


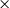
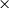
1. Introduction
In recent years, natural language processing (NLP) generative models have advanced rapidly and found applications in a wide range of domains (Chang et al. Reference Chang, Wang, Wang, Wu, Yang, Zhu, Chen, Yi, Wang, Wang, Ye, Zhang, Chang, Yu, Yang and Xie2024; Kalyan Reference Kalyan2024). These models, especially transformer-based sequence-to-sequence (seq2seq) architectures (Sutskever, Vinyals, and Le Reference Sutskever, Vinyals and Le2014; Vaswani Reference Vaswani, Shazeer, Parmar, Uszkoreit, Jones, Gomez, Kaiser and Polosukhin2017), excel at capturing complex relationships between input and output sequences. However, they are typically built on complex neural network architectures, which are often described as ‘black boxes’ due to their opaque internal mechanisms (Dayhoff and DeLeo Reference Dayhoff and De Leo2001; Burkart and Huber Reference Burkart and Huber2021). To address this challenge, the field of Explainable AI (XAI) has attracted researchers seeking to improve transparency and interpretability and to explain models’ behavior. One of the main objectives of XAI is to assess, quantify, or characterize the importance (or attribution) of input features in shaping the final outputs of these models (Arya et al. Reference Arya, Bellamy, Chen, Dhurandhar, Hind, Hoffman, Houde, Liao, Luss, Mojsilović, Mourad, Pedemonte, Raghavendra, Richards, Sattigeri, Shanmugam, Singh, Varshney, Wei and Zhang2019; Vieira and Digiampietri Reference Vieira and Digiampietri2022; Saeed and Omlin, Reference Saeed and Omlin2023). Several XAI methods have been developed and applied specifically to NLP models to evaluate the contribution of input information to the model’s output across various tasks (Madsen, Reddy, and Chandar Reference Madsen, Reddy and Chandar2022; Mohammadi et al. Reference Mohammadi, Bagheri, Giachanou and Oberski2025). Despite these advances, identifying which explanation methods more accurately reflect model reasoning remains challenging, especially in seq2seq settings, which are characterized by intricate encoding-decoding dynamics and many-to-many mappings (Li et al. Reference Li, Liu, Li, Li, Huang and Shi2020; Gurrapu et al. Reference Gurrapu, Kulkarni, Huang, Lourentzou and Batarseh2023).
The calculation and extraction of the decision-making process of neural networks per input features, which are also applied to Neural Machine Translation (NMT) models (X. Li et al. Reference Li, Li, Liu, Meng and Shi2019; He et al. Reference He, Tu, Wang, Wang, Lyu and Shi2019; Eksi et al. Reference Eksi, Gelbing, Stieber and Vu2021; Fomicheva, Specia, and Aletras Reference Fomicheva, Specia and Aletras2022; Perrella et al. Reference Perrella, Proietti, Cabot, Barba and Navigli2024), are often grouped into three broad families of gradient-based, model-based, and perturbation-based methods (Dwivedi et al. Reference Dwivedi, Dave, Naik, Singhal, Omer, Patel, Qian, Wen, Shah, Morgan and Ranjan2023; Sarti et al. Reference Sarti, Feldhus, Sickert and van der Wal2023; Fantozzi and Naldi Reference Fantozzi and Naldi2024). Gradient-based approaches estimate the contribution of each input by computing derivatives of the model output with respect to the input or intermediate representations; examples include Saliency (Simonyan, Vedaldi, and Zisserman Reference Simonyan, Vedaldi and Zisserman2014) and Integrated Gradients (Sundararajan, Taly, and Yan Reference Sundararajan, Taly and Yan2017). Model-based approaches rely on components that already produce interpretable signals, such as the attention mechanism. Perturbation-based methods, instead, modify or remove parts of the input and measure the resulting change in model output; LIME (Ribeiro, Singh, and Guestrin Reference Ribeiro, Singh and Guestrin2016) and Value Zeroing (Mohebbi et al. Reference Mohebbi, Zuidema, Chrupała and Alishahi2023) fall into this category. However, the boundaries between these families are not always strict. Some techniques combine properties of multiple categories, such as GradientSHAP (Lundberg and Lee Reference Lundberg and Lee2017), which blends gradient information with stochastic perturbations. Nevertheless, because these methods rest on different assumptions about how models encode and use information, they compute feature importance in different ways and can therefore produce divergent explanations for the same prediction, raising the question of which methods best reflect the model’s behavior.
Despite the proliferation of explainability methods, comprehensive and scalable evaluation of XAI methods in NLP remains limited. Evaluation practices that rely on human validation, which, although insightful, are costly and difficult to scale (Leiter et al. Reference Leiter, Lertvittayakumjorn, Fomicheva, Zhao, Gao and Eger2022; Kim, Maathuis, and Sent Reference Kim, Maathuis and Sent2024). Automated evaluation frameworks that are common in computer vision (Ribeiro et al. Reference Ribeiro, Singh and Guestrin2016; Chang et al. Reference Chang, Creager, Goldenberg and Duvenaud2019; Hooker et al. Reference Hooker, Erhan, Kindermans and Kim2019) are underrepresented in NLP and NMT, and existing work typically focuses on a small number of explanation methods. This signifies the need for systematic, model-based evaluation approaches capable of objectively comparing diverse explainability techniques in seq2seq settings. Prior evaluations have, for example, compared attribution maps with human-annotated word alignments (see Section 2.1). Yet, such alignments only approximate the underlying translation dynamics and may not represent the information flow within modern NMT systems.
In this work, we address these gaps by proposing an automated evaluation framework based on the simulatability of XAI methods (Doshi-Velez and Kim Reference Doshi-Velez and Kim2017; Hase and Bansal Reference Hase and Bansal2020), specifically designed to assess and compare multiple attribution methods within seq2seq models for NMT. Intuitively, if an attribution method captures a model’s input–output dependencies, it should provide useful guidance for a student model to make better predictions. We operationalize this idea through a teacher–student setup: attribution maps are extracted from a pre-trained teacher NMT model and injected into the attention mechanism of a smaller, untrained student model. Concretely, we treat the attribution maps as attention priors within the encoder-decoder architecture and explore several ways to combine them with the student’s own attention scores. The resulting student performance provides an automated, task-specific measure for evaluating different explanation methods. Within this framework, higher-quality explanations produce more informative attribution maps, which in turn allow the student to make more accurate predictions, thereby serving as a proxy for judging the effectiveness of the XAI attribution method. We apply this framework across three language pairs, using Marian-MT (Tiedemann and Thottingal Reference Tiedemann and Thottingal2020) and mBART (Liu et al. Reference Liu, Gu, Goyal, Li, Edunov, Ghazvininejad, Lewis and Zettlemoyer2020) models’ attributions.
As part of our analysis, we deliberately compute attribution maps with respect to the gold reference translation, and in another part, we compute the attributions based on the teacher’s generation. This defines an oracle setting in which the explanation is allowed to depend on the true target sequence and the resulting translation. Therefore, the model sees the source and attribution maps for all target tokens during encoding and at each autoregressive step. We use this oracle setup to address two questions. First, to what extent can attribution-guided attention priors help a student model reproduce the gold, human-generated target when the student model has access to the attributions? Second, given a fixed teacher-generated translation, which attribution methods produce maps that are most helpful for a student model to approximate that teacher, that is which explanations best capture the teacher’s input–output behavior under our idealized conditions? In this way, the oracle setting serves as a controlled environment for comparing attribution methods, and we interpret the reported BLEU/chrF scores as relative indicators of explanation quality rather than as standard test-set performance.
To interpret the discrepancy in student performance under different attribution methods, we propose a hypothesis that their behavior can be explained by the closeness of their mappings to what a transformer is able to produce. To investigate that, we design a separate encoder-decoder transformer, named Attributor, and train it to reconstruct the teacher’s attribution map based on the respective source-target pair. Our experiments confirm the claim and highlight that the Attributor’s ability to reproduce scores of top-3 salient tokens per column of the attribution maps very strongly correlates with the student performance in the MT task utilizing those maps.
Beyond the primary goal of evaluating XAI attribution methods in NMT, this work also provides insight into the behavior of the attention mechanism itself. We show that attributions derived from the teacher model’s attention tend to be more effective in guiding the student model. This is aligned with the fact that attention maps are the easiest for the Attributor to reproduce. We also observe an interesting and somewhat unintuitive pattern in how the student model responds to externally injected attribution signals. In particular, the intervention is more effective when applied to the encoder attention (see Section 3). A detailed discussion of these findings appears later in the paper.
In summary, the main contributions of this work are as follows:
-
• We propose an evaluation framework that uses knowledge distillation to systematically assess and compare explainability methods by integrating attribution explanations into seq2seq model architectures.
-
• We conduct extensive experiments exploring multiple strategies for incorporating explanations within the Transformer architecture and systematically compare their effects on model performance across various language pairs.
-
• We provide empirical evidence that XAI attribution methods influence the performance of seq2seq models. Our findings demonstrate that the quality and type of explanations can enhance or degrade model output relative to baseline models without attribution guidance.
-
• Finally, we investigate reasons why each attribution mapping yields different results when used within the student model for NMT tasks and show a strong correlation of those results with the ability of a transformer to approximate top-3 salient scores per target token of such mappings.
The paper is organized as follows: Section 2 reviews the background and related work. Section 3 describes the proposed approach. Sections 4 and 5 present and discuss the obtained results. In Section 6 we present the Attributor network. Section 7 concludes the paper and outlines the limitations of this work, highlighting directions for future research.
2. Related work
In this section, we first summarize related work on evaluating and analyzing XAI attribution methods, with a particular focus on NMT. We then briefly review the seq2seq NMT architecture and outline the XAI methods used in this study.
2.1 Evaluation of explanations and their application in NMT
The XAI literature distinguishes several dimensions of what explanations can provide. A central distinction is between plausibility and faithfulness/fidelity: plausibility refers to how well an explanation aligns with human intuition, whereas faithfulness describes how accurately an explanation reflects the model’s actual decision-making process (Arrieta et al. Reference Barredo Arrieta, Díaz-Rodríguez, Del Ser, Bennetot, Tabik, Barbado, Garcia, Gil-Lopez, Molina, Benjamins, Chatila and Herrera2020; Jacovi and Goldberg Reference Jacovi and Goldberg2020). Doshi-Velez and Kim (Doshi-Velez and Kim Reference Doshi-Velez and Kim2017, Reference Doshi-Velez and Kim2018) have proposed three approaches to evaluate XAI methods, one of which is a functionally grounded evaluation protocol. In this protocol, explanations are assessed by automatic task performance metrics rather than human judgments. This paradigm has been adopted in NLP for evaluating the faithfulness of saliencyFootnote b methods. For example, Arras et al. (Reference Arras, Horn, Montavon, Müller and Wojciech2016); Nguyen (Reference Nguyen2018); DeYoung et al. (Reference De Young, Jain, Rajani, Lehman, Xiong, Socher and Wallace2020); Atanasova et al. (Reference Atanasova, Simonsen, Lioma and Augenstein2020); Nauta et al. (Reference Nauta, Trienes, Pathak, Nguyen, Peters, Schmitt, Schlötterer, van Keulen and Seifert2023) proposed automatic, task-based metrics for classification models that quantify how well feature attributions capture model behavior.
Our focus is on the NMT task, in particular, transformer-based (Vaswani Reference Vaswani, Shazeer, Parmar, Uszkoreit, Jones, Gomez, Kaiser and Polosukhin2017) seq2seq models (Sutskever et al. Reference Sutskever, Vinyals and Le2014). Compared to standard classification, NMT introduces additional challenges for explanation because it decomposes prediction into a sequence of conditional next-token decisions, one per decoding timestep, and the importance of each source token depends not only on the current target token but also on the previous target prefix (Stahlberg Reference Stahlberg2020; Shakil, Farooq, and Kalita Reference Shakil, Farooq and Kalita2024). This temporal and source–target coupling complicates both the design and the evaluation of token-level attribution methods.
A large body of work has studied the attention mechanism as an interpretable component of NMT, using encoder–decoder attention weights to estimate word importance and to approximate word alignments (Ghader and Monz Reference Ghader and Monz2017; Raganato and Tiedemann Reference Raganato and Tiedemann2018; Kobayashi et al. Reference Kobayashi, Kuribayashi, Yokoi and Inui2020; Ferrando and Costa-jussà Reference Ferrando and Costa-Jussà2021). These studies show that attention patterns correlate with, but do not faithfully reproduce, traditional word alignments, and that attention weights also reflect how the model balances source information against the evolving target prefix. On the other hand, other work has questioned the plausibility and faithfulness of attention as an explanation, arguing that attention weights should be interpreted cautiously based on the task and model, and in some cases, augmented with more explicit attribution mechanisms (Jain and Wallace Reference Jain and Wallace2019; Meister et al. Reference Meister, Lazov, Augenstein and Cotterell2021; Madsen et al. Reference Madsen, Meade, Adlakha and Reddy2022).
Beyond attention, other explanation methods exist to compute per-token importance. The most common metrics to evaluate token importance are comprehensiveness (does removing the highlighted tokens reduce the model’s confidence or translation quality?) and sufficiency (are the highlighted tokens alone sufficient to preserve model performance?) (DeYoung et al. Reference De Young, Jain, Rajani, Lehman, Xiong, Socher and Wallace2020; Nauta et al. Reference Nauta, Trienes, Pathak, Nguyen, Peters, Schmitt, Schlötterer, van Keulen and Seifert2023). In NMT, such approaches have been explored to measure the drop in log-probability of the chosen next token after input perturbations or at the sequence level, where changes in BLEU scores after manipulating important source tokens, according to XAI methods, were used as a test bed for assessing whether attribution maps identify tokens that are necessary and/or sufficient for the model’s predictions (He et al. Reference He, Tu, Wang, Wang, Lyu and Shi2019; Moradi, Kambhatla, and Sarkar Reference Moradi, Kambhatla and Sarkar2021).
Word alignment (Brown et al. Reference Brown, Pietra, Pietra and Mercer1993) has also been widely used as a proxy for the plausibility of model attributions in NMT. X. Li et al. (Reference Li, Li, Liu, Meng and Shi2019) showed that attention-based alignments have clear limitations, motivating alternative alignment models and prediction-difference techniques to improve alignment quality. In parallel, Zenkel, Wuebker, and De Nero (Reference Zenkel, Wuebker and DeNero2019) proposed augmenting NMT models with dedicated alignment layers, treating alignment as an auxiliary prediction task rather than a by-product of standard attention. Their approach improves alignment accuracy compared to classical tools such as GIZA++ (Och and Ney Reference Och and Ney2003) and FastAlign (Dyer, Chahuneau, and Smith Reference Dyer, Chahuneau and Smith2013). Ding, Xu, and Koehn (Reference Ding, Xu and Koehn2019) introduced saliency-driven, gradient-based methods that yield more interpretable alignment signals without modifying the underlying NMT architecture. Building on these ideas, Ferrando and Costa-jussà (Reference Ferrando and Costa-Jussà2021) analyzed encoder–decoder attention in detail, highlighting systematic alignment errors and proposing techniques that explicitly quantify the relative contributions of source and target contexts. Ferrando et al. (Reference Ferrando, Gállego, Alastruey, Escolano and Costa-Jussà2022) further developed ALTI+, an attention-rollout-based framework that traces contributions from both source and target contexts across layers in multilingual Transformer models. ALTI + has been used as an internal explanation metric for downstream diagnostic tasks; for instance, Dale et al. (Reference Dale, Voita, Barrault and Costa-Jussà2023) employ ALTI+-based scores to detect and mitigate hallucinations in NMT outputs. Related work by Voita, Sennrich, and Titov (Reference Voita, Sennrich and Titov2021) used layer-wise propagation (LPR) to analyze the intrinsic contributions of source and target contexts under different training regimes and dataset conditions, while Kobayashi et al. (Reference Kobayashi, Kuribayashi, Yokoi and Inui2020) performed a norm-based analysis of attention and transformed representations to study internal alignment mechanisms within Transformers. Closer to the current work, Li et al. (Reference Li, Liu, Li, Li, Huang and Shi2020) evaluated XAI methods in NMT by training surrogate models on the important words identified by the XAI methods and measuring the prediction success of each token
 $i$
based on the top-k tokens identified as the most contributing tokens to the generation of that token. Other work has explored and compared XAI methods, such as gradient and perturbation methods, to detect word-level translation errors in NMT (Eksi et al. Reference Eksi, Gelbing, Stieber and Vu2021; Fomicheva et al. Reference Fomicheva, Specia and Aletras2022).
$i$
based on the top-k tokens identified as the most contributing tokens to the generation of that token. Other work has explored and compared XAI methods, such as gradient and perturbation methods, to detect word-level translation errors in NMT (Eksi et al. Reference Eksi, Gelbing, Stieber and Vu2021; Fomicheva et al. Reference Fomicheva, Specia and Aletras2022).
2.2 Simulatability of XAI methods
A complementary line of work evaluates explanations through simulatability. Simulatability is how well an explanation helps a user replicate a model’s behavior. Doshi-Velez and Kim (Reference Doshi-Velez and Kim2017); Hase et al. (Reference Hase and Bansal2020) propose human-grounded protocols in which participants are asked to predict a model’s output on a given input, first without and then with access to explanations. The underlying idea is that an explanation method is better if it improves human prediction accuracy of the model’s decisions. These studies implement such user-in-the-loop evaluations on tabular and text classification tasks, using common XAI techniques to generate explanations that are shown to human subjects.
Closer to our setting, Pruthi et al. (Reference Pruthi, Bansal, Dhingra, Soares, Collins, Lipton, Neubig and Cohen2022) worked on a related idea without relying on human annotators. Building on the notion of simulatability, they transfer important information learned from one model to another. Token-level importance scores are used to guide a new model on several classification tasks, and the resulting change in performance is taken as evidence for the usefulness of the original attributions. In other words, an explanation is considered higher quality if it can be leveraged to train another model that better simulates or reconstructs the original model’s behavior. Our work adopts a similar spirit of model-based simulatability, but in the more complex seq2seq NMT setting.
2.3 Injection of knowledge into the attention mechanism
There is also some work on injecting external or structured linguistic knowledge directly into the attention mechanism (Jiao et al. Reference Jiao, Yichun, Lifeng, Xin, Xiao, Linlin, Wang and Liu2020; Bai et al. Reference Bai, Wang, Sun, Wu, Yang, Tang, Cao, Zhang, Tong, Yang, Bai, Zhang, Sun and Shen2022; Zhao and Shan Reference Zhao and Shan2024). In NMT Bugliarello and Okazaki (Reference Bugliarello and Okazaki2020) incorporate syntactic information by encoding, for each token, the distance to the syntactic ‘parent’ in a dependency tree, and using this signal to bias attention patterns. In their approach, knowledge injection is applied on the encoder side for the source sentence, enabling attention heads to exploit syntactic structure. Slobodkin, Choshen, and Abend (Reference Slobodkin, Choshen and Abend2022) augment encoder attention with syntactic and semantic information in the form of alignment-like constraints over the input. Their architecture modifies the attention computation so that heads are explicitly informed by these external signals, rather than learning them implicitly. They report that enriching attention with semantic information benefits translation quality. Similar to the current work Nourbakhsh, Lamsiyah, and Schommer (Reference Nourbakhsh, Lamsiyah and Schommer2025) inject attributions in the form of hard alignments and compare them to linguistic information, such as POS and Dependency information. In this work, we deal with soft attributions and more diverse XAI methods. These works suggest that attention can serve as a locus for the injection of task-relevant prior knowledge.
Bringing together these strands of work, we propose an evaluation framework for XAI attribution methods to inject attribution matrix scores into the attention mechanism and compare the resulting effects on the translation task itself. Our design is inspired by Remove and Retrain (ROAR) retraining paradigms (Hooker et al. Reference Hooker, Erhan, Kindermans and Kim2019), the simulatability of XAI methods (Hase et al. Reference Hase and Bansal2020), and prior work on knowledge injection into attention, and it contributes to this line of research by providing a comprehensive, functionally grounded comparison of several attribution methods in the seq2seq NMT model.
2.4 NMT with sequence-to-sequence models
Seq2seq models (Sutskever et al. Reference Sutskever, Vinyals and Le2014; Bahdanau, Cho, and Bengio Reference Bahdanau, Cho and Bengio2015), originally introduced for machine translation (Cho et al. Reference Cho, van Merriënboer, Gulcehre, Bahdanau, Bougares, Schwenk and Bengio2014), are conditional language models that learn to generate the target sentence token by token, conditioned on the source sentence and the previously generated target tokens. The original Transformer model, a precursor to encoder-based classifiers and decoder-based large language models, was an encoder–decoder (Vaswani Reference Vaswani, Shazeer, Parmar, Uszkoreit, Jones, Gomez, Kaiser and Polosukhin2017):
An NMT encoder–decoder model operates on two sequences:
 \begin{equation*} \mathbf{x} = (x_1, x_2, \ldots , x_{T_x}), \quad \mathbf{y} = (y_1, y_2, \ldots , y_{T_y}). \end{equation*}
\begin{equation*} \mathbf{x} = (x_1, x_2, \ldots , x_{T_x}), \quad \mathbf{y} = (y_1, y_2, \ldots , y_{T_y}). \end{equation*}
Where
 $\mathbf{x}$
and
$\mathbf{x}$
and
 $\mathbf{y}$
are the source and target sequences, an NMT model with a seq2seq architecture defines a conditional probability distribution over the target sequence given the source sequence and previous target tokens:
$\mathbf{y}$
are the source and target sequences, an NMT model with a seq2seq architecture defines a conditional probability distribution over the target sequence given the source sequence and previous target tokens:
 \begin{equation*} p(\mathbf{y} \mid \mathbf{x};\, \theta ) = \prod _{t=1}^{T_y} p (y_t \mid y_{\lt t}, \mathbf{x};\, \theta ), \end{equation*}
\begin{equation*} p(\mathbf{y} \mid \mathbf{x};\, \theta ) = \prod _{t=1}^{T_y} p (y_t \mid y_{\lt t}, \mathbf{x};\, \theta ), \end{equation*}
where
 $y_{\lt t} = (y_1, \ldots , y_{t-1})$
and
$y_{\lt t} = (y_1, \ldots , y_{t-1})$
and
 $\theta$
are all model parameters.
$\theta$
are all model parameters.
The encoder maps the source sequence to a sequence of continuous contextual representations based on stacked self-attention and feed-forward layers.
 \begin{equation*} \mathbf{H} = ( \mathbf{h}_1, \ldots , \mathbf{h}_{T_x} ), \end{equation*}
\begin{equation*} \mathbf{H} = ( \mathbf{h}_1, \ldots , \mathbf{h}_{T_x} ), \end{equation*}
The decoder is another neural network that, at each time step
 $t$
, takes as input the previously generated target tokens (through masked self-attention over
$t$
, takes as input the previously generated target tokens (through masked self-attention over
 $y_{\lt t}$
) and attends to the encoder representations
$y_{\lt t}$
) and attends to the encoder representations
 $\mathbf{H}$
(via cross-attention), producing a decoder representation
$\mathbf{H}$
(via cross-attention), producing a decoder representation
 $\mathbf{s}_t$
from which the next-token distribution
$\mathbf{s}_t$
from which the next-token distribution
 $p(y_t \mid y_{\lt t}, \mathbf{x};\, \theta )$
is computed.
$p(y_t \mid y_{\lt t}, \mathbf{x};\, \theta )$
is computed.
Given a training corpus
 \begin{equation*} \mathcal{D} = \big\{\big(\mathbf{x}^{(n)}, \mathbf{y}^{(n)}\big)\big\}_{n=1}^N \end{equation*}
\begin{equation*} \mathcal{D} = \big\{\big(\mathbf{x}^{(n)}, \mathbf{y}^{(n)}\big)\big\}_{n=1}^N \end{equation*}
of source–target pairs, model parameters
 $\theta$
are typically learned by maximizing the conditional log-likelihood:
$\theta$
are typically learned by maximizing the conditional log-likelihood:
 \begin{equation*} \mathcal{L}(\theta ) = - \sum _{n=1}^N \sum _{t=1}^{T_y^{(n)}} \log p\Bigl (y_t^{(n)} \mid y_{\lt t}^{(n)}, \mathbf{x}^{(n)};\, \theta \Bigr ). \end{equation*}
\begin{equation*} \mathcal{L}(\theta ) = - \sum _{n=1}^N \sum _{t=1}^{T_y^{(n)}} \log p\Bigl (y_t^{(n)} \mid y_{\lt t}^{(n)}, \mathbf{x}^{(n)};\, \theta \Bigr ). \end{equation*}
During training, teacher forcing is commonly used, meaning that the decoder receives the ground-truth previous token
 $y_{t-1}^{(n)}$
as input when predicting
$y_{t-1}^{(n)}$
as input when predicting
 $y_t^{(n)}$
.
$y_t^{(n)}$
.
An example of attribution maps derived from different XAI methods. For the source sentence ‘Dann gibt es noch Anbieter, die kaum Fahrraderfahrung, jedoch gute Fernostkontakte haben und so an günstige E-Bikes kommen.’ and the target ‘Then there are suppliers with little or no experience in the bicycle industry but good contacts in the Far East, thus giving them access to low-cost e-bikes.’. In the heatmaps, the rows correspond to source tokens, and the columns to target tokens. The heatmaps are generated from the normalized columns using the MinMax normalizer.

Figure 1 Long description
The image displays a comparative heat map analysis of various Explainable AI (XAI) techniques applied to Marian-MT and mBART models. Each heat map represents the attribution of input features to the output of neural network models, with rows corresponding to source tokens and columns to target tokens. The heat maps are generated from normalized columns using the MinMax normalizer. The methods compared include IxG, Saliency, LGxA, IG, GSHAP, DeepLIFT, Attention, and ValueZeroing. The heat maps show distinct patterns of attribution, with some methods like Attention and ValueZeroing yielding larger gains in BLEU scores, indicating better alignment between source and target representations. The heat maps for Marian-MT and mBART models reveal different levels of intensity and distribution of attribution scores, highlighting the varying effectiveness of different XAI techniques in capturing relevant signals.
2.5 AI explainability methods
XAI attribution methods can be broadly categorized into three main types: gradient-based, internal model-based, and perturbation-based approaches. Below, we briefly describe the attribution methods used in this work to extract attribution maps. To extract these attribution maps, we used the Inseq Python library (Sarti et al. Reference Sarti, Feldhus, Sickert and van der Wal2023).
Saliency: The saliency method was originally introduced for image classification tasks using convolutional neural networks (CNNs) and is one of the earliest gradient-based explanation techniques (Simonyan et al. Reference Simonyan, Vedaldi and Zisserman2014). It treats a trained neural network as a locally linear function of its input around a given example. The primary objective is to identify which pixels in an input image are most influential for a particular class prediction. The ‘saliency map’ is defined as the gradient of the class score with respect to each input dimension, often visualized as the element-wise magnitude of this gradient. Intuitively, if a small change in a particular input dimension (e.g., a pixel intensity) leads to a large change in the class score, that dimension is considered important for the model’s decision for class
 $c$
.
$c$
.
Let
 $\mathbf{x} \in \mathbb{R}^d$
be an input and
$\mathbf{x} \in \mathbb{R}^d$
be an input and
 $S_c(\mathbf{x})$
the score for class
$S_c(\mathbf{x})$
the score for class
 $c$
. The saliency map for class
$c$
. The saliency map for class
 $c$
at
$c$
at
 $\mathbf{x}_0$
is defined as:
$\mathbf{x}_0$
is defined as:
 \begin{equation} M_c^{(i)}(\mathbf{x}_0) = \frac {\partial S_c(\mathbf{x}_0)}{\partial x_i}, \quad i=1,\ldots ,d. \end{equation}
\begin{equation} M_c^{(i)}(\mathbf{x}_0) = \frac {\partial S_c(\mathbf{x}_0)}{\partial x_i}, \quad i=1,\ldots ,d. \end{equation}
In NLP,
 $\mathbf{x}$
corresponds to token embeddings; we aggregate per-dimension gradients to obtain a scalar attribution per token (see Section 3).
$\mathbf{x}$
corresponds to token embeddings; we aggregate per-dimension gradients to obtain a scalar attribution per token (see Section 3).
Input
 $\times$
Gradient (I
$\times$
Gradient (I
 $\times$
G): It is a simple extension of saliency that combines information about how sensitive a prediction is to a feature with how strongly that feature is present in the input (Denil, Demiraj, and De Freitas Reference Denil, Demiraj and de Freitas2014). As in the saliency method, it considers the gradient of the class score with respect to the input, but instead of using the gradient alone, each input dimension is weighted by its own value. Intuitively, a feature should only be considered important if (i) small changes in that feature have a large effect on the score, and (ii) the feature is actually active in the current example. Raw gradients ignore the importance of the feature itself. I
$\times$
G): It is a simple extension of saliency that combines information about how sensitive a prediction is to a feature with how strongly that feature is present in the input (Denil, Demiraj, and De Freitas Reference Denil, Demiraj and de Freitas2014). As in the saliency method, it considers the gradient of the class score with respect to the input, but instead of using the gradient alone, each input dimension is weighted by its own value. Intuitively, a feature should only be considered important if (i) small changes in that feature have a large effect on the score, and (ii) the feature is actually active in the current example. Raw gradients ignore the importance of the feature itself. I
 $\times$
G takes this information into account by scaling the gradient by the input. In image models, this corresponds to weighting pixel-wise gradients by the pixel intensities. Let
$\times$
G takes this information into account by scaling the gradient by the input. In image models, this corresponds to weighting pixel-wise gradients by the pixel intensities. Let
 $\mathbf{x} \in \mathbb{R}^d$
be an input and
$\mathbf{x} \in \mathbb{R}^d$
be an input and
 $S_c(\mathbf{x})$
the score for class
$S_c(\mathbf{x})$
the score for class
 $c$
. The Input
$c$
. The Input
 $\times$
Gradient attribution for class
$\times$
Gradient attribution for class
 $c$
at
$c$
at
 $\mathbf{x}_0$
is defined as:
$\mathbf{x}_0$
is defined as:
 \begin{equation} M_c^{(i)}(\mathbf{x}_0) = x_{0,i}\,\frac {\partial S_c(\mathbf{x}_0)}{\partial x_i}, \quad i=1,\ldots ,d. \end{equation}
\begin{equation} M_c^{(i)}(\mathbf{x}_0) = x_{0,i}\,\frac {\partial S_c(\mathbf{x}_0)}{\partial x_i}, \quad i=1,\ldots ,d. \end{equation}
Layer Gradient
 $\times$
Activation (LG
$\times$
Activation (LG
 $\times$
A): LG
$\times$
A): LG
 $\times$
A applies I
$\times$
A applies I
 $\times$
G to a chosen hidden layer. Let
$\times$
G to a chosen hidden layer. Let
 $\mathbf{h}(\mathbf{x}_0)\in \mathbb{R}^{m}$
be its activation vector; the attribution for unit
$\mathbf{h}(\mathbf{x}_0)\in \mathbb{R}^{m}$
be its activation vector; the attribution for unit
 $j$
is:
$j$
is:
 \begin{equation} M_{c}^{(j)}(\mathbf{x}_0) = h_j(\mathbf{x}_0)\,\frac {\partial S_c(\mathbf{x}_0)}{\partial h_j}, \quad j=1,\ldots ,m. \end{equation}
\begin{equation} M_{c}^{(j)}(\mathbf{x}_0) = h_j(\mathbf{x}_0)\,\frac {\partial S_c(\mathbf{x}_0)}{\partial h_j}, \quad j=1,\ldots ,m. \end{equation}
Integrated Gradients (IG): IG is motivated by two axioms: (i) Sensitivity, which requires that features responsible for a change in the model output relative to a baseline receive non-zero attribution, and (ii) Implementation invariance, which requires that attributions depend only on the input–output function
 $S(\mathbf{x})$
, not on a particular network parameterization (Sundararajan et al. Reference Sundararajan, Taly and Yan2017). The authors define IG as:
$S(\mathbf{x})$
, not on a particular network parameterization (Sundararajan et al. Reference Sundararajan, Taly and Yan2017). The authors define IG as:
 \begin{equation} \mathrm{IG}_i(\mathbf{x}_0;\,\mathbf{x}') = (x_{0,i}-x'_i)\int _{0}^{1} \frac {\partial S_c \left (\mathbf{x}' + \alpha (\mathbf{x}_0-\mathbf{x}')\right )}{\partial x_i}\,d\alpha . \end{equation}
\begin{equation} \mathrm{IG}_i(\mathbf{x}_0;\,\mathbf{x}') = (x_{0,i}-x'_i)\int _{0}^{1} \frac {\partial S_c \left (\mathbf{x}' + \alpha (\mathbf{x}_0-\mathbf{x}')\right )}{\partial x_i}\,d\alpha . \end{equation}
Given an input
 $\mathbf{x}$
and a baseline
$\mathbf{x}$
and a baseline
 $\mathbf{x}'$
representing the absence of information (e.g., the zero vector), IG attributes feature
$\mathbf{x}'$
representing the absence of information (e.g., the zero vector), IG attributes feature
 $i$
by integrating gradients along the straight-line path from
$i$
by integrating gradients along the straight-line path from
 $\mathbf{x}'$
to
$\mathbf{x}'$
to
 $\mathbf{x}$
, capturing how the prediction changes as the input moves from the baseline to the actual example.
$\mathbf{x}$
, capturing how the prediction changes as the input moves from the baseline to the actual example.
Gradient SHAP (GSHAP): GSHAP mixes IG with SHAP and estimates SHAP-style (Lundberg et al. Reference Lundberg and Lee2017) attributions by averaging gradients over randomized reference points. For each of
 $n$
samples, it adds small noise to the input, draws a random baseline from a set of baselines, and picks a random interpolation point along the straight line to compute the gradientFootnote
c
.
$n$
samples, it adds small noise to the input, draws a random baseline from a set of baselines, and picks a random interpolation point along the straight line to compute the gradientFootnote
c
.
Deep learning important features (DeepLIFT): DeepLIFT explains a prediction by comparing the network’s response on an input
 $\mathbf{x}_0$
to a reference input
$\mathbf{x}_0$
to a reference input
 $\mathbf{x}'$
(Shrikumar, Greenside, and Kundaje Reference Shrikumar, Greenside and Kundaje2017). Instead of raw gradients, it propagates differences from reference layer by layer and assigns contribution scores to input features that sum to the output difference
$\mathbf{x}'$
(Shrikumar, Greenside, and Kundaje Reference Shrikumar, Greenside and Kundaje2017). Instead of raw gradients, it propagates differences from reference layer by layer and assigns contribution scores to input features that sum to the output difference
 $S_c(\mathbf{x}_0)-S_c(\mathbf{x}')$
, which helps mitigate gradient saturation and captures both positive and negative influences more reliably than standard gradient-based saliency methods.
$S_c(\mathbf{x}_0)-S_c(\mathbf{x}')$
, which helps mitigate gradient saturation and captures both positive and negative influences more reliably than standard gradient-based saliency methods.
Attention: In the Transformer model (Vaswani Reference Vaswani, Shazeer, Parmar, Uszkoreit, Jones, Gomez, Kaiser and Polosukhin2017), each token representation
 $x_t\in \mathbb{R}^{d_{\text{model}}}$
is linearly projected into a query, key, and value using learned parameter matrices
$x_t\in \mathbb{R}^{d_{\text{model}}}$
is linearly projected into a query, key, and value using learned parameter matrices
 $W_Q,W_K,W_V\in \mathbb{R}^{d_{\text{model}}\times d_k}$
. Scaled dot-product attention computes similarities between queries and keys, normalizes them with a softmax to obtain attention weights, and then uses these weights to form weighted sums of the values. In multi-head attention,
$W_Q,W_K,W_V\in \mathbb{R}^{d_{\text{model}}\times d_k}$
. Scaled dot-product attention computes similarities between queries and keys, normalizes them with a softmax to obtain attention weights, and then uses these weights to form weighted sums of the values. In multi-head attention,
 $H$
such projections
$H$
such projections
 $\{W_Q^{(h)},W_K^{(h)},W_V^{(h)}\}_{h=1}^{H}$
are used in parallel, and the concatenated head outputs are linearly projected back to the model dimension with a learned matrix
$\{W_Q^{(h)},W_K^{(h)},W_V^{(h)}\}_{h=1}^{H}$
are used in parallel, and the concatenated head outputs are linearly projected back to the model dimension with a learned matrix
 $W_O\in \mathbb{R}^{(H d_k)\times d_{\text{model}}}$
.
$W_O\in \mathbb{R}^{(H d_k)\times d_{\text{model}}}$
.
Given queries
 $Q\in \mathbb{R}^{T_q\times d_k}$
, keys
$Q\in \mathbb{R}^{T_q\times d_k}$
, keys
 $K\in \mathbb{R}^{T_k\times d_k}$
, and values
$K\in \mathbb{R}^{T_k\times d_k}$
, and values
 $V\in \mathbb{R}^{T_k\times d_v}$
, scaled dot-product attention is
$V\in \mathbb{R}^{T_k\times d_v}$
, scaled dot-product attention is
 \begin{equation} \mathrm{Attention}(Q,K,V) = \mathrm{softmax} \left (\frac {QK^\top }{\sqrt {d_k}}\right )\!V. \end{equation}
\begin{equation} \mathrm{Attention}(Q,K,V) = \mathrm{softmax} \left (\frac {QK^\top }{\sqrt {d_k}}\right )\!V. \end{equation}
In (5), the score matrix
 $QK^\top$
can be interpreted as pairwise similarity scores between queries and keys; after softmax normalization, these become attention weights that determine how strongly each query attends to each key.
$QK^\top$
can be interpreted as pairwise similarity scores between queries and keys; after softmax normalization, these become attention weights that determine how strongly each query attends to each key.
Value Zeroing (ValueZeroing): In the attention mechanism, the value vector
 $V_j$
for token
$V_j$
for token
 $j$
carries contextual content that is mixed into the representation of other tokens via attention weights derived from the
$j$
carries contextual content that is mixed into the representation of other tokens via attention weights derived from the
 $QK^\top$
scores. ValueZeroing is an ablation technique that quantifies how much a context token
$QK^\top$
scores. ValueZeroing is an ablation technique that quantifies how much a context token
 $j$
contributes to the representation of an output token at position
$j$
contributes to the representation of an output token at position
 $i$
by recomputing the model’s hidden representation at
$i$
by recomputing the model’s hidden representation at
 $i$
after zeroing out the value vector of token
$i$
after zeroing out the value vector of token
 $j$
, while keeping all keys and queries fixed (Mohebbi et al. Reference Mohebbi, Zuidema, Chrupała and Alishahi2023).
$j$
, while keeping all keys and queries fixed (Mohebbi et al. Reference Mohebbi, Zuidema, Chrupała and Alishahi2023).
Let
 $\tilde {\mathbf{x}}_i$
denote the original representation of the output token at position
$\tilde {\mathbf{x}}_i$
denote the original representation of the output token at position
 $i$
, and let
$i$
, and let
 $\tilde {\mathbf{x}}_i^{\neg j}$
denote the representation obtained when the value vector of token
$\tilde {\mathbf{x}}_i^{\neg j}$
denote the representation obtained when the value vector of token
 $j$
is replaced by the zero vector. The context-mixing score between output position
$j$
is replaced by the zero vector. The context-mixing score between output position
 $i$
and token
$i$
and token
 $j$
is defined as the cosine distance between these two representations:
$j$
is defined as the cosine distance between these two representations:
 \begin{equation} C_{i,j} = 1 - \cos \bigl (\tilde {\mathbf{x}}_i^{\neg j},\,\tilde {\mathbf{x}}_i\bigr ). \end{equation}
\begin{equation} C_{i,j} = 1 - \cos \bigl (\tilde {\mathbf{x}}_i^{\neg j},\,\tilde {\mathbf{x}}_i\bigr ). \end{equation}
Higher values of
 $C_{i,j}$
indicate that token
$C_{i,j}$
indicate that token
 $j$
induces a larger change in the output representation at position
$j$
induces a larger change in the output representation at position
 $i$
, and therefore has a stronger influence on that output.
$i$
, and therefore has a stronger influence on that output.
In this subsection, we briefly summarize the XAI attribution methods used in our comparison. Our goal was to include representatives from all three major families of attribution methods while also respecting practical constraints on computation. In particular, many perturbation-based methods are computationally expensive, and generating their attribution maps at scale for our datasets would be infeasible within a reasonable runtime.
3. Methodology
Inspired by the forward simulation of XAI methods (Hase et al. Reference Hase and Bansal2020), we design a pipeline to compare different explainability attribution maps based on their impact on model performance in the NMT task. For this purpose, we use teacher–student knowledge distillation (Hinton Reference Hinton, Vinyals and Dean2015) (Figure 2). In the first step, we use the Inseq libraryFootnote
d
to extract input–output attribution maps using the eight explainability algorithms specified in Subsection 2.5. The teacher model receives source-target sample pairs as input, and the output of Inseq is a set of attributions
 $ (\mathbf{x}, \mathbf{y}) \to E$
mapping the target to the source tokens . Then, the student models are trained under teacher forcing, receiving
$ (\mathbf{x}, \mathbf{y}) \to E$
mapping the target to the source tokens . Then, the student models are trained under teacher forcing, receiving
 $ (\mathbf{x}, \mathbf{y}, E)$
for training. During testing, the student model gets the source token and attributions to predict the target
$ (\mathbf{x}, \mathbf{y}, E)$
for training. During testing, the student model gets the source token and attributions to predict the target
 $ (\mathbf{x}, E) \to \hat {\mathbf{y}}$
.
$ (\mathbf{x}, E) \to \hat {\mathbf{y}}$
.
Gradient-based attributions are in the shape
 $ e \in \mathbb{R}^{j \times k \times l}$
, where
$ e \in \mathbb{R}^{j \times k \times l}$
, where
 $ j$
is the input sequence length,
$ j$
is the input sequence length,
 $ k$
is the output sequence length, and
$ k$
is the output sequence length, and
 $ l$
is the hidden dimension of the model. Gradient-based methods get the weight of the gradient for each individual input feature in the vector space. We aggregate these values along the last dimension by getting the L2 norm
$ l$
is the hidden dimension of the model. Gradient-based methods get the weight of the gradient for each individual input feature in the vector space. We aggregate these values along the last dimension by getting the L2 norm
 $\lVert \mathbf{e}_i \rVert _{2}$
of the token vectors. L2 norm represents the magnitude of a vector and has a non-negative value.Footnote
e
The final result is in the shape of
$\lVert \mathbf{e}_i \rVert _{2}$
of the token vectors. L2 norm represents the magnitude of a vector and has a non-negative value.Footnote
e
The final result is in the shape of
 $e\in \mathbb{R}^{ j\times k}$
. For all the attribution methods, we get the scores from the first layer of the transformer model. However, for LG
$e\in \mathbb{R}^{ j\times k}$
. For all the attribution methods, we get the scores from the first layer of the transformer model. However, for LG
 $\times$
A, where the attribution from the first layer is the same as I
$\times$
A, where the attribution from the first layer is the same as I
 $\times$
G, we chose to obtain attributions from the encoder’s last layer. Prior work has examined which task-relevant properties are encoded at different layers (Langedijk et al. Reference Langedijk, Mohebbi, Sarti, Zuidema and Jumelet2024), but for our purposes, the encoder’s final layer is the natural choice since its representations are the ones the decoder attends to when producing predictions.
$\times$
G, we chose to obtain attributions from the encoder’s last layer. Prior work has examined which task-relevant properties are encoded at different layers (Langedijk et al. Reference Langedijk, Mohebbi, Sarti, Zuidema and Jumelet2024), but for our purposes, the encoder’s final layer is the natural choice since its representations are the ones the decoder attends to when producing predictions.
The Attention attributions are extracted in the shape
 $e \in \mathbb{R}^{j \times k \times n \times h}$
, where
$e \in \mathbb{R}^{j \times k \times n \times h}$
, where
 $ j$
and
$ j$
and
 $ k$
are the same as before,
$ k$
are the same as before,
 $ n$
represents the number of layers of the transformers, and
$ n$
represents the number of layers of the transformers, and
 $ h$
is the number of attention heads. We then compute the average along both of the last two axes to obtain a final shape of
$ h$
is the number of attention heads. We then compute the average along both of the last two axes to obtain a final shape of
 $ e \in \mathbb{R}^{j \times k}$
. ValueZeroing yields the importance score for each layer, and therefore the scores are in the shape of
$ e \in \mathbb{R}^{j \times k}$
. ValueZeroing yields the importance score for each layer, and therefore the scores are in the shape of
 $e \in \mathbb{R}^{j \times k \times n}$
. Similarly, we get the average of the scores on the last dimension to reach
$e \in \mathbb{R}^{j \times k \times n}$
. Similarly, we get the average of the scores on the last dimension to reach
 $e \in \mathbb{R}^{j \times k}$
. To normalize and handle negative values in the attribution matrices, we apply the MinMaxScalerFootnote
f
to the columns of the attribution maps as follows:
$e \in \mathbb{R}^{j \times k}$
. To normalize and handle negative values in the attribution matrices, we apply the MinMaxScalerFootnote
f
to the columns of the attribution maps as follows:
 \begin{equation} \mathbf{e}'_{i,j} = \frac {\mathbf{e}_{i,j} - \min \limits _{i} (\mathbf{e}_{:,j})}{\max \limits _{i} (\mathbf{e}_{:,j}) - \min \limits _{i} (\mathbf{e}_{:,j})} \end{equation}
\begin{equation} \mathbf{e}'_{i,j} = \frac {\mathbf{e}_{i,j} - \min \limits _{i} (\mathbf{e}_{:,j})}{\max \limits _{i} (\mathbf{e}_{:,j}) - \min \limits _{i} (\mathbf{e}_{:,j})} \end{equation}
Minmax transformation rescales values linearly to the
 $[0,1]$
interval while preserving their rank and relative structure. This choice over the softmax function avoids the additional inductive bias introduced by a softmax transformation, which converts scores into a probability distribution whose shape depends nonlinearly on their scale and forces scores to compete with one another. In our setting, we were interested in comparing the pattern and relative magnitude of attributions across methods and tokens, rather than imposing a probabilistic interpretation. Minmax normalization, therefore, preserves the geometry of the original attribution map.Footnote
g
$[0,1]$
interval while preserving their rank and relative structure. This choice over the softmax function avoids the additional inductive bias introduced by a softmax transformation, which converts scores into a probability distribution whose shape depends nonlinearly on their scale and forces scores to compete with one another. In our setting, we were interested in comparing the pattern and relative magnitude of attributions across methods and tokens, rather than imposing a probabilistic interpretation. Minmax normalization, therefore, preserves the geometry of the original attribution map.Footnote
g
(a) Illustrates the overall design of our approach. The input sequence and the gold output
 $(\mathbf{x}, \mathbf{y})$
are given to a teacher model, and their attributions
$(\mathbf{x}, \mathbf{y})$
are given to a teacher model, and their attributions
 $E$
are obtained. Then, a new untrained model is trained using the same
$E$
are obtained. Then, a new untrained model is trained using the same
 $(\mathbf{x}, \mathbf{y}, E)$
triples. In the testing phase, the model gets the
$(\mathbf{x}, \mathbf{y}, E)$
triples. In the testing phase, the model gets the
 $(\mathbf{x}, E)\rightarrow \hat {\mathbf{y}}$
. (b) Shows two places where we inject the attributions obtained from XAI methods.
$(\mathbf{x}, E)\rightarrow \hat {\mathbf{y}}$
. (b) Shows two places where we inject the attributions obtained from XAI methods.

Figure 2 Long description
The diagram consists of two main parts. The first part, labeled (a), shows the overall design of the approach. It depicts a pre-trained teacher model receiving an input sequence and gold output, generating attributions, which are then used to train a student model. In the testing phase, the student model uses the input sequence and attributions to generate predicted outputs. The second part, labeled (b), illustrates the injection of attributions obtained from Explainable AI (XAI) methods into the student model's attention mechanism. The diagram includes various components such as input sequences, gold outputs, attributions, and the student model, highlighting the flow and interaction between these elements.
Next, the student model receives as input the triple
 $(\mathbf{x}, \mathbf{y}, \mathbf{E}')$
, where
$(\mathbf{x}, \mathbf{y}, \mathbf{E}')$
, where
 $\mathbf{E}'$
represents the (normalized) attribution map associated with the source–target pairs. Subsequently, we perform four distinct operations on the pre-softmax attention scores
$\mathbf{E}'$
represents the (normalized) attribution map associated with the source–target pairs. Subsequently, we perform four distinct operations on the pre-softmax attention scores
 $\mathbf{A}^{(h)} = \frac {Q^{(h)} {K^{(h)}}^\top }{\sqrt {d_k}}$
for each head
$\mathbf{A}^{(h)} = \frac {Q^{(h)} {K^{(h)}}^\top }{\sqrt {d_k}}$
for each head
 $h$
:
$h$
:
 \begin{align} \tilde {\text{Attention}}(Q, K, V, \mathbf{E}') &= \text{softmax}(\, f ( \mathbf{A}, \mathbf{E}' ) ) V, \end{align}
\begin{align} \tilde {\text{Attention}}(Q, K, V, \mathbf{E}') &= \text{softmax}(\, f ( \mathbf{A}, \mathbf{E}' ) ) V, \end{align}
where
 $f$
is one of the following operations (applied element-wise):
$f$
is one of the following operations (applied element-wise):
Addition (
 $+$
): add attributions to the attention scores:
$+$
): add attributions to the attention scores:
 \begin{equation} \tilde {\mathbf{A}}^{(h)} = \mathbf{A}^{(h)} + \mathbf{E}'. \end{equation}
\begin{equation} \tilde {\mathbf{A}}^{(h)} = \mathbf{A}^{(h)} + \mathbf{E}'. \end{equation}
Multiply (
 $\odot$
): element-wise multiplication with the attention scores:
$\odot$
): element-wise multiplication with the attention scores:
 \begin{equation} \tilde {\mathbf{A}}^{(h)} = \mathbf{A}^{(h)} \odot \mathbf{E}'. \end{equation}
\begin{equation} \tilde {\mathbf{A}}^{(h)} = \mathbf{A}^{(h)} \odot \mathbf{E}'. \end{equation}
Average (
 $\mu$
): take the average of attributions and attention scores:
$\mu$
): take the average of attributions and attention scores:
 \begin{equation} \tilde {\mathbf{A}}^{(h)} = \frac {\mathbf{A}^{(h)} + \mathbf{E}'}{2}. \end{equation}
\begin{equation} \tilde {\mathbf{A}}^{(h)} = \frac {\mathbf{A}^{(h)} + \mathbf{E}'}{2}. \end{equation}
Replace (
 $R$
): substitute the attention scores with attribution maps:
$R$
): substitute the attention scores with attribution maps:
 \begin{equation} \tilde {\mathbf{A}}^{(h)} \leftarrow \mathbf{E}'. \end{equation}
\begin{equation} \tilde {\mathbf{A}}^{(h)} \leftarrow \mathbf{E}'. \end{equation}
The last operation replaces
 $\mathbf{A}^{(h)}$
with
$\mathbf{A}^{(h)}$
with
 $\mathbf{E}'$
, completely substituting
$\mathbf{E}'$
, completely substituting
 $\frac {QK^\top }{\sqrt {d_k}}$
. The point of applying these simple element-wise operators is to treat the normalized attribution matrices
$\frac {QK^\top }{\sqrt {d_k}}$
. The point of applying these simple element-wise operators is to treat the normalized attribution matrices
 $\mathbf{E}'$
as soft importance weights over the similarity scores
$\mathbf{E}'$
as soft importance weights over the similarity scores
 $A^{(h)} = QK^\top$
in each attention head. Acting directly on
$A^{(h)} = QK^\top$
in each attention head. Acting directly on
 $QK^\top$
(i.e., at the level of the similarity matrix before softmax) rather than on the values
$QK^\top$
(i.e., at the level of the similarity matrix before softmax) rather than on the values
 $V$
or the hidden states confines the intervention to the alignment structure between source and target tokens, which is precisely what attribution methods aim to characterize.
$V$
or the hidden states confines the intervention to the alignment structure between source and target tokens, which is precisely what attribution methods aim to characterize.
The four operators correspond to qualitatively different ways of using
 $\mathbf{E}'$
as a scaling factor for the similarity matrix. The multiplicative update
$\mathbf{E}'$
as a scaling factor for the similarity matrix. The multiplicative update
 $\tilde {\mathbf{A}}^{(h)} = \mathbf{A}^{(h)} \odot \mathbf{E}'$
implements a gating mechanism where attributions close to zero suppress specific query–key interactions, whereas attributions close to one leave them largely unchanged. Also, from another perspective, multiplication has a more dire effect if the attribution maps are incorrect. In contrast, the additive update
$\tilde {\mathbf{A}}^{(h)} = \mathbf{A}^{(h)} \odot \mathbf{E}'$
implements a gating mechanism where attributions close to zero suppress specific query–key interactions, whereas attributions close to one leave them largely unchanged. Also, from another perspective, multiplication has a more dire effect if the attribution maps are incorrect. In contrast, the additive update
 $\tilde {\mathbf{A}}^{(h)} = \mathbf{A}^{(h)} + \mathbf{E}'$
behaves like a bias term on the similarity scores; when applied before softmax, it shifts probability mass toward positions preferred by the attribution map while preserving much of the relative structure induced by
$\tilde {\mathbf{A}}^{(h)} = \mathbf{A}^{(h)} + \mathbf{E}'$
behaves like a bias term on the similarity scores; when applied before softmax, it shifts probability mass toward positions preferred by the attribution map while preserving much of the relative structure induced by
 $QK^\top$
. The averaging operator
$QK^\top$
. The averaging operator
 $\tilde {\mathbf{A}}^{(h)} = \tfrac {1}{2}(\mathbf{A}^{(h)} + \mathbf{E}')$
can be seen as a symmetric compromise between the model’s own attention and the external explanation, which smooths extreme scores from both matrices. Finally, the replacement variant, which feeds
$\tilde {\mathbf{A}}^{(h)} = \tfrac {1}{2}(\mathbf{A}^{(h)} + \mathbf{E}')$
can be seen as a symmetric compromise between the model’s own attention and the external explanation, which smooths extreme scores from both matrices. Finally, the replacement variant, which feeds
 $\mathbf{E}'$
directly into the attention module in place of
$\mathbf{E}'$
directly into the attention module in place of
 $\frac {QK^\top }{\sqrt {d_k}}$
, provides a raw testbed in which the attribution map is treated as the only alignment signal. This yields an approximate lower bound on how well a given XAI method can affect the translation task.
$\frac {QK^\top }{\sqrt {d_k}}$
, provides a raw testbed in which the attribution map is treated as the only alignment signal. This yields an approximate lower bound on how well a given XAI method can affect the translation task.
By comparing these operators within the same teacher–student framework, we can probe two questions at once: (i) whether they are strong enough to reliably gate or reroute information flow, and (ii) to quantify the influence of attribution maps on the MT task. In all cases, applying
 $\mathbf{E}'$
as element-wise weights on
$\mathbf{E}'$
as element-wise weights on
 $QK^\top$
makes a source-target token pair suitable for forward-simulation style evaluation, since changes in translation quality can be traced back to the manipulation of the attention matrix by the XAI attribution maps.
$QK^\top$
makes a source-target token pair suitable for forward-simulation style evaluation, since changes in translation quality can be traced back to the manipulation of the attention matrix by the XAI attribution maps.
4. Results
In this section, we first describe our experimental setup, including datasets, metrics, and implementation details. We then analyze the results along four dimensions: (1) the comparison of eight attribution methods based on their influence on translation quality when integrated into the model; (2) the impact of the attribution injection location, comparing encoder self-attention and cross-attention modules; (3) the effect of selectively applying attributions to half of the attention heads (8 heads vs. 4 heads); (4) the ability of the student model to approximate the generation from the teacher model.
4.1 Experimental setup
To evaluate the proposed pipeline, we train the Marian-MT model (Tiedemann and Thottingal Reference Tiedemann and Thottingal2020)Footnote
h
on three datasets from scratch. We choose two datasets belonging to a more closely related language family: German
 $\rightarrow$
English (de-en) and French
$\rightarrow$
English (de-en) and French
 $\rightarrow$
English (fr-en). For the third dataset, we choose Arabic
$\rightarrow$
English (fr-en). For the third dataset, we choose Arabic
 $\rightarrow$
English (ar-en) due to its encoding and linguistic differences from the target language. For de-en and fr-en, we use the WMT14 dataset (Bojar et al. Reference Bojar, Buck, Federmann, Haddow, Koehn, Leveling, Monz, Pecina, Post, Saint-Amand, Soricut, Specia and Tamchyna2014), and for ar-en, we use the UN Parallel Corpus (Ziemski, Junczys-Dowmunt, and Pouliquen Reference Ziemski, Junczys-Dowmunt and Pouliquen2016).
$\rightarrow$
English (ar-en) due to its encoding and linguistic differences from the target language. For de-en and fr-en, we use the WMT14 dataset (Bojar et al. Reference Bojar, Buck, Federmann, Haddow, Koehn, Leveling, Monz, Pecina, Post, Saint-Amand, Soricut, Specia and Tamchyna2014), and for ar-en, we use the UN Parallel Corpus (Ziemski, Junczys-Dowmunt, and Pouliquen Reference Ziemski, Junczys-Dowmunt and Pouliquen2016).
We select 220,000 sample pairs from each dataset and preprocess them to suit our experimental setup. Considering the numerous seq2seq models we train from scratch, we impose constraints to efficiently manage the training process. Specifically, we limit both the input and output sequences to at most 128 tokens. Additionally, we discard samples with fewer than ten tokens and filter out pairs where the input-to-output length ratio (or vice versa) exceeds
 $1.7$
for de-en and fr-en. Since the validation and test sets of the WMT datasets are relatively small, we select an additional 15,000 samples from their training sets (without overlap with our training data). The UN Parallel Corpus does not include separate validation and test sets, so we extract 15,000 samples from the main dataset for validation and testing.
$1.7$
for de-en and fr-en. Since the validation and test sets of the WMT datasets are relatively small, we select an additional 15,000 samples from their training sets (without overlap with our training data). The UN Parallel Corpus does not include separate validation and test sets, so we extract 15,000 samples from the main dataset for validation and testing.
We use two teacher models from which we extract attribution maps: a) monolingual Marian-MT systems and b) multilingual mBART-large (Tang et al. Reference Tang, Tran, Li, Chen, Goyal, Chaudhary, Gu and Fan2020) models. We focus most of our analysis on Marian-MT, since it is substantially smaller than mBART and, therefore, more tractable for computing and training with attribution maps at scale, given its smaller vocabulary size. Marian-MT is a Transformer model with six encoder layers and six decoder layers, each layer containing eight attention heads. In contrast, mBART-large has 12 encoder and 12 decoder layers, each with 12 attention heads. As a multilingual model, mBART uses a much larger subword vocabulary than Marian-MT (on the order of 500k vs. roughly 50k token types), which further increases the computational cost of attribution extraction. The student model shares the same overall architecture as Marian-MT, with feed-forward dimensionality
 $ d_{\mathrm{ff}} = 2048$
and embedding dimensionality
$ d_{\mathrm{ff}} = 2048$
and embedding dimensionality
 $ d_{\mathrm{model}} = 512$
. We limit the maximum sequence length to
$ d_{\mathrm{model}} = 512$
. We limit the maximum sequence length to
 $ L_{\max } = 128$
, while keeping the number of layers
$ L_{\max } = 128$
, while keeping the number of layers
 $ N_{\mathrm{layers}}$
and attention heads
$ N_{\mathrm{layers}}$
and attention heads
 $ H$
unchanged. Overall, Marian-MT has around 74 million parameters, and mBART has 610 million parameters.
$ H$
unchanged. Overall, Marian-MT has around 74 million parameters, and mBART has 610 million parameters.
We train the student Marian-MT models for 20 epochs and apply early stopping after three consecutive epochs without improvement in validation loss. The student model employs the Swish activation function, as proposed by Ramachandran, Zoph, and Le (Reference Ramachandran, Zoph and Le2017), which has been shown to enhance training dynamics and convergence. We used 20 Nvidia V100 GPUs for our experiments.
Throughout our experiments, we report BLEU (Papineni et al. Reference Papineni, Roukos, Ward and Zhu2002), which measures n-gram overlap between system outputs and reference translations, and chrF (Popović Reference Popović2015), a character-level n-gram F-score. This combination is particularly appropriate in our setting. We deliberately do not report semantic evaluation metrics such as COMET for two reasons. First, we conceptualize attribution maps as an auxiliary ‘memory’ that the student model can use to reconstruct the future target sequence
 $Y$
from the teacher’s representations. Our objective is thus fidelity to the reference at the token level, for which BLEU and chrF are sufficient. Second, most of our source–target segments are relatively short, and our datasets are modest in size and length. Thus, COMET can be noisy and add limited additional insight beyond n-gram overlap. All in all, consistent changes across both BLEU and chrF provide sufficient evidence that attribution-guided attention priors affect the underlying translation behavior.
$Y$
from the teacher’s representations. Our objective is thus fidelity to the reference at the token level, for which BLEU and chrF are sufficient. Second, most of our source–target segments are relatively short, and our datasets are modest in size and length. Thus, COMET can be noisy and add limited additional insight beyond n-gram overlap. All in all, consistent changes across both BLEU and chrF provide sufficient evidence that attribution-guided attention priors affect the underlying translation behavior.
4.2 Effectiveness of attribution methods (Encoder attention)
This analysis evaluates the impact of eight XAI attribution methods on translation quality, comparing models with injected attribution maps and the baseline. Tables 1–3 present the BLEU and chrF of this setting and their delta compared to the baseline, using Marian-MT attributions, while 4, 5, and 6 represent the results of mBART attribution maps. The baseline models are trained and evaluated on the same dataset and settings, but without integrating attribution
 $E$
. The difference between the baseline and the models with attribution maps is an indicator that XAI attribution maps changed the results relative to the baseline.
$E$
. The difference between the baseline and the models with attribution maps is an indicator that XAI attribution maps changed the results relative to the baseline.
BLEU and chrF scores for de-en Marian-MT attributions. Scores followed by
 $\Delta$
over the baseline
$\Delta$
over the baseline

Table 1 Long description
The table presents BLEU and chrF scores for de-en Marian-MT attributions, showing the impact of various attribution methods on translation quality. It includes eight methods: I x G, Saliency, LG x A, IG, GSHAP, DeepLIFT, Attention, and ValueZeroing. The table has four rows and nine columns, with the columns labeled as Op., I x G, Saliency, LG x A, IG, GSHAP, DeepLIFT, Attention, and ValueZeroing. Each row represents a different operation or method, with scores and their deltas over the baseline. Notable trends include higher scores for the Attention and ValueZeroing methods across both BLEU and chrF metrics, indicating significant improvements over the baseline.
BLEU and chrF scores for fr-en Marian-MT attributions. Scores followed by
 $\Delta$
over the baseline
$\Delta$
over the baseline

Table 2 Long description
The table presents BLEU and chrF scores for fr-en Marian-MT attributions, comparing various methods and their delta over the baseline. The table has eight columns: I x G, Saliency, LG x A, IG, GSHAP, DeepLIFT, Attention, and ValueZeroing. Each column lists scores for four operations: plus, mu, odot, and R. The BLEU scores for fr-en have a baseline of 27.01, and the chrF scores have a baseline of 53.01. Notable trends include the highest BLEU scores for the ValueZeroing method under the plus operation, with a score of 47.8 and a delta of 20.8. The chrF scores also show the highest values for the ValueZeroing method under the plus operation, with a score of 65.5 and a delta of 12.5. The table provides a detailed comparison of how different attribution methods impact translation quality.
BLEU and chrF scores for ar-en Marian-MT attributions. Scores followed by
 $\Delta$
over the baseline
$\Delta$
over the baseline

Table 3 Long description
The table presents BLEU and chrF scores for ar-en Marian-MT attributions, showing the delta over the baseline. It includes eight XAI attribution methods: I x G, Saliency, LG x A, IG, GSHAP, DeepLIFT, Attention, and ValueZeroing. The table has four rows and nine columns, with the columns labeled as Op., I x G, Saliency, LG x A, IG, GSHAP, DeepLIFT, Attention, and ValueZeroing. Each row provides scores for different operations, with notable trends indicating that the Attention and ValueZeroing methods show the highest improvements over the baseline. The BLEU scores range from 47.3 to 68.7, and the chrF scores range from 68.7 to 81.0.
Starting with attribution maps extracted from Marian-MT, across all three language pairs, injecting attribution maps into the encoder’s attention mechanism consistently improved translation quality over the baseline models. The highest gains come from Attention, ValueZeroing, and LG
 $\times$
A. The highest BLEU gains ranged up to + 20.0 for de-en, +28.8 for fr-en, and + 27.9 for ar-en, with corresponding chrF gains up to + 13.3, +17.5, and + 14.9, respectively. Other gradient-based methods score quite similarly to each other, and among them, GSHAP scores lowest across all three language pairs. Importantly, BLEU and chrF changes were aligned, and the configurations that improved BLEU nearly always improved chrF by a similar margin and vice versa, indicating that the gains are not metric-specific but reflect genuine translation quality.
$\times$
A. The highest BLEU gains ranged up to + 20.0 for de-en, +28.8 for fr-en, and + 27.9 for ar-en, with corresponding chrF gains up to + 13.3, +17.5, and + 14.9, respectively. Other gradient-based methods score quite similarly to each other, and among them, GSHAP scores lowest across all three language pairs. Importantly, BLEU and chrF changes were aligned, and the configurations that improved BLEU nearly always improved chrF by a similar margin and vice versa, indicating that the gains are not metric-specific but reflect genuine translation quality.
For mBART attributions, there are more nuances. ValueZeroing scores higher than all other attribution methods in all cases. Attention maps that used to achieve higher scores on Marian-MT now score lower, and even for de-en, they degrade results in three out of four operators. Among the gradient-based methods, LG
 $\times$
A scores highest for all the operators and all the language pairs. GSHAP yields the weakest results. Similarly, in mBART fr-en, Attention and ValueZeroing with the best operator reached 59.7 and 63.0 BLEU (+32.6 and + 35.9), while GSHAP-based injections remained close to the baseline or produced only small improvements.
$\times$
A scores highest for all the operators and all the language pairs. GSHAP yields the weakest results. Similarly, in mBART fr-en, Attention and ValueZeroing with the best operator reached 59.7 and 63.0 BLEU (+32.6 and + 35.9), while GSHAP-based injections remained close to the baseline or produced only small improvements.
BLEU and chrF scores for de-en mBART attributions. Scores followed by
 $\Delta$
over the baseline
$\Delta$
over the baseline

Table 4 Long description
The table presents BLEU and chrF scores for de-en Marian-MT attributions, evaluating the impact of eight XAI attribution methods on translation quality. It compares models with injected attribution maps to a baseline. The table includes scores for methods such as I times G, Saliency, LG times A, IG, GSHAP, DeepLIFT, Attention, and ValueZeroing. Each method's scores are presented with their delta over the baseline. The baseline BLEU score for de-en is 26.08, and the baseline chrF score is 48.4. The table shows notable improvements in scores for certain methods, such as ValueZeroing, which shows the highest increase in both BLEU and chrF scores. The table is divided into rows for different operations (plus, mu, odot, R) and columns for each attribution method, with corresponding scores and deltas.
BLEU and chrF scores for fr-en mBART attributions. Scores followed by
 $\Delta$
over the baseline
$\Delta$
over the baseline

Table 5 Long description
The table presents BLEU and chrF scores for fr-en mBART attributions, showing the impact of eight XAI attribution methods on translation quality. It includes scores for various operations such as I x G, Saliency, LG x A, IG, GSHAP, DeepLIFT, Attention, and ValueZeroing. Each score is followed by a delta over the baseline, indicating the change relative to the baseline model. The table has four rows and nine columns, with row labels indicating different operations and column headers representing different attribution methods. Notable trends include significant improvements in scores for certain methods like Attention and ValueZeroing, with deltas indicating substantial positive changes over the baseline.
BLEU and chrF scores for ar-en mBART attributions. Scores followed by
 $\Delta$
over the baseline
$\Delta$
over the baseline

Table 6 Long description
The table presents BLEU and chrF scores for ar-en Marian-MT attributions, comparing various methods and their delta over the baseline. The table has eight columns: I x G, Saliency, LG x A, IG, GSHAP, DeepLIFT, Attention, and ValueZeroing. Each column shows scores for different operations: plus, mu, odot, and R. The BLEU scores for ar-en have a baseline of 40.68, and the chrF scores have a baseline of 66.07. Notable trends include the highest BLEU scores for the ValueZeroing method, with a delta of 22.1, and the highest chrF scores for the same method, with a delta of 11.6. The table provides a detailed comparison of how different attribution methods impact translation quality.
The choice of operator used to combine attributions with the original attention weights had a strong and systematic effect. Across attribution methods, language pairs, and models, the element-wise product operator (
 $\odot$
) consistently yielded the highest BLEU and chrF scores, while averaging (
$\odot$
) consistently yielded the highest BLEU and chrF scores, while averaging (
 $\mu$
) was almost always the worst-performing operator, with
$\mu$
) was almost always the worst-performing operator, with
 $+$
and
$+$
and
 $R$
lying in between. For instance, in Marian-MT de-en with ValueZeroing, BLEU improved from 25.82 (baseline) to 41.8 (+16.0) with
$R$
lying in between. For instance, in Marian-MT de-en with ValueZeroing, BLEU improved from 25.82 (baseline) to 41.8 (+16.0) with
 $+$
, 40.2 (+14.4) with
$+$
, 40.2 (+14.4) with
 $\mu$
, 41.9 (+16.1) with
$\mu$
, 41.9 (+16.1) with
 $R$
, and 45.8 (+20) with
$R$
, and 45.8 (+20) with
 $\odot$
. An analogous pattern appeared with Marian-MT fr-en and ar-en, where
$\odot$
. An analogous pattern appeared with Marian-MT fr-en and ar-en, where
 $\odot$
systematically dominated the other operators for all strong attribution sources. The same trend held with mBART: for fr-en, Attention with
$\odot$
systematically dominated the other operators for all strong attribution sources. The same trend held with mBART: for fr-en, Attention with
 $\odot$
reached 59.7 BLEU (+32.6) above the other operators, and ValueZeroing with
$\odot$
reached 59.7 BLEU (+32.6) above the other operators, and ValueZeroing with
 $\odot$
reached 63.0 BLEU (+35.9) versus 51.2, 45.2, and 48.9 BLEU for
$\odot$
reached 63.0 BLEU (+35.9) versus 51.2, 45.2, and 48.9 BLEU for
 $+,\mu$
and
$+,\mu$
and
 $R$
respectively. The magnitude of the difference between the operator for mBART Attention is higher than that for the others. We observed that mBART Attention assigns high values to the last source token (also visible in Figure 1), and that’s why other operators can’t contribute to the student model.
$R$
respectively. The magnitude of the difference between the operator for mBART Attention is higher than that for the others. We observed that mBART Attention assigns high values to the last source token (also visible in Figure 1), and that’s why other operators can’t contribute to the student model.
Finally, the patterns described above were consistent across de-en, fr-en, and ar-en for Marian-MT and across de-en and fr-en for mBART. Although the absolute baselines and magnitudes of improvement varied by language pair, the relative rankings of attribution sources and operators were nearly identical. This cross-lingual consistency suggests that certain XAI attribution methods provide more faithful target–source alignment signals than others, and that these signals can be leveraged as a reliable inductive bias for attention-guided knowledge distillation.
Overall ranking of attribution methods (best to worst).
For de-en, we obtain:
-
• Marian-MT: Attention
 $\approx$
ValueZeroing
$\gt$
LG
$\times$
A
$\gt$
IG
$\gt$
DeepLIFT
$\gt$
Saliency
$\gt$
I
$\times$
G
$\gt$
GSHAP
$\approx$
ValueZeroing
$\gt$
LG
$\times$
A
$\gt$
IG
$\gt$
DeepLIFT
$\gt$
Saliency
$\gt$
I
$\times$
G
$\gt$
GSHAP -
• mBART: ValueZeroing
$\gt$
Attention
$\gt$
LG
$\times$
A
$\gt$
IG
$\gt$
DeepLIFT
$\gt$
Saliency
$\gt$
I
$\times$
G
$\gt$
GSHAP


















For fr-en, we obtain:
-
• Marian-MT: Attention
$\gt$
ValueZeroing
$\gt$
LG
$\times$
A
$\gt$
IG
$\gt$
Saliency
$\gt$
DeepLIFT
$\gt$
I
$\times$
G
$\gt$
GSHAP -
• mBART: ValueZeroing
$\gt$
Attention
$\gt$
LG
$\times$
A
$\gt$
DeepLIFT
$\gt$
Saliency
$\gt$
I
$\times$
G
$\approx$
IG
$\gt$
GSHAP


















For ar-en, we obtain:
-
• Marian-MT: ValueZeroing
$\gt$
Attention
$\gt$
LG
$\times$
A
$\gt$
DeepLIFT
$\approx$
IG
$\approx$
Saliency
$\gt$
I
$\times$
G
$\gt$
GSHAP -
• mBART: ValueZeroing
$\gt$
Attention
$\gt$
LG
$\times$
A
$\gt$
Saliency
$\gt$
DeepLIFT
$\gt$
I
$\times$
G
$\gt$
IG
$\gt$
GSHAP


















4.3 Encoder self-attention versus cross-attention injection
In contrast to the encoder self-attention experiments, injecting attributions into cross-attention rarely improved translation quality and often degraded it (Tables 7–9). Across de-en, fr-en, and ar-en, most attribution–operator combinations reduced BLEU and chrF relative to the baseline. The only consistent but modest gains were observed for de-en and fr-en when using gradient-based attributions (IG, LG
 $\times$
A) with a multiplicative operator (
$\times$
A) with a multiplicative operator (
 $\odot$
), yielding up to + 4.7 BLEU and + 1.0 chrF. ValueZeroing and teacher Attention, which were highly effective for encoder attention, provided little benefit in cross-attention and frequently harmed performance, while GSHAP was consistently detrimental. Replacement of cross-attention weights (R) was particularly destructive, often leading to large drops in BLEU and chrF. These patterns suggest that cross-attention is substantially more brittle than encoder attention, and its alignment structure can only tolerate very limited attribution guidance, and even then, the resulting gains are small and not always reflected consistently across evaluation settings. While the exact reason that attribution injection to the cross-attention does not work is obscure and hard to pinpoint, our primary hypothesis is that during autoregressive inference, due to a decoding strategy such as beam search, the fixed sequence of the attributions for generated targets confuses the model. In other words, the model can deviate from the ground-truth sentence during autoregressive generation, but attributions are added for the fixed sequence of tokens, which not only no longer matches the tokens generated by the model but also actively prevents it from being able to correct itself.Footnote
i
$\odot$
), yielding up to + 4.7 BLEU and + 1.0 chrF. ValueZeroing and teacher Attention, which were highly effective for encoder attention, provided little benefit in cross-attention and frequently harmed performance, while GSHAP was consistently detrimental. Replacement of cross-attention weights (R) was particularly destructive, often leading to large drops in BLEU and chrF. These patterns suggest that cross-attention is substantially more brittle than encoder attention, and its alignment structure can only tolerate very limited attribution guidance, and even then, the resulting gains are small and not always reflected consistently across evaluation settings. While the exact reason that attribution injection to the cross-attention does not work is obscure and hard to pinpoint, our primary hypothesis is that during autoregressive inference, due to a decoding strategy such as beam search, the fixed sequence of the attributions for generated targets confuses the model. In other words, the model can deviate from the ground-truth sentence during autoregressive generation, but attributions are added for the fixed sequence of tokens, which not only no longer matches the tokens generated by the model but also actively prevents it from being able to correct itself.Footnote
i
BLEU and chrF scores for de-en Cross-attention Marian-MT attributions (Baseline: 25.82). Scores followed by
 $\Delta$
over the baseline
$\Delta$
over the baseline

Table 7 Long description
The table presents BLEU and chrF scores for de-en Cross-attention Marian-MT attributions, comparing different operators and their impact on translation quality. The table includes columns for different operators such as plus, mu, circle, and R, along with their respective scores for Saliency, LG times A, IG, GSHAP, DeepLIFT, Attention, and ValueZeroing. Each cell contains a score followed by a delta over the baseline. Notable trends include the consistent but modest gains observed for de-en and fr-en when using gradient-based attributions with a multiplicative operator, yielding up to plus 4.7 BLEU and plus 1.0 chrF. ValueZeroing and teacher Attention, which were highly effective for encoder attention, provided little benefit in cross-attention and frequently harmed performance. Replacement of cross-attention weights was particularly destructive, often leading to large drops in BLEU and chrF. These patterns suggest that cross-attention is substantially more brittle than encoder attention.
BLEU and chrF scores for fr-en Cross-attention Marian-MT attributions (Baseline: 27.01). Scores followed by
 $\Delta$
over the baseline
$\Delta$
over the baseline

Table 8 Long description
The table presents BLEU and chrF scores for French to English Cross-attention Marian-MT attributions, with a baseline of 27.01 for BLEU and 53.01 for chrF. It includes scores for different operations such as I times G, Saliency, LG times A, IG, GSHAP, DeepLIFT, Attention, and ValueZeroing. Each operation's score is followed by its deviation from the baseline. The table has two main sections: BLEU scores and chrF scores, each with four rows labeled with different operations. Notable trends include the highest BLEU score of 31.7 for the operation labeled with the circle symbol, indicating a significant positive deviation of plus 4.7 from the baseline. The lowest BLEU score is 16.6 for the operation labeled R, showing a substantial negative deviation of minus 10.4. For chrF scores, the highest value is 53.5 for the operation labeled with the circle symbol, with a slight positive deviation of plus 0.5, while the lowest is 43.8 for the operation labeled R, with a notable negative deviation of minus 9.2. The table provides a detailed comparison of how different attribution methods impact the performance metrics for the Marian-MT model.
4.4 Selective attribution injection (8 vs. 4 heads)
In another setting, as an ablation study, we applied the attribution methods to only 4 heads out of the 8 heads of the attention, only using Marian-MT attributions. We conduct these experiments only on the encoder side, as previous results showed that these attribution mappings can be useful at this part of the architecture. Tables 14–16 show the results of this comparison. This analysis investigates how reducing the number of attention heads affects the model’s performance when integrating attribution scores. By selectively applying attributions to only four heads (every other head), we assess whether information flow can still be captured and whether the model retains its translation quality. The changes in BLEU and chrF scores between 8-head and 4-head settings are relatively minor. However, some methods and operators show slight improvements. The results suggest that combining standard attention mechanisms with attribution-based operators can be a ‘best of both worlds’ approach, as some heads learn the standard attention mechanisms while others utilize the attribution maps.
BLEU and chrF scores for ar-en Cross-attention Marian-MT attributions (Baseline: 40.68). Scores followed by
 $\Delta$
over the baseline
$\Delta$
over the baseline

Table 9 Long description
The table presents BLEU and chrF scores for ar-en cross-attention Marian-MT attributions, comparing various operators and methods against a baseline. The table includes columns for different operators (Op), Input times Gradient Saliency (I x G), Saliency, LG times A, Input Gradient (IG), GSHAP, DeepLIFT, Attention, and ValueZeroing. Each row shows the scores for these methods, with scores followed by a delta over the baseline. Notable trends include the consistent degradation of translation quality when injecting attributions into cross-attention, with few modest gains observed for specific methods. The table highlights that cross-attention is more brittle than encoder attention and that attribution guidance often harms performance.
4.5 Faithfulness (predicting the model’s output)
Up to this point, our experiments have relied on the assumption that attribution maps should help the student model better predict the gold (human) translation. Faithfulness, in contrast, relates to how precisely an attribution method captures the model’s internal reasoning process that produces a particular output (Jacovi et al. Reference Jacovi and Goldberg2020). Put differently, a faithful attribution provides a close approximation of the model’s actual decision-making procedure that produced the prediction.
To investigate this notion in a teacher–student setting, we replace the human reference with the teacher’s behavior as the supervision signal. Given a source input
 $\mathbf{x}$
, we run the teacher model to produce a translation
$\mathbf{x}$
, we run the teacher model to produce a translation
 $\hat {\mathbf{y}}$
and compute the corresponding attribution map
$\hat {\mathbf{y}}$
and compute the corresponding attribution map
 $\hat {\mathbf{E}}$
with respect to this generated output, yielding training triples
$\hat {\mathbf{E}}$
with respect to this generated output, yielding training triples
 $(\mathbf{x}, \hat {\mathbf{y}}, \hat {\mathbf{E}})$
. The student model is then trained on
$(\mathbf{x}, \hat {\mathbf{y}}, \hat {\mathbf{E}})$
. The student model is then trained on
 $(\mathbf{x}, \hat {\mathbf{y}}, \hat {\mathbf{E}})$
exactly as in our earlier experiments, injecting
$(\mathbf{x}, \hat {\mathbf{y}}, \hat {\mathbf{E}})$
exactly as in our earlier experiments, injecting
 $\hat {\mathbf{E}}$
into its attention mechanism. At test time, we provide the student model with
$\hat {\mathbf{E}}$
into its attention mechanism. At test time, we provide the student model with
 $(\mathbf{x}, \hat {\mathbf{E}})$
and generate a student translation
$(\mathbf{x}, \hat {\mathbf{E}})$
and generate a student translation
 $\hat {\mathbf{y}}'$
, that is
$\hat {\mathbf{y}}'$
, that is
 $(\mathbf{x}, \hat {\mathbf{E}}) \mapsto \hat {\mathbf{y}}'$
. We then compare
$(\mathbf{x}, \hat {\mathbf{E}}) \mapsto \hat {\mathbf{y}}'$
. We then compare
 $\hat {\mathbf{y}}'$
with
$\hat {\mathbf{y}}'$
with
 $\hat {\mathbf{y}}$
to quantify how well the student model can reproduce the teacher’s outputs when guided by a given attribution method. Under this setup, we hypothesize that attribution maps that better capture the teacher’s input–output dependencies will provide more useful guidance and, in turn, enable the student to generate translations
$\hat {\mathbf{y}}$
to quantify how well the student model can reproduce the teacher’s outputs when guided by a given attribution method. Under this setup, we hypothesize that attribution maps that better capture the teacher’s input–output dependencies will provide more useful guidance and, in turn, enable the student to generate translations
 $\hat {\mathbf{y}}'$
that are closer to
$\hat {\mathbf{y}}'$
that are closer to
 $\hat {\mathbf{y}}$
. The resulting agreement between
$\hat {\mathbf{y}}$
. The resulting agreement between
 $\hat {\mathbf{y}}'$
and
$\hat {\mathbf{y}}'$
and
 $\hat {\mathbf{y}}$
therefore serves as an empirical proxy for the utility of the underlying attribution maps for simulating the teacher model.
$\hat {\mathbf{y}}$
therefore serves as an empirical proxy for the utility of the underlying attribution maps for simulating the teacher model.
BLEU and chrF scores for de-en generated by the Marian-MT model. Scores followed by
 $\Delta$
over the baseline
$\Delta$
over the baseline

Table 10 Long description
The table presents BLEU and chrF scores for de-en generated by the Marian-MT model, with scores followed by deviations over the baseline. The table includes columns for different operational metrics such as I times G, Saliency, LG times A, IG, GSHAP, DeepLIFT, Attention, and ValueZeroing. Each row represents different operations denoted by symbols such as plus, mu, circle with a dot, and R. The BLEU scores for de-en have a baseline of 54.55, and the chrF scores for de-en have a baseline of 72.77. Notable trends include the highest BLEU scores for the operation denoted by the circle with a dot in the Attention column and the highest chrF scores for the same operation in the ValueZeroing column. The table provides a detailed comparison of how different operations affect the BLEU and chrF scores.
BLEU and chrF scores for fr-en generated by the Marian-MT model. Scores followed by
 $\Delta$
over the baseline
$\Delta$
over the baseline

Table 11 Long description
The table presents BLEU and chrF scores for French to English translations generated by the Marian-MT model, with scores compared to a baseline. It includes various operational methods such as I times G, Saliency, LG times A, IG, GSHAP, DeepLIFT, Attention, and ValueZeroing. The table has two main sections: BLEU scores and chrF scores, each with multiple rows and columns. Notable trends include significant improvements in scores for certain methods, particularly in the Attention and ValueZeroing columns. The baseline scores for BLEU and chrF are 53.38 and 74.05, respectively. The table highlights the performance differences across various methods, with some methods showing substantial gains over the baseline.
BLEU and chrF scores for ar-en generated by the Marian-MT model. Scores followed by
 $\Delta$
over the baseline
$\Delta$
over the baseline

Table 12 Long description
The table presents BLEU and chrF scores for ar-en generated by the Marian-MT model, with scores followed by a delta over the baseline. The table is divided into two sections: BLEU scores and chrF scores. Each section lists different operations (denoted as Op.) and their corresponding scores across various metrics such as I x G, Saliency, LG x A, IG, GSHAP, DeepLIFT, Attention, and ValueZeroing. The BLEU scores section shows baseline scores and the impact of different operations on these scores, with notable increases in scores for operations like +, μ, ⊙, and R. The chrF scores section similarly shows baseline scores and the impact of different operations, with significant increases in scores for operations like +, μ, ⊙, and R. The table highlights how different operations affect the performance metrics of the Marian-MT model for ar-en translation.
BLEU scores for random attribution matrices (left) and diagonal attribution matrices (right). Scores followed by
 $\Delta$
over the baseline
$\Delta$
over the baseline

Table 13 Long description
A table with two main sections comparing BLEU scores for random attribution matrices on the left and diagonal attribution matrices on the right. The table has four rows and six columns. The columns are labeled with language pairs: de-en, fr-en, and ar-en. Each cell contains a BLEU score followed by a delta value indicating the difference from the baseline. The rows are labeled with different operations: I × G Saliency, LG × A, IG, GSHAP, DeepLIFT, Attention, ValueZeroing, μ, ⊙, and R. Notable trends include higher BLEU scores for the ar-en language pair across most operations, with significant positive deltas indicating improvements over the baseline.
BLEU and chrF scores for de-en Marian-MT 4 head attribution injection. Scores followed by
 $\Delta$
over the baseline
$\Delta$
over the baseline

Table 14 Long description
The table presents a comparison of BLEU and chrF scores for de-en Marian-MT 4 head attribution injection. It includes performance metrics across different operators and methods, with scores followed by a delta over the baseline. The table has 8 rows and 10 columns, with column headers including Op, IxG, Saliency, LGxA, IG, GSHAP, DeepLIFT, Attention, and ValueZeroing. Each row provides specific scores for these columns, indicating the impact of different attribution methods on model performance. The BLEU scores section shows baseline scores and variations for each method, while the chrF scores section does the same. Notable trends include slight improvements in some methods and operators when reducing the number of attention heads from 8 to 4, suggesting that combining standard attention mechanisms with attribution-based operators can enhance model performance.
BLEU and chrF scores for fr-en Marian-MT 4 head attribution injection. Scores followed by
 $\Delta$
over the baseline
$\Delta$
over the baseline

Table 15 Long description
The table presents BLEU and chrF scores for French to English Marian-MT 4 head attribution injection, with scores followed by a delta over the baseline. The table has two main sections: BLEU scores for fr-en and chrF scores for fr-en. Each section contains data for different operations (I x G, Saliency, LG x A, IG, GSHAP, DeepLIFT, Attention, ValueZeroing) and their respective scores. The BLEU scores section shows scores for operations such as plus, mu, circle, and R, with values ranging from 31.2 to 56.1. The chrF scores section similarly lists scores for the same operations, with values ranging from 53.1 to 70.8. Notable trends include higher scores for the Attention and ValueZeroing operations across both BLEU and chrF metrics.
Here, we present the results of this setup for the Marian-MT model in Tables 10–12. The first observation is that the baseline scores are substantially higher for predicting the teacher’s generation compared to the gold data (BLEU scores 54.55 vs 25.82 for de-en, 53.38 vs 27.01 for fr-en, 59.45 vs 40.68 for ar-en). As in the previous setting, injecting attribution maps into the encoder attention substantially improves performance over the baseline student for Attention and Value Zeroing. For de-en, the best configuration reaches 75.4 BLEU and 85.1 chrF (vs. 54.55/72.77 for the baseline), for fr-en 83.0 BLEU and 90.3 chrF (vs. 53.38/74.05), and for ar-en 82.8 BLEU and 90.0 chrF (vs. 59.45/77.96). In these cases, attribution-guided encoder attention markedly reduces the student–teacher gap, with absolute BLEU gains of + 20–30 points, comparable to the gains observed when training on human references, albeit from a higher baseline.
At a high level, the hierarchy of attribution maps remains similar to the human-reference setting. Across de-en, fr-en, and ar-en, the largest gains again come from Attention and ValueZeroing, followed by the gradient-based methods, with GSHAP consistently being the weakest. Aggregating across language pairs, the approximate ordering under the faithfulness objective is
 $\text{Attention} \approx \text{ValueZeroing} \gt \text{LG$\times $A} \gt \text{IG} \gt \text{Saliency} \gt \text{I$\times $G} \approx \text{DeepLIFT} \gt \text{GSHAP}$
with slight nuances for ar-en where IG ranks lower. Because the baseline is already higher, some methods and operators fail to help the student model. For example, in Saliency for fr-en, addition does not change the result from the baseline, whereas multiplication yields improvements. I
$\text{Attention} \approx \text{ValueZeroing} \gt \text{LG$\times $A} \gt \text{IG} \gt \text{Saliency} \gt \text{I$\times $G} \approx \text{DeepLIFT} \gt \text{GSHAP}$
with slight nuances for ar-en where IG ranks lower. Because the baseline is already higher, some methods and operators fail to help the student model. For example, in Saliency for fr-en, addition does not change the result from the baseline, whereas multiplication yields improvements. I
 $\times$
G and DeepLIFT can also degrade the results for fr-en with (
$\times$
G and DeepLIFT can also degrade the results for fr-en with (
 $\mu$
) operator. From the operator’s point of view, the element-wise product operator (
$\mu$
) operator. From the operator’s point of view, the element-wise product operator (
 $\odot$
) yields the largest changes, simple averaging (
$\odot$
) yields the largest changes, simple averaging (
 $\mu$
) is almost always the weakest operator, and
$\mu$
) is almost always the weakest operator, and
 $+$
and
$+$
and
 $R$
lie in between. For example, in fr-en, the best
$R$
lie in between. For example, in fr-en, the best
 $\odot$
configuration with ValueZeroing reaches 83.0 BLEU (+29.6) and 90.2 chrF (+16.2) relative to the baseline student, whereas the corresponding
$\odot$
configuration with ValueZeroing reaches 83.0 BLEU (+29.6) and 90.2 chrF (+16.2) relative to the baseline student, whereas the corresponding
 $+$
,
$+$
,
 $\mu$
, and
$\mu$
, and
 $R$
configurations with ValueZeroing remain between 74.3–80.6 BLEU and 85.2–89.0 chrF. A similar pattern holds for de-en and ar-en. Table 17 (see Appendix) provides an example illustrating the output of encoder attention injection for Marian-MT, mBART and predicting Marian-MT generation.
$R$
configurations with ValueZeroing remain between 74.3–80.6 BLEU and 85.2–89.0 chrF. A similar pattern holds for de-en and ar-en. Table 17 (see Appendix) provides an example illustrating the output of encoder attention injection for Marian-MT, mBART and predicting Marian-MT generation.
BLEU and chrF scores for ar-en Marian-MT 4 head attribution injection. Scores followed by
 $\Delta$
over the baseline
$\Delta$
over the baseline

Table 16 Long description
The table presents a comparison of BLEU and chrF scores for ar-en Marian-MT 4 head attribution injection. It includes performance metrics across different operators and methods, with scores followed by a delta over the baseline. The table has 10 rows and 10 columns, with column headers including Op, IxG, Saliency, LGxA, IG, GSHAP, DeepLIFT, Attention, and ValueZeroing. Each row provides specific scores for these columns, indicating the impact of different attribution methods on model performance. The BLEU scores section shows baseline scores and variations for each operator, while the chrF scores section does the same. Notable trends include slight improvements in some methods and operators when reducing the number of attention heads from 8 to 4, suggesting that combining standard attention mechanisms with attribution-based operators can enhance model performance.
5. Discussion
Because these attribution mappings come from trained models on larger datasets, they encode a learned relation between the source and target pairs, which otherwise cannot be learned by the student model. We conjectured that a better learned mapping can contribute to better results, and hence it can be a way of comparison between XAI attribution methods. In Subsection 4.2, we presented the main findings and contributions of this work. Expanding on our observations, we saw some consistent results for the injection of Marian-MT and mBART attributions into the encoder-attention, with some nuances for the mBART attributions. Particularly for the Marian-MT attributions, we saw improvements in almost all the attribution maps. As a sanity check, we conducted the same experiments with two settings: (1) Injecting random attribution maps taken from a uniform distribution and (2) using nearly diagonal matrices. Table 13 shows the results of these experiments:
The results of these experiments show that the network still learns, albeit with degraded performance. We conclude that non-sensical attribution maps can indeed reduce results, even when a pattern, such as a quasi-diagonal attribution matrix, is present, and that the increase is not accidental. There should be some meaningful alignment encoded by the XAI attribution maps.
While a linguistic and qualitative analysis of the differences between each attribution method, and whether there is a gold standard alignment in which these attributions approximate, is outside the scope of this work, we would like to examine some topological differences and similarities among the attribution matrices. For this reason, we treat each column of the matrices as a probability distribution, from which we can calculate entropy as a measure of confidence in selecting the most important source tokens for the target tokens. Our manual inspection using heatmap visualization, such as Figure 1, showed that higher-scoring attribution methods exhibit more concentrated values around some tokens, and we observed more linear and diagonal patterns.
Figures 3–5 confirm that the three higher attribution maps, ValueZeroing, Attention, and LG
 $\times$
A, have lower entropies compared to other methods. For mBART, the entropy of gradient-based methods is higher than that of Marian-MT. One plausible explanation is that, in a deeper model with a longer computational graph, gradient signals become less sharp as they propagate toward earlier layers (Balduzzi et al. Reference Balduzzi, Frean, Lewis, Leary, Kurt and McWilliams2017). In particular, LG
$\times$
A, have lower entropies compared to other methods. For mBART, the entropy of gradient-based methods is higher than that of Marian-MT. One plausible explanation is that, in a deeper model with a longer computational graph, gradient signals become less sharp as they propagate toward earlier layers (Balduzzi et al. Reference Balduzzi, Frean, Lewis, Leary, Kurt and McWilliams2017). In particular, LG
 $\times$
A at the last layer of the encoder is more informative according to the results. For mBART, we observe that lower-scoring gradient-based attribution maps exhibit higher entropy than those of Marian-MT. Indeed, we can visually confirm that gradient-based methods have more chaotic representations. One point to note is that entropy does not necessarily completely correlate with the results. For example, for mBART, although the Entropy of Attention is lower, we observe that the last input token receives the most weight for all target tokens, which, in turn, leads to lower entropy. An observation that was confirmed by (Kobayashi et al. Reference Kobayashi, Kuribayashi, Yokoi and Inui2020), and in general, ValueZeroing scored higher for this model.
$\times$
A at the last layer of the encoder is more informative according to the results. For mBART, we observe that lower-scoring gradient-based attribution maps exhibit higher entropy than those of Marian-MT. Indeed, we can visually confirm that gradient-based methods have more chaotic representations. One point to note is that entropy does not necessarily completely correlate with the results. For example, for mBART, although the Entropy of Attention is lower, we observe that the last input token receives the most weight for all target tokens, which, in turn, leads to lower entropy. An observation that was confirmed by (Kobayashi et al. Reference Kobayashi, Kuribayashi, Yokoi and Inui2020), and in general, ValueZeroing scored higher for this model.
6. Attribution approximator
From the previous experiments, particularly those involving the attention mechanism (Attention attributions and ValueZeroing), we developed a hypothesis that the usefulness of an attribution method is largely determined by how geometrically close its maps are to those that a transformer can generate. This hypothesis motivates the introduction of a dedicated Attributor network. The Attributor is trained to approximate target–source attribution matrices corresponding to different explanation methods. Concretely, given a source sequence and its target sequence, the Attributor network learns to reconstruct the associated attribution matrix. We implement it as an encoder–decoder transformer so that the function class used to model attributions closely matches the inductive biases of the student translation model itself. Intuitively, if the student model can internally reproduce a particular attribution pattern, then it should also be better positioned to exploit that signal when the same attribution is injected into its attention layers, which in turn leads to more effective attribution-guided translation.
6.1 Attributor implementation
Our proposed Attributor network is a lightweight encoder–decoder transformer. The source sentence is tokenized and mapped to learned token embeddings, which are combined with learned positional embeddings and then processed by a 3-layer, 8-head self-attention encoder. The target sentence is embedded separately with its own learned positional embeddings and passed through 3 causal decoder layers. A standard triangular mask enforces autoregressive ordering to ensure that each target position attends only to previous target tokens. The resulting contextualized source and target embeddings are then fed into a modified cross-attention layer. For each target position of each attention head it returns a row attention score vector over source positions, which are essentially vectors of the per-head attention score matrices.
Column-wise entropy based on Marian-MT attributions.

Figure 3 Long description
Three violin plots compare mean entropy per sentence across different attribution methods for three language pairs. Each plot represents a different language pair: de-en, fr-en, and ar-en. The attribution methods listed vertically include IG, Saliency, LXA, IG, Attribution Method, GSHP, DeepLIFT, Attention, and ValueZering. The x-axis measures mean entropy per sentence in bits, ranging from 0 to 6. Each violin plot shows the distribution of entropy values for each attribution method, with summary statistics provided in the legend. The plots reveal variations in entropy distributions across different methods and language pairs, highlighting differences in how each method attributes importance to input features.
Column-wise entropy based on mBART attributions.

Figure 4 Long description
Three violin plots compare mean entropy per sentence in bits across different attribution methods for three language pairs using mBART. Each plot represents a different language pair: de-en, fr-en, and ar-en. The attribution methods include IG, Saliency, LXA, IG Attribution Method, GSHAP, DeepLIFT, Attention, and Valueazing. The x-axis represents mean entropy per sentence in bits, ranging from 1 to 7. The y-axis lists the attribution methods. Each violin plot shows the distribution of entropy values for each method, with summary statistics including median, quartiles, and density. The plots reveal variations in entropy distributions across different methods and language pairs, highlighting differences in how each method attributes importance to input features in shaping model outputs.
Column-wise entropy based on Marian-MT attributions (Marian-MT-generated targets).

Figure 5 Long description
Three violin plots compare mean entropy per sentence using different attribution methods for Marian-MT-generated targets in three language pairs. Each plot represents a different language pair: de-en, fr-en, and ar-en. The attribution methods include IG, Saliency, LXA, IG, GSHAP, DeepLIFT, Attention, and ValueZeroing. The x-axis represents mean entropy per sentence in bits, ranging from 0 to 6. Each violin plot shows the distribution of entropy values for each attribution method. The summary statistics box within each plot provides the mean, standard deviation, and other statistical measures for each method. The plots reveal variations in entropy distributions across different attribution methods and language pairs, highlighting differences in how these methods attribute importance to input features in Marian-MT-generated sequences.
More formally, let
 $H$
denote the number of heads and
$H$
denote the number of heads and
 $S$
the number of source positions. For each target token
$S$
the number of source positions. For each target token
 $t$
, the cross-attention block produces per-head attention vectors
$t$
, the cross-attention block produces per-head attention vectors
 $\vec {s}_{t,h} \in \mathbb{R}^{S}$
:
$\vec {s}_{t,h} \in \mathbb{R}^{S}$
:
 \begin{equation} \vec {s}_{t,h} = \frac {\vec {q}_{t,h} K_{h}^\top }{\sqrt {d_k}} + \text{mask}, \quad h = 1,\ldots ,H, \end{equation}
\begin{equation} \vec {s}_{t,h} = \frac {\vec {q}_{t,h} K_{h}^\top }{\sqrt {d_k}} + \text{mask}, \quad h = 1,\ldots ,H, \end{equation}
where
 $\vec {q}_{t,h}, K_{h} \in \mathbb{R}^{d_k}$
are the query and key projections.
$\vec {q}_{t,h}, K_{h} \in \mathbb{R}^{d_k}$
are the query and key projections.
To aggregate information across heads, we use a weighted mean of these score vectors across the head dimension. The weights are produced by a small MLP which maps each contextualized target token embedding
 $h_t \in \mathbb{R}^{d}$
to a probability vector over heads
$h_t \in \mathbb{R}^{d}$
to a probability vector over heads
 $p_t$
:
$p_t$
:
 \begin{equation} \vec {p}_t = \operatorname {softmax} (W_2 \,\mathrm{GELU}(W_1 \vec {h}_t) ) \in \mathbb{R}^{H}, \end{equation}
\begin{equation} \vec {p}_t = \operatorname {softmax} (W_2 \,\mathrm{GELU}(W_1 \vec {h}_t) ) \in \mathbb{R}^{H}, \end{equation}
Finally, the combined logit vector over source positions for each target token is obtained as a weighted mean of the per-head attention scores vectors for that target token, after which it is passed to softmax to obtain a distribution
 $\hat {a}_t$
over source tokens:
$\hat {a}_t$
over source tokens:
 \begin{equation} \hat {\vec {a}}_t = \operatorname {softmax}\bigg(\sum _{h=1}^{H} {p_{t}}_h\, \vec {s}_{t,h}\bigg) \in \mathbb{R}^{S}. \end{equation}
\begin{equation} \hat {\vec {a}}_t = \operatorname {softmax}\bigg(\sum _{h=1}^{H} {p_{t}}_h\, \vec {s}_{t,h}\bigg) \in \mathbb{R}^{S}. \end{equation}
The attribution matrix
 $\hat {A}$
is essentially stacked
$\hat {A}$
is essentially stacked
 $\hat {\vec {a}}_t$
for all
$\hat {\vec {a}}_t$
for all
 $t$
.
$t$
.
The objective function during the training is to minimize the average row-wise Kullback–Leibler divergence between the predicted attribution matrix
 $\hat {A}$
and the gold attribution matrix
$\hat {A}$
and the gold attribution matrix
 $A$
, summed over non-padded target positions:
$A$
, summed over non-padded target positions:
 \begin{equation} \mathcal{L}_{\text{KL}} = \frac {1}{T_{\text{valid}}} \sum _{t \in \mathcal{T}_{\text{valid}}} \mathrm{KL}(A_t \ \vert \vert \ \hat {A}_t), \end{equation}
\begin{equation} \mathcal{L}_{\text{KL}} = \frac {1}{T_{\text{valid}}} \sum _{t \in \mathcal{T}_{\text{valid}}} \mathrm{KL}(A_t \ \vert \vert \ \hat {A}_t), \end{equation}
where
 $A_t$
and
$A_t$
and
 $\hat {A}_t$
denote the gold and predicted distributions over source tokens for target position
$\hat {A}_t$
denote the gold and predicted distributions over source tokens for target position
 $t$
.
$t$
.
6.2 Attributor evaluation
We trained the Attributor on three datasets derived from our earlier experiments, covering all three language pairs. (a) A dataset constructed from Marian-MT attribution maps paired with gold (human) target translations. (b) A dataset constructed from mBART attribution maps paired with gold (human) target translations. (c) A faithfulness-oriented dataset in which Marian-MT attribution maps are paired with targets generated by the Marian-MT teacher model.
As a part of preprocessing, source and target sentences were tokenized according to the respective model’s tokenizers, and attribution maps were normalized in the source dimension to represent a valid probability distribution (to accommodate the KL-divergence loss function). To assess the accuracy of the approximation of their attribution maps by the Attributor, we selected the following metrics:
-
• KL-divergence. Being the minimization target, it is the first choice to quantify the difference between the approximated and the gold attributions
-
• Overlap@3 The overlap between sets of top-3 valued source token indices per target token for the approximated and gold attribution maps. As highlighted by the Nourbakhsh et al. (Reference Nourbakhsh, Lamsiyah and Schommer2025) we hypothesized that most of the useful signal attributions per target token comes from a small number of the highest-scoring source tokens. The overlap@3 is calculated as
(17)
\begin{equation} \text{overlap@3}(t) = \frac {| \text{Top}_3(a_t) \cap \text{Top}_3(\hat a_t) |}{3} \end{equation}
-
• Tau@3 Kendall’s
$\tau$
calculated on top-3 values over the source dimension of the gold attribution and values with the same indices but from the approximated attributions. This metric accompanies overlap@3 by quantifying the rank correlation.


6.3 Attributor results
Obtained values for de-en, fr-en, and ar-en pairs are presented in the three settings mentioned above and can be seen in Figures 6–8.
To quantify the link between approximability and downstream gains, we correlate the BLEU scores obtained by Marian-MT when augmented with each attribution method with our three approximability metrics (mean KL divergence, Overlap@3 and Kendall’s
 $\tau @3$
between gold and predicted target–source maps). We compute BLEU separately for each injection operator (add, average, multiply, replace) and also consider the best BLEU per method across operators.
$\tau @3$
between gold and predicted target–source maps). We compute BLEU separately for each injection operator (add, average, multiply, replace) and also consider the best BLEU per method across operators.
Across all three language pairs (ar-en, de-en, fr-en) and all operators, BLEU shows a very strong positive correlation with the ‘top-3’ alignment metrics. Pearson’s (r) between BLEU and Overlap@3 lies in the range (r
 $\approx$
0.88–0.97), and Kendall’s (
$\approx$
0.88–0.97), and Kendall’s (
 $\tau @3$
) achieves (r
$\tau @3$
) achieves (r
 $\approx$
0.74–0.95). In other words, between roughly 75% and 90% of the variance in BLEU across attribution methods can be explained by how well their target–source patterns can be reconstructed by the Attributor. Rank correlations show identical results: Spearman’s (
$\approx$
0.74–0.95). In other words, between roughly 75% and 90% of the variance in BLEU across attribution methods can be explained by how well their target–source patterns can be reconstructed by the Attributor. Rank correlations show identical results: Spearman’s (
 $\rho$
) between BLEU and Overlap@3/(
$\rho$
) between BLEU and Overlap@3/(
 $\tau @3$
) is consistently high (typically
$\tau @3$
) is consistently high (typically
 $\rho$
$\rho$
 $\approx$
0.65–0.85), and for the fr-en pair with multiplication injection the ranking of methods by BLEU is exactly the same as the ranking by
$\approx$
0.65–0.85), and for the fr-en pair with multiplication injection the ranking of methods by BLEU is exactly the same as the ranking by
 $\tau @3$
(
$\tau @3$
(
 $\rho$
= 1.0).
$\rho$
= 1.0).
In contrast, KL divergence exhibits only weak and unstable association with BLEU. Pearson correlations between BLEU and mean KL are low–moderate and positive (r
 $\approx$
0.27–0.56), while Spearman’s (
$\approx$
0.27–0.56), while Spearman’s (
 $\rho$
) tends to be low negative and even changes sign for some operators (
$\rho$
) tends to be low negative and even changes sign for some operators (
 $\rho$
$\rho$
 $\approx$
−0.26–0.11). This behavior, especially for Pearson, is largely driven by outliers such as ValueZeroing, which combines very high KL divergence with strong BLEU gains. These results suggest that global distribution similarity is a poor predictor of downstream effectiveness, whereas agreement on the locations and ordering of a few top-k source positions is highly predictive.
$\approx$
−0.26–0.11). This behavior, especially for Pearson, is largely driven by outliers such as ValueZeroing, which combines very high KL divergence with strong BLEU gains. These results suggest that global distribution similarity is a poor predictor of downstream effectiveness, whereas agreement on the locations and ordering of a few top-k source positions is highly predictive.
Taken together, these findings support our central claim: attribution methods whose target-source maps are closer to what an encoder-decoder transformer (Attributor) can reproduce are exactly the ones that yield the largest BLEU gains when injected into the student model. We first measured this closeness with full-distribution KL divergence, but the correlation analysis shows that the best predictors of BLEU are Overlap@3 and Kendall’s
 $\tau @3$
between the Attributor’s predictions and the gold attribution maps, which correlate very strongly with BLEU, whereas KL shows only weak and unstable correlations. These results suggest that an attribution method tends to be useful precisely when a transformer can reliably recover the same few most-salient source tokens per target token as the teacher. In contrast, matching the full attention distribution beyond the top positions appears much less informative for predicting BLEU gains.
$\tau @3$
between the Attributor’s predictions and the gold attribution maps, which correlate very strongly with BLEU, whereas KL shows only weak and unstable correlations. These results suggest that an attribution method tends to be useful precisely when a transformer can reliably recover the same few most-salient source tokens per target token as the teacher. In contrast, matching the full attention distribution beyond the top positions appears much less informative for predicting BLEU gains.
For the other two settings of generated targets, the manifested trend is the same. For mBART, the highest correlation is observed with the multiplication operator. It should be noted that the approximation accuracy is the highest for Attention from mBART: the last source token consistently gets the highest attribution scores and their reconstruction is easier. However, there are still residual scores for other tokens whose presence can guide the translation. The regression plot of the above approximation metrics for the three language pairs and the corresponding outcomes is provided in the figures 9–11 (see Appendix).
In short, the student benefits from what it can imitate: attribution methods for which target tokens a transformer can reliably reconstruct the same top-3 source tokens are precisely those that give student models the largest gains.
KL-divergence, Overlap@3, and
 $\tau @3$
for the prediction of attribution on Marian-MT attribution and gold (human) data.
$\tau @3$
for the prediction of attribution on Marian-MT attribution and gold (human) data.

Figure 6 Long description
The image contains six bar graphs arranged in two rows of three. The top row shows mean KL divergence for three language pairs: ar-en, de-en, and fr-en. Each graph compares different XAI methods: Attention, ValueZeroing, LGxA, Saliency, DeepLIFT, IXG, IG, and GSHAP. The y-axis represents mean KL, with lower values being better. The bottom row shows top-k=3 agreement for the same language pairs and XAI methods. The y-axis represents the score from zero to one. Each graph includes two bars: one for Overlap k=3 and one for Kendall τ k=3. The graphs illustrate the performance of various XAI methods in predicting attribution for Marian-MT models compared to human gold data. All values are approximated.
KL-divergence, Overlap@3, and
 $\tau @3$
for the prediction of attribution on mBART attribution and gold (human) data.
$\tau @3$
for the prediction of attribution on mBART attribution and gold (human) data.

Figure 7 Long description
The image contains six bar graphs arranged in two rows of three. The top row shows KL divergence for three language pairs: ar-en, de-en, and fr-en. Each graph compares multiple attribution methods, including Attention, ValueZeroing, LGXA, DeepLIFT, Saliency, IG, IXG, and GSHAP. The y-axis represents mean KL values, with lower values indicating better performance. The bottom row displays top-k agreement for the same language pairs, with two metrics: Overlap k equals 3 and Kendall tau k equals 3. The y-axis represents scores ranging from 0 to 1. Each graph compares the same attribution methods, with blue bars for Overlap and orange bars for Kendall tau. The graphs illustrate the performance of different attribution methods in predicting human annotations for mBART models. All values are approximated.
KL-divergence, Overlap@3, and
 $\tau @3$
for the prediction of attribution on Marian-MT attribution generated target.
$\tau @3$
for the prediction of attribution on Marian-MT attribution generated target.

Figure 8 Long description
The image contains six bar graphs arranged in two rows of three. The top row shows mean KL divergence for language pairs ar-en, de-en, and fr-en. Each graph compares different methods such as Attention, ValueZeroing, LGxA, IG, Saliency, DeepLIFT, ixG, and GSHAP. The y-axis represents mean KL, with lower values being better. The bottom row shows top-k agreement for the same language pairs, with two metrics: Overlap k equals 3 and Kendall tau k equals 3. The y-axis represents the score from 0 to 1. Each graph compares the same methods as the top row. The bars indicate the performance of each method, with error bars showing variability. The graphs illustrate the effectiveness of different attribution methods for various language pairs.
7. Conclusion and future work
In this work, we demonstrate that XAI attribution maps derived from a learned teacher model can be injected into a student model, and that the resulting changes in translation behavior provide a practical signal of the relative quality of the XAI attribution methods. We conducted an extensive evaluation across German–English, French–English, and Arabic–English language pairs, comparing eight XAI methods and multiple composition strategies for integrating attribution scores into Transformer attention (addition, multiplication, averaging, and replacement). We further examined where the scores are applied (encoder self-attention vs. cross-attention) and assessed robustness across two distinct teacher models, mBART and Marian-MT.
Our results indicate that Attention and ValueZeroing, as well as LG
 $\times$
A extracted from the final encoder layer, consistently produced the largest gains in BLEU and chrF. We also observed that injecting source–target attributions into the encoder self-attention can yield significant improvements, which is initially counterintuitive given that the encoder is designed to attend only within the source sequence. A plausible explanation is that the non-auto-regressive encoder attention setup makes future information accessible to the entire sequence.
$\times$
A extracted from the final encoder layer, consistently produced the largest gains in BLEU and chrF. We also observed that injecting source–target attributions into the encoder self-attention can yield significant improvements, which is initially counterintuitive given that the encoder is designed to attend only within the source sequence. A plausible explanation is that the non-auto-regressive encoder attention setup makes future information accessible to the entire sequence.
We also showed that getting better results from the different attribution methods is not accidental: (1) Attribution maps with lower entropy tend to score higher. (2) We set up a transformer model, Attributor, which shows that the most beneficial attribution maps are the ones for whose target tokens the transformer model successfully recreates top-3 salient source tokens. These findings offer the NLP community a plausible explanation for the utility of attribution maps and highlight the importance of the attribution’s most salient tokens.
There are some limitations to this work worth noting. First, this study provides an extensive exploration of attribution transfer between models. However, the overall pipeline is computationally expensive, both in deriving attributions at scale and in retraining student models. For this reason, we focused our comparison on attribution signals produced by a range of explainability methods, most of which are gradient-based. This choice was driven largely by practicality. Extracting attributions with perturbation-based approaches such as LIME (Ribeiro et al. Reference Ribeiro, Singh and Guestrin2016) and reAGent (Zhao, Wang, and Wang Reference Zhao, Wang and Wang2023) is substantially more resource-intensive and time-consuming. In addition, some methods available in Inseq produce (self-)attributions on the decoder side of seq2seq models. In this work, we restrict our experiments to encoder self-attention and encoder–decoder cross-attention, leaving decoder-side attribution transfer for future study.
More ablation studies are needed. In this work, we tried with cross-attention, 4 attention heads, and different operators. However, the effects of layer-wise injection, broader choices of head selection and head count, and alternative placement strategies remain underexplored. We also used a coarse attribution extraction procedure. We took attention-based attributions from all the layers and averaged attention scores, and for the gradient methods, our only alteration was the last encoder layer. More systematic investigation of layer-wise signals and aggregation strategies is needed. Moreover, it is important to note that, for the Attributor experiments, we used the top-3 tokens for overlap@3 and Kendall’s
 $\tau$
; it may also be beneficial to extend the experiments to other top-k tokens to draw a line for the most salient tokens more precisely. Also, in this work, our focus was limited to machine translation tasks. Machine translation tasks are characterized by the alignments between source and target pairs. Future work could extend this evaluation framework to other generative models, including those applied in question answering and text summarization.
$\tau$
; it may also be beneficial to extend the experiments to other top-k tokens to draw a line for the most salient tokens more precisely. Also, in this work, our focus was limited to machine translation tasks. Machine translation tasks are characterized by the alignments between source and target pairs. Future work could extend this evaluation framework to other generative models, including those applied in question answering and text summarization.
Funding statement
This work is supported by the Luxembourg National Research Fund (FNR) as part of the project C21 - Collaboration 21: IPBG2020/IS/14839977/C21.
Competing interests
The authors declare that the manuscript complies with the ethical standards of the journal and that there are no competing interests to disclose.
Acknowledgements
We thank Richard Albrecht for early assistance and helpful discussions during project initiation.
Artificial intelligence usage
We used Large Language Models, such as ChatGPT and Copilot, for code autocompletion, proofreading, and spellchecking of the manuscript.
Appendix
Regression plots of the Marian-MT attributions with gold (human) target sentence.

Figure 9 Long description
The image contains nine regression plots arranged in a three-by-three grid. Each plot compares different metrics for Marian-MT attributions with gold target sentences across three language pairs: de-en, fr-en, and ar-en. The first row of plots shows BLEU scores versus Mean KL, the second row shows BLEU scores versus Mean Kendall, and the third row shows BLEU scores versus Mean Overlap. Each plot includes a trend line with shaded confidence intervals and data points labeled with specific values. The x-axes represent different metrics (Mean KL, Mean Kendall, and Mean Overlap), while the y-axes represent BLEU scores. The plots illustrate the relationships between these metrics and the BLEU scores for the different language pairs.
Regression plots of the mBART attributions with gold (human) target sentence.

Figure 10 Long description
The image contains nine scatter plots arranged in a 3x3 grid, each representing regression plots of the mBART attributions with gold human target sentence for different language pairs and metrics. The plots compare various metrics such as Mean KL, Mean Kendall, and Mean Overlap for language pairs de-en, fr-en, and ar-en. Each plot has the mBART BLEU score on the y-axis and the respective metric on the x-axis. The plots show data points with a trend line and shaded confidence intervals. The caption provides context about injecting external linguistic knowledge into attention mechanisms in natural language processing tasks. All values are approximated.
Regression plot of the Marian-MT attributions with generated target sentences.

Figure 11 Long description
The image contains three sets of regression plots, each with three individual graphs. The first set of graphs shows the relationship between BLEU best scores and Mean KL for de-en, fr-en, and ar-en language pairs. The second set illustrates the relationship between BLEU best scores and Mean Kendall τ@3 for the same language pairs. The third set displays the relationship between BLEU best scores and Mean Overlap@3 for de-en, fr-en, and ar-en. Each graph includes data points and trend lines, with shaded areas indicating confidence intervals. The x-axes represent different metrics (Mean KL, Mean Kendall τ@3, and Mean Overlap@3), while the y-axes represent BLEU best scores. The graphs show how these metrics correlate with the quality of generated target sentences in different language pairs.
Sample translations and metrics for Marian-MT and mBART under different attribution/XAI variants for a sample de-en.

Table 17 Long description
The table presents a comparison of translation quality metrics for Marian-MT and mBART models across various attribution methods. It includes columns for the model type, reference text, baseline, and different attribution methods such as I x G, Saliency, LG x A, IG, GSHAP, DeepLIFT, Attention, and ValueZeroing. Each row provides the translated text and corresponding BLEU and chrF scores for each method. The table highlights that Attention and ValueZeroing methods yield the highest improvements in translation quality, followed by gradient-based methods, with GSHAP being the least effective. The data shows that the element-wise product operator yields the largest changes, while simple averaging is the weakest operator. Specific nuances are noted for different language pairs, such as IG ranking lower for ar-en and Saliency not improving results for fr-en. The table also includes a section for generated translations by Marian-MT, showing consistent improvements with certain methods.


 (x,y)
(x,y) E
E (x,y,E)
(x,y,E) (x,E)→y^
(x,E)→y^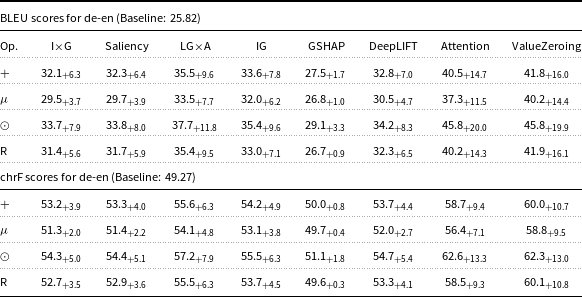
 Δ
Δ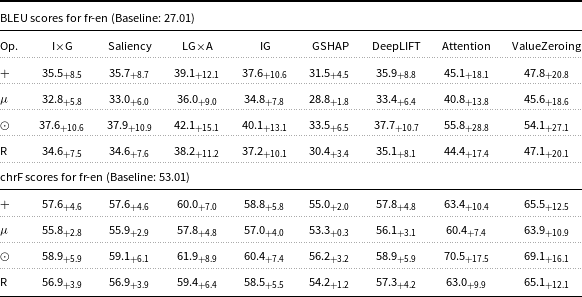
 Δ
Δ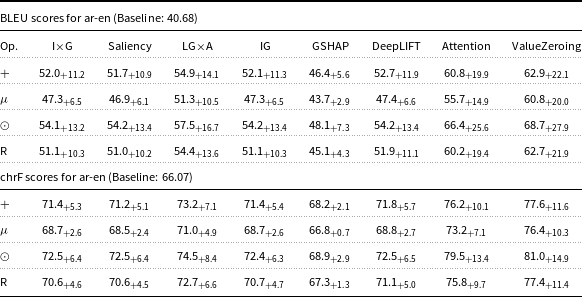
 Δ
Δ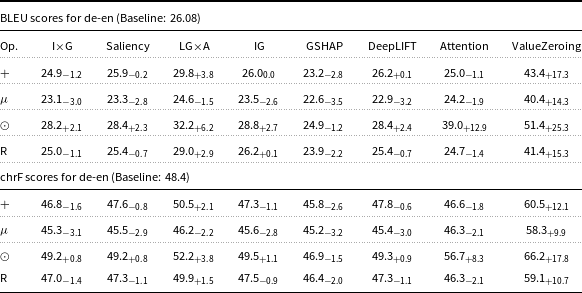
 Δ
Δ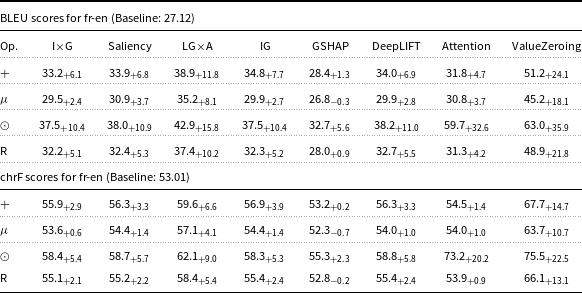
 Δ
Δ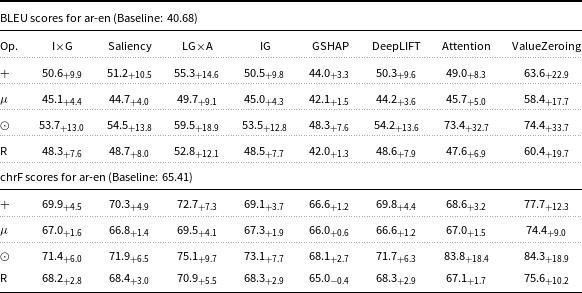
 Δ
Δ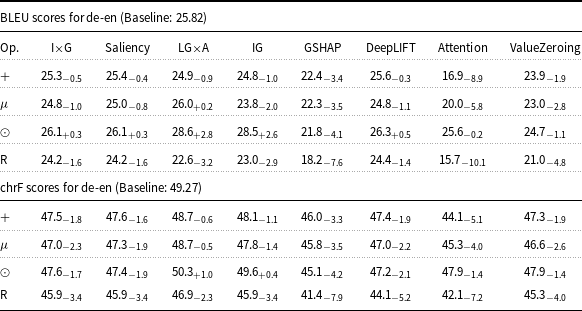
 Δ
Δ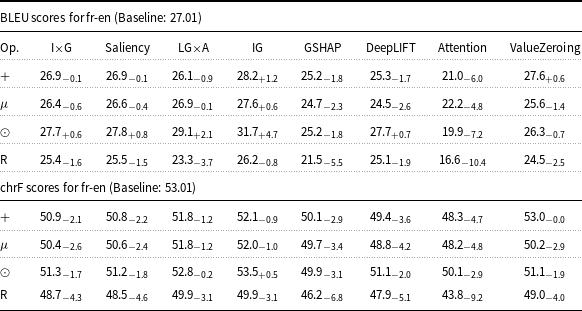
 Δ
Δ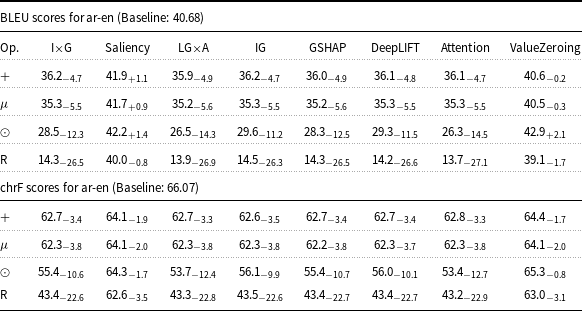
 Δ
Δ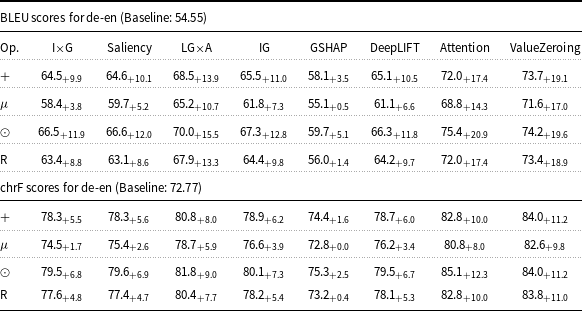
 Δ
Δ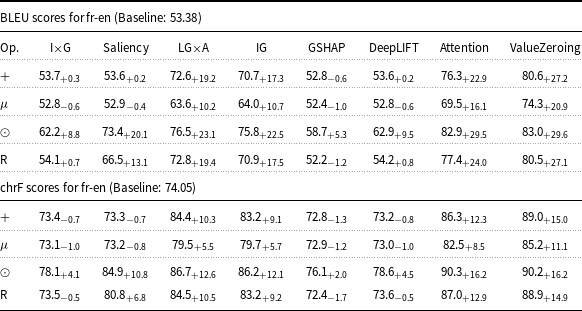
 Δ
Δ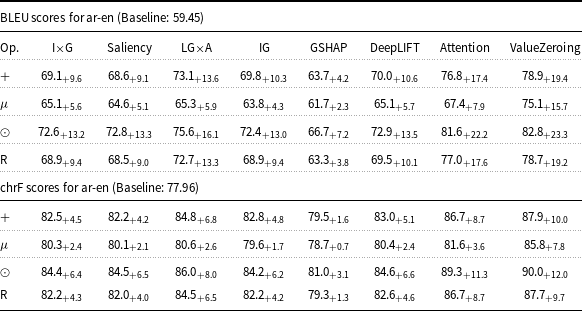
 Δ
Δ
 Δ
Δ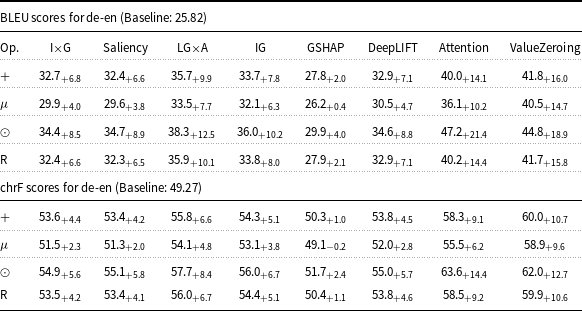
 Δ
Δ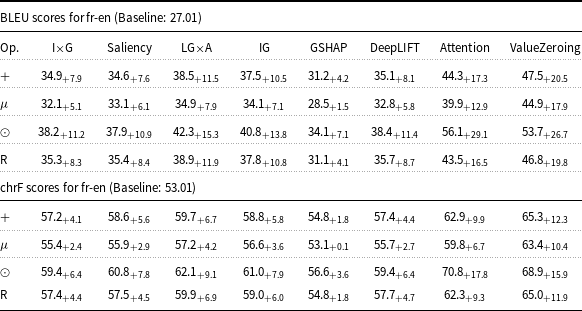
 Δ
Δ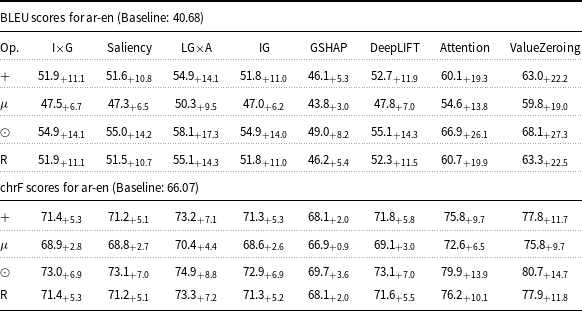
 Δ
Δ



 τ@3
τ@3
 τ@3
τ@3
 τ@3
τ@3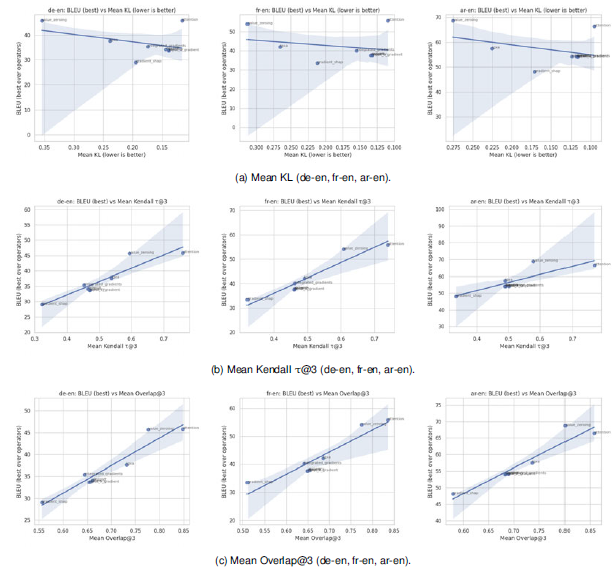


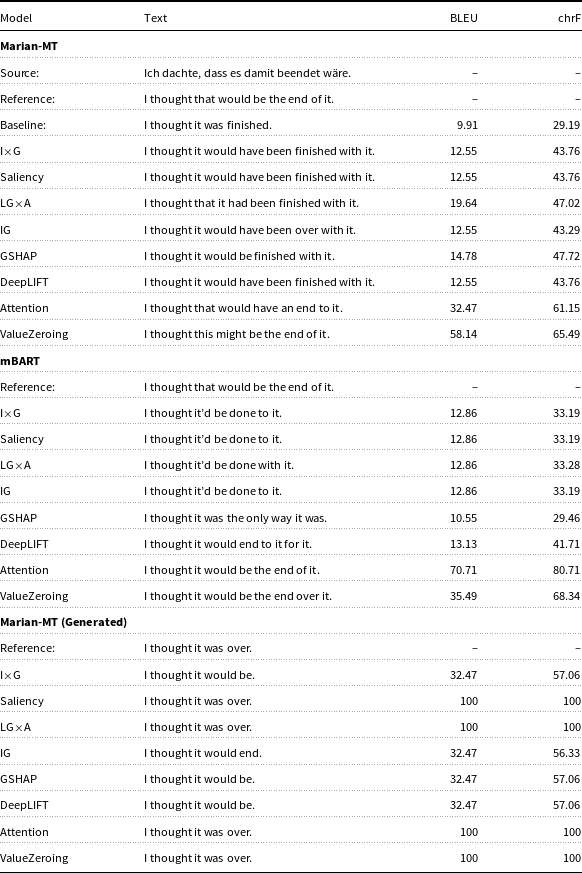

 Open access
Open access