

Cannabis is the most widely used illicit drug in developed countries (Dennis et al., Reference Dennis, Babor, Roebuck and Donaldson2002; Hall et al., Reference Hall, Johnston, Donnelly, Kalant, Corrigal, Hall and Smart1999). Population-based estimates of lifetime cannabis use in the United States between 1990 and 2004 range from 41.2% to 55.9% (Agrawal & Lynskey, Reference Agrawal and Lynskey2007; American Psychiatric Association, 1980, 1987, 1994; Edwards et al., Reference Edwards, Arif and Hadgson1981; Stinson et al., Reference Stinson, Grant, Dawson, Ruan, Huang and Saha2005; von Sydow et al., Reference von Sydow, Lieb, Pfister, Hofler, Sonntag and Wittchen2001). For cannabis use disorder (CUD) in the United States, rates of lifetime abuse range from 5.5% to 8.4%, and those of cannabis dependence span 1.3% to 2.2% (Agrawal & Lynskey, Reference Agrawal and Lynskey2007; Stinson et al., Reference Stinson, Grant, Dawson, Ruan, Huang and Saha2005; von Sydow et al., Reference von Sydow, Lieb, Pfister, Hofler, Sonntag and Wittchen2001).
A central issue concerning the Diagnostic and Statistical Manual of Mental Disorders (4th ed.) (DSM-IV) CUD criteria is whether the criteria of abuse are distinct from those for dependence (American Psychiatric Association, 1980, 1987, 1994; Edwards et al., Reference Edwards, Arif and Hadgson1981). The current consensus is that a single factor captures most of the association between DSM-IV criteria within multiple substances criteria (Feingold & Rounsaville, Reference Feingold and Rounsaville1995a, Reference Feingold and Rounsaville1995b; Gillespie et al., Reference Gillespie, Neale, Prescott, Aggen and Kendler2007; Hartman et al., Reference Hartman, Gelhorn, Crowley, Sakai, Stallings, Young and Hopfer2008; Langenbucher et al., Reference Langenbucher, Labouvie, Martin, Sanjuan, Bavly, Kirisci and Chung2004; Lynskey & Agrawal, Reference Lynskey and Agrawal2007; Nelson et al., Reference Nelson, Rehm, Ustun, Grant and Chatterji1999; Teesson et al., Reference Teesson, Lynskey, Manor and Baillie2002). These findings are reflected in DSM-5, which removed the abuse-dependence distinction along with the legal problems criterion while adding withdrawal and craving criteria. Most, but not all, of these studies (Baillie & Teesson, Reference Baillie and Teesson2010) have been based on North American samples. Replication of these findings in other populations is warranted, and it is necessary to determine whether craving and withdrawal measure the same underlying dimension of liability to CUD.
A further issue is whether other models, notably latent class or factor mixture models (FMMs), fit the data better than factor analytic models. Under the latent class model, items correlate in the population because it consists of two or more subpopulations, which differ in the probability of response to at least one of the criteria. Within each class, item response probabilities are assumed to be independent, such that, for example, the probability of endorsing a tolerance item and an abuse item is simply the product of the two response probabilities. The FMM elaborates on latent class model by allowing for non-independence of item response probabilities within each class. The differences between these models have important implications for etiology, prevention, and treatment. For example, there might exist one class of people who are asymptomatic (low loadings on all criteria), another class whose members have high on abuse but not dependence criteria, and a third class whose members are high on both abuse and dependence criteria. Under both latent class and FMMs, it is possible to compute the probability that an individual belongs to a particular class, and this may be examined by validation against external criteria, such as treatment response or environmental risk factors. Recent model fitting has found little evidence to justify the use of latent class or FMMs when describing CUD (Baillie & Teesson, Reference Baillie and Teesson2010; Gillespie et al., Reference Gillespie, Kendler and Neale2011b), but more research is needed. Muthen (Reference Muthen2006) did find that FMMs fit DSM alcohol use disorder (AUD) criteria in a selected sample better than conventional factor or latent class models, but his study was not population-based as it was performed only on the subset of respondents who endorsed criteria, and it was not a study of cannabis.
To identify the best representation of the population distribution of liability to DSM-V CUD, we apply latent common factor, latent class, and FMMs to data from a population-based sample of young adult Australians.
Methods
Participants
Data are from a population-based sample of young adult Australian twins and their non-twin siblings who are part of the ongoing Brisbane Longitudinal Twin Study (BLTS) at the Queensland Institute of Medical Research (QIMR). Described in detail elsewhere (Gillespie et al., Reference Gillespie, Henders, Davenport, Hermens, Wright, Martin and Hickie2012; Wright & Martin, Reference Wright and Martin2004), the BLTS began in 1992 when twins and their family members were recruited in the greater Brisbane area, mainly through schools, but also via media appeals and by word of mouth as part of an ongoing, multi-wave study examining the development of moles at ages 12 and 14, cognition at age 16, and psychiatric diagnoses, brain imaging, and lifestyle and behavioral assessments in their early twenties. Data for the current analyses were collected between 2009 and 2011 as part of an ongoing US National Institutes of Health/National Institute of Drug Abuse (NIH/NIDA) project to study the genetic and environmental pathways to cannabis use, abuse, and dependence. Ascertainment began with adult twins and non-twin singleton siblings from the BLTS sample in order to obtain data from individuals who had passed through the age of maximum risk for the onset of cannabis use (typically 16–18 years) and cannabis-related problems. Response rates across the BLTS projects since 1992 range from 73% to 85% (Gillespie et al., Reference Gillespie, Henders, Davenport, Hermens, Wright, Martin and Hickie2012). To date, complete data were obtained from 626 twins (367 (58.6%) females and 259 males), aged 20 to 38 years.
Measures and Reliability
A computer-assisted telephone interview (CATI) protocol was used to obtain demographic and background data, together with DSM-IV criteria for cannabis (marijuana, hashish, tetrahydrocannabinol [THC], or ganja) abuse, dependence, craving, and withdrawal. The cannabis assessment began with basic screening criteria, initiation, and frequency of use measures. Following screening for ‘Have you ever used marijuana?’ (Yes/No), only subjects who endorsed either ‘Have you used marijuana six or more times in your life?’ or ‘Have you ever used marijuana 11 or more times in a month?’ were asked the abuse, dependence, withdrawal, and craving criteria.
Following previous analyses, which showed that including screening criteria in the analyses is effective (Gillespie et al., Reference Gillespie, Kendler and Neale2011b, Reference Gillespie, Henders, Davenport, Hermens, Wright, Martin and Hickie2012), these criteria were summed and recoded onto a 3-point ordinal ‘stem’ item, which was included in all analyses. The following coding system was implemented: 0 = never tried or used for less than six times in lifetime; 1 = tried and used for six or more times in lifetime; or 2 = tried and used for 11 or more times in a month. When the stem is coded as 0, all criteria are coded as missing, rather than 0, because there is a non-zero probability that subjects would develop the criteria if they initiated cannabis use. Our rationale for including this stem item was that joint analysis of the stem and cannabis use symptoms produces asymptotically unbiased estimates of (1) the proportion of people in the population who would develop symptoms if they were to initiate cannabis (i.e., the symptom thresholds); (2) the correlation between liability to initiate use and the liability to endorse abuse and dependence criteria; and (3) correlations among the symptoms themselves (Gillespie et al., Reference Gillespie, Kendler and Neale2011b, Reference Gillespie, Henders, Davenport, Hermens, Wright, Martin and Hickie2012). This method therefore yields asymptotically unbiased estimates of factor loadings and other model parameters. Moreover, inclusion of stem score along with marginal maximum likelihood (MML) estimation produces parameter estimates that are valid for the entire population under study rather than only the subset selected to receive the symptom criteria (Kubarych et al., Reference Kubarych, Aggen, Hettema, Kendler and Neale2005). While the stem has three levels, the DSM criteria are binary.
In order to correspond to the ‘failure to fulfill major role obligations’ criterion, the two criteria, ‘used often when doing something important’ and ‘stayed away from school or missed appointments because of use’, were aggregated and scored positive if either of the symptoms was endorsed. Similarly, ‘felt sick when cutting down or stopped use’ and ‘after not using cannabis, used to prevent sickness’ were similarly aggregated to correspond to withdrawal.
Interviewer Training, Quality Control, and Informed Consent
All interviewers were selected from an experienced pool of QIMR staff who participated in a 2-week training session consisting of didactic instruction and supervised practice interviews. All interviewers conducted at least three interviews with community volunteer subjects under the supervision of a faculty trainer or senior staff member. Following consent, the CATI interviews were recorded for editing and quality control. For quality control and to prevent interviewer drift, 5% of the interviews were re-entered by an independent editor listening to the recorded interview on a continuing basis throughout the project. Informed consent was obtained from all subjects. Ethics approvals were obtained from the Human Research Ethics Committee at the QIMR and the Institute Review Panel at Virginia Commonwealth University.
Statistical Analyses
We fit latent factor, latent class, and FMMs to the cannabis use criteria and stem item data. Latent factor analysis (LFA; Spearman, Reference Spearman1904) accounts for covariation among observed indicators in terms of a reduced number of latent factors. In contrast, latent class analysis (LCA) assumes that correlations between symptoms arise because populations consist of subgroups that differ in their means or variances. Although LCA may be useful for defining and validating psychiatric phenotypes (Leoutsakos et al., Reference Leoutsakos, Zandi, Bandeen-Roche and Lyketsos2010), minor differences between classes can make it difficult to distinguish one class from another. Further (Lazarsfeld & Henry, Reference Lazarsfeld and Henry1968), individuals within a class are considered to be homogeneous and are not distinguishable from one another (Muthen, Reference Muthen2006). FMMs represent a hybrid of the two methods (Dolan & Maas, Reference Dolan and Maas1998; Everitt, Reference Everitt1988; Jedidi et al., Reference Jedidi, Jagpal and Desarbo1997; McLachlan & Peel, Reference McLachlan and Peel2000; Muthen, Reference Muthen2006; Muthen & Shedden, Reference Muthen and Shedden1999; Yung, Reference Yung1997). By allowing individuals in each latent class to also vary along continuous dimensions (factors) of observed criteria, FMMs can identify both subpopulations of similar individuals and quantify individual differences among those individuals. Factor models and FMMs impose an underlying parametric model on the data, LCAs do not.
For all three modeling approaches we used MML raw ordinal data analysis in the Mx software package (Neale et al., Reference Neale, Aggen, Maes, Kubarych and Schmitt2006). MML (Bock & Aitken, Reference Bock and Aitken1981) estimates model parameters by computing the joint likelihood of the latent factor(s) and the observed data. This is accomplished by integrating over the latent factor distribution using the 10-point Gauss–Hermite quadrature (Neale et al., Reference Neale, Aggen, Maes, Kubarych and Schmitt2006). For each quadrature point, the product of the quadrature weight and the conditional likelihood of the vector of criteria data is computed, and these products are summed. This approach is computationally efficient because the criteria are independent when conditioned on the factor.
While factor models are typically easy to estimate, latent class and FMMs are more prone to local solutions and estimation problems (Goodman, Reference Goodman1974; Hipp & Bauer, Reference Hipp and Bauer2006). All models were fit repeatedly using different sets of starting values to verify that a global minimum for each model was obtained. Models were considered to have converged on the global solution when the maximum likelihood (ML) value (minimum -2 log likelihood value) was reached for multiple times with different initial parameter values.
Choice of Best Fitting, Most Parsimonious, and Most Interpretable Model
When we compare different factor models, such as the one- and two-factor models, in this analysis, for example, the difference between their likelihoods is asymptotically distributed as a chi-square, so we can use a likelihood difference test (Steiger, Reference Steiger1985). When we compare factor models with latent class or mixture models, however, the difference is not asymptotically distributed as a chi-square. Comparisons between these models require omnibus fit indices. These indices rely on ‘twice the negative log-likelihood’ (-2LL), which is an index of misfit, plus a parsimony adjustment to take into account model complexity. The Akaike Information Criterion (AIC; Akaike, Reference Akaike1987), Bayesian Information Criterion (BIC), and sample size-adjusted BIC (SABIC; Schwarz, Reference Schwarz1978) are common and useful information criterion indices. When comparing models within fit indices, the model with the lowest -2LL value is indicative of the best fitting model whereas the lowest, the most negative AIC, BIC, and SABIC values are indicative of the most parsimonious fit. Parsimony is important because in ML estimation, log likelihoods will continue to decrease with additional model parameters, which can result in ‘over-fitting’. Indices of parsimony penalize models with the increasing number of parameters, thereby providing a balance between model complexity and model/data misfit, with AIC having the weakest penalty for additional parameters and BIC having the strongest penalty. Furthermore, the penalties for BIC and SABIC increase with sample size and the number of parameters, while AIC penalties depend only on the number of estimated parameters.
Simulations have shown that BIC can correctly discriminate between LCA and factor models (Markon & Krueger, Reference Markon and Krueger2004). Differences in BIC between any two LCA models can be interpreted as having corrected for expected effects of sampling variation, and are exponentially related to the posterior odds of one model versus another (Markon & Krueger, Reference Markon and Krueger2005). With sufficiently large samples, the BIC should correctly identify the best approximating model even among non-nested alternative models (Barron & Cover, Reference Barron and Cover1991; Markon & Krueger, Reference Markon and Krueger2005; Vereshchagin & Vitanyi, Reference Vereshchagin and Vitanyi2004). However, because our sample size of 626 is not large for this purpose, our results should be interpreted with caution, especially given the number of parameters estimated. Simulations (Nylund et al., Reference Nylund, Asparouhov and Muthén2007) have also shown that the BIC and SABIC (Schwarz, Reference Schwarz1978) can outperform the AIC in complex structures in which symptoms have different endorsement probabilities for more than one latent class. Although parametric bootstrapping may provide a better discrimination between LCA and FMM models with different numbers of latent classes (Nylund et al., Reference Nylund, Asparouhov and Muthén2007), it is extremely demanding computationally and was not used. Selecting a final model should be based on statistical information, but among those that differ only slightly in their fit to the data, the model with the most interpretable parameter estimates is to be preferred. Subsequent prediction of, for example, clinical outcomes may further validate model selection.
Results
Criteria Endorsements
Endorsement frequencies for the stem and diagnostic criteria are shown in Table 1. By including age at interview as a covariate on criterion thresholds, we adjust for potential age-related cohort changes in symptom endorsement. For both males and females, the most commonly endorsed criterion was ‘trying to cut down or stop using’, although the endorsement rate was higher in males (25.5%) than in females (10.9%). The second most commonly endorsed criterion was ‘ending up taking a lot more than intended or planned’ for males and ‘having to use a lot more in order to get high’ for females. The least frequently endorsed criterion was ‘cannabis use resulting in legal problems or traffic accidents’. The second least commonly endorsed criterion for both males and females was ‘cannabis use causing physical problems or depression’.
TABLE 1 Rates of Endorsement for the Ordinal Stem and Diagnostic Criteria

All items were prefaced with, ‘During this time when you used cannabis the most did you . . .?’
a0 = Never tried or tried but never for more than six times in lifetime, 1 = tried and had used for more than six times in lifetime, 2 = tried and had used for 11+ times in a month; endorsement rates reflect percentage who endorsed 1 or 2 on the stem.
bAggregate of ‘Use while doing something important like being at school or work or taking care of children?’ and ‘Stay away from work or miss appointments because you were using it?’
cAggregate of ‘Did you ever have one or more of the withdrawal symptoms in the list?’ and ‘Use it to relieve, stop, or avoid getting sick or withdrawal symptoms?’
Phenotypic Correlations and Eigenvalues
Table 2 displays the polychoric correlation matrix for the 12 criteria and the stem. The first four eigenvalues were 8.6, 1.6, 1.1, and 0.5; thus, although there were three eigenvalues greater than unity, the ratio of the first to second eigenvalue was very large (5.43).
TABLE 2 FIML-Estimated and Age- and Sex-Adjusted Polychoric Correlation Matrix of CUD Stem, Abuse, and Dependence Criteria
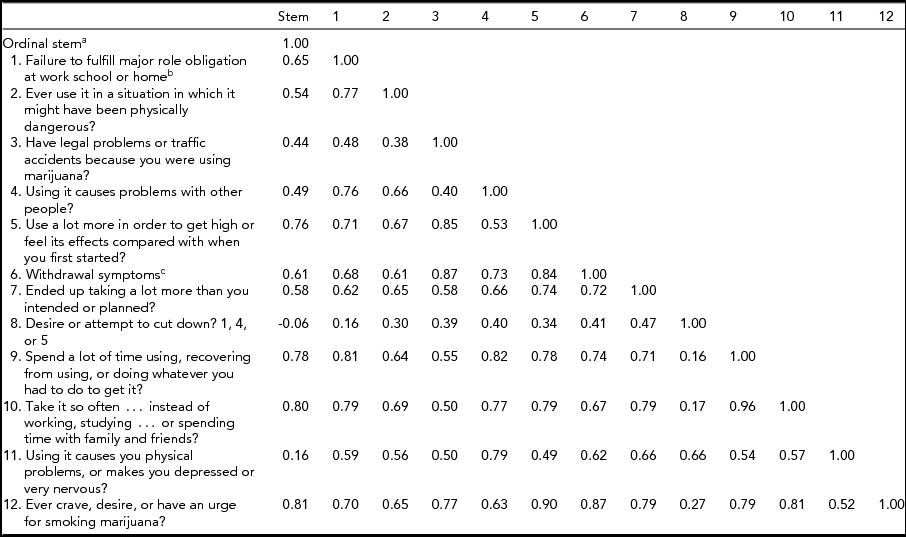
All items were prefaced with ‘During this time when you used cannabis the most did you . . .?’
a0 = Never tried or tried but never for more than six times in lifetime, 1 = tried and had used for more than six times in lifetime, 2 = tried and had used for 11+ times in a month.
bAggregate of ‘Use while doing something important like being at school or work or taking care of children?’ and ‘Stay away from work or miss appointments because you were using it?’
cAggregate of ‘Did you ever have one or more of the withdrawal symptoms in the list?’ and ‘Use it to relieve, stop, or avoid getting sick or withdrawal symptoms?’
Model Comparisons
Table 3 displays the fit statistics for the 1, 2, and 3 class models, 1 factor, two orthogonal factors, two correlated (oblique) factors and three orthogonal factors, and one factor/2 class and one factor/3 class models. The most parsimonious models are shown in bold. The one-factor model provided the best fit as judged by the BIC, whereas the correlated two-factor solution performed better in terms of the AIC and SABIC criteria. The correlation between the unrotated factors for the two-factor oblique model was 0.51. The two-factor solution is the best fitting solution by the likelihood ratio (LR) test, as well, so we can safely ignore the lone BIC result.
TABLE 3 Comparison of Latent Factor, Latent Class, and Factor Mixture Models for Cannabis Symptoms
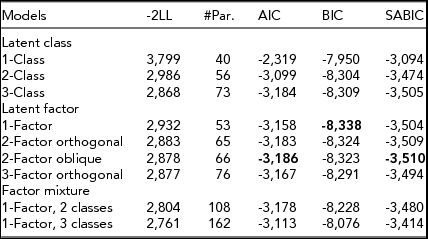
-2LL = -2 × log likelihood, #Par. = number of estimated parameters, AIC = Akaike's Information Criteria, BIC = Bayesian Information Criterion, SABIC = Sample Size-Adjusted Bayesian Information Criteria.
All models included age and sex as covariates on the symptom and stem-item thresholds.
The best fitting model for AIC, BIC, and SABIC criterion are in bold.
We then used PROMAX rotation on the best fitting exploratory two-factor oblique solution in the software program SAS (2011). Factor loadings appear in Table 4. Based on the factor-loading pattern, the first dimension can be interpreted as a general liability to CUD factor. It is defined by use and symptoms of abuse, dependence, withdrawal, and craving. Craving loaded very highly (0.92) on the general factor. The second dimension is an impairment factor defined by four symptoms with loadings of 0.40 and higher: unable to fulfill school or work obligations; use causing problems with other people; spending a lot of time obtaining cannabis, using and recovering from it; and cannabis use that causes interference with work, study, family, and friends. The correlation between the factors for the rotated solution was 0.44.
TABLE 4 Factor Loadings for the Best Fitting Two-Factor Oblique Solution for Cannabis Symptoms and Stem Item (N = 626) Following PROMAX Rotation in SAS

The correlation between the factors is r = 0.51.
a0 = Never tried or tried but never for more than six times in lifetime, 1 = tried and had used for more than six times in lifetime, 2 = tried and had used for 11+ times in a month.
bAggregate of ‘Use while doing something important like being at school or work, or taking care of children?’ and ‘Stay away from work or miss appointments because you were using it?’
cAggregate of ‘Did you ever have one or more of the withdrawal symptoms in the list?’ and ‘Use it to relieve, stop, or avoid getting sick or withdrawal symptoms?’
Discussion
This is the first study to compare the fit of latent factor, latent class, and FMMs to cannabis use, symptoms of cannabis abuse, dependence, and withdrawal, along with DSM-5-based craving in a population-based sample of young adult Australians. Even with the addition of the craving symptom, our results are commensurate with recent findings: latent factor models outperform both latent class and FMMs (Gillespie et al., Reference Gillespie, Kendler and Neale2011a, Reference Gillespie, Henders, Davenport, Hermens, Wright, Martin and Hickie2012). Although most of the observed aggregation between the physiological, behavioral, and cognitive components of CUD is best explained by a general liability to CUD factor, we found evidence for the second, clinically interpretable factor that captures important social and occupational impairment associated with frequent cannabis use. This second factor was moderately correlated with the general CUD factor.
Our results are not fully comparable with those reported previously. Among the reviewed papers that support the consensus of a single liability dimension for CUD (Baillie & Teesson, Reference Baillie and Teesson2010; Compton et al., Reference Compton, Saha, Conway and Grant2009; Feingold & Rounsaville, Reference Feingold and Rounsaville1995a, Reference Feingold and Rounsaville1995b; Gillespie et al., Reference Gillespie, Kendler and Neale2011a, Reference Gillespie, Henders, Davenport, Hermens, Wright, Martin and Hickie2012; Hartman et al., Reference Hartman, Gelhorn, Crowley, Sakai, Stallings, Young and Hopfer2008; Langenbucher et al., Reference Langenbucher, Labouvie, Martin, Sanjuan, Bavly, Kirisci and Chung2004; Lynskey & Agrawal, Reference Lynskey and Agrawal2007; Nelson et al., Reference Nelson, Rehm, Ustun, Grant and Chatterji1999; Teesson et al., Reference Teesson, Lynskey, Manor and Baillie2002), only three provided comparative fit indices between competing factorial models or omnibus comparisons with latent class and FMMs (Baillie & Teesson, Reference Baillie and Teesson2010; Gillespie et al., Reference Gillespie, Kendler and Neale2011a, Reference Gillespie, Henders, Davenport, Hermens, Wright, Martin and Hickie2012), while two reports fitted confirmatory factor models (Compton et al., Reference Compton, Saha, Conway and Grant2009; Nelson et al., Reference Nelson, Rehm, Ustun, Grant and Chatterji1999). In some instances, fit indices to facilitate model comparisons were not provided (Hartman et al., Reference Hartman, Gelhorn, Crowley, Sakai, Stallings, Young and Hopfer2008; Langenbucher et al., Reference Langenbucher, Labouvie, Martin, Sanjuan, Bavly, Kirisci and Chung2004). In others, there were only marginal differences between the one- and two-factor models (Baillie & Teesson, Reference Baillie and Teesson2010; Teesson et al., Reference Teesson, Lynskey, Manor and Baillie2002). In two instances, a two-factor solution actually provided a slightly better fit to the data (Feingold & Rounsaville, Reference Feingold and Rounsaville1995a; Lynskey & Agrawal, Reference Lynskey and Agrawal2007). To what extent the empirical support for unidimensional models for other illicit and licit substances also varies is beyond the scope of this paper. Nevertheless, it is important to acknowledge that model fitting is rarely equivocal and that the reports cited above based their conclusions on additional metrics: eigenvalues or eigenvalue ratios (Hartman et al., Reference Hartman, Gelhorn, Crowley, Sakai, Stallings, Young and Hopfer2008; Langenbucher et al., Reference Langenbucher, Labouvie, Martin, Sanjuan, Bavly, Kirisci and Chung2004); low mean square residual values, and scant residual inter-item correlations (Langenbucher et al., Reference Langenbucher, Labouvie, Martin, Sanjuan, Bavly, Kirisci and Chung2004); poor interpretability of additional dimensions (Gillespie et al., Reference Gillespie, Kendler and Neale2011a); improvement in fit for the two-factor solution attributable to very large samples (Lynskey & Agrawal, Reference Lynskey and Agrawal2007); or the very high observed inter-factor correlations (Lynskey & Agrawal, Reference Lynskey and Agrawal2007; Teesson et al., Reference Teesson, Lynskey, Manor and Baillie2002).
In contrast, our population-based sample was relatively small, and the inter-factor correlation following rotation was only moderate (r = 0.44). Moreover, the two-factor correlated solution was the most consistent solution across the fit indices. Although the first-to-second eigenvalue ratio suggests that the first dimension captures most of the covariance, the pattern of loadings on the second dimension is consistent with the observed statistics. Given the moderate inter-factor correlation, we speculate that there are individuals with high liability to CUD but low impairment, that is, resilience despite use. This makes clinical sense; despite frequent use and manifest signs of the more pharmacological aspects of cannabis addiction, including tolerance, withdrawal, and craving, a proportion of cannabis users can remain resilient in terms of normal functioning as defined by minimal social and occupational impairment. On the whole, our findings are in contrast to a growing consensus that a single factor can adequately account for the covariation among the cannabis criteria. Evidence for the second factor that includes clinically relevant features of addiction not captured by the general CUD factor is substantively plausible and etiologically relevant.
While overall heritability for general problematic cannabis use ranges from 51% in males to 59% in females (Verweij et al., Reference Verweij, Zietsch, Lynskey, Medland, Neale, Martin and Vink2010), estimates of genetic variance for the impairment symptoms have not been determined. A larger sample size is required. There is, however, evidence to support the role of genetic, psychosocial, and developmental components for correlated phenotypes such as resilience (Ahmed, Reference Ahmed2012; Russo et al., Reference Russo, Murrough, Han, Charney and Nestler2012). To what extent the observed general CUD and impairment factors correspond to different genetic or environmental risks is unclear at this point. Twin studies have typically focused on either the genetics of use or at the syndrome levels of abuse or dependence, instead of at the item of symptom level. A recent multivariate genetic analysis of the criteria for DSM-IV alcohol dependence identified not one but three genetic liabilities indexing risk of (1) tolerance and heavy use; (2) loss of control with alcohol-associated social dysfunction; and (3) withdrawal and continued use despite problems (Kendler et al., Reference Kendler, Aggen, Prescott, Crabbe and Neale2012). These results are at odds with a single, coherent phenotypic factor structure (Beseler et al., Reference Beseler, Taylor and Leeman2010; Borges et al., Reference Borges, Ye, Bond, Cherpitel, Cremonte, Moskalewicz and Rubio-Stipec2010; Saha et al., Reference Saha, Chou and Grant2006), but are consistent with rodent studies examining the genetic influences on a variety of alcohol-related traits: genetic contributions to each are either largely distinct or only weakly correlated (Crabbe et al., Reference Crabbe, Phillips, Buck, Cunningham and Belknap1999, Reference Crabbe, Metten, Cameron and Wahlsten2005). It therefore remains to be seen if similar complexity arises from cannabis use and symptoms of abuse, dependence, withdrawal, and craving.
This is also the first report to include craving in a combined analyses of cannabis use and DSM criteria. Reports examining the association between craving and symptoms of AUD have reported similar results (Bond et al., Reference Bond, Ye, Cherpitel, Borges, Cremonte, Moskalewicz and Swiatkiewicz2012; Cherpitel et al., Reference Cherpitel, Borges, Ye, Bond, Cremonte, Moskalewicz and Swiatkiewicz2010; Glockner-Rist et al., Reference Glockner-Rist, Lemenager and Mann2013; Hasin et al., Reference Hasin, Fenton, Beseler, Park and Wall2012; Keyes et al., Reference Keyes, Krueger, Grant and Hasin2011). Based on the direct equivalence of the normal ogive item-response model (IRM) to factor-analysis of binary data (Takane & Leeuw, Reference Takane and Leeuw1987), the symptom threshold and high factor loading for craving suggest that this symptom assesses lower levels of the liability to the general CUD factor with good to very good discrimination. Although a larger sample is required for a more definitive conclusion, the pattern of monozygotic (r mz = 0.75) and dizygotic (r dz = 0.38) polychoric twin pair correlations suggests that there is a high degree of familial aggregation in craving attributable to additive genetic risk factors. The legal problems criterion that was dropped in DSM-5 was infrequently endorsed, implying a high IRM difficulty, but a high loading (0.92), implying that it discriminates extremely well at a very high level of liability to CUD. Legal problems may thus still be a useful criterion for identifying subjects at the highest level of liability to CUD.
The addition of craving also allowed for a comparison between the prevalence of DSM-IV abuse/dependence diagnoses with DSM-5 CUD. In fact, our analyses suggest that the prevalence of DSM-5 CUD will be slightly higher than that of DSM-IV cannabis abuse or dependence — 19.5% versus 16.9%, representing a modest increase of 15.4%. Removing craving did not alter this finding. By comparison, a recent analysis of data from the 2007 Australian National Survey of Mental Health and Wellbeing found that the prevalence of CUD decreased from 6.2% according to DSM-IV criteria to 5.4% using DSM-5 criteria (Mewton et al., Reference Mewton, Slade and Teeson2013). The trend observed with the current data is similar to the anticipated prevalence increase in DSM-5 AUD for North American samples (Agrawal et al., Reference Agrawal, Heath and Lynskey2011; Edwards et al., Reference Edwards, Gillespie, Aggen and Kendler2013) but much lower than those in Australian samples (Mewton et al., Reference Mewton, Slade, McBride, Grove and Teesson2011).
Limitations
Our findings must be interpreted in the context of at least four minor and two larger potential limitations. First, assessments were based on a single interview that necessarily included measurement error.
Second, lower endorsement rates of some criteria may have contributed to unstable parameter estimates.
Third, twin pair members were treated as independent observations. However, failure to take into account statistical non-independence is not expected to bias parameter estimates, but confidence intervals and fit indexes may be slightly underestimated. Based on our own published analyses, we speculated that non-independence of observations is rarely a problem when the group size is small. In the case of our twin data, the group size is at most two.
Fourth, model identification relied on the assumption that the cannabis stem (0 = never tried or used less than six times, 1 = tried and used six times or more, 2 = tried and used 11 or more times) was one-dimensional. We tested this assumption using monozygotic twin pairs and have found no evidence for its violation (Gillespie et al., Reference Gillespie, Neale, Prescott, Aggen and Kendler2007).
Fifth, only subjects who met a minimal threshold of cannabis use were administered the criteria. Consequently, our sample included a relatively large amount of ‘missing’ symptom data. Fortunately, the advantage of including an ordinal stem based on initiation (and use) in the analyses provides a means to predict whether or not symptoms are missing. In other words, the ordinal stem effectively corrects for the fact that we were missing data on abuse, dependence, withdrawal, and craving on subjects who denied ever using cannabis. Moreover, because ML estimates are robust to certain forms of ‘missingness’, it is reasonable to expect good recovery of the population values of the parameters. Including the ordinal stem also allows us to pose the following question: ‘How well does criterion x measure the latent trait or liability to develop symptoms of cannabis use disorder?’
Finally, although our latent class and FMMs can be a useful means of identifying and validating subpopulations of psychiatric phenotypes (Leoutsakos et al., Reference Leoutsakos, Zandi, Bandeen-Roche and Lyketsos2010), the models are still prone to estimation problems. Latent class depends critically on the stringent assumption that local dependence holds, in that there is no residual covariance within a particular class and that whatever variance remains is due to measurement error. This can lead to the creation of classes with very minor differences, making it difficult to distinguish classes from one another (Gillespie & Neale, Reference Gillespie and Neale2006). Distributional abnormalities can generate artifactual latent classes, which are typically substantively uninterpretable (Bauer & Curran, Reference Bauer and Curran2004). One possible explanation for the mixture models fitting less well than dimensional models in this application is that the interviews for substance abuse were not designed to both classify people into groups and measure individuals’ liability (Clark et al., Reference Clark, Muthen, Kaprio, D'Onofrio, Vike and Rose2014); this is a matter for future research.
More generally, estimation problems can arise because of convergence on local rather than global solutions, thereby making it difficult to distinguish between models based on a single optimization. Our solution to this problem was to estimate each model multiple times using a range of possible starting or initial values for each estimated parameter and retaining the best-fitting solution from the entire set of estimated models (Goodman, Reference Goodman1974; Hipp & Bauer, Reference Hipp and Bauer2006). While there is no requirement that the same solution be reached from multiple sets of starting values, greater numbers of convergences on the same solution increase confidence that a global rather than local solution has been found.
Notwithstanding the above limitations, when compared with factor mixture and latent class models, factor models provided a more parsimonious fit to the data. When conditioned on initiation and cannabis use, the association between the symptoms of cannabis abuse, dependence, withdrawal, and craving can be best explained by two correlated latent factors: a general risk factor to CUD; along with a factor defined by clinically relevant features assessing social and occupational impairment related to frequent cannabis use. Secondary analyses revealed that there is a modest increase in the prevalence of DSM-5 CUD compared with DSM-IV cannabis abuse or dependence.
Acknowledgments
Nathan Gillespie was supported by the United States National Institute on Drug Abuse (NIDA) K99R00 award (R00DA023549). Michael Neale was supported by NIDA grants DA-18673 and DA-21169. Ian Hickie was supported by an Australian National Health and Medical Research Council Australia Fellowship (No. 464914). We also acknowledge and thank the following QIMR project staff: Soad Hancock as project coordinator; David Smyth for IT; Lenore Sullivan as research editor; and our research interviewers Pieta-Marie Shertock and Jill Wood. We thank the twins and their siblings for their willing cooperation.




