


Introduction
Health demands constantly grow and evolve to meet the emerging and changing needs of society in response to social, political, economic, and technological changes. The health technology assessment (HTA) process has been increasingly applied throughout the world as the main method to inform policy and decision-making in healthcare on different types of technologies such as medical-hospital materials, equipment, drugs, and procedures; besides, the HTA approach can give information about organizational or educational systems, care programs and protocols (Reference Bertram, Dhaene and Edejer1).
Over the years, several HTA agencies have been created in different countries with the purpose of improving decision-making regarding investments and disinvestments in health. These HTA processes have been the object of several studies to compare differences and similarities between them (e.g., criteria, health priorities, challenges or limitations, among other aspects) (Reference Zisis, Naoum and Athanasakis2–Reference Elias, Morais, Silva and Pereira4). Heupink et al. (Reference Heupink, Peacocke, Sæterdal, Chola and Frønsdal5) highlight that the HTA process requires time and resources. Because of this, the application of the reusing process of existing HTAs can be useful, particularly for critical policy decisions. The author called this process as transferring existing HTAs between different contexts (i.e., countries, regions, or HTA agencies). The benefits could be to accelerate the production of HTA’s reports, reduce duplication, improve knowledge sharing, and subsidy countries with fewer resources for HTA (Reference Heupink, Peacocke, Sæterdal, Chola and Frønsdal5).
Still, in the field of HTA, researchers have studied implicit factors involved in the deliberative process. A systematic review published in 2022 identified studies that categorized these factors in different countries. The HTA deliberative process is influenced by implicit factors related to the behavior and personal values of the individuals involved as well as to the context in which this process is performed. According to the authors, personal biases had consequences in resource allocation which compromise the fairness and legitimacy of HTA decisions. To tackle these hazards, some HTA agencies have been using frameworks for deliberative processes. However, according to the authors, inconsistencies, variability, and lack of predictability have been reported in current HTA value frameworks (Reference Monleón, Späth, Crespo, Dussart and Toumi6).
The quality of HTA reports has been increasingly gaining the attention of researchers (Reference Lima, de Brito and de Andrade7–Reference Cardoso, Thabane and Rugolo11). The World Health Organization conducted two global surveys in 2015 and 2020/2021 about HTA processes (12). Among the responses from 127 countries, data related to the recommendation process showed if, and how organizations share HTA information. Almost 50 percent of respondents answered that reports and recommendations are the most likely materials to be published and publicly available (12).
These surveys highlight the importance of understanding how HTA reports are developed, as these are the main formats to share information (e.g., evidence synthesis, economic evaluation), and it’s the main document used by HTA agencies to get the information to support decision-making.
According to Demner-Fushman et al. (Reference Demner-Fushman, Elhadad, Friedman, Shortliffe and Cimino13), the narrative text is an important component of communication in health care, which includes, besides patient-accessible information in health reports, general biomedical knowledge papers, information from textbooks, and web resources. For Harrison and Sidey‑Gibbons (Reference Harrison and Sidey-Gibbons14), medical records, patient feedback, assessments of doctors’ performance, and social media comments are examples of data that support clinical decision-making and quality improvement.
Natural language processing (NLP) is an artificial intelligence (AI) technique that has been used to analyze narrative/written text in a variety of fields such as environment, governance, health, education, and finance. NLP techniques receive complex text as input, and can interpret data as outputs, after automated processing of the original data (Reference Harrison and Sidey-Gibbons14;Reference Andrew, Scott, Solórzano, Moyer and Hughes15).
Some initiatives have been exploring studies that discuss NLP as a means to predict health outcomes (Reference Feder, Keith and Manzoor16;Reference Velupillai, Suominen and Liakata17). A scoping review mapped AI methods used to generate outcome data to provide decision-makers with knowledge and expand perspectives for HTA. NLP represented 1.4 percent of all methods and was predominantly used to predict the following outcomes: safety, efficacy/effectiveness, and morbidity. Considering the type of technology under assessment, NLP has been applied to evaluate aspects related to drugs and medical devices (Reference Graili, Ieraci, Hosseinkhah and Argent-Katwala18).
As an example of the applicability of NLP in the prediction of outcomes, one could mention the judicial field, in which NLP has been applied to identify facts, relationships, and affirmation in the textual data. Additionally, NLP contributed to the time and cost reduction of judicial services (Reference Alcántara Francia, Nunez-del-Prado and Alatrista-Salas19). Furthermore, it could unveil data patterns driving decisions with high accuracy (Reference Aletras, Tsarapatsanis, Preoţiuc-Pietro and Lampos20–Reference Mumcuoğlu, Öztürk, Ozaktas and Koç24). Alcántara Francia et al. (Reference Alcántara Francia, Nunez-del-Prado and Alatrista-Salas19) identified several advantages of this application such as the reduction of case complexity. Complementary, courts can use Al to expand the workforce to achieve higher productivity with limited resources. Not only that, but the authors also mentioned the use of AI could potentially reduce human bias and guarantee impartiality (Reference Alcántara Francia, Nunez-del-Prado and Alatrista-Salas19).
In considering all the points discussed above, this study aimed to build an NLP model to predict the HTA final decisions. Our main hypothesis is that based on the semantic analysis of summaries from HTA reports, this model could potentially improve the throughput of HTA systems by supporting decision-makers with a set of features or elements that could indicate odds of approval. As a pre-analytical step, it could identify technologies according to the public health system´s priorities compare patterns in earlier decisions with the same characteristics or even reduce the time of the process.
Method
In studies that applied NLP in the judicial system, different models that differ in terms of method and accuracy are presented and compared (Reference Alcántara Francia, Nunez-del-Prado and Alatrista-Salas19, Reference Menezes-Neto and Clementino21, Reference Mumcuoğlu, Öztürk, Ozaktas and Koç24). In this sense, it was decided to carry out an analysis applying different prediction models such as Least Absolute Shrinkage and Selection Operator (LASSO), logistic regression, support vector machine (SVM), random forest, neural network, and extreme gradient boosting (XGBoost) in order to verify which one has the greatest capacity to process the data of interest with greater accuracy, area under the receiver operating characteristic curve (ROC AUC), precision and recall.
Data source
Data were obtained from the official website of the Brazilian National Committee for Health Technology Incorporation (CONITEC), including all summaries of official recommendation reports conducted between 2012 and 2022, (https://www.gov.br/conitec/pt-br/assuntos/avaliacao-de-tecnologias-em-saude/recomendacoes-da-conitec).
On the website of the CONITEC, since 2012, all HTA documents are available for public access, which include updated guidelines, HTA recommendation reports, and new guidelines. For this study, were considered all HTA recommendations reports because these documents precede all updated guidelines, new guidelines, and present all information to support decision-making (economic evaluation, budget impact, clinical evidence, public consultation, and preliminary and final CONITEC´s decision). There is a template for this HTA recommendation report. However, since 2012, this template has been modified and one of these modifications was the inclusion of a summary where all information about all topics mentioned above is included. The initial idea for this first experiment is to apply the model only in this summary. The CONITEC is a permanent committee of the Ministry of Health, with the purpose of advising the Federal Government in the attributions related to the incorporation, exclusion, or alteration of health technologies, as well as in the constitution or alteration of clinical protocols and therapeutic guidelines at the public health system (SUS). This Committee was created by Law 12,401, of 28 April 2011, and from 2012 the HTA documents analyzed were available for public access.
The analysis was developed using Jupyter Notebook and Python 3.9.12.
Data preparation
Definition of sample and outcome
All reports that met the following criteria were considered for analysis: (1) were classified as a recommendation report; (2) presented a report summary; and (3) presented a final result “incorporated” or “not incorporated.”
For each synthesis the following data were analyzed: (i) type of requester/demandant (government, industry, or society); (ii) type of technology (drug, procedure, product); (iii) data on evidence synthesis; (iv) data on recommendations by other agencies; (v) data on technological horizon scanning; (vi) data on patients’ perspectives and; and (vii) general/final considerations.
The report’s synthesis contains a section describing the preliminary and final recommendation by CONITEC. Sections regarding these decisions were excluded from the analyzed text. Documents published as clinical guidelines were not eligible for this study.
Text normalization
Text fields were preprocessed using an automated form by cleaning the text data by removing any irrelevant information such as stop words (e.g., articles, adverbs, prepositions, and conjunctions), punctuation marks, and accents. Stop words are those that are frequently used in a language but do not carry any meaning on their own (e.g., in English “the,” “a/an,” in Portuguese, “o/a/os/as,” and “um/uma/uns/umas,” respectively). Removing them helps to reduce the dimensionality of the dataset and to improve the accuracy of the model. Punctuation marks and accents were also removed to standardize the text data. Finally, all text data were converted to lowercase to ensure consistency in the data.
Stemming is another technique in data preprocessing performed in an automated way. It shortens words to their base or root form, for example, derived words such as “running,” “run,” and “runner” can be reduced to their base form “run” decreasing the dimensionality of the dataset. This technique improves the accuracy of the model by reducing the number of features.
Text vectorization
Feature extraction involves converting the text data into numerical values that can be used in machine learning algorithms. The most commonly used method for feature extraction in NLP is the Term Frequency-Inverse Document Frequency (TF-IDF) method. TF-IDF is a statistical approach that gives weights to words in a document based on their frequency and importance. The TF-IDF score is higher for words that are crucial but rare in the document. Therefore, a term’s TF-IDF score is more significant if it appears frequently in the document but seldom in the corpus. This indicates the term’s importance for that specific document and its potential to differentiate it from other documents in the collection (Reference Sparck Jones25).
Another technique of feature extraction is n-grams, which involves capturing the context of the text (Reference Damashek26). n-Grams are sequences of “n” words, and by considering “n” as 2 or 3, we can capture the context of the text. They can capture the frequency and co-occurrence of words in a text, as well as their order and context. For instance, in the sentence “Conduct market research before launch,” the 2-grams (also known as bigrams) are “Conduct market,” “market research,” “research before,” and “before launch.”
After preprocessing, tokenization of the summary field was performed and the NLP techniques TF-IDF and n-grams were applied for different data sizes. Tokenization is the process of breaking down a text into smaller units called tokens. These tokens are typically words, phrases, or symbols, and they serve as the building blocks for various NLP tasks. Tokenization is a crucial step in language processing pipelines, enabling computers to analyze and understand textual data more effectively (Reference da Rocha, Barbosa and Schnr27;Reference Webster and Kit28).
Train/test split
To evaluate the performance of the model, the preprocessed dataset was randomly split into a training set (75 percent of the reports, n = 324) and a testing set (25 percent of the reports, n = 108) using sci-kit-learn. The training set is used to train the model, and the testing set is used to evaluate the performance of the model on unseen data. Additionally, tenfold cross-validation was applied during the training process to ensure robustness and reliability in assessing the model’s generalization capabilities.
Modeling
Model type
In this step, we evaluate several classification models to predict the label of the text data. We started by using LASSO regression with an alpha value of 0.01 to reduce the noise in the data and improve the accuracy of the model. LASSO regression is a linear model that uses L1 regularization to shrink the less important features to zero (Reference Tibshirani29).
In sequence, logistic regression and SVM models were applied. Logistic regression is a linear model used for binary classification, and SVM is a nonlinear model used for both binary and multi-class classification (Reference Vapnik30;Reference Hosmer, Lemeshow and Sturdivant31). Additionally, a random forest classifier was used, which is an ensemble learning method that utilizes decision trees. Random forests can capture the complex interactions between features and are known for their high accuracy (Reference Breiman32).
Deep learning involves building Neural Networks with multiple layers to improve the accuracy of the model. In this study, Keras and Tensorflow were used to build a neural network with ten epochs, a batch size of thirty-two, and a validation split of 0.1. A binary cross-entropy loss function and the Adam optimizer for training the neural network were used. Lastly, the XGBoost algorithm, which is an ensemble learning method that utilizes decision trees was applied (Reference Chen and Guestrin33). XGBoost is known for its high accuracy and is widely used in NLP applications. The max depth to 5 and the learning rate of 0.1 was set. The optimal hyperparameters for the model were selected using tenfold cross-validation resampling techniques with the aim of maximizing the area under the ROC curve.
Model selection
Each model on the preprocessed data was trained and its performance was evaluated using various metrics, such as accuracy, precision, recall, and the ROC AUC. Based on these metrics, the best-performing model was selected for further analysis.
The accuracy indicates the overall performance of the model of all the classifications, and how many did the models classified correctly. The precision is a metric that evaluates the number of true positives over the sum of all positive values. Recall (Sensitivity) evaluates the ability of the method to successfully detect results classified as positive (Reference Olson and Delen34)
The ROC AUC is a graph that allows you to evaluate a binary classifier. This visualization takes into account the rate of true positives (sensitivity) and the rate of false positives (specificity), in other words, the rate of “approved” predicted by the model that was recommended in the report, and the rate of “rejected” according to the model, and not recommended in the report. This graph allows you to compare different classifiers and define which one is better based on different cut-off points.
K-mode clustering analysis
Once we had extracted the features from the text data, we performed a k-mode clustering analysis. K-mode clustering is a variant of k-means clustering that is designed to work with categorical data, such as text data (Reference Han, Pei and Tong35;Reference Jain and Dubes36).
We used the elbow curve method to determine the optimal number of clusters to use in our analysis. The elbow curve plots the sum of squared errors (SSE) for each number of clusters, and we selected the point where the SSE begins to level off (the “elbow” of the curve) as the optimal number of clusters to use. Based on this analysis, we built two clusters.
Model evaluation
Finally, we evaluated the performance of the selected model by comparing its accuracy to the accuracy of the other models. We also analyzed the results of the k-mode clustering analysis to identify any patterns or trends within each cluster.
Overall, this methodology allowed us to identify patterns and trends in the text data and build a model that accurately predicted the recommendation outcome.
Interpretability
The interpretability of the model is a critical aspect, and XGBoost incorporates strategies such as SHAP (SHapley Additive exPlanations) plots to facilitate model explanation (Figure 2). The SHAP is used to generate interpretable explanations for individual predictions. By highlighting the features that significantly influence the model’s decision, this approach makes the decision process more understandable. The SHAP offers a distinct advantage over more sophisticated NLP models in terms of providing transparent insights into the model’s decision-making process. The simplicity and clarity offered by SHAP plots can be particularly beneficial for understanding and communicating the model’s behavior, making it a valuable tool in scenarios where interpretability is paramount.
Results
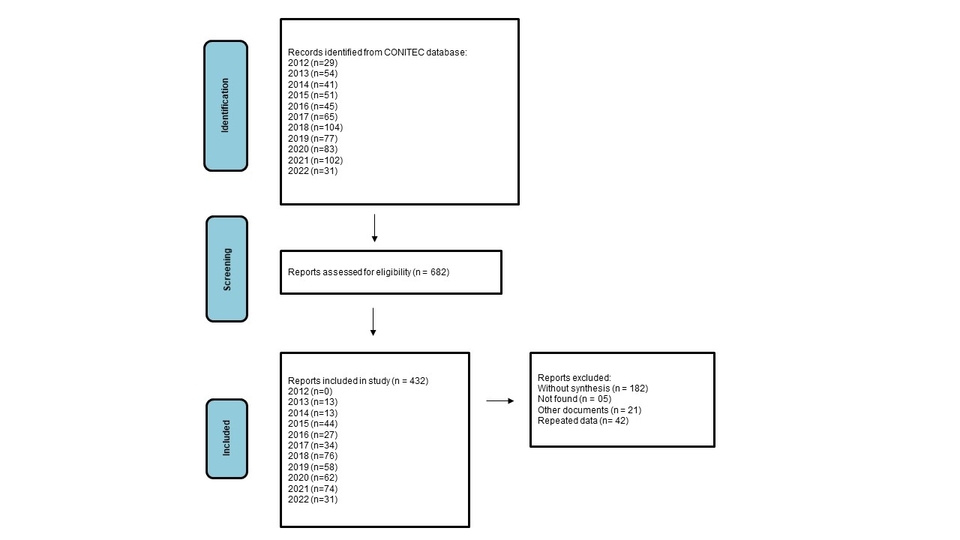
During the period from 2012 to 2022, 627 reports were published on the CONITEC website, after considering the exclusion criteria, 432 remained for the final analysis (Supplementary Figure S1. Flow Diagram adapted from Page et al., 2020 (Reference Page, McKenzie and Bossuyt37)).
Model statistics
The neural network model demonstrated the best accuracy metrics with a precision of 0.815, accuracy of 0.769, ROC AUC of 0.871, and a recall of 0.746, followed by the XGBoost model with a precision of 0.745, accuracy of 0.704, ROC AUC of 0.811, and a recall of 0.695. Table 1 presents the accuracy metrics of all models in the test set.
Table 1. Performance (accuracy, ROC AUC, precision, and recall) of each model, Brazil, 2023

LASSO, least absolute shrinkage and selection operator; ROC AUC, area under the receiver operating characteristic curve; SVM, support vector machine; XGBoost, extreme gradient boosting.
According to the XGBoost model, the variables with the stronger influence on the committee’s decision are presented in Figure 1.

Figure 1. The top twenty important features are determined by SHAP values for the XGBoost model. The mean absolute SHAP values on the left side show global feature importance, while the local explanation summary on the right side indicates the relationship between a variable and the process outcome. Positive SHAP values indicate approval, while negative values indicate non-approval.
It is possible to observe that the variables related to government (“demandante_0,” “secret vigilanc saud,” “demand secret cienc,” “secret cienc tecnolog,” “demand secret vigilanc”) had a great weight in the final decision. Also, variables related to international experience (“internac nation institut,” “experienc internac encontr,” “experienc intern nic,” “and car excellence”) had either a positive or negative weight for incorporation.
Regarding the type of action, the reports that propose to expand the use of technology had a greater weight for the incorporation (“acao_0”). Likewise, procedural technology, even less frequently presented when compared to drugs, had a greater weight for the incorporation (“tipo_1”).
Cluster analysis
In the cluster analysis, the k-modes clustering algorithm to further investigate the results. Based on the elbow method, two clusters were selected, one was the “recommended technology group” being labeled as “0” and the second one, the “non-recommended technology group” being labeled as “1.”
In both analyses, presented in Figures 2 and 3, the clustering algorithm, and the top twenty features by importance from SHAP Value (XGBoost model) showed similar results. Approved technologies were predominantly composed of drug analysis, with the government as the main requester. In contrast, for those not approved, most were drug analysis, but the industry was the main requester.

Figure 2. Composition of groups 0 and 1 by proponent: government, industry, and society.

Figure 3. Composition of groups 0 and 1 by type: drugs, procedures, and products.
Similarly, technology involving “procedure,” also classified in group 0 and ranked 12th in SHAP values, has a higher chance of approval than “Drug” and “Product” projects as presented in Figure 4.

Figure 4. Composition of groups 0 and 1 by action: expansion, incorporation, and modification.
Projects that involve expansion have been classified into group 0, which primarily includes approved projects. Furthermore, based on the SHAP values in the XGBoost model, expansion projects have been identified as the fourth most important feature. As a result, these projects have a higher likelihood of approval when compared to those involving incorporation or modification.
Discussion and implementation consideration
According to the Brazilian legislation for the incorporation of technologies in the SUS, several criteria must be in the evaluations, namely: scientific evidence on the efficacy, accuracy, effectiveness, and safety of the drugs, product, or procedure under analysis. Also, a comparative economic evaluation must show the benefits and costs concerning the technologies already incorporated into the SUS, as well as, the budget impact of incorporation into the health system. However, Souza et al. (Reference Souza, Santos and Cintra38) found that despite not being explicit in the legislation, in practice there are other criteria that are taken into account in the decision process, depending on the rapporteur or the opinion of the members of the commission.
The result of this study showed that some characteristics of the reports (type of technology and the requester’s profile) predict the incorporation, and are not directly related to the criteria settled down. Previous studies that characterized the CONITEC by other methods, in particular descriptive analysis, showed a similar profile, with the drug technology being the most evaluated and approved, and the “government” claimant having the highest number of approved technologies (Reference Elias, Morais, Silva and Pereira4;Reference Yuba, Novaes and de Soárez9;Reference Nunes, Fonteles, Passos and Arrais39).
Another aspect identified by the model was the presence of tokens with greater weight associated with a favorable outcome for technology recommendation, which is related to the international experiences of other agencies.
Brazilian researchers have compared Brazilian processes with international agencies since the selected countries are relevant to the incorporation processes, due to the consolidation time and because they have contexts of universal health systems. The study by Lima SGG et al. (Reference Lima, de Brito and de Andrade7) analyzed the technology incorporation process in Brazil, Australia, Canada, and the UK. One of the key topics of their discussion is the process of (pre)selection and/or prioritization of themes to be analyzed by the agencies, adopted by all countries, except CONITEC. According to the survey, the countries have defined criteria for a pre-selection: alternative technologies; budget impact; clinical impact; controversial nature of proposed technology; disease burden; economic impact; ethical, legal, and psychosocial implications; availability and relevance of evidence; level of interest (government, health professionals and patients); review opportunity; variation in the utilization rate.
Still, at the international level, researchers have also sought to know implicit factors in the deliberative processes in HTA. In 2022, a systematic review identified and categorized these factors for the deliberative process of drugs in Germany, France, Italy, the UK, and Spain. According to the authors, the HTA deliberative process is influenced by implicit factors related to the behavior and personal values of the involved individuals, as well as the context in which this process is performed. They characterized the categories based on the frequency mentioned in the literature: ethics, psychology, qualification and experience, politics and society, culture, functional role, and disease perception. Ethical issues were the most frequent category, especially value judgments. Psychologies (personality and subjective), culture, functional role, qualification and experience, and disease perception were factors that were related to who provided the recommendations. Political (process, pressure, and influence), and organizational culture were also observed. According to the authors, personal biases had consequences on resource allocation compromising the fairness and legitimacy of HTA decisions. To handle these aspects, some HTA agencies have used frameworks for specific deliberative processes. However, according to the authors, inconsistencies, variability, and lack of predictability have been reported in the current HTA value frameworks (Reference Monleón, Späth, Crespo, Dussart and Toumi6).
For Furtado and Lassance (Reference Koga, Palotti and Pinheiro40), taking a new decision, or maintaining (or not) the same in public policy, often involves questions of criticality, urgency, dimension, multi-causality, political-institutional multiplicity, and implementation deadline limitations. For the authors, computational models contribute to evaluation structures through inductive and deductive processes based on algorithms. These methods can detail the results, thus allowing the interlocutors previously to understand the effects and to participate in the decision-making process. Through simulations, it is possible to reduce uncertainties, as well as, to identify measures and anticipate other possibilities. Similarly, NLP is inserted in the judicial systems in several countries for the screening of outcomes prediction, helping in the simulation of an appeal, and dropping the number of unsuccessful ones (Reference Menezes-Neto and Clementino21).
Enhance the workflow of the courts by automatically evaluating an appeal and suggesting the best outcome, creating automated management systems for the most common cases. This technology could potentially improve the throughput of legal systems by supporting federal judges and their staff (Reference Mumcuoğlu, Öztürk, Ozaktas and Koç24).
This study confirmed that an IA model of semantic analysis of the HTA process can predict the CONITEC recommendation outcome, which means that specific characteristics will influence the decision. These results enhance the necessity of reflection for the creation of new structures that potentially might improve the throughput of the HTA system by supporting experts’ decision-making in a pre-selection step.
However, in addressing the concern about the possibility of misalignment between the classifier’s predictions and the decisions of the review committee, the present approach is centered on enhancing the interpretability and transparency of the model to foster trust and facilitate seamless integration of the classifier into the decision-making workflow.
Thus, some strategies are proposed in the following sections.
Model documentation
This documentation will serve as a comprehensive resource for the review committee, offering insights into the model’s inner workings and its learning process. This transparency is crucial for ensuring that decision-makers can confidently assess and understand the model’s capabilities and limitations.
User-friendly interface
A user-friendly interface could be designed that allows decision-makers to interact with the model easily. This interface could provide not only the final predictions but also relevant information on the features contributing to each prediction. A clear and intuitive presentation of the model’s output can significantly enhance interpretability.
Continuous collaboration with decision-makers
Collaboration with the review committee could be ongoing, involving regular meetings to address any concerns, provide clarifications, and receive feedback. This iterative process ensures that decision-makers are actively involved in the deployment and evolution of the model, fostering a sense of ownership and confidence in its utility.
Education and training
A training session could be offered to familiarize decision-makers with the underlying concepts of the model and its application. This educational initiative aims to empower the committee with the knowledge necessary to interpret and critically assess the mode’s predictions.
By implementing these strategies, the potential confusion and obstacles in the decision-making process can be minimized, ensuring that the classifier serves as a valuable tool that aids, rather than complicates, the HTA.
It is important to highlight that in 2023, a new HTA process was implemented in Brazil, in which the CONITEC is no longer composed of a single group of members, but of three thematic committees (drugs, guidelines, or products and procedures). Therefore, in this scenario, models such as the one proposed can facilitate the decision-making process.
Limitations
The analysis was made in the text of decisions from synthesis and not from all reports. Although the accuracy was with a value considered adequate, it is believed that there are possibly other factors that have greater weight in decision-making and that were excluded from the synthesis, especially those related to the numerical values contained in the economic and budget impact analyses. The other limitation is not having HTA studies with similar analyses to compare.
The fact that there is no computerized system for including HTA report data, as is the case in the judicial system, was also considered a limitation. Therefore, for the model to be applied throughout the report, it would be important to analyze computerized forms of application of the evaluation processes. Once computerized, in addition to the analysis performed, it would be possible to identify other data of interest through the creation of fields established according to criteria. For example, data that represent importance for the patient, and priority for the health system, among others.
The last limitation to point out is the use of simpler NLP models, as compared to complex ones. Tokenization, n-grams, and TF-IDF are considered simpler because they operate on more basic linguistic principles, but have a clear and more interpretable structure, while GPT models, besides powerful, are more complex and involve intricate neural network architectures, making them harder to interpret and understand. The choice between these approaches often depends on the specific task and the available resources. Further studies are suggested to explore other more complex models.
Conclusion
This study presented an NLP model for the identification of possible predictors for the final decision process on the incorporation of health technologies in the Brazilian Public Health System (SUS), opening paths for future work using HTA reports coming from other HTA agencies. This model could potentially improve the throughput of HTA systems by supporting experts given some prediction/factors/criteria for approval or not as a previous pre-section step.
In addition, this model could be validated and replicated in other similar contexts using the complete report from HTA agencies. However, considering the different application systems in different countries, it will be necessary to adequate the model to the HTA process in each context.
In this sense, one of the challenges for the model proposed in this study is to adjust it based on what you want to extract from the unknown data of the new database and make reliable predictions. Another challenge is to think of this model as a proposal that is not restricted to just the known base but has the ability to generalize to bases that differ from the one used in training.
Supplementary material
The supplementary material for this article can be found at http://doi.org/10.1017/S0266462324000163.
Acknowledgments
The authors thank Health Technology Assessment International (HTAi) for the scholarship from the Education Program for MMAC to improve knowledge in health technology assessment at McMaster University, Hamilton, ON, Canada.
Author contribution
Concept and design: M.M.d.A.C., N.C.d.R., A.M.P.B., L.G.M.d.A. Acquisition of data: M.M.d.A.C., L.G.M.d.A. Analysis and interpretation of data: M.M.d.A.C., N.C.d.R., A.M.P.B., D.S.K., L.G.M.d.A. Drafting of the manuscript: M.M.d.A.C., J.M-R., L.T., N.C.d.R., A.M.P.B., D.S.K., D.d.S.P.C., S.A.T.W., L.G.M.d.A. Critical revision of the paper for important intellectual content: L.T., D.d.S.P.C. Administrative, technical, or logistic support: J.M-R., J.T.C.d.A., S.A.T.W. Supervision: L.T., L.G.M.d.A.
Competing interest
The authors declare none.
Key messages
-
1. What was known before this study?
-
• Considering the high volume of submissions processed by health technology assessment (HTA) agencies, an automated approach based on artificial intelligence to determine key factors associated with timely evaluation approval would be beneficial.
-
• The HTA deliberative process could be influenced by implicit factors related to behavior aspects and personal values of individuals involved as well as to the context in which this process is performed. To handle these aspects, some HTA agencies have been using frameworks for specific deliberative processes. However, inconsistencies, variability, and lack of predictability have been reported in current HTA value frameworks.
-
-
2. What are the key findings from the study?
-
• Some tokenization identified that linguistic markers could potentially contribute to the prediction of incorporation decisions by the Brazilian HTA Committee, such as quotes about international HTA agencies’ experience and the government as the main requester (demandant).
-
• A cluster analysis was conducted, revealing the existence of two primary groups. The first group consists mainly of drug evaluations, which were primarily requested by the government and had a high approval rate for most projects. The second group, which also evaluated drugs, was mostly composed of industry applicants and had a low approval rate for most projects. Some similarities were found between the extreme gradient boosting and cluster analysis results, such as the government being the primary “demandant,” expansion as the primary “action,” and procedure as the primary “type” for approved projects.
-
-
3. What are the implications of the findings?
-
• The use of natural language processing allowed the identification of predictive features within the Brazilian HTA Committee associated with the final decision process on health technology incorporation.
-
• Artificial intelligence could be used as an auxiliary to the early identification of factors that could indicate odds of approval or, as a pre-analytical step, it could identify technologies according to the public health system´s priorities or compare patterns in earlier decisions with the same characteristic or even reduce the time of the process.
-







 Open access
Open access