


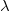
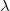
1 Introduction
Property-based testing (PBT) is a technique for validating code that successfully combines two well-trodden ideas: automatic test data generation trying to refute executable specifications. Pioneered by QuickCheck for functional programing (Claessen and Hughes Reference Claessen and Hughes2000), PBT tools are now available for most programing languages and are having a growing impact in industry (Hughes Reference Hughes2007). Moreover, this idea has spread to several proof assistants (see Blanchette et al. Reference Blanchette, Bulwahn and Nipkow2011; Paraskevopoulou et al. Reference Paraskevopoulou, Hritcu, Dénès, Lampropoulos and Pierce2015 to name the main players) to complement (interactive) theorem proving with a preliminary phase of conjecture testing. The synergy of PBT with proof assistants is so accomplished that PBT is now a part of the Software Foundations’s curriculum (Lampropoulos and Pierce Reference Lampropoulos and Pierce2023).
In our opinion, this tumultuous rate of growth is characterized by a lack of common (logical) foundation. For one, PBT comes in different flavors as far as data generation is concerned: while random generation is the most common one, other tools employ exhaustive generation (Runciman et al. Reference Runciman, Naylor and Lindblad2008; Cheney and Momigliano Reference Cheney and Momigliano2017) or a combination thereof (Duregård et al. Reference Duregård, Jansson and Wang2012). At the same time, one could say that PBT is rediscovering logic and, in particular, logic programing: to begin with, QuickCheck’s DSL is based on Horn clause logic; LazySmallCheck (Runciman et al. Reference Runciman, Naylor and Lindblad2008) has adopted narrowing to permit less redundant testing over partial rather than ground terms; a recent version of PLT-Redex (Felleisen et al. Reference Felleisen, Findler and Flatt2009) contains a re-implementation of constraint logic programing in order to better generate well-typed
 $\lambda$
-terms (Fetscher et al. Reference Fetscher, Claessen, Palka, Hughes and Findler2015). Finally, PBT in Isabelle/HOL features the notion of smart test generators (Bulwahn Reference Bulwahn2012), and this is achieved by turning the functional code into logic programs and inferring through mode analysis their data-flow behavior. We refer to the Related Work (Section 8) for more recent examples of this phenomenon, together with the relevant citations.
$\lambda$
-terms (Fetscher et al. Reference Fetscher, Claessen, Palka, Hughes and Findler2015). Finally, PBT in Isabelle/HOL features the notion of smart test generators (Bulwahn Reference Bulwahn2012), and this is achieved by turning the functional code into logic programs and inferring through mode analysis their data-flow behavior. We refer to the Related Work (Section 8) for more recent examples of this phenomenon, together with the relevant citations.
This paper considers the general setting of applying PBT techniques to logic specifications. In doing so, we also insist on the need to involve two levels of logic.
-
1. The specification-level logic is the logic of entailment between a logic program and a goal. In this paper, logic programs can be Horn clauses, hereditary Harrop formulas, or a linear logic extension of the latter. The entailment use at the specification level is classical, intuitionistic, or linear.
-
2. The reasoning-level logic is the logic where statements about the specification level entailment are made. For example, in this logic, one might try to argue that a certain specification-level entailment does not hold. This level of logic can also be called arithmetic since it involves least fixed points. In particular, our use of arithmetic fits within the
 $I\Sigma _1$
fragment of Peano arithmetic, which is known to coincide with Heyting arithmetic (Friedman Reference Friedman1978). As a result, we can consider our uses of the reasoning-level logic to be either classical or intuitionistic.
$I\Sigma _1$
fragment of Peano arithmetic, which is known to coincide with Heyting arithmetic (Friedman Reference Friedman1978). As a result, we can consider our uses of the reasoning-level logic to be either classical or intuitionistic.

We shall use proof-theoretic techniques to deal with both of these logic levels. In particular, instead of attempting some kind of amalgamation of these two levels, we will encode into the reasoning logic inductively defined predicates that faithfully capture specification-level terms, formulas, and provability. One of the strengths of using proof theory (in particular, the sequent calculus) is that it allows for an elegant treatment of syntactic structures with bindings (such as quantified formulas) at both logic levels. As a result, our approach to PBT lifts from the conventional suite of examples to meta-programing examples without significant complications.
Property-based testing requires a flexible way to specify what tests should be generated. This flexibility arises here from our use of foundational proof certificates (FPC) (Chihani et al. Reference Chihani, Miller and Renaud2017). Arising from proof-theoretic considerations, FPCs can describe proofs with varying degrees of detail: in this paper, we use FPCs to describe proofs in the specification logic. For example, an FPC can specify that a proof has a certain height, size, or satisfies a specific outline (Blanco and Miller Reference Blanco and Miller2015). It can also specify that all instantiations for quantifiers have a specific property. By employing standard logic programing techniques (e.g., unification and backtracking search), the very process of checking that a (specification-level) sequent has a proof that satisfies an FPC is a process that generates such proofs, or more in general, results in an attempt to fill in the missing details. In this way, a proof certificate goes through a proof reconstruction to yield a fully elaborated proof that a trusted proof-checking kernel can accept. As we shall see, small localized changes in the specification of relevant FPCs allow us to account for both exhaustive and random generation. We can also use FPCs to perform shrinking: this is an indispensable ingredient in the random generation approach, whereby counterexamples are minimized to be more easily understandable by the user.
Throughout this paper, we use
 $\lambda$
Prolog (Miller and Nadathur Reference Miller and Nadathur2012) to specify and prototype all aspects of our PBT project. One role for
$\lambda$
Prolog (Miller and Nadathur Reference Miller and Nadathur2012) to specify and prototype all aspects of our PBT project. One role for
 $\lambda$
Prolog is as an example of computing within the Specification Logic. However, since the kinds of queries that PBT requires of our Reasoning Logic are relatively weak, it is possible to use
$\lambda$
Prolog is as an example of computing within the Specification Logic. However, since the kinds of queries that PBT requires of our Reasoning Logic are relatively weak, it is possible to use
 $\lambda$
Prolog to implement a prover for the needed properties at the reasoning level. The typing system of
$\lambda$
Prolog to implement a prover for the needed properties at the reasoning level. The typing system of
 $\lambda$
Prolog will help clarify when we are using it at these two different levels: in particular, logic program clauses are used as specifications within a reasoning level prover are given the type sl instead of the usual type o of
$\lambda$
Prolog will help clarify when we are using it at these two different levels: in particular, logic program clauses are used as specifications within a reasoning level prover are given the type sl instead of the usual type o of
 $\lambda$
Prolog clauses.
$\lambda$
Prolog clauses.
If we are only concerned with PBT for logic specifications written using first-order Horn clauses (as is the case for Sections 4 and 5), then the
 $\lambda$
Prolog specifications can be replaced with Prolog specifications without much change. However, this interchangeability between
$\lambda$
Prolog specifications can be replaced with Prolog specifications without much change. However, this interchangeability between
 $\lambda$
Prolog and Prolog disappears when we turn our attention to applying PBT to meta-programing or, equivalently, meta-theory model-checking (Cheney and Momigliano Reference Cheney and Momigliano2017). Although PBT has been used extensively with meta-theory specifications, there are many difficulties (Klein et al. Reference Klein, Clements, Dimoulas, Eastlund, Felleisen, Flatt, McCarthy, Rafkind, Tobin-Hochstadt and Findler2012), mainly dealing with the binding structures one finds within the syntax of many programing language constructs. In that setting,
$\lambda$
Prolog and Prolog disappears when we turn our attention to applying PBT to meta-programing or, equivalently, meta-theory model-checking (Cheney and Momigliano Reference Cheney and Momigliano2017). Although PBT has been used extensively with meta-theory specifications, there are many difficulties (Klein et al. Reference Klein, Clements, Dimoulas, Eastlund, Felleisen, Flatt, McCarthy, Rafkind, Tobin-Hochstadt and Findler2012), mainly dealing with the binding structures one finds within the syntax of many programing language constructs. In that setting,
 $\lambda$
Prolog’s support of
$\lambda$
Prolog’s support of
 $\lambda$
-tree syntax (Miller Reference Miller2019), which is not supported by Prolog, allows us to be competitive with specialized tools, such as
$\lambda$
-tree syntax (Miller Reference Miller2019), which is not supported by Prolog, allows us to be competitive with specialized tools, such as
 $\alpha$
Check (Cheney and Momigliano Reference Cheney and Momigliano2017).
$\alpha$
Check (Cheney and Momigliano Reference Cheney and Momigliano2017).
This paper and its contributions are organized as follows. In Sections 2 and 3, we describe the two levels of logic – the specification level and the reasoning level – whose importance we wish to underline when applying PBT to logic programs. Section 4 gives a gentle introduction to foundational proof certificates (FPCs). We show there that proof checking in logic programing can serve as a nondeterministic elaboration of proof outlines into complete proof structures, which themselves can be used to generate test cases. We use proof outlines (formalized using FPCs) to provide a flexible description of the space of terms in which to search for counterexamples. Section 5 shows how FPCs can be used to specify many flavors of PBT flexibly. The programable nature of the FPC framework allows us not only to describe the search space of possible counterexamples, but also to specify a wide range of popular approaches to PBT, including exhaustive, bounded, and randomized search, as well as the shrinking of counterexamples. In Section 6, we lift our approach to meta-programing with applications to the problem of analyzing confluence in the
 $\lambda$
-calculus. When implemented in
$\lambda$
-calculus. When implemented in
 $\lambda$
Prolog, our proof checker can also treat the search for counterexamples that contain bindings, a feature important when data such as programs are the possible counterexamples under study. For example, we illustrate how the
$\lambda$
Prolog, our proof checker can also treat the search for counterexamples that contain bindings, a feature important when data such as programs are the possible counterexamples under study. For example, we illustrate how the
 $\lambda$
Prolog implementation of this framework easily discovers a counterexample to the (false) claim that, in the untyped
$\lambda$
Prolog implementation of this framework easily discovers a counterexample to the (false) claim that, in the untyped
 $\lambda$
-calculus, beta-conversion satisfies the diamond property. Section 7 extends our approach to a fragment of linear logic. We provide one proof checker (displayed in Figure 24) that can deal with the three specification logics that we employ here, namely (certain restricted subsets of) classical, intuitionistic, and linear logic. The correctness of this checker depends only on its dozen-clause specification and the soundness of the underlying
$\lambda$
-calculus, beta-conversion satisfies the diamond property. Section 7 extends our approach to a fragment of linear logic. We provide one proof checker (displayed in Figure 24) that can deal with the three specification logics that we employ here, namely (certain restricted subsets of) classical, intuitionistic, and linear logic. The correctness of this checker depends only on its dozen-clause specification and the soundness of the underlying
 $\lambda$
Prolog implementation. We conclude with a review of related work (Sections 8 and 9).
$\lambda$
Prolog implementation. We conclude with a review of related work (Sections 8 and 9).
This paper significantly extends our conference paper (Blanco et al. Reference Blanco, Miller and Momigliano2019) by clarifying the relationship between specification and reasoning logics, by tackling new examples and by including logic specifications based on linear logic. The code mentioned in this paper can be found at https://github.com/proofcert/pbt/tree/journal
2 The specification logic SL
Originally, logic programing was based on relational specifications (i.e., formulas in first-order predicate logic) given as Horn clauses. Such clauses can be defined as closed formulas of the form
 $\forall \bar x [G\supset A]$
where
$\forall \bar x [G\supset A]$
where
 $\bar x$
is a list of variables (all universally quantified),
$\bar x$
is a list of variables (all universally quantified),
 $A$
is an atomic formula, and
$A$
is an atomic formula, and
 $G$
(a goal formula) is a formula built using disjunctions, conjunctions, existential quantifiers, true (the unit for conjunction), and atomic formulas. An early extension of the logic programing paradigm, called the hereditary Harrop formulas, allowed both universal quantification and certain restricted forms of the intuitionistic implication (
$G$
(a goal formula) is a formula built using disjunctions, conjunctions, existential quantifiers, true (the unit for conjunction), and atomic formulas. An early extension of the logic programing paradigm, called the hereditary Harrop formulas, allowed both universal quantification and certain restricted forms of the intuitionistic implication (
 $\supset$
) in goal formulas (Miller et al. Reference Miller, Nadathur, Pfenning and Scedrov1991). A subsequent extension of that paradigm, called Lolli (Hodas and Miller Reference Hodas and Miller1994), also allowed certain uses of the linear implication (
$\supset$
) in goal formulas (Miller et al. Reference Miller, Nadathur, Pfenning and Scedrov1991). A subsequent extension of that paradigm, called Lolli (Hodas and Miller Reference Hodas and Miller1994), also allowed certain uses of the linear implication (
 $\multimap$
) from Girard’s linear logic (Girard Reference Girard1987).
$\multimap$
) from Girard’s linear logic (Girard Reference Girard1987).
Except for Section 7, we shall consider the following two classes of formulas.
 \begin{equation*} \begin {array}[t]{rl} D\,\mathrel {::=}& G \supset A \,\vert \, \forall x:\tau . D\\[5pt] G\,\mathrel {::=}& A \,\vert \, tt \,\vert \, G_1\vee G_2\,\vert \, G_1\wedge G_2\,\vert \,\exists x:\tau . G \,\vert \,\forall x:\tau . G\,\vert \, A\supset G \end {array} \end{equation*}
\begin{equation*} \begin {array}[t]{rl} D\,\mathrel {::=}& G \supset A \,\vert \, \forall x:\tau . D\\[5pt] G\,\mathrel {::=}& A \,\vert \, tt \,\vert \, G_1\vee G_2\,\vert \, G_1\wedge G_2\,\vert \,\exists x:\tau . G \,\vert \,\forall x:\tau . G\,\vert \, A\supset G \end {array} \end{equation*}
The
 $D$
-formulas are also called program clauses and definite clauses while
$D$
-formulas are also called program clauses and definite clauses while
 $G$
-formulas are goal formulas. We will omit type information when not relevant. Here,
$G$
-formulas are goal formulas. We will omit type information when not relevant. Here,
 $A$
is a schematic variable that ranges over atomic formulas. Given the
$A$
is a schematic variable that ranges over atomic formulas. Given the
 $D$
-formula
$D$
-formula
 $\forall x_1\ldots \forall x_n[G\supset A]$
, we say that
$\forall x_1\ldots \forall x_n[G\supset A]$
, we say that
 $G$
is the body and
$G$
is the body and
 $A$
is the head of that program clause. In general, every
$A$
is the head of that program clause. In general, every
 $D$
-formula is an hereditary Harrop formula (Miller et al. Reference Miller, Nadathur, Pfenning and Scedrov1991), although the latter is a much richer set of formulas.
$D$
-formula is an hereditary Harrop formula (Miller et al. Reference Miller, Nadathur, Pfenning and Scedrov1991), although the latter is a much richer set of formulas.

Fig. 1. The
 $\lambda$
Prolog specification of five predicates.
$\lambda$
Prolog specification of five predicates.
We use
 $\lambda$
Prolog to display logic programs in this paper. For example, Figure 1 contains the Horn clause specifications of five predicates related to natural numbers and lists. The main difference between Prolog and
$\lambda$
Prolog to display logic programs in this paper. For example, Figure 1 contains the Horn clause specifications of five predicates related to natural numbers and lists. The main difference between Prolog and
 $\lambda$
Prolog that appears from this example is the fact that
$\lambda$
Prolog that appears from this example is the fact that
 $\lambda$
Prolog is explicitly polymorphically typed. Another difference is that
$\lambda$
Prolog is explicitly polymorphically typed. Another difference is that
 $\lambda$
Prolog allows goal formulas to contain universal quantification and implications.
$\lambda$
Prolog allows goal formulas to contain universal quantification and implications.
Traditionally, entailment between a logic program and a goal has been described using classical logic and a theorem proving technique called SLD-resolution refutations (Apt and van Emden Reference Apt and van Emden1982). As now common when intuitionistic (and linear) logics are used within logic programing, refutations are replaced with proofs using Gentzen’s sequent calculus (Gentzen Reference Gentzen1935). Let
 $\mathcal{P}$
be a finite set of
$\mathcal{P}$
be a finite set of
 $D$
-formulas and let
$D$
-formulas and let
 $G$
be a goal formula. We are interested in finding proofs of the sequent
$G$
be a goal formula. We are interested in finding proofs of the sequent
 ${\mathcal{P}}\longrightarrow G$
. As it has been shown in Miller et al. (Reference Miller, Nadathur, Pfenning and Scedrov1991), a simple, two-phase proof search strategy based on goal reduction and backchaining forms a complete proof system when that logic is intuitionistic logic. – for a survey of how Gentzen’s proof theory has been applied to logic programing, see Miller (Reference Miller2022). In the next section, we will write an interpreter for such sequents: the code for that interpreter is taken directly from that two-phase proof system.
${\mathcal{P}}\longrightarrow G$
. As it has been shown in Miller et al. (Reference Miller, Nadathur, Pfenning and Scedrov1991), a simple, two-phase proof search strategy based on goal reduction and backchaining forms a complete proof system when that logic is intuitionistic logic. – for a survey of how Gentzen’s proof theory has been applied to logic programing, see Miller (Reference Miller2022). In the next section, we will write an interpreter for such sequents: the code for that interpreter is taken directly from that two-phase proof system.
3 The reasoning logic RL
The specification logic SL that we presented in the previous section is not capable of proving the negation of any atomic formula. This observation is an immediate consequence of the monotoncity of SL: that is, if
 ${\mathcal{P}}\subseteq{\mathcal{P}}'$
and
${\mathcal{P}}\subseteq{\mathcal{P}}'$
and
 $A$
follows from
$A$
follows from
 $\mathcal{P}$
then
$\mathcal{P}$
then
 $A$
follows from
$A$
follows from
 ${\mathcal{P}}'$
. If
${\mathcal{P}}'$
. If
 $\neg A$
is provable from
$\neg A$
is provable from
 $\mathcal{P}$
then both
$\mathcal{P}$
then both
 $A$
and
$A$
and
 $\neg A$
are provable from
$\neg A$
are provable from
 ${\mathcal{P}}\cup \{A\}$
. Thus, we must conclude that
${\mathcal{P}}\cup \{A\}$
. Thus, we must conclude that
 ${\mathcal{P}}\cup \{A\}$
is inconsistent, but that is not possible since the set
${\mathcal{P}}\cup \{A\}$
is inconsistent, but that is not possible since the set
 ${\mathcal{P}}\cup \{A\}$
is satisfiable (interpret all the predicates to be the universally true property for their corresponding arity). For example, neither
${\mathcal{P}}\cup \{A\}$
is satisfiable (interpret all the predicates to be the universally true property for their corresponding arity). For example, neither
 $(\hbox{reverse}\,(z::nil)\,nil)$
nor its negation are provable from the clauses in Figure 1.
$(\hbox{reverse}\,(z::nil)\,nil)$
nor its negation are provable from the clauses in Figure 1.
Clearly, any PBT setting must permit proving the negation of some formulas, since, for example, a counterexample to the claim
 $\forall x.[P(x)\supset Q(x)]$
is a term
$\forall x.[P(x)\supset Q(x)]$
is a term
 $t$
such that
$t$
such that
 $P(t)$
is provable and
$P(t)$
is provable and
 $\neg Q(t)$
is provable. At least two different approaches have been used to move to a stronger logic in which such negations are provable. The Clark completion of Horn clause programs can be used for this purpose (Clark Reference Clark, Gallaire and Minker1978). An advantage of that approach is that it requires only using first-order classical logic (with an appropriate specification of equality) (Apt and Doets Reference Apt and Doets1994). A disadvantage is that it only seems to work for Horn clauses: this approach does not seem appropriate when working with intuitionistic and linear logics.
$\neg Q(t)$
is provable. At least two different approaches have been used to move to a stronger logic in which such negations are provable. The Clark completion of Horn clause programs can be used for this purpose (Clark Reference Clark, Gallaire and Minker1978). An advantage of that approach is that it requires only using first-order classical logic (with an appropriate specification of equality) (Apt and Doets Reference Apt and Doets1994). A disadvantage is that it only seems to work for Horn clauses: this approach does not seem appropriate when working with intuitionistic and linear logics.

Fig. 2. The basic interpreter for Horn clause specifications.

Fig. 3. The encoding of the Horn clause definitions of two predicates in Figure 1 as atomic formulas in RL.
In this paper, we follow an approach used in both the Abella proof assistant (Gacek et al. Reference Gacek, Miller and Nadathur2012; Baelde et al. Reference Baelde, Chaudhuri, Gacek, Miller, Nadathur, Tiu and Wang2014) and the Hybrid (Felty and Momigliano Reference Felty and Momigliano2012) library for Coq and Isabelle. In those systems, a second logic, called the reasoning logic (RL, for short), is used to give an inductive definition for the provability for a specification logic (in those cases, the specification logic is a fragment of higher-order intuitionistic logic). In particular, consider the
 $\lambda$
Prolog specification in Figure 2. Here, terms of type sl denote formulas in SL. The predicate
$\lambda$
Prolog specification in Figure 2. Here, terms of type sl denote formulas in SL. The predicate
 $\mathtt{\lt\gt}\mathtt{==}$
is used to encode the SL-level program clauses: for example, the specification in Figure 3 encodes the Horn clause programs in Figure 1. Note that we are able to simplify our specification of the
$\mathtt{\lt\gt}\mathtt{==}$
is used to encode the SL-level program clauses: for example, the specification in Figure 3 encodes the Horn clause programs in Figure 1. Note that we are able to simplify our specification of the
 $\mathtt{\lt\gt}\mathtt{==}$
predicate; the universal quantification at the RL level can be used to encode the (implicit) quantifiers in the SL level.
$\mathtt{\lt\gt}\mathtt{==}$
predicate; the universal quantification at the RL level can be used to encode the (implicit) quantifiers in the SL level.
Figure 4 contains the single clause specification of interp that corresponds to its Clark’s completion – in
 $\lambda$
Prolog, the existential quantifier
$\lambda$
Prolog, the existential quantifier
 $\exists X$
is written as sigma X. This single clause can be turned directly into the least fixed point expression displayed in Figure 5. The proof theory for RL specifications using fixed points and equality has been developing since the 1990s. Early partial steps were taken by Girard (Girard Reference Girard1992) and Schroeder-Heister (Schroeder-Heister Reference Schroeder-Heister1993). Their approach was strengthened to include least and greatest fixed points for intuitionistic logic (McDowell and Miller Reference McDowell and Miller2000; Momigliano and Tiu Reference Momigliano and Tiu2012). Applications of this fixed point logic were made to both model checking (McDowell et al. Reference McDowell, Miller and Palamidessi2003; Heath and Miller Reference Heath and Miller2019) and to interactive theorem proving (Baelde et al. Reference Baelde, Chaudhuri, Gacek, Miller, Nadathur, Tiu and Wang2014).
$\exists X$
is written as sigma X. This single clause can be turned directly into the least fixed point expression displayed in Figure 5. The proof theory for RL specifications using fixed points and equality has been developing since the 1990s. Early partial steps were taken by Girard (Girard Reference Girard1992) and Schroeder-Heister (Schroeder-Heister Reference Schroeder-Heister1993). Their approach was strengthened to include least and greatest fixed points for intuitionistic logic (McDowell and Miller Reference McDowell and Miller2000; Momigliano and Tiu Reference Momigliano and Tiu2012). Applications of this fixed point logic were made to both model checking (McDowell et al. Reference McDowell, Miller and Palamidessi2003; Heath and Miller Reference Heath and Miller2019) and to interactive theorem proving (Baelde et al. Reference Baelde, Chaudhuri, Gacek, Miller, Nadathur, Tiu and Wang2014).

Fig. 4. An equivalent specification of interp as one clause.

Fig. 5. The least fixed point expression for interp.
The proof search problem for the full RL is truly difficult to automate since proofs involving least and greatest fixed points require the proof search mechanism to invent invariants (pre- and post-fixed points), a problem which is far outside the usual logic programing search paradigm. Fortunately, for our purposes here, we will be attempting to prove simple theorems in RL that are strictly related to queries about SL formulas. In particular, we consider only the following kinds of theorems in RL. Let
 $A$
and
$A$
and
 $\mathcal{P}$
be, respectively, an atomic formula and a finite set of
$\mathcal{P}$
be, respectively, an atomic formula and a finite set of
 $D$
-formulas in SL. Also, let
$D$
-formulas in SL. Also, let
 $\hat{A}$
be the direct encodings of
$\hat{A}$
be the direct encodings of
 $A$
into a term of type sl, and let
$A$
into a term of type sl, and let
 $\hat{\mathcal{P}}$
be a set of RL atomic formulas using the
$\hat{\mathcal{P}}$
be a set of RL atomic formulas using the
 $\mathtt{\lt\gt}\mathtt{==}$
predicate that encodes the Horn clauses in
$\mathtt{\lt\gt}\mathtt{==}$
predicate that encodes the Horn clauses in
 $\mathcal{P}$
.
$\mathcal{P}$
.
-
1.
$({\mathcal{I}}\,\hat{A})$
is RL-provable from
$\hat{\mathcal{P}}$
if and only if
$A$
is SL-provable from
$\mathcal{P}$
. In addition, these are also equivalent to the fact that (interp
$\hat{A}$
) is provable from
$\hat{\mathcal{P}}$
using the logic program for the interpreter in Figure 2. This statement is proved by a simple induction on RL and SL proofs. -
2. If
$\lambda$
Prolog’s negation-as-finite-failure procedure succeeds for the goal (interp
$\hat{A}$
) with respect to the program
$\hat{\mathcal{P}}$
(using the logic program for the interpreter in Figure 2), then
$\neg ({\mathcal{I}}\,\hat{A})$
is RL-provable from
$\hat{\mathcal{P}}$
(Hallnäs and Schroeder-Heister Reference Hallnäs and Schroeder-Heister1991). In this case, there is no SL-proof of
$A$
from
$\mathcal{P}$
.













Note that the second statement above is not an equivalence: that is, there may be proofs of
 $\neg ({\mathcal{I}}\,\hat{A})$
in RL, which will not be captured by negation-as-finite-failure. For example, if
$\neg ({\mathcal{I}}\,\hat{A})$
in RL, which will not be captured by negation-as-finite-failure. For example, if
 $p$
is an atomic SL formula and
$p$
is an atomic SL formula and
 $\mathcal{P}$
is the set containing just
$\mathcal{P}$
is the set containing just
 $p\supset p$
, then the usual notion of negation-as-finite-failure will not succeed with the goal
$p\supset p$
, then the usual notion of negation-as-finite-failure will not succeed with the goal
 $\hat{p}$
and logic program containing just
$\hat{p}$
and logic program containing just
 $\hat{p}\,$
$\hat{p}\,$
 $\mathtt{\lt\gt}\mathtt{==}$
$\mathtt{\lt\gt}\mathtt{==}$
 $\,\hat{p}$
, while there would be a proof (using induction) that
$\,\hat{p}$
, while there would be a proof (using induction) that
 $\neg ({\mathcal{I}}\,\hat{p})$
.
$\neg ({\mathcal{I}}\,\hat{p})$
.
Thus, we can use
 $\lambda$
Prolog as follows. If
$\lambda$
Prolog as follows. If
 $\lambda$
Prolog proves (interp
$\lambda$
Prolog proves (interp
 $\hat{A}$
) then we know that
$\hat{A}$
) then we know that
 $A$
is provable from
$A$
is provable from
 $\mathcal{P}$
in SL. Also, if
$\mathcal{P}$
in SL. Also, if
 $\lambda$
Prolog’s negation-as-finite-failure proves that (interp
$\lambda$
Prolog’s negation-as-finite-failure proves that (interp
 $\hat{A}$
) does not hold, then we know that
$\hat{A}$
) does not hold, then we know that
 $A$
is not provable from
$A$
is not provable from
 $\mathcal{P}$
in SL. In conclusion, although
$\mathcal{P}$
in SL. In conclusion, although
 $\lambda$
Prolog has limited abilities to prove formulas in RL, it can still be used in the context of PBT where we require limited forms of inference.
$\lambda$
Prolog has limited abilities to prove formulas in RL, it can still be used in the context of PBT where we require limited forms of inference.
4 Controlling the generation of tests
4.1 Generate-and-test as a proof-search strategy
Imagine that we wish to write a relational specification for reversing lists. There are, of course, many ways to write such a specification, say
 $\mathcal{P}$
, but in every case it should be the case that if
$\mathcal{P}$
, but in every case it should be the case that if
 ${\mathcal{P}}\vdash (\hbox{reverse}\,L\,R)$
then
${\mathcal{P}}\vdash (\hbox{reverse}\,L\,R)$
then
 ${\mathcal{P}}\vdash (\hbox{reverse}\,R\,L)$
: that is, reverse is symmetric.
${\mathcal{P}}\vdash (\hbox{reverse}\,R\,L)$
: that is, reverse is symmetric.
In the RL setting that we have described in the last section, this property can be written as the formula
 \begin{equation*} \forall L\forall R. (\mathtt {interp}\,(\hbox {reverse}\,L\,R))\supset (\mathtt {interp}\,(\hbox {reverse}\,R\,L)) \end{equation*}
\begin{equation*} \forall L\forall R. (\mathtt {interp}\,(\hbox {reverse}\,L\,R))\supset (\mathtt {interp}\,(\hbox {reverse}\,R\,L)) \end{equation*}
where we forgo the
 $\hat{(\_)}$
notation. If a formula like this is provable, it is likely that the such a proof would involve finding an appropriate induction invariant (and possibly additional lemmas). In the property-based testing setting, we are willing to look, instead, for counterexamples to a proposed property. In other words, we are willing to consider searching for proofs of the negation of this formula, namely
$\hat{(\_)}$
notation. If a formula like this is provable, it is likely that the such a proof would involve finding an appropriate induction invariant (and possibly additional lemmas). In the property-based testing setting, we are willing to look, instead, for counterexamples to a proposed property. In other words, we are willing to consider searching for proofs of the negation of this formula, namely
 \begin{equation*} \exists L\exists R. (\mathtt {interp}\,(\hbox {reverse}\,L\,R))\wedge \neg (\mathtt {interp}\,(\hbox {reverse}\,R\,L)). \end{equation*}
\begin{equation*} \exists L\exists R. (\mathtt {interp}\,(\hbox {reverse}\,L\,R))\wedge \neg (\mathtt {interp}\,(\hbox {reverse}\,R\,L)). \end{equation*}
This formula might be easier to prove since it involves only standard logic programing search mechanisms. Of course, proving this second formula would mean that the first formula is not provable.
More generally, we might wish to prove a number of formulas of the form
 \begin{equation*}\forall x\colon \tau \ [(\mathtt {interp}\,(P(x))) \supset (\mathtt {interp}\,(Q(x)))]\end{equation*}
\begin{equation*}\forall x\colon \tau \ [(\mathtt {interp}\,(P(x))) \supset (\mathtt {interp}\,(Q(x)))]\end{equation*}
where both
 $P$
and
$P$
and
 $Q$
are SL-level relations (predicates) of a single argument (it is an easy matter to deal with more than one argument). Often, it can be important in this setting to move the type judgment
$Q$
are SL-level relations (predicates) of a single argument (it is an easy matter to deal with more than one argument). Often, it can be important in this setting to move the type judgment
 $x\colon \tau$
into the logic by turning the type into a predicate:
$x\colon \tau$
into the logic by turning the type into a predicate:
 $\forall x [(\mathtt{interp}\,(\tau (x)\wedge P(x))) \supset (\mathtt{interp}\,(Q(x)))]$
. As we mentioned above, it can be valuable to first attempt to find counterexamples to such formulas prior to pursuing a proof. That is, we might try to prove formulas of the form
$\forall x [(\mathtt{interp}\,(\tau (x)\wedge P(x))) \supset (\mathtt{interp}\,(Q(x)))]$
. As we mentioned above, it can be valuable to first attempt to find counterexamples to such formulas prior to pursuing a proof. That is, we might try to prove formulas of the form
 \begin{align} \exists x [(\mathtt{interp}\,(\tau (x)\wedge P(x))) \wedge \neg (\mathtt{interp}\,(Q(x)))] \end{align}
\begin{align} \exists x [(\mathtt{interp}\,(\tau (x)\wedge P(x))) \wedge \neg (\mathtt{interp}\,(Q(x)))] \end{align}
instead. If a term
 $t$
of type
$t$
of type
 $\tau$
can be discovered such that
$\tau$
can be discovered such that
 $P(t)$
holds while
$P(t)$
holds while
 $Q(t)$
does not, then one can return to the specifications in
$Q(t)$
does not, then one can return to the specifications in
 $P$
and
$P$
and
 $Q$
and revise them using the concrete evidence in
$Q$
and revise them using the concrete evidence in
 $t$
as a witness of how the specifications are wrong. The process of writing and revising relational specifications should be smoother if such counterexamples are discovered quickly and automatically.
$t$
as a witness of how the specifications are wrong. The process of writing and revising relational specifications should be smoother if such counterexamples are discovered quickly and automatically.
The search for a proof of (*) can be seen as essentially the generate-and-test paradigm that is behind much of property-based testing. In particular, a proof of (*) contains the information needed to prove
 \begin{align} \exists x [(\mathtt{interp}\,(\tau (x)\wedge P(x)))] \end{align}
\begin{align} \exists x [(\mathtt{interp}\,(\tau (x)\wedge P(x)))] \end{align}
Conversely, not every proof of (**) yields, in fact, a proof of (*). However, if we are willing to generate proofs of (**), each such proof yields a term
 $t$
such that
$t$
such that
 $[\tau (t)\wedge P(t)]$
is provable. In order to achieve a proof of (*), we only need to prove
$[\tau (t)\wedge P(t)]$
is provable. In order to achieve a proof of (*), we only need to prove
 $\neg Q(t)$
. In the proof systems used for RL, such a proof involves only negation-as-finite-failure: that is, all possible paths for proving
$\neg Q(t)$
. In the proof systems used for RL, such a proof involves only negation-as-finite-failure: that is, all possible paths for proving
 $Q(t)$
must be attempted and all of these must end in failures.
$Q(t)$
must be attempted and all of these must end in failures.
Of course, there can be many possible terms
 $t$
that are generated in the first steps of this process. We next show how the notion of a proof certificate can be used to flexibly constraint the space of terms that can generated for consideration against the testing phase.
$t$
that are generated in the first steps of this process. We next show how the notion of a proof certificate can be used to flexibly constraint the space of terms that can generated for consideration against the testing phase.
4.2 Proof certificate checking with expert predicates
Recall that we assume that the SL is limited so that
 $D$
-formulas are Horn clauses. We shall consider the full range of
$D$
-formulas are Horn clauses. We shall consider the full range of
 $D$
and
$D$
and
 $G$
-formulas in Section 6 when we examine PBT for meta-programing.
$G$
-formulas in Section 6 when we examine PBT for meta-programing.

Fig. 6. A proof system augmented with proof certificates and expert predicates.

Fig. 7. A simple proof-checking kernel.
Figure 6 contains a simple proof system for Horn clause provability that is augmented with proof certificates (using the schematic variable
 $\Xi$
) and additional premises involving expert predicates. The intended meaning of these augmentations is the following: proof certificates contain some description of a proof. That outline might be detailed or it might just provide some hints or constraints on the proofs it describes. The expert predicates provide additional premises that are used to “extract” information from proof certificates (in the case of
$\Xi$
) and additional premises involving expert predicates. The intended meaning of these augmentations is the following: proof certificates contain some description of a proof. That outline might be detailed or it might just provide some hints or constraints on the proofs it describes. The expert predicates provide additional premises that are used to “extract” information from proof certificates (in the case of
 $\vee$
and
$\vee$
and
 $\exists$
) and to provide continuation certificates where needed.
$\exists$
) and to provide continuation certificates where needed.
Figure 7 contains the
 $\lambda$
Prolog implementation of the inference rules in Figure 6: here the infix turnstile
$\lambda$
Prolog implementation of the inference rules in Figure 6: here the infix turnstile
 $\vdash$
symbol is replaced by the check predicate and the predicates ttE, andE, orE, someE, eqE, and backchainE name the predicates
$\vdash$
symbol is replaced by the check predicate and the predicates ttE, andE, orE, someE, eqE, and backchainE name the predicates
 ${tt_e}(\cdot )$
,
${tt_e}(\cdot )$
,
 ${\wedge _e}(\cdot, \cdot, \cdot )$
,
${\wedge _e}(\cdot, \cdot, \cdot )$
,
 ${\vee _e}(\cdot, \cdot, \cdot )$
,
${\vee _e}(\cdot, \cdot, \cdot )$
,
 $\exists _e(\cdot, \cdot, \cdot )$
,
$\exists _e(\cdot, \cdot, \cdot )$
,
 ${=_e}(\cdot )$
, and
${=_e}(\cdot )$
, and
 ${\hbox{backchain}_e}(\cdot, \cdot, \cdot )$
used as premises in the inference rules in Figure 6. The intended meaning of the predicate check Cert G is that there exists a proof of G from the Horn clauses in
${\hbox{backchain}_e}(\cdot, \cdot, \cdot )$
used as premises in the inference rules in Figure 6. The intended meaning of the predicate check Cert G is that there exists a proof of G from the Horn clauses in
 $\mathcal{P}$
that fits the outline prescribed by the proof certificate Cert. Note that it is easy to show that no matter how the expert predicates are defined, if the goal check Cert G is provable in
$\mathcal{P}$
that fits the outline prescribed by the proof certificate Cert. Note that it is easy to show that no matter how the expert predicates are defined, if the goal check Cert G is provable in
 $\lambda$
Prolog then the goal interp G is provable in
$\lambda$
Prolog then the goal interp G is provable in
 $\lambda$
Prolog and, therefore, G is a consequence of the program clauses stored in
$\lambda$
Prolog and, therefore, G is a consequence of the program clauses stored in
 $\mathcal{P}$
.
$\mathcal{P}$
.
A proof certificate is a term of type cert (see Figure 7) and an FPC is a logic program that specifies the meaning of the (six) expert predicates. Two useful proof certificates are based on the measurements of the height and the size of a proof. In our examples here, we choose to only count the invocations of the backchainE predicate when defining these measurements. (One could also choose to count the invocations of all or some other subset of expert predicates.) The height measurement counts the maximum number of backchains on branches in a proof.Footnote
1
The size measurement counts the total number of backchain steps within a given proof. Proof certificates based on these two measurements are specified in Figure 8 with the declaration of two constructors for certificates and the listing of clauses describing how the expert predicates treat certificates based on these two measurements. Specifically, the first FPC defines the experts for treating certificates that are constructed using the height constructor. As is easy to verify, the query ?- check (height 5) G (for the encoding G of a goal formula) is provable in
 $\lambda$
Prolog using the clauses in Figures 7 and 8 if and only if the height of that proof is 5 or less. Similarly, the second FPC uses the constructor szeFootnote 2 (with two integers) and can be used to bound the total number of instances of backchaining steps in a proof. In particular, the query ?- sigma H\ check (sze 5 H) G is provable if and only if the total number is 5 or less.
$\lambda$
Prolog using the clauses in Figures 7 and 8 if and only if the height of that proof is 5 or less. Similarly, the second FPC uses the constructor szeFootnote 2 (with two integers) and can be used to bound the total number of instances of backchaining steps in a proof. In particular, the query ?- sigma H\ check (sze 5 H) G is provable if and only if the total number is 5 or less.

Fig. 8. Two FPCs that describe proofs that are limited in either height or in size.

Fig. 9. The max FPC.
Figure 9 contains the FPC based on the constructor max that is used to record explicitly all information within a proof, not unlike a proof-term in type theory: in particular, all disjunctive choices and all substitution instances for existential quantifiers are collected into a binary tree structure of type max. In this sense, proof certificates built with this constructor are maximally explicit. Such proof certificates are used, for example, in Blanco et al. Reference Blanco, Chihani and Miller(2017); it is important to note that proof checking with such maximally explicit certificates can be done with much simpler proof-checkers than those used in logic programing since backtracking search and unification are not needed.
A characteristic of the FPCs that we have presented here is that none contain the substitution terms used in backchaining. At the same time, they may choose to explicitly store substitution information for the existential quantifiers in goals (see the max FPC above). While there is no problem in reorganizing our setting so that the substitution instances used in the backchaining inference are stored explicitly (see, e.g., Chihani et al. Reference Chihani, Miller and Renaud2017), we find our particular design convenient. Furthermore, if we wish to record all the substitution instances used in a proof, we can write logic programs in the Clark completion style. In that case, all substitutions used in specifying backchaining are also captured by explicit existential quantifiers in the body of those clauses.
If we view a particular FPC as a means of restricting proofs, it is possible to build an FPC that restricts proofs satisfying two FPCs simultaneously. In particular, Figure 10 defines an FPC based on the (infix) constructor
 $\mathtt{\lt}\mathtt{c}\mathtt{\gt}$
, which pairs two terms of type cert. The pairing experts for the certificate Cert1
$\mathtt{\lt}\mathtt{c}\mathtt{\gt}$
, which pairs two terms of type cert. The pairing experts for the certificate Cert1
 $\mathtt{\lt}\mathtt{c}\mathtt{\gt}$
Cert2 simply request that the corresponding experts succeed for both Cert1 and Cert2 and, in the case of the orE and someE, also return the same choice and substitution term, respectively. Thus, the query
$\mathtt{\lt}\mathtt{c}\mathtt{\gt}$
Cert2 simply request that the corresponding experts succeed for both Cert1 and Cert2 and, in the case of the orE and someE, also return the same choice and substitution term, respectively. Thus, the query
?- check ((height 4)
 $\mathtt{\lt}\mathtt{c}\mathtt{\gt}$
(sze 10 H)) G
$\mathtt{\lt}\mathtt{c}\mathtt{\gt}$
(sze 10 H)) G
will succeed if there is a proof of G that has a height less than or equal to 4 while also being of size less than or equal to 10. A related use of the pairing of two proof certificates is to distill or elaborate proof certificates. For example, the proof certificate (sze 5 0) is rather implicit since it will match any proof that used backchain exactly 5 times. However, the query
?- check ((sze 5 0)
 $\mathtt{\lt}\mathtt{c}\mathtt{\gt}$
(max Max)) G.
$\mathtt{\lt}\mathtt{c}\mathtt{\gt}$
(max Max)) G.
will store into the
 $\lambda$
Prolog variable Max more complete details of any proof that satisfies the (sze 5 0) constraint. These maximal certificates are an appropriate starting point for documenting both the counterexample and why it serves as such. In particular, this forms the infrastructure of an explanation tool for attributing “blame” for the origin of a counterexample.
$\lambda$
Prolog variable Max more complete details of any proof that satisfies the (sze 5 0) constraint. These maximal certificates are an appropriate starting point for documenting both the counterexample and why it serves as such. In particular, this forms the infrastructure of an explanation tool for attributing “blame” for the origin of a counterexample.

Fig. 10. FPC for pairing.
Various additional examples and experiments using the pairing of FPCs can be found in Blanco et al. Reference Blanco, Chihani and Miller(2017). Using similar techniques, it is possible to define FPCs that target specific types for special treatment: for example, when generating integers, only (user-defined) small integers can be inserted into counterexamples.
5 PBT as proof elaboration in the reasoning logic
The two-level logic approach resembles the use of meta-interpreters in logic programing. Particularly strong versions of such interpreters have been formalized in McDowell and Miller (Reference McDowell and Miller2002),Gacek et al. Reference Gacek, Miller and Nadathur(2012) and exploited in Felty and Momigliano (Reference Felty and Momigliano2012), Baelde et al. Reference Baelde, Chaudhuri, Gacek, Miller, Nadathur, Tiu and Wang(2014). In our generate-and-test approach to PBT, the generation phase is controlled by using appropriate FPCs, and the testing phase is performed by the standard vanilla meta-interpreter (such as the one in Figure 2).
To illustrate this division between generation and testing, consider the following two simple examples. Suppose we want to falsify the assertion that the reversal of a list is equal to itself. The generation phase is steered by the predicate check, which uses a certificate (its first argument) to produce candidate lists according to a generation strategy. The testing phase performs the list reversal computation using the meta-interpreter interp, and then negates the conclusion using negation-as-finite-failure, yielding the clause:
prop_rev_id Gen Xs :-
check Gen (nlist Xs),
interp (rev Xs Ys),
not (interp (Xs eq Ys)).
If we set Gen to be say height 3, the logic programing engine will return, among others, the answer Xs = s z :: z :: nil. Note that the call to not is safe since, by the totality of rev, Ys will be ground at calling time.
As a second simple example, the testing of the symmetry of reverse can be written as:
prop_rev_sym Gen Xs :-
check Gen (nlist Xs),
interp (reverse Xs Ys),
not (interp (reverse Ys Xs)).
Unless one’s implementation of reverse is grossly mistaken, the engine should complete its search (according to the prescriptions of the generator Gen) without finding a counterexample.
We now illustrate how we can capture in our framework various flavors of PBT.
5.1 Exhaustive generation
While PBT is traditionally associated with random generation, several tools rely on exhaustive data generation up to a bound (Sullivan et al. Reference Sullivan, Yang, Coppit, Khurshid and Jackson2004) – in fact, such strategy is now the default in Isabelle/HOL’s PBT suite (Blanchette et al. Reference Blanchette, Bulwahn and Nipkow2011). In particular,
-
1. (Lazy)SmallCheck (Runciman et al. Reference Runciman, Naylor and Lindblad2008) views the bound as the nesting depth of constructors of algebraic data types.
-
2.
$\alpha$
Check (Cheney et al. Reference Cheney, Momigliano, Pessina, Aichernig and Furia2016) employs the derivation height.

Our sze and height FPCs in Figure 8, respectively, match (1) and (2) and, therefore, can accommodate both.
One minor limitation of our method is that, although check Gen P will generate terms up to the specified bound when using either sze or height for Gen, the logic programing engine will enumerate these terms in reverse order, starting from the bound and going downwards. For example, a query such as ?- prop_rev_id (height 10) Xs will return larger counterexamples first, starting here with a list of nine
 $0$
and a
$0$
and a
 $1$
. This means that if we do not have a good estimate of the dimension of our counterexample, our query may take an unnecessary long time or even loop.
$1$
. This means that if we do not have a good estimate of the dimension of our counterexample, our query may take an unnecessary long time or even loop.
A first fix uses again certificate pairing. The query
?- prop_rev_id ((height 10)
 $\mathtt{\lt}\mathtt{c}\mathtt{\gt}$
(sze 6 _)) Xs
$\mathtt{\lt}\mathtt{c}\mathtt{\gt}$
(sze 6 _)) Xs
will converge quickly to the usual minimal answer. Generally speaking, constraining the size to
 $n$
will also effectively constrain the height to be approximately
$n$
will also effectively constrain the height to be approximately
 $O(\log{n})$
. However, we still ought to have some idea about the dimension of the counterexample beforehand and this is not realistic. Yet, it is easy, thanks to logic programing, to implement a simple-minded form of iterative deepening, where we backtrack over an increasing list of bounds:
$O(\log{n})$
. However, we still ought to have some idea about the dimension of the counterexample beforehand and this is not realistic. Yet, it is easy, thanks to logic programing, to implement a simple-minded form of iterative deepening, where we backtrack over an increasing list of bounds:
prop_rev_sym_it Start End Xs :-
mk_list Start End Range,
member H Range,
check (height H) (nlist Xs),
interp (reverse Xs Ys),
not (interp (Xs eq Ys)).
Here, mk_list Start End Range holds when Start,End are positive integers and Range is the list natural numbers [Start,…,End]. In addition, we can choose to express size as a function of height – of course this can be tuned by the user, depending on the data they are working with:
prop_rev_sym_it Start End Xs :-
mk_list Start End Range,
member H Range, Sh is H * 3,
check ((height H)
 $\mathtt{\lt}\mathtt{c}\mathtt{\gt}$
(sze Sh _)) (nlist Xs),
$\mathtt{\lt}\mathtt{c}\mathtt{\gt}$
(sze Sh _)) (nlist Xs),
interp (reverse Xs Ys),
not (interp (Xs eq Ys)).
While these test generators are easy to construct, they have the drawback of recomputing candidates at each level. A better approach is to introduce an FPC for a form of iterative deepening for exact bounds, where we output only those candidates requiring that precise bound. This has some similarity with the approach in Feat (Duregård et al. Reference Duregård, Jansson and Wang2012). We will not pursue this avenue here.

Fig. 11. FPC for random generation.
5.2 Random generation
The FPC setup can be extended to support random generation of candidates. The idea is to implement a form of randomization of choice points: when a choice appears, we flip a coin to decide which case to choose. There are two major sources of choice in running a logic program: which disjunct in a disjunction to pick and which clause on which to backchain. In this subsection, we will assume that there is only one clause for backchaining: this can be done by putting clauses into their Clark-completion format. Thus, both forms of choice are represented as the selection of a disjunct within a disjunction. For example, we shall write the definitions of the isnat and nlist predicates from Figure 3 as follows.

In these two examples, the body of clauses is written as a list of disjunctions: that is, the body of such clauses is written as
 \begin{equation*} D_1\mathtt { or } D_2\mathtt { or } \cdots D_n\mathtt { or ff}, \end{equation*}
\begin{equation*} D_1\mathtt { or } D_2\mathtt { or } \cdots D_n\mathtt { or ff}, \end{equation*}
where
 $n\ge 1$
and
$n\ge 1$
and
 $D_1, \ldots, D_n$
are formulas that are not disjunctions – here, false, written as ff, represents the empty list of disjunctions. This choice of writing the body of clauses will make it easier to specify a probability distribution to the disjunctions
$D_1, \ldots, D_n$
are formulas that are not disjunctions – here, false, written as ff, represents the empty list of disjunctions. This choice of writing the body of clauses will make it easier to specify a probability distribution to the disjunctions
 $D_1, \ldots, D_n$
, see the FPC defined in Figure 12.
$D_1, \ldots, D_n$
, see the FPC defined in Figure 12.
A simple FPC given by the constructor random is described in Figure 11. Here, we assume that the predicate next_bit can access a stream of random bits.
A more useful random test generator is based on a certificate instructing the kernel to select disjunctions according to certain probability distributions. The user can specify such a distribution in a list of weights assigned to each disjunction. In the examples we consider here, these disjuncts appear only at the top level of the body of the clause defining a given predicate. When the kernel encounters an atomic formula, the backchain expert backchainE is responsible for expanding that atomic formula into its definition, which is why the expert is indexed by an atom. At this stage, it is necessary to consider the list of weights assigned to individual predicates.

Fig. 12. An FPC that selects randomly from a weighted disjunct.
Consider the FPC specification in Figure 12. This certificate has two constructors: the constant noweight indicates that no weights are enforced at this part of the certificate. The other certificate is of the form cases Rnd Ws Acc, where Rnd is a random number (between 0 and 127 inclusively), Ws are the remaining weights for the other disjunctions, and Acc is the accumulation of the weights that have been skipped at this point in the proof-checking process. The value of this certificate is initialized (by the backchainE expert) to be cases Rnd Ws 0 using the random 7-bit number Rnd (which can be computed by calling next_bit seven times) and a list of weights Ws stored in the weights predicate associated to the atomic formula that is being unfolded.
The weights (Figure 12) used here for nat-atoms select the first disjunction (for zero) one time out of four and select the successor clause in the remaining cases. Thus, this weighting scheme favors selecting small natural numbers. The weighting scheme for nlist similarly favors short lists. For example, the queryFootnote 3
?- iterate 5, check noweight (nlist L).
would then generate the following stream of five lists of natural numbers (depending, of course, on the random stream of bits provided).
L = nil
L = nil
L = s (s (s (s (s (s z))))) :: s (s (s (s (s (s (s z)))))) :: z ::
s (s z) :: s (s (s z)) :: s z :: s z ::
s (s (s (s (s (s (s (s (s (s (s (s (s (s z))))))))))))) ::
s z :: z :: nil
L = s z :: z :: z :: s z :: s (s (s (s (s (s (s (s z))))))) :: nil
L = s z :: s (s (s (s (s (s z))))) :: nil
As an example of using such randomize test case generation, the query
?- iterate 10, check noweight (nlist L),
interp (reverse L R),
not (interp (reverse R L))).
will test the property that reverse is a symmetric relation on 10 randomly selected short lists of small numbers.
As we mention in Section 8, this is but one strategy for random generation and quite possibly not the most efficient one, as the experiments in Blanco et al. Reference Blanco, Miller and Momigliano(2019) indicate. In fact, programing random generators is an art (Hritcu et al. Reference Hritcu, Hughes, Pierce, Spector-Zabusky, Vytiniotis, Azevedo de Amorim and Lampropoulos2013; Fetscher et al. Reference Fetscher, Claessen, Palka, Hughes and Findler2015; Lampropoulos et al. Reference Lampropoulos, Paraskevopoulou and Pierce2018) in every PBT approach. We can, of course, use the pairing of FPCs (Figure 10) to help filter and fully elaborate structures generated using the randomization techniques mentioned above.
5.3 Shrinking
Randomly generated data that raise counterexamples may be too large to be the starting point of the often frustrating process of bug-fixing. For a compelling example, look no further than the run of the information-flow abstract machine described in Hritcu et al. Reference Hritcu, Hughes, Pierce, Spector-Zabusky, Vytiniotis, Azevedo de Amorim and Lampropoulos(2013). For our much simpler example, there is certainly a smaller counterexample than the above for our running property, say z :: s z :: nil.
Clearly, it is desirable to find automatically such smaller counterexamples. This phase is known as shrinking and consists of creating a number of smaller variants of the bug-triggering data. These variants are then tested to determine if they induce a failure. If that is the case, the shrinking process can be repeated until we get to a local minimum. In the QuickCheck tradition, shrinkers, as well as custom generators, are the user’s responsibility, in the sense that PBT tools offer little support for their formulation. This is particularly painful when we need to shrink modulo some invariant, for example well-typed terms or meaningful sequences of machine instructions.

Fig. 13. An FPC for collecting substitution terms from proof and a predicate to compute subterm.
One way to describe shrinking using FPCs is to consider the following outline.
Step 1: Collect all substitution terms in an existing proof.
Given a successful proof that a counterexample exists, use the collect FPC in Figure 13 to extract the list of terms instantiating the existentials in that proof. Note that this FPC formally collects a list of terms of different types, in our running example nat and list nat: we accommodate such a collection by providing constructors (e.g., c_nat and c_list_nat) that map each of these types into the type item. Since the third argument of the someE expert predicate can be of any type, we use the ad hoc polymorphism available in
 $\lambda$
Prolog (Nadathur and Pfenning Reference Nadathur, Pfenning and Pfenning1992) to specify different clauses for this expert depending on the type of the term in that position: this allows us to choose different coercion constructors to inject all these terms into the one type item.
$\lambda$
Prolog (Nadathur and Pfenning Reference Nadathur, Pfenning and Pfenning1992) to specify different clauses for this expert depending on the type of the term in that position: this allows us to choose different coercion constructors to inject all these terms into the one type item.
For the purposes of the next step, it might be useful to remove from this list any item that is a subterm of another item in that list, where The definition of the subterm relation is given also in Figure 13.

Fig. 14. An FPC for restricting existential choices.
Step 2: Search again restricting substitution instances.
Search again for the proof of a counterexample but this time use the huniv FPC (Figure 14) that restricts the existential quantifiers to use subterms of terms collected in the first pass. (The name huniv is mnemonic for “Herbrand universe”: i.e.,, its argument is a predicate that describes the set of allowed substitution terms within the certificate.) Replacing the subterm relation with the proper-subterm relation can further constrain the search for proofs. For example, consider the following
 $\lambda$
Prolog query, where G is a formula that encodes the generator, Is is the list of terms (items) collected from the proof of a counterexample, and H is the height determined for that proof.
$\lambda$
Prolog query, where G is a formula that encodes the generator, Is is the list of terms (items) collected from the proof of a counterexample, and H is the height determined for that proof.
In this case, the variable Max will record the details of a proof that satisfies the height bound as well as instantiates the existential quantifiers with terms that were subterms of the original proof. One can also rerun this query with a lower height bound and by replacing the implemented notion of subterm with “proper subterm.” In this way, the search for proofs involving smaller but related instantiations can be used to shrink a counterexample.
6 PBT for meta-programing
We now explore how to extend PBT to the domain of meta-programing. This extension will allow us to find counterexamples to statements about the execution of functional programs or above desirable relations (such as type preservation) between the static and the dynamic semantics of a programing language. The main difficulty in treating entities such as programs as data structures within a (meta) programing settings is the treatment of bound variables. There have been many approaches to the treatment of term-level bindings within symbolic systems: they include nameless dummies (de Bruijn Reference de Bruijn1972), higher-order abstract syntax (HOAS) (Pfenning and Elliott Reference Pfenning and Elliott1988), nominal logic (Pitts Reference Pitts2003), parametric HOAS (Chlipala Reference Chlipala2008), and locally nameless (Charguéraud Reference Charguéraud2011). The approach used in
 $\lambda$
Prolog, called
$\lambda$
Prolog, called
 $\lambda$
-tree syntax (Miller Reference Miller2019), is based on the movement of binders from term-level abstractions to formula-level abstractions (i.e., quantifiers) to proof-level abstract variables (called eigenvariables in Gentzen Reference Gentzen1935). This approach to bindings is probably the oldest one, since it appears naturally when organizing Church’s Simple Theory of Types (Church Reference Church1940) within Gentzen’s sequent calculus (Gentzen Reference Gentzen1935). As we illustrate in this section, the
$\lambda$
-tree syntax (Miller Reference Miller2019), is based on the movement of binders from term-level abstractions to formula-level abstractions (i.e., quantifiers) to proof-level abstract variables (called eigenvariables in Gentzen Reference Gentzen1935). This approach to bindings is probably the oldest one, since it appears naturally when organizing Church’s Simple Theory of Types (Church Reference Church1940) within Gentzen’s sequent calculus (Gentzen Reference Gentzen1935). As we illustrate in this section, the
 $\lambda$
-tree syntax approach to bindings allows us to lift PBT to the meta-programing setting in a simple and modular manner. In what follows, we assume that the reader has a passing understanding of how
$\lambda$
-tree syntax approach to bindings allows us to lift PBT to the meta-programing setting in a simple and modular manner. In what follows, we assume that the reader has a passing understanding of how
 $\lambda$
-tree syntax is supported in frameworks such as
$\lambda$
-tree syntax is supported in frameworks such as
 $\lambda$
Prolog or Twelf (Pfenning and Schürmann Reference Pfenning and Schürmann1999).
$\lambda$
Prolog or Twelf (Pfenning and Schürmann Reference Pfenning and Schürmann1999).
The treatment of bindings in
 $\lambda$
Prolog is intimately related to including into
$\lambda$
Prolog is intimately related to including into
 $G$
-formulas universal quantification and implications. While we restricted SL in the previous two sections to Horn clauses, we now allow the full set of
$G$
-formulas universal quantification and implications. While we restricted SL in the previous two sections to Horn clauses, we now allow the full set of
 $D$
and
$D$
and
 $G$
-formulas that were defined in Section 2. To that end, we now replace the interpreter code given in Figure 2 with the specification in Figure 15. Here, the goal interp Ctx G is intended to capture the fact that G follows (in SL) from the union of the atomic formulas in Ctx and the logic programs defined by the
$G$
-formulas that were defined in Section 2. To that end, we now replace the interpreter code given in Figure 2 with the specification in Figure 15. Here, the goal interp Ctx G is intended to capture the fact that G follows (in SL) from the union of the atomic formulas in Ctx and the logic programs defined by the
 $\mathtt{\lt\gt}\mathtt{==}$
predicate.
$\mathtt{\lt\gt}\mathtt{==}$
predicate.

Fig. 15. A re-implementation of the interpreter in Figure 2 that treats implications and universal quantifiers in
 $G$
-formulas.
$G$
-formulas.

Fig. 16. A re-implementation of the FPC checker in Figure 7 that treats implications and universal quantifiers in
 $G$
-formulas.
$G$
-formulas.
Similar to the extensions made to interp, we need to extend the notion of FPC and the check program: this is given in Figure 16. Three new predicates –initE, impC, and allC – have been added to FPCs. Using the terminology of Chihani et al. Reference Chihani, Miller and Renaud(2017), the last two of these predicates are referred to as clerks instead of experts. This distinction arises from the fact that no essential information is extracted from a certificate by these predicates, whereas experts often need to make such extractions. In order to use a previously defined FPC in this setting, we simply need to provide the definition of these three definitions for the constructors used in that FPC. For example, the max and sze FPCs (see Section 4.2) are accommodated by the additional clauses listed in Figure 17.
To showcase the ease with which we handle searching for counterexamples in binding signatures, we go back in history and explore a tiny bit of the classical theory of the
 $\lambda$
-calculus, namely the Church-Rosser theorem and related notions. We recall two basic definitions, for a binary relation
$\lambda$
-calculus, namely the Church-Rosser theorem and related notions. We recall two basic definitions, for a binary relation
 $R$
and its Kleene closure
$R$
and its Kleene closure
 $R^*$
:
$R^*$
:

Given the syntax of the untyped
 $\lambda$
-calculus:
$\lambda$
-calculus:
 \begin{equation*} \begin {array}{llcl} \mbox {Terms} & M & \mathrel {::=} & x \mid \lambda {x}.\,{M} \mid {M_1}\,{M_2} \end {array} \end{equation*}
\begin{equation*} \begin {array}{llcl} \mbox {Terms} & M & \mathrel {::=} & x \mid \lambda {x}.\,{M} \mid {M_1}\,{M_2} \end {array} \end{equation*}
in Figure 18 we display the standard rules for beta reduction, consisting of the beta rule itself augmented by congruences.

Fig. 17. Additional clauses for two FPCs.
Figure 19 displays the
 $\lambda$
-tree encoding of the term structure of the untyped
$\lambda$
-tree encoding of the term structure of the untyped
 $\lambda$
-calculus as well as the specification of the inference rules in Figure 18. As it is now a staple of
$\lambda$
-calculus as well as the specification of the inference rules in Figure 18. As it is now a staple of
 $\lambda$
Prolog and similar systems, we only note how in the encoding of the beta rule, substitution is realized via meta-level application; further, in the
$\lambda$
Prolog and similar systems, we only note how in the encoding of the beta rule, substitution is realized via meta-level application; further, in the
 $\mathtt{B}-\xi$
rule we descend into an abstraction via SL-level universal quantification. The clause for generating/checking abstractions features the combination of hypothetical and parametric judgments.
$\mathtt{B}-\xi$
rule we descend into an abstraction via SL-level universal quantification. The clause for generating/checking abstractions features the combination of hypothetical and parametric judgments.

Fig. 18. Specifications of beta reduction and well-formed terms.

Fig. 19. The
 $\lambda$
Prolog specification of the inference rules in Figure 18.
$\lambda$
Prolog specification of the inference rules in Figure 18.
When proving the confluence of a (binary) reduction relation, a key stepping stone is the diamond property. In fact, diamond implies confluence. It is a well-known fact, however, that beta reduction does not satisfy the diamond property, since redexes can be discarded or duplicated and this is why notions such as parallel reduction have been developed (Takahashi Reference Takahashi1995).
To find a counterexample to the claim that beta reduction implies the diamond property, we write the following predicates, which abstract over a binary reduction relation.

Note that the negation-as-failure call is safe since, when the last goal is called, all variables in it will be bound to closed terms. A minimal counterexample found by exhaustive generation is:
M = app (lam x\ app x x) (app (lam x\ x) (lam x\ x))
or, using the identity combinators, the term
 $(\lambda x.\ x\ x) (I\ I)$
, which beta reduces to
$(\lambda x.\ x\ x) (I\ I)$
, which beta reduces to
 $ (I\ I) (I\ I)$
and
$ (I\ I) (I\ I)$
and
 $ (I\ I)$
.
$ (I\ I)$
.
It is worth keeping in mind that the property holds true had we defined Step to be the reflexive-transitive closure of beta reduction, or other relations of interest, such as parallel reduction or complete developments. The code in the repository provides implementations of these relations. As expected, such queries do not report any counterexample, up to a reasonable bound.
Let us dive further by looking at
 $\eta$
-reduction in a typed setting. Again, it is well-know (see, e.g. Selinger Reference Selinger2008) that the diamond property fails for
$\eta$
-reduction in a typed setting. Again, it is well-know (see, e.g. Selinger Reference Selinger2008) that the diamond property fails for
 $\beta \eta$
-reduction for the simply-typed
$\beta \eta$
-reduction for the simply-typed
 $\lambda$
-calculus, once we add unit and pairs: the main culprit is the
$\lambda$
-calculus, once we add unit and pairs: the main culprit is the
 $\eta$
rule for unit, which licenses any term of type unit to
$\eta$
rule for unit, which licenses any term of type unit to
 $\eta$
-reduce to the empty pair. Verifying the existence of such counterexamples requires building-in typing obligations in the reduction semantics, following the style of Goguen (Reference Goguen1995). In fact, it is not enough for the generation phase to yield only well-typed terms, lest we meet false positives.
$\eta$
-reduce to the empty pair. Verifying the existence of such counterexamples requires building-in typing obligations in the reduction semantics, following the style of Goguen (Reference Goguen1995). In fact, it is not enough for the generation phase to yield only well-typed terms, lest we meet false positives.
Since a counterexample manifests itself considering only
 $\eta$
and unit, we list in Figure 20 the
$\eta$
and unit, we list in Figure 20 the
 $\eta$
rules restricted to arrow and unit; see Figure 21 for their implementation.
$\eta$
rules restricted to arrow and unit; see Figure 21 for their implementation.

Fig. 20. Type-directed
 $\eta$
-reduction.
$\eta$
-reduction.

Fig. 21. The
 $\lambda$
Prolog specification of the inference rules in Figure 20.
$\lambda$
Prolog specification of the inference rules in Figure 20.
A first order of business is to ensure that the typing annotations that we have added to the reduction semantics are consistent with the standard typing rules. In other words, we need to verify that eta reduction preserves typing. The encoding of the property
 \begin{equation*} \Gamma \vdash M \longrightarrow _{\eta } M' : A \Longrightarrow \Gamma \vdash M : A \land \Gamma \vdash M' : A \end{equation*}
\begin{equation*} \Gamma \vdash M \longrightarrow _{\eta } M' : A \Longrightarrow \Gamma \vdash M : A \land \Gamma \vdash M' : A \end{equation*}
is the following and does not report any problem.
wt_pres M M’ A
 $\mathtt{\lt\gt}\mathtt{==}$
(wt M A) and (wt M’ A).
$\mathtt{\lt\gt}\mathtt{==}$
(wt M A) and (wt M’ A).
prop_eta_pres Gen M M’ A:-
check Gen nil (is_exp M),
interp nil (teta M M’ A),
not (interp nil (wt_pres M M’ A)).
However, suppose we made a small mistake in the rules in Figure 20, say forget a typing assumption in a congruence rule:
 \begin{equation*} \frac {\Gamma \vdash M\,N \longrightarrow _{\eta } M'\,N : B}{{\Gamma \vdash M \longrightarrow _{\eta } M' : A \rightarrow B}}\mathtt {E-App-L}-\mathtt {BUG} \end{equation*}
\begin{equation*} \frac {\Gamma \vdash M\,N \longrightarrow _{\eta } M'\,N : B}{{\Gamma \vdash M \longrightarrow _{\eta } M' : A \rightarrow B}}\mathtt {E-App-L}-\mathtt {BUG} \end{equation*}
then type preservation is refuted with the following counterexample.
A = unitTy
N = app (lam (x\ unit)) (lam (x\ x))
M = app (lam (x\ x)) (lam (x\ x))
A failed attempt of an inductive proof of this property in a proof assistant would have eventually pointed to the missing assumption, but testing is certainly a faster way to discover this mistake.
We can now refute the diamond property for
 $\eta$
. The harness is the obvious extension of the previous definitions, where to foster better coverage we only generate well-typed terms:
$\eta$
. The harness is the obvious extension of the previous definitions, where to foster better coverage we only generate well-typed terms:

One counterexample found by exhaustive generation is lam x\ lam y\ (app x y), which, at type (unitTy -
 $\mathtt{\gt}$
unitTy) -
$\mathtt{\gt}$
unitTy) -
 $\mathtt{\gt}$
unitTy -
$\mathtt{\gt}$
unitTy -
 $\mathtt{\gt}$
unitTy, reduces to lam (x\ x) by the
$\mathtt{\gt}$
unitTy, reduces to lam (x\ x) by the
 $\eta$
rule and lam x\ lam y\ unit by
$\eta$
rule and lam x\ lam y\ unit by
 $\eta -\mathbf{1}$
.
$\eta -\mathbf{1}$
.
7 Linear logic as the specification logic
One of linear logic’s early promises was that it could help in specifying computational systems with side-effects, exceptions, and concurrency (Girard Reference Girard1987). In support of that promise, an early application of linear logic was to enhance big-step operational semantic specifications (Kahn Reference Kahn1987) for programing languages that incorporated such features: see, for example, Andreoli and Pareschi (Reference Andreoli and Pareschi1990), Hodas and Miller (Reference Hodas and Miller1994), Chirimar (Reference Chirimar1995), Miller (Reference Miller1996), Pfenning (Reference Pfenning2000). In this section, we adapt the work in Mantovani and Momigliano (Reference Mantovani and Momigliano2021) to show how PBT can be applied in the setting where the specification logic is a fragment of linear logic.
7.1 SL as a subset of linear logic
We extend the definition of SL given in Section 2 to involve the following grammar for
 $D$
and
$D$
and
 $G$
-formulas.
$G$
-formulas.
 \begin{equation*} \begin {array}[t]{rl} D\,\mathrel {::=}& G \multimap A \,\vert \, \forall x:\tau . D\\[5pt] G\,\mathrel {::=}& A \,\vert \, tt \,\vert \, G_1\vee G_2\,\vert \, G_1\wedge G_2\,\vert \,\exists x:\tau . G \,\vert \,\forall x:\tau . G\,\vert \, A\supset G\\[5pt] & \kern 8pt\,\vert \, A\multimap G \,\vert \, ! G \end {array} \end{equation*}
\begin{equation*} \begin {array}[t]{rl} D\,\mathrel {::=}& G \multimap A \,\vert \, \forall x:\tau . D\\[5pt] G\,\mathrel {::=}& A \,\vert \, tt \,\vert \, G_1\vee G_2\,\vert \, G_1\wedge G_2\,\vert \,\exists x:\tau . G \,\vert \,\forall x:\tau . G\,\vert \, A\supset G\\[5pt] & \kern 8pt\,\vert \, A\multimap G \,\vert \, ! G \end {array} \end{equation*}
That is, we allow
 $G$
-formulas to be formed using the linear implications
$G$
-formulas to be formed using the linear implications
 $\multimap$
(with atomic antecedents) and the exponential
$\multimap$
(with atomic antecedents) and the exponential
 $!$
. As the reader might be aware, linear logic has two conjunctions (& and
$!$
. As the reader might be aware, linear logic has two conjunctions (& and
 $\otimes$
) and two disjunctions (& and
$\otimes$
) and two disjunctions (& and
 $\oplus$
). When we view
$\oplus$
). When we view
 $G$
-formulas in terms of linear logic, we identify
$G$
-formulas in terms of linear logic, we identify
 $\vee$
as
$\vee$
as
 $\oplus$
and
$\oplus$
and
 $\wedge$
as
$\wedge$
as
 $\otimes$
(and
$\otimes$
(and
 $tt$
as the unit of
$tt$
as the unit of
 $\otimes$
). Note that we have also changed the top-level implication for
$\otimes$
). Note that we have also changed the top-level implication for
 $D$
-formulas into a linear implication: this change is actually a refinement in the sense that
$D$
-formulas into a linear implication: this change is actually a refinement in the sense that
 $\multimap$
is a more precise form of the top-level implications of
$\multimap$
is a more precise form of the top-level implications of
 $D$
-formulas.
$D$
-formulas.

Fig. 22. A sequent calculus proof system for our linear SL.
A proof system for this specification logic is given in Figure 22: here,
 $\mathcal{P}$
is a set of closed
$\mathcal{P}$
is a set of closed
 $D$
-formulas. The sequent
$D$
-formulas. The sequent
 ${\Gamma };{\Delta }\vdash{G}$
has a left-hand side that is divided into two zones. The
${\Gamma };{\Delta }\vdash{G}$
has a left-hand side that is divided into two zones. The
 $\Gamma$
zone is the unbounded zone, meaning that the atomic assumptions that it contains can be used any number of times in building this proof; it can be seen as a set. The
$\Gamma$
zone is the unbounded zone, meaning that the atomic assumptions that it contains can be used any number of times in building this proof; it can be seen as a set. The
 $\Delta$
zone is the bounded zone, meaning that its atomic assumptions must be used exactly once in building this proof; it can be seen as a multiset. To ensure the accurate accounting of formulas in the bounded zone, the zone must satisfy three conditions: it must be empty in certain rules (the empty zone is denoted by
$\Delta$
zone is the bounded zone, meaning that its atomic assumptions must be used exactly once in building this proof; it can be seen as a multiset. To ensure the accurate accounting of formulas in the bounded zone, the zone must satisfy three conditions: it must be empty in certain rules (the empty zone is denoted by
 $\cdot$
), it must contain exactly one formula (as in the two initial rules displayed in the last row of inference rules), and it must be split when handling a conjunctive goal. Also note that (when reading inference rules from conclusion to premises) a goal of the form
$\cdot$
), it must contain exactly one formula (as in the two initial rules displayed in the last row of inference rules), and it must be split when handling a conjunctive goal. Also note that (when reading inference rules from conclusion to premises) a goal of the form
 $A\supset G$
places its assumption
$A\supset G$
places its assumption
 $A$
in the unbounded zone and a goal of the form
$A$
in the unbounded zone and a goal of the form
 $A\multimap G$
places its assumption
$A\multimap G$
places its assumption
 $A$
in the bounded zone. Finally, the goal
$A$
in the bounded zone. Finally, the goal
 $! G$
can only be proved if the bounded zone is empty: this is the promotion rule of linear logic.
$! G$
can only be proved if the bounded zone is empty: this is the promotion rule of linear logic.

Fig. 23. The I/O proof system.
The inference rule for
 $\wedge$
can be expensive to realize in a proof search setting, since, when we read inference rules from conclusion to premises, it requires splitting the bounded zone into two multisets before proceeding with the proof. Unfortunately, at the time that this split is made, it might not be clear which atoms in the bounded zone will be needed to prove the left premise and which are needed to prove the right premise. If the bounded zone contains
$\wedge$
can be expensive to realize in a proof search setting, since, when we read inference rules from conclusion to premises, it requires splitting the bounded zone into two multisets before proceeding with the proof. Unfortunately, at the time that this split is made, it might not be clear which atoms in the bounded zone will be needed to prove the left premise and which are needed to prove the right premise. If the bounded zone contains
 $n$
distinct items, there are
$n$
distinct items, there are
 $2^n$
possible ways to make such a split: thus, considering all splittings is far from desirable. Figure 23 presents a different proof system, known as the I/O system (Hodas and Miller Reference Hodas and Miller1994), that is organized around making this split in a lazy fashion. Here, the sequents are of the form
$2^n$
possible ways to make such a split: thus, considering all splittings is far from desirable. Figure 23 presents a different proof system, known as the I/O system (Hodas and Miller Reference Hodas and Miller1994), that is organized around making this split in a lazy fashion. Here, the sequents are of the form
 ${\Delta _I}\setminus{\Delta _O} \vdash{G}$
where
${\Delta _I}\setminus{\Delta _O} \vdash{G}$
where
 $\Delta _I$
and
$\Delta _I$
and
 $\Delta _O$
are lists of items that are of the form
$\Delta _O$
are lists of items that are of the form
 $\square$
,
$\square$
,
 $A$
, and
$A$
, and
 $! A$
(where
$! A$
(where
 $A$
is an atomic formula).
$A$
is an atomic formula).
The idea behind proving the sequent
 ${\Delta _I}\setminus{\Delta _O} \vdash{G}$
is that all the formulas in
${\Delta _I}\setminus{\Delta _O} \vdash{G}$
is that all the formulas in
 $\Delta _I$
are input to the proof search process for finding a proof of
$\Delta _I$
are input to the proof search process for finding a proof of
 $G$
: in that process, atoms in
$G$
: in that process, atoms in
 $\Delta _I$
that are not marked by a
$\Delta _I$
that are not marked by a
 $!$
and that are used in building that proof are then deleted (by replacing them with
$!$
and that are used in building that proof are then deleted (by replacing them with
 $\square$
). That proof search method outputs
$\square$
). That proof search method outputs
 $\Delta _O$
as a result of such a deletion. Thus, the process of proving
$\Delta _O$
as a result of such a deletion. Thus, the process of proving
 ${\Delta _I}\setminus{\Delta _O} \vdash{G_1\otimes G_2}$
involves sending the full context
${\Delta _I}\setminus{\Delta _O} \vdash{G_1\otimes G_2}$
involves sending the full context
 $\Delta _I$
into the process of finding a proof of
$\Delta _I$
into the process of finding a proof of
 $G_1$
, which returns the output context
$G_1$
, which returns the output context
 $\Delta _M$
, which is then made into the input for the process of finding a proof of
$\Delta _M$
, which is then made into the input for the process of finding a proof of
 $G_2$
. The correctness and completeness of this alternative proof system follows directly from results in Hodas and Miller (Reference Hodas and Miller1994). A
$G_2$
. The correctness and completeness of this alternative proof system follows directly from results in Hodas and Miller (Reference Hodas and Miller1994). A
 $\lambda$
Prolog specification of this proof system appears in Figure 24. In that specification, the input and output contexts are represented by a list of option-SL-formulas, which are of three kinds: del to denote
$\lambda$
Prolog specification of this proof system appears in Figure 24. In that specification, the input and output contexts are represented by a list of option-SL-formulas, which are of three kinds: del to denote
 $\square$
, (ubnd A) to denote
$\square$
, (ubnd A) to denote
 $! A$
, and (bnd A) to denote simply
$! A$
, and (bnd A) to denote simply
 $A$
.
$A$
.
Note that if we use this interpreter on the version of SL described in Section 2 (i.e., without occurrences of
 $\multimap$
and
$\multimap$
and
 $!$
within
$!$
within
 $G$
formulas), then the first two arguments of llinterp are always the same. If we further restrict ourselves to having only Horn clauses (i.e., they have no occurrences of implication in
$G$
formulas), then the first two arguments of llinterp are always the same. If we further restrict ourselves to having only Horn clauses (i.e., they have no occurrences of implication in
 $G$
formulas), then those first two arguments of llinterp are both nil. Given these observations, the interpreters in Figures 2 and 15 can be derived directly from the one given in Figure 24.
$G$
formulas), then those first two arguments of llinterp are both nil. Given these observations, the interpreters in Figures 2 and 15 can be derived directly from the one given in Figure 24.

Fig. 24. An interpreter based on the proof system in Figure 23.
It is a simple matter to modify the interpreter in Figure 24 in order to get the corresponding llcheck predicate that works with proof certificates. In the process of making that change, we need to add two new predicates: the clerk predicate limpC to treat the linear implication and the expert predicate bangE to treat the
 $!$
operator. In order to save space, we do not display the clauses for the llcheck predicate.
$!$
operator. In order to save space, we do not display the clauses for the llcheck predicate.
To exemplify derivations and refutations with linear logic programing, consider the following specification of the predicate that relates two lists if and only if they are permutations of each other.

As the reader can verify, the goal
?- llinterp nil nil (perm [1,2,3] K).
will produce six solutions for the list K and they will all be permutations of [1,2,3].
A property that should hold of any definition of permutation is that the latter preserves list membership:
perm_pres Cert PermDef L K :-
llcheck Cert nil nil (nlist L),
member X L,
llinterp nil nil (PermDef L K),
not (member X K).
Note the interplay of the various levels in this property:
-
1. We generate (ephemeral) lists of natural numbers using the interpreter for linear logic (llcheck): however, the specification for nlist makes use of only intuitionistic connectives.
-
2. The member predicate is the standard
$\lambda$
Prolog predicate. -
3. The test expects a definition of permutation to be interpreted linearly.

Suppose now we made a mistake in the definition of load confusing linear with intuitionistic implication:
A call to the checker with goal perm_pres (height 2) (perm’ L K) would separate the good from the bad implementation with counterexample:
K = nil
L = z :: nil
7.2 The operational semantics of
$\lambda$
-terms with a counter

Figure 25 contains the SL specification of call-by-value and call-by-name big-step operational semantics for a version of the
 $\lambda$
-calculus to which a single memory location (a counter) is added.Footnote
4
The untyped
$\lambda$
-calculus to which a single memory location (a counter) is added.Footnote
4
The untyped
 $\lambda$
-calculus of Section 6, with its two constructors app and lam, is extended with the additional four constants.
$\lambda$
-calculus of Section 6, with its two constructors app and lam, is extended with the additional four constants.

Fig. 25. Specifications of call-by-name (cbn) and call-by-value (cbv) evaluations.

The specification in Figure 25 uses continuations to provide for a sequencing of operations. A continuation is an SL goal formula that should be called once the program getting evaluated is completed. For example, the attempt to prove the goal cbn M V K when the bounded zone is the multiset containing only the formula
 ${{counter}}\,C$
(for some integer
${{counter}}\,C$
(for some integer
 $C$
) reduces to an attempt to prove the goal K with the bounded zone consisting of just
$C$
) reduces to an attempt to prove the goal K with the bounded zone consisting of just
 ${{counter}}\,D$
(for some other integer
${{counter}}\,D$
(for some other integer
 $D$
), provided V is the call-by-name value of M. This situation can be represented as the following (open) derivation (following the rules in Figure 22).
$D$
), provided V is the call-by-name value of M. This situation can be represented as the following (open) derivation (following the rules in Figure 22).

Such a goal reduction can be captured in
 $\lambda$
Prolog using the following higher-order quantified expression
$\lambda$
Prolog using the following higher-order quantified expression
Operationally,
 $\lambda$
Prolog introduces a new eigenvariable (essentially a local constant) k of type sl and assumes that this new SL formula can be proved no matter the values of the input and output contexts. Once this assumption is made, the linear logic interpreter is called with the counter given the initial value of 0 and with the cbn evaluator asked to compute the call-by-name value of M to be V and with the final continuation being k. This hypothetical reasoning can be captured by the following predicate.
$\lambda$
Prolog introduces a new eigenvariable (essentially a local constant) k of type sl and assumes that this new SL formula can be proved no matter the values of the input and output contexts. Once this assumption is made, the linear logic interpreter is called with the counter given the initial value of 0 and with the cbn evaluator asked to compute the call-by-name value of M to be V and with the final continuation being k. This hypothetical reasoning can be captured by the following predicate.

It is well known that if the call-by-name and call-by-value strategies terminate when evaluating a pure untyped
 $\lambda$
-term (those without side-effects such as our counter), then those two strategies yield the same value. One might conjecture that this is also true once counters are added. To probe that conjecture, we write the following logic program:
$\lambda$
-term (those without side-effects such as our counter), then those two strategies yield the same value. One might conjecture that this is also true once counters are added. To probe that conjecture, we write the following logic program:

The query ?- prop_cbnv (height 3) M V U returns the smallest counterexample to the claim that call-by-name and call-by-value produce the same values in this setting. In particular, this query instantiates M with app (lam (w get)) (set (- 1)): this expression has the call-by-name value of 0 while the it has a call-by-value value of
 $-1$
, given the generator is_prog in Figure 25.
$-1$
, given the generator is_prog in Figure 25.
7.3 Queries over linear
$\lambda$
-expressions

A slight variation to is_exp (Figure 19) yields the following SL specification that succeeds with a
 $\lambda$
-term only when the bindings are used linearly.
$\lambda$
-term only when the bindings are used linearly.

Using this predicate and others defined in Section 6, it is an easy matter to search for untyped
 $\lambda$
-terms with various properties. Consider, for example, the following two predicates definitions.
$\lambda$
-terms with various properties. Consider, for example, the following two predicates definitions.

The prop_pres1 predicate is designed to search for linear
 $\lambda$
-terms that are related by Step to a non-linear
$\lambda$
-terms that are related by Step to a non-linear
 $\lambda$
-term. When Step is cbn or cbv, no such term is possible. The prop_pres2 predicate is designed to search for non-linear
$\lambda$
-term. When Step is cbn or cbv, no such term is possible. The prop_pres2 predicate is designed to search for non-linear
 $\lambda$
-terms that have a simple type (via the wt predicate) and are related by Step to a linear
$\lambda$
-terms that have a simple type (via the wt predicate) and are related by Step to a linear
 $\lambda$
-term. When Step is cbn or cbv, the smallest such terms (using the certificate (height 4)) are
$\lambda$
-term. When Step is cbn or cbv, the smallest such terms (using the certificate (height 4)) are
app (lam x\ lam y\ y) (app (lam x\ x) (lam x\ x))
app (lam x\ lam y\ y) (lam x\ x)
app (lam x\ lam y\ y) (lam x\ lam y\ y)
app (lam x\ lam y\ y) (lam x\ lam y\ x)
All of these terms evaluates (using either cbn or cbv) to the term (lam x x).
8 Related and future work
8.1 Two-level logic approach
First-order Horn clauses have a long tradition, via the Prolog language, of specifying computation. Such clauses have also been used to specify the operational semantics of other programing languages: see, for example, the early work on natural semantics (Kahn Reference Kahn1987) and the Centaur system (Borras et al. Reference Borras, Clément, Despeyroux, Incerpi, Kahn, Lang and Pascual1988). The intuitionistic logic setting of higher-order hereditary Harrop formulas (Miller et al. Reference Miller, Nadathur, Pfenning and Scedrov1991) – a logical framework that significantly extends the SL logic in Section 2 – has similarly been used for the past three decades to specify the static and dynamic semantics of programing language: see, for example, Hannan and Miller (Reference Hannan and Miller1992), Hannan (Reference Hannan1993). Similar specifications could also be written in the dependently typed
 $\lambda$
-calculus LF (Harper et al. Reference Harper, Honsell and Plotkin1993); see, for example, Michaylov and Pfenning (Reference Michaylov and Pfenning1992).
$\lambda$
-calculus LF (Harper et al. Reference Harper, Honsell and Plotkin1993); see, for example, Michaylov and Pfenning (Reference Michaylov and Pfenning1992).
Linear logic has been effectively used to enrich the natural semantic framework. The Lolli subset of linear logic (Hodas and Miller Reference Hodas and Miller1994) as well as the Forum presentation (Miller Reference Miller1996) of all of linear logic have been used to specify the operational semantics of references and concurrency (Miller Reference Miller1996) as well as the behavior of the sequential and the concurrent (piped-line) operational semantics of the DLX RISC processor (Chirimar Reference Chirimar1995). Another fruitful example is the specification of session types (Caires et al. Reference Caires, Pfenning and Toninho2016). Ordered logic programing (Polakow and Yi Reference Polakow and Yi2000; Pfenning and Simmons Reference Pfenning and Simmons2009) has also been investigated. Similar specifications are also possible in linear logic-inspired variants of LF (Cervesato and Pfenning Reference Cervesato and Pfenning2002; Schack-Nielsen and Schürmann Reference Schack-Nielsen and Schürmann2008; Georges et al. Reference Georges, Murawska, Otis and Pientka2017).
The use of a separate reasoning logic to reason directly on the kind of logic specifications used in this paper was proposed in McDowell and Miller (Reference McDowell and Miller2002). That logic included certain inductive principles that could be applied to the definition of sequent calculus provability. That framework was challenged, however, by the need to treat eigenvariables in sequent calculus proof systems. The
 $\nabla$
-quantifier, introduced in Miller and Tiu (Reference Miller and Tiu2005), provided an elegant solution to the treatment of eigenvariables (Gacek et al. Reference Gacek, Miller and Nadathur(2012). In this paper, our use of the reasoning logic is mainly to determine reachability and nonreachability: in those situations, the
$\nabla$
-quantifier, introduced in Miller and Tiu (Reference Miller and Tiu2005), provided an elegant solution to the treatment of eigenvariables (Gacek et al. Reference Gacek, Miller and Nadathur(2012). In this paper, our use of the reasoning logic is mainly to determine reachability and nonreachability: in those situations, the
 $\nabla$
-quantifier can be implemented by the universal quantifier in
$\nabla$
-quantifier can be implemented by the universal quantifier in
 $\lambda$
Prolog (see Miller and Tiu Reference Miller and Tiu2005, Proposition 7.10). If we were to investigate PBT examples that go beyond that simple class of queries, then we would have to abandon
$\lambda$
Prolog (see Miller and Tiu Reference Miller and Tiu2005, Proposition 7.10). If we were to investigate PBT examples that go beyond that simple class of queries, then we would have to abandon
 $\lambda$
Prolog for the richer logic that underlies Abella (Gacek et al. Reference Gacek, Miller and Nadathur2011): see, for example, the specifications of bisimulation for the
$\lambda$
Prolog for the richer logic that underlies Abella (Gacek et al. Reference Gacek, Miller and Nadathur2011): see, for example, the specifications of bisimulation for the
 $\pi$
-calculus in Tiu and Miller (Reference Tiu and Miller2010). The two-level approach extends to reasoning over specifications in dependently typed
$\pi$
-calculus in Tiu and Miller (Reference Tiu and Miller2010). The two-level approach extends to reasoning over specifications in dependently typed
 $\lambda$
-calculus, first via the
$\lambda$
-calculus, first via the
 $\mathcal{M}_{\omega }$
reasoning logic over LF in Schürmann (Reference Schürmann2000) and then more extensively within the Beluga proof environment (Pientka and Dunfield Reference Pientka and Dunfield2010; Pientka and Cave Reference Pientka and Cave2015).
$\mathcal{M}_{\omega }$
reasoning logic over LF in Schürmann (Reference Schürmann2000) and then more extensively within the Beluga proof environment (Pientka and Dunfield Reference Pientka and Dunfield2010; Pientka and Cave Reference Pientka and Cave2015).
However, formal verification by reasoning over a linear logic frameworks, is still in its infancy, although the two-level approach is flexible enough to accommodate one reasoning logic over several SL. The most common case study is type soundness of MiniML with references, first checked in McDowell and Miller (Reference McDowell and Miller2002) with the
 $\Pi$
proof checker and then by Martin in his dissertation (Martin Reference Martin2010) using Isabelle/HOL’s Hybrid library (Felty and Momigliano Reference Felty and Momigliano2012), in several styles, including linear and ordered specifications. More extensive use of Hybrid, this time on top of Coq, includes the recent verification in a Lolli-like specification logic of type soundness of the proto-Quipper quantum functional programing language (Mahmoud and Felty Reference Mahmoud and Felty2019), as well as the meta-theory of sequent calculi (Felty et al. Reference Felty, Olarte and Xavier2021).
$\Pi$
proof checker and then by Martin in his dissertation (Martin Reference Martin2010) using Isabelle/HOL’s Hybrid library (Felty and Momigliano Reference Felty and Momigliano2012), in several styles, including linear and ordered specifications. More extensive use of Hybrid, this time on top of Coq, includes the recent verification in a Lolli-like specification logic of type soundness of the proto-Quipper quantum functional programing language (Mahmoud and Felty Reference Mahmoud and Felty2019), as well as the meta-theory of sequent calculi (Felty et al. Reference Felty, Olarte and Xavier2021).
8.2 Foundational proof certificates
The notion of foundational proof certificates was introduced in Chihani et al. Reference Chihani, Miller and Renaud(2017) as a means for flexibly describing proofs to a logic programing base proof checker (Miller Reference Miller2017). In that setting, proof certificates can include all or just certain details, whereby missing details can often be recreated during checking using unification and backtracking search. The pairing FPC in Section 4.2 can be used to elaborate a proof certificate into one including full details and to distill a detailed proof into a certificate containing less information (Blanco et al. Reference Blanco, Chihani and Miller2017).
Using this style of proof elaboration, it is possible to use the ELPI plugin to Coq (Tassi Reference Tassi2018), which supplies the Coq computing environment with a
 $\lambda$
Prolog implementation, to elaborate proof certificates from an external theorem prover into fully detailed certificates that can be checked by the Coq kernel (Manighetti et al. Reference Manighetti, Miller and Momigliano2020; Manighetti Reference Manighetti2022). This same interface between Coq and ELPI allowed Manighetti el al. to illustrate how PBT could be used to search for counterexamples to conjectures proposed to Coq.
$\lambda$
Prolog implementation, to elaborate proof certificates from an external theorem prover into fully detailed certificates that can be checked by the Coq kernel (Manighetti et al. Reference Manighetti, Miller and Momigliano2020; Manighetti Reference Manighetti2022). This same interface between Coq and ELPI allowed Manighetti el al. to illustrate how PBT could be used to search for counterexamples to conjectures proposed to Coq.
Using an FPC as a description of how to traverse a search space bears some resemblance with principled ways to change the depth-first nature of search in logic programing implementations. An example is Tor (Schrijvers et al. Reference Schrijvers, Demoen, Triska and Desouter2014), which, however, is unable to account for random search. Similarly to Tor, FPCs would benefit of partial evaluation to remove the meta-interpretive layer.
8.3 Property-based testing for meta-theory model-checking
The literature on PBT is very large and always evolving. We refer to Cheney and Momigliano (Reference Cheney and Momigliano2017) for a partial review with an emphasis to its interaction with proof assistants and specialized domains such as programing language meta-theory.
While Isabelle/HOL were at the forefront of combining theorem proving and refutations (Blanchette et al. Reference Blanchette, Bulwahn and Nipkow2011; Bulwahn Reference Bulwahn2012), nowadays most of the action is within Coq: QuickChick (Paraskevopoulou et al. Reference Paraskevopoulou, Hritcu, Dénès, Lampropoulos and Pierce2015) started as a clone of QuickCheck, but soon evolved in a major research project involving automatic generation of custom generators (Lampropoulos et al. Reference Lampropoulos, Paraskevopoulou and Pierce2018), coverage based improvements of random generation (Lampropoulos et al. Reference Lampropoulos, Hicks and Pierce2019; Goldstein et al. Reference Goldstein, Hughes, Lampropoulos and Pierce2021), as well as going beyond the executable fragment of Coq (Paraskevopoulou et al. Reference Paraskevopoulou, Eline and Lampropoulos2022).
Within the confine of model-checking PL theory, a major player is PLT-Redex (Felleisen et al. Reference Felleisen, Findler and Flatt2009), an executable DSL for mechanizing semantic models built on top of DrRacket with support for random testing à la QuickCheck; its usefulness has been demonstrated in several impressive case studies (Klein et al. Reference Klein, Clements, Dimoulas, Eastlund, Felleisen, Flatt, McCarthy, Rafkind, Tobin-Hochstadt and Findler2012). However, Redex has limited support for relational specifications and none whatsoever for binding signature. On the other hand,
 $\alpha$
Check (Cheney et al. Reference Cheney, Momigliano, Pessina, Aichernig and Furia2016; Cheney and Momigliano Reference Cheney and Momigliano2017) is built on top of the nominal logic programing language
$\alpha$
Check (Cheney et al. Reference Cheney, Momigliano, Pessina, Aichernig and Furia2016; Cheney and Momigliano Reference Cheney and Momigliano2017) is built on top of the nominal logic programing language
 $\alpha$
Prolog and it checks relational specifications similar to those considered here. Arguably,
$\alpha$
Prolog and it checks relational specifications similar to those considered here. Arguably,
 $\alpha$
Check is less flexible than the FPC-based architecture, since its generation strategy can be seen as a fixed choice of experts. The same comment applies to (Lazy)SmallCheck (Runciman et al. Reference Runciman, Naylor and Lindblad2008). In both cases, those strategies are wired-in and cannot be varied, let alone combined as we can via pairing. For a small empirical comparison between our approach and
$\alpha$
Check is less flexible than the FPC-based architecture, since its generation strategy can be seen as a fixed choice of experts. The same comment applies to (Lazy)SmallCheck (Runciman et al. Reference Runciman, Naylor and Lindblad2008). In both cases, those strategies are wired-in and cannot be varied, let alone combined as we can via pairing. For a small empirical comparison between our approach and
 $\alpha$
Check on the PLT-Redex benchmark,Footnote
5
please see Blanco et al. Reference Blanco, Miller and Momigliano(2019).
$\alpha$
Check on the PLT-Redex benchmark,Footnote
5
please see Blanco et al. Reference Blanco, Miller and Momigliano(2019).
In the random case, the logic programing paradigm has some advantages over the labor-intensive QuickCheck approach of writing custom generators. Moreover, the last few years have witnessed an increasing interest in the (random) generation of data satisfying some invariants (Claessen et al. Reference Claessen, Duregård and Palka2015; Fetscher et al. Reference Fetscher, Claessen, Palka, Hughes and Findler2015; Lampropoulos et al. Reference Lampropoulos, Paraskevopoulou and Pierce2018); in particular well-typed
 $\lambda$
-terms, with an application to testing optimizing compilers (Palka et al. Reference Palka, Claessen, Russo and Hughes2011; Midtgaard et al. Reference Midtgaard, Justesen, Kasting, Nielson and Nielson2017; Bendkowski et al. Reference Bendkowski, Grygiel and Tarau2018). Our approach can use judgments (think typing), as generators, avoiding the issue of keeping generators and predicates in sync when checking invariant-preserving properties such as type preservation (Lampropoulos et al. Reference Lampropoulos, Gallois-Wong, Hriţcu, Hughes, Pierce and Xia2017). Further, viewing random generation as expert-driven random backchaining opens up several possibilities: we have chosen just one simple-minded strategy, namely permuting the predicate definition at each unfolding, but we could easily follow others, such as the ones described in Fetscher et al. Reference Fetscher, Claessen, Palka, Hughes and Findler(2015): permuting the definition just once at the start of the generation phase, or even changing the weights at the end of the run so as to steer the derivation towards axioms/facts. Of course, our default uniform distribution corresponds to QuickCheck’s oneOf combinator, while the weights table to frequency. Moreover, pairing random and size-based FPC accounts for some of QuickCheck’s configuration options, such as StartSize and EndSize.
$\lambda$
-terms, with an application to testing optimizing compilers (Palka et al. Reference Palka, Claessen, Russo and Hughes2011; Midtgaard et al. Reference Midtgaard, Justesen, Kasting, Nielson and Nielson2017; Bendkowski et al. Reference Bendkowski, Grygiel and Tarau2018). Our approach can use judgments (think typing), as generators, avoiding the issue of keeping generators and predicates in sync when checking invariant-preserving properties such as type preservation (Lampropoulos et al. Reference Lampropoulos, Gallois-Wong, Hriţcu, Hughes, Pierce and Xia2017). Further, viewing random generation as expert-driven random backchaining opens up several possibilities: we have chosen just one simple-minded strategy, namely permuting the predicate definition at each unfolding, but we could easily follow others, such as the ones described in Fetscher et al. Reference Fetscher, Claessen, Palka, Hughes and Findler(2015): permuting the definition just once at the start of the generation phase, or even changing the weights at the end of the run so as to steer the derivation towards axioms/facts. Of course, our default uniform distribution corresponds to QuickCheck’s oneOf combinator, while the weights table to frequency. Moreover, pairing random and size-based FPC accounts for some of QuickCheck’s configuration options, such as StartSize and EndSize.
In mainstream programing, property-based testing of stateful programs is accomplished via some form of state machine (Hughes Reference Hughes2007; de Barrio et al. Reference de Barrio, Fredlund, Herranz, Earle and Mari no2021). The idea of linear PBT has been proposed in Mantovani and Momigliano (Reference Mantovani and Momigliano2021) and applied to mechanized meta-theory model checking, restricted to first-order encodings, for example the compilation of a simple imperative language to a stack machine. For efficient generation of typed linear
 $\lambda$
-terms, albeit limited to the purely implicational propositional fragment, see Tarau and de Paiva (Reference Tarau and de Paiva2020)
$\lambda$
-terms, albeit limited to the purely implicational propositional fragment, see Tarau and de Paiva (Reference Tarau and de Paiva2020)
8.4 Future work
While
 $\lambda$
Prolog is used here to discover counterexamples, one does not actually need to trust the logical soundness of
$\lambda$
Prolog is used here to discover counterexamples, one does not actually need to trust the logical soundness of
 $\lambda$
Prolog, negation-as-failure making this a complex issue. Any identified counterexample can be exported and utilized within a proof assistants such as Abella. In fact, it would be a logical future task to incorporate our perspective on PBT into Abella in order to accommodate both proofs and disproofs, as many proof helpers frequently do. As mentioned in Section 8.2, the implementation of the ELPI plugin for the Coq theorem prover (Tassi Reference Tassi2018) should allow the PBT techniques described in this paper to be applied to proposed theorems within Coq: discovering a counterexamples to a proposed theorem could save a lot of time in attempting the proof of a non-theorem.
$\lambda$
Prolog, negation-as-failure making this a complex issue. Any identified counterexample can be exported and utilized within a proof assistants such as Abella. In fact, it would be a logical future task to incorporate our perspective on PBT into Abella in order to accommodate both proofs and disproofs, as many proof helpers frequently do. As mentioned in Section 8.2, the implementation of the ELPI plugin for the Coq theorem prover (Tassi Reference Tassi2018) should allow the PBT techniques described in this paper to be applied to proposed theorems within Coq: discovering a counterexamples to a proposed theorem could save a lot of time in attempting the proof of a non-theorem.
The strategy we have outlined here serves more as a proof-of-concept or logical reconstruction than as a robust implementation. A natural environment to support PBT for every specification in Abella is the Bedwyr model-checker (Baelde et al. Reference Baelde, Gacek, Miller, Nadathur and Tiu2007), which shares the same meta-logic, but is more efficient from the point of view of proof search.
Finally, we have just hinted at ways for localizing the origin of the bugs reported by PBT. This issue can benefit from research in declarative debugging as well as in justification for logic programs (Pemmasani et al. Reference Pemmasani, Guo, Dong, Ramakrishnan and Ramakrishnan2004). Coupled with results in linking game semantics and focusing (Miller and Saurin Reference Miller and Saurin2006), this could lead us also to a reappraisal of techniques for repairing (inductive) proofs (Ireland and Bundy Reference Ireland and Bundy1996).
9 Conclusions
We have presented a framework for property-based testing whose design relies on logic programing and proof theory. This framework offers a versatile and consistent foundation for various PBT features based on relational specifications. It leverages proof outlines (i.e., incomplete proof certificates) for flexible counterexample search. It employs a single, transparent proof checker for certain subsets of classical, intuitionistic, and linear logic to elaborate proof outlines nondeterministically. Furthermore, this framework easily handles counterexamples involving bindings, making it possible to apply PBT to specifications that deal directly with programs as objects. The framework’s programmability enables specifying diverse search strategies (exhaustive, bounded, randomized) and counterexample shrinking.
Acknowledgments
We would like to thank Rob Blanco for his major contributions to Blanco et al. Reference Blanco, Miller and Momigliano(2019), on which the present paper is based. We also thank the reviewers for their comments on an earlier draft of this paper. The second author is a member of the Gruppo Nazionale Calcolo Scientifico-Istituto Nazionale di Alta Matematica (GNCS-INdAM) and he acknowledges the support of the APC central fund of the University of Milan.



































 Open access
Open access