



Policy Significance Statement
Machine-learning algorithms coupled with genetic algorithm-based feature selection offer a powerful approach for detecting fake accounts in Online Social Networks platforms. This research demonstrates that by leveraging advanced machine-learning techniques and employing genetic algorithms for feature selection, it is possible to achieve highly accurate and efficient identification of fake accounts. Furthermore, the integration of genetic algorithm-based feature selection optimizes the performance of the detection system by identifying the most informative features. This improves the efficiency and effectiveness of fake account detection and reduces computational complexity.
1. Introduction
As technology has advanced, Facebook, LinkedIn, Twitter, Instagram, and other social media networks have been overgrown during the previous century. In addition, smartphones, tablets, computers, and other contemporary technologies make wireless communication more effective and convenient.
In January 2023, Northern and Southern African nations claimed the highest proportion of social media users on the continent. According to Statista (Galal Reference Galal2023), statistics report in Northern Africa, approximately 49% of the population engaged with social media, whereas in Southern Africa, this metric reached 41.3%. Conversely, Central Africa exhibited the lowest social media usage rate in Africa, with only around 7% of its population participating, representing both the lowest figure across the continent and the smallest regional presence globally.
A fake profile is a cloned or malicious account. When a user impersonates another user’s account, we refer to it as a “duplicate.” Hiding a malicious account’s true identity for malicious activity has developed considerably in recent years. Making use of fraudulent accounts damages one’s reputation, causing unneeded perplexity through unexpected received messages (Sheikhi, Reference Sheikhi2020).
First, it should be highlighted that Facebook has developed an immune system called (Carmi, Reference Carmi2020) to combat issues caused by fake accounts by building classifiers. Every read and written operation is subject to real-time inspections and classifications by this immune system. In situations involving Advanced Persistent Threats, fake identities on social media are frequently used to transmit malwares or suspicious links. Furthermore, they are employed in various nefarious activities like sending spams and spam emails, and in certain applications, to promote and inflate the number of users (Joshi et al., Reference Joshi, Nagariya, Dhanotiya and Jain2020).
In this research, we have attempted to detect active fake accounts on Facebook and Instagram. Furthermore, we have applied feature selection to decrease the number of variables and reduce computation time.
Typically, machine-learning classifiers employed for the prediction of fake accounts can be classified into the following categories (Singhal et al., Reference Singhal, Jain, Batra, Varshney and Rathi2018):
-
1. Bagging, which frequently considers homogenous weak learners, who learn from one another both in parallel and separately, and then aggregates them using some deterministic averaging procedure.
-
2. Boosting, which often includes homogenous weak learners, learns them sequentially in a highly adaptative manner (each base model is dependent on the preceding ones) and combines them using a deterministic technique.
The aforementioned machine-learning models are based on input data that includes attributes characterizing the objects under investigation. In the machine-learning language, a feature is a variable, parameter or property. Therefore, feature selection significantly impacts model performance in data-driven models.
In recent years, datasets have commonly included numerous attributes, encompassing both pertinent and superfluous information. However, the existence of redundant and unimportant attributes not only expands the feature space but also hinders the effectiveness of machine-learning techniques (Cai et al., Reference Cai, Luo, Wang and Yang2018; Venkatesh and Anuradha, Reference Venkatesh and Anuradha2019). Consequently, feature selection emerges as an effective approach to reduce dimensionality issues. This method, performed as a pre-processing step, enhances data interpretability by carefully selecting a subset of significant attributes. The primary purpose of feature selection is to discover the optimal combination of relevant features that may significantly improve classification performance while reducing classification model complexity.
For statistical pattern recognition, data mining, and machine learning, feature selection has been a promising field of study and development since the 1970s. As a result, many attempts have been made to assess the feature selection techniques, which can be divided into four groups based on the evaluation process, namely, filters, wrappers, hybrids, and embedded (Rostami et al., Reference Rostami, Berahmand and Forouzandeh2021). A filter technique conducts feature selection independently of any learning algorithm (for example, a totally separate preprocessing). The feature set filter strategy requires statistical analysis, which can only be used to handle the feature selection problem without using a learning model. On the other hand, the wrapper technique uses a predefined learning process to determine the quality of the chosen subsets. Furthermore, Wrappers may produce superior results but are more expensive to run and can disintegrate with too many features. The hybrid strategy uses a combination of both filter and wrapper techniques. Finally, the embedded approaches benefit from selecting features in the learning process and are equivalent to a specific learning model (Liu et al., Reference Liu, Liang, Wang, Yang and Ye2018; Moslehi and Haeri, Reference Moslehi and Haeri2020).
The BORUTA algorithm (Kursa and Rudnicki, Reference Kursa and Rudnicki2020) was used to select the specified characteristics. Given that reducing the number of input variables is an essential aspect of building a predictive model, it was also determined that Boruta should explore whether, during the construction of a predictive model, it is necessary to select all the features identified as relevant by the BORUTA algorithm, or if it is possible to reduce the number of features and assess how such reduction impacts the accuracy of fake account prediction. Evaluation criteria such as AUC, Accuracy, Precision, and MCC were used to evaluate the quality of the built prediction model (Rácz et al., Reference Rácz, Bajusz and Héberger2019).
Another helpful approach is the genetic algorithm (GA), which provides optimized output through distinct feature analyses for the input data. J.H. Holland suggested GA in 1992. Chromosome representation, fitness, selection, and biological-inspired operators are the fundamental parts of GA (Katoch et al., Reference Katoch, Chauhan and Kumar2021). This strategy is more efficient and effective in terms of efficiency and performance. The genetic algorithm (GA) has been extensively employed in feature selection problems as a basic optimization method. However, one of the weaknesses of GA is hyperparameter tuning, high computing cost, and randomness of the selection procedure (Allam and Nandhini, Reference Allam and Nandhini2018).
The remainder of this paper is organized as follows: In Section 2, we discuss previous works in the area of detecting fake accounts in online social networks and feature selection methods. Section 3 discusses our fake detection method and provides experimental findings. The study concludes with a summary of the findings and some conclusions in Section 4.
2. Related Work
In recent years, feature selection has emerged as a critical research component in machine learning; the focus areas encompass image retrieval, text mining, intrusion detection, and other fields. As a result, various methods for feature selection have been developed and used in the literature (Deng et al., Reference Deng, Li, Weng and Zhang2019; Adewole et al., Reference Adewole, Balogun, Raheem, Jimoh, Jimoh, Mabayoje, Usman-Hamza, Akintola and Asaju-Gbolagade2021; Anand et al., Reference Anand, Sehgal, Anand and Kaushik2021). For example, such as particle swarm optimization (PSO) (Shami et al., Reference Shami, El-Saleh, Alswaitti, Al-Tashi, Summakieh and Mirjalili2022), ant colony optimization (ACO) (Ma et al., Reference Ma, Zhou, Zhu, Li and Jiao2021), and GA (Ghatasheh et al., Reference Ghatasheh, Altaharwa and Aldebei2022). GA has long been recognized as a very effective and practical method for feature selection, as described in Fraser et al. (Reference Fraser and Burnell1970), Deepa (Reference Deepa2008). This is due to its capacity to change the functional configuration for better performance outcomes. Online social networks have attracted various types of undesirable activities, and the academic community has already provided a variety of remedies to the issue, which are focused on profile-based (Kaubiyal and Jain, Reference Kaubiyal and Jain2019), emotion-based (Wani et al., Reference Wani, Agarwal, Jabin and Hussain2019), graph-based (Mohammadrezaei et al., Reference Mohammadrezaei, Shiri and Rahmani2018; Wang et al., Reference Wang, Lai, Lin, Hsieh, Wu and Cam2019) and behavioral-based (Bhattasali and Saeed, Reference Bhattasali and Saeed2021) features, including:
-
1. Profile-based: account age, gender, relationship status, education details, country, followers Count and friends Count.
-
2. Graph-based: betweenness centrality, in/out-degree, Friendship evolution, OSN graph structure evolution, clustering coefficient, connection strength, etc.
-
3. Content-based: URLs in the post, message, similarity, message length, hashtags, number of tags, punctuation count, number of capital letter words, sentence length, and so forth.
-
4. Behavioral-based: Posts sent in a particular time interval, time in days.
Gupta and Kaushal (Reference Gupta and Kaushal2017) attempted to identify fraudulent accounts on Facebook based on user profile activity and interactions with other users. These actions were defined by an extensive feature set that included Facebook users’like, comment, share, tag, and app use patterns. They then used their dataset to apply the most widely used supervised machine-learning classification algorithms.
The suggested strategy was based on establishing the effective features for the identification procedure in Munga and Mohandas (Reference Munga, Mohandas, Usman, Liew, Ahmad and Ibrahim2022). Then, the obtained features were filtered using entropy and information gain. As a result, the suggested technique contains just eight effective features for fraudulent account identification out of 25 attributes, with five decided features based on information gain.
Sahoo and Gupta (Reference Sahoo and Gupta2020) presented a hybrid solution that uses several machine-learning algorithms to distinguish between spammer and non-spammer contents and accounts. Initially, the genetic algorithm analyzes the numerous variables and picks the most relevant features that impact the behavior of user accounts, which are then used for training classifiers. As a result, their system was successful in effectively differentiating spammer and non-spammer content. Finally, a comparison with certain current state-of-the-art methodologies is performed to demonstrate the effectiveness of the suggested framework. According to the experimental results, their strategy produces a high detection rate of 99.6%, which is superior to other state-of-the-art approaches.
Akyon and Esat Kalfaoglu (Reference Akyon and Esat Kalfaoglu2019) gathered datasets to identify fake and automated accounts, introducing derived characteristics for classifying fake and automated accounts. Additionally, they implemented a cost-sensitive feature reduction approach using genetic algorithms to optimize the selection of features for automated account classification. Furthermore, they used the SMOTE-NC algorithm to rectify the unevenness in the fake account dataset and evaluate multiple pattern recognition algorithms on the obtained datasets. As a result, SVM obtained an F1 score of 86% for automated account identification, and the neural network achieved an F1 score of 95%.
3. Proposed Methodology
Our study explores the application of genetic algorithms for feature selection in the context of fake account detection. Our objective is to identify the most relevant features to be considered in the detection process. The workflow for this research is shown in Figure 1. The experiment comprises several steps. Firstly, we initiated our work by collecting and processing the dataset. Secondly, we employed the GA and Boruta methods for selecting key features. Next, we compared seven classifier methods using the selected features to determine the optimal classification approach for predicting unknown user accounts.
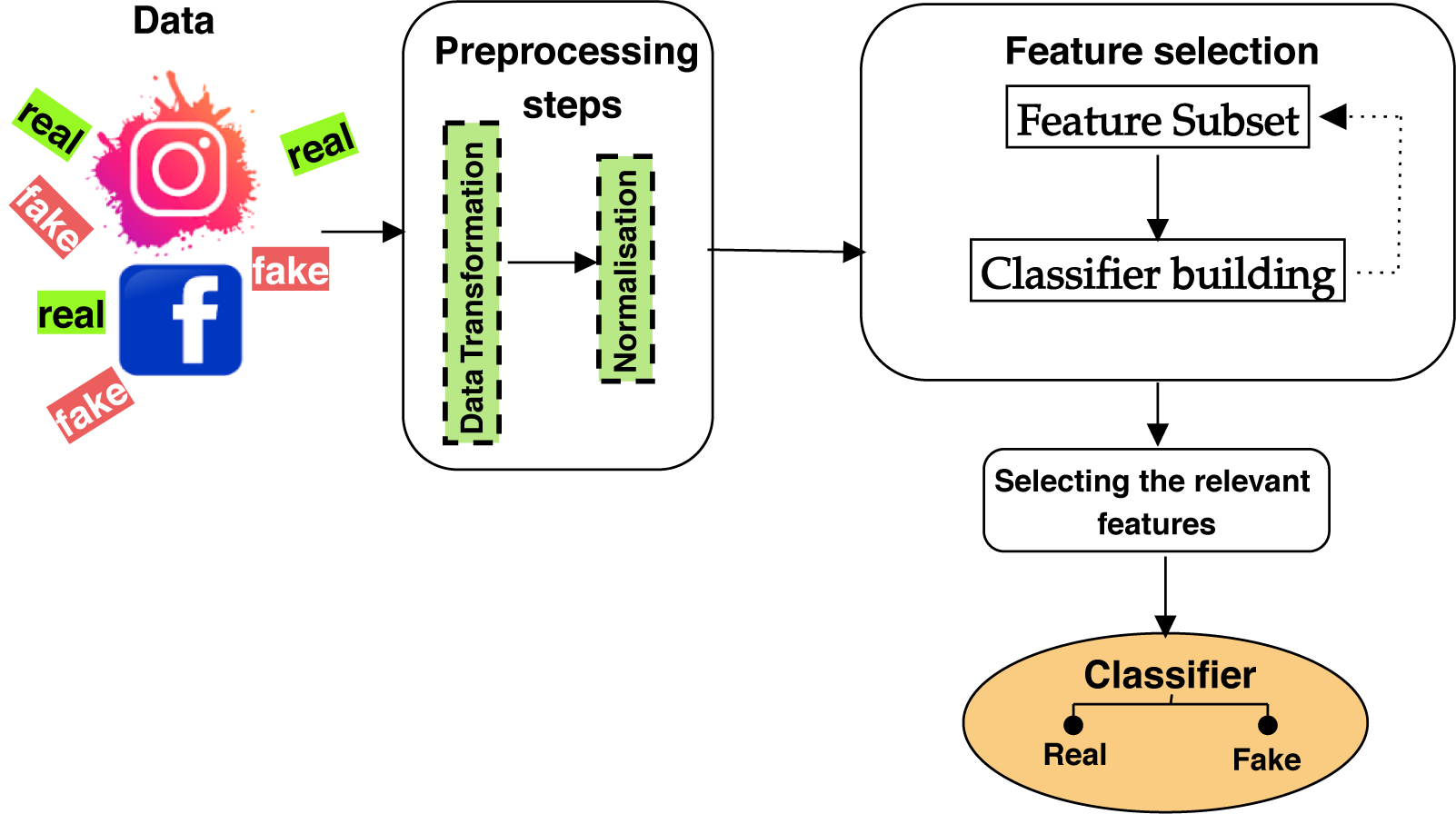
Figure 1. Proposed system detection.
3.1. Dataset and features
Many datasets are openly accessible on the Internet, and we can adopt them for Instagram and Facebook fake account classification. Figure 2 shows how each set is balanced for the target class.
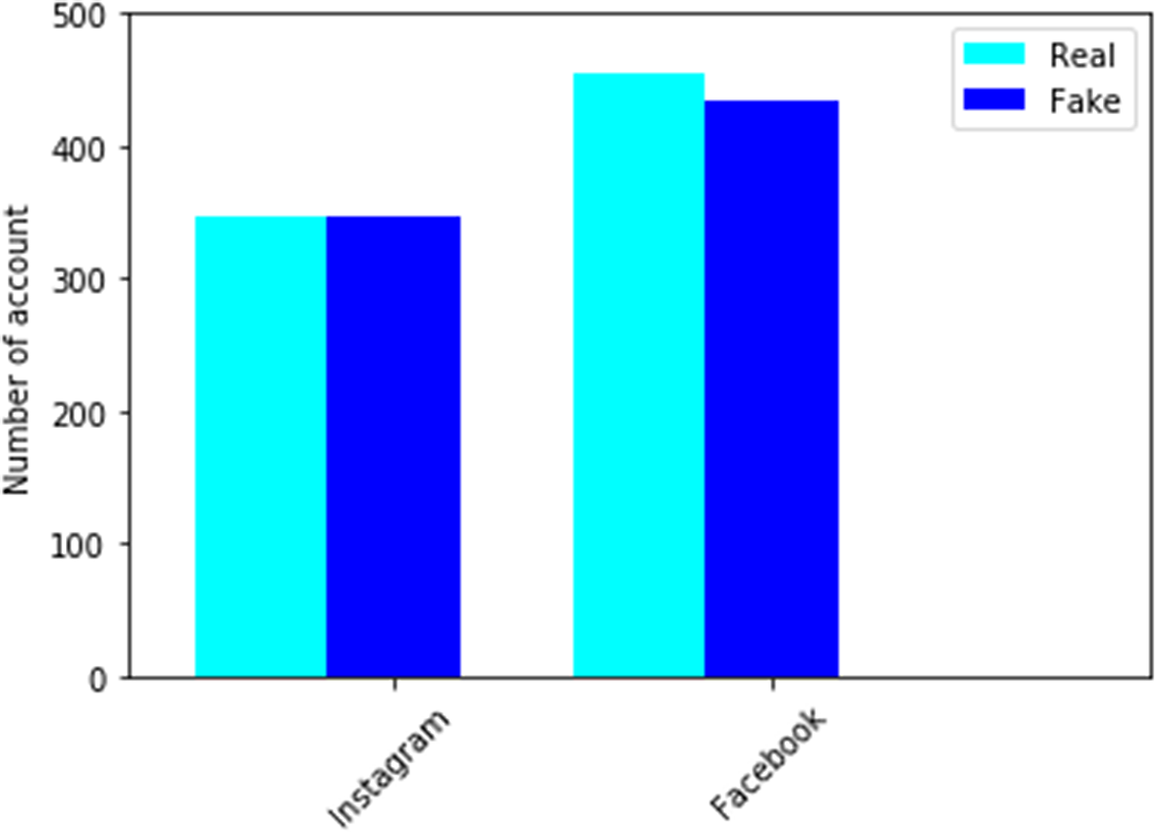
Figure 2. Count plot of the number of instances of the partitions of the Facebook and Instagram dataset for each class.
3.1.1. Instagram
A CSV file with 699 rows and 12 columns, including the target variable, was downloaded as the dataset. The source of this Dataset is Bakhshandeh (Reference Bakhshandeh2019). The target variable accepts the values genuine and fake, allowing us to determine if the account is fraudulent. A collection of 11 characteristics were given as stated, according to Table 1.
Table 1. Features that characterize each user profile on Instagram

Before constructing any machine-learning model for a tabular dataset, assessing the association between the independent and target variables is common practice. This assessment typically involves quantifying the correlation between the two variables. For this purpose, we exploit a Pearson correlation, a number between −1 and 1 that indicates the extent to which two variables are linearly related. The heat map data in Figure 3 reveal no high association between the variables.
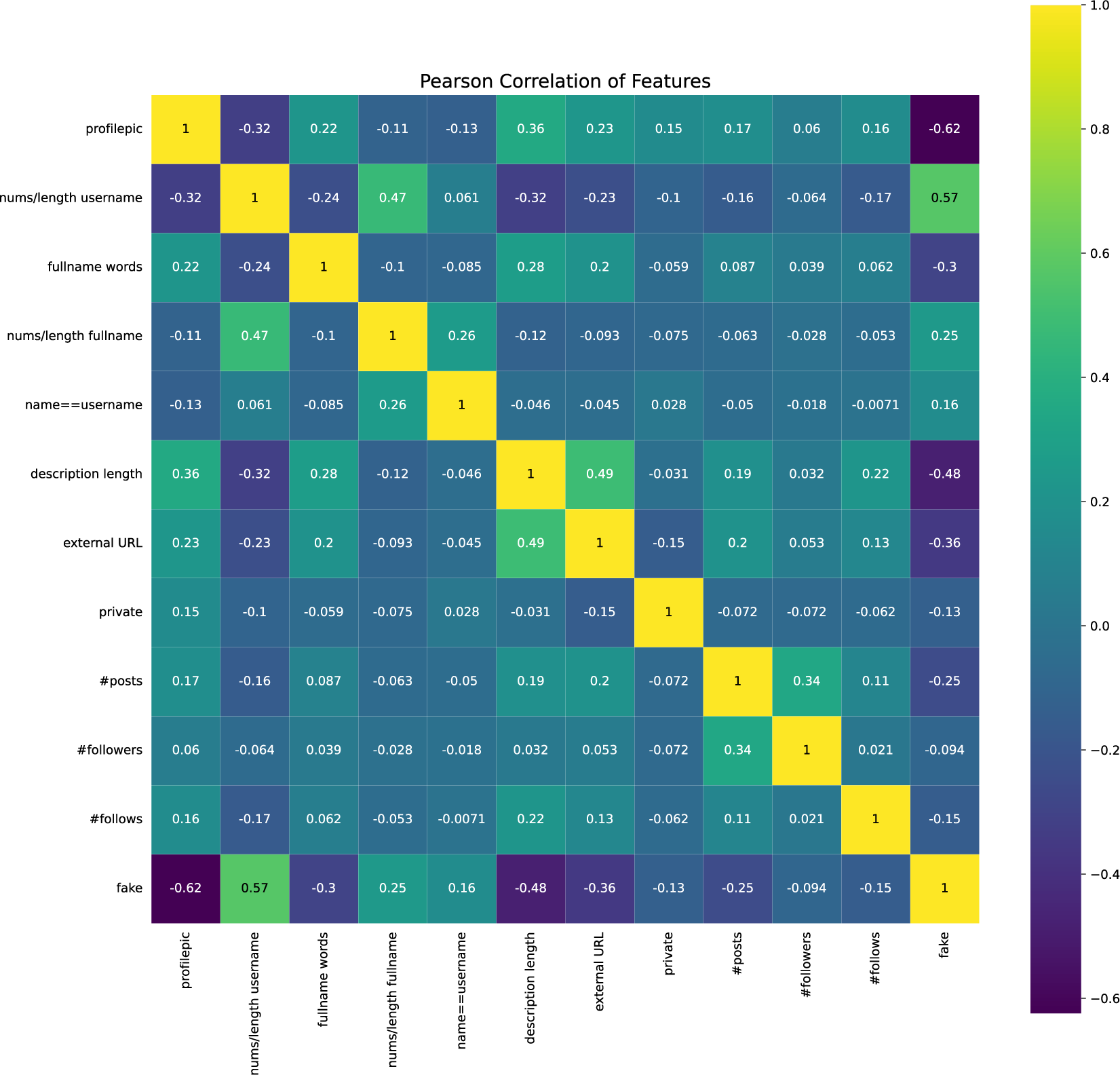
Figure 3. Heat map data and the correlation between different variables in Instagram.
3.1.2. Facebook
The second dataset comprises profiles of two statutes: real and fake. We used the dataset “Fake and Real Accounts Fakebook” (Albayati and Altamimi, Reference Albayati and Altamimi2019) for our research. The collection includes data from 889 public Facebook accounts. It consists of 22 predictor variables and one outcome variable (Status), indicating whether the account is legitimate or fake. In Figure 4, we provide a quick overview of all the predictor variables.

Figure 4. Screenshot of Facebook dataset.
We initially analyzed the Facebook dataset for multicollinearity concerns among our predictor variables. This is interpreted as follows: a correlation value of 0.7 between two variables indicates that the two have a significant and positive association (Nettleton, Reference Nettleton2014). Consider Figure 5, which depicts the correlation between 23 variables.

Figure 5. Heat map data and the correlation between different variables in Facebook.
3.2. Feature selection
It is rare for all the dataset’s variables to be employed in the development of a machine-learning model. Unnecessary variables impact a model’s capacity to generalize and might lower a classifier’s overall accuracy. Additionally, increasing the number of variables in a model makes it more complicated overall (Gazeloglu, Reference Gazeloglu2020).
3.2.1. Genetic algorithm
GA (Jennings et al., Reference Jennings, Lysgaard, Hummelshøj, Vegge and Bligaard2019) is an evolutionary computation technique that consists of methods for solving multi-objective optimization problems, GA is used to find the optimal combination of feature subsets and parameters.
The terms population and generation refer to groups of people, generation is an iteration of the optimization (evolutionary) process, and multi-objective fitness function
 $ m\in \mathrm{\mathbb{N}} $
refers to a collection of real functions
$ m\in \mathrm{\mathbb{N}} $
refers to a collection of real functions
 $ {g}_i:S $
for
$ {g}_i:S $
for
 $ i\in \left\{1,\dots, m\right\} $
, where each function
$ i\in \left\{1,\dots, m\right\} $
, where each function
 $ {g}_i: $
assesses a different quality of a given individual. A person belongs to the set
$ {g}_i: $
assesses a different quality of a given individual. A person belongs to the set
 $ S $
of all prospective individuals who may be formed for a certain problem. A standard generation of an evolutionary process based on GA consists of the phases listed below:
$ S $
of all prospective individuals who may be formed for a certain problem. A standard generation of an evolutionary process based on GA consists of the phases listed below:
-
1. Fitness evaluation: The fitness function processes the execution using specific classification algorithms by choosing various features. Here, we examine and validate each feature related to the Facebook and Instagram accounts using a classifier. Then, the classifier’s performance and other features in various chromo are used to estimate the fitness value;
-
2. Selection: based on the fitness value threshold cut-off, multiple fitness chromosomes are chosen. Chromosomes with greater probability are selected for the following stage of procedures;
-
3. Crossover: it includes fusing and combining the data structures of two parents to create children;
-
4. Mutation: Each bit in a chromosome with binary values typically has a predetermined probability of flipping.
The standard procedure of a GA is shown in Figure 6.
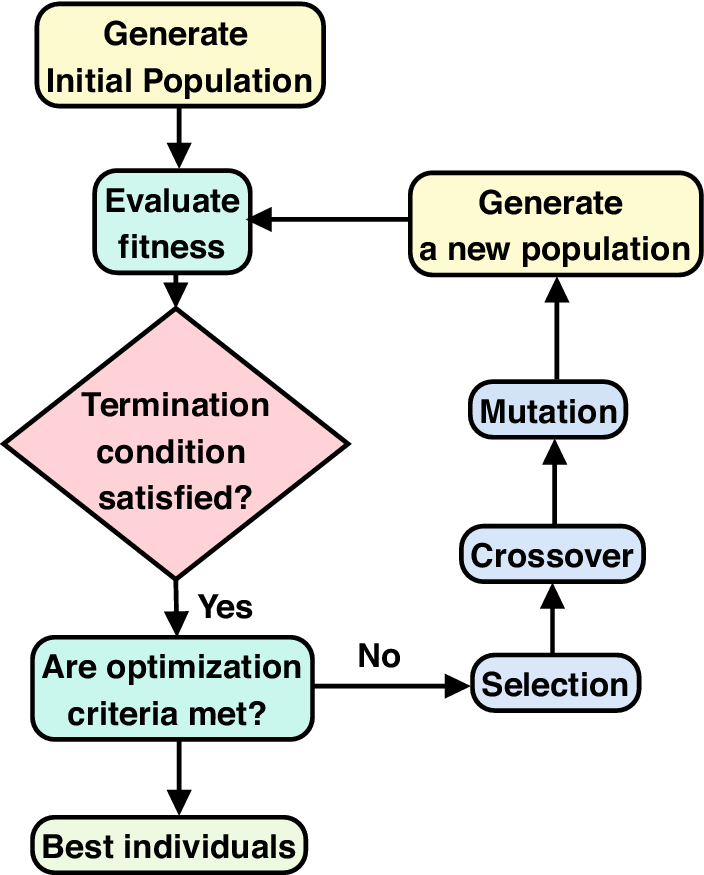
Figure 6. Standard procedure of genetic algorithm.
3.2.2. Boruta
Boruta is a method for selecting and prioritizing features that relies on the Random Forest algorithm. The advantages of Boruta include determining the relevance of the variable and statistically selecting important variables.
3.2.2.1. How does Boruta algorithm work?
To begin, Boruta algorithm initiates the process by augmenting the provided dataset with randomly generated duplicates of all the features, referred to as Shadow Features.
Subsequently, using this expanded dataset (comprising both original attributes and shadow attributes), Boruta algorithm trains a random forest classifier and evaluates the significance of each feature by employing a feature importance metric like Mean Decrease Accuracy.
Boruta Algorithm scrutinizes the relative importance of each actual feature at each iteration, systematically discarding features that are deemed nonessential, all while retaining the best-performing shadow features.
Finally, Boruta Algorithm concludes when all features have been validated or rejected or when it nears a predetermined threshold associated with the random forest.
In contrast, Boruta identifies all features that exhibit varying degrees of correlation with the target variable, whether strong or weak.
3.3. Performance metrics
The effectiveness of each approach is evaluated across multiple performance metrics, including precision, recall, F1-score, accuracy, and the Area Under the Receiver Operating Characteristic Curve (AUC/ROC). In this section, we provide concise but comprehensive explanations of each performance metric that we have used in our research.
-
1. Accuracy measures the proportion of correctly classified instances among all instances in a classification proble:
 $$ \mathrm{Accuracy}=\frac{True\ Positive+ True\ Negative}{True\ Positive+ True\ Negative+ False\ Negative+ False\ Positive} $$
$$ \mathrm{Accuracy}=\frac{True\ Positive+ True\ Negative}{True\ Positive+ True\ Negative+ False\ Negative+ False\ Positive} $$
-
2. Precision assesses the ability of a classifier to correctly identify positive instances. It is the ratio of true positive predictions to the total positive predictions.
 $$ \mathrm{Precision}=\frac{True\ Positive}{True\ Positive+ FalseP\ ositive} $$
$$ \mathrm{Precision}=\frac{True\ Positive}{True\ Positive+ FalseP\ ositive} $$
-
3. Recall measures the ability of a classifier to identify all relevant instances. It is the ratio of true positive predictions to the total actual positive instances.
 $$ \mathrm{Recall}=\frac{True\ Positive}{True\ Positive+ False\ Negative} $$
$$ \mathrm{Recall}=\frac{True\ Positive}{True\ Positive+ False\ Negative} $$
-
4. F1-Score evaluates the trade-off between recall and precision and can be computed as follows:
 $$ F1- Score=2\times \frac{\left(\mathrm{precision}\times \mathrm{recall}\right)}{\left(\mathrm{precision}+\mathrm{recall}\right)} $$
$$ F1- Score=2\times \frac{\left(\mathrm{precision}\times \mathrm{recall}\right)}{\left(\mathrm{precision}+\mathrm{recall}\right)} $$
-
5. AUC (area under the ROC curve):
Machine-learning classification techniques that yield a score within the range
 $ \left[0,1\right] $
, as opposed to a binary class assignment {0, 1}, can benefit from optimization through the selection of a threshold value that may differ from
$ 0.5 $
. This threshold is employed to convert the continuous score into a categorical prediction. Each potential threshold value is associated with both a true positive rate (TPR) and a false positive rate
$ (FPR) $
. Assessing the inherent quality of the score can be accomplished by means of an ROC (Receiver Operating Characteristic) curve. This curve illustrates, for each envisageable threshold, the
$ TPR $
in relation to the
$ FPR $
.
$ \left[0,1\right] $
, as opposed to a binary class assignment {0, 1}, can benefit from optimization through the selection of a threshold value that may differ from
$ 0.5 $
. This threshold is employed to convert the continuous score into a categorical prediction. Each potential threshold value is associated with both a true positive rate (TPR) and a false positive rate
$ (FPR) $
. Assessing the inherent quality of the score can be accomplished by means of an ROC (Receiver Operating Characteristic) curve. This curve illustrates, for each envisageable threshold, the
$ TPR $
in relation to the
$ FPR $
.





The true positive rate (TPR), which is equivalent to the recall, is defined as follows:
 $$ TPR=\mathrm{Sensitivity}=\frac{TP}{TP+ FN} $$
$$ TPR=\mathrm{Sensitivity}=\frac{TP}{TP+ FN} $$
False positive rate (FPR) is defined as follows:
 $$ FPR=1-\mathrm{Specificity}=\frac{FP}{FP+ TN} $$
$$ FPR=1-\mathrm{Specificity}=\frac{FP}{FP+ TN} $$
To establish the coordinates along the Receiver Operating Characteristic (ROC) curve, it is conceivable to conduct multiple model evaluations while altering classification thresholds; however, this approach would be deemed inefficient. A commonly employed metric for assessing performance is the Area Under the ROC Curve (AUC), which assumes values within the range of 0 to 1. A higher AUC value approximating 1 signifies the model’s exceptional predictive capability.
3.4. Models construction
We used seven classification algorithms to train our models: Gradient Boosting, Extreme Gradient Boosting, catBoost, Random Forest, LightGBM, AdaBoost, and ExtraTree Classifier. First, we train our model with all of its features. Then, we use the two-feature selection approach and choose important features and train our model with the chosen features. Finally, various measures are used to examine the suggested model, including accuracy, recall, precision, F1-score, and others.
We performed a 10-fold cross-validation to evaluate our models. We began by dividing the total number of observations into 10 random subsets. Next, we trained a model using nine subsets for each iteration, then tested the fitted model on the remaining subset. We then averaged the cross-validated performance measures over the 10 iterations.
4. Results
This part presents the methodology used to evaluate the effectiveness of detecting fake Instagram and Facebook profiles. Initially, we predicted fake accounts with seven classifiers and no selection. Then, we use two feature selection methods, and after picking essential features, we reapply to the classifier described before. Here, we want to demonstrate how the feature selection approach influences the prediction outcome.
4.1. Experimental setup
In this study, the development of a machine-learning classifier and the incorporation of feature selection methods based on Genetic and Boruta algorithms were accomplished through the utilization of Python scripts.
The National Center for Scientific and Technical Research (CNRST), Rabat, Morocco, supplied computing resources for this study via HPC-MARWAN (hpc.marwan.ma). The National Center for Scientific and Technical Research provides Moroccan researchers with a remotely accessible High-Performance Computing (HPC) infrastructure. The infrastructure consists of 38 nodes, each of which has the following capacity:
-
1. 1672 CPU Cores (165 TFlops)
-
2. 4 GPUs
-
3. 396 TB Storage
-
4. TB RAM
To enhance the replicability and reproducibility of our study, we provide detailed information to allow others to replicate our experiments. We also added a summary table (see Table 2) containing the algorithms’ hyperparameters. Here are specific steps to achieve this:
-
1. GeneticSelectionCV is a module of the scikit-learn library in Python. It is a feature selection technique that uses a genetic algorithm to optimize the feature subset for a machine-learning model while performing cross-validation.
-
2. BorutaPy library is a feature selection method for machine learning. The main objective of BorutaPy is to identify relevant features from a potentially large pool of features, improving the model’s performance and reducing the risk of overfitting.
-
3. Scikit-learn is a popular machine-learning library in Python that includes ensemble methods like Random Forest, AdaBoost, and Gradient Boosting, which combine multiple models to improve performance.
Table 2. Hyperparameters used for implementing feature selection methods and classifiers

4.2. Results obtained before applying feature selection method
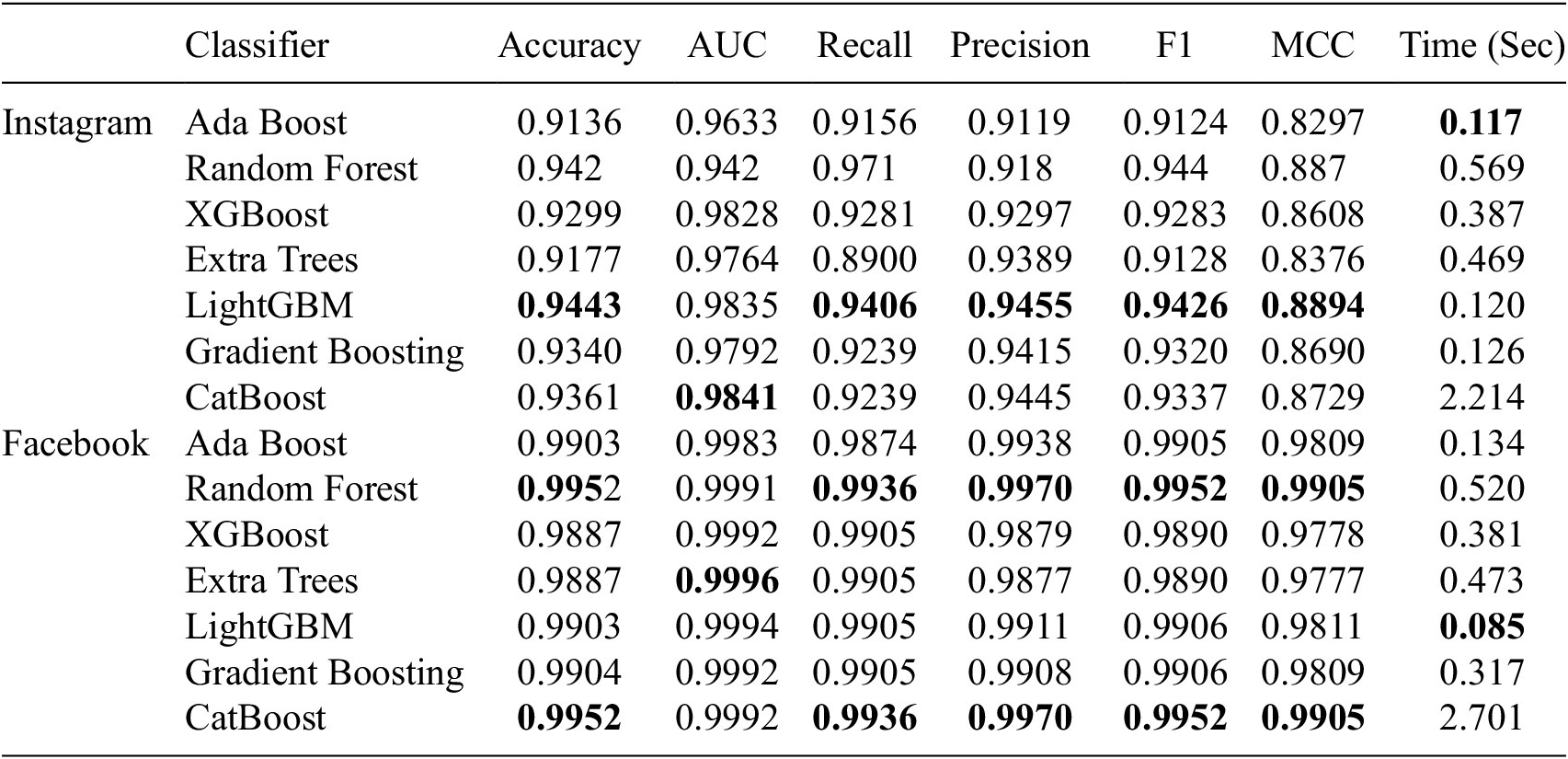
The primary goal of using these evaluation metrics is to determine how well a machine-learning model will perform on unseen data. For balanced datasets, metrics like accuracy, precision, and recall are useful for evaluating classification models. However, if the data is unbalanced, ROC/AUC provides a more accurate evaluation of model performance. Table 3 shows the result of classifiers. This table shows that catBoost yields the highest AUC on Instagram when it uses all features. In addition, Extra Trees achieved the best AUC using the Facebook dataset. Conversely, catboost consumes more execution time among all the classifiers before applying any feature selection method.
Table 3. Overall results of our experiment using full feature(selection)
4.3. Result obtained after applying Boruta feature selection method
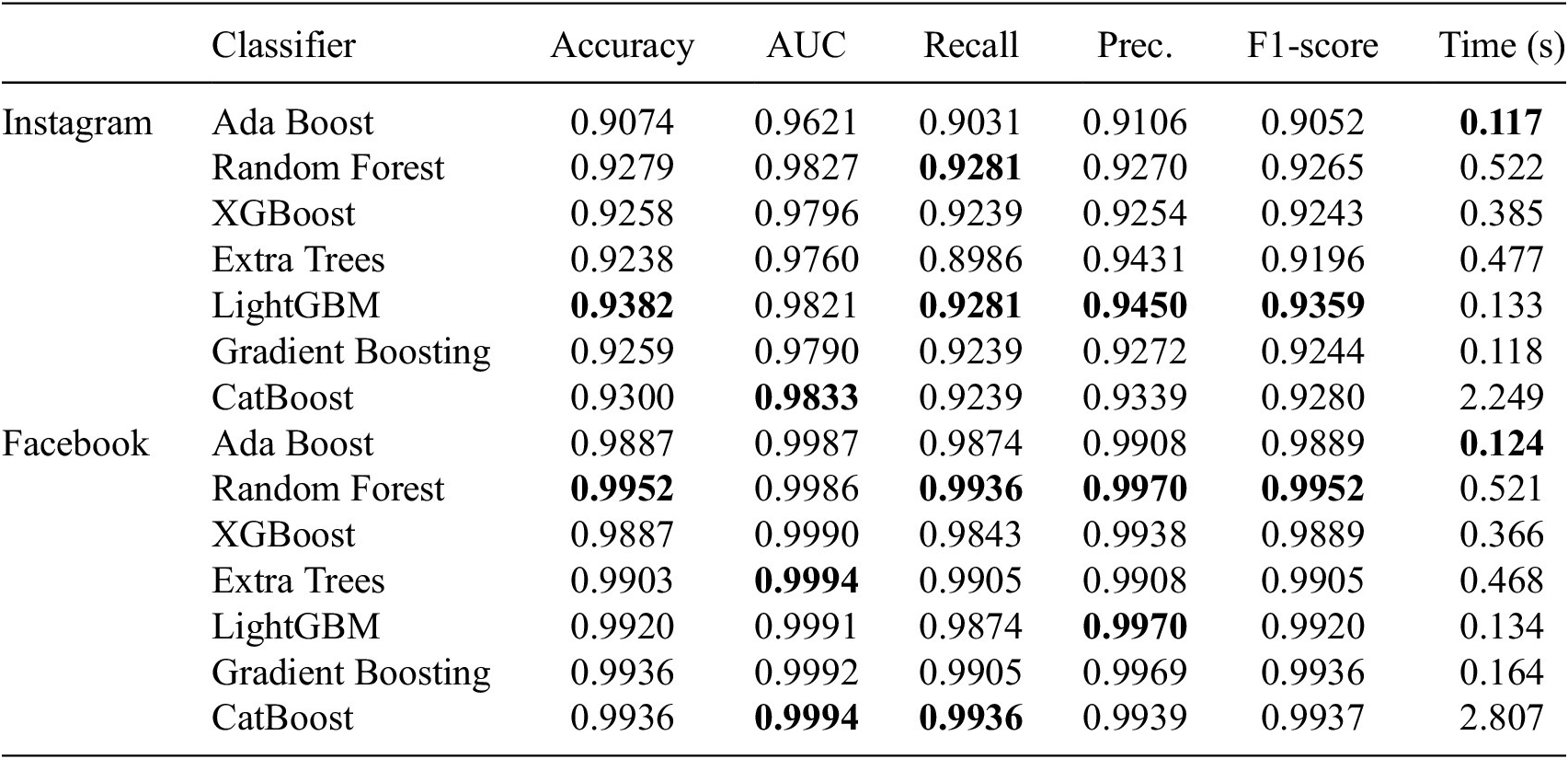
The Instagram dataset with 11 attributes was selected in the initial step of developing the prediction model to uncover all the important features impacting the fake account prediction. The outcomes of the selection are presented in Table 4. As shown in the table below, BORUTA highlighted the relevance of characteristics in the dataset. In this situation, 2 of the 11 features are rejected. As indicated in Table 5, Boruta uses 63% of the Facebook features offered. Following feature selection, the predictive model is built by considering the feature selection outcomes. Table 6 displays the outcome of classifiers after applying Boruta. According to the table, the classifiers’ AUCs stay consistent when compared to the Non-Selection technique, except for the Random Forest classifier, which obtained a 4% improvement in AUC when the Boruta feature selection was applied to the Instagram dataset.
Table 4. Ranking features by Boruta algorithm in Instagram
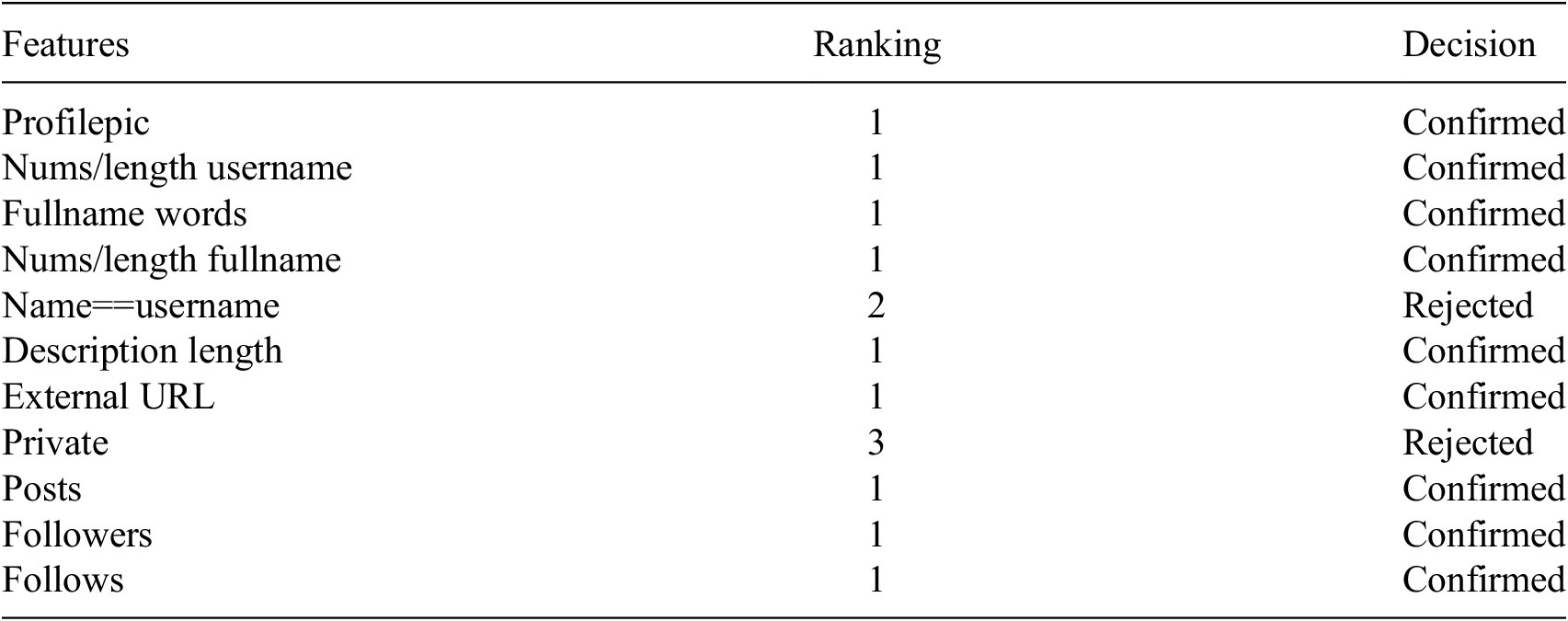
Table 5. Ranking features by Boruta algorithm in Facebook
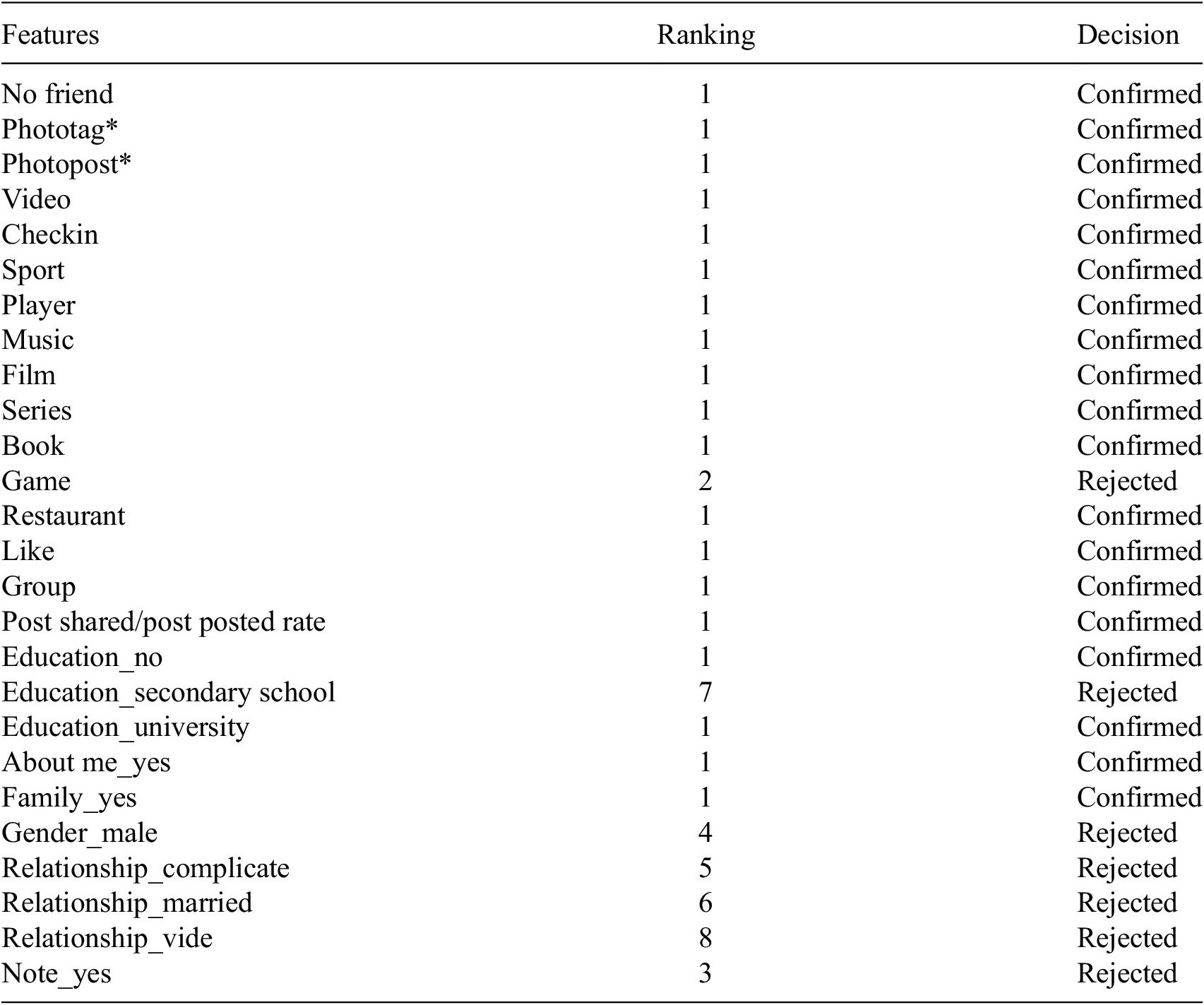
Table 6. Overall results of our experiment using Boruta
4.4. Result obtained after applying genetic algorithm feature selection method
By applying a genetic algorithm to choose the best combination of features with better accuracy than the baseline, We find an acceptable solution to reaching a certain number of generations. In our example, GA will stop after 50 generations.
The GA feature selection approach selects the most relevant features. Table 7 shows that the followers, fullname words,description length,posts and follows are essentials for predicting fake account in Instagram.
Table 7. Selected features by genetic algorithm in Instagram

Concerning Facebook, The main features chosen using the GA feature selection methodology are visualized in Table 8. According to the outcome of selection result, it can be concluded that the important features with Gradient Boosting and AdaBoost, that affect the prediction of fake profiles, are: No Friend, video, checkin, sport, like, group, post shared/post posted rate and about me.
Table 8. Selected features by genetic algorithm in Facebook

Table 9 shows the classification results for each classifier examined. AUC is an independent metric for evaluating the performance of a prediction model that relates the True Positive Rate (TPR) to the False Positive Rate (FPR). The best prediction model will have an AUC of 1. According to these results, the performance of the method without feature selection typically exhibited superior performance compared to the one using feature selection methods such as Genetic Algorithm (GA) and Boruta. Nevertheless, it is important to note that the results without feature selection displayed subtle distinctions of less than 07.04% and greater than 1.78% in terms of AUC for all machine-learning classifiers keeping only a subset of 63% among all Instagram features(see Tables 3 and 9). In this context, the findings suggest that a feature selection may eliminate a hundred or even thousands of features. This study also shows an exciting result; Gradient Boosting Classifier got a similar score with Non-selection and GA using 30% of Facebook features. Moreover, all classifiers (excluding GB Classifier) degraded AUC between 5% and 0.02% when the feature selection was applied to the Facebook dataset.
Table 9. Overall results of our experiment using genetic algorithm

Machine learning using all characteristics is not always advantageous since it takes considerable time to learn information about many different features. Tables 3, 6, and 9 show the time required to construct a model for each method. Comparing Boruta with Non-selection, the values imply that the genetic algorithm requires less time to construct a model than Boruta.
5. Conclusion and Future Scope
It is crucial to detect fake accounts in OSNs quickly and accurately. Various studies have employed machine learning to detect malicious fake accounts and feature selection to accelerate the process of solving this issue. Experiments were conducted in this study to select the appropriate features to apply machine learning based on previous research, and the findings of this research demonstrate the utility of employing genetic algorithm-based feature selection in comparison to the widely used Boruta technique. Furthermore, this approach offers a notable advantage over non-selection methods, primarily by significantly reducing the time necessary for model construction. However, the feature selection performance using the Gradient Boosting Classifier in conjunction with the GA algorithm yielded a promising result by reducing the number of features by 70%. We can conclude that using data without feature selection is the optimal method based on the evaluation metrics. However, considering the required time, selecting features using genetic algorithms is preferable. In the future, we aim to contribute to the development of strategies and tools that resonate with the unique dynamics of African OSNs. We also emphasize the importance of adapting machine-learning techniques to take account of the linguistic diversity, users’ behavior, and regional trends prevalent in African digital communities.
Funding statement
This research work is not funded by any governmental or non-governmental funding agencies.
Competing interest
The authors whose names are listed immediately below certify that they have no affiliations with or involvement in any organization or entity with any financial interest (such as honoraria; educational grants; participation in speakers’ bureaus; membership, employment, consultancies, stock ownership, or other equity interest; and expert testimony or patent-licensing arrangements), or non-financial interest (such as personal or professional relationships, affiliations, knowledge, or beliefs) in the subject matter or materials discussed in this manuscript.
Author contribution
Conceptualization, Methodology, Software, Writing—Reviewing and Editing: A.S.; Data curation, Writing—Original Draft Preparation: E.A.A.A.; Investigation, Methodology: S.C.K.T.; Visualization, Investigation, Software, Supervision: S.A.
Data availability statement
The datasets used during the current study are available in Albayati and Altamimi (Reference Albayati and Altamimi2019) and Bakhshandeh (Reference Bakhshandeh2019).
















 Open access
Open access
Comments
No Comments have been published for this article.