - 1}$
to predict the object pose
 ${\textbf{T}}_{mt}^{i\;\;'}$
in the map coordinate
${\textbf{T}}_{mt}^{i\;\;'}$
in the map coordinate
 $m$
:
$m$
:
 \begin{align}{\textbf{T}}_{mt}^{i\;\;'} ={\textbf{T}}_{mo}^{i - 1}{\textbf{T}}_{ot}^i \end{align}
\begin{align}{\textbf{T}}_{mt}^{i\;\;'} ={\textbf{T}}_{mo}^{i - 1}{\textbf{T}}_{ot}^i \end{align}
By calculating the motion increment of the predicted object pose and the static oldest object pose in ATTL, we can determine whether each object is in motion. Note that the detected object in the first frame is set to be static by default.
3.4.2. Static map creation
By matching the static object feature set
 ${\bar{\boldsymbol{\gamma }}}_c^i$
in the current frame with the accumulated object map, ground feature set
${\bar{\boldsymbol{\gamma }}}_c^i$
in the current frame with the accumulated object map, ground feature set
 ${\bar{\boldsymbol{\chi }}}_c^i$
, background edge feature set
${\bar{\boldsymbol{\chi }}}_c^i$
, background edge feature set
 ${\bar{\boldsymbol{\psi }}}_c^i$
, and surface feature set
${\bar{\boldsymbol{\psi }}}_c^i$
, and surface feature set
 ${\bar{\boldsymbol{\zeta }}}_c^i$
with their accumulated feature map, it is possible to obtain the corrected robot pose
${\bar{\boldsymbol{\zeta }}}_c^i$
with their accumulated feature map, it is possible to obtain the corrected robot pose
 ${\textbf{T}}_{ml}^i$
in the map coordinate
${\textbf{T}}_{ml}^i$
in the map coordinate
 $m$
. Then, we align the non-semantic feature sets to the map coordinate
$m$
. Then, we align the non-semantic feature sets to the map coordinate
 $m$
to create a long-term static map. Readers can refer to ref. [Reference Zhang and Singh1] for more details about feature mapping and optimization.
$m$
to create a long-term static map. Readers can refer to ref. [Reference Zhang and Singh1] for more details about feature mapping and optimization.
Using the ego pose
 ${\textbf{T}}_{ol}^i$
in the odometry coordinate
${\textbf{T}}_{ol}^i$
in the odometry coordinate
 $o$
and the corrected pose
$o$
and the corrected pose
 ${\textbf{T}}_{ml}^i$
in the map coordinate
${\textbf{T}}_{ml}^i$
in the map coordinate
 $m$
, the updated accumulated error correction matrix
$m$
, the updated accumulated error correction matrix
 ${\textbf{T}}_{mo}^i$
can be computed.
${\textbf{T}}_{mo}^i$
can be computed.
3.4.3. Tracking list maintain
The ATTL can be updated based on the motion state of each object. If the object is moving, the object map and tracking trajectory should be cleared first. Otherwise, they will remain unchanged. Then, we use
 ${\textbf{T}}_{mo}^i$
and
${\textbf{T}}_{mo}^i$
and
 ${\textbf{T}}_{ml}^i$
to convert the object odometry pose
${\textbf{T}}_{ml}^i$
to convert the object odometry pose
 ${\textbf{T}}_{ot}^i$
and extracted object feature set
${\textbf{T}}_{ot}^i$
and extracted object feature set
 ${\bar{\boldsymbol{\gamma }}}_c^{k,i}$
into the map coordinate
${\bar{\boldsymbol{\gamma }}}_c^{k,i}$
into the map coordinate
 $m$
, which will participate in the following mapping steps.
$m$
, which will participate in the following mapping steps.
4. Results
In this section, we validate the proposed MLO system and SGF-MOT module using the public KITTI [Reference Geiger, Lenz and Urtasun53] dataset. First, the ego-motion trajectory generated by the MLO system is compared with other feature-based 3D lidar SLAM systems (A-LOAM [Reference Qin and Cao54], Lego-LOAM [Reference Shan and Englot2], F-LOAM [Reference Wang, Wang, Chen and Xie55]) on the KITTI-odometry benchmark. In addition, we compared the MLO system with the visual SLAM (DSO [Reference Wang, Schworer and Cremers56]) and multi-sensor fusion systems (V-LOAM [Reference Zhang and Singh36], LIO-SAM [Reference Shan, Englot, Meyers, Wang, Ratti and Rus40]) under the KITTI-raw benchmark to analyze its performance in dynamic scenarios. The geometric consistency checking algorithm and the dynamic object detection method are verified. Then, the SGF-MOT module is compared in the KITTI-tracking benchmark with another two efficient MOT methods (AB3DMOT [Reference Weng, Wang, Held and Kitani21], PC3T [Reference Wu, Han, Wen, Li and Wang57]), which also perform on CPU and use point clouds as input. Meanwhile, we use the absolute object trajectory generated by MLO to evaluate the advantages of the SGF-MOT method compared with semantic-only and geometric-only methods under the KITTI-raw benchmark.
4.1. Experiment setup and evaluation metrics
All experiments in this paper were performed with AMD
 $\circledR$
Ryzen 7 5800h (8 cores @3.2 GHz), 16 GB RAM, ROS Melodic, and NVIDIA GeForce RTX 3070. The absolute trajectory error [Reference Sturm, Engelhard, Endres, Burgard and Cremers58] (ATE) is used to evaluate localization accuracy. The relative rotation error (RRE) and relative translation error (RTE) [Reference Geiger, Lenz and Urtasun53] can evaluate the drift of odometry estimation. The CLEAR MOT metric [Reference Bernardin and Stiefelhagen59] denotes the estimated accuracy and consistent tracking of object configurations over time for the MOT module.
$\circledR$
Ryzen 7 5800h (8 cores @3.2 GHz), 16 GB RAM, ROS Melodic, and NVIDIA GeForce RTX 3070. The absolute trajectory error [Reference Sturm, Engelhard, Endres, Burgard and Cremers58] (ATE) is used to evaluate localization accuracy. The relative rotation error (RRE) and relative translation error (RTE) [Reference Geiger, Lenz and Urtasun53] can evaluate the drift of odometry estimation. The CLEAR MOT metric [Reference Bernardin and Stiefelhagen59] denotes the estimated accuracy and consistent tracking of object configurations over time for the MOT module.
Note that our MOT module is performed in the lidar coordinate. Therefore, the ability to track the relative motion of the object is evaluated. On the other hand, object trajectories in the map coordinate
 $m$
evaluate the overall accuracy of the MLO system.
$m$
evaluate the overall accuracy of the MLO system.
Considering that the KITTI-raw benchmark does not provide ground-truth trajectories that can be used directly for localization evaluation, we process the raw GPS/IMU data by the Kalman filter [Reference Moore and Stouch60] algorithm to get the ground truth of robot pose in the map coordinate
 $m$
. Meanwhile, based on the artificial annotation in the KITTI-tracking dataset, we can further compute the absolute tracking trajectory of each object.
$m$
. Meanwhile, based on the artificial annotation in the KITTI-tracking dataset, we can further compute the absolute tracking trajectory of each object.
The frameworks used in the comparison experiments, SLAM and MOT, both keep a default parameter configuration. The parameter configuration of each module in the MLO system is as follows:
-
(1) Geometric consistency feature checking algorithm (3.3.1): Total iteration times
 ${N_{iter,gc}} = 100$
; Threshold for Euclidean distance
$t{h_{ed}} = 0.5\,{\rm m}$
; Proportional threshold
$t{h_r} = 0.4$
; Threshold for point number
$t{h_g} = 20$
,
$t{h_b} = 30$
; Association update interval
$\lambda = 5$
.
${N_{iter,gc}} = 100$
; Threshold for Euclidean distance
$t{h_{ed}} = 0.5\,{\rm m}$
; Proportional threshold
$t{h_r} = 0.4$
; Threshold for point number
$t{h_g} = 20$
,
$t{h_b} = 30$
; Association update interval
$\lambda = 5$
. -
(2) Kuhn-Munkres algorithm (3.3.2): Position error weight
${w_p} = 0.7$
; Direction error weight
${w_d} = 0.25$
; Size error weight
${w_s} = 0.1$
; Total error threshold
$t{h_{km}} = 5$
. -
(3) Semantic-geometric fusion least-squares estimator (3.3.2): Number of kd-tree nearest points used in computing covariance
${N_{kd}} = 10$
; Voxel size in VG-ICP
${v_s} = 0.2\,{\rm m}$
; Maximum iteration times
${N_{iter,ls}} = 5$
; Angle increment threshold
$t{h_{a,ls}} ={0.1^ \circ }$
, Translation increment threshold
$t{h_{t,ls}} = 1{e^{ - 2}}\,{\rm m}$
(convergence conditions of the estimator). -
(4) Absolute trajectory tracking list (3.4.1): Yaw angle increment threshold
$t{h_{yaw,attl}} ={2^ \circ }$
; Translation increment threshold
$t{h_{t,attl}} = 0.2\,{\rm m}$
(static object judgment conditions).

















4.2. Ego odometry localization accuracy experiment
The KITTI-odometry benchmark contains many static objects with long sequences. The KITTI-raw dataset, on the other hand, contains more challenging scenes, such as the city sequence with unknown dynamic semantic objects (trains). We evaluate the MLO system in these two datasets by comparing it with other state-of-the-art SLAM systems. Since the KITTI dataset labels semantic objects within the camera’s field of view, only the ROI-cutting lidar data is input into the fusion perception module. Figure 6 shows the long-term static map created by the MLO system.
For the experimental 3D lidar SLAM system, A-LOAM [Reference Qin and Cao54] is a simplified version of LOAM [Reference Zhang and Singh1] with removing the use of IMU. It also extracts edge and surface features by the roughness of the scan line to perform frame-to-frame matching for odometry estimation and frame-to-map matching for lidar mapping. Lego-LOAM [Reference Shan and Englot2] takes into account ground constraints. Use the ground feature set and background edge feature set to estimate the increment
 $ [{t_z},{\theta _{roll}},{\theta _{pitch}}]$
and
$ [{t_z},{\theta _{roll}},{\theta _{pitch}}]$
and
 $ [{t_x},{t_y},{\theta _{yaw}}]$
to improve efficiency. F-LOAM [Reference Wang, Wang, Chen and Xie55] proposes a two-step algorithm for motion distortion in the point cloud, and then, localization and mapping are performed directly through frame-to-map matching. To fully validate the system performance, we also selected a purely visual SLAM and two multi-sensor fusion systems for comparative experiments. DSO-stereo [Reference Wang, Schworer and Cremers56] is a direct sparse stereo visual odometry based on the assumption of constant luminosity. LIO-SAM [Reference Shan, Englot, Meyers, Wang, Ratti and Rus40] is a tightly coupled lidar-inertial odometry that uses high-frequency imu-predicted pose as the initial estimation and can effectively correct point cloud distortion even when the robot is in vigorous motion. V-LOAM [Reference Zhang and Singh36] is a visual-lidar fusion framework that fixes the scale uncertainty problem in monocular visual odometry by point cloud and uses high-frequency visual odometry as a prior value for high-precision lidar mapping.
$ [{t_x},{t_y},{\theta _{yaw}}]$
to improve efficiency. F-LOAM [Reference Wang, Wang, Chen and Xie55] proposes a two-step algorithm for motion distortion in the point cloud, and then, localization and mapping are performed directly through frame-to-map matching. To fully validate the system performance, we also selected a purely visual SLAM and two multi-sensor fusion systems for comparative experiments. DSO-stereo [Reference Wang, Schworer and Cremers56] is a direct sparse stereo visual odometry based on the assumption of constant luminosity. LIO-SAM [Reference Shan, Englot, Meyers, Wang, Ratti and Rus40] is a tightly coupled lidar-inertial odometry that uses high-frequency imu-predicted pose as the initial estimation and can effectively correct point cloud distortion even when the robot is in vigorous motion. V-LOAM [Reference Zhang and Singh36] is a visual-lidar fusion framework that fixes the scale uncertainty problem in monocular visual odometry by point cloud and uses high-frequency visual odometry as a prior value for high-precision lidar mapping.
As shown in Table I, our method successfully performs all sequences under the KITTI-odometry benchmark and achieves the best results in most cases. When estimating
 $ [{t_x},{t_y},{\theta _{yaw}}]$
based on the background edge feature set, the Lego-LOAM [Reference Shan and Englot2] system shows an obvious drift in many sequences because it uses only point clouds from the camera perspective. Our system also uses the two-step estimation algorithm to ensure computational efficiency. However, using the background surface feature set based on roughness prior
$ [{t_x},{t_y},{\theta _{yaw}}]$
based on the background edge feature set, the Lego-LOAM [Reference Shan and Englot2] system shows an obvious drift in many sequences because it uses only point clouds from the camera perspective. Our system also uses the two-step estimation algorithm to ensure computational efficiency. However, using the background surface feature set based on roughness prior
 ${R_a}$
and the geometric consistency check algorithm improves the robustness of the MLO system.
${R_a}$
and the geometric consistency check algorithm improves the robustness of the MLO system.
Table I. Ego localization accuracy under KITTI-odometry benchmark.


Figure 6. Point cloud map created by sequence 00 in the KITTI-odometry dataset. As shown in the magnified part on the right, the resulting map does not contain semantic objects that may change over time by maintaining semantic objects and the static map separately.
Table II. Evaluation for ego localization accuracy under KITTI-raw City and Residential sequences.

In addition, detecting dynamic objects by ATTL and adding static object constraints for static map creation can better eliminate accumulated error compared to the MLO-attl system, which does not use the dynamic object detection method in the mapping module. In sequences 00, 02, 03, 05, and 07 containing many static objects, the MLO system achieved better localization accuracy.
Table II shows the localization accuracy of the proposed MLO system and other SLAM frameworks in complex scenes with dynamic objects. Although the DSO-stereo system avoids the scale uncertainty problem of monocular visual SLAM, it is found that the overall accuracy of lidar-based SLAM systems using point clouds is better. Compared to the A-LOAM, LIO-SAM, and V-LOAM systems, the proposed MLO system has higher robustness for localization in dynamic scenes. V-LOAM uses visual odometry as a prior, but fails several times in dynamic scenes. The reason is that the system does not process the dynamic objects appearing in the image and could not achieve the ideal situation of providing a better prior value. Meanwhile, the LIO-SAM uses the measurement of IMU, which is not affected by external environments, thus improving the robustness and accuracy of the system compared with V-LOAM. However, the IMU measurement can only estimate the ego localization of the robot, so it cannot correct the relative motion distortion of extracted features on dynamic objects, which may also lead to estimation errors in the system.
Taking sequence 0926-0056 as an example, there is a train that the object detection module cannot detect. The MLO-gc system without Algorithm 1 to check geometric consistency (When Algorithm 1 is not used, the amount of dynamic data association for pose estimation will be significant) and the V-LOAM system, which uses visual odometry as a prior, cannot deal with this situation. A-LOAM and LIO-SAM can work stably in dynamic scenarios. However, their localization accuracy is slightly lower because they do not filter the extracted features and directly use all features for localization and mapping. Compared with the above framework, the MLO system, which considers static and dynamic object processing, achieved the best localization results.
4.3. Object tracking accuracy and robustness experiment
First, we compare the SGF-MOT module proposed in this paper with AB3DMOT [Reference Weng, Wang, Held and Kitani21] and PC3T [Reference Wu, Han, Wen, Li and Wang57] trackers under the KITTI-tracking benchmark. The tracking results are evaluated in 2D image, which can be computed by the KITTI calibration matrix. AB3DMOT [Reference Weng, Wang, Held and Kitani21] only takes the point cloud as input and uses the Kalman filter for 3D-BB tracking in the lidar coordinate. PC3T [Reference Wu, Han, Wen, Li and Wang57] uses the ground truth of ego localization provided by the KITTI dataset to transform the detected object into the map coordinate
 $m$
. Then, it performs absolute motion tracking based on the kinetic model of the object.
$m$
. Then, it performs absolute motion tracking based on the kinetic model of the object.
Table III. Evaluation for multi-object tracking module under the KITTI-tracking benchmark.


Figure 7. The running time of SGF-MOT module in sequences filled with objects under the KITTI-tracking dataset.
Table IV. Evaluation for absolute object trajectory accuracy under KITTI-raw City and Road sequences.


Figure 8. Comparison of different tracking methods in sequence 0926-0056 under the KITTI-tracking dataset. Both semantic-only and fusion methods can track objects robustly, but geometric-only method has the problems of object tracking loss and trajectory drift.
As shown in Table III, thanks to the accurate point cloud, the three methods have little difference in the MOTP metric, which illustrates the estimation accuracy of the proposed tracker. Since the object is transformed into the map coordinate
 $m$
using the prior ego ground truth, PC3T [Reference Wu, Han, Wen, Li and Wang57] tracker only needs to consider the uncertainty caused by absolute object motion between frames. Moreover, it achieves the best results on the MOTA metric. The proposed SGF-MOT tracker does not use ego localization information but also improves tracking robustness by introducing a least-squares estimator fusing geometric and semantic constraints. So, we achieve better MOTA results than the AB3DMOT [Reference Weng, Wang, Held and Kitani21] tracker.
$m$
using the prior ego ground truth, PC3T [Reference Wu, Han, Wen, Li and Wang57] tracker only needs to consider the uncertainty caused by absolute object motion between frames. Moreover, it achieves the best results on the MOTA metric. The proposed SGF-MOT tracker does not use ego localization information but also improves tracking robustness by introducing a least-squares estimator fusing geometric and semantic constraints. So, we achieve better MOTA results than the AB3DMOT [Reference Weng, Wang, Held and Kitani21] tracker.
Like the other two methods, our method runs in real-time on the CPU. The running time of the SGF-MOT module executed on sequences 0001 and 0015 is shown in Fig. 7. On the KITTI-raw City and Road datasets, which are full of moving objects, we used the absolute tracking trajectory of objects generated by the MLO system to verify the semantic-geometric fusion tracking method (Fusion Method). The fusion method is compared to trackers that use only geometric object points (Geometry only) and semantic box planes (Semantic only) for motion estimation.
As shown in Table IV, the object localization accuracy of the geometry-only method exhibits a distinct “bipolar” distribution. There are two main reasons why the geometry-only method cannot reliably track the object: (1) The estimator requires iterative matching to obtain the point-level data association and places high demands on the initial value of the estimation. (2) Semantic objects are sometimes observed only from a specific perspective within the lidar perception range, for example, when the vehicle is directly in front of or next to the robot. In this case, the lidar sensor can only obtain a single planar point cloud with 3-DOF constraints on the motion of the object. On the other hand, we also find that the geometry-only tracking method can work better than the semantic-only tracking method in terms of accuracy when the estimator is successfully convergent.
Therefore, semantic box constraints, which can provide complete motion constraints, should be considered together with high-precision measurement point clouds in the MOT task. In this way, the tracker can well balance the accuracy of estimation and the robustness of tracking and achieve better overall performance. The experimental results in Table IV support this conclusion. The object motion trajectories of different tracking methods under sequence 0926-0056 in Fig. 8 can also confirm this qualitatively.
5. Conclusions
In this paper, we propose a novel MLO system to solve the problem of simultaneous localization, mapping, and MOT only using a lidar sensor. Specifically, we propose a fused least-squares estimator that uses the semantic bounding box and geometric point cloud for updating the object SGF-MOT. In the mapping module, dynamic semantic objects are detected based on the applied absolute trajectory tracking list, and the system can achieve reliable mapping in highly dynamic scenarios. Experiments with open datasets show that the SGF-MOT module can achieve better overall performance compared to the pure semantic and geometry tracking methods and other advanced MOT frameworks. Compared with other lidar, visual, and multi-sensor fusion SLAM systems, the MLO system with the SGF-MOT tracker can provide more stable and accurate robot and object localization in complex scenes. On the other hand, the high-frequency IMU, which is unaffected by the external environment, can provide good guidance in extracting static feature points and effectively cope with the intense movements of the robot. Therefore, the correct integration of the IMU measurement into the MLO and the building of a fusion SLAM system that can adapt to dynamic scenes as well as to the complex motions of the robot are meaningful problems.
Supplementary material
The supplementary material for this article can be found at http://doi.org/10.1017/S0263574723001868.
Author contributions
Tingchen Ma conceived and designed the study. Guolai Jiang and Sheng Xu completed the experimental verification. Tingchen Ma, Guolai Jiang, Yongsheng Ou, and Sheng Xu wrote the article.
Financial support
This research was funded by the National Key Research and Development Program of China under Grant 2018AAA0103001; in part by the National Natural Science Foundation of China (Grants No. 62173319, 62063006); in part by the Guangdong Basic and Applied Basic Research Foundation (2022B1515120067); in part by the Guangdong Provincial Science and Technology Program (2022A0505050057); and in part by the Shenzhen Fundamental Research Program (JCYJ20200109115610172).
Competing interests
The authors declare no competing interests exist.
Ethical approval
Not applicable.
















